
| | |  Xem nguồn trên GitHub Xem nguồn trên GitHub | |
Hướng dẫn này đào tạo mô hình mạng nơ-ron để phân loại hình ảnh của quần áo, như giày thể thao và áo sơ mi. Không sao nếu bạn không hiểu tất cả các chi tiết; đây là tổng quan có nhịp độ nhanh về một chương trình TensorFlow hoàn chỉnh với các chi tiết được giải thích khi bạn tiếp tục.
Hướng dẫn này sử dụng tf.keras , một API cấp cao để xây dựng và đào tạo các mô hình trong TensorFlow.
# TensorFlow and tf.keras
import tensorflow as tf
# Helper libraries
import numpy as np
import matplotlib.pyplot as plt
print(tf.__version__)
2.8.0
Nhập tập dữ liệu MNIST Thời trang
Hướng dẫn này sử dụng tập dữ liệu Fashion MNIST chứa 70.000 hình ảnh thang độ xám trong 10 danh mục. Các hình ảnh hiển thị từng mặt hàng quần áo ở độ phân giải thấp (28 x 28 pixel), như được thấy ở đây:
| Hình 1. Các mẫu thời trang-MNIST (của Zalando, Giấy phép MIT). |
Fashion MNIST được thiết kế để thay thế cho tập dữ liệu MNIST cổ điển — thường được dùng làm chương trình máy học "Hello, World" cho thị giác máy tính. Tập dữ liệu MNIST chứa hình ảnh của các chữ số viết tay (0, 1, 2, v.v.) ở định dạng giống với định dạng của các mặt hàng quần áo bạn sẽ sử dụng ở đây.
Hướng dẫn này sử dụng Fashion MNIST vì sự đa dạng và vì nó là một vấn đề khó hơn một chút so với MNIST thông thường. Cả hai tập dữ liệu đều tương đối nhỏ và được sử dụng để xác minh rằng một thuật toán hoạt động như mong đợi. Chúng là những điểm khởi đầu tốt để kiểm tra và gỡ lỗi mã.
Ở đây, 60.000 hình ảnh được sử dụng để huấn luyện mạng và 10.000 hình ảnh để đánh giá mức độ chính xác của mạng đã học để phân loại hình ảnh. Bạn có thể truy cập MNIST Thời trang trực tiếp từ TensorFlow. Nhập và tải dữ liệu Fashion MNIST trực tiếp từ TensorFlow:
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 32768/29515 [=================================] - 0s 0us/step 40960/29515 [=========================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26427392/26421880 [==============================] - 0s 0us/step 26435584/26421880 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 16384/5148 [===============================================================================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4423680/4422102 [==============================] - 0s 0us/step 4431872/4422102 [==============================] - 0s 0us/step
Tải tập dữ liệu trả về bốn mảng NumPy:
-
train_imagesvàtrain_labelslà tập huấn luyện — dữ liệu mà mô hình sử dụng để học. - Mô hình được kiểm tra dựa trên tập thử nghiệm , mảng
test_imagesvàtest_labels.
Hình ảnh là mảng NumPy 28x28, với giá trị pixel nằm trong khoảng từ 0 đến 255. Các nhãn là một mảng các số nguyên, từ 0 đến 9. Các nhãn này tương ứng với loại quần áo mà hình ảnh đại diện:
| Nhãn mác | Lớp học |
|---|---|
| 0 | Áo phông / áo sơ mi |
| 1 | Ống quần |
| 2 | Kéo qua |
| 3 | Trang phục |
| 4 | Áo choàng |
| 5 | Sandal |
| 6 | Áo sơ mi |
| 7 | Giày thể thao |
| số 8 | Túi |
| 9 | Ủng cổ chân |
Mỗi hình ảnh được ánh xạ tới một nhãn duy nhất. Vì tên lớp không được bao gồm trong tập dữ liệu, hãy lưu trữ chúng ở đây để sử dụng sau này khi vẽ biểu đồ hình ảnh:
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
Khám phá dữ liệu
Hãy cùng khám phá định dạng của tập dữ liệu trước khi huấn luyện mô hình. Phần sau cho thấy có 60.000 hình ảnh trong tập huấn luyện, với mỗi hình ảnh được biểu thị là 28 x 28 pixel:
train_images.shape
(60000, 28, 28)
Tương tự như vậy, có 60.000 nhãn trong tập huấn luyện:
len(train_labels)
60000
Mỗi nhãn là một số nguyên từ 0 đến 9:
train_labels
array([9, 0, 0, ..., 3, 0, 5], dtype=uint8)
Có 10.000 hình ảnh trong bộ thử nghiệm. Một lần nữa, mỗi hình ảnh được biểu thị dưới dạng 28 x 28 pixel:
test_images.shape
(10000, 28, 28)
Và bộ thử nghiệm bao gồm 10.000 nhãn hình ảnh:
len(test_labels)
10000
Xử lý trước dữ liệu
Dữ liệu phải được xử lý trước trước khi huấn luyện mạng. Nếu bạn kiểm tra hình ảnh đầu tiên trong tập hợp đào tạo, bạn sẽ thấy rằng các giá trị pixel nằm trong phạm vi từ 0 đến 255:
plt.figure()
plt.imshow(train_images[0])
plt.colorbar()
plt.grid(False)
plt.show()
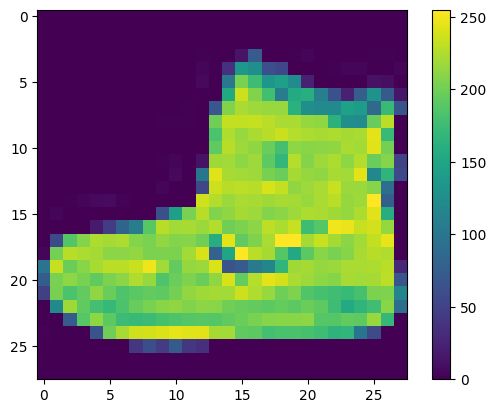
Chia tỷ lệ các giá trị này thành một phạm vi từ 0 đến 1 trước khi đưa chúng vào mô hình mạng thần kinh. Để làm như vậy, hãy chia các giá trị cho 255. Điều quan trọng là tập huấn luyện và tập thử nghiệm phải được xử lý trước theo cùng một cách:
train_images = train_images / 255.0
test_images = test_images / 255.0
Để xác minh rằng dữ liệu ở định dạng chính xác và bạn đã sẵn sàng xây dựng và đào tạo mạng, hãy hiển thị 25 hình ảnh đầu tiên từ tập hợp đào tạo và hiển thị tên lớp bên dưới mỗi hình ảnh.
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
plt.show()

Xây dựng mô hình
Xây dựng mạng nơ-ron yêu cầu cấu hình các lớp của mô hình, sau đó biên dịch mô hình.
Thiết lập các lớp
Khối xây dựng cơ bản của mạng nơ-ron là lớp . Các lớp trích xuất các đại diện từ dữ liệu được đưa vào chúng. Hy vọng rằng, những biểu diễn này có ý nghĩa đối với vấn đề đang giải quyết.
Hầu hết học sâu bao gồm xâu chuỗi các lớp đơn giản lại với nhau. Hầu hết các lớp, chẳng hạn như tf.keras.layers.Dense , có các tham số được học trong quá trình đào tạo.
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10)
])
Lớp đầu tiên trong mạng này, tf.keras.layers.Flatten , chuyển đổi định dạng của hình ảnh từ mảng hai chiều (28 x 28 pixel) thành mảng một chiều (28 * 28 = 784 pixel). Hãy nghĩ về lớp này giống như các hàng pixel trong hình ảnh và xếp chúng thành hàng. Lớp này không có tham số nào để học; nó chỉ định dạng lại dữ liệu.
Sau khi các pixel được làm phẳng, mạng bao gồm một chuỗi hai lớp tf.keras.layers.Dense . Đây là các lớp thần kinh được kết nối dày đặc, hoặc được kết nối đầy đủ. Lớp Dense đầu tiên có 128 nút (hoặc tế bào thần kinh). Lớp thứ hai (và cuối cùng) trả về một mảng logits có độ dài là 10. Mỗi nút chứa một điểm cho biết hình ảnh hiện tại thuộc về một trong 10 lớp.
Biên dịch mô hình
Trước khi mô hình sẵn sàng để đào tạo, nó cần thêm một số cài đặt. Chúng được thêm vào trong bước biên dịch của mô hình:
- Hàm mất mát —Điều này đo lường mức độ chính xác của mô hình trong quá trình đào tạo. Bạn muốn thu nhỏ chức năng này để "chèo lái" mô hình đi đúng hướng.
- Trình tối ưu hóa —Đây là cách mô hình được cập nhật dựa trên dữ liệu mà nó thấy và chức năng mất của nó.
- Chỉ số —Được sử dụng để theo dõi các bước đào tạo và thử nghiệm. Ví dụ sau sử dụng độ chính xác , phần hình ảnh được phân loại chính xác.
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
Đào tạo mô hình
Đào tạo mô hình mạng nơ-ron yêu cầu các bước sau:
- Cung cấp dữ liệu đào tạo vào mô hình. Trong ví dụ này, dữ liệu huấn luyện nằm trong mảng
train_imagesvàtrain_labels. - Mô hình học cách liên kết hình ảnh và nhãn.
- Bạn yêu cầu mô hình đưa ra dự đoán về một tập hợp thử nghiệm — trong ví dụ này là mảng
test_images. - Xác minh rằng các dự đoán khớp với các nhãn từ mảng
test_labels.
Nuôi mô hình
Để bắt đầu đào tạo, hãy gọi phương thức model.fit — được gọi như vậy vì nó "khớp" mô hình với dữ liệu đào tạo:
model.fit(train_images, train_labels, epochs=10)
Epoch 1/10 1875/1875 [==============================] - 4s 2ms/step - loss: 0.4986 - accuracy: 0.8253 Epoch 2/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.3751 - accuracy: 0.8651 Epoch 3/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.3364 - accuracy: 0.8769 Epoch 4/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.3124 - accuracy: 0.8858 Epoch 5/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2949 - accuracy: 0.8913 Epoch 6/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2776 - accuracy: 0.8977 Epoch 7/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2669 - accuracy: 0.9022 Epoch 8/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2552 - accuracy: 0.9046 Epoch 9/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2463 - accuracy: 0.9089 Epoch 10/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2376 - accuracy: 0.9117 <keras.callbacks.History at 0x7f5f2c785110>
Khi mô hình đào tạo, các số liệu về tổn thất và độ chính xác được hiển thị. Mô hình này đạt độ chính xác khoảng 0,91 (hoặc 91%) trên dữ liệu huấn luyện.
Đánh giá độ chính xác
Tiếp theo, so sánh cách mô hình hoạt động trên tập dữ liệu thử nghiệm:
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('\nTest accuracy:', test_acc)
313/313 - 1s - loss: 0.3176 - accuracy: 0.8895 - 553ms/epoch - 2ms/step Test accuracy: 0.8895000219345093
Nó chỉ ra rằng độ chính xác trên tập dữ liệu thử nghiệm ít hơn một chút so với độ chính xác trên tập dữ liệu đào tạo. Khoảng cách giữa độ chính xác của quá trình huấn luyện và độ chính xác của bài kiểm tra thể hiện sự trang bị quá mức . Việc trang bị quá mức xảy ra khi một mô hình học máy hoạt động kém hơn trên các đầu vào mới, chưa từng thấy trước đây so với mô hình học trên dữ liệu đào tạo. Một mô hình được trang bị quá mức sẽ "ghi nhớ" tiếng ồn và chi tiết trong tập dữ liệu huấn luyện đến một điểm mà nó tác động tiêu cực đến hiệu suất của mô hình trên dữ liệu mới. Để biết thêm thông tin, hãy xem phần sau:
Dự đoán
Với mô hình được đào tạo, bạn có thể sử dụng nó để đưa ra dự đoán về một số hình ảnh. Đính kèm một lớp softmax để chuyển đổi các đầu ra tuyến tính của mô hình— log — thành xác suất, sẽ dễ hiểu hơn.
probability_model = tf.keras.Sequential([model,
tf.keras.layers.Softmax()])
predictions = probability_model.predict(test_images)
Ở đây, mô hình đã dự đoán nhãn cho từng hình ảnh trong bộ thử nghiệm. Hãy cùng xem dự đoán đầu tiên:
predictions[0]
array([1.3835326e-08, 2.7011181e-11, 2.6019606e-10, 5.6872784e-11,
1.2070331e-08, 4.1874609e-04, 1.1151612e-08, 5.7000564e-03,
8.1178889e-08, 9.9388099e-01], dtype=float32)
Dự đoán là một dãy 10 số. Chúng đại diện cho "sự tự tin" của người mẫu rằng hình ảnh tương ứng với mỗi trong số 10 mặt hàng quần áo khác nhau. Bạn có thể xem nhãn nào có giá trị tin cậy cao nhất:
np.argmax(predictions[0])
9
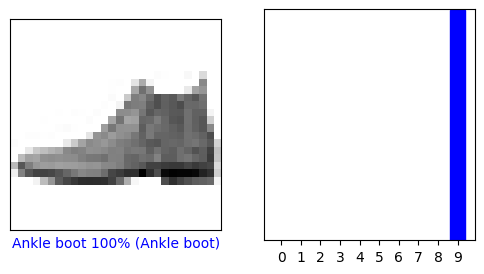
Vì vậy, người mẫu tin tưởng nhất rằng hình ảnh này là giày bốt đến mắt cá chân, hoặc class_names[9] . Kiểm tra nhãn thử nghiệm cho thấy rằng phân loại này là chính xác:
test_labels[0]
9
Vẽ biểu đồ này để xem toàn bộ dự đoán lớp 10.
def plot_image(i, predictions_array, true_label, img):
true_label, img = true_label[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label],
100*np.max(predictions_array),
class_names[true_label]),
color=color)
def plot_value_array(i, predictions_array, true_label):
true_label = true_label[i]
plt.grid(False)
plt.xticks(range(10))
plt.yticks([])
thisplot = plt.bar(range(10), predictions_array, color="#777777")
plt.ylim([0, 1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')
Xác minh dự đoán
Với mô hình được đào tạo, bạn có thể sử dụng nó để đưa ra dự đoán về một số hình ảnh.
Hãy xem hình ảnh thứ 0, dự đoán và mảng dự đoán. Nhãn dự đoán đúng có màu xanh lam và nhãn dự đoán không chính xác có màu đỏ. Con số cho biết tỷ lệ phần trăm (trong số 100) cho nhãn được dự đoán.
i = 0
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions[i], test_labels)
plt.show()
i = 12
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions[i], test_labels)
plt.show()
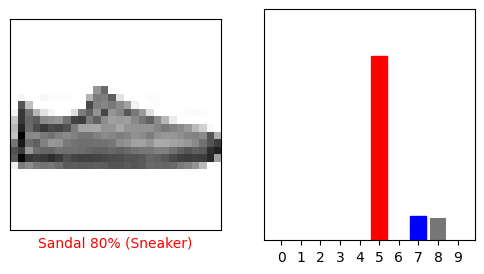
Hãy vẽ một số hình ảnh với dự đoán của họ. Lưu ý rằng mô hình có thể sai ngay cả khi rất tự tin.
# Plot the first X test images, their predicted labels, and the true labels.
# Color correct predictions in blue and incorrect predictions in red.
num_rows = 5
num_cols = 3
num_images = num_rows*num_cols
plt.figure(figsize=(2*2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, 2*num_cols, 2*i+1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(num_rows, 2*num_cols, 2*i+2)
plot_value_array(i, predictions[i], test_labels)
plt.tight_layout()
plt.show()

Sử dụng mô hình được đào tạo
Cuối cùng, sử dụng mô hình đã đào tạo để đưa ra dự đoán về một hình ảnh duy nhất.
# Grab an image from the test dataset.
img = test_images[1]
print(img.shape)
(28, 28)
Các mô hình tf.keras được tối ưu hóa để đưa ra dự đoán trên một loạt hoặc một bộ sưu tập các ví dụ cùng một lúc. Do đó, mặc dù bạn đang sử dụng một hình ảnh duy nhất, bạn cần thêm nó vào danh sách:
# Add the image to a batch where it's the only member.
img = (np.expand_dims(img,0))
print(img.shape)
(1, 28, 28)
Bây giờ hãy dự đoán nhãn chính xác cho hình ảnh này:
predictions_single = probability_model.predict(img)
print(predictions_single)
[[8.26038831e-06 1.10213664e-13 9.98591125e-01 1.16777841e-08 1.29609776e-03 2.54965649e-11 1.04560357e-04 7.70050608e-19 4.55051066e-11 3.53864888e-17]]
plot_value_array(1, predictions_single[0], test_labels)
_ = plt.xticks(range(10), class_names, rotation=45)
plt.show()
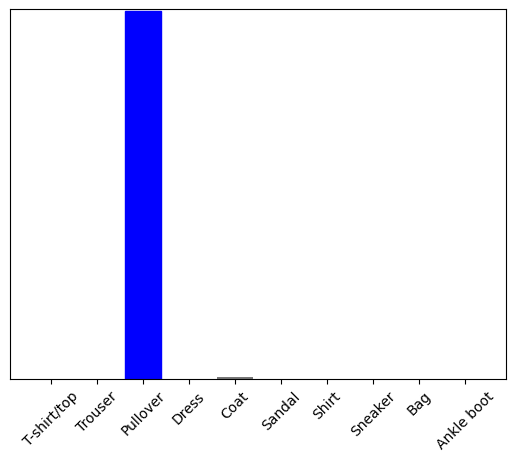
tf.keras.Model.predict trả về một danh sách các danh sách — một danh sách cho mỗi hình ảnh trong lô dữ liệu. Lấy các dự đoán cho hình ảnh (duy nhất) của chúng tôi trong lô:
np.argmax(predictions_single[0])
2
Và mô hình dự đoán một nhãn như mong đợi.
# MIT License
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.