
| | |  GitHub-এ উৎস দেখুন GitHub-এ উৎস দেখুন | |
এই টিউটোরিয়ালটি টেনসরফ্লোতে পান্ডা ডেটাফ্রেমগুলি কীভাবে লোড করতে হয় তার উদাহরণ প্রদান করে।
আপনি UCI মেশিন লার্নিং রিপোজিটরি দ্বারা প্রদত্ত একটি ছোট হৃদরোগের ডেটাসেট ব্যবহার করবেন। CSV-তে কয়েকশো সারি আছে। প্রতিটি সারি একটি রোগীর বর্ণনা করে, এবং প্রতিটি কলাম একটি বৈশিষ্ট্য বর্ণনা করে। একজন রোগীর হৃদরোগ আছে কিনা তা ভবিষ্যদ্বাণী করতে আপনি এই তথ্য ব্যবহার করবেন, যা একটি বাইনারি শ্রেণীবিভাগের কাজ।
পান্ডা ব্যবহার করে ডেটা পড়ুন
import pandas as pd
import tensorflow as tf
SHUFFLE_BUFFER = 500
BATCH_SIZE = 2
হৃদরোগের ডেটাসেট সহ CSV ফাইলটি ডাউনলোড করুন:
csv_file = tf.keras.utils.get_file('heart.csv', 'https://storage.googleapis.com/download.tensorflow.org/data/heart.csv')
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/heart.csv 16384/13273 [=====================================] - 0s 0us/step 24576/13273 [=======================================================] - 0s 0us/step
পান্ডা ব্যবহার করে CSV ফাইল পড়ুন:
df = pd.read_csv(csv_file)
এই তথ্য মত দেখায় কি:
df.head()
df.dtypes
age int64 sex int64 cp int64 trestbps int64 chol int64 fbs int64 restecg int64 thalach int64 exang int64 oldpeak float64 slope int64 ca int64 thal object target int64 dtype: object
target কলামে থাকা লেবেলের পূর্বাভাস দেওয়ার জন্য আপনি মডেল তৈরি করবেন।
target = df.pop('target')
একটি অ্যারে হিসাবে একটি ডেটাফ্রেম
যদি আপনার ডেটাতে একটি ইউনিফর্ম ডেটাটাইপ বা dtype , তাহলে আপনি একটি NumPy অ্যারে ব্যবহার করতে পারেন এমন যেকোনো জায়গায় একটি পান্ডাস ডেটাফ্রেম ব্যবহার করা সম্ভব। এটি কাজ করে কারণ pandas.DataFrame ক্লাস __array__ প্রোটোকল সমর্থন করে এবং TensorFlow এর tf.convert_to_tensor ফাংশন প্রোটোকল সমর্থন করে এমন বস্তু গ্রহণ করে।
ডেটাসেট থেকে সাংখ্যিক বৈশিষ্ট্যগুলি নিন (এখন শ্রেণীগত বৈশিষ্ট্যগুলি এড়িয়ে যান):
numeric_feature_names = ['age', 'thalach', 'trestbps', 'chol', 'oldpeak']
numeric_features = df[numeric_feature_names]
numeric_features.head()
DataFrame.values প্রপার্টি বা numpy.array(df) ব্যবহার করে ডেটাফ্রেমটিকে একটি NumPy অ্যারেতে রূপান্তর করা যেতে পারে। এটিকে টেনসরে রূপান্তর করতে, tf.convert_to_tensor ব্যবহার করুন:
tf.convert_to_tensor(numeric_features)
<tf.Tensor: shape=(303, 5), dtype=float64, numpy=
array([[ 63. , 150. , 145. , 233. , 2.3],
[ 67. , 108. , 160. , 286. , 1.5],
[ 67. , 129. , 120. , 229. , 2.6],
...,
[ 65. , 127. , 135. , 254. , 2.8],
[ 48. , 150. , 130. , 256. , 0. ],
[ 63. , 154. , 150. , 407. , 4. ]])>
সাধারণভাবে, যদি একটি বস্তুকে tf.convert_to_tensor দিয়ে একটি tf.convert_to_tensor রূপান্তর করা যায় তবে এটি যেকোনো স্থানে পাস করা যেতে পারে আপনি একটি tf.Tensor পাস করতে পারেন।
Model.fit সহ
একটি ডেটাফ্রেম, একটি একক টেনসর হিসাবে ব্যাখ্যা করা, Model.fit পদ্ধতিতে একটি যুক্তি হিসাবে সরাসরি ব্যবহার করা যেতে পারে।
নীচে ডেটাসেটের সংখ্যাসূচক বৈশিষ্ট্যগুলির উপর একটি মডেলকে প্রশিক্ষণের একটি উদাহরণ দেওয়া হল৷
প্রথম ধাপ হল ইনপুট রেঞ্জ স্বাভাবিক করা। এর জন্য একটি tf.keras.layers.Normalization লেয়ার ব্যবহার করুন।
এটি চালানোর আগে স্তরটির গড় এবং মান-বিচ্যুতি সেট করতে Normalization.adapt পদ্ধতিতে কল করতে ভুলবেন না:
normalizer = tf.keras.layers.Normalization(axis=-1)
normalizer.adapt(numeric_features)
এই স্তর থেকে আউটপুটের একটি উদাহরণ কল্পনা করতে DataFrame-এর প্রথম তিনটি সারিতে স্তরটিকে কল করুন:
normalizer(numeric_features.iloc[:3])
<tf.Tensor: shape=(3, 5), dtype=float32, numpy=
array([[ 0.93383914, 0.03480718, 0.74578077, -0.26008663, 1.0680453 ],
[ 1.3782105 , -1.7806165 , 1.5923285 , 0.7573877 , 0.38022864],
[ 1.3782105 , -0.87290466, -0.6651321 , -0.33687714, 1.3259765 ]],
dtype=float32)>
একটি সাধারণ মডেলের প্রথম স্তর হিসাবে স্বাভাবিককরণ স্তরটি ব্যবহার করুন:
def get_basic_model():
model = tf.keras.Sequential([
normalizer,
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(1)
])
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
return model
আপনি যখন Model.fit-এ x আর্গুমেন্ট হিসেবে Model.fit পাস করেন, Keras DataFrame কে NumPy অ্যারে হিসাবে বিবেচনা করে:
model = get_basic_model()
model.fit(numeric_features, target, epochs=15, batch_size=BATCH_SIZE)
Epoch 1/15 152/152 [==============================] - 1s 2ms/step - loss: 0.6839 - accuracy: 0.7690 Epoch 2/15 152/152 [==============================] - 0s 2ms/step - loss: 0.5789 - accuracy: 0.7789 Epoch 3/15 152/152 [==============================] - 0s 2ms/step - loss: 0.5195 - accuracy: 0.7723 Epoch 4/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4814 - accuracy: 0.7855 Epoch 5/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4566 - accuracy: 0.7789 Epoch 6/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4427 - accuracy: 0.7888 Epoch 7/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4342 - accuracy: 0.7921 Epoch 8/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4290 - accuracy: 0.7855 Epoch 9/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4240 - accuracy: 0.7987 Epoch 10/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4232 - accuracy: 0.7987 Epoch 11/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4208 - accuracy: 0.7987 Epoch 12/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4186 - accuracy: 0.7954 Epoch 13/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4172 - accuracy: 0.8020 Epoch 14/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4156 - accuracy: 0.8020 Epoch 15/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4138 - accuracy: 0.8020 <keras.callbacks.History at 0x7f1ddc27b110>
tf.data সহ
আপনি যদি একটি অভিন্ন dtype এর একটি DataFrame-এ tf.data রূপান্তর প্রয়োগ করতে চান, Dataset.from_tensor_slices পদ্ধতি একটি ডেটাসেট তৈরি করবে যা ডেটাফ্রেমের সারিগুলিতে পুনরাবৃত্তি করে। প্রতিটি সারি প্রাথমিকভাবে মানগুলির একটি ভেক্টর। একটি মডেলকে প্রশিক্ষণের জন্য, আপনার প্রয়োজন (inputs, labels) জোড়া, তাই পাস (features, labels) এবং Dataset.from_tensor_slices প্রয়োজনীয় জোড়া স্লাইস ফিরিয়ে দেবে:
numeric_dataset = tf.data.Dataset.from_tensor_slices((numeric_features, target))
for row in numeric_dataset.take(3):
print(row)
(<tf.Tensor: shape=(5,), dtype=float64, numpy=array([ 63. , 150. , 145. , 233. , 2.3])>, <tf.Tensor: shape=(), dtype=int64, numpy=0>) (<tf.Tensor: shape=(5,), dtype=float64, numpy=array([ 67. , 108. , 160. , 286. , 1.5])>, <tf.Tensor: shape=(), dtype=int64, numpy=1>) (<tf.Tensor: shape=(5,), dtype=float64, numpy=array([ 67. , 129. , 120. , 229. , 2.6])>, <tf.Tensor: shape=(), dtype=int64, numpy=0>)
numeric_batches = numeric_dataset.shuffle(1000).batch(BATCH_SIZE)
model = get_basic_model()
model.fit(numeric_batches, epochs=15)
Epoch 1/15 152/152 [==============================] - 1s 2ms/step - loss: 0.7677 - accuracy: 0.6865 Epoch 2/15 152/152 [==============================] - 0s 2ms/step - loss: 0.6319 - accuracy: 0.7591 Epoch 3/15 152/152 [==============================] - 0s 2ms/step - loss: 0.5717 - accuracy: 0.7459 Epoch 4/15 152/152 [==============================] - 0s 2ms/step - loss: 0.5228 - accuracy: 0.7558 Epoch 5/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4820 - accuracy: 0.7624 Epoch 6/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4584 - accuracy: 0.7657 Epoch 7/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4454 - accuracy: 0.7657 Epoch 8/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4379 - accuracy: 0.7789 Epoch 9/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4324 - accuracy: 0.7789 Epoch 10/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4282 - accuracy: 0.7756 Epoch 11/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4273 - accuracy: 0.7789 Epoch 12/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4268 - accuracy: 0.7756 Epoch 13/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4248 - accuracy: 0.7789 Epoch 14/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4235 - accuracy: 0.7855 Epoch 15/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4223 - accuracy: 0.7888 <keras.callbacks.History at 0x7f1ddc406510>
একটি অভিধান হিসাবে একটি ডেটাফ্রেম
আপনি যখন ভিন্নধর্মী ডেটা নিয়ে কাজ শুরু করেন, তখন ডেটাফ্রেমকে একটি একক অ্যারের মতো আচরণ করা আর সম্ভব হয় না। টেনসরফ্লো টেনসরগুলির জন্য প্রয়োজন যে সমস্ত উপাদান একই dtype আছে।
সুতরাং, এই ক্ষেত্রে, আপনাকে এটিকে কলামের অভিধান হিসাবে বিবেচনা করা শুরু করতে হবে, যেখানে প্রতিটি কলামের একটি অভিন্ন dtype আছে। একটি ডেটাফ্রেম অনেকটা অ্যারের অভিধানের মতো, তাই সাধারণত আপনাকে যা করতে হবে তা হল ডাটাফ্রেমকে একটি পাইথন ডিক্টে নিক্ষেপ করা। অনেক গুরুত্বপূর্ণ টেনসরফ্লো এপিআই ইনপুট হিসাবে অ্যারের ডিকশনারি (নেস্টেড-) সমর্থন করে।
tf.data ইনপুট পাইপলাইন এটি বেশ ভালভাবে পরিচালনা করে। সমস্ত tf.data অপারেশন স্বয়ংক্রিয়ভাবে অভিধান এবং tuples পরিচালনা করে। সুতরাং, একটি ডেটাফ্রেম থেকে অভিধান-উদাহরণগুলির একটি ডেটাসেট তৈরি করতে, Dataset.from_tensor_slices দিয়ে এটিকে স্লাইস করার আগে এটিকে একটি Dataset.from_tensor_slices কাস্ট করুন:
numeric_dict_ds = tf.data.Dataset.from_tensor_slices((dict(numeric_features), target))
এখানে সেই ডেটাসেটের প্রথম তিনটি উদাহরণ রয়েছে:
for row in numeric_dict_ds.take(3):
print(row)
({'age': <tf.Tensor: shape=(), dtype=int64, numpy=63>, 'thalach': <tf.Tensor: shape=(), dtype=int64, numpy=150>, 'trestbps': <tf.Tensor: shape=(), dtype=int64, numpy=145>, 'chol': <tf.Tensor: shape=(), dtype=int64, numpy=233>, 'oldpeak': <tf.Tensor: shape=(), dtype=float64, numpy=2.3>}, <tf.Tensor: shape=(), dtype=int64, numpy=0>)
({'age': <tf.Tensor: shape=(), dtype=int64, numpy=67>, 'thalach': <tf.Tensor: shape=(), dtype=int64, numpy=108>, 'trestbps': <tf.Tensor: shape=(), dtype=int64, numpy=160>, 'chol': <tf.Tensor: shape=(), dtype=int64, numpy=286>, 'oldpeak': <tf.Tensor: shape=(), dtype=float64, numpy=1.5>}, <tf.Tensor: shape=(), dtype=int64, numpy=1>)
({'age': <tf.Tensor: shape=(), dtype=int64, numpy=67>, 'thalach': <tf.Tensor: shape=(), dtype=int64, numpy=129>, 'trestbps': <tf.Tensor: shape=(), dtype=int64, numpy=120>, 'chol': <tf.Tensor: shape=(), dtype=int64, numpy=229>, 'oldpeak': <tf.Tensor: shape=(), dtype=float64, numpy=2.6>}, <tf.Tensor: shape=(), dtype=int64, numpy=0>)
কেরাসের সাথে অভিধান
সাধারণত, কেরাস মডেল এবং স্তরগুলি একটি একক ইনপুট টেনসর আশা করে, তবে এই ক্লাসগুলি অভিধান, টিপল এবং টেনসরগুলির নেস্টেড কাঠামো গ্রহণ করতে এবং ফিরিয়ে দিতে পারে। এই কাঠামোগুলি "নেস্ট" নামে পরিচিত (বিশদ বিবরণের জন্য tf.nest মডিউল পড়ুন)।
আপনি একটি কেরাস মডেল লিখতে পারেন এমন দুটি সমতুল্য উপায় রয়েছে যা একটি অভিধানকে ইনপুট হিসাবে গ্রহণ করে।
1. মডেল-সাবক্লাস শৈলী
আপনি tf.keras.Model (বা tf.keras.Layer ) এর একটি সাবক্লাস লিখুন। আপনি সরাসরি ইনপুটগুলি পরিচালনা করেন এবং আউটপুট তৈরি করেন:
def stack_dict(inputs, fun=tf.stack):
values = []
for key in sorted(inputs.keys()):
values.append(tf.cast(inputs[key], tf.float32))
return fun(values, axis=-1)
class MyModel(tf.keras.Model):
def __init__(self):
# Create all the internal layers in init.
super().__init__(self)
self.normalizer = tf.keras.layers.Normalization(axis=-1)
self.seq = tf.keras.Sequential([
self.normalizer,
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(1)
])
def adapt(self, inputs):
# Stach the inputs and `adapt` the normalization layer.
inputs = stack_dict(inputs)
self.normalizer.adapt(inputs)
def call(self, inputs):
# Stack the inputs
inputs = stack_dict(inputs)
# Run them through all the layers.
result = self.seq(inputs)
return result
model = MyModel()
model.adapt(dict(numeric_features))
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'],
run_eagerly=True)
এই মডেলটি প্রশিক্ষণের জন্য কলামের অভিধান বা অভিধান-উপাদানের একটি ডেটাসেট গ্রহণ করতে পারে:
model.fit(dict(numeric_features), target, epochs=5, batch_size=BATCH_SIZE)
Epoch 1/5 152/152 [==============================] - 3s 17ms/step - loss: 0.6736 - accuracy: 0.7063 Epoch 2/5 152/152 [==============================] - 3s 17ms/step - loss: 0.5577 - accuracy: 0.7294 Epoch 3/5 152/152 [==============================] - 2s 16ms/step - loss: 0.4869 - accuracy: 0.7591 Epoch 4/5 152/152 [==============================] - 2s 16ms/step - loss: 0.4525 - accuracy: 0.7690 Epoch 5/5 152/152 [==============================] - 2s 16ms/step - loss: 0.4403 - accuracy: 0.7624 <keras.callbacks.History at 0x7f1de4fa9390>
numeric_dict_batches = numeric_dict_ds.shuffle(SHUFFLE_BUFFER).batch(BATCH_SIZE)
model.fit(numeric_dict_batches, epochs=5)
Epoch 1/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4328 - accuracy: 0.7756 Epoch 2/5 152/152 [==============================] - 2s 14ms/step - loss: 0.4297 - accuracy: 0.7888 Epoch 3/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4270 - accuracy: 0.7888 Epoch 4/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4245 - accuracy: 0.8020 Epoch 5/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4240 - accuracy: 0.7921 <keras.callbacks.History at 0x7f1ddc0dba90>
এখানে প্রথম তিনটি উদাহরণের ভবিষ্যদ্বাণী রয়েছে:
model.predict(dict(numeric_features.iloc[:3]))
array([[[0.00565109]],
[[0.60601974]],
[[0.03647463]]], dtype=float32)
2. কেরাস কার্যকরী শৈলী
inputs = {}
for name, column in numeric_features.items():
inputs[name] = tf.keras.Input(
shape=(1,), name=name, dtype=tf.float32)
inputs
{'age': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'age')>,
'thalach': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'thalach')>,
'trestbps': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'trestbps')>,
'chol': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'chol')>,
'oldpeak': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'oldpeak')>}
x = stack_dict(inputs, fun=tf.concat)
normalizer = tf.keras.layers.Normalization(axis=-1)
normalizer.adapt(stack_dict(dict(numeric_features)))
x = normalizer(x)
x = tf.keras.layers.Dense(10, activation='relu')(x)
x = tf.keras.layers.Dense(10, activation='relu')(x)
x = tf.keras.layers.Dense(1)(x)
model = tf.keras.Model(inputs, x)
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'],
run_eagerly=True)
tf.keras.utils.plot_model(model, rankdir="LR", show_shapes=True)

আপনি কার্যকরী মডেলটিকে মডেল সাবক্লাসের মতোই প্রশিক্ষণ দিতে পারেন:
model.fit(dict(numeric_features), target, epochs=5, batch_size=BATCH_SIZE)
Epoch 1/5 152/152 [==============================] - 2s 15ms/step - loss: 0.6529 - accuracy: 0.7492 Epoch 2/5 152/152 [==============================] - 2s 15ms/step - loss: 0.5448 - accuracy: 0.7624 Epoch 3/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4935 - accuracy: 0.7756 Epoch 4/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4650 - accuracy: 0.7789 Epoch 5/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4486 - accuracy: 0.7855 <keras.callbacks.History at 0x7f1ddc0d0f90>
numeric_dict_batches = numeric_dict_ds.shuffle(SHUFFLE_BUFFER).batch(BATCH_SIZE)
model.fit(numeric_dict_batches, epochs=5)
Epoch 1/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4398 - accuracy: 0.7855 Epoch 2/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4330 - accuracy: 0.7855 Epoch 3/5 152/152 [==============================] - 2s 16ms/step - loss: 0.4294 - accuracy: 0.7921 Epoch 4/5 152/152 [==============================] - 2s 16ms/step - loss: 0.4271 - accuracy: 0.7888 Epoch 5/5 152/152 [==============================] - 2s 16ms/step - loss: 0.4231 - accuracy: 0.7855 <keras.callbacks.History at 0x7f1d7c5d5d10>
সম্পূর্ণ উদাহরণ
এটি আপনি কেরাসে একটি ভিন্নধর্মী DataFrame পাস করছেন, প্রতিটি কলামের অনন্য প্রিপ্রসেসিংয়ের প্রয়োজন হতে পারে। আপনি ডাটাফ্রেমে সরাসরি এই প্রিপ্রসেসিং করতে পারেন, কিন্তু একটি মডেল সঠিকভাবে কাজ করার জন্য, ইনপুটগুলিকে সবসময় একইভাবে প্রিপ্রসেস করতে হবে। সুতরাং, সর্বোত্তম পন্থা হল মডেলে প্রিপ্রসেসিং তৈরি করা। কেরাস প্রিপ্রসেসিং লেয়ারগুলি অনেক সাধারণ কাজ কভার করে।
প্রিপ্রসেসিং হেড তৈরি করুন
এই ডেটাসেটে কাঁচা ডেটার কিছু "পূর্ণসংখ্যা" বৈশিষ্ট্য আসলে শ্রেণীগত সূচক। এই সূচকগুলি সত্যিই সাংখ্যিক মানগুলির ক্রমানুসারে নয় (বিশদ বিবরণের জন্য ডেটাসেটের বিবরণ পড়ুন)। কারণ এগুলি ক্রমবিন্যস্ত, এগুলি সরাসরি মডেলকে খাওয়ানো অনুপযুক্ত; মডেল তাদের আদেশ করা হচ্ছে হিসাবে ব্যাখ্যা করবে. এই ইনপুটগুলি ব্যবহার করার জন্য আপনাকে সেগুলিকে এনকোড করতে হবে, হয় এক-হট ভেক্টর বা এমবেডিং ভেক্টর হিসাবে। একই স্ট্রিং-শ্রেণীগত বৈশিষ্ট্য প্রযোজ্য.
অন্যদিকে বাইনারি বৈশিষ্ট্যগুলি সাধারণত এনকোড বা স্বাভাবিককরণের প্রয়োজন হয় না।
প্রতিটি গ্রুপের মধ্যে পড়ে এমন বৈশিষ্ট্যগুলির একটি তালিকা তৈরি করে শুরু করুন:
binary_feature_names = ['sex', 'fbs', 'exang']
categorical_feature_names = ['cp', 'restecg', 'slope', 'thal', 'ca']
পরবর্তী ধাপ হল একটি প্রি-প্রসেসিং মডেল তৈরি করা যা প্রতিটি ইনপুটে প্রতিটির জন্য উপযুক্ত প্রিপ্রসেসিং প্রয়োগ করবে এবং ফলাফলগুলিকে সংযুক্ত করবে।
এই বিভাগটি কেরাস ফাংশনাল এপিআই ব্যবহার করে প্রিপ্রসেসিং বাস্তবায়ন করতে। আপনি ডেটাফ্রেমের প্রতিটি কলামের জন্য একটি tf.keras.Input .ইনপুট তৈরি করে শুরু করুন:
inputs = {}
for name, column in df.items():
if type(column[0]) == str:
dtype = tf.string
elif (name in categorical_feature_names or
name in binary_feature_names):
dtype = tf.int64
else:
dtype = tf.float32
inputs[name] = tf.keras.Input(shape=(), name=name, dtype=dtype)
inputs
{'age': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'age')>,
'sex': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'sex')>,
'cp': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'cp')>,
'trestbps': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'trestbps')>,
'chol': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'chol')>,
'fbs': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'fbs')>,
'restecg': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'restecg')>,
'thalach': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'thalach')>,
'exang': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'exang')>,
'oldpeak': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'oldpeak')>,
'slope': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'slope')>,
'ca': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'ca')>,
'thal': <KerasTensor: shape=(None,) dtype=string (created by layer 'thal')>}
প্রতিটি ইনপুটের জন্য আপনি কেরাস স্তর এবং টেনসরফ্লো অপ্স ব্যবহার করে কিছু রূপান্তর প্রয়োগ করবেন। প্রতিটি বৈশিষ্ট্য স্কেলারের একটি ব্যাচ হিসাবে শুরু হয় ( shape=(batch,) )। প্রতিটির জন্য আউটপুট tf.float32 ভেক্টরের একটি ব্যাচ হওয়া উচিত ( shape=(batch, n) )। শেষ ধাপটি সেই সমস্ত ভেক্টরকে একত্রিত করবে।
বাইনারি ইনপুট
যেহেতু বাইনারি ইনপুটগুলির কোনো প্রিপ্রসেসিংয়ের প্রয়োজন নেই, শুধু ভেক্টর অক্ষ যোগ করুন, float32 এ কাস্ট করুন এবং প্রিপ্রসেসড ইনপুটগুলির তালিকায় যুক্ত করুন:
preprocessed = []
for name in binary_feature_names:
inp = inputs[name]
inp = inp[:, tf.newaxis]
float_value = tf.cast(inp, tf.float32)
preprocessed.append(float_value)
preprocessed
[<KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_5')>, <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_6')>, <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_7')>]
সংখ্যাসূচক ইনপুট
আগের বিভাগে যেমন আপনি এই সংখ্যাসূচক ইনপুটগুলি ব্যবহার করার আগে tf.keras.layers.Normalization স্তরের মাধ্যমে চালাতে চাইবেন। পার্থক্য হল এই সময় তারা একটি নির্দেশ হিসাবে ইনপুট করছি. নীচের কোডটি ডেটাফ্রেম থেকে সংখ্যাসূচক বৈশিষ্ট্যগুলি সংগ্রহ করে, সেগুলিকে একত্রে স্ট্যাক করে এবং Normalization.adapt পদ্ধতিতে পাস করে।
normalizer = tf.keras.layers.Normalization(axis=-1)
normalizer.adapt(stack_dict(dict(numeric_features)))
নীচের কোডটি সাংখ্যিক বৈশিষ্ট্যগুলিকে স্ট্যাক করে এবং সেগুলিকে স্বাভাবিককরণ স্তরের মাধ্যমে চালায়।
numeric_inputs = {}
for name in numeric_feature_names:
numeric_inputs[name]=inputs[name]
numeric_inputs = stack_dict(numeric_inputs)
numeric_normalized = normalizer(numeric_inputs)
preprocessed.append(numeric_normalized)
preprocessed
[<KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_5')>, <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_6')>, <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_7')>, <KerasTensor: shape=(None, 5) dtype=float32 (created by layer 'normalization_3')>]
শ্রেণীবদ্ধ বৈশিষ্ট্য
শ্রেণীবদ্ধ বৈশিষ্ট্যগুলি ব্যবহার করার জন্য আপনাকে প্রথমে বাইনারি ভেক্টর বা এমবেডিংগুলিতে এনকোড করতে হবে। যেহেতু এই বৈশিষ্ট্যগুলিতে শুধুমাত্র অল্প সংখ্যক বিভাগ রয়েছে, তাই tf.keras.layers.StringLookup এবং tf.keras.layers.IntegerLookup উভয় স্তর দ্বারা সমর্থিত output_mode='one_hot' বিকল্প ব্যবহার করে ইনপুটগুলিকে সরাসরি এক-হট ভেক্টরে রূপান্তর করুন।
এই স্তরগুলি কীভাবে কাজ করে তার একটি উদাহরণ এখানে রয়েছে:
vocab = ['a','b','c']
lookup = tf.keras.layers.StringLookup(vocabulary=vocab, output_mode='one_hot')
lookup(['c','a','a','b','zzz'])
<tf.Tensor: shape=(5, 4), dtype=float32, numpy=
array([[0., 0., 0., 1.],
[0., 1., 0., 0.],
[0., 1., 0., 0.],
[0., 0., 1., 0.],
[1., 0., 0., 0.]], dtype=float32)>
vocab = [1,4,7,99]
lookup = tf.keras.layers.IntegerLookup(vocabulary=vocab, output_mode='one_hot')
lookup([-1,4,1])
<tf.Tensor: shape=(3, 5), dtype=float32, numpy=
array([[1., 0., 0., 0., 0.],
[0., 0., 1., 0., 0.],
[0., 1., 0., 0., 0.]], dtype=float32)>
প্রতিটি ইনপুটের জন্য শব্দভান্ডার নির্ধারণ করতে, সেই শব্দভাণ্ডারটিকে এক-হট ভেক্টরে রূপান্তর করতে একটি স্তর তৈরি করুন:
for name in categorical_feature_names:
vocab = sorted(set(df[name]))
print(f'name: {name}')
print(f'vocab: {vocab}\n')
if type(vocab[0]) is str:
lookup = tf.keras.layers.StringLookup(vocabulary=vocab, output_mode='one_hot')
else:
lookup = tf.keras.layers.IntegerLookup(vocabulary=vocab, output_mode='one_hot')
x = inputs[name][:, tf.newaxis]
x = lookup(x)
preprocessed.append(x)
name: cp vocab: [0, 1, 2, 3, 4] name: restecg vocab: [0, 1, 2] name: slope vocab: [1, 2, 3] name: thal vocab: ['1', '2', 'fixed', 'normal', 'reversible'] name: ca vocab: [0, 1, 2, 3]
প্রিপ্রসেসিং হেড একত্রিত করুন
এই মুহুর্তে preprocessed করা হল সমস্ত প্রিপ্রসেসিং ফলাফলের একটি পাইথন তালিকা, প্রতিটি ফলাফলের আকৃতি রয়েছে (batch_size, depth) :
preprocessed
[<KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_5')>, <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_6')>, <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_7')>, <KerasTensor: shape=(None, 5) dtype=float32 (created by layer 'normalization_3')>, <KerasTensor: shape=(None, 6) dtype=float32 (created by layer 'integer_lookup_1')>, <KerasTensor: shape=(None, 4) dtype=float32 (created by layer 'integer_lookup_2')>, <KerasTensor: shape=(None, 4) dtype=float32 (created by layer 'integer_lookup_3')>, <KerasTensor: shape=(None, 6) dtype=float32 (created by layer 'string_lookup_1')>, <KerasTensor: shape=(None, 5) dtype=float32 (created by layer 'integer_lookup_4')>]
depth অক্ষ বরাবর সমস্ত প্রাক-প্রক্রিয়াজাত বৈশিষ্ট্যগুলিকে সংযুক্ত করুন, তাই প্রতিটি অভিধান-উদাহরণ একটি একক ভেক্টরে রূপান্তরিত হয়। ভেক্টরে রয়েছে শ্রেণীগত বৈশিষ্ট্য, সংখ্যাসূচক বৈশিষ্ট্য এবং শ্রেণীগত এক-হট বৈশিষ্ট্য:
preprocesssed_result = tf.concat(preprocessed, axis=-1)
preprocesssed_result
<KerasTensor: shape=(None, 33) dtype=float32 (created by layer 'tf.concat_1')>
এখন সেই গণনা থেকে একটি মডেল তৈরি করুন যাতে এটি পুনরায় ব্যবহার করা যায়:
preprocessor = tf.keras.Model(inputs, preprocesssed_result)
tf.keras.utils.plot_model(preprocessor, rankdir="LR", show_shapes=True)
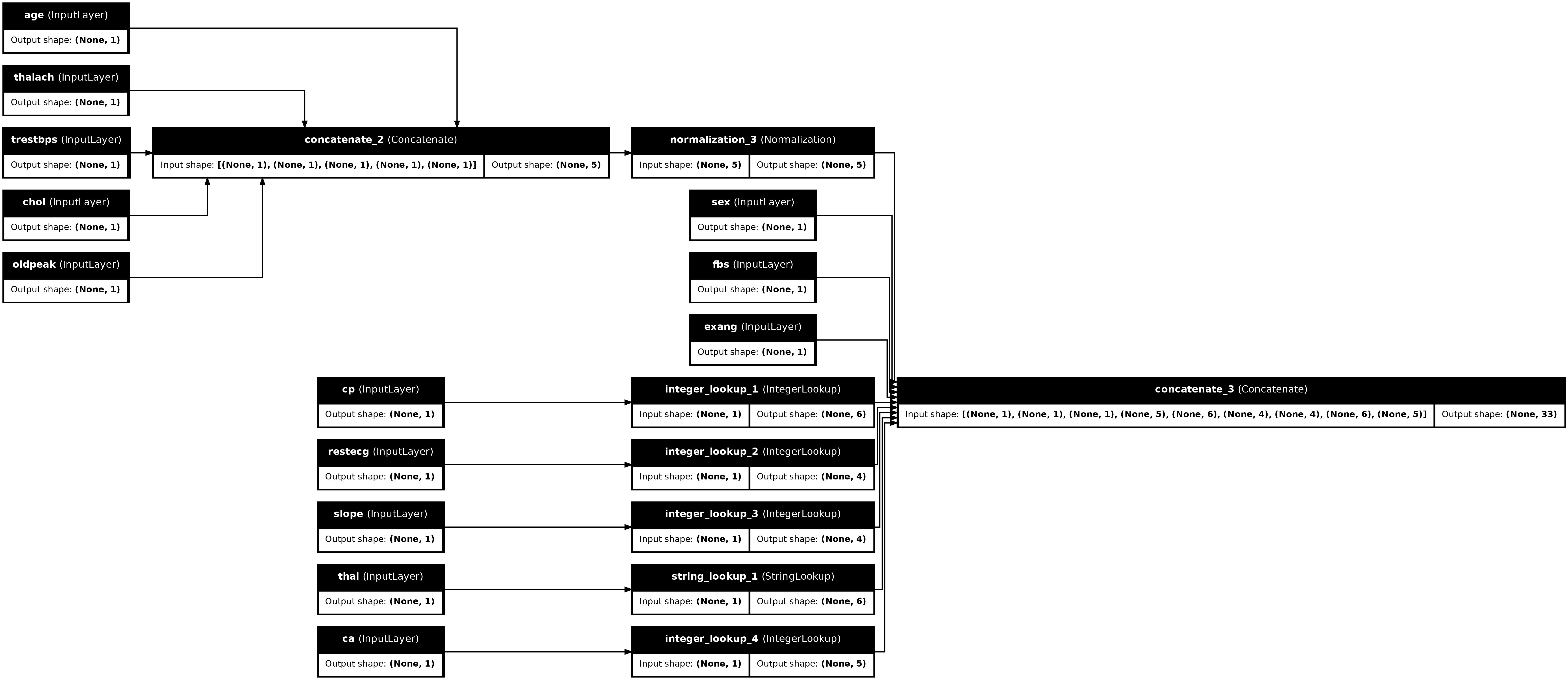
প্রিপ্রসেসর পরীক্ষা করতে, DataFrame.iloc অ্যাক্সেসর ব্যবহার করুন DataFrame থেকে প্রথম উদাহরণটি স্লাইস করতে। তারপর এটিকে একটি অভিধানে রূপান্তর করুন এবং অভিধানটি প্রিপ্রসেসরে পাস করুন। ফলাফল হল একটি একক ভেক্টর যার মধ্যে বাইনারি বৈশিষ্ট্য, স্বাভাবিক করা সংখ্যাসূচক বৈশিষ্ট্য এবং এক-হট শ্রেণীগত বৈশিষ্ট্য রয়েছে, সেই ক্রমে:
preprocessor(dict(df.iloc[:1]))
<tf.Tensor: shape=(1, 33), dtype=float32, numpy=
array([[ 1. , 1. , 0. , 0.93383914, -0.26008663,
1.0680453 , 0.03480718, 0.74578077, 0. , 0. ,
1. , 0. , 0. , 0. , 0. ,
0. , 0. , 1. , 0. , 0. ,
0. , 1. , 0. , 0. , 0. ,
1. , 0. , 0. , 0. , 1. ,
0. , 0. , 0. ]], dtype=float32)>
একটি মডেল তৈরি এবং প্রশিক্ষণ
এখন মডেলটির মূল অংশটি তৈরি করুন। আগের উদাহরণের মতো একই কনফিগারেশন ব্যবহার করুন: শ্রেণীবিভাগের জন্য কয়েকটি Dense সংশোধন-রৈখিক স্তর এবং একটি Dense(1) আউটপুট স্তর।
body = tf.keras.Sequential([
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(1)
])
এখন কেরাস ফাংশনাল API ব্যবহার করে দুটি টুকরো একসাথে রাখুন।
inputs
{'age': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'age')>,
'sex': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'sex')>,
'cp': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'cp')>,
'trestbps': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'trestbps')>,
'chol': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'chol')>,
'fbs': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'fbs')>,
'restecg': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'restecg')>,
'thalach': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'thalach')>,
'exang': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'exang')>,
'oldpeak': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'oldpeak')>,
'slope': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'slope')>,
'ca': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'ca')>,
'thal': <KerasTensor: shape=(None,) dtype=string (created by layer 'thal')>}
x = preprocessor(inputs)
x
<KerasTensor: shape=(None, 33) dtype=float32 (created by layer 'model_1')>
result = body(x)
result
<KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'sequential_3')>
model = tf.keras.Model(inputs, result)
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
এই মডেল ইনপুট একটি অভিধান আশা করে. ডাটা পাস করার সবচেয়ে সহজ উপায় হল DataFrame কে একটি ডিক্টে রূপান্তর করা এবং সেই ডিক্টটিকে x আর্গুমেন্ট হিসাবে Model.fit এ পাস করা:
history = model.fit(dict(df), target, epochs=5, batch_size=BATCH_SIZE)
Epoch 1/5 152/152 [==============================] - 1s 4ms/step - loss: 0.6911 - accuracy: 0.6997 Epoch 2/5 152/152 [==============================] - 1s 4ms/step - loss: 0.5073 - accuracy: 0.7393 Epoch 3/5 152/152 [==============================] - 1s 4ms/step - loss: 0.4129 - accuracy: 0.7888 Epoch 4/5 152/152 [==============================] - 1s 4ms/step - loss: 0.3663 - accuracy: 0.7921 Epoch 5/5 152/152 [==============================] - 1s 4ms/step - loss: 0.3363 - accuracy: 0.8152
tf.data ব্যবহার করাও কাজ করে:
ds = tf.data.Dataset.from_tensor_slices((
dict(df),
target
))
ds = ds.batch(BATCH_SIZE)
import pprint
for x, y in ds.take(1):
pprint.pprint(x)
print()
print(y)
{'age': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([63, 67])>,
'ca': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([0, 3])>,
'chol': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([233, 286])>,
'cp': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([1, 4])>,
'exang': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([0, 1])>,
'fbs': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([1, 0])>,
'oldpeak': <tf.Tensor: shape=(2,), dtype=float64, numpy=array([2.3, 1.5])>,
'restecg': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([2, 2])>,
'sex': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([1, 1])>,
'slope': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([3, 2])>,
'thal': <tf.Tensor: shape=(2,), dtype=string, numpy=array([b'fixed', b'normal'], dtype=object)>,
'thalach': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([150, 108])>,
'trestbps': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([145, 160])>}
tf.Tensor([0 1], shape=(2,), dtype=int64)
history = model.fit(ds, epochs=5)
Epoch 1/5 152/152 [==============================] - 1s 5ms/step - loss: 0.3150 - accuracy: 0.8284 Epoch 2/5 152/152 [==============================] - 1s 5ms/step - loss: 0.2989 - accuracy: 0.8449 Epoch 3/5 152/152 [==============================] - 1s 5ms/step - loss: 0.2870 - accuracy: 0.8449 Epoch 4/5 152/152 [==============================] - 1s 5ms/step - loss: 0.2782 - accuracy: 0.8482 Epoch 5/5 152/152 [==============================] - 1s 5ms/step - loss: 0.2712 - accuracy: 0.8482