
| | |  GitHub पर स्रोत देखें GitHub पर स्रोत देखें | |
यह ट्यूटोरियल दिखाता है कि किसी छवि डेटासेट को तीन तरीकों से कैसे लोड और प्रीप्रोसेस किया जाए:
- सबसे पहले, आप डिस्क पर छवियों की निर्देशिका को पढ़ने के लिए उच्च-स्तरीय केरस प्रीप्रोसेसिंग उपयोगिताओं (जैसे
tf.keras.utils.image_dataset_from_directory) और परतों (जैसेtf.keras.layers.Rescaling) का उपयोग करेंगे। - इसके बाद, आप tf.data का उपयोग करके स्क्रैच से अपनी खुद की इनपुट पाइपलाइन लिखेंगे।
- अंत में, आप TensorFlow Datasets में उपलब्ध बड़े कैटलॉग से एक डेटासेट डाउनलोड करेंगे।
सेट अप
import numpy as np
import os
import PIL
import PIL.Image
import tensorflow as tf
import tensorflow_datasets as tfds
print(tf.__version__)
2.8.0-rc1
फूल डेटासेट डाउनलोड करें
यह ट्यूटोरियल फूलों की कई हज़ार तस्वीरों के डेटासेट का उपयोग करता है। फूल डेटासेट में पाँच उप-निर्देशिकाएँ होती हैं, एक प्रति वर्ग:
flowers_photos/
daisy/
dandelion/
roses/
sunflowers/
tulips/
import pathlib
dataset_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz"
data_dir = tf.keras.utils.get_file(origin=dataset_url,
fname='flower_photos',
untar=True)
data_dir = pathlib.Path(data_dir)
डाउनलोड करने के बाद (218MB), अब आपके पास फूलों की तस्वीरों की एक प्रति उपलब्ध होनी चाहिए। कुल 3,670 चित्र हैं:
image_count = len(list(data_dir.glob('*/*.jpg')))
print(image_count)
3670
प्रत्येक निर्देशिका में उस प्रकार के फूल के चित्र होते हैं। यहाँ कुछ गुलाब हैं:
roses = list(data_dir.glob('roses/*'))
PIL.Image.open(str(roses[0]))

roses = list(data_dir.glob('roses/*'))
PIL.Image.open(str(roses[1]))

Keras उपयोगिता का उपयोग करके डेटा लोड करें
आइए इन छवियों को सहायक tf.keras.utils.image_dataset_from_directory उपयोगिता का उपयोग करके डिस्क से लोड करें।
डेटासेट बनाएं
लोडर के लिए कुछ पैरामीटर परिभाषित करें:
batch_size = 32
img_height = 180
img_width = 180
अपना मॉडल विकसित करते समय सत्यापन विभाजन का उपयोग करना एक अच्छा अभ्यास है। आप प्रशिक्षण के लिए 80% छवियों और सत्यापन के लिए 20% का उपयोग करेंगे।
train_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 3670 files belonging to 5 classes. Using 2936 files for training.
val_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 3670 files belonging to 5 classes. Using 734 files for validation.
आप इन डेटासेट पर class_names विशेषता में वर्ग के नाम पा सकते हैं।
class_names = train_ds.class_names
print(class_names)
['daisy', 'dandelion', 'roses', 'sunflowers', 'tulips']
डेटा विज़ुअलाइज़ करें
प्रशिक्षण डेटासेट से पहली नौ छवियां यहां दी गई हैं।
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 10))
for images, labels in train_ds.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
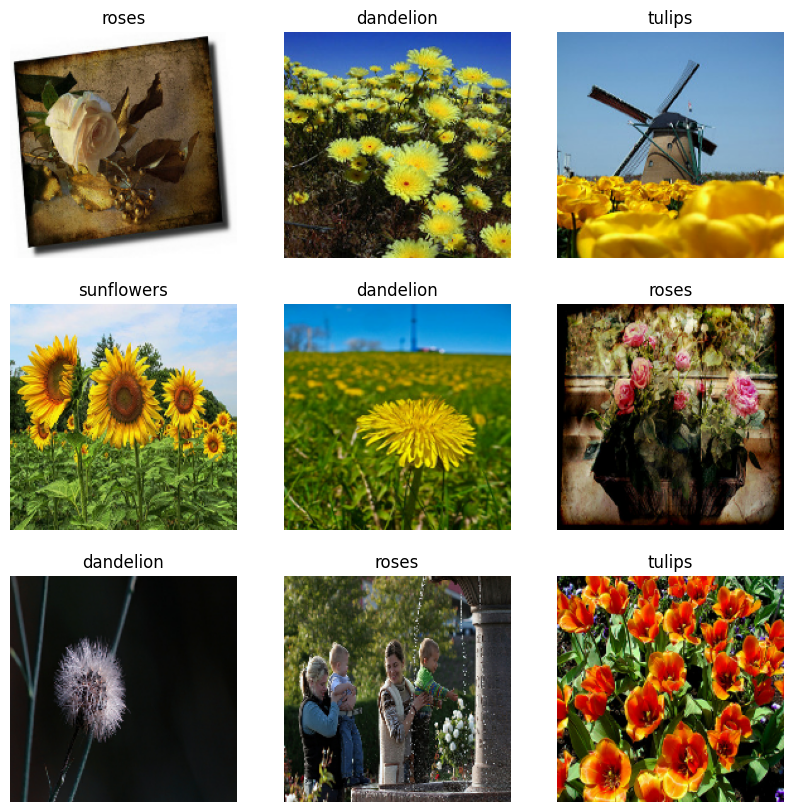
आप इन डेटासेट का उपयोग करके एक मॉडल को model.fit (इस ट्यूटोरियल में बाद में दिखाया गया है) को पास करके प्रशिक्षित कर सकते हैं। यदि आप चाहें, तो आप डेटासेट पर मैन्युअल रूप से पुनरावृति भी कर सकते हैं और छवियों के बैचों को पुनः प्राप्त कर सकते हैं:
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
(32, 180, 180, 3) (32,)
image_batch आकार का एक टेंसर है (32, 180, 180, 3) । यह 180x180x3 आकार की 32 छवियों का एक बैच है (अंतिम आयाम रंग चैनल आरजीबी को संदर्भित करता है)। label_batch आकार (32,) का एक टेंसर है, ये 32 छवियों के अनुरूप लेबल हैं।
आप इनमें से किसी भी टेंसर को numpy.ndarray में बदलने के लिए .numpy() पर कॉल कर सकते हैं।
डेटा को मानकीकृत करें
RGB चैनल मान [0, 255] रेंज में हैं। यह एक तंत्रिका नेटवर्क के लिए आदर्श नहीं है; सामान्य तौर पर आपको अपने इनपुट मूल्यों को छोटा बनाना चाहिए।
यहां, आप tf.keras.layers.Rescaling का उपयोग करके मानों को [0, 1] श्रेणी में मानकीकृत करेंगे:
normalization_layer = tf.keras.layers.Rescaling(1./255)
इस परत का उपयोग करने के दो तरीके हैं। आप इसे Dataset.map पर कॉल करके डेटासेट पर लागू कर सकते हैं:
normalized_ds = train_ds.map(lambda x, y: (normalization_layer(x), y))
image_batch, labels_batch = next(iter(normalized_ds))
first_image = image_batch[0]
# Notice the pixel values are now in `[0,1]`.
print(np.min(first_image), np.max(first_image))
0.0 0.96902645प्लेसहोल्डर22
या, आप परिनियोजन को आसान बनाने के लिए अपनी मॉडल परिभाषा के अंदर परत शामिल कर सकते हैं। आप यहां दूसरे दृष्टिकोण का उपयोग करेंगे।
प्रदर्शन के लिए डेटासेट कॉन्फ़िगर करें
आइए बफ़र्ड प्रीफ़ेचिंग का उपयोग करना सुनिश्चित करें ताकि आप I/O को ब्लॉक किए बिना डिस्क से डेटा प्राप्त कर सकें। डेटा लोड करते समय आपको इन दो महत्वपूर्ण विधियों का उपयोग करना चाहिए:
-
Dataset.cacheपहले युग के दौरान डिस्क से लोड होने के बाद छवियों को स्मृति में रखता है। यह सुनिश्चित करेगा कि आपके मॉडल को प्रशिक्षित करते समय डेटासेट एक अड़चन न बने। यदि आपका डेटासेट मेमोरी में फ़िट होने के लिए बहुत बड़ा है, तो आप इस विधि का उपयोग डिस्क पर परफ़ॉर्मेंट कैश बनाने के लिए भी कर सकते हैं। -
Dataset.prefetchप्रशिक्षण के दौरान डेटा प्रीप्रोसेसिंग और मॉडल निष्पादन को ओवरलैप करता है।
इच्छुक पाठक tf.data API मार्गदर्शिका के साथ बेहतर प्रदर्शन के प्रीफ़ेचिंग अनुभाग में दोनों विधियों के साथ-साथ डिस्क पर डेटा कैश करने के तरीके के बारे में अधिक जान सकते हैं।
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
एक मॉडल को प्रशिक्षित करें
पूर्णता के लिए, आप दिखाएंगे कि आपने अभी-अभी तैयार किए गए डेटासेट का उपयोग करके एक साधारण मॉडल को कैसे प्रशिक्षित किया जाए।
अनुक्रमिक मॉडल में तीन कनवल्शन ब्लॉक होते हैं ( tf.keras.layers.Conv2D ) जिनमें से प्रत्येक में अधिकतम पूलिंग परत ( tf.keras.layers.MaxPooling2D ) होती है। एक पूरी तरह से जुड़ी हुई परत है ( tf.keras.layers.Dense ) जिसके ऊपर 128 इकाइयाँ हैं जो एक ReLU सक्रियण फ़ंक्शन ( 'relu' ) द्वारा सक्रिय है। इस मॉडल को किसी भी तरह से ट्यून नहीं किया गया है—लक्ष्य आपके द्वारा अभी बनाए गए डेटासेट का उपयोग करके आपको यांत्रिकी दिखाना है। छवि वर्गीकरण के बारे में अधिक जानने के लिए, छवि वर्गीकरण ट्यूटोरियल पर जाएँ।
num_classes = 5
model = tf.keras.Sequential([
tf.keras.layers.Rescaling(1./255),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(num_classes)
])
tf.keras.optimizers.Adam ऑप्टिमाइज़र और tf.keras.losses.SparseCategoricalCrossentropy loss function चुनें। प्रत्येक प्रशिक्षण युग के लिए प्रशिक्षण और सत्यापन सटीकता देखने के लिए, metrics तर्क को Model.compile पर पास करें।
model.compile(
optimizer='adam',
loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(
train_ds,
validation_data=val_ds,
epochs=3
)
Epoch 1/3 92/92 [==============================] - 4s 21ms/step - loss: 1.3091 - accuracy: 0.4281 - val_loss: 1.0982 - val_accuracy: 0.5599 Epoch 2/3 92/92 [==============================] - 1s 12ms/step - loss: 1.0196 - accuracy: 0.5879 - val_loss: 0.9572 - val_accuracy: 0.6213 Epoch 3/3 92/92 [==============================] - 1s 12ms/step - loss: 0.8455 - accuracy: 0.6775 - val_loss: 0.8839 - val_accuracy: 0.6512 <keras.callbacks.History at 0x7ff10c168850>
आप देख सकते हैं कि प्रशिक्षण सटीकता की तुलना में सत्यापन सटीकता कम है, यह दर्शाता है कि आपका मॉडल ओवरफिटिंग है। आप इस ट्यूटोरियल में ओवरफिटिंग और इसे कम करने के तरीके के बारे में अधिक जान सकते हैं।
बेहतर नियंत्रण के लिए tf.data का उपयोग करना
उपरोक्त केरस प्रीप्रोसेसिंग उपयोगिता- tf.keras.utils.image_dataset_from_directory - छवियों की निर्देशिका से tf.data.Dataset बनाने का एक सुविधाजनक तरीका है।
बेहतर अनाज नियंत्रण के लिए, आप tf.data का उपयोग करके अपनी खुद की इनपुट पाइपलाइन लिख सकते हैं। यह खंड दिखाता है कि यह कैसे करना है, जिसकी शुरुआत आपके द्वारा पहले डाउनलोड की गई TGZ फ़ाइल के फ़ाइल पथों से होती है।
list_ds = tf.data.Dataset.list_files(str(data_dir/'*/*'), shuffle=False)
list_ds = list_ds.shuffle(image_count, reshuffle_each_iteration=False)
for f in list_ds.take(5):
print(f.numpy())
b'/home/kbuilder/.keras/datasets/flower_photos/roses/14267691818_301aceda07.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/daisy/2641151167_3bf1349606_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/sunflowers/6495554833_86eb8faa8e_n.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/tulips/4578030672_e6aefd45af.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/dandelion/144686365_d7e96941ee_n.jpg'
फ़ाइलों की ट्री संरचना का उपयोग class_names सूची को संकलित करने के लिए किया जा सकता है।
class_names = np.array(sorted([item.name for item in data_dir.glob('*') if item.name != "LICENSE.txt"]))
print(class_names)
['daisy' 'dandelion' 'roses' 'sunflowers' 'tulips']
डेटासेट को प्रशिक्षण और सत्यापन सेट में विभाजित करें:
val_size = int(image_count * 0.2)
train_ds = list_ds.skip(val_size)
val_ds = list_ds.take(val_size)
आप प्रत्येक डेटासेट की लंबाई इस प्रकार प्रिंट कर सकते हैं:
print(tf.data.experimental.cardinality(train_ds).numpy())
print(tf.data.experimental.cardinality(val_ds).numpy())
2936 734
एक छोटा फ़ंक्शन लिखें जो फ़ाइल पथ को एक (img, label) जोड़ी में परिवर्तित करता है:
def get_label(file_path):
# Convert the path to a list of path components
parts = tf.strings.split(file_path, os.path.sep)
# The second to last is the class-directory
one_hot = parts[-2] == class_names
# Integer encode the label
return tf.argmax(one_hot)
def decode_img(img):
# Convert the compressed string to a 3D uint8 tensor
img = tf.io.decode_jpeg(img, channels=3)
# Resize the image to the desired size
return tf.image.resize(img, [img_height, img_width])
def process_path(file_path):
label = get_label(file_path)
# Load the raw data from the file as a string
img = tf.io.read_file(file_path)
img = decode_img(img)
return img, label
image, label जोड़े का डेटासेट बनाने के लिए Dataset.map का उपयोग करें:
# Set `num_parallel_calls` so multiple images are loaded/processed in parallel.
train_ds = train_ds.map(process_path, num_parallel_calls=AUTOTUNE)
val_ds = val_ds.map(process_path, num_parallel_calls=AUTOTUNE)
for image, label in train_ds.take(1):
print("Image shape: ", image.numpy().shape)
print("Label: ", label.numpy())
Image shape: (180, 180, 3) Label: 1
प्रदर्शन के लिए डेटासेट कॉन्फ़िगर करें
इस डेटासेट के साथ एक मॉडल को प्रशिक्षित करने के लिए आपको डेटा चाहिए:
- अच्छी तरह से फेंटना।
- बैच किया जाना है।
- बैच यथाशीघ्र उपलब्ध कराये जायें।
इन सुविधाओं को tf.data API का उपयोग करके जोड़ा जा सकता है। अधिक जानकारी के लिए, इनपुट पाइपलाइन प्रदर्शन मार्गदर्शिका देखें।
def configure_for_performance(ds):
ds = ds.cache()
ds = ds.shuffle(buffer_size=1000)
ds = ds.batch(batch_size)
ds = ds.prefetch(buffer_size=AUTOTUNE)
return ds
train_ds = configure_for_performance(train_ds)
val_ds = configure_for_performance(val_ds)
डेटा विज़ुअलाइज़ करें
आप इस डेटासेट की कल्पना उसी तरह कर सकते हैं जैसे आपने पहले बनाया था:
image_batch, label_batch = next(iter(train_ds))
plt.figure(figsize=(10, 10))
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(image_batch[i].numpy().astype("uint8"))
label = label_batch[i]
plt.title(class_names[label])
plt.axis("off")
2022-01-26 06:29:45.209901: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
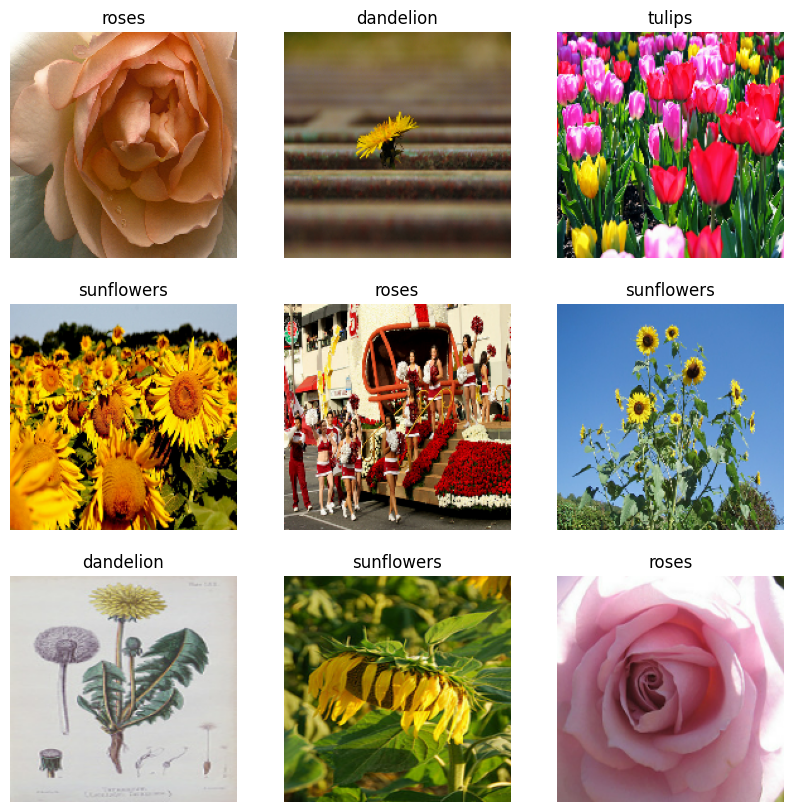
मॉडल का प्रशिक्षण जारी रखें
अब आपने ऊपर tf.keras.utils.image_dataset_from_directory द्वारा बनाए गए एक समान tf.data.Dataset को मैन्युअल रूप से बनाया है। आप इसके साथ मॉडल का प्रशिक्षण जारी रख सकते हैं। पहले की तरह, आप दौड़ने के समय को कम रखने के लिए कुछ ही युगों के लिए प्रशिक्षण लेंगे।
model.fit(
train_ds,
validation_data=val_ds,
epochs=3
)
Epoch 1/3 92/92 [==============================] - 3s 21ms/step - loss: 0.7305 - accuracy: 0.7245 - val_loss: 0.7311 - val_accuracy: 0.7139 Epoch 2/3 92/92 [==============================] - 1s 13ms/step - loss: 0.5279 - accuracy: 0.8069 - val_loss: 0.7021 - val_accuracy: 0.7316 Epoch 3/3 92/92 [==============================] - 1s 13ms/step - loss: 0.3739 - accuracy: 0.8644 - val_loss: 0.8266 - val_accuracy: 0.6948 <keras.callbacks.History at 0x7ff0ee071f10>
TensorFlow डेटासेट का उपयोग करना
अब तक, इस ट्यूटोरियल ने डिस्क से डेटा लोड करने पर ध्यान केंद्रित किया है। आप TensorFlow Datasets पर डाउनलोड करने में आसान डेटासेट के बड़े कैटलॉग को एक्सप्लोर करके उपयोग करने के लिए डेटासेट भी ढूंढ सकते हैं।
जैसा कि आपने पहले फ्लावर डेटासेट को डिस्क से लोड किया है, चलिए अब इसे TensorFlow डेटासेट के साथ आयात करते हैं।
TensorFlow डेटासेट का उपयोग करके फूल डेटासेट डाउनलोड करें:
(train_ds, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
फूल डेटासेट में पाँच वर्ग होते हैं:
num_classes = metadata.features['label'].num_classes
print(num_classes)
5
डेटासेट से एक छवि पुनर्प्राप्त करें:
get_label_name = metadata.features['label'].int2str
image, label = next(iter(train_ds))
_ = plt.imshow(image)
_ = plt.title(get_label_name(label))
2022-01-26 06:29:54.281352: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.

पहले की तरह, प्रदर्शन के लिए प्रशिक्षण, सत्यापन और परीक्षण सेट को बैच, फेरबदल और कॉन्फ़िगर करना याद रखें:
train_ds = configure_for_performance(train_ds)
val_ds = configure_for_performance(val_ds)
test_ds = configure_for_performance(test_ds)
आप डेटा वृद्धि ट्यूटोरियल पर जाकर फ़्लॉवर डेटासेट और TensorFlow डेटासेट के साथ काम करने का एक पूरा उदाहरण पा सकते हैं।
अगले कदम
इस ट्यूटोरियल ने डिस्क से छवियों को लोड करने के दो तरीके दिखाए। सबसे पहले, आपने सीखा कि कैसे केरस प्रीप्रोसेसिंग परतों और उपयोगिताओं का उपयोग करके एक छवि डेटासेट को लोड और प्रीप्रोसेस करना है। इसके बाद, आपने सीखा कि tf.data का उपयोग करके स्क्रैच से इनपुट पाइपलाइन कैसे लिखना है। अंत में, आपने सीखा कि TensorFlow डेटासेट से डेटासेट कैसे डाउनलोड करें।
आपके अगले चरणों के लिए:
- आप डेटा संवर्द्धन जोड़ना सीख सकते हैं।
-
tf.dataपर जा सकते हैं : TensorFlow इनपुट पाइपलाइन गाइड बनाएँ ।