
| | |  Zobacz na GitHub Zobacz na GitHub | | |
YAMNet to wstępnie wytrenowana głęboka sieć neuronowa, która może przewidywać zdarzenia dźwiękowe z 521 klas , takie jak śmiech, szczekanie lub syrena.
W tym samouczku dowiesz się, jak:
- Załaduj i użyj modelu YAMNet do wnioskowania.
- Zbuduj nowy model, korzystając z osadzeń YAMNet, aby klasyfikować odgłosy kotów i psów.
- Oceń i wyeksportuj swój model.
Importuj TensorFlow i inne biblioteki
Zacznij od zainstalowania TensorFlow I/O , co ułatwi ładowanie plików audio z dysku.
pip install tensorflow_io
import os
from IPython import display
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_io as tfio
O YAMNet
YAMNet to wstępnie wytrenowana sieć neuronowa, która wykorzystuje architekturę konwolucji MobileNetV1 z możliwością głębokiej separacji. Może używać fali dźwiękowej jako sygnału wejściowego i dokonywać niezależnych prognoz dla każdego z 521 zdarzeń dźwiękowych z korpusu AudioSet .
Wewnętrznie model wyodrębnia „ramki” z sygnału audio i przetwarza partie tych ramek. Ta wersja modelu wykorzystuje klatki o długości 0,96 sekundy i wyodrębnia jedną klatkę co 0,48 sekundy.
Model akceptuje macierz 1-D float32 Tensor lub NumPy zawierającą przebieg o dowolnej długości, reprezentowany jako próbki jednokanałowe (mono) 16 kHz w zakresie [-1.0, +1.0] . Ten samouczek zawiera kod, który pomoże Ci przekonwertować pliki WAV do obsługiwanego formatu.
Model zwraca 3 dane wyjściowe, w tym wyniki klas, osadzenia (których użyjesz do uczenia transferu) i spektrogram log mel . Więcej szczegółów znajdziesz tutaj .
Jednym z konkretnych zastosowań YAMNet jest ekstrakcja funkcji na wysokim poziomie — 1024-wymiarowy wynik osadzania. Użyjesz funkcji wejściowych modelu bazowego (YAMNet) i wprowadzisz je do swojego płytszego modelu składającego się z jednej ukrytej warstwy tf.keras.layers.Dense . Następnie nauczysz sieć na niewielkiej ilości danych do klasyfikacji dźwięku, nie wymagając dużej ilości oznaczonych danych i szkolenia od końca do końca. (Jest to podobne do uczenia transferu w celu klasyfikacji obrazów za pomocą TensorFlow Hub , aby uzyskać więcej informacji.)
Najpierw przetestujesz model i zobaczysz wyniki klasyfikacji dźwięku. Następnie utworzysz potok wstępnego przetwarzania danych.
Ładowanie YAMNet z TensorFlow Hub
Użyjesz przeszkolonego YAMNet z Tensorflow Hub , aby wyodrębnić osadzania z plików dźwiękowych.
Ładowanie modelu z TensorFlow Hub jest proste: wybierz model, skopiuj jego adres URL i użyj funkcji load .
yamnet_model_handle = 'https://tfhub.dev/google/yamnet/1'
yamnet_model = hub.load(yamnet_model_handle)
Po załadowaniu modelu możesz postępować zgodnie z samouczkiem dotyczącym podstawowego użytkowania YAMNet i pobrać przykładowy plik WAV, aby uruchomić wnioskowanie.
testing_wav_file_name = tf.keras.utils.get_file('miaow_16k.wav',
'https://storage.googleapis.com/audioset/miaow_16k.wav',
cache_dir='./',
cache_subdir='test_data')
print(testing_wav_file_name)
Downloading data from https://storage.googleapis.com/audioset/miaow_16k.wav 221184/215546 [==============================] - 0s 0us/step 229376/215546 [===============================] - 0s 0us/step ./test_data/miaow_16k.wav
Będziesz potrzebować funkcji do wczytywania plików audio, która będzie używana później podczas pracy z danymi treningowymi. (Dowiedz się więcej o odczytywaniu plików audio i ich etykietach w sekcji Proste rozpoznawanie dźwięku .
# Utility functions for loading audio files and making sure the sample rate is correct.
@tf.function
def load_wav_16k_mono(filename):
""" Load a WAV file, convert it to a float tensor, resample to 16 kHz single-channel audio. """
file_contents = tf.io.read_file(filename)
wav, sample_rate = tf.audio.decode_wav(
file_contents,
desired_channels=1)
wav = tf.squeeze(wav, axis=-1)
sample_rate = tf.cast(sample_rate, dtype=tf.int64)
wav = tfio.audio.resample(wav, rate_in=sample_rate, rate_out=16000)
return wav
testing_wav_data = load_wav_16k_mono(testing_wav_file_name)
_ = plt.plot(testing_wav_data)
# Play the audio file.
display.Audio(testing_wav_data,rate=16000)
2022-01-26 08:07:19.084427: W tensorflow_io/core/kernels/audio_video_mp3_kernels.cc:271] libmp3lame.so.0 or lame functions are not available WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample

Załaduj mapowanie klas
Ważne jest, aby załadować nazwy klas, które YAMNet jest w stanie rozpoznać. Plik mapowania znajduje się w yamnet_model.class_map_path() w formacie CSV.
class_map_path = yamnet_model.class_map_path().numpy().decode('utf-8')
class_names =list(pd.read_csv(class_map_path)['display_name'])
for name in class_names[:20]:
print(name)
print('...')
Speech Child speech, kid speaking Conversation Narration, monologue Babbling Speech synthesizer Shout Bellow Whoop Yell Children shouting Screaming Whispering Laughter Baby laughter Giggle Snicker Belly laugh Chuckle, chortle Crying, sobbing ...
Uruchom wnioskowanie
YAMNet zapewnia wyniki klas na poziomie klatki (tj. 521 wyników dla każdej klatki). W celu określenia przewidywań na poziomie klipu, wyniki mogą być agregowane według klasy w klatkach (np. przy użyciu agregacji średniej lub maksymalnej). Odbywa się to poniżej przez scores_np.mean(axis=0) . Na koniec, aby znaleźć najwyżej punktowaną klasę na poziomie klipu, bierzesz maksimum z 521 zagregowanych wyników.
scores, embeddings, spectrogram = yamnet_model(testing_wav_data)
class_scores = tf.reduce_mean(scores, axis=0)
top_class = tf.argmax(class_scores)
inferred_class = class_names[top_class]
print(f'The main sound is: {inferred_class}')
print(f'The embeddings shape: {embeddings.shape}')
The main sound is: Animal The embeddings shape: (13, 1024)
Zbiór danych ESC-50
Zbiór danych ESC-50 ( Piczak, 2015 ) jest oznaczonym zbiorem 2000 pięciosekundowych nagrań dźwiękowych środowiska. Zbiór danych składa się z 50 klas, z 40 przykładami na klasę.
Pobierz zbiór danych i wyodrębnij go.
_ = tf.keras.utils.get_file('esc-50.zip',
'https://github.com/karoldvl/ESC-50/archive/master.zip',
cache_dir='./',
cache_subdir='datasets',
extract=True)
Downloading data from https://github.com/karoldvl/ESC-50/archive/master.zip 645103616/Unknown - 47s 0us/step
Przeglądaj dane
Metadane dla każdego pliku są określone w pliku csv pod adresem ./datasets/ESC-50-master/meta/esc50.csv
a wszystkie pliki audio znajdują się w ./datasets/ESC-50-master/audio/
Utworzysz pandy DataFrame z mapowaniem i użyjesz go, aby uzyskać wyraźniejszy widok danych.
esc50_csv = './datasets/ESC-50-master/meta/esc50.csv'
base_data_path = './datasets/ESC-50-master/audio/'
pd_data = pd.read_csv(esc50_csv)
pd_data.head()
Filtruj dane
Teraz, gdy dane są przechowywane w DataFrame , zastosuj kilka przekształceń:
- Odfiltruj wiersze i używaj tylko wybranych klas -
dogicat. Jeśli chcesz skorzystać z innych klas, tutaj możesz je wybrać. - Zmień nazwę pliku, aby zawierała pełną ścieżkę. Ułatwi to późniejsze ładowanie.
- Zmień cele, aby mieściły się w określonym zakresie. W tym przykładzie
dogpozostanie na0, alecatzmieni się na1zamiast pierwotnej wartości5.
my_classes = ['dog', 'cat']
map_class_to_id = {'dog':0, 'cat':1}
filtered_pd = pd_data[pd_data.category.isin(my_classes)]
class_id = filtered_pd['category'].apply(lambda name: map_class_to_id[name])
filtered_pd = filtered_pd.assign(target=class_id)
full_path = filtered_pd['filename'].apply(lambda row: os.path.join(base_data_path, row))
filtered_pd = filtered_pd.assign(filename=full_path)
filtered_pd.head(10)
Załaduj pliki audio i pobierz osadzania
Tutaj zastosujesz load_wav_16k_mono i przygotujesz dane WAV dla modelu.
Podczas wyodrębniania osadzeń z danych WAV otrzymujesz tablicę kształtów (N, 1024) gdzie N jest liczbą klatek znalezionych przez YAMNet (jedna na każde 0,48 sekundy dźwięku).
Twój model użyje każdej klatki jako jednego wejścia. Dlatego musisz utworzyć nową kolumnę, która ma jedną ramkę na wiersz. Musisz również rozwinąć etykiety i kolumnę fold , aby odpowiednio odzwierciedlić te nowe wiersze.
Rozszerzona kolumna fold zachowuje oryginalne wartości. Nie możesz mieszać klatek, ponieważ podczas wykonywania podziałów możesz mieć części tego samego dźwięku w różnych podziałach, co zmniejszyłoby skuteczność kroków walidacji i testowania.
filenames = filtered_pd['filename']
targets = filtered_pd['target']
folds = filtered_pd['fold']
main_ds = tf.data.Dataset.from_tensor_slices((filenames, targets, folds))
main_ds.element_spec
(TensorSpec(shape=(), dtype=tf.string, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
def load_wav_for_map(filename, label, fold):
return load_wav_16k_mono(filename), label, fold
main_ds = main_ds.map(load_wav_for_map)
main_ds.element_spec
WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample (TensorSpec(shape=<unknown>, dtype=tf.float32, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
# applies the embedding extraction model to a wav data
def extract_embedding(wav_data, label, fold):
''' run YAMNet to extract embedding from the wav data '''
scores, embeddings, spectrogram = yamnet_model(wav_data)
num_embeddings = tf.shape(embeddings)[0]
return (embeddings,
tf.repeat(label, num_embeddings),
tf.repeat(fold, num_embeddings))
# extract embedding
main_ds = main_ds.map(extract_embedding).unbatch()
main_ds.element_spec
(TensorSpec(shape=(1024,), dtype=tf.float32, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
Podziel dane
Użyjesz kolumny fold , aby podzielić zbiór danych na zestawy do pociągu, walidacji i testów.
ESC-50 jest ułożony w pięć jednakowych rozmiarów fold , tak że klipy z tego samego oryginalnego źródła są zawsze w tym samym fold - dowiedz się więcej w artykule ESC: Dataset for Environmental Sound Classification .
Ostatnim krokiem jest usunięcie kolumny fold z zestawu danych, ponieważ nie będziesz jej używać podczas treningu.
cached_ds = main_ds.cache()
train_ds = cached_ds.filter(lambda embedding, label, fold: fold < 4)
val_ds = cached_ds.filter(lambda embedding, label, fold: fold == 4)
test_ds = cached_ds.filter(lambda embedding, label, fold: fold == 5)
# remove the folds column now that it's not needed anymore
remove_fold_column = lambda embedding, label, fold: (embedding, label)
train_ds = train_ds.map(remove_fold_column)
val_ds = val_ds.map(remove_fold_column)
test_ds = test_ds.map(remove_fold_column)
train_ds = train_ds.cache().shuffle(1000).batch(32).prefetch(tf.data.AUTOTUNE)
val_ds = val_ds.cache().batch(32).prefetch(tf.data.AUTOTUNE)
test_ds = test_ds.cache().batch(32).prefetch(tf.data.AUTOTUNE)
Stwórz swój model
Wykonałeś większość pracy! Następnie zdefiniuj bardzo prosty model sekwencyjny z jedną ukrytą warstwą i dwoma wyjściami do rozpoznawania kotów i psów na podstawie dźwięków.
my_model = tf.keras.Sequential([
tf.keras.layers.Input(shape=(1024), dtype=tf.float32,
name='input_embedding'),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(len(my_classes))
], name='my_model')
my_model.summary()
Model: "my_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 512) 524800
dense_1 (Dense) (None, 2) 1026
=================================================================
Total params: 525,826
Trainable params: 525,826
Non-trainable params: 0
_________________________________________________________________
my_model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer="adam",
metrics=['accuracy'])
callback = tf.keras.callbacks.EarlyStopping(monitor='loss',
patience=3,
restore_best_weights=True)
history = my_model.fit(train_ds,
epochs=20,
validation_data=val_ds,
callbacks=callback)
Epoch 1/20 15/15 [==============================] - 6s 49ms/step - loss: 0.7811 - accuracy: 0.8229 - val_loss: 0.4866 - val_accuracy: 0.9125 Epoch 2/20 15/15 [==============================] - 0s 18ms/step - loss: 0.3385 - accuracy: 0.8938 - val_loss: 0.2185 - val_accuracy: 0.8813 Epoch 3/20 15/15 [==============================] - 0s 18ms/step - loss: 0.3091 - accuracy: 0.9021 - val_loss: 0.4290 - val_accuracy: 0.8813 Epoch 4/20 15/15 [==============================] - 0s 18ms/step - loss: 0.5354 - accuracy: 0.9062 - val_loss: 0.2074 - val_accuracy: 0.9125 Epoch 5/20 15/15 [==============================] - 0s 18ms/step - loss: 0.4651 - accuracy: 0.9333 - val_loss: 0.6857 - val_accuracy: 0.8813 Epoch 6/20 15/15 [==============================] - 0s 18ms/step - loss: 0.2489 - accuracy: 0.9167 - val_loss: 0.3640 - val_accuracy: 0.8750 Epoch 7/20 15/15 [==============================] - 0s 17ms/step - loss: 0.2020 - accuracy: 0.9292 - val_loss: 0.2158 - val_accuracy: 0.9125 Epoch 8/20 15/15 [==============================] - 0s 16ms/step - loss: 0.4550 - accuracy: 0.9208 - val_loss: 0.9893 - val_accuracy: 0.8750 Epoch 9/20 15/15 [==============================] - 0s 17ms/step - loss: 0.3434 - accuracy: 0.9354 - val_loss: 0.2670 - val_accuracy: 0.8813 Epoch 10/20 15/15 [==============================] - 0s 17ms/step - loss: 0.2864 - accuracy: 0.9208 - val_loss: 0.5122 - val_accuracy: 0.8813
Przeprowadźmy metodę evaluate na danych testowych, aby upewnić się, że nie ma przesadnego dopasowania.
loss, accuracy = my_model.evaluate(test_ds)
print("Loss: ", loss)
print("Accuracy: ", accuracy)
5/5 [==============================] - 0s 9ms/step - loss: 0.2526 - accuracy: 0.9000 Loss: 0.25257644057273865 Accuracy: 0.8999999761581421
Zrobiłeś to!
Przetestuj swój model
Następnie wypróbuj swój model na osadzeniu z poprzedniego testu, używając tylko YAMNet.
scores, embeddings, spectrogram = yamnet_model(testing_wav_data)
result = my_model(embeddings).numpy()
inferred_class = my_classes[result.mean(axis=0).argmax()]
print(f'The main sound is: {inferred_class}')
The main sound is: cat
Zapisz model, który może bezpośrednio pobrać plik WAV jako dane wejściowe
Twój model działa, gdy podasz mu osadzenia jako dane wejściowe.
W rzeczywistym scenariuszu będziesz chciał użyć danych dźwiękowych jako bezpośredniego wejścia.
W tym celu połączysz YAMNet ze swoim modelem w jeden model, który możesz wyeksportować do innych aplikacji.
Aby ułatwić korzystanie z wyniku modelu, ostatnią warstwą będzie operacja reduce_mean . Używając tego modelu do serwowania (o czym dowiesz się w dalszej części samouczka), będziesz potrzebować nazwy ostatniej warstwy. Jeśli go nie zdefiniujesz, TensorFlow automatycznie zdefiniuje przyrostowy, który utrudni testowanie, ponieważ będzie się zmieniał za każdym razem, gdy trenujesz model. Używając surowej operacji TensorFlow, nie możesz przypisać jej nazwy. Aby rozwiązać ten problem, utworzysz niestandardową warstwę, która stosuje reduce_mean i nazwiesz ją 'classifier' .
class ReduceMeanLayer(tf.keras.layers.Layer):
def __init__(self, axis=0, **kwargs):
super(ReduceMeanLayer, self).__init__(**kwargs)
self.axis = axis
def call(self, input):
return tf.math.reduce_mean(input, axis=self.axis)
saved_model_path = './dogs_and_cats_yamnet'
input_segment = tf.keras.layers.Input(shape=(), dtype=tf.float32, name='audio')
embedding_extraction_layer = hub.KerasLayer(yamnet_model_handle,
trainable=False, name='yamnet')
_, embeddings_output, _ = embedding_extraction_layer(input_segment)
serving_outputs = my_model(embeddings_output)
serving_outputs = ReduceMeanLayer(axis=0, name='classifier')(serving_outputs)
serving_model = tf.keras.Model(input_segment, serving_outputs)
serving_model.save(saved_model_path, include_optimizer=False)
WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. 2022-01-26 08:08:33.807036: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: ./dogs_and_cats_yamnet/assets INFO:tensorflow:Assets written to: ./dogs_and_cats_yamnet/assets
tf.keras.utils.plot_model(serving_model)
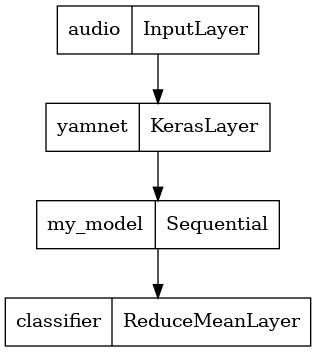
Załaduj zapisany model, aby sprawdzić, czy działa zgodnie z oczekiwaniami.
reloaded_model = tf.saved_model.load(saved_model_path)
A do końcowego testu: czy biorąc pod uwagę pewne dane dźwiękowe, czy Twój model zwraca poprawny wynik?
reloaded_results = reloaded_model(testing_wav_data)
cat_or_dog = my_classes[tf.argmax(reloaded_results)]
print(f'The main sound is: {cat_or_dog}')
The main sound is: cat
Jeśli chcesz wypróbować nowy model w konfiguracji udostępniania, możesz użyć podpisu „serving_default”.
serving_results = reloaded_model.signatures['serving_default'](testing_wav_data)
cat_or_dog = my_classes[tf.argmax(serving_results['classifier'])]
print(f'The main sound is: {cat_or_dog}')
The main sound is: cat
(Opcjonalnie) Jeszcze trochę testów
Model gotowy.
Porównajmy to z YAMNet na testowym zestawie danych.
test_pd = filtered_pd.loc[filtered_pd['fold'] == 5]
row = test_pd.sample(1)
filename = row['filename'].item()
print(filename)
waveform = load_wav_16k_mono(filename)
print(f'Waveform values: {waveform}')
_ = plt.plot(waveform)
display.Audio(waveform, rate=16000)
./datasets/ESC-50-master/audio/5-214759-A-5.wav WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample Waveform values: [ 3.2084468e-09 -7.7704687e-09 -1.2222010e-08 ... 2.2788899e-02 1.0315948e-02 -3.4766860e-02]
# Run the model, check the output.
scores, embeddings, spectrogram = yamnet_model(waveform)
class_scores = tf.reduce_mean(scores, axis=0)
top_class = tf.argmax(class_scores)
inferred_class = class_names[top_class]
top_score = class_scores[top_class]
print(f'[YAMNet] The main sound is: {inferred_class} ({top_score})')
reloaded_results = reloaded_model(waveform)
your_top_class = tf.argmax(reloaded_results)
your_inferred_class = my_classes[your_top_class]
class_probabilities = tf.nn.softmax(reloaded_results, axis=-1)
your_top_score = class_probabilities[your_top_class]
print(f'[Your model] The main sound is: {your_inferred_class} ({your_top_score})')
[YAMNet] The main sound is: Silence (0.500638484954834) [Your model] The main sound is: cat (0.9981643557548523)
Następne kroki
Stworzyłeś model, który potrafi klasyfikować dźwięki od psów lub kotów. Z tym samym pomysłem i innym zbiorem danych można spróbować np. zbudować akustyczny identyfikator ptaków na podstawie ich śpiewu.
Podziel się swoim projektem z zespołem TensorFlow w mediach społecznościowych!