
| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub | |
В этом руководстве показано, как создавать изображения рукописных цифр с помощью глубокой сверточной генеративно-состязательной сети (DCGAN). Код написан с использованием Keras Sequential API с обучающим циклом tf.GradientTape .
Что такое ГАН?
Генеративно-состязательные сети (GAN) — одна из самых интересных идей в компьютерных науках на сегодняшний день. Две модели обучаются одновременно состязательным процессом. Генератор («художник») учится создавать изображения, которые выглядят реальными, а дискриминатор («искусствовед») учится отличать настоящие изображения от подделок.
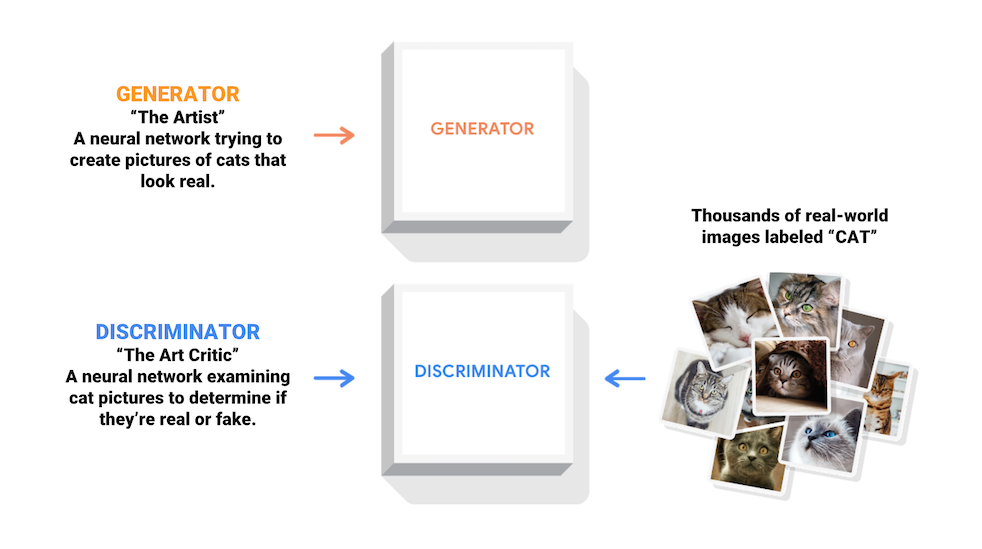
Во время обучения генератор постепенно становится лучше в создании изображений, которые выглядят реальными, в то время как дискриминатор лучше различает их. Процесс достигает равновесия, когда дискриминатор уже не может отличить настоящие изображения от подделок.
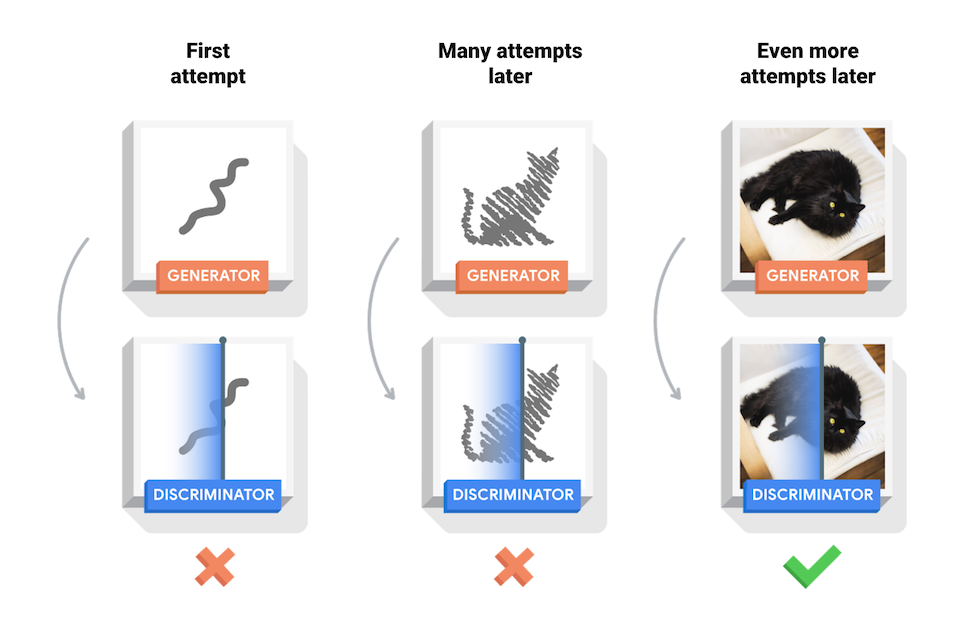
Этот блокнот демонстрирует этот процесс в наборе данных MNIST. Следующая анимация показывает серию изображений, созданных генератором после его обучения в течение 50 эпох. Изображения начинаются как случайный шум и со временем все больше напоминают рукописные цифры.

Чтобы узнать больше о GAN, см. курс Массачусетского технологического института « Введение в глубокое обучение» .
Настраивать
import tensorflow as tf
tf.__version__
'2.8.0-rc1'
# To generate GIFspip install imageiopip install git+https://github.com/tensorflow/docs
import glob
import imageio
import matplotlib.pyplot as plt
import numpy as np
import os
import PIL
from tensorflow.keras import layers
import time
from IPython import display
Загрузите и подготовьте набор данных
Вы будете использовать набор данных MNIST для обучения генератора и дискриминатора. Генератор будет генерировать рукописные цифры, напоминающие данные MNIST.
(train_images, train_labels), (_, _) = tf.keras.datasets.mnist.load_data()
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1).astype('float32')
train_images = (train_images - 127.5) / 127.5 # Normalize the images to [-1, 1]
BUFFER_SIZE = 60000
BATCH_SIZE = 256
# Batch and shuffle the data
train_dataset = tf.data.Dataset.from_tensor_slices(train_images).shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
Создание моделей
И генератор, и дискриминатор определяются с помощью Keras Sequential API .
Генератор
Генератор использует tf.keras.layers.Conv2DTranspose (повышение дискретизации) для создания изображения из начального числа (случайный шум). Начните с Dense слоя, который принимает это начальное значение в качестве входных данных, а затем повышайте дискретизацию несколько раз, пока не достигнете желаемого размера изображения 28x28x1. Обратите внимание на активацию tf.keras.layers.LeakyReLU для каждого слоя, кроме выходного слоя, который использует tanh.
def make_generator_model():
model = tf.keras.Sequential()
model.add(layers.Dense(7*7*256, use_bias=False, input_shape=(100,)))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Reshape((7, 7, 256)))
assert model.output_shape == (None, 7, 7, 256) # Note: None is the batch size
model.add(layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias=False))
assert model.output_shape == (None, 7, 7, 128)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False))
assert model.output_shape == (None, 14, 14, 64)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh'))
assert model.output_shape == (None, 28, 28, 1)
return model
Используйте генератор (еще не обученный) для создания изображения.
generator = make_generator_model()
noise = tf.random.normal([1, 100])
generated_image = generator(noise, training=False)
plt.imshow(generated_image[0, :, :, 0], cmap='gray')
<matplotlib.image.AxesImage at 0x7f6fe7a04b90>

Дискриминатор
Дискриминатор представляет собой классификатор изображений на основе CNN.
def make_discriminator_model():
model = tf.keras.Sequential()
model.add(layers.Conv2D(64, (5, 5), strides=(2, 2), padding='same',
input_shape=[28, 28, 1]))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
model.add(layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same'))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
model.add(layers.Flatten())
model.add(layers.Dense(1))
return model
Используйте (еще не обученный) дискриминатор, чтобы классифицировать сгенерированные изображения как настоящие или поддельные. Модель будет обучена выводить положительные значения для реальных изображений и отрицательные значения для поддельных изображений.
discriminator = make_discriminator_model()
decision = discriminator(generated_image)
print (decision)
tf.Tensor([[-0.00339105]], shape=(1, 1), dtype=float32)
Определение потерь и оптимизаторов
Определите функции потерь и оптимизаторы для обеих моделей.
# This method returns a helper function to compute cross entropy loss
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)
Потеря дискриминатора
Этот метод количественно определяет, насколько хорошо дискриминатор способен отличать настоящие изображения от подделок. Он сравнивает предсказания дискриминатора для реальных изображений с массивом 1, а предсказания дискриминатора для поддельных (сгенерированных) изображений — с массивом 0.
def discriminator_loss(real_output, fake_output):
real_loss = cross_entropy(tf.ones_like(real_output), real_output)
fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output)
total_loss = real_loss + fake_loss
return total_loss
Потеря генератора
Потери генератора количественно определяют, насколько хорошо он смог обмануть дискриминатор. Интуитивно, если генератор работает хорошо, дискриминатор классифицирует поддельные изображения как настоящие (или 1). Здесь сравните решения дискриминаторов по сгенерированным изображениям с массивом из 1 с.
def generator_loss(fake_output):
return cross_entropy(tf.ones_like(fake_output), fake_output)
Оптимизаторы дискриминатора и генератора отличаются, поскольку вы будете обучать две сети по отдельности.
generator_optimizer = tf.keras.optimizers.Adam(1e-4)
discriminator_optimizer = tf.keras.optimizers.Adam(1e-4)
Сохранить контрольные точки
В этой записной книжке также показано, как сохранять и восстанавливать модели, что может быть полезно в случае прерывания длительной учебной задачи.
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(generator_optimizer=generator_optimizer,
discriminator_optimizer=discriminator_optimizer,
generator=generator,
discriminator=discriminator)
Определение цикла обучения
EPOCHS = 50
noise_dim = 100
num_examples_to_generate = 16
# You will reuse this seed overtime (so it's easier)
# to visualize progress in the animated GIF)
seed = tf.random.normal([num_examples_to_generate, noise_dim])
Цикл обучения начинается с того, что генератор получает на вход случайное начальное число. Это семя используется для создания изображения. Затем дискриминатор используется для классификации реальных изображений (извлеченных из обучающего набора) и поддельных изображений (созданных генератором). Потери рассчитываются для каждой из этих моделей, а градиенты используются для обновления генератора и дискриминатора.
# Notice the use of `tf.function`
# This annotation causes the function to be "compiled".
@tf.function
def train_step(images):
noise = tf.random.normal([BATCH_SIZE, noise_dim])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
generated_images = generator(noise, training=True)
real_output = discriminator(images, training=True)
fake_output = discriminator(generated_images, training=True)
gen_loss = generator_loss(fake_output)
disc_loss = discriminator_loss(real_output, fake_output)
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
def train(dataset, epochs):
for epoch in range(epochs):
start = time.time()
for image_batch in dataset:
train_step(image_batch)
# Produce images for the GIF as you go
display.clear_output(wait=True)
generate_and_save_images(generator,
epoch + 1,
seed)
# Save the model every 15 epochs
if (epoch + 1) % 15 == 0:
checkpoint.save(file_prefix = checkpoint_prefix)
print ('Time for epoch {} is {} sec'.format(epoch + 1, time.time()-start))
# Generate after the final epoch
display.clear_output(wait=True)
generate_and_save_images(generator,
epochs,
seed)
Создание и сохранение изображений
def generate_and_save_images(model, epoch, test_input):
# Notice `training` is set to False.
# This is so all layers run in inference mode (batchnorm).
predictions = model(test_input, training=False)
fig = plt.figure(figsize=(4, 4))
for i in range(predictions.shape[0]):
plt.subplot(4, 4, i+1)
plt.imshow(predictions[i, :, :, 0] * 127.5 + 127.5, cmap='gray')
plt.axis('off')
plt.savefig('image_at_epoch_{:04d}.png'.format(epoch))
plt.show()
Обучите модель
Вызовите метод train() , определенный выше, для одновременного обучения генератора и дискриминатора. Обратите внимание, обучение GAN может быть сложным. Важно, чтобы генератор и дискриминатор не подавляли друг друга (например, чтобы они обучались с одинаковой скоростью).
В начале обучения сгенерированные изображения выглядят как случайный шум. По мере обучения сгенерированные цифры будут выглядеть все более реальными. Примерно через 50 эпох они напоминают цифры MNIST. Это может занять около одной минуты/эпохи с настройками по умолчанию в Colab.
train(train_dataset, EPOCHS)

Восстановите последнюю контрольную точку.
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir))
<tensorflow.python.training.tracking.util.CheckpointLoadStatus at 0x7f6ee8136950>
Создать гифку
# Display a single image using the epoch number
def display_image(epoch_no):
return PIL.Image.open('image_at_epoch_{:04d}.png'.format(epoch_no))
display_image(EPOCHS)

Используйте imageio , чтобы создать анимированный gif, используя изображения, сохраненные во время обучения.
anim_file = 'dcgan.gif'
with imageio.get_writer(anim_file, mode='I') as writer:
filenames = glob.glob('image*.png')
filenames = sorted(filenames)
for filename in filenames:
image = imageio.imread(filename)
writer.append_data(image)
image = imageio.imread(filename)
writer.append_data(image)
import tensorflow_docs.vis.embed as embed
embed.embed_file(anim_file)

Следующие шаги
В этом руководстве показан полный код, необходимый для написания и обучения GAN. В качестве следующего шага вы можете поэкспериментировать с другим набором данных, например, с крупномасштабным набором данных атрибутов лиц знаменитостей (CelebA) , доступным на Kaggle . Чтобы узнать больше о GAN, см. Учебное пособие NIPS 2016: Генеративно-состязательные сети .