
| | |  Voir la source sur GitHub Voir la source sur GitHub | |
Aperçu
Ce didacticiel illustre l'augmentation des données : une technique permettant d'augmenter la diversité de votre ensemble d'entraînement en appliquant des transformations aléatoires (mais réalistes), telles que la rotation d'image.
Vous apprendrez à appliquer l'augmentation des données de deux manières :
- Utilisez les couches de prétraitement Keras, telles que
tf.keras.layers.Resizing,tf.keras.layers.Rescaling,tf.keras.layers.RandomFlipettf.keras.layers.RandomRotation. - Utilisez les méthodes
tf.image, telles quetf.image.flip_left_right,tf.image.rgb_to_grayscale,tf.image.adjust_brightness,tf.image.central_cropettf.image.stateless_random*.
Installer
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow.keras import layers
Télécharger un jeu de données
Ce didacticiel utilise le jeu de données tf_flowers . Pour plus de commodité, téléchargez l'ensemble de données à l'aide de TensorFlow Datasets . Si vous souhaitez en savoir plus sur d'autres façons d'importer des données, consultez le didacticiel de chargement d'images .
(train_ds, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
L'ensemble de données de fleurs a cinq classes.
num_classes = metadata.features['label'].num_classes
print(num_classes)
5
Récupérons une image de l'ensemble de données et utilisons-la pour démontrer l'augmentation des données.
get_label_name = metadata.features['label'].int2str
image, label = next(iter(train_ds))
_ = plt.imshow(image)
_ = plt.title(get_label_name(label))
2022-01-26 05:09:18.712477: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.

Utiliser les couches de prétraitement Keras
Redimensionnement et mise à l'échelle
Vous pouvez utiliser les calques de prétraitement Keras pour redimensionner vos images en une forme cohérente (avec tf.keras.layers.Resizing ) et pour redimensionner les valeurs de pixel (avec tf.keras.layers.Rescaling ).
IMG_SIZE = 180
resize_and_rescale = tf.keras.Sequential([
layers.Resizing(IMG_SIZE, IMG_SIZE),
layers.Rescaling(1./255)
])
Vous pouvez visualiser le résultat de l'application de ces couches à une image.
result = resize_and_rescale(image)
_ = plt.imshow(result)
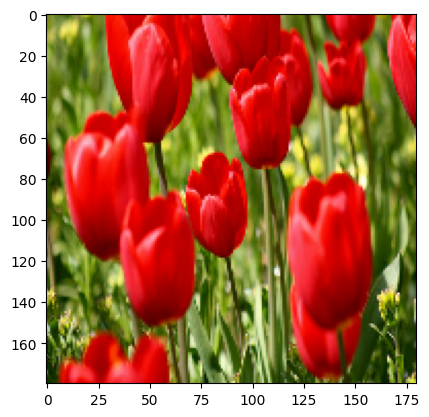
Vérifiez que les pixels sont dans la plage [0, 1] :
print("Min and max pixel values:", result.numpy().min(), result.numpy().max())
Min and max pixel values: 0.0 1.0
Augmentation des données
Vous pouvez également utiliser les couches de prétraitement Keras pour l'augmentation des données, telles que tf.keras.layers.RandomFlip et tf.keras.layers.RandomRotation .
Créons quelques calques de prétraitement et appliquons-les à plusieurs reprises à la même image.
data_augmentation = tf.keras.Sequential([
layers.RandomFlip("horizontal_and_vertical"),
layers.RandomRotation(0.2),
])
# Add the image to a batch.
image = tf.expand_dims(image, 0)
plt.figure(figsize=(10, 10))
for i in range(9):
augmented_image = data_augmentation(image)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_image[0])
plt.axis("off")
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

Il existe une variété de couches de prétraitement que vous pouvez utiliser pour l'augmentation des données, notamment tf.keras.layers.RandomContrast , tf.keras.layers.RandomCrop , tf.keras.layers.RandomZoom , etc.
Deux options pour utiliser les couches de prétraitement Keras
Il existe deux façons d'utiliser ces couches de prétraitement, avec des compromis importants.
Option 1 : Intégrer les couches de prétraitement à votre modèle
model = tf.keras.Sequential([
# Add the preprocessing layers you created earlier.
resize_and_rescale,
data_augmentation,
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
# Rest of your model.
])
Il y a deux points importants à prendre en compte dans ce cas :
L'augmentation des données s'exécutera sur l'appareil, de manière synchrone avec le reste de vos couches, et bénéficiera de l'accélération GPU.
Lorsque vous exportez votre modèle à l'aide
model.save, les couches de prétraitement seront enregistrées avec le reste de votre modèle. Si vous déployez ultérieurement ce modèle, il normalisera automatiquement les images (selon la configuration de vos calques). Cela peut vous éviter d'avoir à réimplémenter cette logique côté serveur.
Option 2 : Appliquer les couches de prétraitement à votre jeu de données
aug_ds = train_ds.map(
lambda x, y: (resize_and_rescale(x, training=True), y))
Avec cette approche, vous utilisez Dataset.map pour créer un jeu de données qui génère des lots d'images augmentées. Dans ce cas:
- L'augmentation des données se produira de manière asynchrone sur le processeur et n'est pas bloquante. Vous pouvez chevaucher la formation de votre modèle sur le GPU avec le prétraitement des données, à l'aide
Dataset.prefetch, illustré ci-dessous. - Dans ce cas, les couches de prétraitement ne seront pas exportées avec le modèle lorsque vous appelez
Model.save. Vous devrez les attacher à votre modèle avant de l'enregistrer ou de les réimplémenter côté serveur. Après la formation, vous pouvez attacher les couches de prétraitement avant l'exportation.
Vous pouvez trouver un exemple de la première option dans le didacticiel sur la classification des images . Démontrons la deuxième option ici.
Appliquer les couches de prétraitement aux jeux de données
Configurez les ensembles de données d'entraînement, de validation et de test avec les couches de prétraitement Keras que vous avez créées précédemment. Vous configurerez également les ensembles de données pour les performances, en utilisant des lectures parallèles et une prélecture en mémoire tampon pour générer des lots à partir du disque sans que les E/S deviennent bloquantes. (En savoir plus sur les performances des ensembles de données dans le guide Meilleures performances avec l'API tf.data .)
batch_size = 32
AUTOTUNE = tf.data.AUTOTUNE
def prepare(ds, shuffle=False, augment=False):
# Resize and rescale all datasets.
ds = ds.map(lambda x, y: (resize_and_rescale(x), y),
num_parallel_calls=AUTOTUNE)
if shuffle:
ds = ds.shuffle(1000)
# Batch all datasets.
ds = ds.batch(batch_size)
# Use data augmentation only on the training set.
if augment:
ds = ds.map(lambda x, y: (data_augmentation(x, training=True), y),
num_parallel_calls=AUTOTUNE)
# Use buffered prefetching on all datasets.
return ds.prefetch(buffer_size=AUTOTUNE)
train_ds = prepare(train_ds, shuffle=True, augment=True)
val_ds = prepare(val_ds)
test_ds = prepare(test_ds)
Former un modèle
Pour être complet, vous allez maintenant entraîner un modèle à l'aide des ensembles de données que vous venez de préparer.
Le modèle séquentiel se compose de trois blocs de convolution ( tf.keras.layers.Conv2D ) avec une couche de regroupement maximum ( tf.keras.layers.MaxPooling2D ) dans chacun d'eux. Il y a une couche entièrement connectée ( tf.keras.layers.Dense ) avec 128 unités dessus qui est activée par une fonction d'activation ReLU ( 'relu' ). Ce modèle n'a pas été réglé pour la précision (le but est de vous montrer la mécanique).
model = tf.keras.Sequential([
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(num_classes)
])
Choisissez l'optimiseur tf.keras.optimizers.Adam et la fonction de perte tf.keras.losses.SparseCategoricalCrossentropy . Pour afficher la précision de la formation et de la validation pour chaque époque de formation, transmettez l'argument metrics à Model.compile .
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
Entraînez-vous pendant quelques époques :
epochs=5
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
Epoch 1/5 92/92 [==============================] - 13s 110ms/step - loss: 1.2768 - accuracy: 0.4622 - val_loss: 1.0929 - val_accuracy: 0.5640 Epoch 2/5 92/92 [==============================] - 3s 25ms/step - loss: 1.0579 - accuracy: 0.5749 - val_loss: 0.9711 - val_accuracy: 0.6349 Epoch 3/5 92/92 [==============================] - 3s 26ms/step - loss: 0.9677 - accuracy: 0.6291 - val_loss: 0.9764 - val_accuracy: 0.6431 Epoch 4/5 92/92 [==============================] - 3s 25ms/step - loss: 0.9150 - accuracy: 0.6468 - val_loss: 0.8906 - val_accuracy: 0.6431 Epoch 5/5 92/92 [==============================] - 3s 25ms/step - loss: 0.8636 - accuracy: 0.6604 - val_loss: 0.8233 - val_accuracy: 0.6730
loss, acc = model.evaluate(test_ds)
print("Accuracy", acc)
12/12 [==============================] - 5s 14ms/step - loss: 0.7922 - accuracy: 0.6948 Accuracy 0.6948229074478149
Augmentation de données personnalisée
Vous pouvez également créer des couches d'augmentation de données personnalisées.
Cette section du didacticiel montre deux manières de procéder :
- Tout d'abord, vous allez créer une couche
tf.keras.layers.Lambda. C'est un bon moyen d'écrire du code concis. - Ensuite, vous écrirez un nouveau calque via le sous- classement , ce qui vous donne plus de contrôle.
Les deux couches inverseront aléatoirement les couleurs d'une image, selon une certaine probabilité.
def random_invert_img(x, p=0.5):
if tf.random.uniform([]) < p:
x = (255-x)
else:
x
return x
def random_invert(factor=0.5):
return layers.Lambda(lambda x: random_invert_img(x, factor))
random_invert = random_invert()
plt.figure(figsize=(10, 10))
for i in range(9):
augmented_image = random_invert(image)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_image[0].numpy().astype("uint8"))
plt.axis("off")
2022-01-26 05:09:53.045204: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045264: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045312: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045369: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045418: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045467: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045511: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.047630: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module

Ensuite, implémentez une couche personnalisée en sous- classant :
class RandomInvert(layers.Layer):
def __init__(self, factor=0.5, **kwargs):
super().__init__(**kwargs)
self.factor = factor
def call(self, x):
return random_invert_img(x)
_ = plt.imshow(RandomInvert()(image)[0])

Ces deux couches peuvent être utilisées comme décrit dans les options 1 et 2 ci-dessus.
Utilisation de tf.image
Les utilitaires de prétraitement Keras ci-dessus sont pratiques. Mais, pour un contrôle plus précis, vous pouvez écrire vos propres pipelines ou couches d'augmentation de données à l'aide tf.data et tf.image . (Vous pouvez également consulter TensorFlow Addons Image : Operations et TensorFlow I/O : Color Space Conversions .)
Étant donné que l'ensemble de données flowers était précédemment configuré avec l'augmentation des données, réimportons-le pour repartir à zéro :
(train_ds, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
Récupérer une image avec laquelle travailler :
image, label = next(iter(train_ds))
_ = plt.imshow(image)
_ = plt.title(get_label_name(label))
2022-01-26 05:09:59.918847: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.

Utilisons la fonction suivante pour visualiser et comparer côte à côte les images originales et augmentées :
def visualize(original, augmented):
fig = plt.figure()
plt.subplot(1,2,1)
plt.title('Original image')
plt.imshow(original)
plt.subplot(1,2,2)
plt.title('Augmented image')
plt.imshow(augmented)
Augmentation des données
Retourner une image
Retournez une image verticalement ou horizontalement avec tf.image.flip_left_right :
flipped = tf.image.flip_left_right(image)
visualize(image, flipped)
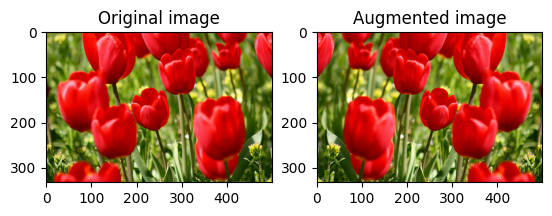
Niveaux de gris d'une image
Vous pouvez mettre une image en niveaux de gris avec tf.image.rgb_to_grayscale :
grayscaled = tf.image.rgb_to_grayscale(image)
visualize(image, tf.squeeze(grayscaled))
_ = plt.colorbar()

Saturer une image
Saturez une image avec tf.image.adjust_saturation en fournissant un facteur de saturation :
saturated = tf.image.adjust_saturation(image, 3)
visualize(image, saturated)
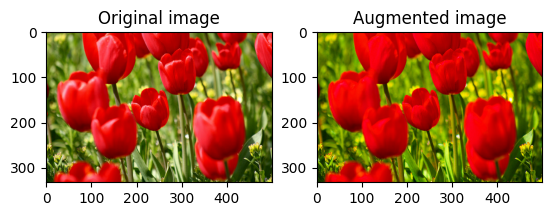
Modifier la luminosité de l'image
Modifiez la luminosité de l'image avec tf.image.adjust_brightness en fournissant un facteur de luminosité :
bright = tf.image.adjust_brightness(image, 0.4)
visualize(image, bright)
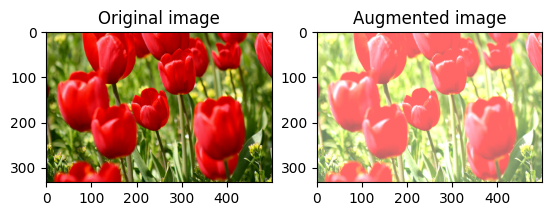
Recadrer une image au centre
Recadrez l'image du centre jusqu'à la partie d'image que vous désirez en utilisant tf.image.central_crop :
cropped = tf.image.central_crop(image, central_fraction=0.5)
visualize(image, cropped)
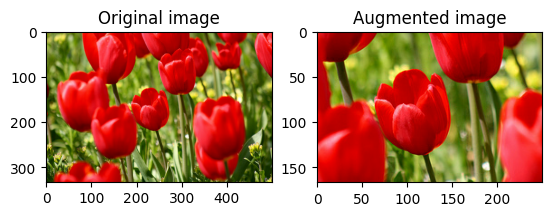
Faire pivoter une image
Faites pivoter une image de 90 degrés avec tf.image.rot90 :
rotated = tf.image.rot90(image)
visualize(image, rotated)

Transformations aléatoires
L'application de transformations aléatoires aux images peut en outre aider à généraliser et à étendre l'ensemble de données. L'API tf.image actuelle fournit huit opérations d'image aléatoires (ops) :
-
tf.image.stateless_random_brightness -
tf.image.stateless_random_contrast -
tf.image.stateless_random_crop -
tf.image.stateless_random_flip_left_right -
tf.image.stateless_random_flip_up_down -
tf.image.stateless_random_hue -
tf.image.stateless_random_jpeg_quality -
tf.image.stateless_random_saturation
Ces opérations d'images aléatoires sont purement fonctionnelles : la sortie ne dépend que de l'entrée. Cela les rend simples à utiliser dans des pipelines d'entrée déterministes hautes performances. Ils nécessitent seed valeur de départ soit saisie à chaque étape. Étant donné la même seed , ils renvoient les mêmes résultats indépendamment du nombre de fois qu'ils sont appelés.
Dans les sections suivantes, vous allez :
- Passez en revue des exemples d'utilisation d'opérations d'image aléatoires pour transformer une image.
- Montrez comment appliquer des transformations aléatoires à un jeu de données d'entraînement.
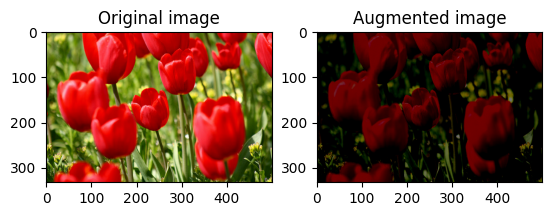
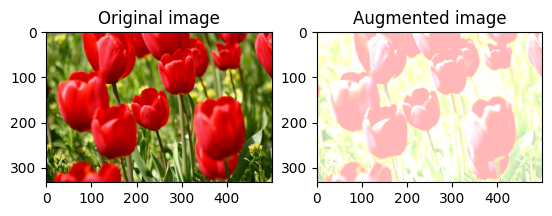
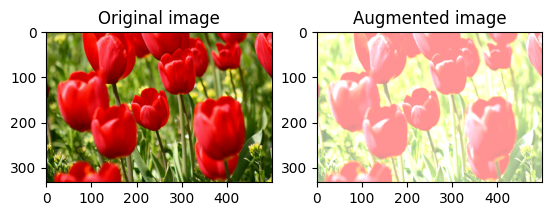
Modifier aléatoirement la luminosité de l'image
Modifiez aléatoirement la luminosité de l' image à l'aide de tf.image.stateless_random_brightness en fournissant un facteur de luminosité et seed . Le facteur de luminosité est choisi au hasard dans la plage [-max_delta, max_delta) et est associé à la seed donnée.
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_brightness = tf.image.stateless_random_brightness(
image, max_delta=0.95, seed=seed)
visualize(image, stateless_random_brightness)
Modifier au hasard le contraste de l'image
Modifiez aléatoirement le contraste de l' image à l'aide de tf.image.stateless_random_contrast en fournissant une plage de contraste et seed . La plage de contraste est choisie au hasard dans l'intervalle [lower, upper] et est associée à la seed donnée.
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_contrast = tf.image.stateless_random_contrast(
image, lower=0.1, upper=0.9, seed=seed)
visualize(image, stateless_random_contrast)
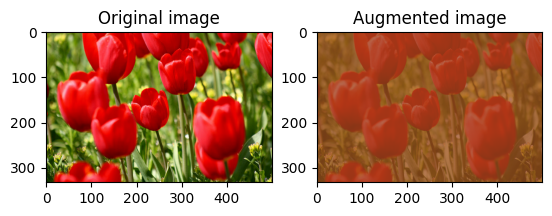

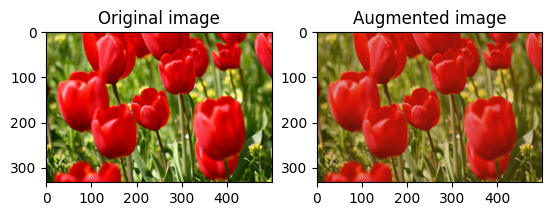
Recadrer une image au hasard
Recadrez l' image de manière aléatoire à l'aide de tf.image.stateless_random_crop en fournissant la size cible et seed . La partie qui est coupée de l' image est à un décalage choisi au hasard et est associée à la seed donnée.
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_crop = tf.image.stateless_random_crop(
image, size=[210, 300, 3], seed=seed)
visualize(image, stateless_random_crop)
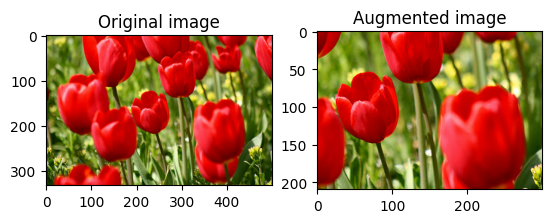
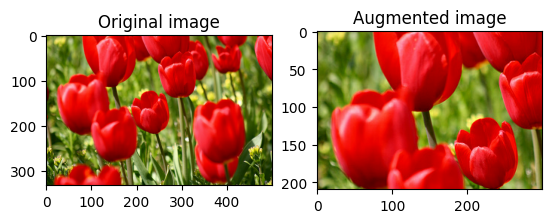
Appliquer l'augmentation à un jeu de données
Commençons par télécharger à nouveau le jeu de données d'image au cas où il serait modifié dans les sections précédentes.
(train_datasets, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
Ensuite, définissez une fonction utilitaire pour redimensionner et redimensionner les images. Cette fonction sera utilisée pour unifier la taille et l'échelle des images dans le jeu de données :
def resize_and_rescale(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, [IMG_SIZE, IMG_SIZE])
image = (image / 255.0)
return image, label
Définissons également la fonction augment qui peut appliquer les transformations aléatoires aux images. Cette fonction sera utilisée sur le jeu de données à l'étape suivante.
def augment(image_label, seed):
image, label = image_label
image, label = resize_and_rescale(image, label)
image = tf.image.resize_with_crop_or_pad(image, IMG_SIZE + 6, IMG_SIZE + 6)
# Make a new seed.
new_seed = tf.random.experimental.stateless_split(seed, num=1)[0, :]
# Random crop back to the original size.
image = tf.image.stateless_random_crop(
image, size=[IMG_SIZE, IMG_SIZE, 3], seed=seed)
# Random brightness.
image = tf.image.stateless_random_brightness(
image, max_delta=0.5, seed=new_seed)
image = tf.clip_by_value(image, 0, 1)
return image, label
Option 1 : Utilisation de tf.data.experimental.Counter
Créez un objet tf.data.experimental.Counter (appelons-le counter ) et Dataset.zip l'ensemble de données avec (counter, counter) . Cela garantira que chaque image de l'ensemble de données est associée à une valeur unique (de forme (2,) ) basée sur le counter qui peut ensuite être transmise à la fonction d' augment en tant seed valeur de départ pour les transformations aléatoires.
# Create a `Counter` object and `Dataset.zip` it together with the training set.
counter = tf.data.experimental.Counter()
train_ds = tf.data.Dataset.zip((train_datasets, (counter, counter)))
augment la fonction d'augmentation à l'ensemble de données d'entraînement :
train_ds = (
train_ds
.shuffle(1000)
.map(augment, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
val_ds = (
val_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
test_ds = (
test_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
Option 2 : Utilisation de tf.random.Generator
- Créez un objet
tf.random.Generatoravec une valeurseedinitiale. L'appel de la fonctionmake_seedssur le même objet générateur renvoie toujours une nouvelle valeurseedunique. - Définissez une fonction wrapper qui : 1) appelle la fonction
make_seeds; et 2) transmet la valeurseednouvellement générée à la fonction d'augmentpour les transformations aléatoires.
# Create a generator.
rng = tf.random.Generator.from_seed(123, alg='philox')
# Create a wrapper function for updating seeds.
def f(x, y):
seed = rng.make_seeds(2)[0]
image, label = augment((x, y), seed)
return image, label
Mappez la fonction wrapper f à l'ensemble de données d'apprentissage et la fonction resize_and_rescale aux ensembles de validation et de test :
train_ds = (
train_datasets
.shuffle(1000)
.map(f, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
val_ds = (
val_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
test_ds = (
test_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
Ces ensembles de données peuvent maintenant être utilisés pour former un modèle comme indiqué précédemment.
Prochaines étapes
Ce didacticiel a démontré l'augmentation des données à l'aide des couches de prétraitement Keras et tf.image .
- Pour savoir comment inclure des calques de prétraitement dans votre modèle, reportez-vous au didacticiel Classification des images .
- Vous pouvez également être intéressé par la façon dont les calques de prétraitement peuvent vous aider à classer le texte, comme indiqué dans le didacticiel de classification de texte de base .
- Vous pouvez en savoir plus sur
tf.datadans ce guide , et vous pouvez apprendre comment configurer vos pipelines d'entrée pour les performances ici .