
| | |  Xem trên GitHub Xem trên GitHub | | |
YAMNet là một mạng nơ-ron sâu được đào tạo trước có thể dự đoán các sự kiện âm thanh từ 521 lớp , chẳng hạn như tiếng cười, tiếng sủa hoặc còi báo động.
Trong hướng dẫn này, bạn sẽ học cách:
- Tải và sử dụng mô hình YAMNet để suy luận.
- Xây dựng một mô hình mới bằng cách sử dụng nhúng YAMNet để phân loại âm thanh của mèo và chó.
- Đánh giá và xuất mô hình của bạn.
Nhập TensorFlow và các thư viện khác
Bắt đầu bằng cách cài đặt TensorFlow I / O , điều này sẽ giúp bạn tải các tệp âm thanh ra đĩa dễ dàng hơn.
pip install tensorflow_io
import os
from IPython import display
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_io as tfio
Về YAMNet
YAMNet là một mạng nơ-ron được đào tạo trước sử dụng kiến trúc tích chập phân tách theo chiều sâu MobileNetV1 . Nó có thể sử dụng dạng sóng âm thanh làm đầu vào và đưa ra các dự đoán độc lập cho từng sự kiện âm thanh trong số 521 sự kiện âm thanh từ kho dữ liệu AudioSet .
Bên trong, mô hình trích xuất "khung" từ tín hiệu âm thanh và xử lý hàng loạt các khung này. Phiên bản của mô hình này sử dụng khung hình dài 0,96 giây và trích ra một khung hình cứ sau 0,48 giây.
Mô hình chấp nhận mảng 1-D float32 Tensor hoặc NumPy chứa dạng sóng có độ dài tùy ý, được biểu diễn dưới dạng các mẫu 16 kHz kênh đơn (mono) trong phạm vi [-1.0, +1.0] . Hướng dẫn này chứa mã để giúp bạn chuyển đổi tệp WAV sang định dạng được hỗ trợ.
Mô hình trả về 3 kết quả đầu ra, bao gồm điểm số của lớp, số lần nhúng (mà bạn sẽ sử dụng để học chuyển tiếp) và biểu đồ phổ log mel. Bạn có thể tìm thêm thông tin chi tiết tại đây .
Một công dụng cụ thể của YAMNet là như một công cụ trích xuất tính năng cấp cao - đầu ra nhúng 1.024 chiều. Bạn sẽ sử dụng các tính năng đầu vào của mô hình cơ sở (YAMNet) và đưa chúng vào mô hình nông hơn của bạn bao gồm một lớp tf.keras.layers.Dense ẩn. Sau đó, bạn sẽ đào tạo mạng về một lượng nhỏ dữ liệu để phân loại âm thanh mà không yêu cầu nhiều dữ liệu được gắn nhãn và đào tạo từ đầu đến cuối. (Điều này tương tự như chuyển giao học tập để phân loại hình ảnh với TensorFlow Hub để biết thêm thông tin.)
Đầu tiên, bạn sẽ chạy thử mô hình và xem kết quả phân loại âm thanh. Sau đó, bạn sẽ xây dựng đường ống xử lý trước dữ liệu.
Đang tải YAMNet từ TensorFlow Hub
Bạn sẽ sử dụng YAMNet được đào tạo trước từ Tensorflow Hub để trích xuất các bản nhúng từ các tệp âm thanh.
Việc tải mô hình từ TensorFlow Hub rất đơn giản: chọn mô hình, sao chép URL của nó và sử dụng chức năng load .
yamnet_model_handle = 'https://tfhub.dev/google/yamnet/1'
yamnet_model = hub.load(yamnet_model_handle)
Với mô hình được tải, bạn có thể làm theo hướng dẫn sử dụng cơ bản YAMNet và tải xuống tệp WAV mẫu để chạy suy luận.
testing_wav_file_name = tf.keras.utils.get_file('miaow_16k.wav',
'https://storage.googleapis.com/audioset/miaow_16k.wav',
cache_dir='./',
cache_subdir='test_data')
print(testing_wav_file_name)
Downloading data from https://storage.googleapis.com/audioset/miaow_16k.wav 221184/215546 [==============================] - 0s 0us/step 229376/215546 [===============================] - 0s 0us/step ./test_data/miaow_16k.wav
Bạn sẽ cần một chức năng để tải các tệp âm thanh, chức năng này cũng sẽ được sử dụng sau này khi làm việc với dữ liệu đào tạo. (Tìm hiểu thêm về cách đọc tệp âm thanh và nhãn của chúng trong Nhận dạng âm thanh đơn giản .
# Utility functions for loading audio files and making sure the sample rate is correct.
@tf.function
def load_wav_16k_mono(filename):
""" Load a WAV file, convert it to a float tensor, resample to 16 kHz single-channel audio. """
file_contents = tf.io.read_file(filename)
wav, sample_rate = tf.audio.decode_wav(
file_contents,
desired_channels=1)
wav = tf.squeeze(wav, axis=-1)
sample_rate = tf.cast(sample_rate, dtype=tf.int64)
wav = tfio.audio.resample(wav, rate_in=sample_rate, rate_out=16000)
return wav
testing_wav_data = load_wav_16k_mono(testing_wav_file_name)
_ = plt.plot(testing_wav_data)
# Play the audio file.
display.Audio(testing_wav_data,rate=16000)
2022-01-26 08:07:19.084427: W tensorflow_io/core/kernels/audio_video_mp3_kernels.cc:271] libmp3lame.so.0 or lame functions are not available WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample

Tải ánh xạ lớp
Điều quan trọng là tải các tên lớp mà YAMNet có thể nhận ra. Tệp ánh xạ có tại yamnet_model.class_map_path() ở định dạng CSV.
class_map_path = yamnet_model.class_map_path().numpy().decode('utf-8')
class_names =list(pd.read_csv(class_map_path)['display_name'])
for name in class_names[:20]:
print(name)
print('...')
Speech Child speech, kid speaking Conversation Narration, monologue Babbling Speech synthesizer Shout Bellow Whoop Yell Children shouting Screaming Whispering Laughter Baby laughter Giggle Snicker Belly laugh Chuckle, chortle Crying, sobbing ...
Chạy suy luận
YAMNet cung cấp điểm số ở cấp độ khung hình (tức là 521 điểm cho mỗi khung hình). Để xác định các dự đoán cấp độ clip, điểm số có thể được tổng hợp cho mỗi lớp trên các khung hình (ví dụ: sử dụng tổng hợp trung bình hoặc tối đa). Điều này được thực hiện bên dưới bởi scores_np.mean(axis=0) . Cuối cùng, để tìm ra lớp có điểm số cao nhất ở cấp độ clip, bạn lấy tối đa 521 điểm tổng hợp.
scores, embeddings, spectrogram = yamnet_model(testing_wav_data)
class_scores = tf.reduce_mean(scores, axis=0)
top_class = tf.argmax(class_scores)
inferred_class = class_names[top_class]
print(f'The main sound is: {inferred_class}')
print(f'The embeddings shape: {embeddings.shape}')
The main sound is: Animal The embeddings shape: (13, 1024)
Bộ dữ liệu ESC-50
Bộ dữ liệu ESC-50 ( Piczak, 2015 ) là một bộ sưu tập được gắn nhãn gồm 2.000 bản ghi âm môi trường dài năm giây. Tập dữ liệu bao gồm 50 lớp, với 40 ví dụ cho mỗi lớp.
Tải xuống tập dữ liệu và giải nén nó.
_ = tf.keras.utils.get_file('esc-50.zip',
'https://github.com/karoldvl/ESC-50/archive/master.zip',
cache_dir='./',
cache_subdir='datasets',
extract=True)
Downloading data from https://github.com/karoldvl/ESC-50/archive/master.zip 645103616/Unknown - 47s 0us/step
Khám phá dữ liệu
Siêu dữ liệu cho mỗi tệp được chỉ định trong tệp csv tại ./datasets/ESC-50-master/meta/esc50.csv
và tất cả các tệp âm thanh đều ở trong ./datasets/ESC-50-master/audio/
Bạn sẽ tạo DataFrame gấu trúc với ánh xạ và sử dụng nó để có cái nhìn rõ ràng hơn về dữ liệu.
esc50_csv = './datasets/ESC-50-master/meta/esc50.csv'
base_data_path = './datasets/ESC-50-master/audio/'
pd_data = pd.read_csv(esc50_csv)
pd_data.head()
Lọc dữ liệu
Bây giờ dữ liệu được lưu trữ trong DataFrame , hãy áp dụng một số biến đổi:
- Lọc ra các hàng và chỉ sử dụng các lớp đã chọn -
dogvàcat. Nếu bạn muốn sử dụng bất kỳ lớp nào khác, đây là nơi bạn có thể chọn chúng. - Sửa đổi tên tệp để có đường dẫn đầy đủ. Điều này sẽ giúp tải dễ dàng hơn sau này.
- Thay đổi mục tiêu để nằm trong một phạm vi cụ thể. Trong ví dụ này,
dogsẽ vẫn ở mức0, nhưngcatsẽ trở thành1thay vì giá trị ban đầu của nó là5.
my_classes = ['dog', 'cat']
map_class_to_id = {'dog':0, 'cat':1}
filtered_pd = pd_data[pd_data.category.isin(my_classes)]
class_id = filtered_pd['category'].apply(lambda name: map_class_to_id[name])
filtered_pd = filtered_pd.assign(target=class_id)
full_path = filtered_pd['filename'].apply(lambda row: os.path.join(base_data_path, row))
filtered_pd = filtered_pd.assign(filename=full_path)
filtered_pd.head(10)
Tải các tệp âm thanh và truy xuất các bản nhúng
Tại đây, bạn sẽ áp dụng load_wav_16k_mono và chuẩn bị dữ liệu WAV cho mô hình.
Khi trích xuất các bản nhúng từ dữ liệu WAV, bạn sẽ nhận được một mảng hình dạng (N, 1024) trong đó N là số khung hình mà YAMNet tìm thấy (một khung hình cho mỗi 0,48 giây âm thanh).
Mô hình của bạn sẽ sử dụng mỗi khung làm một đầu vào. Do đó, bạn cần tạo một cột mới có một khung trên mỗi hàng. Bạn cũng cần mở rộng các nhãn và cột fold đầu tiên để phản ánh đúng các hàng mới này.
Cột fold đầu tiên được mở rộng giữ nguyên các giá trị ban đầu. Bạn không thể kết hợp các khung hình vì khi thực hiện các phần tách, bạn có thể có các phần của cùng một âm thanh trên các phần khác nhau, điều này sẽ làm cho các bước xác thực và kiểm tra của bạn kém hiệu quả hơn.
filenames = filtered_pd['filename']
targets = filtered_pd['target']
folds = filtered_pd['fold']
main_ds = tf.data.Dataset.from_tensor_slices((filenames, targets, folds))
main_ds.element_spec
(TensorSpec(shape=(), dtype=tf.string, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
def load_wav_for_map(filename, label, fold):
return load_wav_16k_mono(filename), label, fold
main_ds = main_ds.map(load_wav_for_map)
main_ds.element_spec
WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample (TensorSpec(shape=<unknown>, dtype=tf.float32, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
# applies the embedding extraction model to a wav data
def extract_embedding(wav_data, label, fold):
''' run YAMNet to extract embedding from the wav data '''
scores, embeddings, spectrogram = yamnet_model(wav_data)
num_embeddings = tf.shape(embeddings)[0]
return (embeddings,
tf.repeat(label, num_embeddings),
tf.repeat(fold, num_embeddings))
# extract embedding
main_ds = main_ds.map(extract_embedding).unbatch()
main_ds.element_spec
(TensorSpec(shape=(1024,), dtype=tf.float32, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
Tách dữ liệu
Bạn sẽ sử dụng cột fold để chia tập dữ liệu thành các tập huấn luyện, xác nhận và thử nghiệm.
ESC-50 được sắp xếp thành năm fold xác thực chéo có kích thước đồng nhất, sao cho các clip từ cùng một nguồn gốc luôn ở trong cùng một fold - tìm hiểu thêm trong bài báo Phân loại Âm thanh Môi trường của ESC: Dataset .
Bước cuối cùng là xóa cột fold đầu tiên khỏi tập dữ liệu vì bạn sẽ không sử dụng nó trong quá trình đào tạo.
cached_ds = main_ds.cache()
train_ds = cached_ds.filter(lambda embedding, label, fold: fold < 4)
val_ds = cached_ds.filter(lambda embedding, label, fold: fold == 4)
test_ds = cached_ds.filter(lambda embedding, label, fold: fold == 5)
# remove the folds column now that it's not needed anymore
remove_fold_column = lambda embedding, label, fold: (embedding, label)
train_ds = train_ds.map(remove_fold_column)
val_ds = val_ds.map(remove_fold_column)
test_ds = test_ds.map(remove_fold_column)
train_ds = train_ds.cache().shuffle(1000).batch(32).prefetch(tf.data.AUTOTUNE)
val_ds = val_ds.cache().batch(32).prefetch(tf.data.AUTOTUNE)
test_ds = test_ds.cache().batch(32).prefetch(tf.data.AUTOTUNE)
Tạo mô hình của bạn
Bạn đã làm hầu hết công việc! Tiếp theo, xác định một mô hình Tuần tự rất đơn giản với một lớp ẩn và hai đầu ra để nhận dạng mèo và chó từ âm thanh.
my_model = tf.keras.Sequential([
tf.keras.layers.Input(shape=(1024), dtype=tf.float32,
name='input_embedding'),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(len(my_classes))
], name='my_model')
my_model.summary()
Model: "my_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 512) 524800
dense_1 (Dense) (None, 2) 1026
=================================================================
Total params: 525,826
Trainable params: 525,826
Non-trainable params: 0
_________________________________________________________________
my_model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer="adam",
metrics=['accuracy'])
callback = tf.keras.callbacks.EarlyStopping(monitor='loss',
patience=3,
restore_best_weights=True)
history = my_model.fit(train_ds,
epochs=20,
validation_data=val_ds,
callbacks=callback)
Epoch 1/20 15/15 [==============================] - 6s 49ms/step - loss: 0.7811 - accuracy: 0.8229 - val_loss: 0.4866 - val_accuracy: 0.9125 Epoch 2/20 15/15 [==============================] - 0s 18ms/step - loss: 0.3385 - accuracy: 0.8938 - val_loss: 0.2185 - val_accuracy: 0.8813 Epoch 3/20 15/15 [==============================] - 0s 18ms/step - loss: 0.3091 - accuracy: 0.9021 - val_loss: 0.4290 - val_accuracy: 0.8813 Epoch 4/20 15/15 [==============================] - 0s 18ms/step - loss: 0.5354 - accuracy: 0.9062 - val_loss: 0.2074 - val_accuracy: 0.9125 Epoch 5/20 15/15 [==============================] - 0s 18ms/step - loss: 0.4651 - accuracy: 0.9333 - val_loss: 0.6857 - val_accuracy: 0.8813 Epoch 6/20 15/15 [==============================] - 0s 18ms/step - loss: 0.2489 - accuracy: 0.9167 - val_loss: 0.3640 - val_accuracy: 0.8750 Epoch 7/20 15/15 [==============================] - 0s 17ms/step - loss: 0.2020 - accuracy: 0.9292 - val_loss: 0.2158 - val_accuracy: 0.9125 Epoch 8/20 15/15 [==============================] - 0s 16ms/step - loss: 0.4550 - accuracy: 0.9208 - val_loss: 0.9893 - val_accuracy: 0.8750 Epoch 9/20 15/15 [==============================] - 0s 17ms/step - loss: 0.3434 - accuracy: 0.9354 - val_loss: 0.2670 - val_accuracy: 0.8813 Epoch 10/20 15/15 [==============================] - 0s 17ms/step - loss: 0.2864 - accuracy: 0.9208 - val_loss: 0.5122 - val_accuracy: 0.8813
Hãy chạy phương pháp evaluate trên dữ liệu thử nghiệm chỉ để đảm bảo không có trang bị quá mức.
loss, accuracy = my_model.evaluate(test_ds)
print("Loss: ", loss)
print("Accuracy: ", accuracy)
5/5 [==============================] - 0s 9ms/step - loss: 0.2526 - accuracy: 0.9000 Loss: 0.25257644057273865 Accuracy: 0.8999999761581421
Bạn làm được rồi!
Kiểm tra mô hình của bạn
Tiếp theo, hãy thử mô hình của bạn trên cách nhúng từ thử nghiệm trước chỉ sử dụng YAMNet.
scores, embeddings, spectrogram = yamnet_model(testing_wav_data)
result = my_model(embeddings).numpy()
inferred_class = my_classes[result.mean(axis=0).argmax()]
print(f'The main sound is: {inferred_class}')
The main sound is: cat
Lưu một mô hình có thể lấy trực tiếp tệp WAV làm đầu vào
Mô hình của bạn hoạt động khi bạn cung cấp cho nó các nhúng làm đầu vào.
Trong tình huống thực tế, bạn sẽ muốn sử dụng dữ liệu âm thanh làm đầu vào trực tiếp.
Để làm điều đó, bạn sẽ kết hợp YAMNet với mô hình của mình thành một mô hình duy nhất mà bạn có thể xuất cho các ứng dụng khác.
Để giúp sử dụng kết quả của mô hình dễ dàng hơn, lớp cuối cùng sẽ là một phép toán reduce_mean . Khi sử dụng mô hình này để phục vụ (bạn sẽ tìm hiểu về phần sau của hướng dẫn), bạn sẽ cần tên của lớp cuối cùng. Nếu bạn không xác định một giá trị, TensorFlow sẽ tự động xác định một giá trị gia tăng khiến bạn khó kiểm tra, vì nó sẽ tiếp tục thay đổi mỗi khi bạn đào tạo mô hình. Khi sử dụng một hoạt động TensorFlow thô, bạn không thể chỉ định tên cho nó. Để giải quyết vấn đề này, bạn sẽ tạo một lớp tùy chỉnh áp dụng reduce_mean và gọi nó 'classifier' .
class ReduceMeanLayer(tf.keras.layers.Layer):
def __init__(self, axis=0, **kwargs):
super(ReduceMeanLayer, self).__init__(**kwargs)
self.axis = axis
def call(self, input):
return tf.math.reduce_mean(input, axis=self.axis)
saved_model_path = './dogs_and_cats_yamnet'
input_segment = tf.keras.layers.Input(shape=(), dtype=tf.float32, name='audio')
embedding_extraction_layer = hub.KerasLayer(yamnet_model_handle,
trainable=False, name='yamnet')
_, embeddings_output, _ = embedding_extraction_layer(input_segment)
serving_outputs = my_model(embeddings_output)
serving_outputs = ReduceMeanLayer(axis=0, name='classifier')(serving_outputs)
serving_model = tf.keras.Model(input_segment, serving_outputs)
serving_model.save(saved_model_path, include_optimizer=False)
WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. 2022-01-26 08:08:33.807036: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: ./dogs_and_cats_yamnet/assets INFO:tensorflow:Assets written to: ./dogs_and_cats_yamnet/assets
tf.keras.utils.plot_model(serving_model)
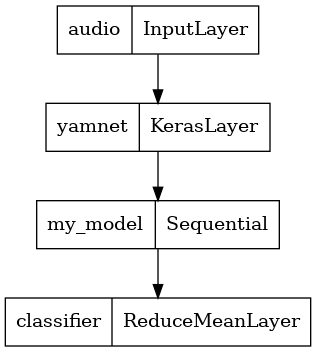
Tải mô hình đã lưu của bạn để xác minh rằng nó hoạt động như mong đợi.
reloaded_model = tf.saved_model.load(saved_model_path)
Và đối với bài kiểm tra cuối cùng: với một số dữ liệu âm thanh, mô hình của bạn có trả lại kết quả chính xác không?
reloaded_results = reloaded_model(testing_wav_data)
cat_or_dog = my_classes[tf.argmax(reloaded_results)]
print(f'The main sound is: {cat_or_dog}')
The main sound is: cat
Nếu bạn muốn thử mô hình mới của mình trên thiết lập phục vụ, bạn có thể sử dụng chữ ký 'serve_default'.
serving_results = reloaded_model.signatures['serving_default'](testing_wav_data)
cat_or_dog = my_classes[tf.argmax(serving_results['classifier'])]
print(f'The main sound is: {cat_or_dog}')
The main sound is: cat
(Tùy chọn) Một số thử nghiệm khác
Mô hình đã sẵn sàng.
Hãy so sánh nó với YAMNet trên tập dữ liệu thử nghiệm.
test_pd = filtered_pd.loc[filtered_pd['fold'] == 5]
row = test_pd.sample(1)
filename = row['filename'].item()
print(filename)
waveform = load_wav_16k_mono(filename)
print(f'Waveform values: {waveform}')
_ = plt.plot(waveform)
display.Audio(waveform, rate=16000)
./datasets/ESC-50-master/audio/5-214759-A-5.wav WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample Waveform values: [ 3.2084468e-09 -7.7704687e-09 -1.2222010e-08 ... 2.2788899e-02 1.0315948e-02 -3.4766860e-02]
# Run the model, check the output.
scores, embeddings, spectrogram = yamnet_model(waveform)
class_scores = tf.reduce_mean(scores, axis=0)
top_class = tf.argmax(class_scores)
inferred_class = class_names[top_class]
top_score = class_scores[top_class]
print(f'[YAMNet] The main sound is: {inferred_class} ({top_score})')
reloaded_results = reloaded_model(waveform)
your_top_class = tf.argmax(reloaded_results)
your_inferred_class = my_classes[your_top_class]
class_probabilities = tf.nn.softmax(reloaded_results, axis=-1)
your_top_score = class_probabilities[your_top_class]
print(f'[Your model] The main sound is: {your_inferred_class} ({your_top_score})')
[YAMNet] The main sound is: Silence (0.500638484954834) [Your model] The main sound is: cat (0.9981643557548523)
Bước tiếp theo
Bạn đã tạo ra một mô hình có thể phân loại âm thanh từ chó hoặc mèo. Ví dụ, với cùng một ý tưởng và một tập dữ liệu khác, bạn có thể thử xây dựng một bộ nhận dạng âm thanh của các loài chim dựa trên tiếng hót của chúng.
Chia sẻ dự án của bạn với nhóm TensorFlow trên mạng xã hội!