
| | |  GitHub पर स्रोत देखें GitHub पर स्रोत देखें | |
यह ट्यूटोरियल CIFAR छवियों को वर्गीकृत करने के लिए एक सरल कन्वेन्शनल न्यूरल नेटवर्क (CNN) के प्रशिक्षण को प्रदर्शित करता है। चूंकि यह ट्यूटोरियल केरस अनुक्रमिक एपीआई का उपयोग करता है, इसलिए आपके मॉडल को बनाने और प्रशिक्षण देने के लिए कोड की कुछ ही पंक्तियां होंगी।
टेंसरफ्लो आयात करें
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
डाउनलोड करें और CIFAR10 डेटासेट तैयार करें
CIFAR10 डेटासेट में प्रत्येक वर्ग में 6,000 छवियों के साथ 10 वर्गों में 60,000 रंगीन चित्र हैं। डेटासेट को 50,000 प्रशिक्षण छवियों और 10,000 परीक्षण छवियों में विभाजित किया गया है। वर्ग परस्पर अनन्य हैं और उनके बीच कोई अतिव्यापन नहीं है।
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
# Normalize pixel values to be between 0 and 1
train_images, test_images = train_images / 255.0, test_images / 255.0
Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz 170500096/170498071 [==============================] - 11s 0us/step 170508288/170498071 [==============================] - 11s 0us/step
डेटा सत्यापित करें
यह सत्यापित करने के लिए कि डेटासेट सही दिखता है, आइए प्रशिक्षण सेट से पहली 25 छवियों को प्लॉट करें और प्रत्येक छवि के नीचे वर्ग का नाम प्रदर्शित करें:
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i])
# The CIFAR labels happen to be arrays,
# which is why you need the extra index
plt.xlabel(class_names[train_labels[i][0]])
plt.show()

दृढ़ आधार बनाएं
नीचे दी गई कोड की 6 पंक्तियाँ एक सामान्य पैटर्न का उपयोग करके दृढ़ आधार को परिभाषित करती हैं: Conv2D और MaxPooling2D परतों का एक ढेर।
इनपुट के रूप में, एक सीएनएन बैच आकार को अनदेखा करते हुए आकार के दसियों (image_height, image_width, color_channels) लेता है। यदि आप इन आयामों के लिए नए हैं, तो color_channels (R,G,B) को संदर्भित करता है। इस उदाहरण में, आप अपने सीएनएन को आकार के इनपुट (32, 32, 3) को संसाधित करने के लिए कॉन्फ़िगर करेंगे, जो कि सीआईएफएआर छवियों का प्रारूप है। आप अपनी पहली परत पर तर्क input_shape पास करके ऐसा कर सकते हैं।
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
आइए अब तक आपके मॉडल की वास्तुकला प्रदर्शित करें:
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 30, 30, 32) 896
max_pooling2d (MaxPooling2D (None, 15, 15, 32) 0
)
conv2d_1 (Conv2D) (None, 13, 13, 64) 18496
max_pooling2d_1 (MaxPooling (None, 6, 6, 64) 0
2D)
conv2d_2 (Conv2D) (None, 4, 4, 64) 36928
=================================================================
Total params: 56,320
Trainable params: 56,320
Non-trainable params: 0
_________________________________________________________________
ऊपर, आप देख सकते हैं कि प्रत्येक Conv2D और MaxPooling2D परत का आउटपुट आकार का एक 3D टेंसर (ऊंचाई, चौड़ाई, चैनल) है। जैसे-जैसे आप नेटवर्क में गहराई तक जाते हैं, चौड़ाई और ऊंचाई के आयाम सिकुड़ते जाते हैं। प्रत्येक Conv2D परत के लिए आउटपुट चैनलों की संख्या पहले तर्क (जैसे, 32 या 64) द्वारा नियंत्रित होती है। आमतौर पर, जैसे-जैसे चौड़ाई और ऊंचाई घटती जाती है, आप प्रत्येक Conv2D परत में अधिक आउटपुट चैनल जोड़ने के लिए (कम्प्यूटेशनल रूप से) खर्च कर सकते हैं।
ऊपर से घनी परतें जोड़ें
मॉडल को पूरा करने के लिए, आप अंतिम आउटपुट टेंसर को कन्वेन्शनल बेस (आकार (4, 4, 64)) से वर्गीकरण करने के लिए एक या अधिक घने परतों में फीड करेंगे। घनी परतें वैक्टर को इनपुट के रूप में लेती हैं (जो कि 1D हैं), जबकि वर्तमान आउटपुट एक 3D टेंसर है। सबसे पहले, आप 3D आउटपुट को 1D में समतल (या अनियंत्रित) करेंगे, फिर शीर्ष पर एक या अधिक सघन परतें जोड़ेंगे। CIFAR में 10 आउटपुट क्लास हैं, इसलिए आप 10 आउटपुट के साथ एक अंतिम Dense लेयर का उपयोग करते हैं।
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10))
यहां आपके मॉडल का पूरा आर्किटेक्चर है:
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 30, 30, 32) 896
max_pooling2d (MaxPooling2D (None, 15, 15, 32) 0
)
conv2d_1 (Conv2D) (None, 13, 13, 64) 18496
max_pooling2d_1 (MaxPooling (None, 6, 6, 64) 0
2D)
conv2d_2 (Conv2D) (None, 4, 4, 64) 36928
flatten (Flatten) (None, 1024) 0
dense (Dense) (None, 64) 65600
dense_1 (Dense) (None, 10) 650
=================================================================
Total params: 122,570
Trainable params: 122,570
Non-trainable params: 0
_________________________________________________________________
नेटवर्क सारांश से पता चलता है कि (4, 4, 64) आउटपुट दो घने परतों से गुजरने से पहले आकार के वैक्टर (1024) में चपटे थे।
मॉडल को संकलित और प्रशिक्षित करें
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
history = model.fit(train_images, train_labels, epochs=10,
validation_data=(test_images, test_labels))
Epoch 1/10 1563/1563 [==============================] - 8s 4ms/step - loss: 1.4971 - accuracy: 0.4553 - val_loss: 1.2659 - val_accuracy: 0.5492 Epoch 2/10 1563/1563 [==============================] - 6s 4ms/step - loss: 1.1424 - accuracy: 0.5966 - val_loss: 1.1025 - val_accuracy: 0.6098 Epoch 3/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.9885 - accuracy: 0.6539 - val_loss: 0.9557 - val_accuracy: 0.6629 Epoch 4/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.8932 - accuracy: 0.6878 - val_loss: 0.8924 - val_accuracy: 0.6935 Epoch 5/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.8222 - accuracy: 0.7130 - val_loss: 0.8679 - val_accuracy: 0.7025 Epoch 6/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.7663 - accuracy: 0.7323 - val_loss: 0.9336 - val_accuracy: 0.6819 Epoch 7/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.7224 - accuracy: 0.7466 - val_loss: 0.8546 - val_accuracy: 0.7086 Epoch 8/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.6726 - accuracy: 0.7611 - val_loss: 0.8777 - val_accuracy: 0.7068 Epoch 9/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.6372 - accuracy: 0.7760 - val_loss: 0.8410 - val_accuracy: 0.7179 Epoch 10/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.6024 - accuracy: 0.7875 - val_loss: 0.8475 - val_accuracy: 0.7192
मॉडल का मूल्यांकन करें
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0.5, 1])
plt.legend(loc='lower right')
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
313/313 - 1s - loss: 0.8475 - accuracy: 0.7192 - 634ms/epoch - 2ms/step
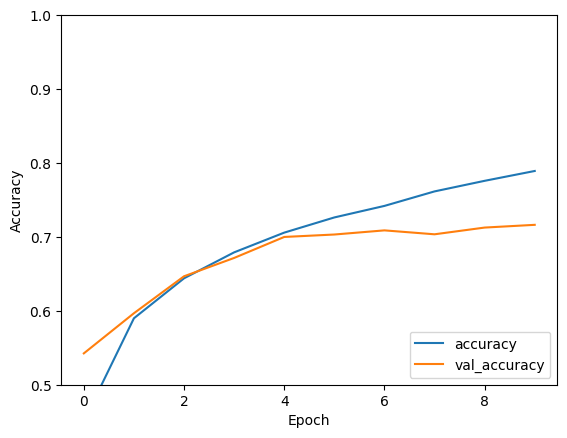
print(test_acc)
0.7192000150680542
आपके साधारण सीएनएन ने 70% से अधिक की परीक्षण सटीकता हासिल की है। कोड की कुछ पंक्तियों के लिए बुरा नहीं है! एक अन्य CNN शैली के लिए, विशेषज्ञ उदाहरण के लिए TensorFlow 2 क्विकस्टार्ट देखें जो Keras सबक्लासिंग API और tf.GradientTape का उपयोग करता है।