
| | |  Ver fonte no GitHub Ver fonte no GitHub | |
Este guia usa aprendizado de máquina para categorizar flores de íris por espécie. Ele usa o TensorFlow para:
- Construir um modelo,
- Treine este modelo em dados de exemplo e
- Use o modelo para fazer previsões sobre dados desconhecidos.
Programação do TensorFlow
Este guia usa estes conceitos de alto nível do TensorFlow:
- Use o ambiente de desenvolvimento de execução antecipada padrão do TensorFlow,
- Importe dados com a API Datasets ,
- Crie modelos e camadas com a API Keras do TensorFlow.
Este tutorial está estruturado como muitos programas do TensorFlow:
- Importe e analise o conjunto de dados.
- Selecione o tipo de modelo.
- Treine o modelo.
- Avalie a eficácia do modelo.
- Use o modelo treinado para fazer previsões.
Programa de configuração
Configurar importações
Importe o TensorFlow e os outros módulos Python necessários. Por padrão, o TensorFlow usa a execução antecipada para avaliar as operações imediatamente, retornando valores concretos em vez de criar um gráfico computacional que é executado posteriormente. Se você está acostumado a um REPL ou ao console interativo python , isso parece familiar.
import os
import matplotlib.pyplot as plt
import tensorflow as tf
print("TensorFlow version: {}".format(tf.__version__))
print("Eager execution: {}".format(tf.executing_eagerly()))
TensorFlow version: 2.8.0-rc1 Eager execution: True
O problema de classificação da íris
Imagine que você é um botânico procurando uma maneira automatizada de categorizar cada flor de íris que encontrar. O aprendizado de máquina fornece muitos algoritmos para classificar flores estatisticamente. Por exemplo, um sofisticado programa de aprendizado de máquina poderia classificar flores com base em fotografias. Nossas ambições são mais modestas – vamos classificar as flores de íris com base nas medidas de comprimento e largura de suas sépalas e pétalas .
O gênero Iris abrange cerca de 300 espécies, mas nosso programa classificará apenas as três seguintes:
- Íris setosa
- Íris virginica
- Íris versicolor
 |
| Figura 1. Iris setosa (por Radomil , CC BY-SA 3.0), Iris versicolor , (por Dlanglois , CC BY-SA 3.0) e Iris virginica (por Frank Mayfield , CC BY-SA 2.0). |
Felizmente, alguém já criou um conjunto de dados de 120 flores de íris com as medidas de sépalas e pétalas. Este é um conjunto de dados clássico que é popular para problemas de classificação de aprendizado de máquina para iniciantes.
Importar e analisar o conjunto de dados de treinamento
Baixe o arquivo do conjunto de dados e converta-o em uma estrutura que possa ser usada por este programa Python.
Baixe o conjunto de dados
Faça download do arquivo do conjunto de dados de treinamento usando a função tf.keras.utils.get_file . Isso retorna o caminho do arquivo baixado:
train_dataset_url = "https://storage.googleapis.com/download.tensorflow.org/data/iris_training.csv"
train_dataset_fp = tf.keras.utils.get_file(fname=os.path.basename(train_dataset_url),
origin=train_dataset_url)
print("Local copy of the dataset file: {}".format(train_dataset_fp))
Local copy of the dataset file: /home/kbuilder/.keras/datasets/iris_training.csv
Inspecione os dados
Esse conjunto de dados, iris_training.csv , é um arquivo de texto simples que armazena dados tabulares formatados como valores separados por vírgula (CSV). Use o comando head -n5 para dar uma olhada nas primeiras cinco entradas:
head -n5 {train_dataset_fp}
120,4,setosa,versicolor,virginica 6.4,2.8,5.6,2.2,2 5.0,2.3,3.3,1.0,1 4.9,2.5,4.5,1.7,2 4.9,3.1,1.5,0.1,0
A partir desta visualização do conjunto de dados, observe o seguinte:
- A primeira linha é um cabeçalho contendo informações sobre o conjunto de dados:
- Há 120 exemplos no total. Cada exemplo tem quatro recursos e um dos três nomes de rótulo possíveis.
- As linhas subsequentes são registros de dados, um exemplo por linha, onde:
- Os primeiros quatro campos são características : estas são as características de um exemplo. Aqui, os campos contêm números flutuantes que representam as medidas das flores.
- A última coluna é o rótulo : este é o valor que queremos prever. Para este conjunto de dados, é um valor inteiro de 0, 1 ou 2 que corresponde a um nome de flor.
Vamos escrever isso no código:
# column order in CSV file
column_names = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species']
feature_names = column_names[:-1]
label_name = column_names[-1]
print("Features: {}".format(feature_names))
print("Label: {}".format(label_name))
Features: ['sepal_length', 'sepal_width', 'petal_length', 'petal_width'] Label: species
Cada rótulo está associado ao nome da string (por exemplo, "setosa"), mas o aprendizado de máquina geralmente depende de valores numéricos. Os números dos rótulos são mapeados para uma representação nomeada, como:
-
0: Íris setosa -
1: Íris versicolor -
2: Íris virginica
Para obter mais informações sobre recursos e rótulos, consulte a seção de terminologia de ML do curso intensivo de aprendizado de máquina .
class_names = ['Iris setosa', 'Iris versicolor', 'Iris virginica']
Crie um tf.data.Dataset
A API Dataset do TensorFlow lida com muitos casos comuns de carregamento de dados em um modelo. Esta é uma API de alto nível para ler dados e transformá-los em um formulário usado para treinamento.
Como o conjunto de dados é um arquivo de texto formatado em CSV, use a função tf.data.experimental.make_csv_dataset para analisar os dados em um formato adequado. Como essa função gera dados para modelos de treinamento, o comportamento padrão é embaralhar os dados ( shuffle=True, shuffle_buffer_size=10000 ) e repetir o conjunto de dados para sempre ( num_epochs=None ). Também definimos o parâmetro batch_size :
batch_size = 32
train_dataset = tf.data.experimental.make_csv_dataset(
train_dataset_fp,
batch_size,
column_names=column_names,
label_name=label_name,
num_epochs=1)
A função make_csv_dataset retorna um tf.data.Dataset de pares (features, label) , onde features é um dicionário: {'feature_name': value}
Esses objetos Dataset são iteráveis. Vejamos um lote de recursos:
features, labels = next(iter(train_dataset))
print(features)
OrderedDict([('sepal_length', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([5. , 7.4, 6. , 7.2, 5.9, 5.8, 5. , 5. , 7.7, 5.7, 6.3, 5.8, 5. ,
4.8, 6.6, 6.3, 5.4, 6.9, 4.8, 6.6, 5.8, 7.7, 6.7, 7.6, 5.5, 6.4,
5.6, 6.4, 4.4, 4.5, 6.5, 6.3], dtype=float32)>), ('sepal_width', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([3.5, 2.8, 2.7, 3.2, 3. , 2.6, 2. , 3.4, 3. , 2.8, 2.3, 2.7, 3.6,
3.1, 2.9, 3.3, 3. , 3.1, 3. , 3. , 4. , 2.6, 3. , 3. , 2.4, 2.7,
2.7, 2.8, 3. , 2.3, 2.8, 2.5], dtype=float32)>), ('petal_length', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([1.6, 6.1, 5.1, 6. , 5.1, 4. , 3.5, 1.6, 6.1, 4.5, 4.4, 5.1, 1.4,
1.6, 4.6, 4.7, 4.5, 5.1, 1.4, 4.4, 1.2, 6.9, 5. , 6.6, 3.7, 5.3,
4.2, 5.6, 1.3, 1.3, 4.6, 5. ], dtype=float32)>), ('petal_width', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([0.6, 1.9, 1.6, 1.8, 1.8, 1.2, 1. , 0.4, 2.3, 1.3, 1.3, 1.9, 0.2,
0.2, 1.3, 1.6, 1.5, 2.3, 0.3, 1.4, 0.2, 2.3, 1.7, 2.1, 1. , 1.9,
1.3, 2.1, 0.2, 0.3, 1.5, 1.9], dtype=float32)>)])
Observe que os recursos semelhantes são agrupados ou agrupados . Os campos de cada linha de exemplo são anexados à matriz de recursos correspondente. Altere o batch_size para definir o número de exemplos armazenados nessas matrizes de recursos.
Você pode começar a ver alguns clusters traçando alguns recursos do lote:
plt.scatter(features['petal_length'],
features['sepal_length'],
c=labels,
cmap='viridis')
plt.xlabel("Petal length")
plt.ylabel("Sepal length")
plt.show()
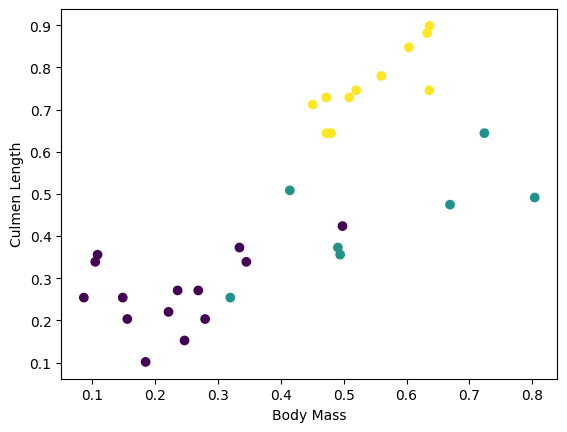
Para simplificar a etapa de construção do modelo, crie uma função para reempacotar o dicionário de recursos em um único array com shape: (batch_size, num_features) .
Esta função usa o método tf.stack que pega valores de uma lista de tensores e cria um tensor combinado na dimensão especificada:
def pack_features_vector(features, labels):
"""Pack the features into a single array."""
features = tf.stack(list(features.values()), axis=1)
return features, labels
Em seguida, use o método tf.data.Dataset#map para empacotar os features de cada par (features,label) no conjunto de dados de treinamento:
train_dataset = train_dataset.map(pack_features_vector)
O elemento features do Dataset agora são arrays com shape (batch_size, num_features) . Vejamos os primeiros exemplos:
features, labels = next(iter(train_dataset))
print(features[:5])
tf.Tensor( [[4.9 3. 1.4 0.2] [6.1 3. 4.9 1.8] [6.1 2.6 5.6 1.4] [6.9 3.2 5.7 2.3] [6.7 3.1 4.4 1.4]], shape=(5, 4), dtype=float32)
Selecione o tipo de modelo
Por que modelo?
Um modelo é um relacionamento entre recursos e o rótulo. Para o problema de classificação da íris, o modelo define a relação entre as medidas da sépala e pétala e as espécies de íris previstas. Alguns modelos simples podem ser descritos com algumas linhas de álgebra, mas modelos complexos de aprendizado de máquina têm um grande número de parâmetros que são difíceis de resumir.
Você poderia determinar a relação entre os quatro recursos e as espécies Iris sem usar o aprendizado de máquina? Ou seja, você poderia usar técnicas de programação tradicionais (por exemplo, muitas instruções condicionais) para criar um modelo? Talvez - se você analisar o conjunto de dados por tempo suficiente para determinar as relações entre as medidas de pétalas e sépalas para uma espécie específica. E isso se torna difícil – talvez impossível – em conjuntos de dados mais complicados. Uma boa abordagem de aprendizado de máquina determina o modelo para você . Se você inserir exemplos representativos suficientes no tipo certo de modelo de aprendizado de máquina, o programa descobrirá os relacionamentos para você.
Selecione o modelo
Precisamos selecionar o tipo de modelo para treinar. Existem muitos tipos de modelos e escolher um bom requer experiência. Este tutorial usa uma rede neural para resolver o problema de classificação da íris. As redes neurais podem encontrar relacionamentos complexos entre os recursos e o rótulo. É um gráfico altamente estruturado, organizado em uma ou mais camadas ocultas . Cada camada oculta consiste em um ou mais neurônios . Existem várias categorias de redes neurais e este programa usa uma rede neural densa ou totalmente conectada : os neurônios em uma camada recebem conexões de entrada de cada neurônio na camada anterior. Por exemplo, a Figura 2 ilustra uma rede neural densa que consiste em uma camada de entrada, duas camadas ocultas e uma camada de saída:
 |
| Figura 2. Uma rede neural com recursos, camadas ocultas e previsões. |
Quando o modelo da Figura 2 é treinado e alimentado com um exemplo não rotulado, ele produz três previsões: a probabilidade de que esta flor seja a determinada espécie de Iris. Essa previsão é chamada de inferência . Para este exemplo, a soma das previsões de saída é 1,0. Na Figura 2, essa previsão se divide em: 0.02 para Iris setosa , 0.95 para Iris versicolor e 0.03 para Iris virginica . Isso significa que o modelo prevê - com 95% de probabilidade - que uma flor de exemplo não rotulada é uma Iris versicolor .
Criar um modelo usando Keras
A API TensorFlow tf.keras é a maneira preferida de criar modelos e camadas. Isso facilita a criação de modelos e experimentos, enquanto o Keras lida com a complexidade de conectar tudo.
O modelo tf.keras.Sequential é uma pilha linear de camadas. Seu construtor recebe uma lista de instâncias de camada, neste caso, duas camadas tf.keras.layers.Dense com 10 nós cada e uma camada de saída com 3 nós representando nossas previsões de rótulo. O parâmetro input_shape da primeira camada corresponde ao número de feições do conjunto de dados e é obrigatório:
model = tf.keras.Sequential([
tf.keras.layers.Dense(10, activation=tf.nn.relu, input_shape=(4,)), # input shape required
tf.keras.layers.Dense(10, activation=tf.nn.relu),
tf.keras.layers.Dense(3)
])
A função de ativação determina a forma de saída de cada nó na camada. Essas não linearidades são importantes – sem elas, o modelo seria equivalente a uma única camada. Existem muitos tf.keras.activations , mas ReLU é comum para camadas ocultas.
O número ideal de camadas ocultas e neurônios depende do problema e do conjunto de dados. Como muitos aspectos do aprendizado de máquina, escolher a melhor forma da rede neural requer uma mistura de conhecimento e experimentação. Como regra geral, aumentar o número de camadas ocultas e neurônios normalmente cria um modelo mais poderoso, que requer mais dados para um treinamento eficaz.
Usando o modelo
Vamos dar uma olhada rápida no que esse modelo faz com um lote de recursos:
predictions = model(features)
predictions[:5]
<tf.Tensor: shape=(5, 3), dtype=float32, numpy=
array([[-4.0874639e+00, 1.5199981e-03, -9.9991310e-01],
[-5.3246369e+00, -1.8366380e-01, -1.3161827e+00],
[-5.1154275e+00, -2.8129923e-01, -1.3305402e+00],
[-6.0694785e+00, -2.1251860e-01, -1.5091233e+00],
[-5.6730523e+00, -1.4321266e-01, -1.4437559e+00]], dtype=float32)>
Aqui, cada exemplo retorna um logit para cada classe.
Para converter esses logits em uma probabilidade para cada classe, use a função softmax :
tf.nn.softmax(predictions[:5])
<tf.Tensor: shape=(5, 3), dtype=float32, numpy=
array([[0.01210616, 0.7224865 , 0.26540732],
[0.00440638, 0.75297093, 0.24262273],
[0.00585618, 0.7362918 , 0.25785193],
[0.00224076, 0.7835035 , 0.21425581],
[0.00310779, 0.7834839 , 0.21340834]], dtype=float32)>
Tomando o tf.argmax entre classes nos dá o índice de classe previsto. Mas o modelo ainda não foi treinado, então essas não são boas previsões:
print("Prediction: {}".format(tf.argmax(predictions, axis=1)))
print(" Labels: {}".format(labels))
Prediction: [1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1]
Labels: [0 2 2 2 1 1 0 1 1 2 2 1 0 2 2 2 1 0 2 2 1 0 2 1 2 0 1 1 2 2 1 2]
Treine o modelo
O treinamento é o estágio do aprendizado de máquina quando o modelo é otimizado gradualmente ou o modelo aprende o conjunto de dados. O objetivo é aprender o suficiente sobre a estrutura do conjunto de dados de treinamento para fazer previsões sobre dados não vistos. Se você aprender muito sobre o conjunto de dados de treinamento, as previsões funcionarão apenas para os dados vistos e não serão generalizáveis. Esse problema é chamado de overfitting — é como memorizar as respostas em vez de entender como resolver um problema.
O problema de classificação Iris é um exemplo de aprendizado de máquina supervisionado : o modelo é treinado a partir de exemplos que contêm rótulos. No aprendizado de máquina não supervisionado , os exemplos não contêm rótulos. Em vez disso, o modelo normalmente encontra padrões entre os recursos.
Defina a função de perda e gradiente
Ambas as etapas de treinamento e avaliação precisam calcular a perda do modelo. Isso mede o quanto as previsões de um modelo estão fora do rótulo desejado, em outras palavras, o desempenho do modelo é ruim. Queremos minimizar ou otimizar esse valor.
Nosso modelo calculará sua perda usando a função tf.keras.losses.SparseCategoricalCrossentropy que pega as previsões de probabilidade de classe do modelo e o rótulo desejado e retorna a perda média entre os exemplos.
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
def loss(model, x, y, training):
# training=training is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
y_ = model(x, training=training)
return loss_object(y_true=y, y_pred=y_)
l = loss(model, features, labels, training=False)
print("Loss test: {}".format(l))
Loss test: 1.6059828996658325
Use o contexto tf.GradientTape para calcular os gradientes usados para otimizar seu modelo:
def grad(model, inputs, targets):
with tf.GradientTape() as tape:
loss_value = loss(model, inputs, targets, training=True)
return loss_value, tape.gradient(loss_value, model.trainable_variables)
Crie um otimizador
Um otimizador aplica os gradientes calculados às variáveis do modelo para minimizar a função de loss . Você pode pensar na função de perda como uma superfície curva (veja a Figura 3) e queremos encontrar seu ponto mais baixo andando por aí. Os gradientes apontam na direção da subida mais íngreme - então vamos viajar na direção oposta e descer a colina. Ao calcular iterativamente a perda e o gradiente para cada lote, ajustaremos o modelo durante o treinamento. Gradualmente, o modelo encontrará a melhor combinação de pesos e viés para minimizar a perda. E quanto menor a perda, melhores as previsões do modelo.
 |
| Figura 3. Algoritmos de otimização visualizados ao longo do tempo no espaço 3D. (Fonte: Stanford class CS231n , Licença MIT, Crédito de imagem: Alec Radford ) |
O TensorFlow tem muitos algoritmos de otimização disponíveis para treinamento. Este modelo usa o tf.keras.optimizers.SGD que implementa o algoritmo estocástico gradiente descendente (SGD). A learning_rate define o tamanho do passo a ser executado para cada iteração ladeira abaixo. Este é um hiperparâmetro que você normalmente ajustará para obter melhores resultados.
Vamos configurar o otimizador:
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
Usaremos isso para calcular uma única etapa de otimização:
loss_value, grads = grad(model, features, labels)
print("Step: {}, Initial Loss: {}".format(optimizer.iterations.numpy(),
loss_value.numpy()))
optimizer.apply_gradients(zip(grads, model.trainable_variables))
print("Step: {}, Loss: {}".format(optimizer.iterations.numpy(),
loss(model, features, labels, training=True).numpy()))
Step: 0, Initial Loss: 1.6059828996658325 Step: 1, Loss: 1.3759253025054932
Ciclo de treinamento
Com todas as peças no lugar, o modelo está pronto para o treino! Um loop de treinamento alimenta os exemplos de conjuntos de dados no modelo para ajudá-lo a fazer melhores previsões. O bloco de código a seguir configura essas etapas de treinamento:
- Iterar cada época . Uma época é uma passagem pelo conjunto de dados.
- Dentro de uma época, itere sobre cada exemplo no conjunto de
Datasetde treinamento pegando seus recursos (x) e rótulo (y). - Usando os recursos do exemplo, faça uma previsão e compare-a com o rótulo. Meça a imprecisão da previsão e use-a para calcular a perda e os gradientes do modelo.
- Use um
optimizerpara atualizar as variáveis do modelo. - Acompanhe algumas estatísticas para visualização.
- Repita para cada época.
A variável num_epochs é o número de vezes para fazer um loop na coleção do conjunto de dados. Contra-intuitivamente, treinar um modelo por mais tempo não garante um modelo melhor. num_epochs é um hiperparâmetro que você pode ajustar. Escolher o número certo geralmente requer experiência e experimentação:
## Note: Rerunning this cell uses the same model variables
# Keep results for plotting
train_loss_results = []
train_accuracy_results = []
num_epochs = 201
for epoch in range(num_epochs):
epoch_loss_avg = tf.keras.metrics.Mean()
epoch_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()
# Training loop - using batches of 32
for x, y in train_dataset:
# Optimize the model
loss_value, grads = grad(model, x, y)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
# Track progress
epoch_loss_avg.update_state(loss_value) # Add current batch loss
# Compare predicted label to actual label
# training=True is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
epoch_accuracy.update_state(y, model(x, training=True))
# End epoch
train_loss_results.append(epoch_loss_avg.result())
train_accuracy_results.append(epoch_accuracy.result())
if epoch % 50 == 0:
print("Epoch {:03d}: Loss: {:.3f}, Accuracy: {:.3%}".format(epoch,
epoch_loss_avg.result(),
epoch_accuracy.result()))
Epoch 000: Loss: 1.766, Accuracy: 43.333% Epoch 050: Loss: 0.579, Accuracy: 71.667% Epoch 100: Loss: 0.398, Accuracy: 82.500% Epoch 150: Loss: 0.307, Accuracy: 92.500% Epoch 200: Loss: 0.224, Accuracy: 95.833%
Visualize a função de perda ao longo do tempo
Embora seja útil imprimir o progresso de treinamento do modelo, geralmente é mais útil ver esse progresso. O TensorBoard é uma boa ferramenta de visualização que acompanha o TensorFlow, mas podemos criar gráficos básicos usando o módulo matplotlib .
Interpretar esses gráficos requer alguma experiência, mas você realmente quer ver a perda diminuir e a precisão aumentar:
fig, axes = plt.subplots(2, sharex=True, figsize=(12, 8))
fig.suptitle('Training Metrics')
axes[0].set_ylabel("Loss", fontsize=14)
axes[0].plot(train_loss_results)
axes[1].set_ylabel("Accuracy", fontsize=14)
axes[1].set_xlabel("Epoch", fontsize=14)
axes[1].plot(train_accuracy_results)
plt.show()
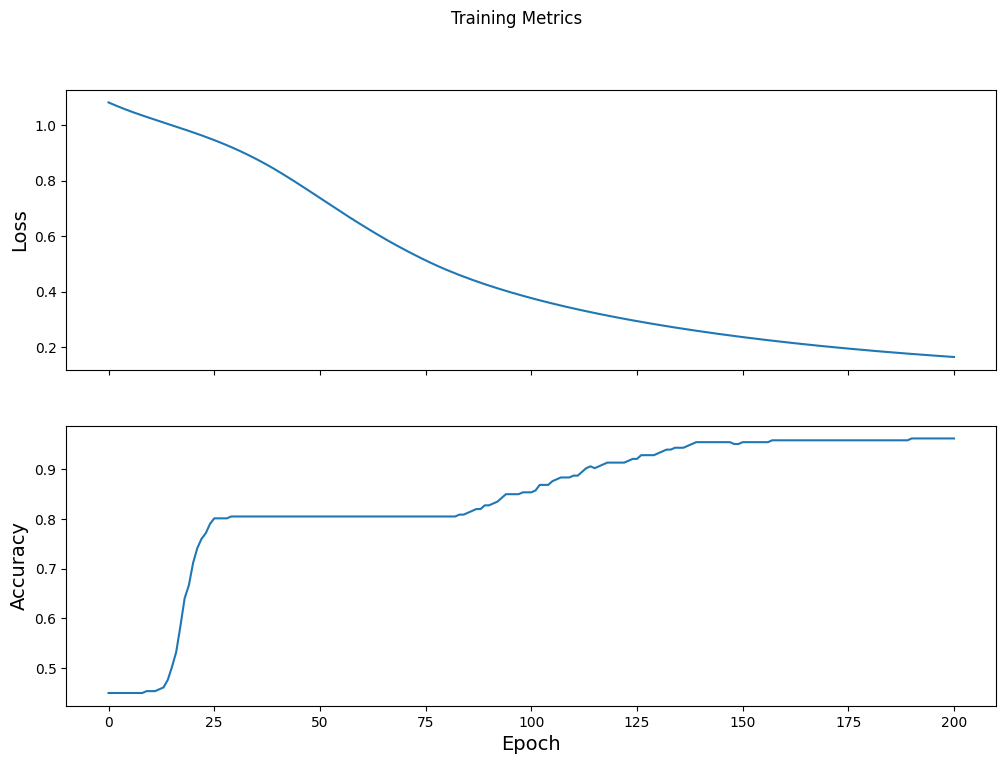
Avalie a eficácia do modelo
Agora que o modelo está treinado, podemos obter algumas estatísticas sobre seu desempenho.
Avaliar significa determinar a eficácia com que o modelo faz previsões. Para determinar a eficácia do modelo na classificação de Iris, passe algumas medidas de sépalas e pétalas para o modelo e peça ao modelo para prever quais espécies de Iris elas representam. Em seguida, compare as previsões do modelo com o rótulo real. Por exemplo, um modelo que escolheu a espécie correta em metade dos exemplos de entrada tem uma precisão de 0.5 . A Figura 4 mostra um modelo um pouco mais eficaz, obtendo 4 de 5 previsões corretas com 80% de precisão:
| Recursos de exemplo | Etiqueta | Previsão do modelo | |||
|---|---|---|---|---|---|
| 5.9 | 3,0 | 4.3 | 1,5 | 1 | 1 |
| 6.9 | 3.1 | 5.4 | 2.1 | 2 | 2 |
| 5.1 | 3.3 | 1,7 | 0,5 | 0 | 0 |
| 6,0 | 3.4 | 4,5 | 1,6 | 1 | 2 |
| 5,5 | 2,5 | 4,0 | 1.3 | 1 | 1 |
| Figura 4. Um classificador Iris com 80% de precisão. | |||||
Configurar o conjunto de dados de teste
Avaliar o modelo é semelhante ao treinamento do modelo. A maior diferença é que os exemplos vêm de um conjunto de teste separado em vez do conjunto de treinamento. Para avaliar de forma justa a eficácia de um modelo, os exemplos usados para avaliar um modelo devem ser diferentes dos exemplos usados para treinar o modelo.
A configuração do conjunto de Dataset de teste é semelhante à configuração do conjunto de Dataset de treinamento. Faça o download do arquivo de texto CSV e analise esses valores e, em seguida, embaralhe um pouco:
test_url = "https://storage.googleapis.com/download.tensorflow.org/data/iris_test.csv"
test_fp = tf.keras.utils.get_file(fname=os.path.basename(test_url),
origin=test_url)
test_dataset = tf.data.experimental.make_csv_dataset(
test_fp,
batch_size,
column_names=column_names,
label_name='species',
num_epochs=1,
shuffle=False)
test_dataset = test_dataset.map(pack_features_vector)
Avalie o modelo no conjunto de dados de teste
Ao contrário do estágio de treinamento, o modelo avalia apenas uma única época dos dados de teste. Na célula de código a seguir, iteramos sobre cada exemplo no conjunto de teste e comparamos a previsão do modelo com o rótulo real. Isso é usado para medir a precisão do modelo em todo o conjunto de teste:
test_accuracy = tf.keras.metrics.Accuracy()
for (x, y) in test_dataset:
# training=False is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
logits = model(x, training=False)
prediction = tf.argmax(logits, axis=1, output_type=tf.int32)
test_accuracy(prediction, y)
print("Test set accuracy: {:.3%}".format(test_accuracy.result()))
Test set accuracy: 96.667%
Podemos ver no último lote, por exemplo, o modelo geralmente está correto:
tf.stack([y,prediction],axis=1)
<tf.Tensor: shape=(30, 2), dtype=int32, numpy=
array([[1, 1],
[2, 2],
[0, 0],
[1, 1],
[1, 1],
[1, 1],
[0, 0],
[2, 2],
[1, 1],
[2, 2],
[2, 2],
[0, 0],
[2, 2],
[1, 1],
[1, 1],
[0, 0],
[1, 1],
[0, 0],
[0, 0],
[2, 2],
[0, 0],
[1, 1],
[2, 2],
[1, 2],
[1, 1],
[1, 1],
[0, 0],
[1, 1],
[2, 2],
[1, 1]], dtype=int32)>
Use o modelo treinado para fazer previsões
Treinamos um modelo e "provamos" que ele é bom - mas não perfeito - na classificação de espécies de íris. Agora vamos usar o modelo treinado para fazer algumas previsões em exemplos não rotulados ; ou seja, em exemplos que contêm recursos, mas não um rótulo.
Na vida real, os exemplos não rotulados podem vir de várias fontes diferentes, incluindo aplicativos, arquivos CSV e feeds de dados. Por enquanto, forneceremos manualmente três exemplos não rotulados para prever seus rótulos. Lembre-se, os números dos rótulos são mapeados para uma representação nomeada como:
-
0: Íris setosa -
1: Íris versicolor -
2: Íris virginica
predict_dataset = tf.convert_to_tensor([
[5.1, 3.3, 1.7, 0.5,],
[5.9, 3.0, 4.2, 1.5,],
[6.9, 3.1, 5.4, 2.1]
])
# training=False is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
predictions = model(predict_dataset, training=False)
for i, logits in enumerate(predictions):
class_idx = tf.argmax(logits).numpy()
p = tf.nn.softmax(logits)[class_idx]
name = class_names[class_idx]
print("Example {} prediction: {} ({:4.1f}%)".format(i, name, 100*p))
Example 0 prediction: Iris setosa (97.6%) Example 1 prediction: Iris versicolor (82.0%) Example 2 prediction: Iris virginica (56.4%)