
| | |  GitHub-এ উৎস দেখুন GitHub-এ উৎস দেখুন | |
এই নির্দেশিকাটি প্রজাতি অনুসারে আইরিস ফুলকে শ্রেণীবদ্ধ করতে মেশিন লার্নিং ব্যবহার করে। এটি TensorFlow ব্যবহার করে:
- একটি মডেল তৈরি করুন,
- উদাহরণ তথ্যের উপর এই মডেল প্রশিক্ষণ, এবং
- অজানা তথ্য সম্পর্কে ভবিষ্যদ্বাণী করতে মডেল ব্যবহার করুন.
টেনসরফ্লো প্রোগ্রামিং
এই নির্দেশিকা এই উচ্চ-স্তরের TensorFlow ধারণাগুলি ব্যবহার করে:
- TensorFlow এর ডিফল্ট উদগ্রীব এক্সিকিউশন ডেভেলপমেন্ট এনভায়রনমেন্ট ব্যবহার করুন,
- ডেটাসেট API দিয়ে ডেটা আমদানি করুন ,
- TensorFlow এর Keras API দিয়ে মডেল এবং স্তর তৈরি করুন।
এই টিউটোরিয়ালটি অনেক TensorFlow প্রোগ্রামের মত গঠন করা হয়েছে:
- ডেটাসেট আমদানি এবং পার্স করুন।
- মডেলের ধরন নির্বাচন করুন।
- মডেলকে প্রশিক্ষণ দিন।
- মডেলের কার্যকারিতা মূল্যায়ন করুন।
- ভবিষ্যদ্বাণী করতে প্রশিক্ষিত মডেল ব্যবহার করুন.
সেটআপ প্রোগ্রাম
আমদানি কনফিগার করুন
TensorFlow এবং অন্যান্য প্রয়োজনীয় পাইথন মডিউল আমদানি করুন। ডিফল্টরূপে, TensorFlow ক্রিয়াকলাপগুলি অবিলম্বে মূল্যায়ন করার জন্য উদগ্রীব সম্পাদন ব্যবহার করে, একটি গণনামূলক গ্রাফ তৈরি করার পরিবর্তে কংক্রিট মান ফিরিয়ে দেয় যা পরে কার্যকর করা হয়। আপনি যদি একটি REPL বা python ইন্টারেক্টিভ কনসোলে অভ্যস্ত হয়ে থাকেন তবে এটি পরিচিত মনে হয়।
import os
import matplotlib.pyplot as plt
import tensorflow as tf
print("TensorFlow version: {}".format(tf.__version__))
print("Eager execution: {}".format(tf.executing_eagerly()))
TensorFlow version: 2.8.0-rc1 Eager execution: True
আইরিস শ্রেণীবিভাগ সমস্যা
কল্পনা করুন যে আপনি একজন উদ্ভিদবিদ যা আপনি খুঁজে পাওয়া প্রতিটি আইরিস ফুলকে শ্রেণীবদ্ধ করার জন্য একটি স্বয়ংক্রিয় উপায় খুঁজছেন। মেশিন লার্নিং ফুলকে পরিসংখ্যানগতভাবে শ্রেণীবদ্ধ করার জন্য অনেক অ্যালগরিদম প্রদান করে। উদাহরণস্বরূপ, একটি অত্যাধুনিক মেশিন লার্নিং প্রোগ্রাম ফটোগ্রাফের উপর ভিত্তি করে ফুলকে শ্রেণীবদ্ধ করতে পারে। আমাদের উচ্চাকাঙ্ক্ষা আরও বিনয়ী—আমরা আইরিস ফুলকে তাদের সিপাল এবং পাপড়ির দৈর্ঘ্য এবং প্রস্থ পরিমাপের উপর ভিত্তি করে শ্রেণিবদ্ধ করতে যাচ্ছি।
আইরিস জেনাসে প্রায় 300টি প্রজাতি রয়েছে, তবে আমাদের প্রোগ্রামটি শুধুমাত্র নিম্নলিখিত তিনটিকে শ্রেণীবদ্ধ করবে:
- আইরিস সেটোসা
- আইরিস ভার্জিনিকা
- আইরিস ভার্সিকলার
 |
| চিত্র 1. আইরিস সেটোসা ( রাডোমিল , সিসি বাই-এসএ 3.0 দ্বারা), আইরিস ভার্সিকলার , ( ডলাংলোইস , সিসি বাই-এসএ 3.0 দ্বারা), এবং আইরিস ভার্জিনিকা ( ফ্রাঙ্ক মেফিল্ড , সিসি বাই-এসএ 2.0 দ্বারা)। |
সৌভাগ্যবশত, কেউ ইতিমধ্যেই সেপাল এবং পাপড়ির পরিমাপ সহ 120টি আইরিস ফুলের একটি ডেটাসেট তৈরি করেছে৷ এটি একটি ক্লাসিক ডেটাসেট যা শিক্ষানবিস মেশিন লার্নিং ক্লাসিফিকেশন সমস্যার জন্য জনপ্রিয়।
প্রশিক্ষণ ডেটাসেট আমদানি এবং পার্স করুন
ডেটাসেট ফাইলটি ডাউনলোড করুন এবং এটিকে একটি কাঠামোতে রূপান্তর করুন যা এই পাইথন প্রোগ্রাম দ্বারা ব্যবহার করা যেতে পারে।
ডেটাসেট ডাউনলোড করুন
tf.keras.utils.get_file ফাংশন ব্যবহার করে প্রশিক্ষণ ডেটাসেট ফাইলটি ডাউনলোড করুন। এটি ডাউনলোড করা ফাইলের ফাইল পাথ ফেরত দেয়:
train_dataset_url = "https://storage.googleapis.com/download.tensorflow.org/data/iris_training.csv"
train_dataset_fp = tf.keras.utils.get_file(fname=os.path.basename(train_dataset_url),
origin=train_dataset_url)
print("Local copy of the dataset file: {}".format(train_dataset_fp))
Local copy of the dataset file: /home/kbuilder/.keras/datasets/iris_training.csv
ডেটা পরিদর্শন করুন
এই ডেটাসেট, iris_training.csv , একটি প্লেইন টেক্সট ফাইল যা কমা-বিভাজিত মান (CSV) হিসাবে ফর্ম্যাট করা ট্যাবুলার ডেটা সঞ্চয় করে। প্রথম পাঁচটি এন্ট্রিতে উঁকি দিতে head -n5 কমান্ডটি ব্যবহার করুন:
head -n5 {train_dataset_fp}
120,4,setosa,versicolor,virginica 6.4,2.8,5.6,2.2,2 5.0,2.3,3.3,1.0,1 4.9,2.5,4.5,1.7,2 4.9,3.1,1.5,0.1,0
ডেটাসেটের এই দৃশ্য থেকে, নিম্নলিখিতগুলি লক্ষ্য করুন:
- প্রথম লাইনটি ডেটাসেট সম্পর্কে তথ্য ধারণকারী একটি শিরোনাম:
- মোট 120টি উদাহরণ রয়েছে। প্রতিটি উদাহরণে চারটি বৈশিষ্ট্য এবং তিনটি সম্ভাব্য লেবেল নামের একটি রয়েছে৷
- পরবর্তী সারিগুলি ডেটা রেকর্ড, প্রতি লাইনে একটি উদাহরণ , যেখানে:
আসুন কোডে এটি লিখি:
# column order in CSV file
column_names = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species']
feature_names = column_names[:-1]
label_name = column_names[-1]
print("Features: {}".format(feature_names))
print("Label: {}".format(label_name))
Features: ['sepal_length', 'sepal_width', 'petal_length', 'petal_width'] Label: species
প্রতিটি লেবেল স্ট্রিং নামের সাথে যুক্ত থাকে (উদাহরণস্বরূপ, "সেটোসা"), কিন্তু মেশিন লার্নিং সাধারণত সংখ্যাসূচক মানের উপর নির্ভর করে। লেবেল নম্বরগুলি একটি নামযুক্ত প্রতিনিধিত্বে ম্যাপ করা হয়, যেমন:
-
0: আইরিস সেটোসা -
1: আইরিস ভার্সিকলার -
2: আইরিস ভার্জিনিকা
বৈশিষ্ট্য এবং লেবেল সম্পর্কে আরও তথ্যের জন্য, মেশিন লার্নিং ক্র্যাশ কোর্সের ML পরিভাষা বিভাগটি দেখুন।
class_names = ['Iris setosa', 'Iris versicolor', 'Iris virginica']
একটি tf.data.Dataset তৈরি করুন
TensorFlow এর ডেটাসেট API একটি মডেলে ডেটা লোড করার জন্য অনেক সাধারণ ক্ষেত্রে পরিচালনা করে। এটি একটি উচ্চ-স্তরের API ডেটা পড়ার এবং প্রশিক্ষণের জন্য ব্যবহৃত একটি ফর্মে রূপান্তরিত করার জন্য।
যেহেতু ডেটাসেটটি একটি CSV-ফরম্যাট করা টেক্সট ফাইল, তাই একটি উপযুক্ত ফর্ম্যাটে ডেটা পার্স করতে tf.data.experimental.make_csv_dataset ফাংশনটি ব্যবহার করুন। যেহেতু এই ফাংশনটি প্রশিক্ষণ মডেলের জন্য ডেটা তৈরি করে, তাই ডিফল্ট আচরণ হল ডেটা ( shuffle=True, shuffle_buffer_size=10000 ), এবং ডেটাসেটটি চিরতরে পুনরাবৃত্তি করা ( num_epochs=None )। আমরা ব্যাচ_সাইজ প্যারামিটারও সেট করি:
batch_size = 32
train_dataset = tf.data.experimental.make_csv_dataset(
train_dataset_fp,
batch_size,
column_names=column_names,
label_name=label_name,
num_epochs=1)
make_csv_dataset ফাংশনটি (features, label) জোড়ার একটি tf.data.Dataset প্রদান করে, যেখানে features একটি অভিধান: {'feature_name': value}
এই Dataset অবজেক্টগুলি পুনরাবৃত্তিযোগ্য। আসুন বৈশিষ্ট্যগুলির একটি ব্যাচ দেখি:
features, labels = next(iter(train_dataset))
print(features)
OrderedDict([('sepal_length', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([5. , 7.4, 6. , 7.2, 5.9, 5.8, 5. , 5. , 7.7, 5.7, 6.3, 5.8, 5. ,
4.8, 6.6, 6.3, 5.4, 6.9, 4.8, 6.6, 5.8, 7.7, 6.7, 7.6, 5.5, 6.4,
5.6, 6.4, 4.4, 4.5, 6.5, 6.3], dtype=float32)>), ('sepal_width', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([3.5, 2.8, 2.7, 3.2, 3. , 2.6, 2. , 3.4, 3. , 2.8, 2.3, 2.7, 3.6,
3.1, 2.9, 3.3, 3. , 3.1, 3. , 3. , 4. , 2.6, 3. , 3. , 2.4, 2.7,
2.7, 2.8, 3. , 2.3, 2.8, 2.5], dtype=float32)>), ('petal_length', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([1.6, 6.1, 5.1, 6. , 5.1, 4. , 3.5, 1.6, 6.1, 4.5, 4.4, 5.1, 1.4,
1.6, 4.6, 4.7, 4.5, 5.1, 1.4, 4.4, 1.2, 6.9, 5. , 6.6, 3.7, 5.3,
4.2, 5.6, 1.3, 1.3, 4.6, 5. ], dtype=float32)>), ('petal_width', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([0.6, 1.9, 1.6, 1.8, 1.8, 1.2, 1. , 0.4, 2.3, 1.3, 1.3, 1.9, 0.2,
0.2, 1.3, 1.6, 1.5, 2.3, 0.3, 1.4, 0.2, 2.3, 1.7, 2.1, 1. , 1.9,
1.3, 2.1, 0.2, 0.3, 1.5, 1.9], dtype=float32)>)])
লক্ষ্য করুন যে লাইক-ফিচারগুলি একসাথে গোষ্ঠীভুক্ত, বা ব্যাচ করা হয়েছে। প্রতিটি উদাহরণ সারির ক্ষেত্র সংশ্লিষ্ট বৈশিষ্ট্য অ্যারেতে যুক্ত করা হয়। এই বৈশিষ্ট্য অ্যারেতে সংরক্ষিত উদাহরণের সংখ্যা সেট করতে batch_size পরিবর্তন করুন।
আপনি ব্যাচ থেকে কয়েকটি বৈশিষ্ট্য প্লট করে কিছু ক্লাস্টার দেখতে শুরু করতে পারেন:
plt.scatter(features['petal_length'],
features['sepal_length'],
c=labels,
cmap='viridis')
plt.xlabel("Petal length")
plt.ylabel("Sepal length")
plt.show()
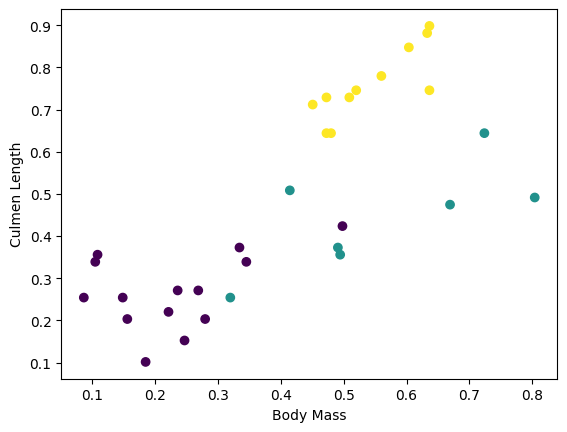
মডেল বিল্ডিং ধাপকে সহজ করার জন্য, ফিচার ডিকশনারিটিকে আকৃতি সহ একটি একক অ্যারেতে পুনরায় প্যাকেজ করার জন্য একটি ফাংশন তৈরি করুন: (batch_size, num_features) ।
এই ফাংশনটি tf.stack পদ্ধতি ব্যবহার করে যা টেনসরের একটি তালিকা থেকে মান নেয় এবং নির্দিষ্ট মাত্রায় একটি সম্মিলিত টেনসর তৈরি করে:
def pack_features_vector(features, labels):
"""Pack the features into a single array."""
features = tf.stack(list(features.values()), axis=1)
return features, labels
তারপর প্রশিক্ষণ ডেটাসেটে প্রতিটি (features,label) জোড়ার features প্যাক করতে tf.data.Dataset#map পদ্ধতিটি ব্যবহার করুন:
train_dataset = train_dataset.map(pack_features_vector)
ডেটাসেটের বৈশিষ্ট্য উপাদানগুলি এখন আকার সহ অ্যারে ( Dataset (batch_size, num_features) । আসুন প্রথম কয়েকটি উদাহরণ দেখি:
features, labels = next(iter(train_dataset))
print(features[:5])
tf.Tensor( [[4.9 3. 1.4 0.2] [6.1 3. 4.9 1.8] [6.1 2.6 5.6 1.4] [6.9 3.2 5.7 2.3] [6.7 3.1 4.4 1.4]], shape=(5, 4), dtype=float32)
মডেলের ধরন নির্বাচন করুন
মডেল কেন?
একটি মডেল বৈশিষ্ট্য এবং লেবেল মধ্যে একটি সম্পর্ক. আইরিস শ্রেণীবিভাগের সমস্যার জন্য, মডেলটি সেপাল এবং পাপড়ির পরিমাপ এবং পূর্বাভাসিত আইরিস প্রজাতির মধ্যে সম্পর্ককে সংজ্ঞায়িত করে। কিছু সাধারণ মডেলকে বীজগণিতের কয়েকটি লাইন দিয়ে বর্ণনা করা যেতে পারে, কিন্তু জটিল মেশিন লার্নিং মডেলগুলিতে প্রচুর পরিমাণে পরামিতি থাকে যা সংক্ষিপ্ত করা কঠিন।
আপনি মেশিন লার্নিং ব্যবহার না করে চারটি বৈশিষ্ট্য এবং আইরিস প্রজাতির মধ্যে সম্পর্ক নির্ধারণ করতে পারেন? যে, আপনি একটি মডেল তৈরি করতে ঐতিহ্যগত প্রোগ্রামিং কৌশল (উদাহরণস্বরূপ, অনেক শর্তসাপেক্ষ বিবৃতি) ব্যবহার করতে পারেন? সম্ভবত—যদি আপনি একটি নির্দিষ্ট প্রজাতির সাথে পাপড়ি এবং সিপাল পরিমাপের মধ্যে সম্পর্ক নির্ধারণ করার জন্য যথেষ্ট দীর্ঘ ডেটাসেট বিশ্লেষণ করেন। এবং এটি আরও জটিল ডেটাসেটে কঠিন-হয়ত অসম্ভব হয়ে ওঠে। একটি ভাল মেশিন লার্নিং পদ্ধতি আপনার জন্য মডেল নির্ধারণ করে । আপনি যদি সঠিক মেশিন লার্নিং মডেল টাইপের মধ্যে যথেষ্ট প্রতিনিধি উদাহরণ প্রদান করেন, তাহলে প্রোগ্রামটি আপনার জন্য সম্পর্ক খুঁজে বের করবে।
মডেল নির্বাচন করুন
আমাদের প্রশিক্ষণের জন্য মডেলের ধরণের নির্বাচন করতে হবে। অনেক ধরণের মডেল রয়েছে এবং একটি ভাল বাছাই করার অভিজ্ঞতা লাগে। এই টিউটোরিয়ালটি আইরিস শ্রেণীবিভাগ সমস্যা সমাধানের জন্য একটি নিউরাল নেটওয়ার্ক ব্যবহার করে। নিউরাল নেটওয়ার্ক বৈশিষ্ট্য এবং লেবেলের মধ্যে জটিল সম্পর্ক খুঁজে পেতে পারে। এটি একটি উচ্চ-গঠিত গ্রাফ, এক বা একাধিক লুকানো স্তরে সংগঠিত। প্রতিটি লুকানো স্তর এক বা একাধিক নিউরন নিয়ে গঠিত। নিউরাল নেটওয়ার্কের বেশ কয়েকটি বিভাগ রয়েছে এবং এই প্রোগ্রামটি একটি ঘন, বা সম্পূর্ণভাবে সংযুক্ত নিউরাল নেটওয়ার্ক ব্যবহার করে: একটি স্তরের নিউরনগুলি পূর্ববর্তী স্তরের প্রতিটি নিউরন থেকে ইনপুট সংযোগ গ্রহণ করে। উদাহরণস্বরূপ, চিত্র 2 একটি ইনপুট স্তর, দুটি লুকানো স্তর এবং একটি আউটপুট স্তর সমন্বিত একটি ঘন নিউরাল নেটওয়ার্ককে চিত্রিত করে:
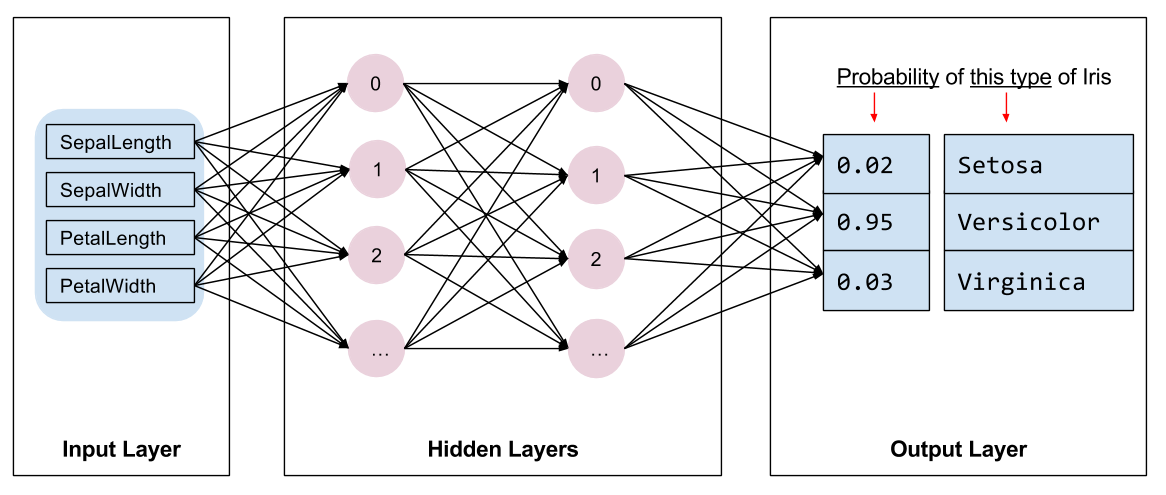 |
| চিত্র 2. বৈশিষ্ট্য, লুকানো স্তর এবং ভবিষ্যদ্বাণী সহ একটি নিউরাল নেটওয়ার্ক। |
যখন চিত্র 2 থেকে মডেলটিকে প্রশিক্ষণ দেওয়া হয় এবং একটি লেবেলবিহীন উদাহরণ খাওয়ানো হয়, তখন এটি তিনটি ভবিষ্যদ্বাণী দেয়: সম্ভাবনা যে এই ফুলটি প্রদত্ত আইরিস প্রজাতি। এই ভবিষ্যদ্বাণীকে অনুমান বলা হয়। এই উদাহরণের জন্য, আউটপুট পূর্বাভাসের যোগফল হল 1.0। চিত্র 2-এ, এই ভবিষ্যদ্বাণীটি ভেঙে যায়: Iris setosa- এর জন্য 0.02 , Iris versicolor- এর জন্য 0.95 , এবং Iris virginica- এর জন্য 0.03 ৷ এর মানে হল মডেলটি ভবিষ্যদ্বাণী করেছে—৯৫% সম্ভাবনার সঙ্গে—যে একটি লেবেলবিহীন উদাহরণ ফুল একটি আইরিস ভার্সিকলার ।
কেরাস ব্যবহার করে একটি মডেল তৈরি করুন
tf.keras API হল মডেল এবং স্তর তৈরি করার পছন্দের উপায়। এটি মডেল তৈরি করা এবং পরীক্ষা করা সহজ করে যখন কেরাস সবকিছুকে একসাথে সংযুক্ত করার জটিলতা পরিচালনা করে।
tf.keras.Sequential মডেলটি স্তরগুলির একটি রৈখিক স্ট্যাক। এর কনস্ট্রাক্টর লেয়ার ইনস্ট্যান্সের একটি তালিকা নেয়, এই ক্ষেত্রে, দুটি tf.keras.layers.Dense . প্রতিটি 10টি নোড সহ ঘন স্তর এবং 3টি নোড সহ একটি আউটপুট লেয়ার আমাদের লেবেল পূর্বাভাস উপস্থাপন করে। প্রথম স্তরের input_shape প্যারামিটারটি ডেটাসেটের বৈশিষ্ট্যগুলির সংখ্যার সাথে মিলে যায় এবং এটি প্রয়োজনীয়:
model = tf.keras.Sequential([
tf.keras.layers.Dense(10, activation=tf.nn.relu, input_shape=(4,)), # input shape required
tf.keras.layers.Dense(10, activation=tf.nn.relu),
tf.keras.layers.Dense(3)
])
অ্যাক্টিভেশন ফাংশন স্তরের প্রতিটি নোডের আউটপুট আকৃতি নির্ধারণ করে। এই অ-রৈখিকতাগুলি গুরুত্বপূর্ণ—এগুলি ছাড়া মডেলটি একটি একক স্তরের সমতুল্য হবে৷ অনেক tf.keras.activations আছে, কিন্তু লুকানো স্তরগুলির জন্য ReLU সাধারণ।
লুকানো স্তর এবং নিউরনের আদর্শ সংখ্যা সমস্যা এবং ডেটাসেটের উপর নির্ভর করে। মেশিন লার্নিংয়ের অনেক দিকগুলির মতো, নিউরাল নেটওয়ার্কের সর্বোত্তম আকৃতি বাছাই করার জন্য জ্ঞান এবং পরীক্ষা-নিরীক্ষার মিশ্রণ প্রয়োজন। একটি সাধারণ নিয়ম হিসাবে, লুকানো স্তর এবং নিউরনের সংখ্যা বৃদ্ধি সাধারণত একটি আরও শক্তিশালী মডেল তৈরি করে, যার কার্যকরভাবে প্রশিক্ষণের জন্য আরও ডেটা প্রয়োজন।
মডেল ব্যবহার করে
এই মডেলটি বৈশিষ্ট্যগুলির একটি ব্যাচের সাথে কী করে তা দ্রুত দেখে নেওয়া যাক:
predictions = model(features)
predictions[:5]
<tf.Tensor: shape=(5, 3), dtype=float32, numpy=
array([[-4.0874639e+00, 1.5199981e-03, -9.9991310e-01],
[-5.3246369e+00, -1.8366380e-01, -1.3161827e+00],
[-5.1154275e+00, -2.8129923e-01, -1.3305402e+00],
[-6.0694785e+00, -2.1251860e-01, -1.5091233e+00],
[-5.6730523e+00, -1.4321266e-01, -1.4437559e+00]], dtype=float32)>
এখানে, প্রতিটি উদাহরণ প্রতিটি ক্লাসের জন্য একটি লগিট প্রদান করে।
প্রতিটি শ্রেণীর জন্য এই লগিটগুলিকে একটি সম্ভাব্যতায় রূপান্তর করতে, সফটম্যাক্স ফাংশনটি ব্যবহার করুন:
tf.nn.softmax(predictions[:5])
<tf.Tensor: shape=(5, 3), dtype=float32, numpy=
array([[0.01210616, 0.7224865 , 0.26540732],
[0.00440638, 0.75297093, 0.24262273],
[0.00585618, 0.7362918 , 0.25785193],
[0.00224076, 0.7835035 , 0.21425581],
[0.00310779, 0.7834839 , 0.21340834]], dtype=float32)>
ক্লাস জুড়ে tf.argmax গ্রহণ করা আমাদের পূর্বাভাসিত শ্রেণী সূচক দেয়। কিন্তু, মডেলটি এখনও প্রশিক্ষিত হয়নি, তাই এগুলি ভাল ভবিষ্যদ্বাণী নয়:
print("Prediction: {}".format(tf.argmax(predictions, axis=1)))
print(" Labels: {}".format(labels))
Prediction: [1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1]
Labels: [0 2 2 2 1 1 0 1 1 2 2 1 0 2 2 2 1 0 2 2 1 0 2 1 2 0 1 1 2 2 1 2]
মডেলকে প্রশিক্ষণ দিন
ট্রেনিং হল মেশিন লার্নিং এর পর্যায় যখন মডেলটি ধীরে ধীরে অপ্টিমাইজ করা হয়, বা মডেল ডেটাসেট শিখে । লক্ষ্য হল অদেখা ডেটা সম্পর্কে ভবিষ্যদ্বাণী করার জন্য প্রশিক্ষণ ডেটাসেটের কাঠামো সম্পর্কে পর্যাপ্ত পরিমাণে শেখা। আপনি যদি প্রশিক্ষণ ডেটাসেট সম্পর্কে খুব বেশি কিছু শিখেন, তাহলে ভবিষ্যদ্বাণীগুলি কেবলমাত্র এটি দেখা ডেটার জন্য কাজ করে এবং সাধারণীকরণযোগ্য হবে না। এই সমস্যাটিকে বলা হয় ওভারফিটিং —এটি একটি সমস্যার সমাধান কীভাবে করা যায় তা বোঝার পরিবর্তে উত্তরগুলি মুখস্থ করার মতো।
আইরিস শ্রেণীবিভাগ সমস্যা হল তত্ত্বাবধানে থাকা মেশিন লার্নিংয়ের একটি উদাহরণ: মডেলটি লেবেল ধারণ করে এমন উদাহরণ থেকে প্রশিক্ষিত। তত্ত্বাবধানহীন মেশিন লার্নিং -এ, উদাহরণগুলিতে লেবেল থাকে না। পরিবর্তে, মডেলটি সাধারণত বৈশিষ্ট্যগুলির মধ্যে নিদর্শন খুঁজে পায়।
ক্ষতি এবং গ্রেডিয়েন্ট ফাংশন সংজ্ঞায়িত করুন
প্রশিক্ষণ এবং মূল্যায়ন উভয় পর্যায়েই মডেলের ক্ষতি গণনা করা প্রয়োজন। এটি পরিমাপ করে যে মডেলের ভবিষ্যদ্বাণীগুলি পছন্দসই লেবেল থেকে কতটা বন্ধ, অন্য কথায়, মডেলটি কতটা খারাপ পারফর্ম করছে৷ আমরা এই মানটিকে ন্যূনতম বা অপ্টিমাইজ করতে চাই।
আমাদের মডেলটি tf.keras.losses.SparseCategoricalCrossentropy ফাংশন ব্যবহার করে এর ক্ষতি গণনা করবে যা মডেলের শ্রেণী সম্ভাব্যতা পূর্বাভাস এবং পছন্দসই লেবেল নেয় এবং উদাহরণ জুড়ে গড় ক্ষতি ফেরত দেয়।
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
def loss(model, x, y, training):
# training=training is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
y_ = model(x, training=training)
return loss_object(y_true=y, y_pred=y_)
l = loss(model, features, labels, training=False)
print("Loss test: {}".format(l))
Loss test: 1.6059828996658325
আপনার মডেল অপ্টিমাইজ করতে ব্যবহৃত গ্রেডিয়েন্ট গণনা করতে tf.GradientTape প্রসঙ্গ ব্যবহার করুন:
def grad(model, inputs, targets):
with tf.GradientTape() as tape:
loss_value = loss(model, inputs, targets, training=True)
return loss_value, tape.gradient(loss_value, model.trainable_variables)
একটি অপ্টিমাইজার তৈরি করুন
একটি অপ্টিমাইজার loss ফাংশন কমানোর জন্য মডেলের ভেরিয়েবলে গণনা করা গ্রেডিয়েন্ট প্রয়োগ করে। আপনি ক্ষতি ফাংশনটিকে একটি বাঁকা পৃষ্ঠ হিসাবে ভাবতে পারেন (চিত্র 3 দেখুন) এবং আমরা চারপাশে হেঁটে এর সর্বনিম্ন বিন্দু খুঁজে পেতে চাই। গ্রেডিয়েন্টগুলি খাড়া চড়ার দিকে নির্দেশ করে—তাই আমরা বিপরীত পথে যাত্রা করব এবং পাহাড়ের নিচে চলে যাব। পুনরাবৃত্তিমূলকভাবে প্রতিটি ব্যাচের জন্য ক্ষতি এবং গ্রেডিয়েন্ট গণনা করে, আমরা প্রশিক্ষণের সময় মডেলটি সামঞ্জস্য করব। ধীরে ধীরে, মডেলটি ক্ষতি কমাতে ওজন এবং পক্ষপাতের সর্বোত্তম সমন্বয় খুঁজে পাবে। এবং ক্ষতি যত কম হবে, মডেলের ভবিষ্যদ্বাণী তত ভাল হবে।
 |
| চিত্র 3. অপ্টিমাইজেশান অ্যালগরিদমগুলি 3D স্পেসে সময়ের সাথে সাথে কল্পনা করা হয়েছে৷ (সূত্র: স্ট্যানফোর্ড ক্লাস CS231n , MIT লাইসেন্স, চিত্র ক্রেডিট: অ্যালেক র্যাডফোর্ড ) |
টেনসরফ্লো-তে প্রশিক্ষণের জন্য অনেক অপ্টিমাইজেশান অ্যালগরিদম উপলব্ধ রয়েছে। এই মডেলটি tf.keras.optimizers.SGD ব্যবহার করে যা স্টোকাস্টিক গ্রেডিয়েন্ট ডিসেন্ট (SGD) অ্যালগরিদম প্রয়োগ করে। learning_rate পাহাড়ের নিচে প্রতিটি পুনরাবৃত্তির জন্য ধাপের আকার নির্ধারণ করে। এটি একটি হাইপারপ্যারামিটার যা আপনি সাধারণত আরও ভাল ফলাফল অর্জনের জন্য সামঞ্জস্য করবেন।
চলুন অপ্টিমাইজার সেটআপ করা যাক:
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
আমরা একটি একক অপ্টিমাইজেশান ধাপ গণনা করতে এটি ব্যবহার করব:
loss_value, grads = grad(model, features, labels)
print("Step: {}, Initial Loss: {}".format(optimizer.iterations.numpy(),
loss_value.numpy()))
optimizer.apply_gradients(zip(grads, model.trainable_variables))
print("Step: {}, Loss: {}".format(optimizer.iterations.numpy(),
loss(model, features, labels, training=True).numpy()))
Step: 0, Initial Loss: 1.6059828996658325 Step: 1, Loss: 1.3759253025054932
প্রশিক্ষণ লুপ
জায়গায় সব টুকরা সঙ্গে, মডেল প্রশিক্ষণের জন্য প্রস্তুত! একটি প্রশিক্ষণ লুপ মডেলটিতে ডেটাসেটের উদাহরণগুলিকে ফিড করে যাতে এটি আরও ভাল ভবিষ্যদ্বাণী করতে সহায়তা করে। নিম্নলিখিত কোড ব্লক এই প্রশিক্ষণ পদক্ষেপ সেট আপ করে:
- প্রতিটি যুগের পুনরাবৃত্তি করুন। একটি যুগ হল ডেটাসেটের মধ্য দিয়ে এক পাস।
- একটি যুগের মধ্যে, প্রশিক্ষণের প্রতিটি উদাহরণের উপর পুনরাবৃত্তি করুন
Datasetবৈশিষ্ট্যগুলি (x) এবং লেবেল (y)। - উদাহরণের বৈশিষ্ট্যগুলি ব্যবহার করে, একটি ভবিষ্যদ্বাণী করুন এবং এটি লেবেলের সাথে তুলনা করুন। ভবিষ্যদ্বাণীর ভুলতা পরিমাপ করুন এবং মডেলের ক্ষতি এবং গ্রেডিয়েন্ট গণনা করতে এটি ব্যবহার করুন।
- মডেলের ভেরিয়েবল আপডেট করতে একটি
optimizerব্যবহার করুন। - ভিজ্যুয়ালাইজেশন জন্য কিছু পরিসংখ্যান ট্র্যাক রাখুন.
- প্রতিটি যুগের জন্য পুনরাবৃত্তি করুন।
num_epochs ভেরিয়েবল হল ডেটাসেট সংগ্রহের উপর লুপ করার সংখ্যা। কাউন্টার-স্বজ্ঞাতভাবে, একটি মডেলকে দীর্ঘক্ষণ প্রশিক্ষণ দেওয়া একটি ভাল মডেলের গ্যারান্টি দেয় না। num_epochs একটি হাইপারপ্যারামিটার যা আপনি টিউন করতে পারেন। সঠিক সংখ্যা নির্বাচন করার জন্য সাধারণত অভিজ্ঞতা এবং পরীক্ষা উভয়েরই প্রয়োজন হয়:
## Note: Rerunning this cell uses the same model variables
# Keep results for plotting
train_loss_results = []
train_accuracy_results = []
num_epochs = 201
for epoch in range(num_epochs):
epoch_loss_avg = tf.keras.metrics.Mean()
epoch_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()
# Training loop - using batches of 32
for x, y in train_dataset:
# Optimize the model
loss_value, grads = grad(model, x, y)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
# Track progress
epoch_loss_avg.update_state(loss_value) # Add current batch loss
# Compare predicted label to actual label
# training=True is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
epoch_accuracy.update_state(y, model(x, training=True))
# End epoch
train_loss_results.append(epoch_loss_avg.result())
train_accuracy_results.append(epoch_accuracy.result())
if epoch % 50 == 0:
print("Epoch {:03d}: Loss: {:.3f}, Accuracy: {:.3%}".format(epoch,
epoch_loss_avg.result(),
epoch_accuracy.result()))
Epoch 000: Loss: 1.766, Accuracy: 43.333% Epoch 050: Loss: 0.579, Accuracy: 71.667% Epoch 100: Loss: 0.398, Accuracy: 82.500% Epoch 150: Loss: 0.307, Accuracy: 92.500% Epoch 200: Loss: 0.224, Accuracy: 95.833%
সময়ের সাথে ক্ষতির ফাংশনটি কল্পনা করুন
মডেলের প্রশিক্ষণের অগ্রগতি মুদ্রণ করা সহায়ক হলেও, এই অগ্রগতি দেখতে প্রায়ই আরও সহায়ক। TensorBoard হল একটি চমৎকার ভিজ্যুয়ালাইজেশন টুল যা টেনসরফ্লো দিয়ে প্যাকেজ করা হয়, কিন্তু আমরা matplotlib মডিউল ব্যবহার করে মৌলিক চার্ট তৈরি করতে পারি।
এই চার্টগুলিকে ব্যাখ্যা করার জন্য কিছু অভিজ্ঞতা লাগে, কিন্তু আপনি সত্যিই দেখতে চান যে ক্ষতি কমে যায় এবং নির্ভুলতা বেড়ে যায়:
fig, axes = plt.subplots(2, sharex=True, figsize=(12, 8))
fig.suptitle('Training Metrics')
axes[0].set_ylabel("Loss", fontsize=14)
axes[0].plot(train_loss_results)
axes[1].set_ylabel("Accuracy", fontsize=14)
axes[1].set_xlabel("Epoch", fontsize=14)
axes[1].plot(train_accuracy_results)
plt.show()
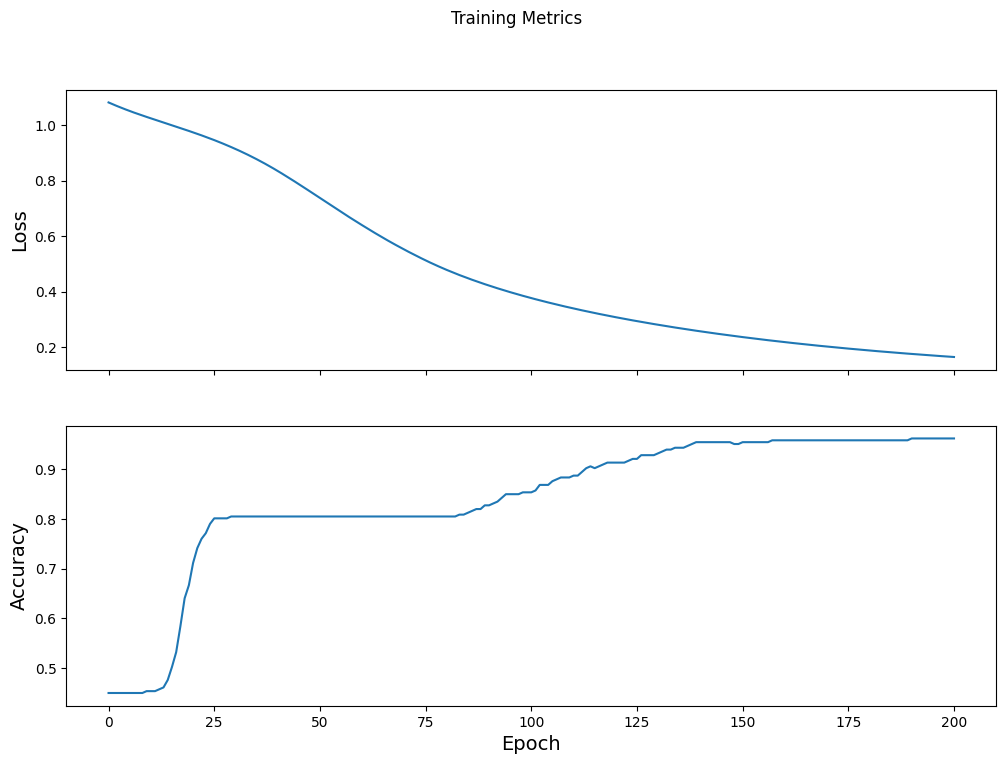
মডেলের কার্যকারিতা মূল্যায়ন করুন
এখন যেহেতু মডেলটি প্রশিক্ষিত, আমরা এর কার্যকারিতার কিছু পরিসংখ্যান পেতে পারি।
মূল্যায়ন মানে মডেলটি কতটা কার্যকরভাবে ভবিষ্যদ্বাণী করে তা নির্ধারণ করা। আইরিস শ্রেণীবিভাগে মডেলের কার্যকারিতা নির্ধারণ করতে, মডেলের কাছে কিছু সেপাল এবং পাপড়ি পরিমাপ পাস করুন এবং মডেলকে ভবিষ্যদ্বাণী করতে বলুন যে তারা কোন আইরিস প্রজাতির প্রতিনিধিত্ব করে। তারপর প্রকৃত লেবেলের বিপরীতে মডেলের ভবিষ্যদ্বাণীর তুলনা করুন। উদাহরণস্বরূপ, অর্ধেক ইনপুট উদাহরণে সঠিক প্রজাতি বাছাই করা একটি মডেলের যথার্থতা 0.5 । চিত্র 4 একটি সামান্য বেশি কার্যকরী মডেল দেখায়, 80% নির্ভুলতায় 5টির মধ্যে 4টি ভবিষ্যদ্বাণী সঠিক হয়েছে:
| উদাহরণ বৈশিষ্ট্য | লেবেল | মডেল ভবিষ্যদ্বাণী | |||
|---|---|---|---|---|---|
| ৫.৯ | 3.0 | 4.3 | 1.5 | 1 | 1 |
| ৬.৯ | 3.1 | 5.4 | 2.1 | 2 | 2 |
| 5.1 | 3.3 | 1.7 | 0.5 | 0 | 0 |
| 6.0 | 3.4 | 4.5 | 1.6 | 1 | 2 |
| 5.5 | 2.5 | 4.0 | 1.3 | 1 | 1 |
| চিত্র 4. একটি আইরিস ক্লাসিফায়ার যা 80% সঠিক। | |||||
পরীক্ষার ডেটাসেট সেটআপ করুন
মডেলের মূল্যায়ন মডেল প্রশিক্ষণের অনুরূপ। সবচেয়ে বড় পার্থক্য হল উদাহরণগুলি প্রশিক্ষণ সেটের পরিবর্তে একটি পৃথক পরীক্ষার সেট থেকে আসে। একটি মডেলের কার্যকারিতা মোটামুটিভাবে মূল্যায়ন করার জন্য, একটি মডেলের মূল্যায়ন করার জন্য ব্যবহৃত উদাহরণগুলি মডেলটিকে প্রশিক্ষণের জন্য ব্যবহৃত উদাহরণ থেকে আলাদা হতে হবে।
পরীক্ষার Dataset সেটআপটি প্রশিক্ষণ Dataset সেটআপের অনুরূপ। CSV পাঠ্য ফাইলটি ডাউনলোড করুন এবং সেই মানগুলিকে পার্স করুন, তারপরে এটিকে একটু এলোমেলো করুন:
test_url = "https://storage.googleapis.com/download.tensorflow.org/data/iris_test.csv"
test_fp = tf.keras.utils.get_file(fname=os.path.basename(test_url),
origin=test_url)
test_dataset = tf.data.experimental.make_csv_dataset(
test_fp,
batch_size,
column_names=column_names,
label_name='species',
num_epochs=1,
shuffle=False)
test_dataset = test_dataset.map(pack_features_vector)
পরীক্ষার ডেটাসেটে মডেলটি মূল্যায়ন করুন
প্রশিক্ষণের পর্যায় থেকে ভিন্ন, মডেলটি শুধুমাত্র পরীক্ষার ডেটার একটি একক যুগের মূল্যায়ন করে। নিম্নলিখিত কোড কক্ষে, আমরা পরীক্ষার সেটের প্রতিটি উদাহরণের উপর পুনরাবৃত্তি করি এবং প্রকৃত লেবেলের সাথে মডেলের পূর্বাভাস তুলনা করি। এটি সম্পূর্ণ পরীক্ষা সেট জুড়ে মডেলের নির্ভুলতা পরিমাপ করতে ব্যবহৃত হয়:
test_accuracy = tf.keras.metrics.Accuracy()
for (x, y) in test_dataset:
# training=False is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
logits = model(x, training=False)
prediction = tf.argmax(logits, axis=1, output_type=tf.int32)
test_accuracy(prediction, y)
print("Test set accuracy: {:.3%}".format(test_accuracy.result()))
Test set accuracy: 96.667%
আমরা শেষ ব্যাচে দেখতে পারি, উদাহরণস্বরূপ, মডেলটি সাধারণত সঠিক:
tf.stack([y,prediction],axis=1)
<tf.Tensor: shape=(30, 2), dtype=int32, numpy=
array([[1, 1],
[2, 2],
[0, 0],
[1, 1],
[1, 1],
[1, 1],
[0, 0],
[2, 2],
[1, 1],
[2, 2],
[2, 2],
[0, 0],
[2, 2],
[1, 1],
[1, 1],
[0, 0],
[1, 1],
[0, 0],
[0, 0],
[2, 2],
[0, 0],
[1, 1],
[2, 2],
[1, 2],
[1, 1],
[1, 1],
[0, 0],
[1, 1],
[2, 2],
[1, 1]], dtype=int32)>
ভবিষ্যদ্বাণী করতে প্রশিক্ষিত মডেল ব্যবহার করুন
আমরা একটি মডেলকে প্রশিক্ষিত করেছি এবং "প্রমাণিত" করেছি যে আইরিস প্রজাতির শ্রেণীবিভাগ করার ক্ষেত্রে এটি ভাল-কিন্তু নিখুঁত নয়। এখন লেবেলবিহীন উদাহরণে কিছু ভবিষ্যদ্বাণী করতে প্রশিক্ষিত মডেল ব্যবহার করা যাক; অর্থাৎ, বৈশিষ্ট্য ধারণ করে এমন উদাহরণে কিন্তু লেবেল নয়।
বাস্তব জীবনে, লেবেলবিহীন উদাহরণগুলি অ্যাপ, CSV ফাইল এবং ডেটা ফিড সহ অনেকগুলি বিভিন্ন উত্স থেকে আসতে পারে৷ আপাতত, আমরা তাদের লেবেলগুলির পূর্বাভাস দিতে ম্যানুয়ালি তিনটি লেবেলবিহীন উদাহরণ প্রদান করতে যাচ্ছি। স্মরণ করুন, লেবেল নম্বরগুলি একটি নামযুক্ত উপস্থাপনায় ম্যাপ করা হয়েছে:
-
0: আইরিস সেটোসা -
1: আইরিস ভার্সিকলার -
2: আইরিস ভার্জিনিকা
predict_dataset = tf.convert_to_tensor([
[5.1, 3.3, 1.7, 0.5,],
[5.9, 3.0, 4.2, 1.5,],
[6.9, 3.1, 5.4, 2.1]
])
# training=False is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
predictions = model(predict_dataset, training=False)
for i, logits in enumerate(predictions):
class_idx = tf.argmax(logits).numpy()
p = tf.nn.softmax(logits)[class_idx]
name = class_names[class_idx]
print("Example {} prediction: {} ({:4.1f}%)".format(i, name, 100*p))
Example 0 prediction: Iris setosa (97.6%) Example 1 prediction: Iris versicolor (82.0%) Example 2 prediction: Iris virginica (56.4%)