
| | |  عرض المصدر على جيثب عرض المصدر على جيثب | |
يستخدم هذا الدليل التعلم الآلي لتصنيف زهور السوسن حسب الأنواع. تستخدم TensorFlow من أجل:
- بناء نموذج،
- تدريب هذا النموذج على بيانات المثال ، و
- استخدم النموذج لعمل تنبؤات حول البيانات غير المعروفة.
برمجة TensorFlow
يستخدم هذا الدليل مفاهيم TensorFlow عالية المستوى:
- استخدم بيئة تطوير التنفيذ الحثيث الافتراضية الخاصة بـ TensorFlow ،
- استيراد البيانات باستخدام Datasets API ،
- بناء النماذج والطبقات باستخدام TensorFlow's Keras API .
تم تنظيم هذا البرنامج التعليمي مثل العديد من برامج TensorFlow:
- استيراد مجموعة البيانات وتحليلها.
- حدد نوع النموذج.
- تدريب النموذج.
- تقييم فعالية النموذج.
- استخدم النموذج المدرب لعمل تنبؤات.
برنامج الإعداد
تكوين الواردات
قم باستيراد TensorFlow ووحدات Python النمطية الأخرى المطلوبة. بشكل افتراضي ، يستخدم TensorFlow التنفيذ الجاد لتقييم العمليات على الفور ، وإرجاع القيم الملموسة بدلاً من إنشاء رسم بياني حسابي يتم تنفيذه لاحقًا. إذا كنت معتادًا على REPL أو وحدة تحكم python التفاعلية ، فهذا يبدو مألوفًا.
import os
import matplotlib.pyplot as plt
import tensorflow as tf
print("TensorFlow version: {}".format(tf.__version__))
print("Eager execution: {}".format(tf.executing_eagerly()))
TensorFlow version: 2.8.0-rc1 Eager execution: True
مشكلة تصنيف قزحية العين
تخيل أنك عالم نبات تبحث عن طريقة آلية لتصنيف كل زهرة قزحية تجدها. يوفر التعلم الآلي العديد من الخوارزميات لتصنيف الزهور إحصائيًا. على سبيل المثال ، يمكن لبرنامج التعلم الآلي المعقد تصنيف الزهور بناءً على الصور الفوتوغرافية. طموحاتنا أكثر تواضعًا - سنقوم بتصنيف زهور السوسن بناءً على قياسات الطول والعرض لكوابلها وبتلاتها .
يستلزم جنس القزحية حوالي 300 نوع ، لكن برنامجنا سيصنف الأنواع الثلاثة التالية فقط:
- ايريس سيتوسا
- ايريس فيرجينيكا
- قزحية مبرقشة
 |
| الشكل 1. إيريس سيتوسا (بواسطة Radomil ، CC BY-SA 3.0)، Iris versicolor ، (بواسطة Dlanglois ، CC BY-SA 3.0) و Iris virginica (بواسطة Frank Mayfield ، CC BY-SA 2.0). |
لحسن الحظ ، قام شخص ما بالفعل بإنشاء مجموعة بيانات من 120 زهرة من زهور السوسن بقياسات السبل والبتلة. هذه مجموعة بيانات كلاسيكية تشتهر بمشكلات تصنيف التعلم الآلي للمبتدئين.
استيراد وتحليل مجموعة بيانات التدريب
قم بتنزيل ملف مجموعة البيانات وقم بتحويله إلى هيكل يمكن استخدامه بواسطة برنامج Python هذا.
قم بتنزيل مجموعة البيانات
قم بتنزيل ملف مجموعة بيانات التدريب باستخدام وظيفة tf.keras.utils.get_file . يؤدي ذلك إلى إرجاع مسار الملف للملف الذي تم تنزيله:
train_dataset_url = "https://storage.googleapis.com/download.tensorflow.org/data/iris_training.csv"
train_dataset_fp = tf.keras.utils.get_file(fname=os.path.basename(train_dataset_url),
origin=train_dataset_url)
print("Local copy of the dataset file: {}".format(train_dataset_fp))
Local copy of the dataset file: /home/kbuilder/.keras/datasets/iris_training.csv
افحص البيانات
مجموعة البيانات هذه ، iris_training.csv ، عبارة عن ملف نصي عادي يخزن البيانات المجدولة المنسقة كقيم مفصولة بفواصل (CSV). استخدم الأمر head -n5 نظرة خاطفة على الإدخالات الخمسة الأولى:
head -n5 {train_dataset_fp}
120,4,setosa,versicolor,virginica 6.4,2.8,5.6,2.2,2 5.0,2.3,3.3,1.0,1 4.9,2.5,4.5,1.7,2 4.9,3.1,1.5,0.1,0
من عرض مجموعة البيانات هذا ، لاحظ ما يلي:
- السطر الأول عبارة عن رأس يحتوي على معلومات حول مجموعة البيانات:
- هناك 120 أمثلة إجمالية. يحتوي كل مثال على أربع ميزات وواحد من ثلاثة أسماء تصنيف محتملة.
- الصفوف اللاحقة هي سجلات البيانات ، مثال واحد لكل سطر ، حيث:
دعنا نكتب ذلك في الكود:
# column order in CSV file
column_names = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species']
feature_names = column_names[:-1]
label_name = column_names[-1]
print("Features: {}".format(feature_names))
print("Label: {}".format(label_name))
Features: ['sepal_length', 'sepal_width', 'petal_length', 'petal_width'] Label: species
يرتبط كل تصنيف باسم السلسلة (على سبيل المثال ، "setosa") ، لكن التعلم الآلي يعتمد عادةً على القيم الرقمية. يتم تعيين أرقام التسمية لتمثيل مسمى ، مثل:
-
0: إيريس سيتوسا -
1: قزحية مبرقشة -
2: إيريس فيرجينيكا
لمزيد من المعلومات حول الميزات والتسميات ، راجع قسم مصطلحات ML من دورة Crash للتعلم الآلي .
class_names = ['Iris setosa', 'Iris versicolor', 'Iris virginica']
قم بإنشاء tf.data.Dataset
تتعامل Dataset API الخاصة بـ TensorFlow مع العديد من الحالات الشائعة لتحميل البيانات في نموذج. هذه واجهة برمجة تطبيقات عالية المستوى لقراءة البيانات وتحويلها إلى نموذج يستخدم للتدريب.
نظرًا لأن مجموعة البيانات عبارة عن ملف نصي بتنسيق CSV ، استخدم الدالة tf.data.experimental.make_csv_dataset لتحليل البيانات إلى تنسيق مناسب. نظرًا لأن هذه الوظيفة تنشئ بيانات لنماذج التدريب ، فإن السلوك الافتراضي هو خلط البيانات ( shuffle=True, shuffle_buffer_size=10000 ) ، وتكرار مجموعة البيانات إلى الأبد ( num_epochs=None ). قمنا أيضًا بتعيين معلمة batch_size :
batch_size = 32
train_dataset = tf.data.experimental.make_csv_dataset(
train_dataset_fp,
batch_size,
column_names=column_names,
label_name=label_name,
num_epochs=1)
ترجع الدالة make_csv_dataset tf.data.Dataset من أزواج (features, label) ، حيث تكون features قاموسًا: {'feature_name': value}
كائنات Dataset هذه قابلة للتكرار. لنلقِ نظرة على مجموعة من الميزات:
features, labels = next(iter(train_dataset))
print(features)
OrderedDict([('sepal_length', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([5. , 7.4, 6. , 7.2, 5.9, 5.8, 5. , 5. , 7.7, 5.7, 6.3, 5.8, 5. ,
4.8, 6.6, 6.3, 5.4, 6.9, 4.8, 6.6, 5.8, 7.7, 6.7, 7.6, 5.5, 6.4,
5.6, 6.4, 4.4, 4.5, 6.5, 6.3], dtype=float32)>), ('sepal_width', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([3.5, 2.8, 2.7, 3.2, 3. , 2.6, 2. , 3.4, 3. , 2.8, 2.3, 2.7, 3.6,
3.1, 2.9, 3.3, 3. , 3.1, 3. , 3. , 4. , 2.6, 3. , 3. , 2.4, 2.7,
2.7, 2.8, 3. , 2.3, 2.8, 2.5], dtype=float32)>), ('petal_length', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([1.6, 6.1, 5.1, 6. , 5.1, 4. , 3.5, 1.6, 6.1, 4.5, 4.4, 5.1, 1.4,
1.6, 4.6, 4.7, 4.5, 5.1, 1.4, 4.4, 1.2, 6.9, 5. , 6.6, 3.7, 5.3,
4.2, 5.6, 1.3, 1.3, 4.6, 5. ], dtype=float32)>), ('petal_width', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([0.6, 1.9, 1.6, 1.8, 1.8, 1.2, 1. , 0.4, 2.3, 1.3, 1.3, 1.9, 0.2,
0.2, 1.3, 1.6, 1.5, 2.3, 0.3, 1.4, 0.2, 2.3, 1.7, 2.1, 1. , 1.9,
1.3, 2.1, 0.2, 0.3, 1.5, 1.9], dtype=float32)>)])
لاحظ أن الميزات المتشابهة مجمعة معًا أو مجمعة . يتم إلحاق كل مثال من حقول الصف بمصفوفة المعالم المقابلة. قم بتغيير حجم batch_size لتعيين عدد الأمثلة المخزنة في مصفوفات الميزات هذه.
يمكنك البدء في رؤية بعض المجموعات من خلال رسم بعض الميزات من المجموعة:
plt.scatter(features['petal_length'],
features['sepal_length'],
c=labels,
cmap='viridis')
plt.xlabel("Petal length")
plt.ylabel("Sepal length")
plt.show()
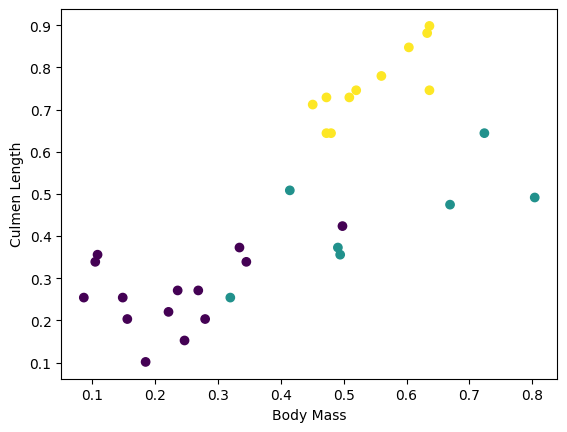
لتبسيط خطوة بناء النموذج ، قم بإنشاء دالة لإعادة تجميع قاموس الميزات في مصفوفة واحدة بالشكل: (batch_size, num_features) .
تستخدم هذه الوظيفة طريقة tf.stack التي تأخذ القيم من قائمة الموترات وتنشئ موترًا مدمجًا في البعد المحدد:
def pack_features_vector(features, labels):
"""Pack the features into a single array."""
features = tf.stack(list(features.values()), axis=1)
return features, labels
ثم استخدم طريقة tf.data.Dataset#map لحزم features كل زوج (features,label) في مجموعة بيانات التدريب:
train_dataset = train_dataset.map(pack_features_vector)
أصبح عنصر الميزات في Dataset الآن صفائف ذات شكل (batch_size, num_features) . لنلقِ نظرة على الأمثلة القليلة الأولى:
features, labels = next(iter(train_dataset))
print(features[:5])
tf.Tensor( [[4.9 3. 1.4 0.2] [6.1 3. 4.9 1.8] [6.1 2.6 5.6 1.4] [6.9 3.2 5.7 2.3] [6.7 3.1 4.4 1.4]], shape=(5, 4), dtype=float32)
حدد نوع النموذج
لماذا النموذج؟
النموذج هو علاقة بين الميزات والتسمية. بالنسبة لمشكلة تصنيف القزحية ، يحدد النموذج العلاقة بين قياسات السبل والبتلة وأنواع القزحية المتوقعة. يمكن وصف بعض النماذج البسيطة ببضعة أسطر من الجبر ، لكن نماذج التعلم الآلي المعقدة بها عدد كبير من المعلمات التي يصعب تلخيصها.
هل يمكنك تحديد العلاقة بين الميزات الأربع وأنواع القزحية دون استخدام التعلم الآلي؟ بمعنى ، هل يمكنك استخدام تقنيات البرمجة التقليدية (على سبيل المثال ، الكثير من العبارات الشرطية) لإنشاء نموذج؟ ربما - إذا قمت بتحليل مجموعة البيانات لفترة كافية لتحديد العلاقات بين قياسات البتلة والسبالة لأنواع معينة. ويصبح هذا صعبًا - وربما مستحيلًا - على مجموعات البيانات الأكثر تعقيدًا. يحدد نهج التعلم الآلي الجيد النموذج المناسب لك . إذا قمت بإدخال أمثلة تمثيلية كافية في نوع نموذج التعلم الآلي الصحيح ، فسيقوم البرنامج بتحديد العلاقات لك.
حدد النموذج
نحن بحاجة إلى اختيار نوع النموذج الذي يجب تدريبه. هناك أنواع عديدة من النماذج واختيار نموذج جيد يتطلب خبرة. يستخدم هذا البرنامج التعليمي شبكة عصبية لحل مشكلة تصنيف قزحية العين. يمكن أن تجد الشبكات العصبية علاقات معقدة بين الميزات والتسمية. إنه رسم بياني عالي التنظيم ، منظم في طبقة مخفية واحدة أو أكثر. تتكون كل طبقة مخفية من خلية عصبية واحدة أو أكثر. هناك عدة فئات من الشبكات العصبية ويستخدم هذا البرنامج شبكة عصبية كثيفة أو متصلة بالكامل : تستقبل الخلايا العصبية في طبقة واحدة اتصالات الإدخال من كل خلية عصبية في الطبقة السابقة. على سبيل المثال ، يوضح الشكل 2 شبكة عصبية كثيفة تتكون من طبقة إدخال وطبقتين مخفيتين وطبقة إخراج:
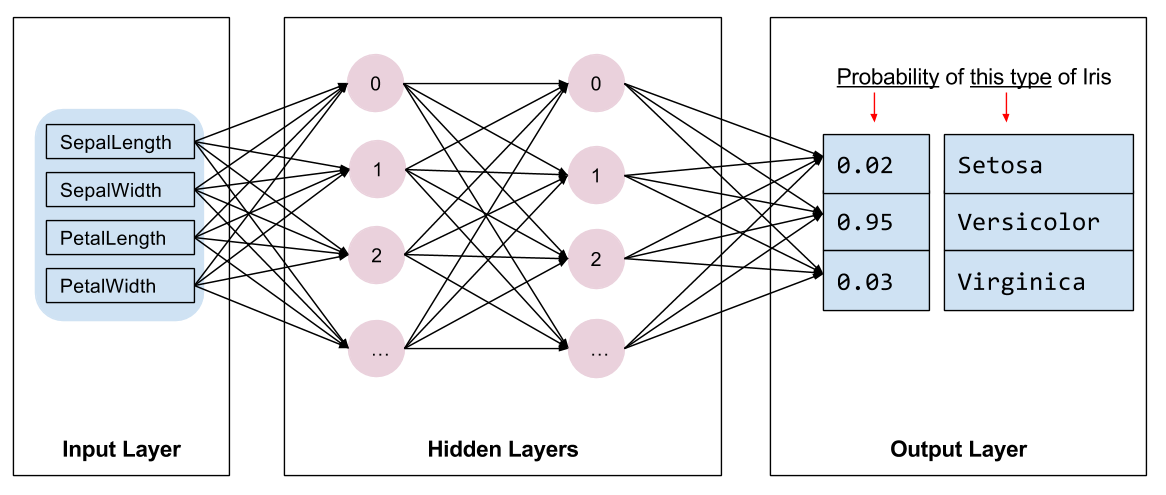 |
| الشكل 2. شبكة عصبية ذات سمات وطبقات مخفية وتنبؤات. |
عندما يتم تدريب النموذج من الشكل 2 وتغذيته بمثال غير مسمى ، فإنه ينتج عنه ثلاثة تنبؤات: احتمال أن تكون هذه الزهرة هي نوع القزحية المحدد. يسمى هذا التنبؤ بالاستدلال . في هذا المثال ، مجموع توقعات المخرجات هو 1.0. في الشكل 2 ، ينقسم هذا التنبؤ على النحو التالي: 0.02 لـ Iris setosa و 0.95 لـ Iris versicolor و 0.03 لـ Iris virginica . هذا يعني أن النموذج يتوقع - باحتمالية 95٪ - أن زهرة المثال غير المصنفة هي زهرة قزحية متعددة الألوان .
قم بإنشاء نموذج باستخدام Keras
TensorFlow tf.keras API هي الطريقة المفضلة لإنشاء النماذج والطبقات. هذا يجعل من السهل بناء النماذج والتجربة بينما يتعامل Keras مع تعقيد ربط كل شيء معًا.
نموذج tf.keras.Sequential عبارة عن كومة من الطبقات الخطية. يأخذ مُنشئه قائمة من مثيلات الطبقة ، في هذه الحالة ، طبقتان من طبقات tf.keras.layers.Dense ، طبقات كثيفة تحتوي كل منها على 10 عقد ، وطبقة إخراج بها 3 عقد تمثل تنبؤات التسمية الخاصة بنا. تتوافق معلمة input_shape للطبقة الأولى مع عدد الميزات من مجموعة البيانات ، وهي مطلوبة:
model = tf.keras.Sequential([
tf.keras.layers.Dense(10, activation=tf.nn.relu, input_shape=(4,)), # input shape required
tf.keras.layers.Dense(10, activation=tf.nn.relu),
tf.keras.layers.Dense(3)
])
تحدد وظيفة التنشيط شكل الإخراج لكل عقدة في الطبقة. هذه اللاخطية مهمة - بدونها يكون النموذج معادلاً لطبقة واحدة. هناك العديد من tf.keras.activations ، لكن ReLU شائع للطبقات المخفية.
يعتمد العدد المثالي للطبقات والخلايا العصبية المخفية على المشكلة ومجموعة البيانات. مثل العديد من جوانب التعلم الآلي ، يتطلب اختيار أفضل شكل للشبكة العصبية مزيجًا من المعرفة والتجريب. كقاعدة عامة ، تؤدي زيادة عدد الطبقات والخلايا العصبية المخفية إلى إنشاء نموذج أكثر قوة ، الأمر الذي يتطلب المزيد من البيانات للتدريب بشكل فعال.
باستخدام النموذج
دعنا نلقي نظرة سريعة على ما يفعله هذا النموذج لمجموعة من الميزات:
predictions = model(features)
predictions[:5]
<tf.Tensor: shape=(5, 3), dtype=float32, numpy=
array([[-4.0874639e+00, 1.5199981e-03, -9.9991310e-01],
[-5.3246369e+00, -1.8366380e-01, -1.3161827e+00],
[-5.1154275e+00, -2.8129923e-01, -1.3305402e+00],
[-6.0694785e+00, -2.1251860e-01, -1.5091233e+00],
[-5.6730523e+00, -1.4321266e-01, -1.4437559e+00]], dtype=float32)>
هنا ، يقوم كل مثال بإرجاع سجل دخول لكل فئة.
لتحويل هذه السجلات إلى احتمالية لكل فئة ، استخدم وظيفة softmax :
tf.nn.softmax(predictions[:5])
<tf.Tensor: shape=(5, 3), dtype=float32, numpy=
array([[0.01210616, 0.7224865 , 0.26540732],
[0.00440638, 0.75297093, 0.24262273],
[0.00585618, 0.7362918 , 0.25785193],
[0.00224076, 0.7835035 , 0.21425581],
[0.00310779, 0.7834839 , 0.21340834]], dtype=float32)>
أخذ tf.argmax عبر الفئات يعطينا فهرس الفئة المتوقع. لكن النموذج لم يتم تدريبه بعد ، لذا فهذه ليست تنبؤات جيدة:
print("Prediction: {}".format(tf.argmax(predictions, axis=1)))
print(" Labels: {}".format(labels))
Prediction: [1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1]
Labels: [0 2 2 2 1 1 0 1 1 2 2 1 0 2 2 2 1 0 2 2 1 0 2 1 2 0 1 1 2 2 1 2]
تدريب النموذج
التدريب هو مرحلة التعلم الآلي عندما يتم تحسين النموذج تدريجيًا ، أو عندما يتعلم النموذج مجموعة البيانات. الهدف هو معرفة ما يكفي عن بنية مجموعة بيانات التدريب لعمل تنبؤات حول البيانات غير المرئية. إذا تعلمت الكثير عن مجموعة بيانات التدريب ، فإن التنبؤات تعمل فقط مع البيانات التي شاهدتها ولن تكون قابلة للتعميم. هذه المشكلة تسمى overfitting - إنها مثل حفظ الإجابات بدلاً من فهم كيفية حل مشكلة ما.
مشكلة تصنيف قزحية العين هي مثال على التعلم الآلي الخاضع للإشراف : يتم تدريب النموذج من الأمثلة التي تحتوي على ملصقات. في التعلم الآلي غير الخاضع للإشراف ، لا تحتوي الأمثلة على تسميات. بدلاً من ذلك ، يجد النموذج عادةً أنماطًا بين الميزات.
تحديد وظيفة الخسارة والتدرج
تحتاج كل من مرحلتي التدريب والتقييم إلى حساب خسارة النموذج. يقيس هذا مدى اختلاف تنبؤات النموذج عن التسمية المرغوبة ، وبعبارة أخرى ، مدى سوء أداء النموذج. نريد تقليل هذه القيمة أو تحسينها.
سيحسب نموذجنا خسارته باستخدام الدالة tf.keras.losses.SparseCategoricalCrossentropy التي تأخذ توقعات احتمالية فئة النموذج والتسمية المرغوبة ، وترجع متوسط الخسارة عبر الأمثلة.
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
def loss(model, x, y, training):
# training=training is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
y_ = model(x, training=training)
return loss_object(y_true=y, y_pred=y_)
l = loss(model, features, labels, training=False)
print("Loss test: {}".format(l))
Loss test: 1.6059828996658325
استخدم سياق tf.GradientTape لحساب التدرجات اللونية المستخدمة لتحسين نموذجك:
def grad(model, inputs, targets):
with tf.GradientTape() as tape:
loss_value = loss(model, inputs, targets, training=True)
return loss_value, tape.gradient(loss_value, model.trainable_variables)
قم بإنشاء مُحسِّن
يقوم المُحسِّن بتطبيق التدرجات المحسوبة على متغيرات النموذج لتقليل وظيفة loss . يمكنك التفكير في وظيفة الخسارة كسطح منحني (انظر الشكل 3) ونريد أن نجد أدنى نقطة من خلال التجول. تشير التدرجات في اتجاه أقصى صعود - لذلك سننتقل في الاتجاه المعاكس ونتحرك أسفل التل. من خلال حساب الخسارة والتدرج بشكل متكرر لكل دفعة ، سنقوم بتعديل النموذج أثناء التدريب. تدريجيًا ، سيجد النموذج أفضل مزيج من الأوزان والتحيز لتقليل الخسارة. وكلما انخفضت الخسارة ، كانت تنبؤات النموذج أفضل.
 |
| الشكل 3. تصور خوارزميات التحسين بمرور الوقت في مساحة ثلاثية الأبعاد. (المصدر: Stanford class CS231n ، MIT License، Image credit: Alec Radford ) |
يحتوي TensorFlow على العديد من خوارزميات التحسين المتاحة للتدريب. يستخدم هذا النموذج tf.keras.optimizers.SGD التي تنفذ خوارزمية النسب العشوائي للتدرج (SGD). يحدد معدل learning_rate حجم الخطوة المطلوب اتخاذه لكل تكرار أسفل التل. هذا هو المعامل الفائق الذي ستقوم بضبطه عادةً لتحقيق نتائج أفضل.
لنقم بإعداد المحسن:
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
سنستخدم هذا لحساب خطوة تحسين واحدة:
loss_value, grads = grad(model, features, labels)
print("Step: {}, Initial Loss: {}".format(optimizer.iterations.numpy(),
loss_value.numpy()))
optimizer.apply_gradients(zip(grads, model.trainable_variables))
print("Step: {}, Loss: {}".format(optimizer.iterations.numpy(),
loss(model, features, labels, training=True).numpy()))
Step: 0, Initial Loss: 1.6059828996658325 Step: 1, Loss: 1.3759253025054932
حلقة التدريب
مع كل القطع في مكانها ، فإن النموذج جاهز للتدريب! تغذي حلقة التدريب أمثلة مجموعة البيانات في النموذج لمساعدته على عمل تنبؤات أفضل. تقوم مجموعة التعليمات البرمجية التالية بإعداد خطوات التدريب هذه:
- كرر كل حقبة . الحقبة هي المرور عبر مجموعة البيانات.
- خلال حقبة ما ، كرر كل مثال في مجموعة بيانات التدريب
Datasetعلى ميزاته (x) والتسمية (y). - باستخدام ميزات المثال ، قم بعمل توقع وقارنه بالتسمية. قم بقياس عدم دقة التنبؤ واستخدم ذلك لحساب خسارة النموذج وتدرجاته.
- استخدم
optimizerلتحديث متغيرات النموذج. - تتبع بعض الإحصائيات للتخيل.
- كرر لكل حقبة.
المتغير num_epochs هو عدد مرات تكرار مجموعة البيانات. على عكس الحدس ، فإن تدريب النموذج لفترة أطول لا يضمن نموذجًا أفضل. num_epochs هو معلمة تشعبية يمكنك ضبطها. عادة ما يتطلب اختيار الرقم الصحيح كلاً من الخبرة والتجريب:
## Note: Rerunning this cell uses the same model variables
# Keep results for plotting
train_loss_results = []
train_accuracy_results = []
num_epochs = 201
for epoch in range(num_epochs):
epoch_loss_avg = tf.keras.metrics.Mean()
epoch_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()
# Training loop - using batches of 32
for x, y in train_dataset:
# Optimize the model
loss_value, grads = grad(model, x, y)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
# Track progress
epoch_loss_avg.update_state(loss_value) # Add current batch loss
# Compare predicted label to actual label
# training=True is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
epoch_accuracy.update_state(y, model(x, training=True))
# End epoch
train_loss_results.append(epoch_loss_avg.result())
train_accuracy_results.append(epoch_accuracy.result())
if epoch % 50 == 0:
print("Epoch {:03d}: Loss: {:.3f}, Accuracy: {:.3%}".format(epoch,
epoch_loss_avg.result(),
epoch_accuracy.result()))
Epoch 000: Loss: 1.766, Accuracy: 43.333% Epoch 050: Loss: 0.579, Accuracy: 71.667% Epoch 100: Loss: 0.398, Accuracy: 82.500% Epoch 150: Loss: 0.307, Accuracy: 92.500% Epoch 200: Loss: 0.224, Accuracy: 95.833%
تصور وظيفة الخسارة بمرور الوقت
في حين أنه من المفيد طباعة تقدم تدريب النموذج ، إلا أنه غالبًا ما يكون من المفيد رؤية هذا التقدم. TensorBoard هي أداة تصور رائعة يتم تعبئتها مع TensorFlow ، ولكن يمكننا إنشاء مخططات أساسية باستخدام وحدة matplotlib .
يتطلب تفسير هذه المخططات بعض الخبرة ، لكنك تريد حقًا رؤية الخسارة تتناقص وترتفع الدقة :
fig, axes = plt.subplots(2, sharex=True, figsize=(12, 8))
fig.suptitle('Training Metrics')
axes[0].set_ylabel("Loss", fontsize=14)
axes[0].plot(train_loss_results)
axes[1].set_ylabel("Accuracy", fontsize=14)
axes[1].set_xlabel("Epoch", fontsize=14)
axes[1].plot(train_accuracy_results)
plt.show()
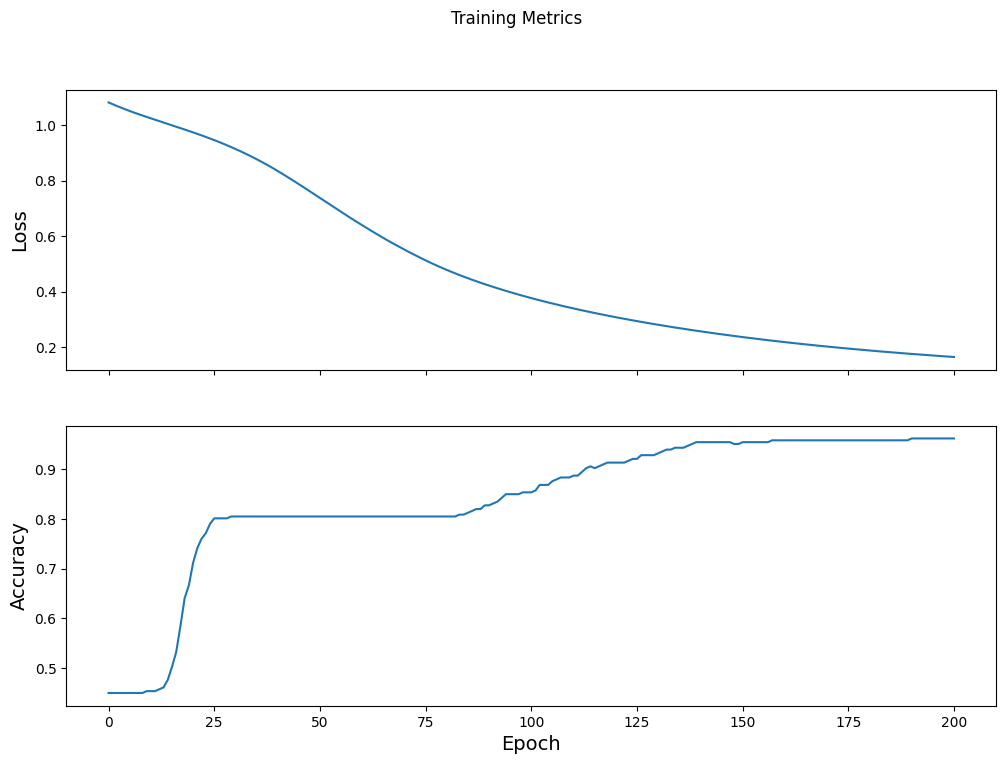
تقييم فعالية النموذج
الآن وقد تم تدريب النموذج ، يمكننا الحصول على بعض الإحصائيات حول أدائه.
يعني التقييم تحديد مدى فعالية النموذج في عمل التنبؤات. لتحديد فعالية النموذج في تصنيف قزحية العين ، مرر بعض قياسات السبل والبتلة إلى النموذج واطلب من النموذج أن يتنبأ بأنواع القزحية التي يمثلونها. ثم قارن بين تنبؤات النموذج والتسمية الفعلية. على سبيل المثال ، النموذج الذي اختار الأنواع الصحيحة بنصف أمثلة الإدخال بدقة 0.5 . يوضح الشكل 4 نموذجًا أكثر فاعلية قليلاً ، حيث تحصل على 4 من أصل 5 تنبؤات صحيحة بدقة 80٪:
| مثال على الميزات | ملصق | توقع النموذج | |||
|---|---|---|---|---|---|
| 5.9 | 3.0 | 4.3 | 1.5 | 1 | 1 |
| 6.9 | 3.1 | 5.4 | 2.1 | 2 | 2 |
| 5.1 | 3.3 | 1.7 | 0.5 | 0 | 0 |
| 6.0 | 3.4 | 4.5 | 1.6 | 1 | 2 |
| 5.5 | 2.5 | 4.0 | 1.3 | 1 | 1 |
| الشكل 4. مصنف قزحية دقيق بنسبة 80٪. | |||||
قم بإعداد مجموعة بيانات الاختبار
تقييم النموذج مشابه لتدريب النموذج. الاختلاف الأكبر هو أن الأمثلة تأتي من مجموعة اختبار منفصلة بدلاً من مجموعة التدريب. لتقييم فعالية النموذج بشكل عادل ، يجب أن تكون الأمثلة المستخدمة لتقييم النموذج مختلفة عن الأمثلة المستخدمة لتدريب النموذج.
يعد إعداد مجموعة بيانات الاختبار Dataset لإعداد Dataset التدريبية. قم بتنزيل الملف النصي CSV وحلّل هذه القيم ، ثم قم بتبديلها قليلاً:
test_url = "https://storage.googleapis.com/download.tensorflow.org/data/iris_test.csv"
test_fp = tf.keras.utils.get_file(fname=os.path.basename(test_url),
origin=test_url)
test_dataset = tf.data.experimental.make_csv_dataset(
test_fp,
batch_size,
column_names=column_names,
label_name='species',
num_epochs=1,
shuffle=False)
test_dataset = test_dataset.map(pack_features_vector)
قم بتقييم النموذج في مجموعة بيانات الاختبار
على عكس مرحلة التدريب ، يقوم النموذج فقط بتقييم فترة واحدة من بيانات الاختبار. في خلية الكود التالية ، نكرر كل مثال في مجموعة الاختبار ونقارن توقع النموذج مقابل التسمية الفعلية. يستخدم هذا لقياس دقة النموذج عبر مجموعة الاختبار بأكملها:
test_accuracy = tf.keras.metrics.Accuracy()
for (x, y) in test_dataset:
# training=False is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
logits = model(x, training=False)
prediction = tf.argmax(logits, axis=1, output_type=tf.int32)
test_accuracy(prediction, y)
print("Test set accuracy: {:.3%}".format(test_accuracy.result()))
Test set accuracy: 96.667%
يمكننا أن نرى في الدفعة الأخيرة ، على سبيل المثال ، النموذج عادة ما يكون صحيحًا:
tf.stack([y,prediction],axis=1)
<tf.Tensor: shape=(30, 2), dtype=int32, numpy=
array([[1, 1],
[2, 2],
[0, 0],
[1, 1],
[1, 1],
[1, 1],
[0, 0],
[2, 2],
[1, 1],
[2, 2],
[2, 2],
[0, 0],
[2, 2],
[1, 1],
[1, 1],
[0, 0],
[1, 1],
[0, 0],
[0, 0],
[2, 2],
[0, 0],
[1, 1],
[2, 2],
[1, 2],
[1, 1],
[1, 1],
[0, 0],
[1, 1],
[2, 2],
[1, 1]], dtype=int32)>
استخدم النموذج المدرب لعمل تنبؤات
لقد قمنا بتدريب نموذج و "أثبتنا" أنه جيد - ولكنه ليس مثاليًا - في تصنيف أنواع السوسنة. الآن دعنا نستخدم النموذج المدرب لعمل بعض التنبؤات على الأمثلة غير المسماة ؛ أي في الأمثلة التي تحتوي على ميزات وليس على تسمية.
في الحياة الواقعية ، يمكن أن تأتي الأمثلة غير المسماة من العديد من المصادر المختلفة بما في ذلك التطبيقات وملفات CSV وموجزات البيانات. في الوقت الحالي ، سنقدم يدويًا ثلاثة أمثلة غير مسماة للتنبؤ بتسمياتها. تذكر ، يتم تعيين أرقام التسمية لتمثيل مسمى على النحو التالي:
-
0: إيريس سيتوسا -
1: قزحية مبرقشة -
2: إيريس فيرجينيكا
predict_dataset = tf.convert_to_tensor([
[5.1, 3.3, 1.7, 0.5,],
[5.9, 3.0, 4.2, 1.5,],
[6.9, 3.1, 5.4, 2.1]
])
# training=False is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
predictions = model(predict_dataset, training=False)
for i, logits in enumerate(predictions):
class_idx = tf.argmax(logits).numpy()
p = tf.nn.softmax(logits)[class_idx]
name = class_names[class_idx]
print("Example {} prediction: {} ({:4.1f}%)".format(i, name, 100*p))
Example 0 prediction: Iris setosa (97.6%) Example 1 prediction: Iris versicolor (82.0%) Example 2 prediction: Iris virginica (56.4%)