
| | |  Xem nguồn trên GitHub Xem nguồn trên GitHub | |
Hướng dẫn này trình bày cách phân loại dữ liệu có cấu trúc, chẳng hạn như dữ liệu dạng bảng, bằng cách sử dụng phiên bản đơn giản hóa của bộ dữ liệu PetFinder từ một cuộc thi Kaggle được lưu trữ trong tệp CSV.
Bạn sẽ sử dụng Keras để xác định mô hình và các lớp tiền xử lý của Keras làm cầu nối để ánh xạ từ các cột trong tệp CSV đến các đối tượng địa lý được sử dụng để huấn luyện mô hình. Mục đích là để dự đoán xem một con vật cưng sẽ được nhận nuôi hay không.
Hướng dẫn này chứa mã hoàn chỉnh cho:
- Tải tệp CSV vào DataFrame bằng gấu trúc .
- Xây dựng một đường dẫn đầu vào để xử lý hàng loạt và xáo trộn các hàng bằng cách sử dụng
tf.data. (Truy cập tf.data: Xây dựng đường ống đầu vào TensorFlow để biết thêm chi tiết.) - Ánh xạ từ các cột trong tệp CSV đến các tính năng được sử dụng để đào tạo mô hình với các lớp tiền xử lý Keras.
- Xây dựng, đào tạo và đánh giá một mô hình bằng các phương pháp tích hợp của Keras.
Tập dữ liệu mini PetFinder.my
Có vài nghìn hàng trong tệp dữ liệu CSV của PetFinder.my mini, trong đó mỗi hàng mô tả một con vật cưng (chó hoặc mèo) và mỗi cột mô tả một thuộc tính, chẳng hạn như tuổi, giống, màu sắc, v.v.
Trong phần tóm tắt của tập dữ liệu dưới đây, hãy lưu ý rằng hầu hết là các cột số và cột phân loại. Trong hướng dẫn này, bạn sẽ chỉ xử lý hai loại tính năng đó, loại bỏ Description (tính năng văn bản miễn phí) và AdoptionSpeed (tính năng phân loại) trong quá trình xử lý trước dữ liệu.
| Cột | Mô tả vật nuôi | Loại tính năng | Loại dữ liệu |
|---|---|---|---|
Type | Loại động vật ( Dog , Cat ) | Phân loại | Chuỗi |
Age | Già đi | Số | Số nguyên |
Breed1 | Giống chính | Phân loại | Chuỗi |
Color1 | Màu 1 | Phân loại | Chuỗi |
Color2 | Màu 2 | Phân loại | Chuỗi |
MaturitySize | Kích thước khi trưởng thành | Phân loại | Chuỗi |
FurLength | Chiều dài lông | Phân loại | Chuỗi |
Vaccinated | Thú cưng đã được tiêm phòng | Phân loại | Chuỗi |
Sterilized | Thú cưng đã được triệt sản | Phân loại | Chuỗi |
Health | Tình trạng sức khỏe | Phân loại | Chuỗi |
Fee | Phí nhận con nuôi | Số | Số nguyên |
Description | Viết lên hồ sơ | Chữ | Chuỗi |
PhotoAmt | Tổng số ảnh đã tải lên | Số | Số nguyên |
AdoptionSpeed | Tốc độ chấp nhận theo phân loại | Phân loại | Số nguyên |
Nhập TensorFlow và các thư viện khác
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow.keras import layers
tf.__version__
'2.8.0-rc1'
Tải tập dữ liệu và đọc nó vào DataFrame gấu trúc
pandas là một thư viện Python với nhiều tiện ích hữu ích để tải và làm việc với dữ liệu có cấu trúc. Sử dụng tf.keras.utils.get_file để tải xuống và giải nén tệp CSV bằng tập dữ liệu nhỏ PetFinder.my và tải nó vào DataFrame với pandas.read_csv :
dataset_url = 'http://storage.googleapis.com/download.tensorflow.org/data/petfinder-mini.zip'
csv_file = 'datasets/petfinder-mini/petfinder-mini.csv'
tf.keras.utils.get_file('petfinder_mini.zip', dataset_url,
extract=True, cache_dir='.')
dataframe = pd.read_csv(csv_file)
Downloading data from http://storage.googleapis.com/download.tensorflow.org/data/petfinder-mini.zip 1671168/1668792 [==============================] - 0s 0us/step 1679360/1668792 [==============================] - 0s 0us/step
Kiểm tra tập dữ liệu bằng cách kiểm tra năm hàng đầu tiên của DataFrame:
dataframe.head()
Tạo một biến mục tiêu
Nhiệm vụ ban đầu trong cuộc thi Dự đoán việc nhận con nuôi PetFinder.my của Kaggle là dự đoán tốc độ thú cưng sẽ được nhận nuôi (ví dụ: trong tuần đầu tiên, tháng đầu tiên, ba tháng đầu tiên, v.v.).
Trong hướng dẫn này, bạn sẽ đơn giản hóa nhiệm vụ bằng cách chuyển nó thành một bài toán phân loại nhị phân, nơi bạn chỉ cần dự đoán liệu một con vật cưng có được nhận nuôi hay không.
Sau khi sửa đổi cột AdoptionSpeed , 0 sẽ cho biết vật nuôi không được nhận nuôi và 1 sẽ cho biết nó đã được nhận nuôi.
# In the original dataset, `'AdoptionSpeed'` of `4` indicates
# a pet was not adopted.
dataframe['target'] = np.where(dataframe['AdoptionSpeed']==4, 0, 1)
# Drop unused features.
dataframe = dataframe.drop(columns=['AdoptionSpeed', 'Description'])
Chia DataFrame thành các bộ đào tạo, xác thực và kiểm tra
Tập dữ liệu nằm trong một DataFrame gấu trúc duy nhất. Chia nó thành các bộ đào tạo, xác thực và kiểm tra bằng cách sử dụng tỷ lệ, ví dụ: 80:10:10, tương ứng:
train, val, test = np.split(dataframe.sample(frac=1), [int(0.8*len(dataframe)), int(0.9*len(dataframe))])
print(len(train), 'training examples')
print(len(val), 'validation examples')
print(len(test), 'test examples')
9229 training examples 1154 validation examples 1154 test examples
Tạo một đường dẫn đầu vào bằng tf.data
Tiếp theo, tạo một chức năng tiện ích chuyển đổi từng tập dữ liệu huấn luyện, xác thực và kiểm tra DataFrame thành tf.data.Dataset , sau đó xáo trộn và chia lô dữ liệu.
def df_to_dataset(dataframe, shuffle=True, batch_size=32):
df = dataframe.copy()
labels = df.pop('target')
df = {key: value[:,tf.newaxis] for key, value in dataframe.items()}
ds = tf.data.Dataset.from_tensor_slices((dict(df), labels))
if shuffle:
ds = ds.shuffle(buffer_size=len(dataframe))
ds = ds.batch(batch_size)
ds = ds.prefetch(batch_size)
return ds
Bây giờ, hãy sử dụng hàm mới được tạo ( df_to_dataset ) để kiểm tra định dạng của dữ liệu mà hàm trợ giúp đường dẫn đầu vào trả về bằng cách gọi nó trên dữ liệu đào tạo và sử dụng kích thước lô nhỏ để giữ cho đầu ra có thể đọc được:
batch_size = 5
train_ds = df_to_dataset(train, batch_size=batch_size)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:4: FutureWarning: Support for multi-dimensional indexing (e.g. `obj[:, None]`) is deprecated and will be removed in a future version. Convert to a numpy array before indexing instead. after removing the cwd from sys.path.
[(train_features, label_batch)] = train_ds.take(1)
print('Every feature:', list(train_features.keys()))
print('A batch of ages:', train_features['Age'])
print('A batch of targets:', label_batch )
Every feature: ['Type', 'Age', 'Breed1', 'Gender', 'Color1', 'Color2', 'MaturitySize', 'FurLength', 'Vaccinated', 'Sterilized', 'Health', 'Fee', 'PhotoAmt', 'target'] A batch of ages: tf.Tensor( [[84] [ 1] [ 5] [ 1] [12]], shape=(5, 1), dtype=int64) A batch of targets: tf.Tensor([1 1 0 1 0], shape=(5,), dtype=int64)
Khi đầu ra minh họa, tập huấn luyện trả về một từ điển tên cột (từ DataFrame) ánh xạ tới các giá trị cột từ các hàng.
Áp dụng các lớp tiền xử lý Keras
Các lớp tiền xử lý Keras cho phép bạn xây dựng các đường ống xử lý đầu vào gốc Keras, có thể được sử dụng làm mã tiền xử lý độc lập trong quy trình làm việc không phải của Keras, kết hợp trực tiếp với các mô hình Keras và được xuất như một phần của Keras SavedModel.
Trong hướng dẫn này, bạn sẽ sử dụng bốn lớp tiền xử lý sau để trình bày cách thực hiện tiền xử lý, mã hóa dữ liệu có cấu trúc và kỹ thuật tính năng:
-
tf.keras.layers.Normalization: Thực hiện chuẩn hóa các tính năng đầu vào một cách thông minh. -
tf.keras.layers.CategoryEncoding: Biến các đối tượng phân loại số nguyên thành các biểu diễn dày đặc một nóng, nhiều nóng hoặc tf-idf . -
tf.keras.layers.StringLookup: Chuyển các giá trị phân loại chuỗi thành các chỉ số nguyên. -
tf.keras.layers.IntegerLookup: Chuyển các giá trị phân loại số nguyên thành chỉ số nguyên.
Bạn có thể tìm hiểu thêm về các lớp có sẵn trong hướng dẫn Làm việc với các lớp tiền xử lý .
- Đối với các tính năng số của tập dữ liệu nhỏ PetFinder.my, bạn sẽ sử dụng lớp
tf.keras.layers.Normalizationđể chuẩn hóa việc phân phối dữ liệu. - Đối với các tính năng phân loại , chẳng hạn như
Typevật nuôi (chuỗiDogvàCat), bạn sẽ biến đổi chúng thành các tenxơ được mã hóa đa điểm nóng vớitf.keras.layers.CategoryEncoding.
Cột số
Đối với mỗi tính năng số trong tập dữ liệu nhỏ PetFinder.my, bạn sẽ sử dụng lớp tf.keras.layers.Normalization để chuẩn hóa việc phân phối dữ liệu.
Xác định một chức năng tiện ích mới trả về một lớp áp dụng chuẩn hóa tính năng khôn ngoan cho các tính năng số bằng cách sử dụng lớp tiền xử lý Keras đó:
def get_normalization_layer(name, dataset):
# Create a Normalization layer for the feature.
normalizer = layers.Normalization(axis=None)
# Prepare a Dataset that only yields the feature.
feature_ds = dataset.map(lambda x, y: x[name])
# Learn the statistics of the data.
normalizer.adapt(feature_ds)
return normalizer
Tiếp theo, hãy kiểm tra chức năng mới bằng cách gọi nó trên tổng số các tính năng ảnh thú cưng đã tải lên để chuẩn hóa 'PhotoAmt' :
photo_count_col = train_features['PhotoAmt']
layer = get_normalization_layer('PhotoAmt', train_ds)
layer(photo_count_col)
<tf.Tensor: shape=(5, 1), dtype=float32, numpy=
array([[-0.8272058 ],
[-0.19125296],
[ 1.3986291 ],
[-0.19125296],
[-0.50922936]], dtype=float32)>
Cột phân loại
Các Type vật nuôi trong tập dữ liệu được biểu thị dưới dạng chuỗi— Các Dog và Cat — cần được mã hóa nhiều vùng nóng trước khi được đưa vào mô hình. Tính năng Age
Xác định một chức năng tiện ích mới khác trả về một lớp ánh xạ các giá trị từ một từ vựng đến các chỉ số nguyên và mã hóa nhiều vùng nóng bằng cách sử dụng tf.keras.layers.StringLookup , tf.keras.layers.IntegerLookup và tf.keras.CategoryEncoding các lớp:
def get_category_encoding_layer(name, dataset, dtype, max_tokens=None):
# Create a layer that turns strings into integer indices.
if dtype == 'string':
index = layers.StringLookup(max_tokens=max_tokens)
# Otherwise, create a layer that turns integer values into integer indices.
else:
index = layers.IntegerLookup(max_tokens=max_tokens)
# Prepare a `tf.data.Dataset` that only yields the feature.
feature_ds = dataset.map(lambda x, y: x[name])
# Learn the set of possible values and assign them a fixed integer index.
index.adapt(feature_ds)
# Encode the integer indices.
encoder = layers.CategoryEncoding(num_tokens=index.vocabulary_size())
# Apply multi-hot encoding to the indices. The lambda function captures the
# layer, so you can use them, or include them in the Keras Functional model later.
return lambda feature: encoder(index(feature))
Kiểm tra hàm get_category_encoding_layer bằng cách gọi nó trên các tính năng 'Type' thú cưng để biến chúng thành các tenxơ được mã hóa đa điểm nóng:
test_type_col = train_features['Type']
test_type_layer = get_category_encoding_layer(name='Type',
dataset=train_ds,
dtype='string')
test_type_layer(test_type_col)
<tf.Tensor: shape=(5, 3), dtype=float32, numpy=
array([[0., 1., 0.],
[0., 1., 0.],
[0., 1., 0.],
[0., 1., 0.],
[0., 1., 0.]], dtype=float32)>
Lặp lại quy trình trên các tính năng 'Age' thú cưng:
test_age_col = train_features['Age']
test_age_layer = get_category_encoding_layer(name='Age',
dataset=train_ds,
dtype='int64',
max_tokens=5)
test_age_layer(test_age_col)
<tf.Tensor: shape=(5, 5), dtype=float32, numpy=
array([[1., 0., 0., 0., 0.],
[0., 0., 0., 1., 0.],
[1., 0., 0., 0., 0.],
[0., 0., 0., 1., 0.],
[1., 0., 0., 0., 0.]], dtype=float32)>
Xử lý trước các tính năng đã chọn để đào tạo mô hình
Bạn đã học cách sử dụng một số loại lớp tiền xử lý Keras. Tiếp theo, bạn sẽ:
- Áp dụng các chức năng tiện ích tiền xử lý được xác định trước đó trên 13 tính năng số và phân loại từ tập dữ liệu mini PetFinder.my.
- Thêm tất cả các đầu vào tính năng vào một danh sách.
Như đã đề cập ở phần đầu, để đào tạo mô hình, bạn sẽ sử dụng số của tập dữ liệu nhỏ PetFinder.my ( 'PhotoAmt' , 'Fee' ) và phân loại ( 'Age' , 'Type' , 'Color1' , 'Color2' , 'Gender' , 'MaturitySize' , 'FurLength' , 'Vaccinated' ,' Sterized 'Sterilized' , 'Health' , 'Breed1' ).
Trước đó, bạn đã sử dụng kích thước lô nhỏ để chứng minh đường dẫn đầu vào. Bây giờ, hãy tạo một đường dẫn đầu vào mới với kích thước lô lớn hơn là 256:
batch_size = 256
train_ds = df_to_dataset(train, batch_size=batch_size)
val_ds = df_to_dataset(val, shuffle=False, batch_size=batch_size)
test_ds = df_to_dataset(test, shuffle=False, batch_size=batch_size)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:4: FutureWarning: Support for multi-dimensional indexing (e.g. `obj[:, None]`) is deprecated and will be removed in a future version. Convert to a numpy array before indexing instead. after removing the cwd from sys.path.
Chuẩn hóa các tính năng số (số lượng ảnh thú cưng và phí nhận nuôi) và thêm chúng vào một danh sách đầu vào được gọi là encoded_features :
all_inputs = []
encoded_features = []
# Numerical features.
for header in ['PhotoAmt', 'Fee']:
numeric_col = tf.keras.Input(shape=(1,), name=header)
normalization_layer = get_normalization_layer(header, train_ds)
encoded_numeric_col = normalization_layer(numeric_col)
all_inputs.append(numeric_col)
encoded_features.append(encoded_numeric_col)
Chuyển các giá trị phân loại số nguyên từ tập dữ liệu (tuổi vật nuôi) thành các chỉ số nguyên, thực hiện mã hóa nhiều vùng nóng và thêm các đầu vào tính năng kết quả vào encoded_features :
age_col = tf.keras.Input(shape=(1,), name='Age', dtype='int64')
encoding_layer = get_category_encoding_layer(name='Age',
dataset=train_ds,
dtype='int64',
max_tokens=5)
encoded_age_col = encoding_layer(age_col)
all_inputs.append(age_col)
encoded_features.append(encoded_age_col)
Lặp lại bước tương tự cho các giá trị phân loại của chuỗi:
categorical_cols = ['Type', 'Color1', 'Color2', 'Gender', 'MaturitySize',
'FurLength', 'Vaccinated', 'Sterilized', 'Health', 'Breed1']
for header in categorical_cols:
categorical_col = tf.keras.Input(shape=(1,), name=header, dtype='string')
encoding_layer = get_category_encoding_layer(name=header,
dataset=train_ds,
dtype='string',
max_tokens=5)
encoded_categorical_col = encoding_layer(categorical_col)
all_inputs.append(categorical_col)
encoded_features.append(encoded_categorical_col)
Tạo, biên dịch và đào tạo mô hình
Bước tiếp theo là tạo một mô hình bằng cách sử dụng API chức năng Keras . Đối với lớp đầu tiên trong mô hình của bạn, hãy hợp nhất danh sách các đầu vào tính năng— encoded_features — vào một vectơ thông qua ghép với tf.keras.layers.concatenate .
all_features = tf.keras.layers.concatenate(encoded_features)
x = tf.keras.layers.Dense(32, activation="relu")(all_features)
x = tf.keras.layers.Dropout(0.5)(x)
output = tf.keras.layers.Dense(1)(x)
model = tf.keras.Model(all_inputs, output)
Định cấu hình mô hình với Keras Model.compile :
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=["accuracy"])
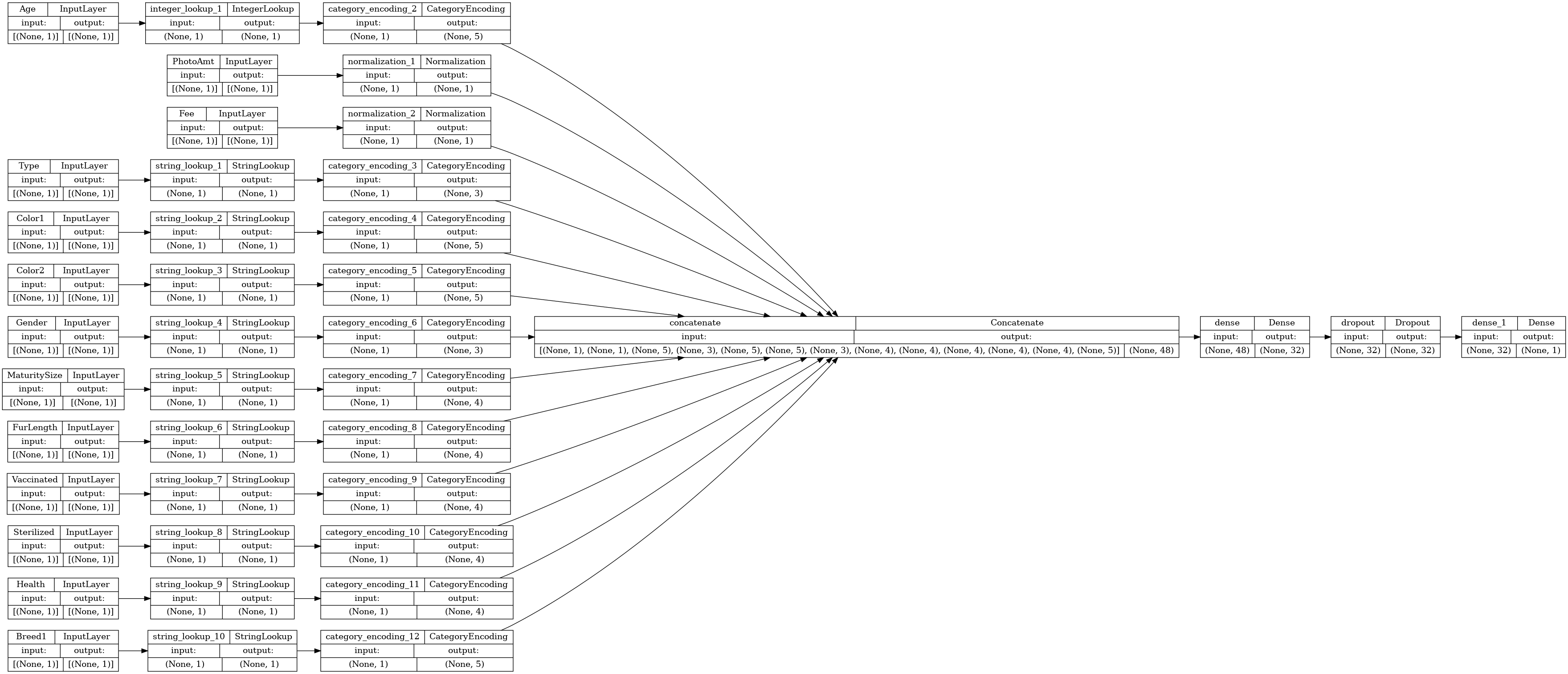
Hãy hình dung biểu đồ kết nối:
# Use `rankdir='LR'` to make the graph horizontal.
tf.keras.utils.plot_model(model, show_shapes=True, rankdir="LR")
Tiếp theo, đào tạo và kiểm tra mô hình:
model.fit(train_ds, epochs=10, validation_data=val_ds)
Epoch 1/10 /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/keras/engine/functional.py:559: UserWarning: Input dict contained keys ['target'] which did not match any model input. They will be ignored by the model. inputs = self._flatten_to_reference_inputs(inputs) 37/37 [==============================] - 2s 19ms/step - loss: 0.6524 - accuracy: 0.5034 - val_loss: 0.5887 - val_accuracy: 0.6941 Epoch 2/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5906 - accuracy: 0.6648 - val_loss: 0.5627 - val_accuracy: 0.7218 Epoch 3/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5697 - accuracy: 0.6924 - val_loss: 0.5463 - val_accuracy: 0.7504 Epoch 4/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5558 - accuracy: 0.6978 - val_loss: 0.5346 - val_accuracy: 0.7504 Epoch 5/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5502 - accuracy: 0.7105 - val_loss: 0.5272 - val_accuracy: 0.7487 Epoch 6/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5415 - accuracy: 0.7123 - val_loss: 0.5210 - val_accuracy: 0.7608 Epoch 7/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5354 - accuracy: 0.7171 - val_loss: 0.5152 - val_accuracy: 0.7435 Epoch 8/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5301 - accuracy: 0.7214 - val_loss: 0.5113 - val_accuracy: 0.7513 Epoch 9/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5286 - accuracy: 0.7189 - val_loss: 0.5087 - val_accuracy: 0.7574 Epoch 10/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5252 - accuracy: 0.7260 - val_loss: 0.5058 - val_accuracy: 0.7539 <keras.callbacks.History at 0x7f5f9fa91c50>
loss, accuracy = model.evaluate(test_ds)
print("Accuracy", accuracy)
5/5 [==============================] - 0s 6ms/step - loss: 0.5012 - accuracy: 0.7626 Accuracy 0.762565016746521
Thực hiện suy luận
Mô hình bạn đã phát triển hiện có thể phân loại một hàng từ tệp CSV trực tiếp sau khi bạn đã bao gồm các lớp tiền xử lý bên trong chính mô hình đó.
Bây giờ bạn có thể lưu và tải lại mô hình Keras với Model.save và Model.load_model trước khi thực hiện suy luận trên dữ liệu mới:
model.save('my_pet_classifier')
reloaded_model = tf.keras.models.load_model('my_pet_classifier')
2022-01-26 06:20:08.013613: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. WARNING:absl:Function `_wrapped_model` contains input name(s) PhotoAmt, Fee, Age, Type, Color1, Color2, Gender, MaturitySize, FurLength, Vaccinated, Sterilized, Health, Breed1 with unsupported characters which will be renamed to photoamt, fee, age, type, color1, color2, gender, maturitysize, furlength, vaccinated, sterilized, health, breed1 in the SavedModel. INFO:tensorflow:Assets written to: my_pet_classifier/assets INFO:tensorflow:Assets written to: my_pet_classifier/assets
Để nhận dự đoán cho một mẫu mới, bạn có thể chỉ cần gọi phương thức Model.predict . Chỉ có hai điều bạn cần làm:
- Gói các đại lượng vô hướng vào một danh sách để có thứ nguyên hàng loạt (
Modelchỉ xử lý các lô dữ liệu, không phải các mẫu đơn lẻ). - Gọi
tf.convert_to_tensortrên từng tính năng.
sample = {
'Type': 'Cat',
'Age': 3,
'Breed1': 'Tabby',
'Gender': 'Male',
'Color1': 'Black',
'Color2': 'White',
'MaturitySize': 'Small',
'FurLength': 'Short',
'Vaccinated': 'No',
'Sterilized': 'No',
'Health': 'Healthy',
'Fee': 100,
'PhotoAmt': 2,
}
input_dict = {name: tf.convert_to_tensor([value]) for name, value in sample.items()}
predictions = reloaded_model.predict(input_dict)
prob = tf.nn.sigmoid(predictions[0])
print(
"This particular pet had a %.1f percent probability "
"of getting adopted." % (100 * prob)
)
This particular pet had a 77.7 percent probability of getting adopted.
Bước tiếp theo
Để tìm hiểu thêm về cách phân loại dữ liệu có cấu trúc, hãy thử làm việc với các tập dữ liệu khác. Để cải thiện độ chính xác trong quá trình đào tạo và thử nghiệm mô hình của bạn, hãy suy nghĩ kỹ về những tính năng nào cần đưa vào mô hình của bạn và cách chúng nên được thể hiện.
Dưới đây là một số gợi ý cho tập dữ liệu:
- TensorFlow Datasets: MovieLens : Tập hợp các xếp hạng phim từ dịch vụ đề xuất phim.
- Bộ dữ liệu TensorFlow: Chất lượng rượu : Hai bộ dữ liệu liên quan đến các biến thể màu đỏ và trắng của rượu vang "Vinho Verde" của Bồ Đào Nha. Bạn cũng có thể tìm thấy bộ dữ liệu Chất lượng rượu vang đỏ trên Kaggle .
- Kaggle: arXiv Dataset : Một kho dữ liệu gồm 1,7 triệu bài báo học thuật từ arXiv, bao gồm vật lý, khoa học máy tính, toán học, thống kê, kỹ thuật điện, sinh học định lượng và kinh tế.