
| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub | |
Это руководство обучает модель нейронной сети классифицировать изображения одежды, например кроссовок и рубашек. Ничего страшного, если вы не понимаете всех деталей; это быстрый обзор полной программы TensorFlow с подробностями, объясняемыми по ходу дела.
В этом руководстве используется высокоуровневый API tf.keras для создания и обучения моделей в TensorFlow.
# TensorFlow and tf.keras
import tensorflow as tf
# Helper libraries
import numpy as np
import matplotlib.pyplot as plt
print(tf.__version__)
2.8.0
Импорт набора данных Fashion MNIST
В этом руководстве используется набор данных Fashion MNIST , который содержит 70 000 изображений в оттенках серого в 10 категориях. На изображениях показаны отдельные предметы одежды с низким разрешением (28 на 28 пикселей), как показано здесь:
| Рисунок 1. Образцы Fashion-MNIST (от Zalando, лицензия MIT). |
Fashion MNIST предназначен для быстрой замены классического набора данных MNIST , который часто используется в качестве «Привет, мир» программ машинного обучения для компьютерного зрения. Набор данных MNIST содержит изображения рукописных цифр (0, 1, 2 и т. д.) в формате, идентичном формату предметов одежды, которые вы будете здесь использовать.
В этом руководстве модный MNIST используется для разнообразия и потому, что это немного более сложная задача, чем обычный MNIST. Оба набора данных относительно малы и используются для проверки того, что алгоритм работает должным образом. Они являются хорошей отправной точкой для тестирования и отладки кода.
Здесь 60 000 изображений используются для обучения сети и 10 000 изображений для оценки того, насколько точно сеть научилась классифицировать изображения. Вы можете получить доступ к Fashion MNIST напрямую из TensorFlow. Импортируйте и загрузите данные Fashion MNIST напрямую из TensorFlow:
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 32768/29515 [=================================] - 0s 0us/step 40960/29515 [=========================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26427392/26421880 [==============================] - 0s 0us/step 26435584/26421880 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 16384/5148 [===============================================================================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4423680/4422102 [==============================] - 0s 0us/step 4431872/4422102 [==============================] - 0s 0us/step
Загрузка набора данных возвращает четыре массива NumPy:
-
train_imagesиtrain_labelsпредставляют собой обучающий набор — данные, которые модель использует для обучения. - Модель тестируется на тестовом наборе ,
test_imagesиtest_labels.
Изображения представляют собой массивы NumPy 28x28 со значениями пикселей в диапазоне от 0 до 255. Метки представляют собой массив целых чисел в диапазоне от 0 до 9. Они соответствуют классу одежды, который представляет изображение:
| Этикетка | Класс |
|---|---|
| 0 | Футболка/топ |
| 1 | Брюки |
| 2 | Натяни |
| 3 | Одеваться |
| 4 | Пальто |
| 5 | Сандалии |
| 6 | Рубашка |
| 7 | кроссовки |
| 8 | Сумка |
| 9 | Ботильоны |
Каждое изображение сопоставляется с одной меткой. Поскольку имена классов не включены в набор данных, сохраните их здесь, чтобы использовать позже при построении изображений:
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
Исследуйте данные
Давайте изучим формат набора данных перед обучением модели. Ниже показано, что в обучающем наборе 60 000 изображений, каждое из которых представлено как 28 x 28 пикселей:
train_images.shape
(60000, 28, 28)
Точно так же в обучающем наборе 60 000 меток:
len(train_labels)
60000
Каждая метка представляет собой целое число от 0 до 9:
train_labels
array([9, 0, 0, ..., 3, 0, 5], dtype=uint8)
В тестовом наборе 10 000 изображений. Опять же, каждое изображение представлено как 28 x 28 пикселей:
test_images.shape
(10000, 28, 28)
И тестовый набор содержит 10 000 меток изображений:
len(test_labels)
10000
Предварительно обработайте данные
Данные должны быть предварительно обработаны перед обучением сети. Если вы посмотрите на первое изображение в тренировочном наборе, вы увидите, что значения пикселей попадают в диапазон от 0 до 255:
plt.figure()
plt.imshow(train_images[0])
plt.colorbar()
plt.grid(False)
plt.show()
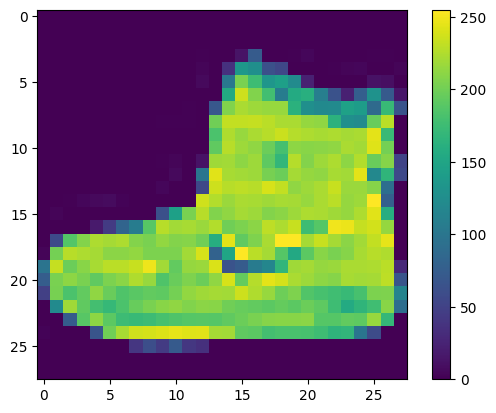
Масштабируйте эти значения в диапазоне от 0 до 1, прежде чем передавать их в модель нейронной сети. Для этого разделите значения на 255. Важно, чтобы обучающая выборка и проверочная выборка были предварительно обработаны одинаково:
train_images = train_images / 255.0
test_images = test_images / 255.0
Чтобы убедиться, что данные имеют правильный формат и что вы готовы построить и обучить сеть, давайте отобразим первые 25 изображений из обучающего набора и отобразим имя класса под каждым изображением.
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
plt.show()

Построить модель
Для построения нейронной сети необходимо настроить слои модели, а затем скомпилировать модель.
Настройка слоев
Основным строительным блоком нейронной сети является слой . Слои извлекают представления из введенных в них данных. Будем надеяться, что эти представления имеют смысл для рассматриваемой проблемы.
Большая часть глубокого обучения состоит из объединения простых слоев. Большинство слоев, таких как tf.keras.layers.Dense , имеют параметры, которые изучаются во время обучения.
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10)
])
Первый слой в этой сети, tf.keras.layers.Flatten , преобразует формат изображений из двумерного массива (28 на 28 пикселей) в одномерный массив (28 * 28 = 784 пикселей). Думайте об этом слое как о разделении рядов пикселей на изображении и их выравнивании. Этот слой не имеет параметров для изучения; он только переформатирует данные.
После выравнивания пикселей сеть состоит из последовательности двух слоев tf.keras.layers.Dense . Это плотно связанные или полностью связанные нейронные слои. Первый Dense слой имеет 128 узлов (или нейронов). Второй (и последний) слой возвращает массив логитов длиной 10. Каждый узел содержит оценку, указывающую, что текущее изображение принадлежит к одному из 10 классов.
Скомпилируйте модель
Прежде чем модель будет готова к обучению, ей нужно еще несколько настроек. Они добавляются на этапе компиляции модели:
- Функция потерь — измеряет, насколько точна модель во время обучения. Вы хотите минимизировать эту функцию, чтобы "направить" модель в правильном направлении.
- Оптимизатор — именно так модель обновляется на основе данных, которые она видит, и ее функции потерь.
- Метрики — используются для мониторинга этапов обучения и тестирования. В следующем примере используется точность , доля правильно классифицированных изображений.
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
Обучите модель
Для обучения модели нейронной сети необходимо выполнить следующие шаги:
- Подайте обучающие данные к модели. В этом примере обучающие данные находятся в
train_imagesиtrain_labels. - Модель учится связывать изображения и метки.
- Вы просите модель сделать прогноз относительно тестового набора — в этом примере массива
test_images. - Убедитесь, что прогнозы соответствуют меткам из массива
test_labels.
Накормить модель
Чтобы начать обучение, вызовите метод model.fit , названный так потому, что он «подгоняет» модель к обучающим данным:
model.fit(train_images, train_labels, epochs=10)
Epoch 1/10 1875/1875 [==============================] - 4s 2ms/step - loss: 0.4986 - accuracy: 0.8253 Epoch 2/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.3751 - accuracy: 0.8651 Epoch 3/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.3364 - accuracy: 0.8769 Epoch 4/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.3124 - accuracy: 0.8858 Epoch 5/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2949 - accuracy: 0.8913 Epoch 6/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2776 - accuracy: 0.8977 Epoch 7/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2669 - accuracy: 0.9022 Epoch 8/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2552 - accuracy: 0.9046 Epoch 9/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2463 - accuracy: 0.9089 Epoch 10/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2376 - accuracy: 0.9117 <keras.callbacks.History at 0x7f5f2c785110>
По мере обучения модели отображаются показатели потерь и точности. Эта модель достигает точности около 0,91 (или 91%) на обучающих данных.
Оцените точность
Затем сравните, как модель работает с тестовым набором данных:
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('\nTest accuracy:', test_acc)
313/313 - 1s - loss: 0.3176 - accuracy: 0.8895 - 553ms/epoch - 2ms/step Test accuracy: 0.8895000219345093
Получается, что точность на тестовом наборе данных немного меньше, чем точность на обучающем наборе данных. Этот разрыв между точностью обучения и точностью теста представляет собой переоснащение . Переоснащение происходит, когда модель машинного обучения работает хуже с новыми, ранее невиданными входными данными, чем с обучающими данными. Переобученная модель «запоминает» шум и детали в обучающем наборе данных до такой степени, что это негативно влияет на производительность модели на новых данных. Для получения дополнительной информации см. следующее:
Делать предсказания
Обученную модель можно использовать для прогнозирования некоторых изображений. Прикрепите слой softmax для преобразования линейных выходных данных модели — логитов — в вероятности, которые должны быть легче интерпретировать.
probability_model = tf.keras.Sequential([model,
tf.keras.layers.Softmax()])
predictions = probability_model.predict(test_images)
Здесь модель предсказала метку для каждого изображения в тестовом наборе. Давайте посмотрим на первый прогноз:
predictions[0]
array([1.3835326e-08, 2.7011181e-11, 2.6019606e-10, 5.6872784e-11,
1.2070331e-08, 4.1874609e-04, 1.1151612e-08, 5.7000564e-03,
8.1178889e-08, 9.9388099e-01], dtype=float32)
Прогноз представляет собой массив из 10 чисел. Они отражают «уверенность» модели в том, что изображение соответствует каждому из 10 различных предметов одежды. Вы можете увидеть, какая метка имеет наивысшее значение достоверности:
np.argmax(predictions[0])
9
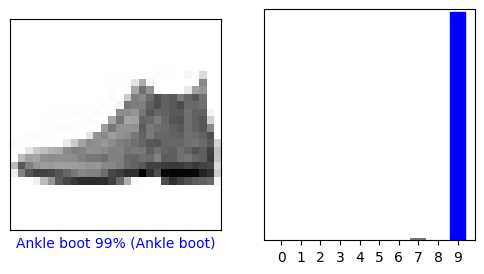
Итак, модель наиболее уверена, что это изображение — ботильоны или class_names[9] . Изучение тестовой этикетки показывает, что эта классификация верна:
test_labels[0]
9
Нарисуйте это, чтобы увидеть полный набор из 10 предсказаний класса.
def plot_image(i, predictions_array, true_label, img):
true_label, img = true_label[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label],
100*np.max(predictions_array),
class_names[true_label]),
color=color)
def plot_value_array(i, predictions_array, true_label):
true_label = true_label[i]
plt.grid(False)
plt.xticks(range(10))
plt.yticks([])
thisplot = plt.bar(range(10), predictions_array, color="#777777")
plt.ylim([0, 1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')
Проверить прогнозы
Обученную модель можно использовать для прогнозирования некоторых изображений.
Давайте посмотрим на 0-е изображение, прогнозы и массив прогнозов. Метки правильных прогнозов выделены синим цветом, а метки неправильных прогнозов — красным. Число указывает процент (из 100) предсказанной метки.
i = 0
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions[i], test_labels)
plt.show()
i = 12
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions[i], test_labels)
plt.show()
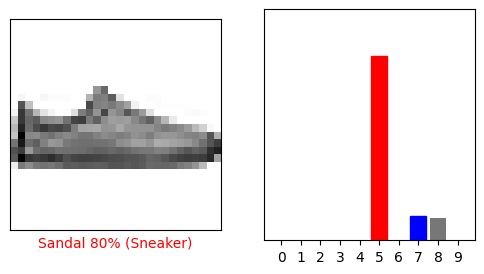
Давайте построим несколько изображений с их предсказаниями. Обратите внимание, что модель может ошибаться, даже если она очень уверена.
# Plot the first X test images, their predicted labels, and the true labels.
# Color correct predictions in blue and incorrect predictions in red.
num_rows = 5
num_cols = 3
num_images = num_rows*num_cols
plt.figure(figsize=(2*2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, 2*num_cols, 2*i+1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(num_rows, 2*num_cols, 2*i+2)
plot_value_array(i, predictions[i], test_labels)
plt.tight_layout()
plt.show()

Используйте обученную модель
Наконец, используйте обученную модель, чтобы сделать прогноз для одного изображения.
# Grab an image from the test dataset.
img = test_images[1]
print(img.shape)
(28, 28)
Модели tf.keras оптимизированы для одновременных прогнозов по группе или набору примеров. Соответственно, даже если вы используете одно изображение, вам нужно добавить его в список:
# Add the image to a batch where it's the only member.
img = (np.expand_dims(img,0))
print(img.shape)
(1, 28, 28)
Теперь предскажите правильную метку для этого изображения:
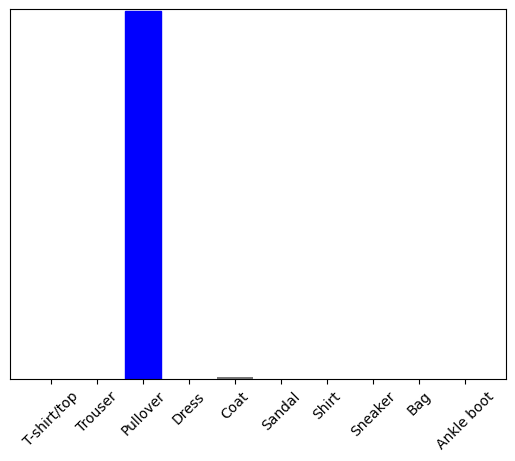
predictions_single = probability_model.predict(img)
print(predictions_single)
[[8.26038831e-06 1.10213664e-13 9.98591125e-01 1.16777841e-08 1.29609776e-03 2.54965649e-11 1.04560357e-04 7.70050608e-19 4.55051066e-11 3.53864888e-17]]
plot_value_array(1, predictions_single[0], test_labels)
_ = plt.xticks(range(10), class_names, rotation=45)
plt.show()
tf.keras.Model.predict возвращает список списков — один список для каждого изображения в пакете данных. Возьмите прогнозы для нашего (единственного) изображения в пакете:
np.argmax(predictions_single[0])
2
И модель предсказывает метку, как и ожидалось.
# MIT License
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.