
| | |  GitHub-এ উৎস দেখুন GitHub-এ উৎস দেখুন | |
এই টিউটোরিয়ালটি দেখায় কিভাবে একটি ডিপ কনভোলিউশনাল জেনারেটিভ অ্যাডভারসারিয়াল নেটওয়ার্ক (DCGAN) ব্যবহার করে হাতে লেখা অঙ্কের ছবি তৈরি করা যায়। কোডটি কেরাস সিকোয়েন্সিয়াল API ব্যবহার করে একটি tf.GradientTape প্রশিক্ষণ লুপ দিয়ে লেখা হয়।
GAN কি?
জেনারেটিভ অ্যাডভারসারিয়াল নেটওয়ার্ক (GANs) হল আজকের কম্পিউটার বিজ্ঞানের সবচেয়ে আকর্ষণীয় ধারণাগুলির মধ্যে একটি। দুটি মডেল একই সাথে একটি প্রতিকূল প্রক্রিয়া দ্বারা প্রশিক্ষিত হয়। একজন জেনারেটর ("শিল্পী") বাস্তব দেখায় এমন চিত্র তৈরি করতে শেখে, যখন একজন বৈষম্যকারী ("শিল্প সমালোচক") নকল ছাড়া বাস্তব চিত্রগুলি বলতে শেখে।
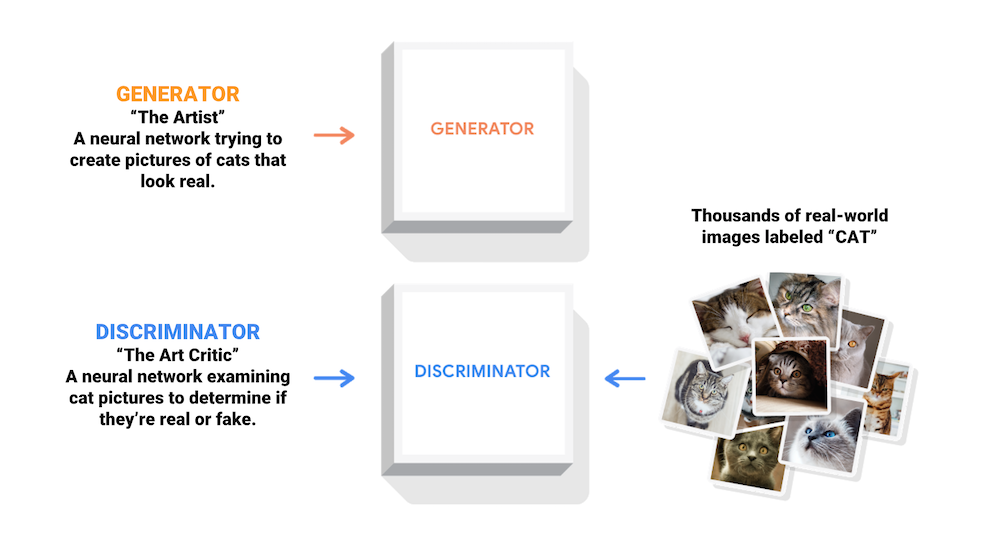
প্রশিক্ষণের সময়, জেনারেটর ক্রমান্বয়ে বাস্তব দেখায় এমন চিত্র তৈরি করতে আরও ভাল হয়ে ওঠে, যখন বৈষম্যকারী তাদের আলাদা করে বলার ক্ষেত্রে আরও ভাল হয়ে ওঠে। প্রক্রিয়াটি ভারসাম্যপূর্ণ অবস্থায় পৌঁছায় যখন বৈষম্যকারী আর নকল থেকে আসল ছবিকে আলাদা করতে পারে না।
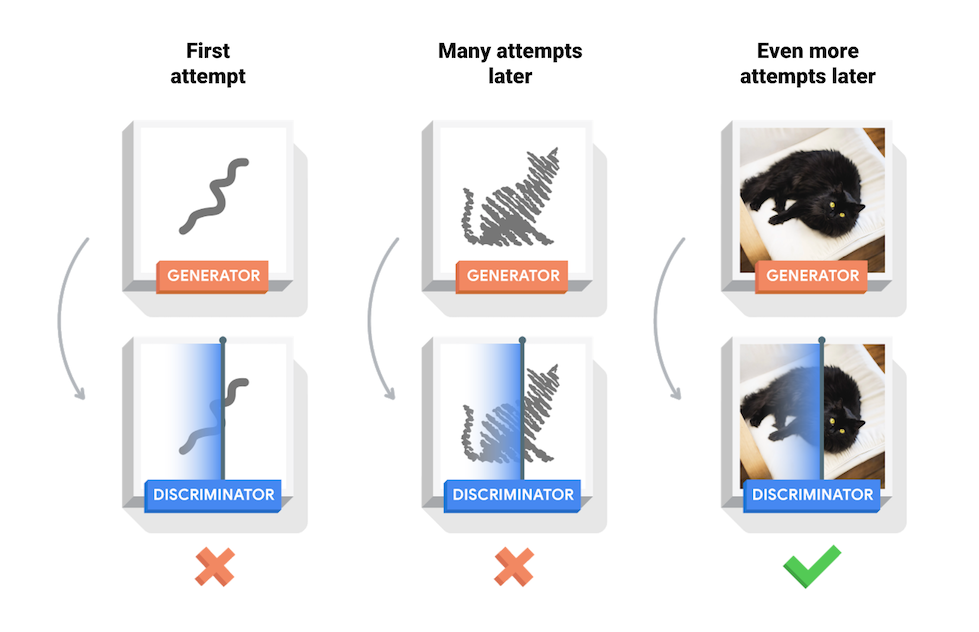
এই নোটবুকটি MNIST ডেটাসেটে এই প্রক্রিয়াটি প্রদর্শন করে। নিম্নলিখিত অ্যানিমেশন জেনারেটর দ্বারা উত্পাদিত চিত্রগুলির একটি সিরিজ দেখায় কারণ এটি 50টি যুগের জন্য প্রশিক্ষিত হয়েছিল। চিত্রগুলি এলোমেলো শব্দ হিসাবে শুরু হয় এবং সময়ের সাথে সাথে ক্রমবর্ধমান হাতে লেখা অঙ্কগুলির সাথে সাদৃশ্যপূর্ণ।

GAN সম্পর্কে আরও জানতে, MIT-এর ইন্ট্রো টু ডিপ লার্নিং কোর্সটি দেখুন।
সেটআপ
import tensorflow as tf
tf.__version__
'2.8.0-rc1'
# To generate GIFspip install imageiopip install git+https://github.com/tensorflow/docs
import glob
import imageio
import matplotlib.pyplot as plt
import numpy as np
import os
import PIL
from tensorflow.keras import layers
import time
from IPython import display
ডেটাসেট লোড করুন এবং প্রস্তুত করুন
জেনারেটর এবং বৈষম্যকারীকে প্রশিক্ষণ দিতে আপনি MNIST ডেটাসেট ব্যবহার করবেন। জেনারেটর এমএনআইএসটি ডেটার অনুরূপ হাতে লেখা অঙ্ক তৈরি করবে।
(train_images, train_labels), (_, _) = tf.keras.datasets.mnist.load_data()
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1).astype('float32')
train_images = (train_images - 127.5) / 127.5 # Normalize the images to [-1, 1]
BUFFER_SIZE = 60000
BATCH_SIZE = 256
# Batch and shuffle the data
train_dataset = tf.data.Dataset.from_tensor_slices(train_images).shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
মডেলগুলি তৈরি করুন
কেরাস সিকোয়েন্সিয়াল API ব্যবহার করে জেনারেটর এবং ডিসক্রিমিনেটর উভয়কেই সংজ্ঞায়িত করা হয়েছে।
জেনারেটর
জেনারেটরটি বীজ (এলোমেলো শব্দ) থেকে একটি চিত্র তৈরি করতে tf.keras.layers.Conv2DT tf.keras.layers.Conv2DTranspose (আপস্যাম্পলিং) স্তরগুলি ব্যবহার করে। একটি Dense স্তর দিয়ে শুরু করুন যা এই বীজটিকে ইনপুট হিসাবে নেয়, তারপরে আপনি 28x28x1 এর পছন্দসই চিত্র আকারে না পৌঁছানো পর্যন্ত বেশ কয়েকবার নমুনা নিন। প্রতিটি স্তরের জন্য tf.keras.layers.LeakyReLU অ্যাক্টিভেশন লক্ষ্য করুন, আউটপুট স্তরটি ছাড়া যা tanh ব্যবহার করে।
def make_generator_model():
model = tf.keras.Sequential()
model.add(layers.Dense(7*7*256, use_bias=False, input_shape=(100,)))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Reshape((7, 7, 256)))
assert model.output_shape == (None, 7, 7, 256) # Note: None is the batch size
model.add(layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias=False))
assert model.output_shape == (None, 7, 7, 128)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False))
assert model.output_shape == (None, 14, 14, 64)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh'))
assert model.output_shape == (None, 28, 28, 1)
return model
একটি ছবি তৈরি করতে (এখনও অপ্রশিক্ষিত) জেনারেটর ব্যবহার করুন।
generator = make_generator_model()
noise = tf.random.normal([1, 100])
generated_image = generator(noise, training=False)
plt.imshow(generated_image[0, :, :, 0], cmap='gray')
<matplotlib.image.AxesImage at 0x7f6fe7a04b90>

বৈষম্যকারী
বৈষম্যকারী একটি সিএনএন-ভিত্তিক চিত্র শ্রেণিবিন্যাসকারী।
def make_discriminator_model():
model = tf.keras.Sequential()
model.add(layers.Conv2D(64, (5, 5), strides=(2, 2), padding='same',
input_shape=[28, 28, 1]))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
model.add(layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same'))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
model.add(layers.Flatten())
model.add(layers.Dense(1))
return model
উত্পন্ন চিত্রগুলিকে আসল বা নকল হিসাবে শ্রেণীবদ্ধ করতে (এখনও অপ্রশিক্ষিত) বৈষম্যকারী ব্যবহার করুন। মডেলটিকে বাস্তব চিত্রের জন্য ইতিবাচক মান এবং নকল চিত্রগুলির জন্য নেতিবাচক মান আউটপুট করার প্রশিক্ষণ দেওয়া হবে।
discriminator = make_discriminator_model()
decision = discriminator(generated_image)
print (decision)
tf.Tensor([[-0.00339105]], shape=(1, 1), dtype=float32)
ক্ষতি এবং অপ্টিমাইজার সংজ্ঞায়িত করুন
উভয় মডেলের জন্য ক্ষতি ফাংশন এবং অপ্টিমাইজার সংজ্ঞায়িত করুন।
# This method returns a helper function to compute cross entropy loss
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)
বৈষম্যকারীর ক্ষতি
এই পদ্ধতিটি পরিমাপ করে যে বৈষম্যকারী কতটা ভালভাবে নকল থেকে বাস্তব চিত্রগুলিকে আলাদা করতে সক্ষম। এটি বাস্তব চিত্রগুলিতে বৈষম্যকারীর ভবিষ্যদ্বাণীকে 1s এর একটি অ্যারের সাথে এবং নকল (উত্পন্ন) চিত্রগুলিতে বৈষম্যকারীর ভবিষ্যদ্বাণী 0s এর একটি অ্যারের সাথে তুলনা করে৷
def discriminator_loss(real_output, fake_output):
real_loss = cross_entropy(tf.ones_like(real_output), real_output)
fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output)
total_loss = real_loss + fake_loss
return total_loss
জেনারেটরের ক্ষতি
জেনারেটরের ক্ষতি পরিমাপ করে যে এটি বৈষম্যকারীকে কতটা ভালভাবে চালাতে সক্ষম হয়েছিল। স্বজ্ঞাতভাবে, যদি জেনারেটরটি ভাল কাজ করে, তবে বৈষম্যকারী নকল ছবিগুলিকে আসল (বা 1) হিসাবে শ্রেণীবদ্ধ করবে। এখানে, 1s এর একটি অ্যারের সাথে জেনারেট করা চিত্রগুলিতে বৈষম্যকারীদের সিদ্ধান্তের তুলনা করুন।
def generator_loss(fake_output):
return cross_entropy(tf.ones_like(fake_output), fake_output)
বৈষম্যকারী এবং জেনারেটর অপ্টিমাইজার ভিন্ন কারণ আপনি দুটি নেটওয়ার্ককে আলাদাভাবে প্রশিক্ষণ দেবেন।
generator_optimizer = tf.keras.optimizers.Adam(1e-4)
discriminator_optimizer = tf.keras.optimizers.Adam(1e-4)
চেকপয়েন্ট সংরক্ষণ করুন
এই নোটবুকটি মডেলগুলিকে কীভাবে সংরক্ষণ এবং পুনরুদ্ধার করতে হয় তাও প্রদর্শন করে, যা একটি দীর্ঘ চলমান প্রশিক্ষণের কাজ বাধাগ্রস্ত হলে সহায়ক হতে পারে।
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(generator_optimizer=generator_optimizer,
discriminator_optimizer=discriminator_optimizer,
generator=generator,
discriminator=discriminator)
প্রশিক্ষণ লুপ সংজ্ঞায়িত করুন
EPOCHS = 50
noise_dim = 100
num_examples_to_generate = 16
# You will reuse this seed overtime (so it's easier)
# to visualize progress in the animated GIF)
seed = tf.random.normal([num_examples_to_generate, noise_dim])
প্রশিক্ষণ লুপ জেনারেটর ইনপুট হিসাবে একটি এলোমেলো বীজ প্রাপ্তির সাথে শুরু হয়। যে বীজ একটি ইমেজ উত্পাদন ব্যবহার করা হয়. বৈষম্যকারীকে তারপর বাস্তব চিত্র (প্রশিক্ষণ সেট থেকে আঁকা) এবং নকল ছবি (জেনারেটর দ্বারা উত্পাদিত) শ্রেণিবদ্ধ করতে ব্যবহৃত হয়। এই প্রতিটি মডেলের জন্য ক্ষতি গণনা করা হয়, এবং গ্রেডিয়েন্টগুলি জেনারেটর এবং বৈষম্যকারী আপডেট করতে ব্যবহৃত হয়।
# Notice the use of `tf.function`
# This annotation causes the function to be "compiled".
@tf.function
def train_step(images):
noise = tf.random.normal([BATCH_SIZE, noise_dim])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
generated_images = generator(noise, training=True)
real_output = discriminator(images, training=True)
fake_output = discriminator(generated_images, training=True)
gen_loss = generator_loss(fake_output)
disc_loss = discriminator_loss(real_output, fake_output)
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
def train(dataset, epochs):
for epoch in range(epochs):
start = time.time()
for image_batch in dataset:
train_step(image_batch)
# Produce images for the GIF as you go
display.clear_output(wait=True)
generate_and_save_images(generator,
epoch + 1,
seed)
# Save the model every 15 epochs
if (epoch + 1) % 15 == 0:
checkpoint.save(file_prefix = checkpoint_prefix)
print ('Time for epoch {} is {} sec'.format(epoch + 1, time.time()-start))
# Generate after the final epoch
display.clear_output(wait=True)
generate_and_save_images(generator,
epochs,
seed)
ছবি তৈরি এবং সংরক্ষণ করুন
def generate_and_save_images(model, epoch, test_input):
# Notice `training` is set to False.
# This is so all layers run in inference mode (batchnorm).
predictions = model(test_input, training=False)
fig = plt.figure(figsize=(4, 4))
for i in range(predictions.shape[0]):
plt.subplot(4, 4, i+1)
plt.imshow(predictions[i, :, :, 0] * 127.5 + 127.5, cmap='gray')
plt.axis('off')
plt.savefig('image_at_epoch_{:04d}.png'.format(epoch))
plt.show()
মডেলকে প্রশিক্ষণ দিন
জেনারেটর এবং বৈষম্যকারীকে একই সাথে প্রশিক্ষণের জন্য উপরে সংজ্ঞায়িত train() পদ্ধতিতে কল করুন। দ্রষ্টব্য, GAN-এর প্রশিক্ষণ কঠিন হতে পারে। এটি গুরুত্বপূর্ণ যে জেনারেটর এবং বৈষম্যকারী একে অপরের উপর প্রভাব ফেলবে না (যেমন, তারা একই হারে প্রশিক্ষণ দেয়)।
প্রশিক্ষণের শুরুতে, তৈরি করা চিত্রগুলি এলোমেলো শব্দের মতো দেখায়। প্রশিক্ষণের অগ্রগতি হিসাবে, উত্পন্ন অঙ্কগুলি ক্রমশ বাস্তব দেখাবে। প্রায় 50টি যুগের পরে, তারা MNIST সংখ্যার সাথে সাদৃশ্যপূর্ণ। Colab-এ ডিফল্ট সেটিংস সহ এটি প্রায় এক মিনিট/যুগ সময় নিতে পারে।
train(train_dataset, EPOCHS)

সর্বশেষ চেকপয়েন্ট পুনরুদ্ধার করুন.
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir))
<tensorflow.python.training.tracking.util.CheckpointLoadStatus at 0x7f6ee8136950>
একটি GIF তৈরি করুন
# Display a single image using the epoch number
def display_image(epoch_no):
return PIL.Image.open('image_at_epoch_{:04d}.png'.format(epoch_no))
display_image(EPOCHS)

প্রশিক্ষণের সময় সংরক্ষিত ছবিগুলি ব্যবহার করে একটি অ্যানিমেটেড জিআইএফ তৈরি করতে imageio ব্যবহার করুন।
anim_file = 'dcgan.gif'
with imageio.get_writer(anim_file, mode='I') as writer:
filenames = glob.glob('image*.png')
filenames = sorted(filenames)
for filename in filenames:
image = imageio.imread(filename)
writer.append_data(image)
image = imageio.imread(filename)
writer.append_data(image)
import tensorflow_docs.vis.embed as embed
embed.embed_file(anim_file)

পরবর্তী পদক্ষেপ
এই টিউটোরিয়ালে একটি GAN লিখতে এবং প্রশিক্ষণের জন্য প্রয়োজনীয় সম্পূর্ণ কোড দেখানো হয়েছে। পরবর্তী পদক্ষেপ হিসাবে, আপনি একটি ভিন্ন ডেটাসেট নিয়ে পরীক্ষা করতে পছন্দ করতে পারেন, উদাহরণস্বরূপ বড়-স্কেল সেলেব ফেস অ্যাট্রিবিউটস (CelebA) ডেটাসেট Kaggle এ উপলব্ধ । GAN সম্পর্কে আরও জানতে NIPS 2016 টিউটোরিয়াল দেখুন: জেনারেটিভ অ্যাডভারসারিয়াল নেটওয়ার্ক ।