
| | |  Xem nguồn trên GitHub Xem nguồn trên GitHub | |
Hướng dẫn này trình bày việc đào tạo Mạng nơron hợp hiến (CNN) đơn giản để phân loại hình ảnh CIFAR . Vì hướng dẫn này sử dụng Keras Sequential API , nên việc tạo và đào tạo mô hình của bạn sẽ chỉ mất một vài dòng mã.
Nhập TensorFlow
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
Tải xuống và chuẩn bị tập dữ liệu CIFAR10
Bộ dữ liệu CIFAR10 chứa 60.000 hình ảnh màu trong 10 lớp, với 6.000 hình ảnh trong mỗi lớp. Bộ dữ liệu được chia thành 50.000 hình ảnh đào tạo và 10.000 hình ảnh thử nghiệm. Các lớp loại trừ lẫn nhau và không có sự chồng chéo giữa chúng.
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
# Normalize pixel values to be between 0 and 1
train_images, test_images = train_images / 255.0, test_images / 255.0
Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz 170500096/170498071 [==============================] - 11s 0us/step 170508288/170498071 [==============================] - 11s 0us/step
Xác minh dữ liệu
Để xác minh rằng tập dữ liệu có đúng không, hãy vẽ biểu đồ 25 hình ảnh đầu tiên từ tập hợp đào tạo và hiển thị tên lớp bên dưới mỗi hình ảnh:
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i])
# The CIFAR labels happen to be arrays,
# which is why you need the extra index
plt.xlabel(class_names[train_labels[i][0]])
plt.show()

Tạo cơ sở phức hợp
6 dòng mã bên dưới xác định cơ sở tích chập bằng cách sử dụng một mẫu chung: chồng các lớp Conv2D và MaxPooling2D .
Khi đầu vào, một CNN có hàng chục hình dạng (chiều cao hình ảnh, chiều rộng hình ảnh, kênh màu), bỏ qua kích thước lô. Nếu bạn chưa quen với các thứ nguyên này, color_channels đề cập đến (R, G, B). Trong ví dụ này, bạn sẽ định cấu hình CNN của mình để xử lý đầu vào của hình dạng (32, 32, 3), là định dạng của hình ảnh CIFAR. Bạn có thể thực hiện việc này bằng cách chuyển đối số input_shape vào lớp đầu tiên của mình.
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
Hãy hiển thị kiến trúc của mô hình của bạn cho đến nay:
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 30, 30, 32) 896
max_pooling2d (MaxPooling2D (None, 15, 15, 32) 0
)
conv2d_1 (Conv2D) (None, 13, 13, 64) 18496
max_pooling2d_1 (MaxPooling (None, 6, 6, 64) 0
2D)
conv2d_2 (Conv2D) (None, 4, 4, 64) 36928
=================================================================
Total params: 56,320
Trainable params: 56,320
Non-trainable params: 0
_________________________________________________________________
Ở trên, bạn có thể thấy rằng đầu ra của mọi lớp Conv2D và MaxPooling2D là một hình dạng 3D (chiều cao, chiều rộng, kênh). Kích thước chiều rộng và chiều cao có xu hướng thu hẹp khi bạn đi sâu hơn vào mạng. Số lượng kênh đầu ra cho mỗi lớp Conv2D được điều khiển bởi đối số đầu tiên (ví dụ: 32 hoặc 64). Thông thường, khi chiều rộng và chiều cao thu hẹp lại, bạn có thể đủ khả năng (về mặt tính toán) để thêm nhiều kênh đầu ra hơn trong mỗi lớp Conv2D.
Thêm các lớp dày đặc lên trên
Để hoàn thành mô hình, bạn sẽ cấp tensor đầu ra cuối cùng từ cơ sở tích chập (có hình dạng (4, 4, 64)) thành một hoặc nhiều lớp dày đặc để thực hiện phân loại. Các lớp dày đặc lấy vectơ làm đầu vào (là 1D), trong khi đầu ra hiện tại là tensor 3D. Đầu tiên, bạn sẽ làm phẳng (hoặc mở cuộn) đầu ra 3D thành 1D, sau đó thêm một hoặc nhiều lớp dày đặc lên trên. CIFAR có 10 lớp đầu ra, vì vậy bạn sử dụng lớp Dày cuối cùng với 10 đầu ra.
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10))
Đây là kiến trúc hoàn chỉnh của mô hình của bạn:
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 30, 30, 32) 896
max_pooling2d (MaxPooling2D (None, 15, 15, 32) 0
)
conv2d_1 (Conv2D) (None, 13, 13, 64) 18496
max_pooling2d_1 (MaxPooling (None, 6, 6, 64) 0
2D)
conv2d_2 (Conv2D) (None, 4, 4, 64) 36928
flatten (Flatten) (None, 1024) 0
dense (Dense) (None, 64) 65600
dense_1 (Dense) (None, 10) 650
=================================================================
Total params: 122,570
Trainable params: 122,570
Non-trainable params: 0
_________________________________________________________________
Tóm tắt mạng cho thấy rằng (4, 4, 64) đầu ra đã được làm phẳng thành các vectơ có hình dạng (1024) trước khi đi qua hai lớp dày đặc.
Biên dịch và đào tạo mô hình
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
history = model.fit(train_images, train_labels, epochs=10,
validation_data=(test_images, test_labels))
Epoch 1/10 1563/1563 [==============================] - 8s 4ms/step - loss: 1.4971 - accuracy: 0.4553 - val_loss: 1.2659 - val_accuracy: 0.5492 Epoch 2/10 1563/1563 [==============================] - 6s 4ms/step - loss: 1.1424 - accuracy: 0.5966 - val_loss: 1.1025 - val_accuracy: 0.6098 Epoch 3/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.9885 - accuracy: 0.6539 - val_loss: 0.9557 - val_accuracy: 0.6629 Epoch 4/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.8932 - accuracy: 0.6878 - val_loss: 0.8924 - val_accuracy: 0.6935 Epoch 5/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.8222 - accuracy: 0.7130 - val_loss: 0.8679 - val_accuracy: 0.7025 Epoch 6/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.7663 - accuracy: 0.7323 - val_loss: 0.9336 - val_accuracy: 0.6819 Epoch 7/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.7224 - accuracy: 0.7466 - val_loss: 0.8546 - val_accuracy: 0.7086 Epoch 8/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.6726 - accuracy: 0.7611 - val_loss: 0.8777 - val_accuracy: 0.7068 Epoch 9/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.6372 - accuracy: 0.7760 - val_loss: 0.8410 - val_accuracy: 0.7179 Epoch 10/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.6024 - accuracy: 0.7875 - val_loss: 0.8475 - val_accuracy: 0.7192
Đánh giá mô hình
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0.5, 1])
plt.legend(loc='lower right')
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
313/313 - 1s - loss: 0.8475 - accuracy: 0.7192 - 634ms/epoch - 2ms/step
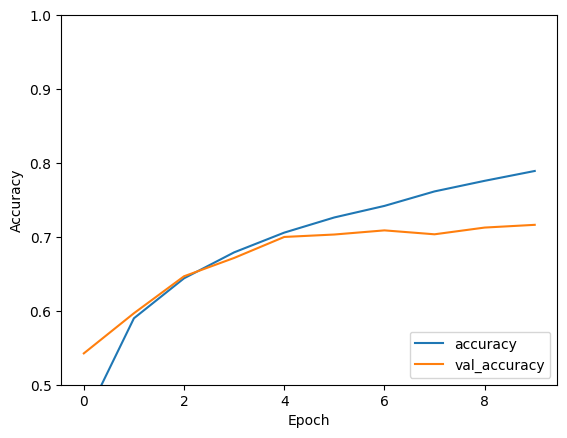
print(test_acc)
0.7192000150680542
CNN đơn giản của bạn đã đạt được độ chính xác trong bài kiểm tra hơn 70%. Không tệ cho một vài dòng mã! Đối với một phong cách CNN khác, hãy xem phần khởi động nhanh TensorFlow 2 để biết ví dụ về các chuyên gia sử dụng API phân lớp Keras và tf.GradientTape .