
| | |  Wyświetl źródło na GitHub Wyświetl źródło na GitHub | |
Przegląd
W tym samouczku przedstawiono wzbogacanie danych: technikę zwiększania różnorodności zestawu treningowego poprzez zastosowanie losowych (ale realistycznych) przekształceń, takich jak obracanie obrazu.
Dowiesz się, jak zastosować augmentację danych na dwa sposoby:
- Użyj warstw przetwarzania wstępnego Keras, takich jak
tf.keras.layers.Resizing,tf.keras.layers.Rescaling,tf.keras.layers.RandomFlipitf.keras.layers.RandomRotation. - Użyj metod
tf.image, takich jaktf.image.flip_left_right,tf.image.rgb_to_grayscale,tf.image.adjust_brightness,tf.image.central_cropitf.image.stateless_random*.
Ustawiać
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow.keras import layers
Pobierz zbiór danych
Ten samouczek używa zestawu danych tf_flowers . Dla wygody pobierz zestaw danych za pomocą TensorFlow Datasets . Jeśli chcesz poznać inne sposoby importowania danych, zapoznaj się z samouczkiem dotyczącym ładowania obrazów .
(train_ds, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
Zbiór danych o kwiatach ma pięć klas.
num_classes = metadata.features['label'].num_classes
print(num_classes)
5
Pobierzmy obraz z zestawu danych i użyjmy go do zademonstrowania rozszerzenia danych.
get_label_name = metadata.features['label'].int2str
image, label = next(iter(train_ds))
_ = plt.imshow(image)
_ = plt.title(get_label_name(label))
2022-01-26 05:09:18.712477: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.

Użyj warstw przetwarzania wstępnego Keras
Zmiana rozmiaru i skalowanie
Możesz użyć warstw przetwarzania wstępnego Keras, aby zmienić rozmiar obrazów do spójnego kształtu (za pomocą tf.keras.layers.Resizing ) i zmienić skalę wartości pikseli (za pomocą tf.keras.layers.Rescaling ).
IMG_SIZE = 180
resize_and_rescale = tf.keras.Sequential([
layers.Resizing(IMG_SIZE, IMG_SIZE),
layers.Rescaling(1./255)
])
Możesz zwizualizować efekt zastosowania tych warstw na obrazie.
result = resize_and_rescale(image)
_ = plt.imshow(result)
Sprawdź, czy piksele znajdują się w zakresie [0, 1] :
print("Min and max pixel values:", result.numpy().min(), result.numpy().max())
Min and max pixel values: 0.0 1.0
Rozszerzanie danych
Warstw przetwarzania wstępnego Keras można również używać do powiększania danych, takich jak tf.keras.layers.RandomFlip i tf.keras.layers.RandomRotation .
Utwórzmy kilka warstw przetwarzania wstępnego i zastosujmy je wielokrotnie do tego samego obrazu.
data_augmentation = tf.keras.Sequential([
layers.RandomFlip("horizontal_and_vertical"),
layers.RandomRotation(0.2),
])
# Add the image to a batch.
image = tf.expand_dims(image, 0)
plt.figure(figsize=(10, 10))
for i in range(9):
augmented_image = data_augmentation(image)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_image[0])
plt.axis("off")
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

Istnieje wiele warstw przetwarzania wstępnego, których można używać do powiększania danych, w tym tf.keras.layers.RandomContrast , tf.keras.layers.RandomCrop , tf.keras.layers.RandomZoom i inne.
Dwie opcje korzystania z warstw przetwarzania wstępnego Keras
Istnieją dwa sposoby wykorzystania tych warstw przetwarzania wstępnego, z ważnymi kompromisami.
Opcja 1: Uczyń warstwy przetwarzania wstępnego częścią swojego modelu
model = tf.keras.Sequential([
# Add the preprocessing layers you created earlier.
resize_and_rescale,
data_augmentation,
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
# Rest of your model.
])
W tym przypadku należy pamiętać o dwóch ważnych kwestiach:
Rozszerzanie danych będzie działać na urządzeniu synchronicznie z pozostałymi warstwami i korzystać z akceleracji GPU.
Podczas eksportowania modelu za pomocą
model.savewarstwy przetwarzania wstępnego zostaną zapisane wraz z resztą modelu. Jeśli później wdrożysz ten model, automatycznie ujednolici on obrazy (zgodnie z konfiguracją Twoich warstw). Może to zaoszczędzić na wysiłku związanym z koniecznością ponownego wdrożenia tej logiki po stronie serwera.
Opcja 2: Zastosuj warstwy przetwarzania wstępnego do swojego zbioru danych
aug_ds = train_ds.map(
lambda x, y: (resize_and_rescale(x, training=True), y))
W tym podejściu używasz Dataset.map do tworzenia zestawu danych, który dostarcza partie rozszerzonych obrazów. W tym przypadku:
- Rozszerzanie danych odbywa się asynchronicznie na procesorze i nie blokuje. Uczenie modelu na GPU można nakładać na wstępne przetwarzanie danych za pomocą
Dataset.prefetch, pokazanego poniżej. - W takim przypadku warstwy przetwarzania wstępnego nie zostaną wyeksportowane z modelem po wywołaniu
Model.save. Musisz je dołączyć do swojego modelu przed zapisaniem lub ponownym zaimplementowaniem po stronie serwera. Po szkoleniu można dołączyć warstwy przetwarzania wstępnego przed eksportem.
Przykład pierwszej opcji można znaleźć w samouczku dotyczącym klasyfikacji obrazów . Zademonstrujmy tutaj drugą opcję.
Zastosuj warstwy przetwarzania wstępnego do zbiorów danych
Skonfiguruj zestawy danych do trenowania, walidacji i testowania za pomocą utworzonych wcześniej warstw przetwarzania wstępnego Keras. Skonfigurujesz również zestawy danych pod kątem wydajności, używając równoległych odczytów i buforowanego pobierania wstępnego, aby uzyskać partie z dysku bez blokowania operacji we/wy. (Dowiedz się więcej o wydajności zestawu danych w artykule Lepsza wydajność dzięki przewodnikowi po interfejsie API tf.data ).
batch_size = 32
AUTOTUNE = tf.data.AUTOTUNE
def prepare(ds, shuffle=False, augment=False):
# Resize and rescale all datasets.
ds = ds.map(lambda x, y: (resize_and_rescale(x), y),
num_parallel_calls=AUTOTUNE)
if shuffle:
ds = ds.shuffle(1000)
# Batch all datasets.
ds = ds.batch(batch_size)
# Use data augmentation only on the training set.
if augment:
ds = ds.map(lambda x, y: (data_augmentation(x, training=True), y),
num_parallel_calls=AUTOTUNE)
# Use buffered prefetching on all datasets.
return ds.prefetch(buffer_size=AUTOTUNE)
train_ds = prepare(train_ds, shuffle=True, augment=True)
val_ds = prepare(val_ds)
test_ds = prepare(test_ds)
Wytrenuj modelkę
Aby uzyskać kompletność, teraz wytrenujesz model przy użyciu właśnie przygotowanych zestawów danych.
Model sekwencyjny składa się z trzech bloków konwolucji ( tf.keras.layers.Conv2D ) z maksymalną warstwą puli ( tf.keras.layers.MaxPooling2D ) w każdym z nich. Istnieje w pełni połączona warstwa ( tf.keras.layers.Dense ) z 128 jednostkami na wierzchu, która jest aktywowana przez funkcję aktywacji ReLU ( 'relu' ). Ten model nie został dostrojony pod kątem dokładności (celem jest pokazanie mechaniki).
model = tf.keras.Sequential([
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(num_classes)
])
Wybierz tf.keras.optimizers.Adam Optimizer i tf.keras.losses.SparseCategoricalCrossentropy funkcję utraty. Aby wyświetlić dokładność uczenia i walidacji dla każdej epoki uczenia, przekaż argument metrics do Model.compile .
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
Trenuj przez kilka epok:
epochs=5
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
Epoch 1/5 92/92 [==============================] - 13s 110ms/step - loss: 1.2768 - accuracy: 0.4622 - val_loss: 1.0929 - val_accuracy: 0.5640 Epoch 2/5 92/92 [==============================] - 3s 25ms/step - loss: 1.0579 - accuracy: 0.5749 - val_loss: 0.9711 - val_accuracy: 0.6349 Epoch 3/5 92/92 [==============================] - 3s 26ms/step - loss: 0.9677 - accuracy: 0.6291 - val_loss: 0.9764 - val_accuracy: 0.6431 Epoch 4/5 92/92 [==============================] - 3s 25ms/step - loss: 0.9150 - accuracy: 0.6468 - val_loss: 0.8906 - val_accuracy: 0.6431 Epoch 5/5 92/92 [==============================] - 3s 25ms/step - loss: 0.8636 - accuracy: 0.6604 - val_loss: 0.8233 - val_accuracy: 0.6730
loss, acc = model.evaluate(test_ds)
print("Accuracy", acc)
12/12 [==============================] - 5s 14ms/step - loss: 0.7922 - accuracy: 0.6948 Accuracy 0.6948229074478149
Niestandardowe powiększanie danych
Możesz także tworzyć niestandardowe warstwy rozszerzania danych.
Ta sekcja samouczka pokazuje dwa sposoby na zrobienie tego:
- Najpierw utworzysz warstwę
tf.keras.layers.Lambda. To dobry sposób na napisanie zwięzłego kodu. - Następnie napiszesz nową warstwę za pomocą podklasy , która zapewni ci większą kontrolę.
Obie warstwy będą losowo odwracać kolory na obrazie, zgodnie z pewnym prawdopodobieństwem.
def random_invert_img(x, p=0.5):
if tf.random.uniform([]) < p:
x = (255-x)
else:
x
return x
def random_invert(factor=0.5):
return layers.Lambda(lambda x: random_invert_img(x, factor))
random_invert = random_invert()
plt.figure(figsize=(10, 10))
for i in range(9):
augmented_image = random_invert(image)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_image[0].numpy().astype("uint8"))
plt.axis("off")
2022-01-26 05:09:53.045204: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045264: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045312: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045369: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045418: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045467: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045511: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.047630: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module

Następnie zaimplementuj niestandardową warstwę, tworząc podklasy :
class RandomInvert(layers.Layer):
def __init__(self, factor=0.5, **kwargs):
super().__init__(**kwargs)
self.factor = factor
def call(self, x):
return random_invert_img(x)
_ = plt.imshow(RandomInvert()(image)[0])

Obie te warstwy można stosować zgodnie z opisem w opcjach 1 i 2 powyżej.
Korzystanie z tf.image
Powyższe narzędzia do przetwarzania wstępnego Keras są wygodne. Aby jednak uzyskać lepszą kontrolę, możesz napisać własne potoki lub warstwy rozszerzania danych za pomocą tf.data i tf.image . (Możesz również sprawdzić TensorFlow Addons Image: Operations i TensorFlow I/O: Color Space Conversions .)
Ponieważ zbiór danych o kwiatach był wcześniej skonfigurowany z rozszerzeniem danych, zaimportujmy go ponownie, aby zacząć od nowa:
(train_ds, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
Pobierz obraz do pracy:
image, label = next(iter(train_ds))
_ = plt.imshow(image)
_ = plt.title(get_label_name(label))
2022-01-26 05:09:59.918847: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.

Użyjmy następującej funkcji, aby zwizualizować i porównać oryginalne i rozszerzone obrazy obok siebie:
def visualize(original, augmented):
fig = plt.figure()
plt.subplot(1,2,1)
plt.title('Original image')
plt.imshow(original)
plt.subplot(1,2,2)
plt.title('Augmented image')
plt.imshow(augmented)
Rozszerzanie danych
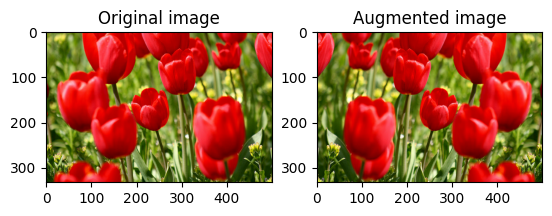
Odwróć obraz
Odwróć obraz w pionie lub w poziomie za pomocą tf.image.flip_left_right :
flipped = tf.image.flip_left_right(image)
visualize(image, flipped)
Skala szarości obrazu
Możesz zmienić skalę szarości obrazu za pomocą tf.image.rgb_to_grayscale :
grayscaled = tf.image.rgb_to_grayscale(image)
visualize(image, tf.squeeze(grayscaled))
_ = plt.colorbar()

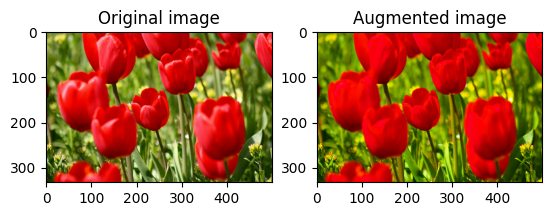
Nasycić obraz
Nasycenie obrazu za pomocą tf.image.adjust_saturation , podając współczynnik nasycenia:
saturated = tf.image.adjust_saturation(image, 3)
visualize(image, saturated)
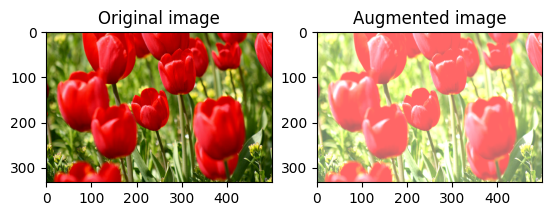
Zmień jasność obrazu
Zmień jasność obrazu za pomocą tf.image.adjust_brightness , podając współczynnik jasności:
bright = tf.image.adjust_brightness(image, 0.4)
visualize(image, bright)
Przytnij obraz na środku
Przytnij obraz od środka do żądanej części obrazu, używając tf.image.central_crop :
cropped = tf.image.central_crop(image, central_fraction=0.5)
visualize(image, cropped)
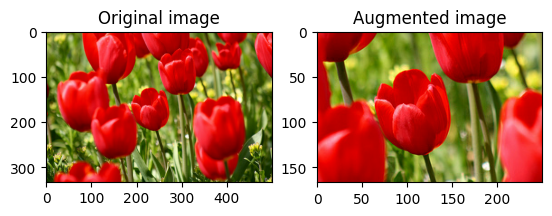
Obróć obraz
Obróć obraz o 90 stopni za pomocą tf.image.rot90 :
rotated = tf.image.rot90(image)
visualize(image, rotated)

Transformacje losowe
Zastosowanie losowych przekształceń do obrazów może dodatkowo pomóc w uogólnieniu i rozszerzeniu zbioru danych. Obecny interfejs API tf.image zapewnia osiem takich losowych operacji obrazu (ops):
-
tf.image.stateless_random_brightness -
tf.image.stateless_random_contrast -
tf.image.stateless_random_crop -
tf.image.stateless_random_flip_left_right -
tf.image.stateless_random_flip_up_down -
tf.image.stateless_random_hue -
tf.image.stateless_random_jpeg_quality -
tf.image.stateless_random_saturation
Te losowe operacje na obrazach są czysto funkcjonalne: dane wyjściowe zależą tylko od danych wejściowych. Dzięki temu są proste w użyciu w wysokowydajnych, deterministycznych potokach wejściowych. Wymagają one wprowadzenia wartości seed w każdym kroku. Biorąc pod uwagę to samo seed , zwracają te same wyniki niezależnie od tego, ile razy zostaną wywołane.
W kolejnych sekcjach będziesz:
- Przejrzyj przykłady użycia losowych operacji na obrazach do przekształcenia obrazu.
- Zademonstruj, jak zastosować losowe przekształcenia do uczącego zestawu danych.
Losowo zmień jasność obrazu
Losowo zmieniaj jasność image za pomocą tf.image.stateless_random_brightness , podając współczynnik jasności i seed . Współczynnik jasności wybierany jest losowo z zakresu [-max_delta, max_delta) i jest powiązany z danym seed .
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_brightness = tf.image.stateless_random_brightness(
image, max_delta=0.95, seed=seed)
visualize(image, stateless_random_brightness)
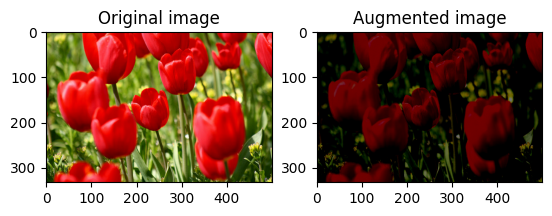
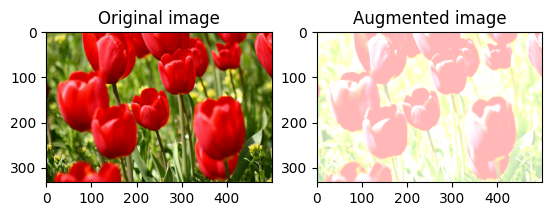
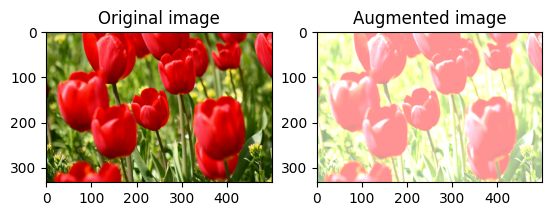
Losowo zmień kontrast obrazu
Losowo zmień kontrast image za pomocą tf.image.stateless_random_contrast , podając zakres kontrastu i seed . Zakres kontrastu wybierany jest losowo w przedziale [lower, upper] i jest powiązany z danym seed .
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_contrast = tf.image.stateless_random_contrast(
image, lower=0.1, upper=0.9, seed=seed)
visualize(image, stateless_random_contrast)
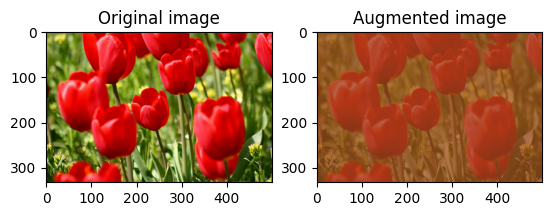
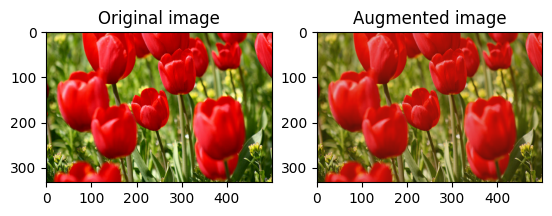
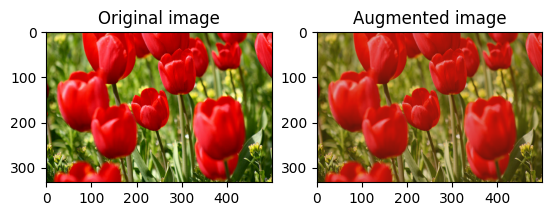
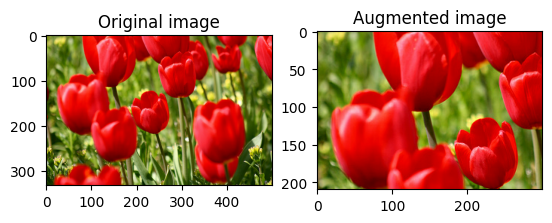
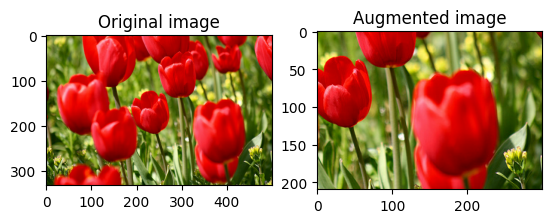
Przytnij obraz losowo
Przytnij image losowo za pomocą tf.image.stateless_random_crop , podając docelowy size i seed . Część, która zostaje wykadrowana z image , znajduje się w losowo wybranym przesunięciu i jest powiązana z danym seed .
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_crop = tf.image.stateless_random_crop(
image, size=[210, 300, 3], seed=seed)
visualize(image, stateless_random_crop)
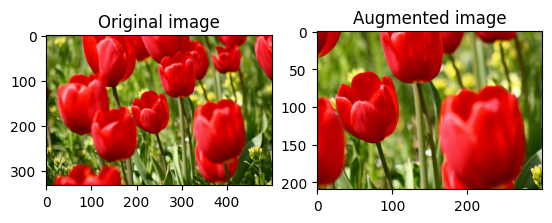
Zastosuj rozszerzenie do zbioru danych
Najpierw pobierzmy ponownie zestaw danych obrazu na wypadek, gdyby zostały zmodyfikowane w poprzednich sekcjach.
(train_datasets, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
Następnie zdefiniuj funkcję narzędziową do zmiany rozmiaru i skalowania obrazów. Ta funkcja zostanie wykorzystana do ujednolicenia rozmiaru i skali obrazów w zbiorze danych:
def resize_and_rescale(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, [IMG_SIZE, IMG_SIZE])
image = (image / 255.0)
return image, label
Zdefiniujmy również funkcję augment , która może zastosować losowe przekształcenia do obrazów. Ta funkcja zostanie użyta w zestawie danych w następnym kroku.
def augment(image_label, seed):
image, label = image_label
image, label = resize_and_rescale(image, label)
image = tf.image.resize_with_crop_or_pad(image, IMG_SIZE + 6, IMG_SIZE + 6)
# Make a new seed.
new_seed = tf.random.experimental.stateless_split(seed, num=1)[0, :]
# Random crop back to the original size.
image = tf.image.stateless_random_crop(
image, size=[IMG_SIZE, IMG_SIZE, 3], seed=seed)
# Random brightness.
image = tf.image.stateless_random_brightness(
image, max_delta=0.5, seed=new_seed)
image = tf.clip_by_value(image, 0, 1)
return image, label
Opcja 1: Korzystanie z tf.data.experimental.Counter
Utwórz obiekt tf.data.experimental.Counter (nazwijmy go counter ) i Dataset.zip zestaw danych za pomocą (counter, counter) . Zapewni to, że każdy obraz w zestawie danych zostanie skojarzony z unikalną wartością (o kształcie (2,) ) na podstawie counter , który później może zostać przekazany do funkcji augment jako wartość seed dla przekształceń losowych.
# Create a `Counter` object and `Dataset.zip` it together with the training set.
counter = tf.data.experimental.Counter()
train_ds = tf.data.Dataset.zip((train_datasets, (counter, counter)))
augment funkcję rozszerzania na treningowy zbiór danych:
train_ds = (
train_ds
.shuffle(1000)
.map(augment, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
val_ds = (
val_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
test_ds = (
test_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
Opcja 2: Korzystanie z tf.random.Generator
- Utwórz obiekt
tf.random.Generatorz początkową wartościąseed. Wywołanie funkcjimake_seedsna tym samym obiekcie generatora zawsze zwraca nową,seedwartość inicjatora. - Zdefiniuj funkcję opakowującą, która: 1) wywołuje funkcję
make_seeds; oraz 2) przekazuje nowoseedwartość inicjatora do funkcjiaugmentdla przekształceń losowych.
# Create a generator.
rng = tf.random.Generator.from_seed(123, alg='philox')
# Create a wrapper function for updating seeds.
def f(x, y):
seed = rng.make_seeds(2)[0]
image, label = augment((x, y), seed)
return image, label
Odwzoruj funkcję opakowującą f na treningowy zbiór danych, a funkcję resize_and_rescale — na zbiory walidacyjne i testowe:
train_ds = (
train_datasets
.shuffle(1000)
.map(f, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
val_ds = (
val_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
test_ds = (
test_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
Te zestawy danych mogą być teraz używane do trenowania modelu, jak pokazano wcześniej.
Następne kroki
Ten samouczek zademonstrował wzbogacanie danych przy użyciu warstw przetwarzania wstępnego Keras i tf.image .
- Aby dowiedzieć się, jak dołączyć warstwy przetwarzania wstępnego do modelu, zapoznaj się z samouczkiem dotyczącym klasyfikacji obrazów .
- Możesz również zainteresować się tym, jak wstępne przetwarzanie warstw może pomóc w klasyfikowaniu tekstu, jak pokazano w samouczku Podstawowej klasyfikacji tekstu .
- Możesz dowiedzieć się więcej o
tf.dataw tym przewodniku , a jak skonfigurować potoki wejściowe pod kątem wydajności .