
| | |  Lihat sumber di GitHub Lihat sumber di GitHub | |
Tutorial ini menunjukkan cara memuat dan melakukan praproses dataset gambar dalam tiga cara:
- Pertama, Anda akan menggunakan utilitas prapemrosesan Keras tingkat tinggi (seperti
tf.keras.utils.image_dataset_from_directory) dan lapisan (sepertitf.keras.layers.Rescaling) untuk membaca direktori gambar pada disk. - Selanjutnya, Anda akan menulis saluran input Anda sendiri dari awal menggunakan tf.data .
- Terakhir, Anda akan mendownload kumpulan data dari katalog besar yang tersedia di TensorFlow Datasets .
Mempersiapkan
import numpy as np
import os
import PIL
import PIL.Image
import tensorflow as tf
import tensorflow_datasets as tfds
print(tf.__version__)
2.8.0-rc1
Unduh kumpulan data bunga
Tutorial ini menggunakan kumpulan data beberapa ribu foto bunga. Dataset bunga berisi lima sub-direktori, satu per kelas:
flowers_photos/
daisy/
dandelion/
roses/
sunflowers/
tulips/
import pathlib
dataset_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz"
data_dir = tf.keras.utils.get_file(origin=dataset_url,
fname='flower_photos',
untar=True)
data_dir = pathlib.Path(data_dir)
Setelah mengunduh (218MB), Anda sekarang harus memiliki salinan foto bunga yang tersedia. Ada 3.670 total gambar:
image_count = len(list(data_dir.glob('*/*.jpg')))
print(image_count)
3670
Setiap direktori berisi gambar dari jenis bunga tersebut. Berikut beberapa bunga mawar:
roses = list(data_dir.glob('roses/*'))
PIL.Image.open(str(roses[0]))

roses = list(data_dir.glob('roses/*'))
PIL.Image.open(str(roses[1]))

Muat data menggunakan utilitas Keras
Mari muat gambar-gambar ini dari disk menggunakan utilitas tf.keras.utils.image_dataset_from_directory yang bermanfaat.
Buat kumpulan data
Tentukan beberapa parameter untuk loader:
batch_size = 32
img_height = 180
img_width = 180
Ini adalah praktik yang baik untuk menggunakan pemisahan validasi saat mengembangkan model Anda. Anda akan menggunakan 80% gambar untuk pelatihan dan 20% untuk validasi.
train_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 3670 files belonging to 5 classes. Using 2936 files for training.
val_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 3670 files belonging to 5 classes. Using 734 files for validation.
Anda dapat menemukan nama kelas di atribut class_names pada kumpulan data ini.
class_names = train_ds.class_names
print(class_names)
['daisy', 'dandelion', 'roses', 'sunflowers', 'tulips']
Visualisasikan datanya
Berikut adalah sembilan gambar pertama dari dataset pelatihan.
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 10))
for images, labels in train_ds.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
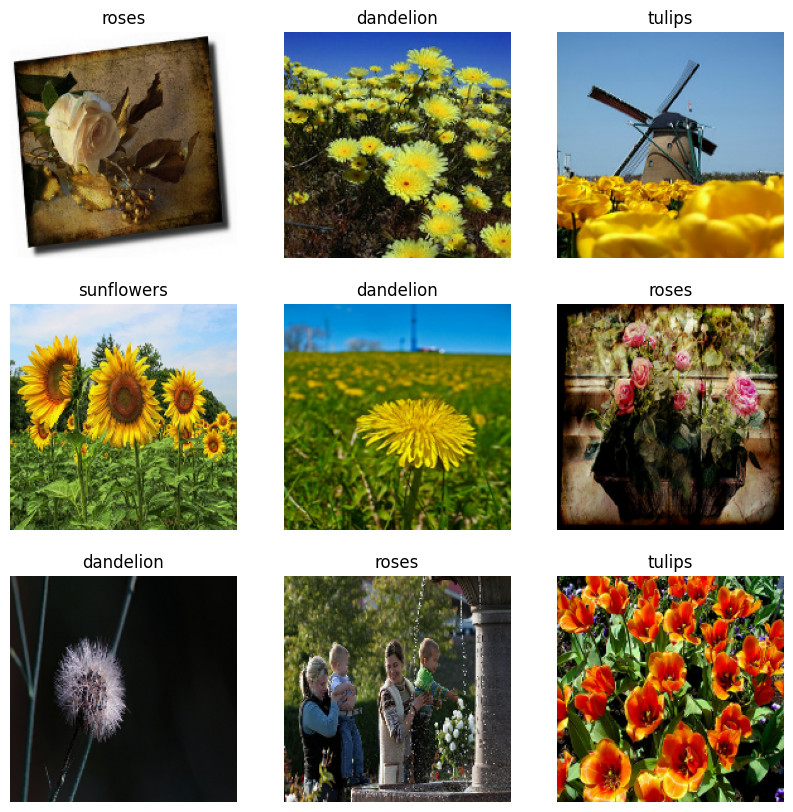
Anda dapat melatih model menggunakan kumpulan data ini dengan meneruskannya ke model.fit (ditampilkan nanti dalam tutorial ini). Jika Anda suka, Anda juga dapat secara manual mengulangi kumpulan data dan mengambil kumpulan gambar:
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
(32, 180, 180, 3) (32,)
image_batch adalah tensor dari bentuk (32, 180, 180, 3) . Ini adalah kumpulan 32 gambar dengan bentuk 180x180x3 (dimensi terakhir mengacu pada saluran warna RGB). label_batch adalah tensor dari bentuk (32,) , ini adalah label yang sesuai dengan 32 gambar.
Anda dapat memanggil .numpy() pada salah satu dari tensor ini untuk mengonversinya menjadi numpy.ndarray .
Standarisasi data
Nilai saluran RGB berada dalam kisaran [0, 255] . Ini tidak ideal untuk jaringan saraf; secara umum Anda harus berusaha membuat nilai input Anda kecil.
Di sini, Anda akan menstandardisasi nilai agar berada dalam kisaran [0, 1] dengan menggunakan tf.keras.layers.Rescaling :
normalization_layer = tf.keras.layers.Rescaling(1./255)
Ada dua cara untuk menggunakan lapisan ini. Anda dapat menerapkannya ke dataset dengan memanggil Dataset.map :
normalized_ds = train_ds.map(lambda x, y: (normalization_layer(x), y))
image_batch, labels_batch = next(iter(normalized_ds))
first_image = image_batch[0]
# Notice the pixel values are now in `[0,1]`.
print(np.min(first_image), np.max(first_image))
0.0 0.96902645
Atau, Anda dapat menyertakan lapisan di dalam definisi model Anda untuk menyederhanakan penerapan. Anda akan menggunakan pendekatan kedua di sini.
Konfigurasikan kumpulan data untuk kinerja
Mari pastikan untuk menggunakan buffered prefetching sehingga Anda dapat menghasilkan data dari disk tanpa I/O menjadi pemblokiran. Ini adalah dua metode penting yang harus Anda gunakan saat memuat data:
-
Dataset.cachemenyimpan gambar dalam memori setelah mereka dimuat dari disk selama epoch pertama. Ini akan memastikan kumpulan data tidak menjadi hambatan saat melatih model Anda. Jika kumpulan data Anda terlalu besar untuk dimasukkan ke dalam memori, Anda juga dapat menggunakan metode ini untuk membuat cache di disk yang berkinerja baik. -
Dataset.prefetchtumpang tindih dengan prapemrosesan data dan eksekusi model saat pelatihan.
Pembaca yang tertarik dapat mempelajari lebih lanjut tentang kedua metode tersebut, serta cara menyimpan data ke disk di bagian Prefetching pada Performa yang lebih baik dengan panduan API tf.data .
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
Latih seorang model
Untuk kelengkapan, Anda akan menunjukkan cara melatih model sederhana menggunakan kumpulan data yang baru saja Anda siapkan.
Model Sequential terdiri dari tiga blok konvolusi ( tf.keras.layers.Conv2D ) dengan lapisan pooling maks ( tf.keras.layers.MaxPooling2D ) di masing-masing blok. Ada lapisan yang sepenuhnya terhubung ( tf.keras.layers.Dense ) dengan 128 unit di atasnya yang diaktifkan oleh fungsi aktivasi ReLU ( 'relu' ). Model ini belum disetel dengan cara apa pun—tujuannya adalah untuk menunjukkan kepada Anda mekanisme menggunakan kumpulan data yang baru saja Anda buat. Untuk mempelajari lebih lanjut tentang klasifikasi gambar, kunjungi Tutorial klasifikasi gambar .
num_classes = 5
model = tf.keras.Sequential([
tf.keras.layers.Rescaling(1./255),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(num_classes)
])
Pilih fungsi kehilangan tf.keras.optimizers.Adam dan tf.keras.losses.SparseCategoricalCrossentropy . Untuk melihat akurasi pelatihan dan validasi untuk setiap periode pelatihan, teruskan argumen metrics ke Model.compile .
model.compile(
optimizer='adam',
loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(
train_ds,
validation_data=val_ds,
epochs=3
)
Epoch 1/3 92/92 [==============================] - 4s 21ms/step - loss: 1.3091 - accuracy: 0.4281 - val_loss: 1.0982 - val_accuracy: 0.5599 Epoch 2/3 92/92 [==============================] - 1s 12ms/step - loss: 1.0196 - accuracy: 0.5879 - val_loss: 0.9572 - val_accuracy: 0.6213 Epoch 3/3 92/92 [==============================] - 1s 12ms/step - loss: 0.8455 - accuracy: 0.6775 - val_loss: 0.8839 - val_accuracy: 0.6512 <keras.callbacks.History at 0x7ff10c168850>
Anda mungkin melihat akurasi validasi rendah dibandingkan dengan akurasi pelatihan, yang menunjukkan model Anda terlalu pas. Anda dapat mempelajari lebih lanjut tentang overfitting dan cara menguranginya dalam tutorial ini.
Menggunakan tf.data untuk kontrol yang lebih baik
Utilitas prapemrosesan Keras di tf.keras.utils.image_dataset_from_directory —adalah cara mudah untuk membuat tf.data.Dataset dari direktori gambar.
Untuk kontrol butir yang lebih halus, Anda dapat menulis saluran input Anda sendiri menggunakan tf.data . Bagian ini menunjukkan bagaimana melakukan hal itu, dimulai dengan jalur file dari file TGZ yang Anda unduh sebelumnya.
list_ds = tf.data.Dataset.list_files(str(data_dir/'*/*'), shuffle=False)
list_ds = list_ds.shuffle(image_count, reshuffle_each_iteration=False)
for f in list_ds.take(5):
print(f.numpy())
b'/home/kbuilder/.keras/datasets/flower_photos/roses/14267691818_301aceda07.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/daisy/2641151167_3bf1349606_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/sunflowers/6495554833_86eb8faa8e_n.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/tulips/4578030672_e6aefd45af.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/dandelion/144686365_d7e96941ee_n.jpg'
Struktur pohon file dapat digunakan untuk mengkompilasi daftar class_names .
class_names = np.array(sorted([item.name for item in data_dir.glob('*') if item.name != "LICENSE.txt"]))
print(class_names)
['daisy' 'dandelion' 'roses' 'sunflowers' 'tulips']
Pisahkan set data menjadi set pelatihan dan validasi:
val_size = int(image_count * 0.2)
train_ds = list_ds.skip(val_size)
val_ds = list_ds.take(val_size)
Anda dapat mencetak panjang setiap kumpulan data sebagai berikut:
print(tf.data.experimental.cardinality(train_ds).numpy())
print(tf.data.experimental.cardinality(val_ds).numpy())
2936 734
Tulis fungsi singkat yang mengubah jalur file menjadi pasangan (img, label) :
def get_label(file_path):
# Convert the path to a list of path components
parts = tf.strings.split(file_path, os.path.sep)
# The second to last is the class-directory
one_hot = parts[-2] == class_names
# Integer encode the label
return tf.argmax(one_hot)
def decode_img(img):
# Convert the compressed string to a 3D uint8 tensor
img = tf.io.decode_jpeg(img, channels=3)
# Resize the image to the desired size
return tf.image.resize(img, [img_height, img_width])
def process_path(file_path):
label = get_label(file_path)
# Load the raw data from the file as a string
img = tf.io.read_file(file_path)
img = decode_img(img)
return img, label
Gunakan Dataset.map untuk membuat kumpulan data image, label :
# Set `num_parallel_calls` so multiple images are loaded/processed in parallel.
train_ds = train_ds.map(process_path, num_parallel_calls=AUTOTUNE)
val_ds = val_ds.map(process_path, num_parallel_calls=AUTOTUNE)
for image, label in train_ds.take(1):
print("Image shape: ", image.numpy().shape)
print("Label: ", label.numpy())
Image shape: (180, 180, 3) Label: 1
Konfigurasikan kumpulan data untuk kinerja
Untuk melatih model dengan kumpulan data ini, Anda memerlukan data:
- Untuk dikocok dengan baik.
- Untuk di-batch.
- Batch akan tersedia sesegera mungkin.
Fitur-fitur ini dapat ditambahkan menggunakan tf.data API. Untuk detail selengkapnya, kunjungi panduan Kinerja Saluran Pipa Input .
def configure_for_performance(ds):
ds = ds.cache()
ds = ds.shuffle(buffer_size=1000)
ds = ds.batch(batch_size)
ds = ds.prefetch(buffer_size=AUTOTUNE)
return ds
train_ds = configure_for_performance(train_ds)
val_ds = configure_for_performance(val_ds)
Visualisasikan datanya
Anda dapat memvisualisasikan kumpulan data ini mirip dengan yang Anda buat sebelumnya:
image_batch, label_batch = next(iter(train_ds))
plt.figure(figsize=(10, 10))
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(image_batch[i].numpy().astype("uint8"))
label = label_batch[i]
plt.title(class_names[label])
plt.axis("off")
2022-01-26 06:29:45.209901: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
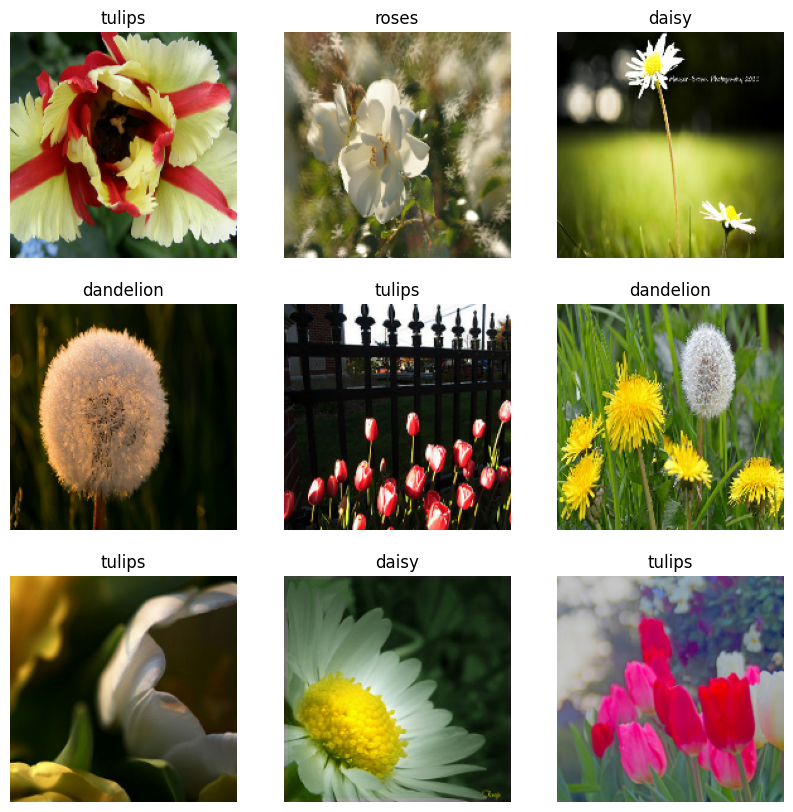
Lanjutkan melatih model
Anda sekarang telah membuat tf.data.Dataset serupa secara manual dengan yang dibuat oleh tf.keras.utils.image_dataset_from_directory di atas. Anda dapat melanjutkan melatih model dengannya. Seperti sebelumnya, Anda akan berlatih hanya beberapa epoch untuk mempersingkat waktu lari.
model.fit(
train_ds,
validation_data=val_ds,
epochs=3
)
Epoch 1/3 92/92 [==============================] - 3s 21ms/step - loss: 0.7305 - accuracy: 0.7245 - val_loss: 0.7311 - val_accuracy: 0.7139 Epoch 2/3 92/92 [==============================] - 1s 13ms/step - loss: 0.5279 - accuracy: 0.8069 - val_loss: 0.7021 - val_accuracy: 0.7316 Epoch 3/3 92/92 [==============================] - 1s 13ms/step - loss: 0.3739 - accuracy: 0.8644 - val_loss: 0.8266 - val_accuracy: 0.6948 <keras.callbacks.History at 0x7ff0ee071f10>
Menggunakan Kumpulan Data TensorFlow
Sejauh ini, tutorial ini berfokus pada memuat data dari disk. Anda juga dapat menemukan kumpulan data untuk digunakan dengan menjelajahi katalog besar kumpulan data yang mudah diunduh di TensorFlow Datasets .
Karena sebelumnya Anda telah memuat set data Flowers dari disk, sekarang mari impor dengan TensorFlow Datasets.
Unduh kumpulan data Bunga menggunakan Kumpulan Data TensorFlow:
(train_ds, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
Dataset bunga memiliki lima kelas:
num_classes = metadata.features['label'].num_classes
print(num_classes)
5
Ambil gambar dari kumpulan data:
get_label_name = metadata.features['label'].int2str
image, label = next(iter(train_ds))
_ = plt.imshow(image)
_ = plt.title(get_label_name(label))
2022-01-26 06:29:54.281352: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.

Seperti sebelumnya, ingatlah untuk mengelompokkan, mengacak, dan mengonfigurasi set pelatihan, validasi, dan pengujian untuk kinerja:
train_ds = configure_for_performance(train_ds)
val_ds = configure_for_performance(val_ds)
test_ds = configure_for_performance(test_ds)
Anda dapat menemukan contoh lengkap bekerja dengan kumpulan data Flowers dan TensorFlow Dataset dengan mengunjungi tutorial augmentasi Data .
Langkah selanjutnya
Tutorial ini menunjukkan dua cara memuat gambar dari disk. Pertama, Anda mempelajari cara memuat dan melakukan praproses kumpulan data gambar menggunakan lapisan dan utilitas prapemrosesan Keras. Selanjutnya, Anda mempelajari cara menulis saluran input dari awal menggunakan tf.data . Terakhir, Anda telah mempelajari cara mendownload set data dari TensorFlow Datasets.
Untuk langkah Anda selanjutnya:
- Anda dapat mempelajari cara menambahkan augmentasi data .
- Untuk mempelajari lebih lanjut tentang
tf.data, Anda dapat mengunjungi tf.data: Membangun panduan pipeline input TensorFlow .