
| | |  Lihat sumber di GitHub Lihat sumber di GitHub | |
Panduan ini menggunakan pembelajaran mesin untuk mengkategorikan bunga Iris berdasarkan spesies. Ini menggunakan TensorFlow untuk:
- Membangun model,
- Latih model ini pada contoh data, dan
- Gunakan model untuk membuat prediksi tentang data yang tidak diketahui.
Pemrograman TensorFlow
Panduan ini menggunakan konsep TensorFlow tingkat tinggi berikut:
- Gunakan lingkungan pengembangan eksekusi bersemangat default TensorFlow,
- Impor data dengan Datasets API ,
- Bangun model dan lapisan dengan Keras API TensorFlow .
Tutorial ini terstruktur seperti banyak program TensorFlow:
- Impor dan parsing kumpulan data.
- Pilih jenis modelnya.
- Latih modelnya.
- Evaluasi keefektifan model.
- Gunakan model terlatih untuk membuat prediksi.
Program pengaturan
Konfigurasikan impor
Impor TensorFlow dan modul Python lain yang diperlukan. Secara default, TensorFlow menggunakan eksekusi bersemangat untuk mengevaluasi operasi dengan segera, mengembalikan nilai konkret alih-alih membuat grafik komputasi yang dieksekusi nanti. Jika Anda terbiasa dengan REPL atau konsol interaktif python , ini terasa familier.
import os
import matplotlib.pyplot as plt
import tensorflow as tf
print("TensorFlow version: {}".format(tf.__version__))
print("Eager execution: {}".format(tf.executing_eagerly()))
TensorFlow version: 2.8.0-rc1 Eager execution: True
Masalah klasifikasi Iris
Bayangkan Anda adalah seorang ahli botani yang mencari cara otomatis untuk mengkategorikan setiap bunga Iris yang Anda temukan. Pembelajaran mesin menyediakan banyak algoritma untuk mengklasifikasikan bunga secara statistik. Misalnya, program pembelajaran mesin yang canggih dapat mengklasifikasikan bunga berdasarkan foto. Ambisi kami lebih sederhana—kami akan mengklasifikasikan bunga Iris berdasarkan ukuran panjang dan lebar sepal dan petalnya .
Genus Iris mencakup sekitar 300 spesies, tetapi program kami hanya akan mengklasifikasikan tiga spesies berikut:
- Iris setosa
- Iris virginica
- Iris versikolor
 |
| Gambar 1. Iris setosa (oleh Radomil , CC BY-SA 3.0), Iris versicolor , (oleh Dlanglois , CC BY-SA 3.0), dan Iris virginica (oleh Frank Mayfield , CC BY-SA 2.0). |
Untungnya, seseorang telah membuat dataset 120 bunga Iris dengan ukuran sepal dan petal. Ini adalah kumpulan data klasik yang populer untuk masalah klasifikasi pembelajaran mesin pemula.
Impor dan urai set data pelatihan
Unduh file dataset dan ubah menjadi struktur yang dapat digunakan oleh program Python ini.
Unduh kumpulan data
Unduh file dataset pelatihan menggunakan fungsi tf.keras.utils.get_file . Ini mengembalikan jalur file dari file yang diunduh:
train_dataset_url = "https://storage.googleapis.com/download.tensorflow.org/data/iris_training.csv"
train_dataset_fp = tf.keras.utils.get_file(fname=os.path.basename(train_dataset_url),
origin=train_dataset_url)
print("Local copy of the dataset file: {}".format(train_dataset_fp))
Local copy of the dataset file: /home/kbuilder/.keras/datasets/iris_training.csv
Periksa datanya
Dataset ini, iris_training.csv , adalah file teks biasa yang menyimpan data tabular yang diformat sebagai nilai yang dipisahkan koma (CSV). Gunakan perintah head -n5 untuk mengintip lima entri pertama:
head -n5 {train_dataset_fp}
120,4,setosa,versicolor,virginica 6.4,2.8,5.6,2.2,2 5.0,2.3,3.3,1.0,1 4.9,2.5,4.5,1.7,2 4.9,3.1,1.5,0.1,0
Dari tampilan kumpulan data ini, perhatikan hal berikut:
- Baris pertama adalah header yang berisi informasi tentang dataset:
- Ada 120 total contoh. Setiap contoh memiliki empat fitur dan satu dari tiga kemungkinan nama label.
- Baris berikutnya adalah catatan data, satu contoh per baris, di mana:
- Empat bidang pertama adalah fitur : ini adalah karakteristik dari sebuah contoh. Di sini, bidang menyimpan nomor float yang mewakili pengukuran bunga.
- Kolom terakhir adalah label : ini adalah nilai yang ingin kita prediksi. Untuk kumpulan data ini, ini adalah nilai bilangan bulat 0, 1, atau 2 yang sesuai dengan nama bunga.
Mari kita tuliskan itu dalam kode:
# column order in CSV file
column_names = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species']
feature_names = column_names[:-1]
label_name = column_names[-1]
print("Features: {}".format(feature_names))
print("Label: {}".format(label_name))
Features: ['sepal_length', 'sepal_width', 'petal_length', 'petal_width'] Label: species
Setiap label dikaitkan dengan nama string (misalnya, "setosa"), tetapi pembelajaran mesin biasanya bergantung pada nilai numerik. Nomor label dipetakan ke representasi bernama, seperti:
-
0: Iris setosa -
1: Iris versikolor -
2: Iris virginica
Untuk informasi selengkapnya tentang fitur dan label, lihat bagian Terminologi ML dari Kursus Singkat Machine Learning .
class_names = ['Iris setosa', 'Iris versicolor', 'Iris virginica']
Buat tf.data.Dataset
Dataset API TensorFlow menangani banyak kasus umum untuk memuat data ke dalam model. Ini adalah API tingkat tinggi untuk membaca data dan mengubahnya menjadi bentuk yang digunakan untuk pelatihan.
Karena kumpulan data adalah file teks berformat CSV, gunakan fungsi tf.data.experimental.make_csv_dataset untuk mengurai data ke dalam format yang sesuai. Karena fungsi ini menghasilkan data untuk model pelatihan, perilaku defaultnya adalah mengacak data ( shuffle=True, shuffle_buffer_size=10000 ), dan mengulang kumpulan data selamanya ( num_epochs=None ). Kami juga mengatur parameter batch_size :
batch_size = 32
train_dataset = tf.data.experimental.make_csv_dataset(
train_dataset_fp,
batch_size,
column_names=column_names,
label_name=label_name,
num_epochs=1)
Fungsi make_csv_dataset mengembalikan tf.data.Dataset dari pasangan (features, label) , di mana features adalah kamus: {'feature_name': value}
Objek Dataset ini dapat diubah. Mari kita lihat sekumpulan fitur:
features, labels = next(iter(train_dataset))
print(features)
OrderedDict([('sepal_length', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([5. , 7.4, 6. , 7.2, 5.9, 5.8, 5. , 5. , 7.7, 5.7, 6.3, 5.8, 5. ,
4.8, 6.6, 6.3, 5.4, 6.9, 4.8, 6.6, 5.8, 7.7, 6.7, 7.6, 5.5, 6.4,
5.6, 6.4, 4.4, 4.5, 6.5, 6.3], dtype=float32)>), ('sepal_width', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([3.5, 2.8, 2.7, 3.2, 3. , 2.6, 2. , 3.4, 3. , 2.8, 2.3, 2.7, 3.6,
3.1, 2.9, 3.3, 3. , 3.1, 3. , 3. , 4. , 2.6, 3. , 3. , 2.4, 2.7,
2.7, 2.8, 3. , 2.3, 2.8, 2.5], dtype=float32)>), ('petal_length', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([1.6, 6.1, 5.1, 6. , 5.1, 4. , 3.5, 1.6, 6.1, 4.5, 4.4, 5.1, 1.4,
1.6, 4.6, 4.7, 4.5, 5.1, 1.4, 4.4, 1.2, 6.9, 5. , 6.6, 3.7, 5.3,
4.2, 5.6, 1.3, 1.3, 4.6, 5. ], dtype=float32)>), ('petal_width', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([0.6, 1.9, 1.6, 1.8, 1.8, 1.2, 1. , 0.4, 2.3, 1.3, 1.3, 1.9, 0.2,
0.2, 1.3, 1.6, 1.5, 2.3, 0.3, 1.4, 0.2, 2.3, 1.7, 2.1, 1. , 1.9,
1.3, 2.1, 0.2, 0.3, 1.5, 1.9], dtype=float32)>)])
Perhatikan bahwa fitur-fitur serupa dikelompokkan bersama, atau dikelompokkan . Setiap bidang contoh baris ditambahkan ke larik fitur yang sesuai. Ubah batch_size untuk mengatur jumlah contoh yang disimpan dalam larik fitur ini.
Anda dapat mulai melihat beberapa kluster dengan memplot beberapa fitur dari kumpulan:
plt.scatter(features['petal_length'],
features['sepal_length'],
c=labels,
cmap='viridis')
plt.xlabel("Petal length")
plt.ylabel("Sepal length")
plt.show()
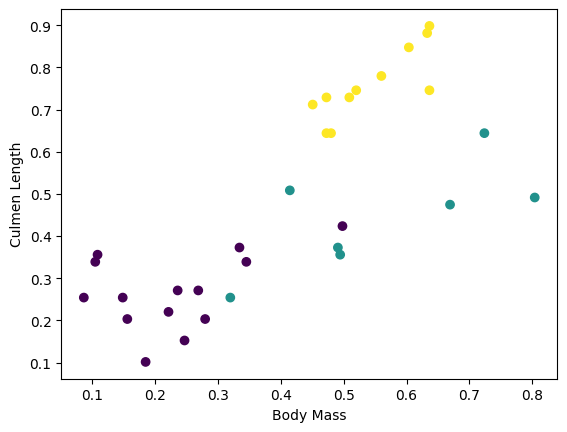
Untuk menyederhanakan langkah pembuatan model, buat fungsi untuk mengemas ulang kamus fitur menjadi satu larik dengan bentuk: (batch_size, num_features) .
Fungsi ini menggunakan metode tf.stack yang mengambil nilai dari daftar tensor dan membuat tensor gabungan pada dimensi yang ditentukan:
def pack_features_vector(features, labels):
"""Pack the features into a single array."""
features = tf.stack(list(features.values()), axis=1)
return features, labels
Kemudian gunakan metode tf.data.Dataset#map untuk mengemas features dari setiap pasangan (features,label) ke dalam set data pelatihan:
train_dataset = train_dataset.map(pack_features_vector)
Elemen fitur dari Dataset sekarang adalah array dengan bentuk (batch_size, num_features) . Mari kita lihat beberapa contoh pertama:
features, labels = next(iter(train_dataset))
print(features[:5])
tf.Tensor( [[4.9 3. 1.4 0.2] [6.1 3. 4.9 1.8] [6.1 2.6 5.6 1.4] [6.9 3.2 5.7 2.3] [6.7 3.1 4.4 1.4]], shape=(5, 4), dtype=float32)
Pilih jenis model
Mengapa model?
Model adalah hubungan antara fitur dan label. Untuk masalah klasifikasi Iris, model mendefinisikan hubungan antara ukuran sepal dan petal dan spesies Iris yang diprediksi. Beberapa model sederhana dapat dijelaskan dengan beberapa baris aljabar, tetapi model pembelajaran mesin yang kompleks memiliki sejumlah besar parameter yang sulit untuk diringkas.
Bisakah Anda menentukan hubungan antara empat fitur dan spesies Iris tanpa menggunakan pembelajaran mesin? Yaitu, dapatkah Anda menggunakan teknik pemrograman tradisional (misalnya, banyak pernyataan bersyarat) untuk membuat model? Mungkin—jika Anda menganalisis kumpulan data cukup lama untuk menentukan hubungan antara ukuran kelopak dan sepal untuk spesies tertentu. Dan ini menjadi sulit—mungkin tidak mungkin—pada kumpulan data yang lebih rumit. Pendekatan pembelajaran mesin yang baik menentukan model untuk Anda . Jika Anda memasukkan cukup banyak contoh representatif ke dalam jenis model pembelajaran mesin yang tepat, program akan mencari tahu hubungannya untuk Anda.
Pilih modelnya
Kita perlu memilih jenis model yang akan dilatih. Ada banyak jenis model dan memilih yang bagus membutuhkan pengalaman. Tutorial ini menggunakan jaringan saraf untuk menyelesaikan masalah klasifikasi Iris. Jaringan saraf dapat menemukan hubungan yang kompleks antara fitur dan label. Ini adalah grafik yang sangat terstruktur, diatur ke dalam satu atau lebih lapisan tersembunyi . Setiap lapisan tersembunyi terdiri dari satu atau lebih neuron . Ada beberapa kategori jaringan saraf dan program ini menggunakan jaringan saraf padat, atau sepenuhnya terhubung : neuron dalam satu lapisan menerima koneksi input dari setiap neuron di lapisan sebelumnya. Misalnya, Gambar 2 mengilustrasikan jaringan saraf padat yang terdiri dari lapisan input, dua lapisan tersembunyi, dan lapisan output:
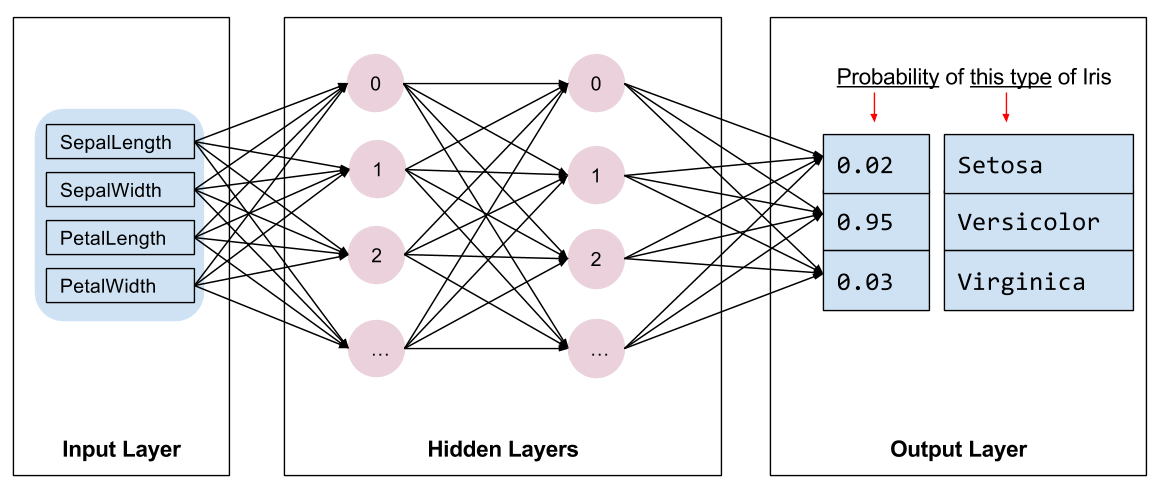 |
| Gambar 2. Jaringan saraf dengan fitur, lapisan tersembunyi, dan prediksi. |
Ketika model dari Gambar 2 dilatih dan diberi makan contoh yang tidak berlabel, itu menghasilkan tiga prediksi: kemungkinan bahwa bunga ini adalah spesies Iris yang diberikan. Prediksi ini disebut inferensi . Untuk contoh ini, jumlah prediksi keluaran adalah 1,0. Pada Gambar 2, prediksi ini dipecah menjadi: 0.02 untuk Iris setosa , 0.95 untuk Iris versicolor , dan 0.03 untuk Iris virginica . Ini berarti bahwa model memprediksi—dengan probabilitas 95%—bahwa contoh bunga yang tidak berlabel adalah Iris versicolor .
Buat model menggunakan Keras
API tf.keras adalah cara yang lebih disukai untuk membuat model dan lapisan. Ini membuatnya mudah untuk membangun model dan bereksperimen sementara Keras menangani kerumitan menghubungkan semuanya bersama-sama.
Model tf.keras.Sequential adalah tumpukan lapisan linier. Konstruktornya mengambil daftar instance lapisan, dalam hal ini, dua lapisan tf.keras.layers.Dense dengan masing-masing 10 node, dan lapisan output dengan 3 node yang mewakili prediksi label kami. Parameter input_shape lapisan pertama sesuai dengan jumlah fitur dari kumpulan data, dan diperlukan:
model = tf.keras.Sequential([
tf.keras.layers.Dense(10, activation=tf.nn.relu, input_shape=(4,)), # input shape required
tf.keras.layers.Dense(10, activation=tf.nn.relu),
tf.keras.layers.Dense(3)
])
Fungsi aktivasi menentukan bentuk output dari setiap node di lapisan. Non-linearitas ini penting—tanpanya model akan setara dengan satu lapisan. Ada banyak tf.keras.activations , tetapi ReLU umum untuk lapisan tersembunyi.
Jumlah ideal lapisan tersembunyi dan neuron tergantung pada masalah dan dataset. Seperti banyak aspek pembelajaran mesin, memilih bentuk terbaik dari jaringan saraf membutuhkan campuran pengetahuan dan eksperimen. Sebagai aturan praktis, meningkatkan jumlah lapisan tersembunyi dan neuron biasanya menciptakan model yang lebih kuat, yang membutuhkan lebih banyak data untuk dilatih secara efektif.
Menggunakan model
Mari kita lihat sekilas apa yang dilakukan model ini pada sekumpulan fitur:
predictions = model(features)
predictions[:5]
<tf.Tensor: shape=(5, 3), dtype=float32, numpy=
array([[-4.0874639e+00, 1.5199981e-03, -9.9991310e-01],
[-5.3246369e+00, -1.8366380e-01, -1.3161827e+00],
[-5.1154275e+00, -2.8129923e-01, -1.3305402e+00],
[-6.0694785e+00, -2.1251860e-01, -1.5091233e+00],
[-5.6730523e+00, -1.4321266e-01, -1.4437559e+00]], dtype=float32)>
Di sini, setiap contoh mengembalikan logit untuk setiap kelas.
Untuk mengonversi logit ini menjadi probabilitas untuk setiap kelas, gunakan fungsi softmax :
tf.nn.softmax(predictions[:5])
<tf.Tensor: shape=(5, 3), dtype=float32, numpy=
array([[0.01210616, 0.7224865 , 0.26540732],
[0.00440638, 0.75297093, 0.24262273],
[0.00585618, 0.7362918 , 0.25785193],
[0.00224076, 0.7835035 , 0.21425581],
[0.00310779, 0.7834839 , 0.21340834]], dtype=float32)>
Mengambil tf.argmax di seluruh kelas memberi kita indeks kelas yang diprediksi. Tapi, modelnya belum dilatih, jadi ini bukan prediksi yang bagus:
print("Prediction: {}".format(tf.argmax(predictions, axis=1)))
print(" Labels: {}".format(labels))
Prediction: [1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1]
Labels: [0 2 2 2 1 1 0 1 1 2 2 1 0 2 2 2 1 0 2 2 1 0 2 1 2 0 1 1 2 2 1 2]
Latih modelnya
Pelatihan adalah tahap pembelajaran mesin saat model dioptimalkan secara bertahap, atau model mempelajari kumpulan data. Tujuannya adalah untuk mempelajari cukup banyak tentang struktur dataset pelatihan untuk membuat prediksi tentang data yang tidak terlihat. Jika Anda belajar terlalu banyak tentang dataset pelatihan, maka prediksi hanya berfungsi untuk data yang telah dilihatnya dan tidak akan dapat digeneralisasikan. Masalah ini disebut overfitting —seperti mengingat jawaban alih-alih memahami cara memecahkan masalah.
Masalah klasifikasi Iris adalah contoh pembelajaran mesin yang diawasi : model dilatih dari contoh yang berisi label. Dalam pembelajaran mesin tanpa pengawasan , contoh tidak berisi label. Sebaliknya, model biasanya menemukan pola di antara fitur.
Tentukan fungsi kerugian dan gradien
Baik tahap pelatihan maupun evaluasi perlu menghitung kerugian model . Ini mengukur seberapa jauh prediksi model dari label yang diinginkan, dengan kata lain, seberapa buruk kinerja model. Kami ingin meminimalkan, atau mengoptimalkan, nilai ini.
Model kami akan menghitung kerugiannya menggunakan fungsi tf.keras.losses.SparseCategoricalCrossentropy yang mengambil prediksi probabilitas kelas model dan label yang diinginkan, dan mengembalikan kerugian rata-rata di seluruh contoh.
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
def loss(model, x, y, training):
# training=training is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
y_ = model(x, training=training)
return loss_object(y_true=y, y_pred=y_)
l = loss(model, features, labels, training=False)
print("Loss test: {}".format(l))
Loss test: 1.6059828996658325
Gunakan konteks tf.GradientTape untuk menghitung gradien yang digunakan untuk mengoptimalkan model Anda:
def grad(model, inputs, targets):
with tf.GradientTape() as tape:
loss_value = loss(model, inputs, targets, training=True)
return loss_value, tape.gradient(loss_value, model.trainable_variables)
Buat pengoptimal
Pengoptimal menerapkan gradien yang dihitung ke variabel model untuk meminimalkan fungsi loss . Anda dapat menganggap fungsi kerugian sebagai permukaan melengkung (lihat Gambar 3) dan kami ingin menemukan titik terendahnya dengan berjalan-jalan. Gradien menunjuk ke arah pendakian paling curam—jadi kita akan melakukan perjalanan ke arah yang berlawanan dan menuruni bukit. Dengan menghitung kerugian dan gradien secara iteratif untuk setiap batch, kami akan menyesuaikan model selama pelatihan. Secara bertahap, model akan menemukan kombinasi bobot dan bias terbaik untuk meminimalkan kerugian. Dan semakin rendah kerugiannya, semakin baik prediksi model.
 |
| Gambar 3. Algoritma optimasi divisualisasikan dari waktu ke waktu dalam ruang 3D. (Sumber: Stanford class CS231n , Lisensi MIT, Kredit gambar: Alec Radford ) |
TensorFlow memiliki banyak algoritme pengoptimalan yang tersedia untuk pelatihan. Model ini menggunakan tf.keras.optimizers.SGD yang mengimplementasikan algoritme penurunan gradien stokastik (SGD). learning_rate menetapkan ukuran langkah yang harus diambil untuk setiap iterasi menuruni bukit. Ini adalah hyperparameter yang biasanya Anda sesuaikan untuk mencapai hasil yang lebih baik.
Mari kita siapkan pengoptimal:
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
Kami akan menggunakan ini untuk menghitung satu langkah pengoptimalan:
loss_value, grads = grad(model, features, labels)
print("Step: {}, Initial Loss: {}".format(optimizer.iterations.numpy(),
loss_value.numpy()))
optimizer.apply_gradients(zip(grads, model.trainable_variables))
print("Step: {}, Loss: {}".format(optimizer.iterations.numpy(),
loss(model, features, labels, training=True).numpy()))
Step: 0, Initial Loss: 1.6059828996658325 Step: 1, Loss: 1.3759253025054932
Lingkaran pelatihan
Dengan semua bagian di tempatnya, model siap untuk pelatihan! Loop pelatihan memasukkan contoh kumpulan data ke dalam model untuk membantunya membuat prediksi yang lebih baik. Blok kode berikut menyiapkan langkah-langkah pelatihan ini:
- Ulangi setiap zaman . Epoch adalah satu kali melewati dataset.
- Dalam sebuah epoch, ulangi setiap contoh dalam
Datasetpelatihan dengan mengambil fitur- fiturnya (x) dan label (y). - Menggunakan fitur contoh, buat prediksi dan bandingkan dengan label. Ukur ketidakakuratan prediksi dan gunakan itu untuk menghitung kerugian dan gradien model.
- Gunakan
optimizeruntuk memperbarui variabel model. - Melacak beberapa statistik untuk visualisasi.
- Ulangi untuk setiap zaman.
Variabel num_epochs adalah berapa kali pengulangan kumpulan dataset. Secara kontra-intuitif, melatih model lebih lama tidak menjamin model yang lebih baik. num_epochs adalah hyperparameter yang dapat Anda atur. Memilih nomor yang tepat biasanya membutuhkan pengalaman dan eksperimen:
## Note: Rerunning this cell uses the same model variables
# Keep results for plotting
train_loss_results = []
train_accuracy_results = []
num_epochs = 201
for epoch in range(num_epochs):
epoch_loss_avg = tf.keras.metrics.Mean()
epoch_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()
# Training loop - using batches of 32
for x, y in train_dataset:
# Optimize the model
loss_value, grads = grad(model, x, y)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
# Track progress
epoch_loss_avg.update_state(loss_value) # Add current batch loss
# Compare predicted label to actual label
# training=True is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
epoch_accuracy.update_state(y, model(x, training=True))
# End epoch
train_loss_results.append(epoch_loss_avg.result())
train_accuracy_results.append(epoch_accuracy.result())
if epoch % 50 == 0:
print("Epoch {:03d}: Loss: {:.3f}, Accuracy: {:.3%}".format(epoch,
epoch_loss_avg.result(),
epoch_accuracy.result()))
Epoch 000: Loss: 1.766, Accuracy: 43.333% Epoch 050: Loss: 0.579, Accuracy: 71.667% Epoch 100: Loss: 0.398, Accuracy: 82.500% Epoch 150: Loss: 0.307, Accuracy: 92.500% Epoch 200: Loss: 0.224, Accuracy: 95.833%
Visualisasikan fungsi kerugian dari waktu ke waktu
Meskipun membantu untuk mencetak kemajuan pelatihan model, sering kali lebih membantu untuk melihat kemajuan ini. TensorBoard adalah alat visualisasi bagus yang dikemas dengan TensorFlow, tetapi kita dapat membuat bagan dasar menggunakan modul matplotlib .
Menafsirkan grafik ini membutuhkan beberapa pengalaman, tetapi Anda benar-benar ingin melihat kerugian turun dan akurasi naik:
fig, axes = plt.subplots(2, sharex=True, figsize=(12, 8))
fig.suptitle('Training Metrics')
axes[0].set_ylabel("Loss", fontsize=14)
axes[0].plot(train_loss_results)
axes[1].set_ylabel("Accuracy", fontsize=14)
axes[1].set_xlabel("Epoch", fontsize=14)
axes[1].plot(train_accuracy_results)
plt.show()
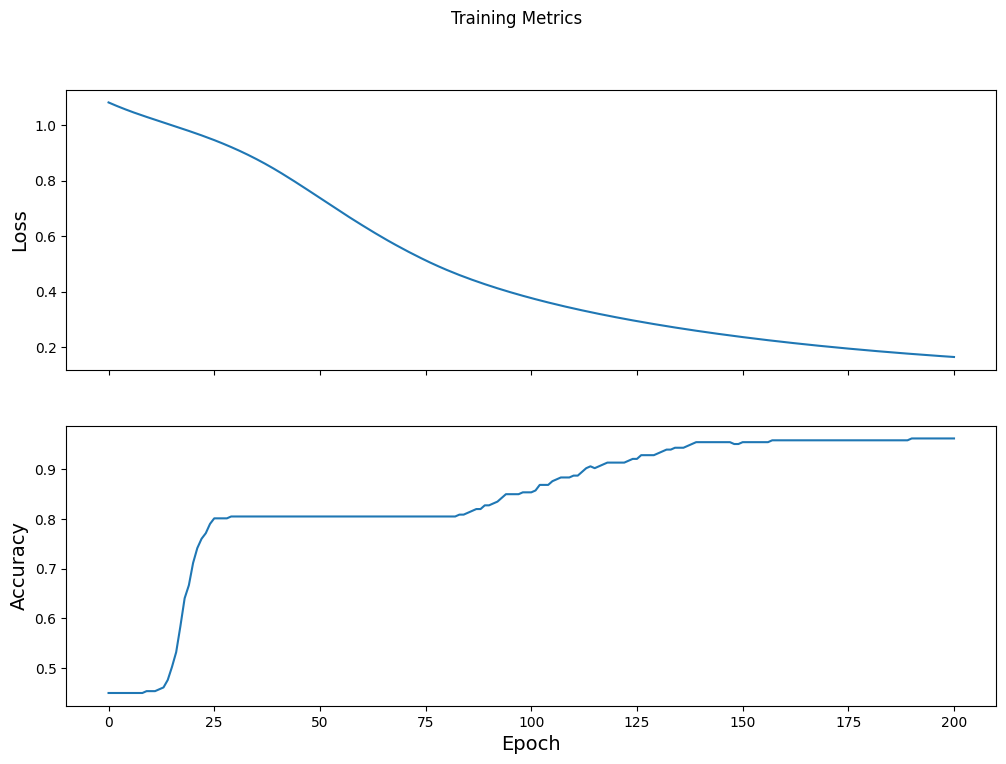
Evaluasi keefektifan model
Sekarang setelah model dilatih, kita bisa mendapatkan beberapa statistik tentang kinerjanya.
Mengevaluasi berarti menentukan seberapa efektif model membuat prediksi. Untuk menentukan keefektifan model pada klasifikasi Iris, berikan beberapa pengukuran sepal dan petal ke model dan minta model untuk memprediksi spesies Iris apa yang diwakilinya. Kemudian bandingkan prediksi model dengan label yang sebenarnya. Misalnya, model yang memilih spesies yang benar pada setengah contoh masukan memiliki akurasi 0.5 . Gambar 4 menunjukkan model yang sedikit lebih efektif, mendapatkan 4 dari 5 prediksi yang benar pada akurasi 80%:
| Contoh fitur | Label | Prediksi model | |||
|---|---|---|---|---|---|
| 5.9 | 3.0 | 4.3 | 1.5 | 1 | 1 |
| 6.9 | 3.1 | 5.4 | 2.1 | 2 | 2 |
| 5.1 | 3.3 | 1.7 | 0,5 | 0 | 0 |
| 6.0 | 3.4 | 4,5 | 1.6 | 1 | 2 |
| 5.5 | 2.5 | 4.0 | 1.3 | 1 | 1 |
| Gambar 4. Pengklasifikasi Iris yang 80% akurat. | |||||
Siapkan kumpulan data pengujian
Mengevaluasi model mirip dengan melatih model. Perbedaan terbesar adalah contoh berasal dari set tes yang terpisah daripada set pelatihan. Untuk menilai keefektifan model secara adil, contoh yang digunakan untuk mengevaluasi model harus berbeda dari contoh yang digunakan untuk melatih model.
Setup untuk Dataset uji mirip dengan setup untuk Dataset pelatihan. Unduh file teks CSV dan parsing nilai itu, lalu berikan sedikit acak:
test_url = "https://storage.googleapis.com/download.tensorflow.org/data/iris_test.csv"
test_fp = tf.keras.utils.get_file(fname=os.path.basename(test_url),
origin=test_url)
test_dataset = tf.data.experimental.make_csv_dataset(
test_fp,
batch_size,
column_names=column_names,
label_name='species',
num_epochs=1,
shuffle=False)
test_dataset = test_dataset.map(pack_features_vector)
Evaluasi model pada dataset uji
Berbeda dengan tahap pelatihan, model hanya mengevaluasi satu epoch dari data uji. Dalam sel kode berikut, kami mengulangi setiap contoh di set pengujian dan membandingkan prediksi model dengan label yang sebenarnya. Ini digunakan untuk mengukur akurasi model di seluruh rangkaian pengujian:
test_accuracy = tf.keras.metrics.Accuracy()
for (x, y) in test_dataset:
# training=False is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
logits = model(x, training=False)
prediction = tf.argmax(logits, axis=1, output_type=tf.int32)
test_accuracy(prediction, y)
print("Test set accuracy: {:.3%}".format(test_accuracy.result()))
Test set accuracy: 96.667%
Kita bisa lihat di batch terakhir, misalnya, modelnya biasanya benar:
tf.stack([y,prediction],axis=1)
<tf.Tensor: shape=(30, 2), dtype=int32, numpy=
array([[1, 1],
[2, 2],
[0, 0],
[1, 1],
[1, 1],
[1, 1],
[0, 0],
[2, 2],
[1, 1],
[2, 2],
[2, 2],
[0, 0],
[2, 2],
[1, 1],
[1, 1],
[0, 0],
[1, 1],
[0, 0],
[0, 0],
[2, 2],
[0, 0],
[1, 1],
[2, 2],
[1, 2],
[1, 1],
[1, 1],
[0, 0],
[1, 1],
[2, 2],
[1, 1]], dtype=int32)>
Gunakan model terlatih untuk membuat prediksi
Kami telah melatih model dan "membuktikan" bahwa itu bagus—tetapi tidak sempurna—dalam mengklasifikasikan spesies Iris. Sekarang mari kita gunakan model terlatih untuk membuat beberapa prediksi pada contoh yang tidak berlabel ; yaitu, pada contoh yang berisi fitur tetapi bukan label.
Dalam kehidupan nyata, contoh tanpa label dapat berasal dari banyak sumber berbeda termasuk aplikasi, file CSV, dan umpan data. Untuk saat ini, kami akan memberikan tiga contoh yang tidak berlabel secara manual untuk memprediksi labelnya. Ingat, nomor label dipetakan ke representasi bernama sebagai:
-
0: Iris setosa -
1: Iris versikolor -
2: Iris virginica
predict_dataset = tf.convert_to_tensor([
[5.1, 3.3, 1.7, 0.5,],
[5.9, 3.0, 4.2, 1.5,],
[6.9, 3.1, 5.4, 2.1]
])
# training=False is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
predictions = model(predict_dataset, training=False)
for i, logits in enumerate(predictions):
class_idx = tf.argmax(logits).numpy()
p = tf.nn.softmax(logits)[class_idx]
name = class_names[class_idx]
print("Example {} prediction: {} ({:4.1f}%)".format(i, name, 100*p))
Example 0 prediction: Iris setosa (97.6%) Example 1 prediction: Iris versicolor (82.0%) Example 2 prediction: Iris virginica (56.4%)