
| | |  GitHub पर स्रोत देखें GitHub पर स्रोत देखें | |
यह ट्यूटोरियल उदाहरण देता है कि कैसे पांडा डेटाफ़्रेम को TensorFlow में लोड किया जाए।
आप यूसीआई मशीन लर्निंग रिपोजिटरी द्वारा प्रदान किए गए एक छोटे हृदय रोग डेटासेट का उपयोग करेंगे। CSV में कई सौ पंक्तियाँ हैं। प्रत्येक पंक्ति एक रोगी का वर्णन करती है, और प्रत्येक स्तंभ एक विशेषता का वर्णन करता है। आप इस जानकारी का उपयोग यह अनुमान लगाने के लिए करेंगे कि क्या रोगी को हृदय रोग है, जो एक द्विआधारी वर्गीकरण कार्य है।
पांडा का उपयोग करके डेटा पढ़ें
import pandas as pd
import tensorflow as tf
SHUFFLE_BUFFER = 500
BATCH_SIZE = 2
हृदय रोग डेटासेट वाली CSV फ़ाइल डाउनलोड करें:
csv_file = tf.keras.utils.get_file('heart.csv', 'https://storage.googleapis.com/download.tensorflow.org/data/heart.csv')
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/heart.csv 16384/13273 [=====================================] - 0s 0us/step 24576/13273 [=======================================================] - 0s 0us/step
पांडा का उपयोग करके CSV फ़ाइल पढ़ें:
df = pd.read_csv(csv_file)
डेटा इस तरह दिखता है:
df.head()
df.dtypes
age int64 sex int64 cp int64 trestbps int64 chol int64 fbs int64 restecg int64 thalach int64 exang int64 oldpeak float64 slope int64 ca int64 thal object target int64 dtype: object
आप target कॉलम में निहित लेबल की भविष्यवाणी करने के लिए मॉडल बनाएंगे।
target = df.pop('target')
एक डेटाफ़्रेम एक सरणी के रूप में
यदि आपके डेटा में एक समान डेटाटाइप, या dtype है, तो यह संभव है कि आप एक पांडा डेटाफ़्रेम का उपयोग करें जहाँ कहीं भी आप एक NumPy सरणी का उपयोग कर सकते हैं। यह काम करता है क्योंकि pandas.DataFrame वर्ग __array__ प्रोटोकॉल का समर्थन करता है, और TensorFlow का tf.convert_to_tensor फ़ंक्शन प्रोटोकॉल का समर्थन करने वाली वस्तुओं को स्वीकार करता है।
डेटासेट से संख्यात्मक विशेषताएं लें (अभी के लिए श्रेणीबद्ध सुविधाओं को छोड़ दें):
numeric_feature_names = ['age', 'thalach', 'trestbps', 'chol', 'oldpeak']
numeric_features = df[numeric_feature_names]
numeric_features.head()
DataFrame को DataFrame.values प्रॉपर्टी या numpy.array(df) का उपयोग करके एक NumPy सरणी में परिवर्तित किया जा सकता है। इसे टेंसर में बदलने के लिए, tf.convert_to_tensor का उपयोग करें:
tf.convert_to_tensor(numeric_features)
<tf.Tensor: shape=(303, 5), dtype=float64, numpy=
array([[ 63. , 150. , 145. , 233. , 2.3],
[ 67. , 108. , 160. , 286. , 1.5],
[ 67. , 129. , 120. , 229. , 2.6],
...,
[ 65. , 127. , 135. , 254. , 2.8],
[ 48. , 150. , 130. , 256. , 0. ],
[ 63. , 154. , 150. , 407. , 4. ]])>
सामान्य तौर पर, यदि किसी वस्तु को tf.convert_to_tensor के साथ एक टेंसर में परिवर्तित किया जा सकता है तो इसे कहीं भी पास किया जा सकता है आप tf.Tensor पास कर सकते हैं।
Model.fit . के साथ
एक डेटाफ़्रेम, जिसे एकल टेंसर के रूप में व्याख्या किया गया है, को सीधे Model.fit विधि के तर्क के रूप में उपयोग किया जा सकता है।
डेटासेट की संख्यात्मक विशेषताओं पर एक मॉडल को प्रशिक्षित करने का एक उदाहरण नीचे दिया गया है।
पहला कदम इनपुट रेंज को सामान्य करना है। उसके लिए tf.keras.layers.Normalization लेयर का उपयोग करें।
परत के माध्य और मानक-विचलन को चलाने से पहले सेट करने के लिए, Normalization.adapt विधि को कॉल करना सुनिश्चित करें:
normalizer = tf.keras.layers.Normalization(axis=-1)
normalizer.adapt(numeric_features)
इस परत से आउटपुट के उदाहरण की कल्पना करने के लिए DataFrame की पहली तीन पंक्तियों पर परत को कॉल करें:
normalizer(numeric_features.iloc[:3])
<tf.Tensor: shape=(3, 5), dtype=float32, numpy=
array([[ 0.93383914, 0.03480718, 0.74578077, -0.26008663, 1.0680453 ],
[ 1.3782105 , -1.7806165 , 1.5923285 , 0.7573877 , 0.38022864],
[ 1.3782105 , -0.87290466, -0.6651321 , -0.33687714, 1.3259765 ]],
dtype=float32)>
एक साधारण मॉडल की पहली परत के रूप में सामान्यीकरण परत का उपयोग करें:
def get_basic_model():
model = tf.keras.Sequential([
normalizer,
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(1)
])
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
return model
जब आप DataFrame को x तर्क के रूप में Model.fit के रूप में पास करते हैं, तो Keras DataFrame को एक NumPy सरणी के रूप में मानता है:
model = get_basic_model()
model.fit(numeric_features, target, epochs=15, batch_size=BATCH_SIZE)
Epoch 1/15 152/152 [==============================] - 1s 2ms/step - loss: 0.6839 - accuracy: 0.7690 Epoch 2/15 152/152 [==============================] - 0s 2ms/step - loss: 0.5789 - accuracy: 0.7789 Epoch 3/15 152/152 [==============================] - 0s 2ms/step - loss: 0.5195 - accuracy: 0.7723 Epoch 4/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4814 - accuracy: 0.7855 Epoch 5/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4566 - accuracy: 0.7789 Epoch 6/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4427 - accuracy: 0.7888 Epoch 7/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4342 - accuracy: 0.7921 Epoch 8/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4290 - accuracy: 0.7855 Epoch 9/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4240 - accuracy: 0.7987 Epoch 10/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4232 - accuracy: 0.7987 Epoch 11/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4208 - accuracy: 0.7987 Epoch 12/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4186 - accuracy: 0.7954 Epoch 13/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4172 - accuracy: 0.8020 Epoch 14/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4156 - accuracy: 0.8020 Epoch 15/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4138 - accuracy: 0.8020 <keras.callbacks.History at 0x7f1ddc27b110>प्लेसहोल्डर17
tf.डेटा के साथ
यदि आप एक समान dtype के DataFrame में tf.data रूपांतरण लागू करना चाहते हैं, तो Dataset.from_tensor_slices विधि एक ऐसा डेटासेट बनाएगी जो डेटाफ़्रेम की पंक्तियों पर पुनरावृति करता है। प्रत्येक पंक्ति प्रारंभ में मानों का एक सदिश है। एक मॉडल को प्रशिक्षित करने के लिए, आपको (inputs, labels) जोड़े की आवश्यकता होती है, इसलिए पास (features, labels) और Dataset.from_tensor_slices स्लाइस के आवश्यक जोड़े लौटाएगा:
numeric_dataset = tf.data.Dataset.from_tensor_slices((numeric_features, target))
for row in numeric_dataset.take(3):
print(row)
(<tf.Tensor: shape=(5,), dtype=float64, numpy=array([ 63. , 150. , 145. , 233. , 2.3])>, <tf.Tensor: shape=(), dtype=int64, numpy=0>) (<tf.Tensor: shape=(5,), dtype=float64, numpy=array([ 67. , 108. , 160. , 286. , 1.5])>, <tf.Tensor: shape=(), dtype=int64, numpy=1>) (<tf.Tensor: shape=(5,), dtype=float64, numpy=array([ 67. , 129. , 120. , 229. , 2.6])>, <tf.Tensor: shape=(), dtype=int64, numpy=0>)
numeric_batches = numeric_dataset.shuffle(1000).batch(BATCH_SIZE)
model = get_basic_model()
model.fit(numeric_batches, epochs=15)
Epoch 1/15 152/152 [==============================] - 1s 2ms/step - loss: 0.7677 - accuracy: 0.6865 Epoch 2/15 152/152 [==============================] - 0s 2ms/step - loss: 0.6319 - accuracy: 0.7591 Epoch 3/15 152/152 [==============================] - 0s 2ms/step - loss: 0.5717 - accuracy: 0.7459 Epoch 4/15 152/152 [==============================] - 0s 2ms/step - loss: 0.5228 - accuracy: 0.7558 Epoch 5/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4820 - accuracy: 0.7624 Epoch 6/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4584 - accuracy: 0.7657 Epoch 7/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4454 - accuracy: 0.7657 Epoch 8/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4379 - accuracy: 0.7789 Epoch 9/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4324 - accuracy: 0.7789 Epoch 10/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4282 - accuracy: 0.7756 Epoch 11/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4273 - accuracy: 0.7789 Epoch 12/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4268 - accuracy: 0.7756 Epoch 13/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4248 - accuracy: 0.7789 Epoch 14/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4235 - accuracy: 0.7855 Epoch 15/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4223 - accuracy: 0.7888 <keras.callbacks.History at 0x7f1ddc406510>
एक डेटाफ़्रेम एक शब्दकोश के रूप में
जब आप विषम डेटा के साथ काम करना शुरू करते हैं, तो डेटाफ़्रेम के साथ ऐसा व्यवहार करना संभव नहीं है जैसे कि यह एक एकल सरणी हो। TensorFlow टेंसर के लिए आवश्यक है कि सभी तत्वों का dtype समान हो।
तो, इस मामले में, आपको इसे कॉलम के शब्दकोश के रूप में मानना शुरू करना होगा, जहां प्रत्येक कॉलम में एक समान प्रकार है। एक डेटाफ़्रेम बहुत कुछ सरणियों के शब्दकोश की तरह है, इसलिए आम तौर पर आपको केवल डेटाफ़्रेम को पायथन डिक्टेट में डालना है। कई महत्वपूर्ण TensorFlow API इनपुट के रूप में सरणियों के (नेस्टेड-) शब्दकोशों का समर्थन करते हैं।
tf.data इनपुट पाइपलाइन इसे काफी अच्छी तरह से संभालती हैं। सभी tf.data संचालन स्वचालित रूप से शब्दकोशों और टुपल्स को संभालते हैं। इसलिए, डेटाफ़्रेम से डिक्शनरी-उदाहरणों का एक डेटासेट बनाने के लिए, इसे Dataset.from_tensor_slices के साथ स्लाइस करने से पहले बस इसे एक तानाशाही में डालें:
numeric_dict_ds = tf.data.Dataset.from_tensor_slices((dict(numeric_features), target))
उस डेटासेट के पहले तीन उदाहरण यहां दिए गए हैं:
for row in numeric_dict_ds.take(3):
print(row)
({'age': <tf.Tensor: shape=(), dtype=int64, numpy=63>, 'thalach': <tf.Tensor: shape=(), dtype=int64, numpy=150>, 'trestbps': <tf.Tensor: shape=(), dtype=int64, numpy=145>, 'chol': <tf.Tensor: shape=(), dtype=int64, numpy=233>, 'oldpeak': <tf.Tensor: shape=(), dtype=float64, numpy=2.3>}, <tf.Tensor: shape=(), dtype=int64, numpy=0>)
({'age': <tf.Tensor: shape=(), dtype=int64, numpy=67>, 'thalach': <tf.Tensor: shape=(), dtype=int64, numpy=108>, 'trestbps': <tf.Tensor: shape=(), dtype=int64, numpy=160>, 'chol': <tf.Tensor: shape=(), dtype=int64, numpy=286>, 'oldpeak': <tf.Tensor: shape=(), dtype=float64, numpy=1.5>}, <tf.Tensor: shape=(), dtype=int64, numpy=1>)
({'age': <tf.Tensor: shape=(), dtype=int64, numpy=67>, 'thalach': <tf.Tensor: shape=(), dtype=int64, numpy=129>, 'trestbps': <tf.Tensor: shape=(), dtype=int64, numpy=120>, 'chol': <tf.Tensor: shape=(), dtype=int64, numpy=229>, 'oldpeak': <tf.Tensor: shape=(), dtype=float64, numpy=2.6>}, <tf.Tensor: shape=(), dtype=int64, numpy=0>)
केरासी के साथ शब्दकोश
आमतौर पर, केरस मॉडल और परतें एकल इनपुट टेंसर की अपेक्षा करती हैं, लेकिन ये वर्ग शब्दकोशों, टुपल्स और टेंसर की नेस्टेड संरचनाओं को स्वीकार और वापस कर सकते हैं। इन संरचनाओं को "घोंसले" के रूप में जाना जाता है (विवरण के लिए tf.nest मॉड्यूल देखें)।
दो समान तरीके हैं जिनसे आप एक केरस मॉडल लिख सकते हैं जो एक शब्दकोश को इनपुट के रूप में स्वीकार करता है।
1. मॉडल-उपवर्ग शैली
आप tf.keras.Model (या tf.keras.Layer ) का उपवर्ग लिखते हैं। आप सीधे इनपुट को संभालते हैं, और आउटपुट बनाते हैं:
def stack_dict(inputs, fun=tf.stack):
values = []
for key in sorted(inputs.keys()):
values.append(tf.cast(inputs[key], tf.float32))
return fun(values, axis=-1)
class MyModel(tf.keras.Model):
def __init__(self):
# Create all the internal layers in init.
super().__init__(self)
self.normalizer = tf.keras.layers.Normalization(axis=-1)
self.seq = tf.keras.Sequential([
self.normalizer,
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(1)
])
def adapt(self, inputs):
# Stach the inputs and `adapt` the normalization layer.
inputs = stack_dict(inputs)
self.normalizer.adapt(inputs)
def call(self, inputs):
# Stack the inputs
inputs = stack_dict(inputs)
# Run them through all the layers.
result = self.seq(inputs)
return result
model = MyModel()
model.adapt(dict(numeric_features))
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'],
run_eagerly=True)
यह मॉडल प्रशिक्षण के लिए या तो स्तंभों के शब्दकोश या शब्दकोश-तत्वों के डेटासेट को स्वीकार कर सकता है:
model.fit(dict(numeric_features), target, epochs=5, batch_size=BATCH_SIZE)
Epoch 1/5 152/152 [==============================] - 3s 17ms/step - loss: 0.6736 - accuracy: 0.7063 Epoch 2/5 152/152 [==============================] - 3s 17ms/step - loss: 0.5577 - accuracy: 0.7294 Epoch 3/5 152/152 [==============================] - 2s 16ms/step - loss: 0.4869 - accuracy: 0.7591 Epoch 4/5 152/152 [==============================] - 2s 16ms/step - loss: 0.4525 - accuracy: 0.7690 Epoch 5/5 152/152 [==============================] - 2s 16ms/step - loss: 0.4403 - accuracy: 0.7624 <keras.callbacks.History at 0x7f1de4fa9390>
numeric_dict_batches = numeric_dict_ds.shuffle(SHUFFLE_BUFFER).batch(BATCH_SIZE)
model.fit(numeric_dict_batches, epochs=5)
Epoch 1/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4328 - accuracy: 0.7756 Epoch 2/5 152/152 [==============================] - 2s 14ms/step - loss: 0.4297 - accuracy: 0.7888 Epoch 3/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4270 - accuracy: 0.7888 Epoch 4/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4245 - accuracy: 0.8020 Epoch 5/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4240 - accuracy: 0.7921 <keras.callbacks.History at 0x7f1ddc0dba90>
यहां पहले तीन उदाहरणों के लिए भविष्यवाणियां दी गई हैं:
model.predict(dict(numeric_features.iloc[:3]))
array([[[0.00565109]],
[[0.60601974]],
[[0.03647463]]], dtype=float32)
2. केरस कार्यात्मक शैली
inputs = {}
for name, column in numeric_features.items():
inputs[name] = tf.keras.Input(
shape=(1,), name=name, dtype=tf.float32)
inputs
{'age': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'age')>,
'thalach': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'thalach')>,
'trestbps': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'trestbps')>,
'chol': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'chol')>,
'oldpeak': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'oldpeak')>}
x = stack_dict(inputs, fun=tf.concat)
normalizer = tf.keras.layers.Normalization(axis=-1)
normalizer.adapt(stack_dict(dict(numeric_features)))
x = normalizer(x)
x = tf.keras.layers.Dense(10, activation='relu')(x)
x = tf.keras.layers.Dense(10, activation='relu')(x)
x = tf.keras.layers.Dense(1)(x)
model = tf.keras.Model(inputs, x)
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'],
run_eagerly=True)
tf.keras.utils.plot_model(model, rankdir="LR", show_shapes=True)

आप कार्यात्मक मॉडल को उसी तरह प्रशिक्षित कर सकते हैं जैसे मॉडल उपवर्ग:
model.fit(dict(numeric_features), target, epochs=5, batch_size=BATCH_SIZE)
Epoch 1/5 152/152 [==============================] - 2s 15ms/step - loss: 0.6529 - accuracy: 0.7492 Epoch 2/5 152/152 [==============================] - 2s 15ms/step - loss: 0.5448 - accuracy: 0.7624 Epoch 3/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4935 - accuracy: 0.7756 Epoch 4/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4650 - accuracy: 0.7789 Epoch 5/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4486 - accuracy: 0.7855 <keras.callbacks.History at 0x7f1ddc0d0f90>
numeric_dict_batches = numeric_dict_ds.shuffle(SHUFFLE_BUFFER).batch(BATCH_SIZE)
model.fit(numeric_dict_batches, epochs=5)
Epoch 1/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4398 - accuracy: 0.7855 Epoch 2/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4330 - accuracy: 0.7855 Epoch 3/5 152/152 [==============================] - 2s 16ms/step - loss: 0.4294 - accuracy: 0.7921 Epoch 4/5 152/152 [==============================] - 2s 16ms/step - loss: 0.4271 - accuracy: 0.7888 Epoch 5/5 152/152 [==============================] - 2s 16ms/step - loss: 0.4231 - accuracy: 0.7855 <keras.callbacks.History at 0x7f1d7c5d5d10>
पूरा उदाहरण
यह आप केरस को एक विषम DataFrame पास कर रहे हैं, प्रत्येक कॉलम को अद्वितीय प्रीप्रोसेसिंग की आवश्यकता हो सकती है। आप इस प्रीप्रोसेसिंग को सीधे डेटाफ़्रेम में कर सकते हैं, लेकिन एक मॉडल के सही ढंग से काम करने के लिए, इनपुट को हमेशा उसी तरह प्रीप्रोसेस करने की आवश्यकता होती है। तो, मॉडल में प्रीप्रोसेसिंग का निर्माण करना सबसे अच्छा तरीका है। केरस प्रीप्रोसेसिंग परतें कई सामान्य कार्यों को कवर करती हैं।
प्रीप्रोसेसिंग हेड बनाएं
इस डेटासेट में कच्चे डेटा में कुछ "पूर्णांक" विशेषताएं वास्तव में श्रेणीबद्ध सूचकांक हैं। इन सूचकांकों को वास्तव में संख्यात्मक मानों का आदेश नहीं दिया जाता है (विवरण के लिए डेटासेट विवरण देखें)। क्योंकि ये अनियंत्रित हैं, इसलिए वे सीधे मॉडल को फीड करने के लिए अनुपयुक्त हैं; मॉडल उन्हें आदेश के रूप में व्याख्या करेगा। इन इनपुट का उपयोग करने के लिए आपको उन्हें एक-हॉट वैक्टर या एम्बेडिंग वैक्टर के रूप में एन्कोड करना होगा। वही स्ट्रिंग-श्रेणीबद्ध सुविधाओं पर लागू होता है।
दूसरी ओर बाइनरी सुविधाओं को आम तौर पर एन्कोड या सामान्यीकृत करने की आवश्यकता नहीं होती है।
प्रत्येक समूह में आने वाली सुविधाओं की सूची बनाकर प्रारंभ करें:
binary_feature_names = ['sex', 'fbs', 'exang']
categorical_feature_names = ['cp', 'restecg', 'slope', 'thal', 'ca']
अगला कदम एक प्रीप्रोसेसिंग मॉडल बनाना है जो प्रत्येक इनपुट के लिए उपयुक्त प्रीप्रोसेसिंग लागू करेगा और परिणामों को जोड़ देगा।
यह खंड प्रीप्रोसेसिंग को लागू करने के लिए केरस फंक्शनल एपीआई का उपयोग करता है। आप डेटाफ़्रेम के प्रत्येक स्तंभ के लिए एक tf.keras.Input बनाकर प्रारंभ करें:
inputs = {}
for name, column in df.items():
if type(column[0]) == str:
dtype = tf.string
elif (name in categorical_feature_names or
name in binary_feature_names):
dtype = tf.int64
else:
dtype = tf.float32
inputs[name] = tf.keras.Input(shape=(), name=name, dtype=dtype)
inputs
{'age': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'age')>,
'sex': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'sex')>,
'cp': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'cp')>,
'trestbps': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'trestbps')>,
'chol': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'chol')>,
'fbs': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'fbs')>,
'restecg': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'restecg')>,
'thalach': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'thalach')>,
'exang': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'exang')>,
'oldpeak': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'oldpeak')>,
'slope': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'slope')>,
'ca': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'ca')>,
'thal': <KerasTensor: shape=(None,) dtype=string (created by layer 'thal')>}
प्रत्येक इनपुट के लिए आप Keras परतों और TensorFlow ops का उपयोग करके कुछ परिवर्तन लागू करेंगे। प्रत्येक सुविधा अदिश के एक बैच के रूप में शुरू होती है ( shape=(batch,) )। प्रत्येक के लिए आउटपुट tf.float32 वैक्टर ( shape=(batch, n) ) का एक बैच होना चाहिए। अंतिम चरण उन सभी वैक्टरों को एक साथ जोड़ देगा।
बाइनरी इनपुट
चूंकि बाइनरी इनपुट को किसी प्रीप्रोसेसिंग की आवश्यकता नहीं है, बस वेक्टर अक्ष जोड़ें, उन्हें float32 में डालें और उन्हें प्रीप्रोसेस्ड इनपुट की सूची में जोड़ें:
preprocessed = []
for name in binary_feature_names:
inp = inputs[name]
inp = inp[:, tf.newaxis]
float_value = tf.cast(inp, tf.float32)
preprocessed.append(float_value)
preprocessed
[<KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_5')>, <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_6')>, <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_7')>]
संख्यात्मक इनपुट
पिछले अनुभाग की तरह आप इन संख्यात्मक इनपुट को tf.keras.layers.Normalization लेयर के माध्यम से उपयोग करने से पहले चलाना चाहेंगे। अंतर यह है कि इस बार वे एक निर्देश के रूप में इनपुट कर रहे हैं। नीचे दिया गया कोड डेटाफ़्रेम से संख्यात्मक विशेषताओं को एकत्र करता है, उन्हें एक साथ ढेर करता है और उन्हें Normalization.adapt विधि में भेजता है।
normalizer = tf.keras.layers.Normalization(axis=-1)
normalizer.adapt(stack_dict(dict(numeric_features)))
नीचे दिया गया कोड संख्यात्मक विशेषताओं को ढेर करता है और उन्हें सामान्यीकरण परत के माध्यम से चलाता है।
numeric_inputs = {}
for name in numeric_feature_names:
numeric_inputs[name]=inputs[name]
numeric_inputs = stack_dict(numeric_inputs)
numeric_normalized = normalizer(numeric_inputs)
preprocessed.append(numeric_normalized)
preprocessed
[<KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_5')>, <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_6')>, <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_7')>, <KerasTensor: shape=(None, 5) dtype=float32 (created by layer 'normalization_3')>]
श्रेणीबद्ध विशेषताएं
श्रेणीबद्ध सुविधाओं का उपयोग करने के लिए आपको पहले उन्हें बाइनरी वैक्टर या एम्बेडिंग में एन्कोड करना होगा। चूंकि इन सुविधाओं में केवल श्रेणियों की एक छोटी संख्या होती है, tf.keras.layers.StringLookup और tf.keras.layers.IntegerLookup परतों दोनों द्वारा समर्थित, output_mode='one_hot' विकल्प का उपयोग करके इनपुट को सीधे एक-हॉट वैक्टर में परिवर्तित करें।
यहां एक उदाहरण दिया गया है कि ये परतें कैसे काम करती हैं:
vocab = ['a','b','c']
lookup = tf.keras.layers.StringLookup(vocabulary=vocab, output_mode='one_hot')
lookup(['c','a','a','b','zzz'])
<tf.Tensor: shape=(5, 4), dtype=float32, numpy=
array([[0., 0., 0., 1.],
[0., 1., 0., 0.],
[0., 1., 0., 0.],
[0., 0., 1., 0.],
[1., 0., 0., 0.]], dtype=float32)>
vocab = [1,4,7,99]
lookup = tf.keras.layers.IntegerLookup(vocabulary=vocab, output_mode='one_hot')
lookup([-1,4,1])
<tf.Tensor: shape=(3, 5), dtype=float32, numpy=
array([[1., 0., 0., 0., 0.],
[0., 0., 1., 0., 0.],
[0., 1., 0., 0., 0.]], dtype=float32)>
प्रत्येक इनपुट के लिए शब्दावली निर्धारित करने के लिए, उस शब्दावली को एक-हॉट वेक्टर में बदलने के लिए एक परत बनाएं:
for name in categorical_feature_names:
vocab = sorted(set(df[name]))
print(f'name: {name}')
print(f'vocab: {vocab}\n')
if type(vocab[0]) is str:
lookup = tf.keras.layers.StringLookup(vocabulary=vocab, output_mode='one_hot')
else:
lookup = tf.keras.layers.IntegerLookup(vocabulary=vocab, output_mode='one_hot')
x = inputs[name][:, tf.newaxis]
x = lookup(x)
preprocessed.append(x)
name: cp vocab: [0, 1, 2, 3, 4] name: restecg vocab: [0, 1, 2] name: slope vocab: [1, 2, 3] name: thal vocab: ['1', '2', 'fixed', 'normal', 'reversible'] name: ca vocab: [0, 1, 2, 3]
प्रीप्रोसेसिंग हेड को इकट्ठा करें
इस बिंदु पर preprocessed सभी प्रीप्रोसेसिंग परिणामों की सिर्फ एक पायथन सूची है, प्रत्येक परिणाम का आकार (batch_size, depth) होता है:
preprocessed
[<KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_5')>, <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_6')>, <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_7')>, <KerasTensor: shape=(None, 5) dtype=float32 (created by layer 'normalization_3')>, <KerasTensor: shape=(None, 6) dtype=float32 (created by layer 'integer_lookup_1')>, <KerasTensor: shape=(None, 4) dtype=float32 (created by layer 'integer_lookup_2')>, <KerasTensor: shape=(None, 4) dtype=float32 (created by layer 'integer_lookup_3')>, <KerasTensor: shape=(None, 6) dtype=float32 (created by layer 'string_lookup_1')>, <KerasTensor: shape=(None, 5) dtype=float32 (created by layer 'integer_lookup_4')>]
सभी पूर्व-संसाधित सुविधाओं को depth अक्ष के साथ संयोजित करें, ताकि प्रत्येक शब्दकोश-उदाहरण एक एकल वेक्टर में परिवर्तित हो जाए। वेक्टर में श्रेणीबद्ध विशेषताएं, संख्यात्मक विशेषताएं और श्रेणीबद्ध एक-गर्म विशेषताएं शामिल हैं:
preprocesssed_result = tf.concat(preprocessed, axis=-1)
preprocesssed_result
<KerasTensor: shape=(None, 33) dtype=float32 (created by layer 'tf.concat_1')>
अब उस गणना से एक मॉडल बनाएं ताकि उसका पुन: उपयोग किया जा सके:
preprocessor = tf.keras.Model(inputs, preprocesssed_result)
tf.keras.utils.plot_model(preprocessor, rankdir="LR", show_shapes=True)
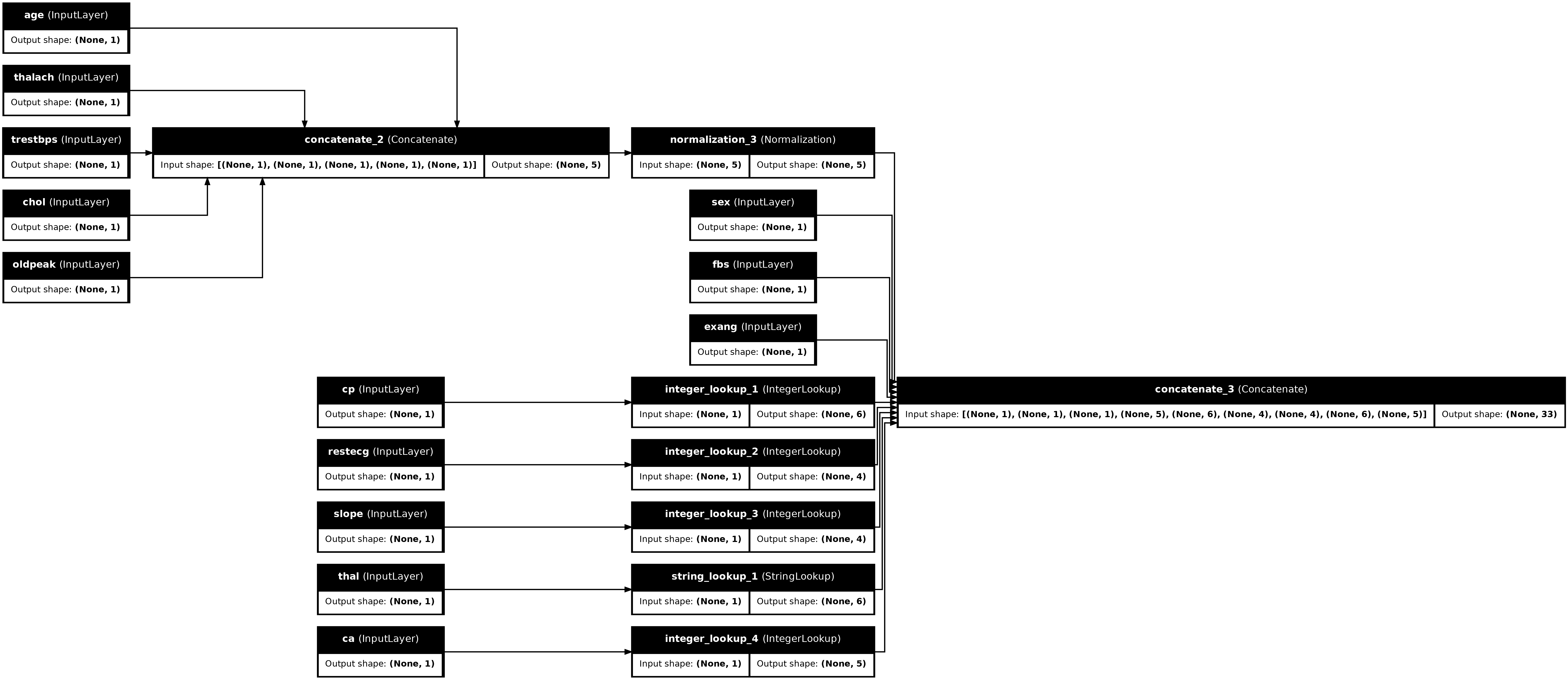
प्रीप्रोसेसर का परीक्षण करने के लिए, DataFrame से पहले उदाहरण को स्लाइस करने के लिए DataFrame.iloc एक्सेसर का उपयोग करें। फिर इसे एक डिक्शनरी में कनवर्ट करें और डिक्शनरी को प्रीप्रोसेसर को पास करें। परिणाम एक एकल वेक्टर है जिसमें बाइनरी फीचर्स, सामान्यीकृत संख्यात्मक विशेषताएं और एक-गर्म श्रेणीबद्ध विशेषताएं हैं, उस क्रम में:
preprocessor(dict(df.iloc[:1]))
<tf.Tensor: shape=(1, 33), dtype=float32, numpy=
array([[ 1. , 1. , 0. , 0.93383914, -0.26008663,
1.0680453 , 0.03480718, 0.74578077, 0. , 0. ,
1. , 0. , 0. , 0. , 0. ,
0. , 0. , 1. , 0. , 0. ,
0. , 1. , 0. , 0. , 0. ,
1. , 0. , 0. , 0. , 1. ,
0. , 0. , 0. ]], dtype=float32)>
एक मॉडल बनाएं और प्रशिक्षित करें
अब मॉडल की मुख्य बॉडी बनाएं। पिछले उदाहरण के समान कॉन्फ़िगरेशन का उपयोग करें: वर्गीकरण के लिए कुछ घनी रेक्टिफाइड-रैखिक परतें और एक Dense Dense(1) आउटपुट परत।
body = tf.keras.Sequential([
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(1)
])
अब केरस फंक्शनल एपीआई का उपयोग करके दो टुकड़ों को एक साथ रखें।
inputs
{'age': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'age')>,
'sex': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'sex')>,
'cp': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'cp')>,
'trestbps': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'trestbps')>,
'chol': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'chol')>,
'fbs': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'fbs')>,
'restecg': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'restecg')>,
'thalach': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'thalach')>,
'exang': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'exang')>,
'oldpeak': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'oldpeak')>,
'slope': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'slope')>,
'ca': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'ca')>,
'thal': <KerasTensor: shape=(None,) dtype=string (created by layer 'thal')>}
x = preprocessor(inputs)
x
<KerasTensor: shape=(None, 33) dtype=float32 (created by layer 'model_1')>70 l10n-
result = body(x)
result
<KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'sequential_3')>
model = tf.keras.Model(inputs, result)
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
यह मॉडल इनपुट्स के डिक्शनरी की अपेक्षा करता है। इसे डेटा पास करने का सबसे आसान तरीका है डेटाफ्रेम को एक ताना में परिवर्तित करना और उस निर्देश को x तर्क के रूप में Model.fit पर पास करना:
history = model.fit(dict(df), target, epochs=5, batch_size=BATCH_SIZE)
Epoch 1/5 152/152 [==============================] - 1s 4ms/step - loss: 0.6911 - accuracy: 0.6997 Epoch 2/5 152/152 [==============================] - 1s 4ms/step - loss: 0.5073 - accuracy: 0.7393 Epoch 3/5 152/152 [==============================] - 1s 4ms/step - loss: 0.4129 - accuracy: 0.7888 Epoch 4/5 152/152 [==============================] - 1s 4ms/step - loss: 0.3663 - accuracy: 0.7921 Epoch 5/5 152/152 [==============================] - 1s 4ms/step - loss: 0.3363 - accuracy: 0.8152
tf.data का उपयोग करना भी काम करता है:
ds = tf.data.Dataset.from_tensor_slices((
dict(df),
target
))
ds = ds.batch(BATCH_SIZE)
import pprint
for x, y in ds.take(1):
pprint.pprint(x)
print()
print(y)
{'age': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([63, 67])>,
'ca': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([0, 3])>,
'chol': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([233, 286])>,
'cp': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([1, 4])>,
'exang': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([0, 1])>,
'fbs': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([1, 0])>,
'oldpeak': <tf.Tensor: shape=(2,), dtype=float64, numpy=array([2.3, 1.5])>,
'restecg': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([2, 2])>,
'sex': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([1, 1])>,
'slope': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([3, 2])>,
'thal': <tf.Tensor: shape=(2,), dtype=string, numpy=array([b'fixed', b'normal'], dtype=object)>,
'thalach': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([150, 108])>,
'trestbps': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([145, 160])>}
tf.Tensor([0 1], shape=(2,), dtype=int64)
history = model.fit(ds, epochs=5)
Epoch 1/5 152/152 [==============================] - 1s 5ms/step - loss: 0.3150 - accuracy: 0.8284 Epoch 2/5 152/152 [==============================] - 1s 5ms/step - loss: 0.2989 - accuracy: 0.8449 Epoch 3/5 152/152 [==============================] - 1s 5ms/step - loss: 0.2870 - accuracy: 0.8449 Epoch 4/5 152/152 [==============================] - 1s 5ms/step - loss: 0.2782 - accuracy: 0.8482 Epoch 5/5 152/152 [==============================] - 1s 5ms/step - loss: 0.2712 - accuracy: 0.8482