
| | |  Kaynağı GitHub'da görüntüleyin Kaynağı GitHub'da görüntüleyin | |
Bu öğretici, Isola ve diğerleri tarafından koşullu rakip ağlarla Görüntüden görüntüye çeviri bölümünde açıklandığı gibi, giriş görüntülerinden çıktı görüntülerine bir eşleme öğrenen pix2pix adlı koşullu bir üretici hasım ağının (cGAN) nasıl oluşturulacağını ve eğitileceğini gösterir. (2017). pix2pix uygulamaya özel değildir; etiket haritalarından fotoğrafları sentezlemek, siyah beyaz görüntülerden renkli fotoğraflar oluşturmak, Google Haritalar fotoğraflarını havadan görüntülere dönüştürmek ve hatta eskizleri fotoğraflara dönüştürmek gibi çok çeşitli görevlere uygulanabilir.
Bu örnekte, ağınız Prag'daki Çek Teknik Üniversitesi'ndeki Makine Algılama Merkezi tarafından sağlanan CMP Cephe Veritabanını kullanarak bina cephelerinin görüntülerini oluşturacaktır. Kısa tutmak için, pix2pix yazarları tarafından oluşturulan bu veri kümesinin önceden işlenmiş bir kopyasını kullanacaksınız.
pix2pix cGAN'da giriş görüntülerini koşullandırır ve karşılık gelen çıktı görüntülerini oluşturursunuz. cGAN'lar ilk olarak Koşullu Üretken Düşman Ağlarında önerildi (Mirza ve Osindero, 2014)
Ağınızın mimarisi şunları içerecektir:
- U-Net tabanlı mimariye sahip bir jeneratör.
- Evrişimli PatchGAN sınıflandırıcısı tarafından temsil edilen bir ayırıcı ( pix2pix makalesinde önerilmiştir).
Tek bir V100 GPU'da her dönemin yaklaşık 15 saniye sürebileceğini unutmayın.
Aşağıda, cepheler veri kümesinde (80k adım) 200 dönemlik eğitimden sonra pix2pix cGAN tarafından üretilen çıktının bazı örnekleri verilmiştir.


TensorFlow ve diğer kitaplıkları içe aktarın
import tensorflow as tf
import os
import pathlib
import time
import datetime
from matplotlib import pyplot as plt
from IPython import display
Veri kümesini yükleyin
CMP Cephe Veritabanı verilerini indirin (30MB). Ek veri kümeleri burada aynı biçimde mevcuttur. Colab'de açılır menüden diğer veri kümelerini seçebilirsiniz. Diğer veri kümelerinden bazılarının önemli ölçüde daha büyük olduğuna dikkat edin ( edges2handbags 8GB).
dataset_name = "facades"
_URL = f'http://efrosgans.eecs.berkeley.edu/pix2pix/datasets/{dataset_name}.tar.gz'
path_to_zip = tf.keras.utils.get_file(
fname=f"{dataset_name}.tar.gz",
origin=_URL,
extract=True)
path_to_zip = pathlib.Path(path_to_zip)
PATH = path_to_zip.parent/dataset_name
Downloading data from http://efrosgans.eecs.berkeley.edu/pix2pix/datasets/facades.tar.gz 30171136/30168306 [==============================] - 19s 1us/step 30179328/30168306 [==============================] - 19s 1us/step
list(PATH.parent.iterdir())
[PosixPath('/home/kbuilder/.keras/datasets/facades.tar.gz'),
PosixPath('/home/kbuilder/.keras/datasets/YellowLabradorLooking_new.jpg'),
PosixPath('/home/kbuilder/.keras/datasets/facades'),
PosixPath('/home/kbuilder/.keras/datasets/mnist.npz')]
Her orijinal görüntü, iki adet 256 x 256 görüntü içeren 256 x 512 boyutundadır:
sample_image = tf.io.read_file(str(PATH / 'train/1.jpg'))
sample_image = tf.io.decode_jpeg(sample_image)
print(sample_image.shape)
(256, 512, 3)yer tutucu8 l10n-yer
plt.figure()
plt.imshow(sample_image)
<matplotlib.image.AxesImage at 0x7f35a3653c90>
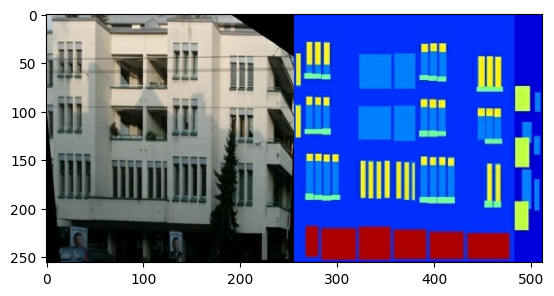
Gerçek bina cephe görüntülerini mimari etiket görüntülerinden ayırmanız gerekir; bunların tümü 256 x 256 boyutunda olacaktır.
Görüntü dosyalarını yükleyen ve iki görüntü tensörü çıkaran bir işlev tanımlayın:
def load(image_file):
# Read and decode an image file to a uint8 tensor
image = tf.io.read_file(image_file)
image = tf.io.decode_jpeg(image)
# Split each image tensor into two tensors:
# - one with a real building facade image
# - one with an architecture label image
w = tf.shape(image)[1]
w = w // 2
input_image = image[:, w:, :]
real_image = image[:, :w, :]
# Convert both images to float32 tensors
input_image = tf.cast(input_image, tf.float32)
real_image = tf.cast(real_image, tf.float32)
return input_image, real_image
Girdi (mimari etiket görüntüsü) ve gerçek (bina cephe fotoğrafı) görüntülerin bir örneğini çizin:
inp, re = load(str(PATH / 'train/100.jpg'))
# Casting to int for matplotlib to display the images
plt.figure()
plt.imshow(inp / 255.0)
plt.figure()
plt.imshow(re / 255.0)
<matplotlib.image.AxesImage at 0x7f35981a4910>
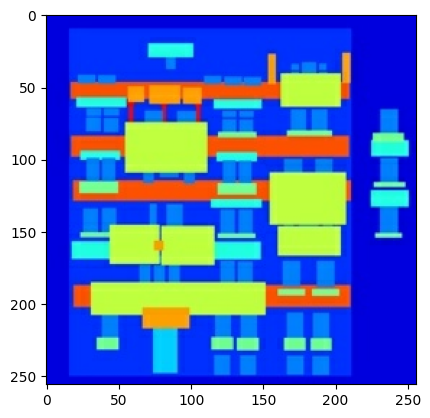
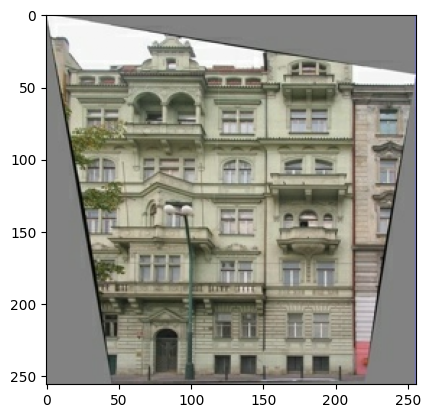
pix2pix makalesinde açıklandığı gibi, eğitim setini önceden işlemek için rastgele titreşim ve aynalama uygulamanız gerekir.
Aşağıdakileri sağlayan birkaç işlevi tanımlayın:
- Her
256 x 256görüntüyü daha büyük bir yükseklik ve genişlikte yeniden boyutlandırın -286 x 286. - Rastgele
256 x 256kırpın. - Görüntüyü rastgele yatay olarak, yani soldan sağa çevirin (rastgele yansıtma).
- Görüntüleri
[-1, 1]aralığına normalleştirin.
# The facade training set consist of 400 images
BUFFER_SIZE = 400
# The batch size of 1 produced better results for the U-Net in the original pix2pix experiment
BATCH_SIZE = 1
# Each image is 256x256 in size
IMG_WIDTH = 256
IMG_HEIGHT = 256
def resize(input_image, real_image, height, width):
input_image = tf.image.resize(input_image, [height, width],
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
real_image = tf.image.resize(real_image, [height, width],
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
return input_image, real_image
def random_crop(input_image, real_image):
stacked_image = tf.stack([input_image, real_image], axis=0)
cropped_image = tf.image.random_crop(
stacked_image, size=[2, IMG_HEIGHT, IMG_WIDTH, 3])
return cropped_image[0], cropped_image[1]
# Normalizing the images to [-1, 1]
def normalize(input_image, real_image):
input_image = (input_image / 127.5) - 1
real_image = (real_image / 127.5) - 1
return input_image, real_image
@tf.function()
def random_jitter(input_image, real_image):
# Resizing to 286x286
input_image, real_image = resize(input_image, real_image, 286, 286)
# Random cropping back to 256x256
input_image, real_image = random_crop(input_image, real_image)
if tf.random.uniform(()) > 0.5:
# Random mirroring
input_image = tf.image.flip_left_right(input_image)
real_image = tf.image.flip_left_right(real_image)
return input_image, real_image
Önceden işlenmiş çıktılardan bazılarını inceleyebilirsiniz:
plt.figure(figsize=(6, 6))
for i in range(4):
rj_inp, rj_re = random_jitter(inp, re)
plt.subplot(2, 2, i + 1)
plt.imshow(rj_inp / 255.0)
plt.axis('off')
plt.show()
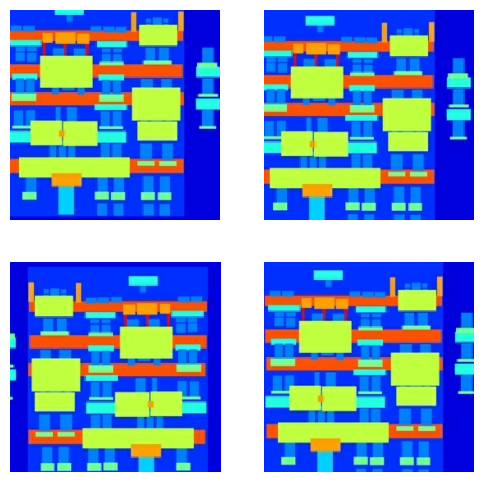
Yükleme ve ön işlemenin çalıştığını kontrol ettikten sonra, eğitim ve test setlerini yükleyen ve önişleyen birkaç yardımcı fonksiyon tanımlayalım:
def load_image_train(image_file):
input_image, real_image = load(image_file)
input_image, real_image = random_jitter(input_image, real_image)
input_image, real_image = normalize(input_image, real_image)
return input_image, real_image
def load_image_test(image_file):
input_image, real_image = load(image_file)
input_image, real_image = resize(input_image, real_image,
IMG_HEIGHT, IMG_WIDTH)
input_image, real_image = normalize(input_image, real_image)
return input_image, real_image
tf.data ile bir girdi ardışık düzeni oluşturun
train_dataset = tf.data.Dataset.list_files(str(PATH / 'train/*.jpg'))
train_dataset = train_dataset.map(load_image_train,
num_parallel_calls=tf.data.AUTOTUNE)
train_dataset = train_dataset.shuffle(BUFFER_SIZE)
train_dataset = train_dataset.batch(BATCH_SIZE)
try:
test_dataset = tf.data.Dataset.list_files(str(PATH / 'test/*.jpg'))
except tf.errors.InvalidArgumentError:
test_dataset = tf.data.Dataset.list_files(str(PATH / 'val/*.jpg'))
test_dataset = test_dataset.map(load_image_test)
test_dataset = test_dataset.batch(BATCH_SIZE)
Jeneratörü inşa et
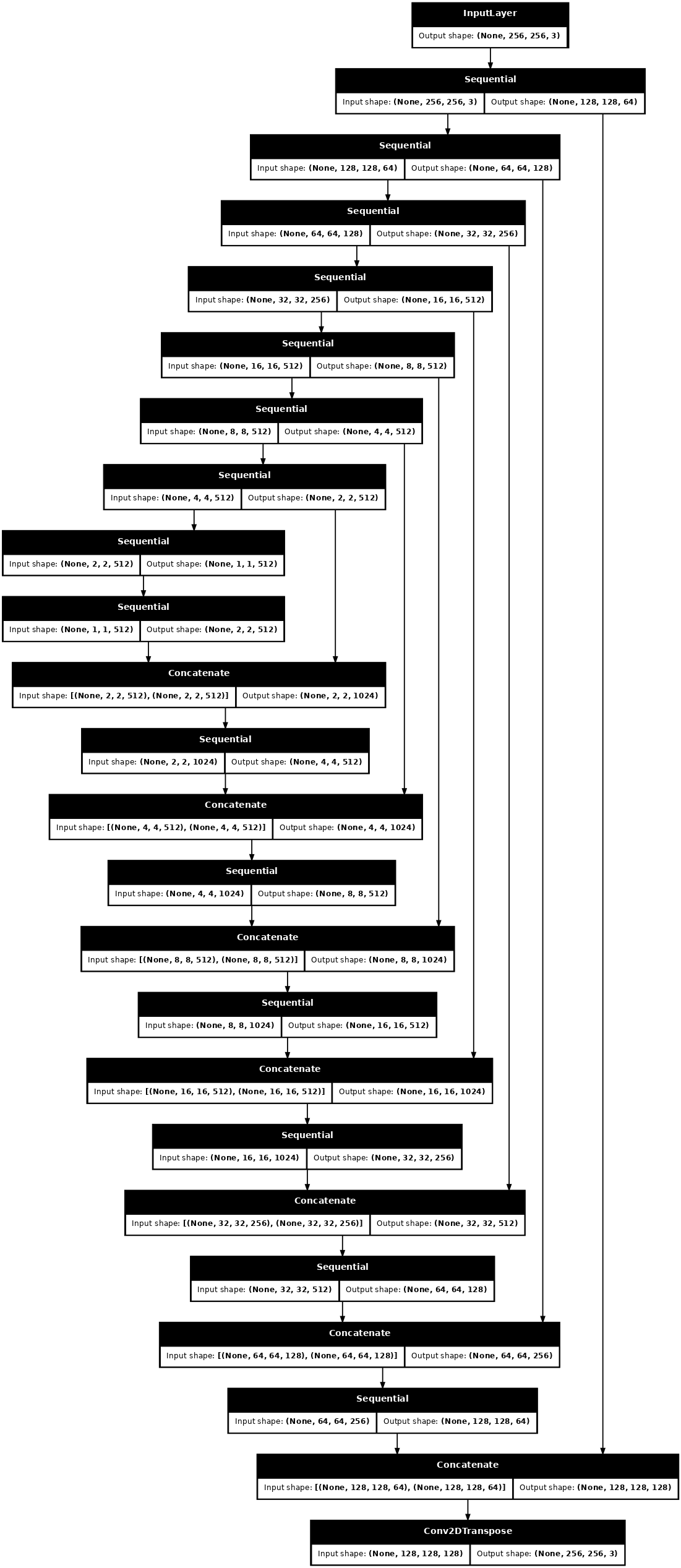
pix2pix cGAN'ınızın oluşturucusu değiştirilmiş bir U- Net'tir. Bir U-Net, bir kodlayıcı (alt örnekleyici) ve kod çözücüden (yukarı örnekleyici) oluşur. (Bununla ilgili daha fazla bilgiyi Görüntü segmentasyonu eğitiminde ve U-Net proje web sitesinde bulabilirsiniz .)
- Kodlayıcıdaki her blok: Evrişim -> Toplu normalleştirme -> Sızdıran ReLU
- Kod çözücüdeki her blok: Aktarılan evrişim -> Toplu normalleştirme -> Bırakma (ilk 3 bloğa uygulanır) -> ReLU
- Kodlayıcı ve kod çözücü arasında atlama bağlantıları vardır (U-Net'te olduğu gibi).
Altörnekleyiciyi (kodlayıcı) tanımlayın:
OUTPUT_CHANNELS = 3
def downsample(filters, size, apply_batchnorm=True):
initializer = tf.random_normal_initializer(0., 0.02)
result = tf.keras.Sequential()
result.add(
tf.keras.layers.Conv2D(filters, size, strides=2, padding='same',
kernel_initializer=initializer, use_bias=False))
if apply_batchnorm:
result.add(tf.keras.layers.BatchNormalization())
result.add(tf.keras.layers.LeakyReLU())
return result
down_model = downsample(3, 4)
down_result = down_model(tf.expand_dims(inp, 0))
print (down_result.shape)
(1, 128, 128, 3)
Üst örnekleyiciyi (kod çözücü) tanımlayın:
def upsample(filters, size, apply_dropout=False):
initializer = tf.random_normal_initializer(0., 0.02)
result = tf.keras.Sequential()
result.add(
tf.keras.layers.Conv2DTranspose(filters, size, strides=2,
padding='same',
kernel_initializer=initializer,
use_bias=False))
result.add(tf.keras.layers.BatchNormalization())
if apply_dropout:
result.add(tf.keras.layers.Dropout(0.5))
result.add(tf.keras.layers.ReLU())
return result
up_model = upsample(3, 4)
up_result = up_model(down_result)
print (up_result.shape)
(1, 256, 256, 3)
Altörnekleyici ve üstörnekleyici ile jeneratörü tanımlayın:
def Generator():
inputs = tf.keras.layers.Input(shape=[256, 256, 3])
down_stack = [
downsample(64, 4, apply_batchnorm=False), # (batch_size, 128, 128, 64)
downsample(128, 4), # (batch_size, 64, 64, 128)
downsample(256, 4), # (batch_size, 32, 32, 256)
downsample(512, 4), # (batch_size, 16, 16, 512)
downsample(512, 4), # (batch_size, 8, 8, 512)
downsample(512, 4), # (batch_size, 4, 4, 512)
downsample(512, 4), # (batch_size, 2, 2, 512)
downsample(512, 4), # (batch_size, 1, 1, 512)
]
up_stack = [
upsample(512, 4, apply_dropout=True), # (batch_size, 2, 2, 1024)
upsample(512, 4, apply_dropout=True), # (batch_size, 4, 4, 1024)
upsample(512, 4, apply_dropout=True), # (batch_size, 8, 8, 1024)
upsample(512, 4), # (batch_size, 16, 16, 1024)
upsample(256, 4), # (batch_size, 32, 32, 512)
upsample(128, 4), # (batch_size, 64, 64, 256)
upsample(64, 4), # (batch_size, 128, 128, 128)
]
initializer = tf.random_normal_initializer(0., 0.02)
last = tf.keras.layers.Conv2DTranspose(OUTPUT_CHANNELS, 4,
strides=2,
padding='same',
kernel_initializer=initializer,
activation='tanh') # (batch_size, 256, 256, 3)
x = inputs
# Downsampling through the model
skips = []
for down in down_stack:
x = down(x)
skips.append(x)
skips = reversed(skips[:-1])
# Upsampling and establishing the skip connections
for up, skip in zip(up_stack, skips):
x = up(x)
x = tf.keras.layers.Concatenate()([x, skip])
x = last(x)
return tf.keras.Model(inputs=inputs, outputs=x)
Jeneratör modeli mimarisini görselleştirin:
generator = Generator()
tf.keras.utils.plot_model(generator, show_shapes=True, dpi=64)
Jeneratörü test edin:
gen_output = generator(inp[tf.newaxis, ...], training=False)
plt.imshow(gen_output[0, ...])
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). <matplotlib.image.AxesImage at 0x7f35cfd20610>
Jeneratör kaybını tanımlayın
GAN'lar verilere uyum sağlayan bir kayıp öğrenirken cGAN'lar, pix2pix belgesinde açıklandığı gibi ağ çıkışından ve hedef görüntüden farklı olası bir yapıyı cezalandıran yapılandırılmış bir kaybı öğrenir.
- Jeneratör kaybı, oluşturulan görüntülerin ve bir dizi birin sigmoid çapraz entropi kaybıdır.
- Pix2pix belgesi ayrıca, oluşturulan görüntü ile hedef görüntü arasında bir MAE (ortalama mutlak hata) olan L1 kaybından da bahseder.
- Bu, oluşturulan görüntünün hedef görüntüye yapısal olarak benzer hale gelmesini sağlar.
- Toplam jeneratör kaybını hesaplama formülü
gan_loss + LAMBDA * l1_loss, buradaLAMBDA = 100. Bu değere makalenin yazarları karar vermiştir.
LAMBDA = 100
loss_object = tf.keras.losses.BinaryCrossentropy(from_logits=True)
def generator_loss(disc_generated_output, gen_output, target):
gan_loss = loss_object(tf.ones_like(disc_generated_output), disc_generated_output)
# Mean absolute error
l1_loss = tf.reduce_mean(tf.abs(target - gen_output))
total_gen_loss = gan_loss + (LAMBDA * l1_loss)
return total_gen_loss, gan_loss, l1_loss
Jeneratör için eğitim prosedürü aşağıdaki gibidir:

Ayrımcıyı oluşturun
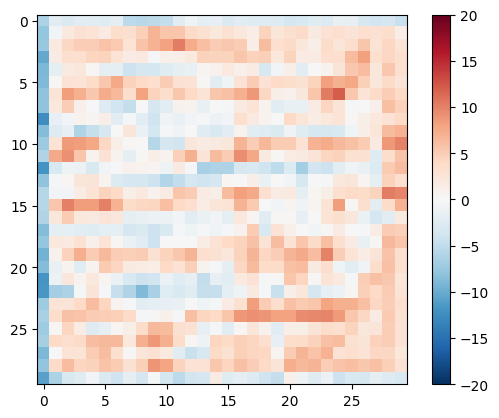
pix2pix cGAN'deki ayrımcı, evrişimli bir PatchGAN sınıflandırıcıdır; pix2pix belgesinde açıklandığı gibi her bir görüntü yamasının gerçek olup olmadığını sınıflandırmaya çalışır.
- Ayırıcıdaki her blok: Evrişim -> Toplu normalleştirme -> Sızdıran ReLU.
- Son katmandan sonraki çıktının şekli
(batch_size, 30, 30, 1). - Çıktının her
30 x 30görüntü yaması, giriş görüntüsünün70 x 70bir bölümünü sınıflandırır. - Ayırıcı 2 girdi alır:
- Gerçek olarak sınıflandırması gereken giriş görüntüsü ve hedef görüntü.
- Sahte olarak sınıflandırması gereken giriş görüntüsü ve oluşturulan görüntü (jeneratörün çıkışı).
- Bu 2 girişi birleştirmek için
tf.concat([inp, tar], axis=-1)kullanın.
Ayırıcıyı tanımlayalım:
def Discriminator():
initializer = tf.random_normal_initializer(0., 0.02)
inp = tf.keras.layers.Input(shape=[256, 256, 3], name='input_image')
tar = tf.keras.layers.Input(shape=[256, 256, 3], name='target_image')
x = tf.keras.layers.concatenate([inp, tar]) # (batch_size, 256, 256, channels*2)
down1 = downsample(64, 4, False)(x) # (batch_size, 128, 128, 64)
down2 = downsample(128, 4)(down1) # (batch_size, 64, 64, 128)
down3 = downsample(256, 4)(down2) # (batch_size, 32, 32, 256)
zero_pad1 = tf.keras.layers.ZeroPadding2D()(down3) # (batch_size, 34, 34, 256)
conv = tf.keras.layers.Conv2D(512, 4, strides=1,
kernel_initializer=initializer,
use_bias=False)(zero_pad1) # (batch_size, 31, 31, 512)
batchnorm1 = tf.keras.layers.BatchNormalization()(conv)
leaky_relu = tf.keras.layers.LeakyReLU()(batchnorm1)
zero_pad2 = tf.keras.layers.ZeroPadding2D()(leaky_relu) # (batch_size, 33, 33, 512)
last = tf.keras.layers.Conv2D(1, 4, strides=1,
kernel_initializer=initializer)(zero_pad2) # (batch_size, 30, 30, 1)
return tf.keras.Model(inputs=[inp, tar], outputs=last)
Ayrımcı model mimarisini görselleştirin:
discriminator = Discriminator()
tf.keras.utils.plot_model(discriminator, show_shapes=True, dpi=64)

Ayırt ediciyi test edin:
disc_out = discriminator([inp[tf.newaxis, ...], gen_output], training=False)
plt.imshow(disc_out[0, ..., -1], vmin=-20, vmax=20, cmap='RdBu_r')
plt.colorbar()
<matplotlib.colorbar.Colorbar at 0x7f35cec82c50>
Diskriminatör kaybını tanımlayın
-
discriminator_lossişlevi 2 girdi alır: gerçek görüntüler ve oluşturulan görüntüler . -
real_loss, gerçek görüntülerin ve bir dizi olanın sigmoid çapraz entropi kaybıdır (çünkü bunlar gerçek görüntülerdir) . -
generated_loss, oluşturulan görüntülerin ve bir dizi sıfırın sigmoid çapraz entropi kaybıdır (çünkü bunlar sahte görüntülerdir) . -
total_loss,real_lossgenerated_loss.
def discriminator_loss(disc_real_output, disc_generated_output):
real_loss = loss_object(tf.ones_like(disc_real_output), disc_real_output)
generated_loss = loss_object(tf.zeros_like(disc_generated_output), disc_generated_output)
total_disc_loss = real_loss + generated_loss
return total_disc_loss
Ayrımcı için eğitim prosedürü aşağıda gösterilmiştir.
Mimari ve hiperparametreler hakkında daha fazla bilgi edinmek için pix2pix belgesine başvurabilirsiniz.

Optimize edicileri ve bir kontrol noktası koruyucuyu tanımlayın
generator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(generator_optimizer=generator_optimizer,
discriminator_optimizer=discriminator_optimizer,
generator=generator,
discriminator=discriminator)
Görüntü oluştur
Eğitim sırasında bazı görüntüleri çizmek için bir fonksiyon yazın.
- Test setinden görüntüleri jeneratöre iletin.
- Jeneratör daha sonra giriş görüntüsünü çıkışa çevirecektir.
- Son adım, tahminleri planlamak ve işte !
def generate_images(model, test_input, tar):
prediction = model(test_input, training=True)
plt.figure(figsize=(15, 15))
display_list = [test_input[0], tar[0], prediction[0]]
title = ['Input Image', 'Ground Truth', 'Predicted Image']
for i in range(3):
plt.subplot(1, 3, i+1)
plt.title(title[i])
# Getting the pixel values in the [0, 1] range to plot.
plt.imshow(display_list[i] * 0.5 + 0.5)
plt.axis('off')
plt.show()
İşlevi test edin:
for example_input, example_target in test_dataset.take(1):
generate_images(generator, example_input, example_target)

Eğitim
- Her örnek için girdi bir çıktı üretir.
- Ayırıcı,
input_imageve oluşturulan görüntüyü ilk girdi olarak alır. İkinci girdiinput_imagevetarget_image. - Ardından, üreteci ve diskriminatör kaybını hesaplayın.
- Ardından, hem oluşturucu hem de ayırıcı değişkenlere (girdiler) göre kayıp gradyanlarını hesaplayın ve bunları optimize ediciye uygulayın.
- Son olarak, kayıpları TensorBoard'a kaydedin.
log_dir="logs/"
summary_writer = tf.summary.create_file_writer(
log_dir + "fit/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
@tf.function
def train_step(input_image, target, step):
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
gen_output = generator(input_image, training=True)
disc_real_output = discriminator([input_image, target], training=True)
disc_generated_output = discriminator([input_image, gen_output], training=True)
gen_total_loss, gen_gan_loss, gen_l1_loss = generator_loss(disc_generated_output, gen_output, target)
disc_loss = discriminator_loss(disc_real_output, disc_generated_output)
generator_gradients = gen_tape.gradient(gen_total_loss,
generator.trainable_variables)
discriminator_gradients = disc_tape.gradient(disc_loss,
discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(generator_gradients,
generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(discriminator_gradients,
discriminator.trainable_variables))
with summary_writer.as_default():
tf.summary.scalar('gen_total_loss', gen_total_loss, step=step//1000)
tf.summary.scalar('gen_gan_loss', gen_gan_loss, step=step//1000)
tf.summary.scalar('gen_l1_loss', gen_l1_loss, step=step//1000)
tf.summary.scalar('disc_loss', disc_loss, step=step//1000)
Gerçek eğitim döngüsü. Bu öğretici birden fazla veri kümesini çalıştırabileceğinden ve veri kümelerinin boyutu büyük ölçüde değişiklik gösterdiğinden, eğitim döngüsü dönemler yerine adım adım çalışacak şekilde ayarlanmıştır.
- Adım sayısı üzerinden yinelenir.
- Her 10 adımda bir nokta (
.) yazdırın. - Her 1k adımda: ekranı temizleyin ve ilerlemeyi göstermek için
generate_imageskomutunu çalıştırın. - Her 5 bin adımda bir: bir kontrol noktası kaydedin.
def fit(train_ds, test_ds, steps):
example_input, example_target = next(iter(test_ds.take(1)))
start = time.time()
for step, (input_image, target) in train_ds.repeat().take(steps).enumerate():
if (step) % 1000 == 0:
display.clear_output(wait=True)
if step != 0:
print(f'Time taken for 1000 steps: {time.time()-start:.2f} sec\n')
start = time.time()
generate_images(generator, example_input, example_target)
print(f"Step: {step//1000}k")
train_step(input_image, target, step)
# Training step
if (step+1) % 10 == 0:
print('.', end='', flush=True)
# Save (checkpoint) the model every 5k steps
if (step + 1) % 5000 == 0:
checkpoint.save(file_prefix=checkpoint_prefix)
Bu eğitim döngüsü, eğitim ilerlemesini izlemek için TensorBoard'da görüntüleyebileceğiniz günlükleri kaydeder.
Yerel bir makinede çalışıyorsanız, ayrı bir TensorBoard işlemi başlatırsınız. Bir dizüstü bilgisayarda çalışırken, TensorBoard ile izleme eğitimine başlamadan önce görüntüleyiciyi başlatın.
Görüntüleyiciyi başlatmak için aşağıdakileri bir kod hücresine yapıştırın:
%load_ext tensorboard
%tensorboard --logdir {log_dir}
Son olarak, eğitim döngüsünü çalıştırın:
fit(train_dataset, test_dataset, steps=40000)
Time taken for 1000 steps: 36.53 sec

Step: 39k ....................................................................................................
TensorBoard sonuçlarını herkese açık olarak paylaşmak istiyorsanız, aşağıdakileri bir kod hücresine kopyalayarak günlükleri TensorBoard.dev'e yükleyebilirsiniz.
tensorboard dev upload --logdir {log_dir}
Bu not defterinin önceki bir çalışmasının sonuçlarını TensorBoard.dev'de görüntüleyebilirsiniz .
TensorBoard.dev, makine öğrenimi deneylerini herkesle barındırmak, izlemek ve paylaşmak için yönetilen bir deneyimdir.
Ayrıca bir <iframe> kullanarak satır içi olarak da dahil edilebilir:
display.IFrame(
src="https://tensorboard.dev/experiment/lZ0C6FONROaUMfjYkVyJqw",
width="100%",
height="1000px")
Günlükleri yorumlamak, basit bir sınıflandırma veya regresyon modeline kıyasla bir GAN'ı (veya pix2pix benzeri bir cGAN'ı) eğitirken daha inceliklidir. Aranacak şeyler:
- Ne jeneratörün ne de ayrımcı modelin "kazanmadığını" kontrol edin.
gen_gan_lossveyadisc_lossçok düşerse, bu modelin diğerine hakim olduğunun ve birleşik modeli başarılı bir şekilde eğitemediğinizin bir göstergesidir. -
log(2) = 0.69değeri, bu kayıplar için iyi bir referans noktasıdır, çünkü 2'lik bir karışıklığı gösterir - ayırıcı, ortalama olarak, iki seçenek hakkında eşit derecede belirsizdir. -
0.69için,disc_lossaltındaki bir değer, ayırıcının gerçek ve oluşturulan görüntülerin birleştirilmiş kümesinde rastgeleden daha iyi performans gösterdiği anlamına gelir. - gen_gan_loss için
gen_gan_lossaltındaki bir değer, üretecin0.69kandırmada rastgele olmaktan daha iyi olduğu anlamına gelir. - Eğitim ilerledikçe,
gen_l1_loss.
En son kontrol noktasını geri yükleyin ve ağı test edin
ls {checkpoint_dir}
checkpoint ckpt-5.data-00000-of-00001 ckpt-1.data-00000-of-00001 ckpt-5.index ckpt-1.index ckpt-6.data-00000-of-00001 ckpt-2.data-00000-of-00001 ckpt-6.index ckpt-2.index ckpt-7.data-00000-of-00001 ckpt-3.data-00000-of-00001 ckpt-7.index ckpt-3.index ckpt-8.data-00000-of-00001 ckpt-4.data-00000-of-00001 ckpt-8.index ckpt-4.indexyer tutucu57 l10n-yer
# Restoring the latest checkpoint in checkpoint_dir
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir))
<tensorflow.python.training.tracking.util.CheckpointLoadStatus at 0x7f35cfd6b8d0>
Test setini kullanarak bazı görüntüler oluşturun
# Run the trained model on a few examples from the test set
for inp, tar in test_dataset.take(5):
generate_images(generator, inp, tar)




