
| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub |
این آموزش نمونه هایی از نحوه استفاده از داده های CSV با TensorFlow را ارائه می دهد.
این دو بخش اصلی دارد:
- بارگیری داده ها از روی دیسک
- از پیش پردازش آن را به شکل مناسب برای آموزش.
این آموزش بر بارگذاری تمرکز دارد و چند نمونه سریع از پیش پردازش را ارائه می دهد. برای آموزشی که بر جنبه پیش پردازش تمرکز دارد، راهنمای لایه های پیش پردازش و آموزش را ببینید.
برپایی
import pandas as pd
import numpy as np
# Make numpy values easier to read.
np.set_printoptions(precision=3, suppress=True)
import tensorflow as tf
from tensorflow.keras import layers
در داده های حافظه
برای هر مجموعه داده کوچک CSV، ساده ترین راه برای آموزش یک مدل TensorFlow بر روی آن، بارگذاری آن در حافظه به عنوان یک Dataframe پاندا یا یک آرایه NumPy است.
یک مثال نسبتاً ساده مجموعه داده abalone است.
- مجموعه داده کوچک است.
- همه ویژگی های ورودی همه مقادیر ممیز شناور با برد محدود هستند.
در اینجا نحوه بارگیری داده ها در Pandas DataFrame :
abalone_train = pd.read_csv(
"https://storage.googleapis.com/download.tensorflow.org/data/abalone_train.csv",
names=["Length", "Diameter", "Height", "Whole weight", "Shucked weight",
"Viscera weight", "Shell weight", "Age"])
abalone_train.head()
مجموعه داده شامل مجموعه ای از اندازه گیری های آبلون ، نوعی حلزون دریایی است.

"پوسته آبالون" (توسط نیکی دوگان پوگ ، CC BY-SA 2.0)
وظیفه اسمی این مجموعه داده پیش بینی سن از اندازه گیری های دیگر است، بنابراین ویژگی ها و برچسب ها را برای آموزش جدا کنید:
abalone_features = abalone_train.copy()
abalone_labels = abalone_features.pop('Age')
برای این مجموعه داده، با تمام ویژگیها یکسان رفتار میکنید. ویژگی ها را در یک آرایه NumPy بسته بندی کنید.:
abalone_features = np.array(abalone_features)
abalone_features
array([[0.435, 0.335, 0.11 , ..., 0.136, 0.077, 0.097],
[0.585, 0.45 , 0.125, ..., 0.354, 0.207, 0.225],
[0.655, 0.51 , 0.16 , ..., 0.396, 0.282, 0.37 ],
...,
[0.53 , 0.42 , 0.13 , ..., 0.374, 0.167, 0.249],
[0.395, 0.315, 0.105, ..., 0.118, 0.091, 0.119],
[0.45 , 0.355, 0.12 , ..., 0.115, 0.067, 0.16 ]])
سپس یک مدل رگرسیون ایجاد کنید که سن را پیش بینی کند. از آنجایی که تنها یک تانسور ورودی وجود دارد، یک مدل keras.Sequential . Sequential در اینجا کافی است.
abalone_model = tf.keras.Sequential([
layers.Dense(64),
layers.Dense(1)
])
abalone_model.compile(loss = tf.losses.MeanSquaredError(),
optimizer = tf.optimizers.Adam())
برای آموزش آن مدل، ویژگی ها و برچسب ها را به Model.fit :
abalone_model.fit(abalone_features, abalone_labels, epochs=10)
Epoch 1/10 104/104 [==============================] - 1s 2ms/step - loss: 63.0446 Epoch 2/10 104/104 [==============================] - 0s 2ms/step - loss: 11.9429 Epoch 3/10 104/104 [==============================] - 0s 2ms/step - loss: 8.4836 Epoch 4/10 104/104 [==============================] - 0s 2ms/step - loss: 8.0052 Epoch 5/10 104/104 [==============================] - 0s 2ms/step - loss: 7.6073 Epoch 6/10 104/104 [==============================] - 0s 2ms/step - loss: 7.2485 Epoch 7/10 104/104 [==============================] - 0s 2ms/step - loss: 6.9883 Epoch 8/10 104/104 [==============================] - 0s 2ms/step - loss: 6.7977 Epoch 9/10 104/104 [==============================] - 0s 2ms/step - loss: 6.6477 Epoch 10/10 104/104 [==============================] - 0s 2ms/step - loss: 6.5359 <keras.callbacks.History at 0x7f70543c7350>
شما به تازگی ابتدایی ترین راه را برای آموزش یک مدل با استفاده از داده های CSV مشاهده کرده اید. در مرحله بعد، نحوه اعمال پیش پردازش برای عادی سازی ستون های عددی را خواهید آموخت.
پیش پردازش اولیه
این تمرین خوبی است که ورودی های مدل خود را عادی کنید. لایه های پیش پردازش Keras یک راه راحت برای ایجاد این نرمال سازی در مدل شما فراهم می کند.
این لایه میانگین و واریانس هر ستون را از پیش محاسبه می کند و از آنها برای عادی سازی داده ها استفاده می کند.
ابتدا لایه را ایجاد می کنید:
normalize = layers.Normalization()
سپس از متد Normalization.adapt() برای تطبیق لایه نرمال سازی با داده های خود استفاده می کنید.
normalize.adapt(abalone_features)
سپس از لایه نرمال سازی در مدل خود استفاده کنید:
norm_abalone_model = tf.keras.Sequential([
normalize,
layers.Dense(64),
layers.Dense(1)
])
norm_abalone_model.compile(loss = tf.losses.MeanSquaredError(),
optimizer = tf.optimizers.Adam())
norm_abalone_model.fit(abalone_features, abalone_labels, epochs=10)
Epoch 1/10 104/104 [==============================] - 0s 2ms/step - loss: 92.5851 Epoch 2/10 104/104 [==============================] - 0s 2ms/step - loss: 55.1199 Epoch 3/10 104/104 [==============================] - 0s 2ms/step - loss: 18.2937 Epoch 4/10 104/104 [==============================] - 0s 2ms/step - loss: 6.2633 Epoch 5/10 104/104 [==============================] - 0s 2ms/step - loss: 5.1257 Epoch 6/10 104/104 [==============================] - 0s 2ms/step - loss: 5.0217 Epoch 7/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9775 Epoch 8/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9730 Epoch 9/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9348 Epoch 10/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9416 <keras.callbacks.History at 0x7f70541b2a50>
انواع داده های مختلط
مجموعه داده «تایتانیک» حاوی اطلاعاتی درباره مسافران کشتی تایتانیک است. وظیفه اسمی این مجموعه داده این است که پیش بینی کند چه کسی زنده مانده است.

تصویر از ویکی مدیا
{kind=link}
داده های خام را می توان به راحتی به عنوان یک Pandas DataFrame ، اما فوراً به عنوان ورودی مدل TensorFlow قابل استفاده نیست.
titanic = pd.read_csv("https://storage.googleapis.com/tf-datasets/titanic/train.csv")
titanic.head()
titanic_features = titanic.copy()
titanic_labels = titanic_features.pop('survived')
به دلیل انواع داده ها و محدوده های مختلف، نمی توانید به سادگی ویژگی ها را در آرایه NumPy قرار دهید و آن را به یک مدل keras.Sequential کنید. هر ستون باید به صورت جداگانه مدیریت شود.
به عنوان یکی از گزینهها، میتوانید دادههای خود را بهصورت آفلاین (با استفاده از هر ابزاری که دوست دارید) برای تبدیل ستونهای دستهبندی به ستونهای عددی از قبل پردازش کنید، سپس خروجی پردازش شده را به مدل TensorFlow خود منتقل کنید. نقطه ضعف این روش این است که اگر مدل خود را ذخیره و صادر کنید، پیش پردازش با آن ذخیره نمی شود. لایه های پیش پردازش Keras از این مشکل جلوگیری می کنند زیرا آنها بخشی از مدل هستند.
در این مثال، مدلی میسازید که منطق پیشپردازش را با استفاده از API عملکردی Keras پیادهسازی میکند. شما همچنین می توانید این کار را با زیر کلاس بندی انجام دهید.
API عملکردی بر روی تانسورهای "سمبلیک" عمل می کند. تانسورهای معمولی " مشتاق " مقداری دارند. در مقابل این تانسورهای «نمادین» اینطور نیستند. درعوض آنها عملیاتی را که روی آنها اجرا می شود را پیگیری می کنند و نمایشی از محاسبات ایجاد می کنند که می توانید بعداً اجرا کنید. در اینجا یک مثال سریع آورده شده است:
# Create a symbolic input
input = tf.keras.Input(shape=(), dtype=tf.float32)
# Perform a calculation using the input
result = 2*input + 1
# the result doesn't have a value
result
<KerasTensor: shape=(None,) dtype=float32 (created by layer 'tf.__operators__.add')>
calc = tf.keras.Model(inputs=input, outputs=result)
print(calc(1).numpy())
print(calc(2).numpy())
3.0 5.0
برای ساختن مدل پیش پردازش، با ساخت مجموعه ای از keras.Input نمادین شروع کنید. اشیاء ورودی، مطابق با نام ها و انواع داده های ستون های CSV.
inputs = {}
for name, column in titanic_features.items():
dtype = column.dtype
if dtype == object:
dtype = tf.string
else:
dtype = tf.float32
inputs[name] = tf.keras.Input(shape=(1,), name=name, dtype=dtype)
inputs
{'sex': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'sex')>,
'age': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'age')>,
'n_siblings_spouses': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'n_siblings_spouses')>,
'parch': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'parch')>,
'fare': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'fare')>,
'class': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'class')>,
'deck': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'deck')>,
'embark_town': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'embark_town')>,
'alone': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'alone')>}
اولین گام در منطق پیش پردازش شما این است که ورودی های عددی را به هم متصل کنید و آنها را از طریق یک لایه عادی سازی اجرا کنید:
numeric_inputs = {name:input for name,input in inputs.items()
if input.dtype==tf.float32}
x = layers.Concatenate()(list(numeric_inputs.values()))
norm = layers.Normalization()
norm.adapt(np.array(titanic[numeric_inputs.keys()]))
all_numeric_inputs = norm(x)
all_numeric_inputs
<KerasTensor: shape=(None, 4) dtype=float32 (created by layer 'normalization_1')>
تمام نتایج پیش پردازش نمادین را جمع آوری کنید تا بعداً آنها را به هم بچسبانید.
preprocessed_inputs = [all_numeric_inputs]
برای ورودیهای رشته، از تابع tf.keras.layers.StringLookup برای نگاشت از رشتهها به شاخصهای عدد صحیح در یک واژگان استفاده کنید. سپس، از tf.keras.layers.CategoryEncoding برای تبدیل ایندکس ها به داده های float32 مناسب برای مدل استفاده کنید.
تنظیمات پیشفرض برای لایه tf.keras.layers.CategoryEncoding یک بردار یک داغ برای هر ورودی ایجاد میکند. layers.Embedding ها. جاسازی نیز کار خواهد کرد. برای اطلاعات بیشتر در مورد این موضوع، راهنمای لایه های پیش پردازش و آموزش را ببینید.
for name, input in inputs.items():
if input.dtype == tf.float32:
continue
lookup = layers.StringLookup(vocabulary=np.unique(titanic_features[name]))
one_hot = layers.CategoryEncoding(max_tokens=lookup.vocab_size())
x = lookup(input)
x = one_hot(x)
preprocessed_inputs.append(x)
WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead.
با مجموعه inputs و processed_inputs ، میتوانید تمام ورودیهای پیشپردازششده را به هم متصل کنید و مدلی بسازید که پیشپردازش را مدیریت کند:
preprocessed_inputs_cat = layers.Concatenate()(preprocessed_inputs)
titanic_preprocessing = tf.keras.Model(inputs, preprocessed_inputs_cat)
tf.keras.utils.plot_model(model = titanic_preprocessing , rankdir="LR", dpi=72, show_shapes=True)
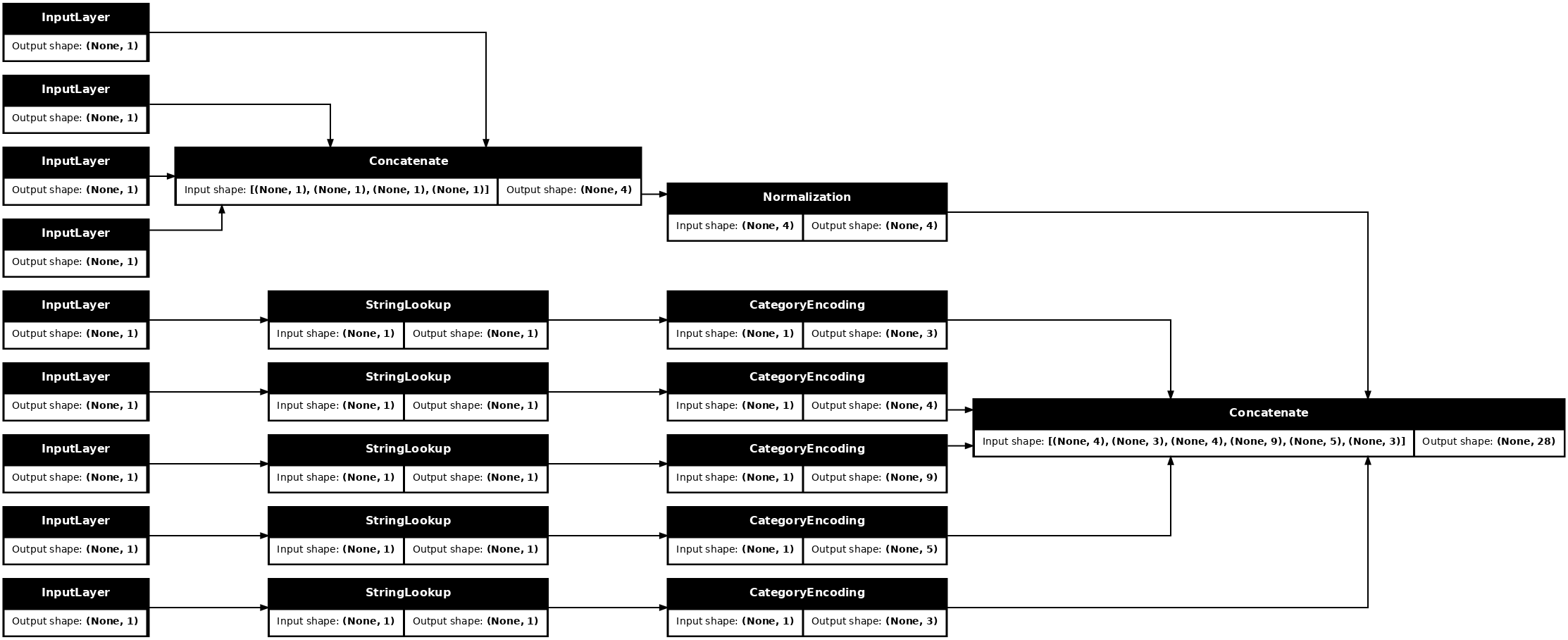
این model فقط شامل پیش پردازش ورودی است. می توانید آن را اجرا کنید تا ببینید با داده های شما چه می کند. مدلهای Keras بهطور خودکار Pandas DataFrames را تبدیل نمیکنند زیرا مشخص نیست که آیا باید به یک تانسور یا به فرهنگ لغت تانسور تبدیل شود. بنابراین آن را به فرهنگ لغت تانسورها تبدیل کنید:
titanic_features_dict = {name: np.array(value)
for name, value in titanic_features.items()}
اولین مثال آموزشی را برش بزنید و آن را به این مدل پیش پردازش منتقل کنید، ویژگی های عددی و رشته های تکی را می بینید که همه به هم پیوسته اند:
features_dict = {name:values[:1] for name, values in titanic_features_dict.items()}
titanic_preprocessing(features_dict)
<tf.Tensor: shape=(1, 28), dtype=float32, numpy=
array([[-0.61 , 0.395, -0.479, -0.497, 0. , 0. , 1. , 0. ,
0. , 0. , 1. , 0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 1. , 0. , 0. , 0. , 1. ,
0. , 0. , 1. , 0. ]], dtype=float32)>
حالا مدل را بالای این بسازید:
def titanic_model(preprocessing_head, inputs):
body = tf.keras.Sequential([
layers.Dense(64),
layers.Dense(1)
])
preprocessed_inputs = preprocessing_head(inputs)
result = body(preprocessed_inputs)
model = tf.keras.Model(inputs, result)
model.compile(loss=tf.losses.BinaryCrossentropy(from_logits=True),
optimizer=tf.optimizers.Adam())
return model
titanic_model = titanic_model(titanic_preprocessing, inputs)
وقتی مدل را آموزش میدهید، فرهنگ لغت ویژگیها را به صورت x و برچسب را به عنوان y ارسال کنید.
titanic_model.fit(x=titanic_features_dict, y=titanic_labels, epochs=10)
Epoch 1/10 20/20 [==============================] - 1s 4ms/step - loss: 0.8017 Epoch 2/10 20/20 [==============================] - 0s 4ms/step - loss: 0.5913 Epoch 3/10 20/20 [==============================] - 0s 5ms/step - loss: 0.5212 Epoch 4/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4841 Epoch 5/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4615 Epoch 6/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4470 Epoch 7/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4367 Epoch 8/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4304 Epoch 9/10 20/20 [==============================] - 0s 4ms/step - loss: 0.4265 Epoch 10/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4239 <keras.callbacks.History at 0x7f70b1f82a50>
از آنجایی که پیش پردازش بخشی از مدل است، می توانید مدل را ذخیره کنید و آن را در جای دیگری بارگذاری مجدد کنید و نتایج یکسانی دریافت کنید:
titanic_model.save('test')
reloaded = tf.keras.models.load_model('test')
2022-01-26 06:36:18.822459: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: test/assets
features_dict = {name:values[:1] for name, values in titanic_features_dict.items()}
before = titanic_model(features_dict)
after = reloaded(features_dict)
assert (before-after)<1e-3
print(before)
print(after)
tf.Tensor([[-1.791]], shape=(1, 1), dtype=float32) tf.Tensor([[-1.791]], shape=(1, 1), dtype=float32)
با استفاده از tf.data
در بخش قبل، در حین آموزش مدل، به ترکیب و دستهبندی دادههای داخلی مدل تکیه کردید.
اگر به کنترل بیشتری روی خط لوله داده های ورودی نیاز دارید یا نیاز به استفاده از داده هایی دارید که به راحتی در حافظه قرار نمی گیرند: از tf.data استفاده کنید.
برای مثالهای بیشتر به راهنمای tf.data مراجعه کنید.
در داده های حافظه روشن است
به عنوان اولین مثال از اعمال tf.data به داده های CSV، کد زیر را برای برش دستی فرهنگ لغت ویژگی های بخش قبل در نظر بگیرید. برای هر شاخص، آن شاخص را برای هر ویژگی می گیرد:
import itertools
def slices(features):
for i in itertools.count():
# For each feature take index `i`
example = {name:values[i] for name, values in features.items()}
yield example
این را اجرا کنید و نمونه اول را چاپ کنید:
for example in slices(titanic_features_dict):
for name, value in example.items():
print(f"{name:19s}: {value}")
break
sex : male age : 22.0 n_siblings_spouses : 1 parch : 0 fare : 7.25 class : Third deck : unknown embark_town : Southampton alone : n
ابتدایی ترین tf.data.Dataset در بارگذار اطلاعات حافظه، سازنده Dataset.from_tensor_slices است. این یک tf.data.Dataset برمی گرداند که یک نسخه تعمیم یافته از تابع slices بالا را در TensorFlow پیاده سازی می کند.
features_ds = tf.data.Dataset.from_tensor_slices(titanic_features_dict)
شما میتوانید روی یک tf.data.Dataset مانند هر پایتون دیگری تکرار کنید:
for example in features_ds:
for name, value in example.items():
print(f"{name:19s}: {value}")
break
sex : b'male' age : 22.0 n_siblings_spouses : 1 parch : 0 fare : 7.25 class : b'Third' deck : b'unknown' embark_town : b'Southampton' alone : b'n'
تابع from_tensor_slices میتواند هر ساختاری از دیکشنریهای تودرتو یا چند تایی را مدیریت کند. کد زیر مجموعه داده ای از جفت (features_dict, labels) می سازد:
titanic_ds = tf.data.Dataset.from_tensor_slices((titanic_features_dict, titanic_labels))
برای آموزش یک مدل با استفاده از این Dataset ، حداقل باید داده ها را به هم shuffle و batch کنید.
titanic_batches = titanic_ds.shuffle(len(titanic_labels)).batch(32)
به جای ارسال features و labels به Model.fit ، مجموعه داده را ارسال میکنید:
titanic_model.fit(titanic_batches, epochs=5)
Epoch 1/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4230 Epoch 2/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4216 Epoch 3/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4203 Epoch 4/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4198 Epoch 5/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4194 <keras.callbacks.History at 0x7f70b12485d0>
از یک فایل
تاکنون این آموزش با داده های درون حافظه کار کرده است. tf.data یک جعبه ابزار بسیار مقیاس پذیر برای ساخت خطوط لوله داده است و عملکردهای کمی برای بارگذاری فایل های CSV ارائه می دهد.
titanic_file_path = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
Downloading data from https://storage.googleapis.com/tf-datasets/titanic/train.csv 32768/30874 [===============================] - 0s 0us/step 40960/30874 [=======================================] - 0s 0us/step
اکنون داده های CSV را از فایل بخوانید و یک tf.data.Dataset ایجاد کنید.
(برای مستندات کامل، tf.data.experimental.make_csv_dataset را ببینید)
titanic_csv_ds = tf.data.experimental.make_csv_dataset(
titanic_file_path,
batch_size=5, # Artificially small to make examples easier to show.
label_name='survived',
num_epochs=1,
ignore_errors=True,)
این عملکرد شامل بسیاری از ویژگی های راحت است، بنابراین کار با داده ها آسان است. این شامل:
- استفاده از سرصفحه ستون به عنوان کلید فرهنگ لغت.
- تعیین خودکار نوع هر ستون.
for batch, label in titanic_csv_ds.take(1):
for key, value in batch.items():
print(f"{key:20s}: {value}")
print()
print(f"{'label':20s}: {label}")
sex : [b'male' b'male' b'female' b'male' b'male'] age : [27. 18. 15. 46. 50.] n_siblings_spouses : [0 0 0 1 0] parch : [0 0 0 0 0] fare : [ 7.896 7.796 7.225 61.175 13. ] class : [b'Third' b'Third' b'Third' b'First' b'Second'] deck : [b'unknown' b'unknown' b'unknown' b'E' b'unknown'] embark_town : [b'Southampton' b'Southampton' b'Cherbourg' b'Southampton' b'Southampton'] alone : [b'y' b'y' b'y' b'n' b'y'] label : [0 0 1 0 0]
همچنین می تواند داده ها را در حین پرواز از حالت فشرده خارج کند. در اینجا یک فایل CSV زیپ شده حاوی مجموعه داده ترافیک بین ایالتی مترو است

تصویر از ویکی مدیا
{kind=link}
traffic_volume_csv_gz = tf.keras.utils.get_file(
'Metro_Interstate_Traffic_Volume.csv.gz',
"https://archive.ics.uci.edu/ml/machine-learning-databases/00492/Metro_Interstate_Traffic_Volume.csv.gz",
cache_dir='.', cache_subdir='traffic')
Downloading data from https://archive.ics.uci.edu/ml/machine-learning-databases/00492/Metro_Interstate_Traffic_Volume.csv.gz 409600/405373 [==============================] - 1s 1us/step 417792/405373 [==============================] - 1s 1us/step
آرگومان compression_type را طوری تنظیم کنید که مستقیماً از فایل فشرده خوانده شود:
traffic_volume_csv_gz_ds = tf.data.experimental.make_csv_dataset(
traffic_volume_csv_gz,
batch_size=256,
label_name='traffic_volume',
num_epochs=1,
compression_type="GZIP")
for batch, label in traffic_volume_csv_gz_ds.take(1):
for key, value in batch.items():
print(f"{key:20s}: {value[:5]}")
print()
print(f"{'label':20s}: {label[:5]}")
holiday : [b'None' b'None' b'None' b'None' b'None'] temp : [280.56 266.79 281.64 292.71 270.48] rain_1h : [0. 0. 0. 0. 0.] snow_1h : [0. 0. 0. 0. 0.] clouds_all : [46 90 90 0 64] weather_main : [b'Clear' b'Clouds' b'Mist' b'Clear' b'Clouds'] weather_description : [b'sky is clear' b'overcast clouds' b'mist' b'Sky is Clear' b'broken clouds'] date_time : [b'2012-11-05 20:00:00' b'2012-12-17 23:00:00' b'2013-10-06 19:00:00' b'2013-08-23 22:00:00' b'2013-11-11 05:00:00'] label : [2415 966 3459 2633 2576]
ذخیره سازی
مقداری سربار برای تجزیه داده های CSV وجود دارد. برای مدل های کوچک این می تواند گلوگاه آموزش باشد.
بسته به مورد استفاده شما، ممکن است ایده خوبی باشد که از Dataset.cache یا data.experimental.snapshot استفاده کنید تا داده های csv فقط در اولین دوره تجزیه شوند.
تفاوت اصلی بین روشهای cache و snapshot در این است که فایلهای cache را فقط میتوان توسط فرآیند TensorFlow که آنها را ایجاد کرده استفاده کرد، اما فایلهای snapshot را میتوان توسط فرآیندهای دیگر خواند.
برای مثال، تکرار ۲۰ بار بر روی traffic_volume_csv_gz_ds ، ~ 15 ثانیه بدون کش کردن، یا ~2 ثانیه با کش کردن طول می کشد.
%%time
for i, (batch, label) in enumerate(traffic_volume_csv_gz_ds.repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
............................................................................................... CPU times: user 14.9 s, sys: 3.7 s, total: 18.6 s Wall time: 11.2 s
%%time
caching = traffic_volume_csv_gz_ds.cache().shuffle(1000)
for i, (batch, label) in enumerate(caching.shuffle(1000).repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
............................................................................................... CPU times: user 1.43 s, sys: 173 ms, total: 1.6 s Wall time: 1.28 s
%%time
snapshot = tf.data.experimental.snapshot('titanic.tfsnap')
snapshotting = traffic_volume_csv_gz_ds.apply(snapshot).shuffle(1000)
for i, (batch, label) in enumerate(snapshotting.shuffle(1000).repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
WARNING:tensorflow:From <timed exec>:1: snapshot (from tensorflow.python.data.experimental.ops.snapshot) is deprecated and will be removed in a future version. Instructions for updating: Use `tf.data.Dataset.snapshot(...)`. ............................................................................................... CPU times: user 2.17 s, sys: 460 ms, total: 2.63 s Wall time: 1.6 s
اگر بارگیری دادههای شما با بارگیری فایلهای csv کند میشود، و cache و snapshot برای مورد استفاده شما کافی نیست، در نظر داشته باشید که دادههای خود را مجدداً در قالبی سادهتر رمزگذاری کنید.
فایل های متعدد
تمام مثالهایی که تاکنون در این بخش آمدهاند به راحتی بدون tf.data قابل انجام هستند. جایی که tf.data واقعاً میتواند کارها را ساده کند، زمانی است که با مجموعهای از فایلها سر و کار دارید.
به عنوان مثال، مجموعه داده تصاویر فونت کاراکتر به صورت مجموعه ای از فایل های csv، یکی در هر فونت، توزیع می شود.

تصویر توسط ویلی هایدلباخ از Pixabay
مجموعه داده را دانلود کنید و به فایل های داخل آن نگاهی بیندازید:
fonts_zip = tf.keras.utils.get_file(
'fonts.zip', "https://archive.ics.uci.edu/ml/machine-learning-databases/00417/fonts.zip",
cache_dir='.', cache_subdir='fonts',
extract=True)
Downloading data from https://archive.ics.uci.edu/ml/machine-learning-databases/00417/fonts.zip 160317440/160313983 [==============================] - 8s 0us/step 160325632/160313983 [==============================] - 8s 0us/step
import pathlib
font_csvs = sorted(str(p) for p in pathlib.Path('fonts').glob("*.csv"))
font_csvs[:10]
['fonts/AGENCY.csv', 'fonts/ARIAL.csv', 'fonts/BAITI.csv', 'fonts/BANKGOTHIC.csv', 'fonts/BASKERVILLE.csv', 'fonts/BAUHAUS.csv', 'fonts/BELL.csv', 'fonts/BERLIN.csv', 'fonts/BERNARD.csv', 'fonts/BITSTREAMVERA.csv']
len(font_csvs)
153
هنگامی که با یک دسته فایل سروکار دارید، می توانید یک file_pattern به سبک glob را به تابع experimental.make_csv_dataset ارسال کنید. ترتیب فایل ها در هر تکرار به هم ریخته می شود.
از آرگومان num_parallel_reads برای تعیین تعداد فایلهایی که به صورت موازی خوانده میشوند و با هم ترکیب میشوند، استفاده کنید.
fonts_ds = tf.data.experimental.make_csv_dataset(
file_pattern = "fonts/*.csv",
batch_size=10, num_epochs=1,
num_parallel_reads=20,
shuffle_buffer_size=10000)
این فایلهای csv تصاویر را در یک ردیف صاف میکنند. نام ستون ها r{row}c{column} فرمت بندی شده اند. در اینجا اولین دسته است:
for features in fonts_ds.take(1):
for i, (name, value) in enumerate(features.items()):
if i>15:
break
print(f"{name:20s}: {value}")
print('...')
print(f"[total: {len(features)} features]")
font : [b'HANDPRINT' b'NIAGARA' b'EUROROMAN' b'NIAGARA' b'CENTAUR' b'NINA' b'GOUDY' b'SITKA' b'BELL' b'SITKA'] fontVariant : [b'scanned' b'NIAGARA SOLID' b'EUROROMAN' b'NIAGARA SOLID' b'CENTAUR' b'NINA' b'GOUDY STOUT' b'SITKA TEXT' b'BELL MT' b'SITKA TEXT'] m_label : [ 49 8482 245 88 174 9643 77 974 117 339] strength : [0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4] italic : [0 0 0 1 0 0 1 0 1 0] orientation : [0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] m_top : [ 0 32 24 32 28 57 38 48 51 64] m_left : [ 0 20 24 20 22 24 27 23 25 23] originalH : [20 27 55 47 50 15 51 50 27 34] originalW : [ 4 33 25 33 50 15 116 43 28 53] h : [20 20 20 20 20 20 20 20 20 20] w : [20 20 20 20 20 20 20 20 20 20] r0c0 : [ 1 255 255 1 1 255 1 1 1 1] r0c1 : [ 1 255 255 1 1 255 1 1 1 1] r0c2 : [ 1 217 255 1 1 255 54 1 1 1] r0c3 : [ 1 213 255 1 1 255 255 1 1 64] ... [total: 412 features]
اختیاری: زمینه های بسته بندی
احتمالاً نمی خواهید با هر پیکسل در ستون های جداگانه مانند این کار کنید. قبل از استفاده از این مجموعه داده، مطمئن شوید که پیکسل ها را در یک تانسور تصویر بسته بندی کنید.
در اینجا کدی وجود دارد که نام ستون ها را برای ساخت تصاویر برای هر مثال تجزیه می کند:
import re
def make_images(features):
image = [None]*400
new_feats = {}
for name, value in features.items():
match = re.match('r(\d+)c(\d+)', name)
if match:
image[int(match.group(1))*20+int(match.group(2))] = value
else:
new_feats[name] = value
image = tf.stack(image, axis=0)
image = tf.reshape(image, [20, 20, -1])
new_feats['image'] = image
return new_feats
این تابع را برای هر دسته در مجموعه داده اعمال کنید:
fonts_image_ds = fonts_ds.map(make_images)
for features in fonts_image_ds.take(1):
break
تصاویر حاصل را رسم کنید:
from matplotlib import pyplot as plt
plt.figure(figsize=(6,6), dpi=120)
for n in range(9):
plt.subplot(3,3,n+1)
plt.imshow(features['image'][..., n])
plt.title(chr(features['m_label'][n]))
plt.axis('off')

توابع سطح پایین تر
تاکنون این آموزش بر روی بالاترین سطح ابزار برای خواندن داده های csv متمرکز شده است. اگر مورد استفاده شما با الگوهای اولیه مطابقت نداشته باشد، دو API دیگر وجود دارد که ممکن است برای کاربران پیشرفته مفید باشد.
-
tf.io.decode_csv- تابعی برای تجزیه خطوط متن به لیستی از تانسورهای ستون CSV. -
tf.data.experimental.CsvDataset- سازنده مجموعه داده csv سطح پایین تر.
این بخش عملکرد ارائه شده توسط make_csv_dataset را دوباره ایجاد می کند تا نشان دهد چگونه می توان از این عملکرد سطح پایین تر استفاده کرد.
tf.io.decode_csv
این تابع یک رشته یا لیست رشته ها را به لیستی از ستون ها رمزگشایی می کند.
برخلاف make_csv_dataset این تابع سعی نمیکند تا انواع دادههای ستون را حدس بزند. انواع ستون ها را با ارائه لیستی از record_defaults حاوی مقداری از نوع صحیح برای هر ستون مشخص می کنید.
برای خواندن داده های تایتانیک به عنوان رشته با استفاده از decode_csv می توانید بگویید:
text = pathlib.Path(titanic_file_path).read_text()
lines = text.split('\n')[1:-1]
all_strings = [str()]*10
all_strings
['', '', '', '', '', '', '', '', '', '']
features = tf.io.decode_csv(lines, record_defaults=all_strings)
for f in features:
print(f"type: {f.dtype.name}, shape: {f.shape}")
type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,)
برای تجزیه آنها با انواع واقعی آنها، لیستی از record_defaults از انواع مربوطه ایجاد کنید:
print(lines[0])
0,male,22.0,1,0,7.25,Third,unknown,Southampton,n
titanic_types = [int(), str(), float(), int(), int(), float(), str(), str(), str(), str()]
titanic_types
[0, '', 0.0, 0, 0, 0.0, '', '', '', '']
features = tf.io.decode_csv(lines, record_defaults=titanic_types)
for f in features:
print(f"type: {f.dtype.name}, shape: {f.shape}")
type: int32, shape: (627,) type: string, shape: (627,) type: float32, shape: (627,) type: int32, shape: (627,) type: int32, shape: (627,) type: float32, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,)
tf.data.experimental.CsvDataset
کلاس tf.data.experimental.CsvDataset یک رابط حداقلی CSV Dataset را بدون ویژگیهای راحت تابع make_csv_dataset فراهم میکند: تجزیه سرصفحه ستون، استنتاج نوع ستون، درهمرفتن خودکار، درهمآمیزی فایل.
این سازنده از io.parse_csv record_defaults می کند:
simple_titanic = tf.data.experimental.CsvDataset(titanic_file_path, record_defaults=titanic_types, header=True)
for example in simple_titanic.take(1):
print([e.numpy() for e in example])
[0, b'male', 22.0, 1, 0, 7.25, b'Third', b'unknown', b'Southampton', b'n']
کد بالا در اصل معادل است با:
def decode_titanic_line(line):
return tf.io.decode_csv(line, titanic_types)
manual_titanic = (
# Load the lines of text
tf.data.TextLineDataset(titanic_file_path)
# Skip the header row.
.skip(1)
# Decode the line.
.map(decode_titanic_line)
)
for example in manual_titanic.take(1):
print([e.numpy() for e in example])
[0, b'male', 22.0, 1, 0, 7.25, b'Third', b'unknown', b'Southampton', b'n']
فایل های متعدد
برای تجزیه مجموعه فونت ها با استفاده از experimental.CsvDataset ، ابتدا باید انواع ستون ها را برای record_defaults تعیین کنید. با بررسی ردیف اول یک فایل شروع کنید:
font_line = pathlib.Path(font_csvs[0]).read_text().splitlines()[1]
print(font_line)
AGENCY,AGENCY FB,64258,0.400000,0,0.000000,35,21,51,22,20,20,1,1,1,21,101,210,255,255,255,255,255,255,255,255,255,255,255,255,255,255,1,1,1,93,255,255,255,176,146,146,146,146,146,146,146,146,216,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,141,141,141,182,255,255,255,172,141,141,141,115,1,1,1,1,163,255,255,255,255,255,255,255,255,255,255,255,255,255,255,209,1,1,1,1,163,255,255,255,6,6,6,96,255,255,255,74,6,6,6,5,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255
فقط دو فیلد اول رشته هستند، بقیه فیلدهای داخلی یا شناور هستند و با شمارش کاما می توانید تعداد کل ویژگی ها را بدست آورید:
num_font_features = font_line.count(',')+1
font_column_types = [str(), str()] + [float()]*(num_font_features-2)
سازنده CsvDatasaet می تواند لیستی از فایل های ورودی را بگیرد، اما آنها را به صورت متوالی می خواند. اولین فایل در لیست CSV ها AGENCY.csv است:
font_csvs[0]
'fonts/AGENCY.csv'
بنابراین وقتی لیست فایل ها را به CsvDataaset می دهید، سوابق AGENCY.csv ابتدا خوانده می شوند:
simple_font_ds = tf.data.experimental.CsvDataset(
font_csvs,
record_defaults=font_column_types,
header=True)
for row in simple_font_ds.take(10):
print(row[0].numpy())
b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY'
برای بهم پیوستن چندین فایل، از Dataset.interleave استفاده کنید.
در اینجا یک مجموعه داده اولیه است که حاوی نام فایل csv است:
font_files = tf.data.Dataset.list_files("fonts/*.csv")
این نام فایل هر دوره را به هم می زند:
print('Epoch 1:')
for f in list(font_files)[:5]:
print(" ", f.numpy())
print(' ...')
print()
print('Epoch 2:')
for f in list(font_files)[:5]:
print(" ", f.numpy())
print(' ...')
Epoch 1:
b'fonts/CORBEL.csv'
b'fonts/GLOUCESTER.csv'
b'fonts/GABRIOLA.csv'
b'fonts/FORTE.csv'
b'fonts/GILL.csv'
...
Epoch 2:
b'fonts/MONEY.csv'
b'fonts/ISOC.csv'
b'fonts/DUTCH801.csv'
b'fonts/CALIBRI.csv'
b'fonts/ROMANTIC.csv'
...
متد interleave یک map_func می گیرد که برای هر عنصر از Dataset پدر یک Dataset فرزند ایجاد می کند.
در اینجا، شما می خواهید از هر عنصر مجموعه داده فایل ها یک CsvDataset ایجاد کنید:
def make_font_csv_ds(path):
return tf.data.experimental.CsvDataset(
path,
record_defaults=font_column_types,
header=True)
Dataset ای که توسط interleave بازگردانده شده است، عناصر را با چرخش روی تعدادی از Dataset های فرزند برمی گرداند. توجه داشته باشید، در زیر، نحوه چرخش مجموعه داده بر روی cycle_length=3 سه فایل فونت:
font_rows = font_files.interleave(make_font_csv_ds,
cycle_length=3)
fonts_dict = {'font_name':[], 'character':[]}
for row in font_rows.take(10):
fonts_dict['font_name'].append(row[0].numpy().decode())
fonts_dict['character'].append(chr(row[2].numpy()))
pd.DataFrame(fonts_dict)
کارایی
قبلاً اشاره شد که io.decode_csv هنگام اجرا بر روی یک دسته از رشته ها کارآمدتر است.
هنگام استفاده از اندازههای دستهای بزرگ، میتوان از این واقعیت برای بهبود عملکرد بارگیری CSV استفاده کرد (اما ابتدا سعی کنید حافظه پنهان را ذخیره کنید).
با لودر داخلی 20، دسته های نمونه 2048 حدود 17 ثانیه طول می کشد.
BATCH_SIZE=2048
fonts_ds = tf.data.experimental.make_csv_dataset(
file_pattern = "fonts/*.csv",
batch_size=BATCH_SIZE, num_epochs=1,
num_parallel_reads=100)
%%time
for i,batch in enumerate(fonts_ds.take(20)):
print('.',end='')
print()
.................... CPU times: user 24.3 s, sys: 1.46 s, total: 25.7 s Wall time: 10.9 s
ارسال دستهای از خطوط متن به decode_csv سریعتر در حدود 5 ثانیه اجرا میشود:
fonts_files = tf.data.Dataset.list_files("fonts/*.csv")
fonts_lines = fonts_files.interleave(
lambda fname:tf.data.TextLineDataset(fname).skip(1),
cycle_length=100).batch(BATCH_SIZE)
fonts_fast = fonts_lines.map(lambda x: tf.io.decode_csv(x, record_defaults=font_column_types))
%%time
for i,batch in enumerate(fonts_fast.take(20)):
print('.',end='')
print()
.................... CPU times: user 8.77 s, sys: 0 ns, total: 8.77 s Wall time: 1.57 s
برای مثال دیگری از افزایش عملکرد csv با استفاده از دسته های بزرگ، آموزش overfit و underfit را ببینید.
این نوع رویکرد ممکن است کارساز باشد، اما گزینههای دیگری مانند cache و snapshot یا رمزگذاری مجدد دادههای خود را در قالبی سادهتر در نظر بگیرید.