
| | |  عرض المصدر على جيثب عرض المصدر على جيثب | |
يوضح هذا البرنامج التعليمي كيفية تصنيف البيانات المنظمة ، مثل البيانات المجدولة ، باستخدام نسخة مبسطة من مجموعة بيانات PetFinder من مسابقة Kaggle المخزنة في ملف CSV.
ستستخدم Keras لتعريف النموذج ، وستستخدم طبقات Keras المسبقة كجسر للتعيين من الأعمدة في ملف CSV إلى الميزات المستخدمة لتدريب النموذج. الهدف هو توقع ما إذا كان سيتم تبني حيوان أليف.
يحتوي هذا البرنامج التعليمي على تعليمات برمجية كاملة لـ:
- تحميل ملف CSV في DataFrame باستخدام الباندا .
- بناء خط أنابيب إدخال لدفعة وخلط الصفوف باستخدام
tf.data. (تفضل بزيارة tf.data: إنشاء خطوط أنابيب إدخال TensorFlow لمزيد من التفاصيل.) - التعيين من الأعمدة في ملف CSV إلى الميزات المستخدمة لتدريب النموذج باستخدام طبقات Keras المسبقة.
- بناء النموذج وتدريبه وتقييمه باستخدام أساليب Keras المدمجة.
مجموعة بيانات PetFinder.my المصغرة
هناك عدة آلاف من الصفوف في ملف مجموعة بيانات CSV الخاص بـ PetFinder.my mini ، حيث يصف كل صف حيوانًا أليفًا (كلب أو قطة) ويصف كل عمود سمة ، مثل العمر والسلالة واللون وما إلى ذلك.
في ملخص مجموعة البيانات أدناه ، لاحظ أن هناك في الغالب أعمدة عددية وفئوية. في هذا البرنامج التعليمي ، سوف تتعامل فقط مع هذين النوعين من الميزات ، وإسقاط Description (ميزة نص حر) و AdoptionSpeed (ميزة تصنيف) أثناء المعالجة المسبقة للبيانات.
| عمود | وصف الحيوانات الأليفة | نوع الميزة | نوع البيانات |
|---|---|---|---|
Type | نوع الحيوان ( Dog ، Cat ) | قاطع | سلسلة |
Age | عمر | عددي | عدد صحيح |
Breed1 | سلالة أولية | قاطع | سلسلة |
Color1 | اللون 1 | قاطع | سلسلة |
Color2 | اللون 2 | قاطع | سلسلة |
MaturitySize | الحجم عند الاستحقاق | قاطع | سلسلة |
FurLength | طول الفراء | قاطع | سلسلة |
Vaccinated | تم تطعيم حيوان أليف | قاطع | سلسلة |
Sterilized | تم تعقيم الحيوانات الأليفة | قاطع | سلسلة |
Health | الحالة الصحية | قاطع | سلسلة |
Fee | رسوم التبني | عددي | عدد صحيح |
Description | كتابة الملف الشخصي | نص | سلسلة |
PhotoAmt | إجمالي الصور التي تم تحميلها | عددي | عدد صحيح |
AdoptionSpeed | السرعة الفئوية للاعتماد | تصنيف | عدد صحيح |
استيراد TensorFlow ومكتبات أخرى
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow.keras import layers
tf.__version__
'2.8.0-rc1'
قم بتحميل مجموعة البيانات وقراءتها في DataFrame الباندا
pandas هي مكتبة Python بها العديد من الأدوات المساعدة لتحميل البيانات المهيكلة والعمل معها. استخدم tf.keras.utils.get_file لتنزيل ملف CSV واستخراجه باستخدام مجموعة البيانات المصغرة PetFinder.my ، وتحميله في DataFrame باستخدام pandas.read_csv :
dataset_url = 'http://storage.googleapis.com/download.tensorflow.org/data/petfinder-mini.zip'
csv_file = 'datasets/petfinder-mini/petfinder-mini.csv'
tf.keras.utils.get_file('petfinder_mini.zip', dataset_url,
extract=True, cache_dir='.')
dataframe = pd.read_csv(csv_file)
Downloading data from http://storage.googleapis.com/download.tensorflow.org/data/petfinder-mini.zip 1671168/1668792 [==============================] - 0s 0us/step 1679360/1668792 [==============================] - 0s 0us/step
افحص مجموعة البيانات عن طريق التحقق من الصفوف الخمسة الأولى من DataFrame:
dataframe.head()
أنشئ متغيرًا مستهدفًا
كانت المهمة الأصلية في مسابقة Kaggle's PetFinder.my للتنبؤ بالتبني هي توقع السرعة التي سيتم بها تبني حيوان أليف (على سبيل المثال في الأسبوع الأول والشهر الأول والأشهر الثلاثة الأولى وما إلى ذلك).
في هذا البرنامج التعليمي ، ستقوم بتبسيط المهمة عن طريق تحويلها إلى مشكلة تصنيف ثنائية ، حيث عليك ببساطة توقع ما إذا كان قد تم تبني حيوان أليف أم لا.
بعد تعديل عمود AdoptionSpeed ، تشير القيمة 0 إلى أنه لم يتم تبني الحيوان الأليف ، بينما يشير الرقم 1 إلى أنه تم تبنيها.
# In the original dataset, `'AdoptionSpeed'` of `4` indicates
# a pet was not adopted.
dataframe['target'] = np.where(dataframe['AdoptionSpeed']==4, 0, 1)
# Drop unused features.
dataframe = dataframe.drop(columns=['AdoptionSpeed', 'Description'])
قم بتقسيم DataFrame إلى مجموعات تدريب وتحقق واختبار
مجموعة البيانات موجودة في إطار بيانات الباندا واحد. قسّمها إلى مجموعات تدريب وتحقق من الصحة واختبار باستخدام ، على سبيل المثال ، نسبة 80:10:10 ، على التوالي:
train, val, test = np.split(dataframe.sample(frac=1), [int(0.8*len(dataframe)), int(0.9*len(dataframe))])
print(len(train), 'training examples')
print(len(val), 'validation examples')
print(len(test), 'test examples')
9229 training examples 1154 validation examples 1154 test examples
قم بإنشاء مسار إدخال باستخدام tf.data
بعد ذلك ، قم بإنشاء وظيفة الأداة المساعدة التي تحول كل تدريب ، والتحقق من الصحة ، واختبار مجموعة DataFrame إلى tf.data.Dataset ، ثم خلط البيانات وتجميعها.
def df_to_dataset(dataframe, shuffle=True, batch_size=32):
df = dataframe.copy()
labels = df.pop('target')
df = {key: value[:,tf.newaxis] for key, value in dataframe.items()}
ds = tf.data.Dataset.from_tensor_slices((dict(df), labels))
if shuffle:
ds = ds.shuffle(buffer_size=len(dataframe))
ds = ds.batch(batch_size)
ds = ds.prefetch(batch_size)
return ds
الآن ، استخدم الوظيفة التي تم إنشاؤها حديثًا ( df_to_dataset ) للتحقق من تنسيق البيانات التي ترجعها وظيفة مساعد خط أنابيب الإدخال من خلال استدعائها في بيانات التدريب ، واستخدام حجم دفعة صغير للحفاظ على الإخراج قابلاً للقراءة:
batch_size = 5
train_ds = df_to_dataset(train, batch_size=batch_size)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:4: FutureWarning: Support for multi-dimensional indexing (e.g. `obj[:, None]`) is deprecated and will be removed in a future version. Convert to a numpy array before indexing instead. after removing the cwd from sys.path.
[(train_features, label_batch)] = train_ds.take(1)
print('Every feature:', list(train_features.keys()))
print('A batch of ages:', train_features['Age'])
print('A batch of targets:', label_batch )
Every feature: ['Type', 'Age', 'Breed1', 'Gender', 'Color1', 'Color2', 'MaturitySize', 'FurLength', 'Vaccinated', 'Sterilized', 'Health', 'Fee', 'PhotoAmt', 'target'] A batch of ages: tf.Tensor( [[84] [ 1] [ 5] [ 1] [12]], shape=(5, 1), dtype=int64) A batch of targets: tf.Tensor([1 1 0 1 0], shape=(5,), dtype=int64)
كما يوضح الإخراج ، تقوم مجموعة التدريب بإرجاع قاموس لأسماء الأعمدة (من DataFrame) يتم تعيينها لقيم العمود من الصفوف.
تطبيق طبقات Keras للمعالجة المسبقة
تسمح لك طبقات المعالجة المسبقة لـ Keras ببناء خطوط أنابيب معالجة المدخلات الأصلية لـ Keras ، والتي يمكن استخدامها كرمز معالجة مسبق مستقل في تدفقات عمل بخلاف Keras ، مدمجة مباشرةً مع نماذج Keras ، وتصديرها كجزء من Keras SavedModel.
في هذا البرنامج التعليمي ، ستستخدم طبقات المعالجة المسبقة الأربع التالية لتوضيح كيفية إجراء المعالجة المسبقة ، وتشفير البيانات المنظمة ، وهندسة الميزات:
-
tf.keras.layers.Normalization: يقوم بالتطبيع الحكيم لميزات الإدخال. -
tf.keras.layers.CategoryEncoding. -
tf.keras.layers.StringLookup: يحول القيم الفئوية للسلسلة إلى فهارس أعداد صحيحة. -
tf.keras.layers.IntegerLookup: يحول القيم الفئوية الصحيحة إلى فهارس أعداد صحيحة.
يمكنك معرفة المزيد حول الطبقات المتوفرة في دليل العمل مع طبقات المعالجة المسبقة .
- بالنسبة إلى الميزات العددية لمجموعة البيانات المصغرة PetFinder.my ، سوف تستخدم
tf.keras.layers.Normalizationlayer لتوحيد توزيع البيانات. - بالنسبة إلى الميزات الفئوية ، مثل
Typeالحيوانات الأليفة (سلاسلDogCat) ، ستقوم بتحويلها إلى موترات متعددة التشفير باستخدامtf.keras.layers.CategoryEncoding.
أعمدة عددية
لكل معلم رقمي في PetFinder.my mini dataet ، سوف تستخدم tf.keras.layers.Normalization layer لتوحيد توزيع البيانات.
حدد وظيفة أداة مساعدة جديدة تقوم بإرجاع طبقة تطبق التسوية الحكيمة للميزات على الميزات العددية باستخدام طبقة المعالجة المسبقة لـ Keras:
def get_normalization_layer(name, dataset):
# Create a Normalization layer for the feature.
normalizer = layers.Normalization(axis=None)
# Prepare a Dataset that only yields the feature.
feature_ds = dataset.map(lambda x, y: x[name])
# Learn the statistics of the data.
normalizer.adapt(feature_ds)
return normalizer
بعد ذلك ، اختبر الوظيفة الجديدة عن طريق تسميتها بإجمالي ميزات صور الحيوانات الأليفة التي تم تحميلها لتطبيع 'PhotoAmt' :
photo_count_col = train_features['PhotoAmt']
layer = get_normalization_layer('PhotoAmt', train_ds)
layer(photo_count_col)
<tf.Tensor: shape=(5, 1), dtype=float32, numpy=
array([[-0.8272058 ],
[-0.19125296],
[ 1.3986291 ],
[-0.19125296],
[-0.50922936]], dtype=float32)>
أعمدة فئوية
يتم تمثيل الحيوانات الأليفة من Type s في مجموعة البيانات كسلاسل - Dog Cat - والتي تحتاج إلى تشفير متعدد السخونة قبل إدخالها في النموذج. ميزة Age
حدد وظيفة أداة مساعدة جديدة أخرى تقوم بإرجاع طبقة تقوم بتعيين القيم من المفردات إلى فهارس الأعداد الصحيحة وتشفير الخصائص المتعددة باستخدام tf.keras.layers.StringLookup و tf.keras.layers.IntegerLookup و tf.keras.CategoryEncoding preprocessing الطبقات:
def get_category_encoding_layer(name, dataset, dtype, max_tokens=None):
# Create a layer that turns strings into integer indices.
if dtype == 'string':
index = layers.StringLookup(max_tokens=max_tokens)
# Otherwise, create a layer that turns integer values into integer indices.
else:
index = layers.IntegerLookup(max_tokens=max_tokens)
# Prepare a `tf.data.Dataset` that only yields the feature.
feature_ds = dataset.map(lambda x, y: x[name])
# Learn the set of possible values and assign them a fixed integer index.
index.adapt(feature_ds)
# Encode the integer indices.
encoder = layers.CategoryEncoding(num_tokens=index.vocabulary_size())
# Apply multi-hot encoding to the indices. The lambda function captures the
# layer, so you can use them, or include them in the Keras Functional model later.
return lambda feature: encoder(index(feature))
اختبر وظيفة get_category_encoding_layer عن طريق تسميتها بميزات الحيوانات الأليفة 'Type' لتحويلها إلى موترات متعددة التشفير:
test_type_col = train_features['Type']
test_type_layer = get_category_encoding_layer(name='Type',
dataset=train_ds,
dtype='string')
test_type_layer(test_type_col)
<tf.Tensor: shape=(5, 3), dtype=float32, numpy=
array([[0., 1., 0.],
[0., 1., 0.],
[0., 1., 0.],
[0., 1., 0.],
[0., 1., 0.]], dtype=float32)>
كرر العملية على ميزات 'Age' للحيوان الأليف:
test_age_col = train_features['Age']
test_age_layer = get_category_encoding_layer(name='Age',
dataset=train_ds,
dtype='int64',
max_tokens=5)
test_age_layer(test_age_col)
<tf.Tensor: shape=(5, 5), dtype=float32, numpy=
array([[1., 0., 0., 0., 0.],
[0., 0., 0., 1., 0.],
[1., 0., 0., 0., 0.],
[0., 0., 0., 1., 0.],
[1., 0., 0., 0., 0.]], dtype=float32)>
معالجة الميزات المحددة مسبقًا لتدريب النموذج عليها
لقد تعلمت كيفية استخدام عدة أنواع من طبقات المعالجة المسبقة لـ Keras. بعد ذلك ، سوف:
- قم بتطبيق وظائف الأداة المساعدة للمعالجة المسبقة المحددة مسبقًا في 13 ميزة عددية وفئوية من مجموعة البيانات المصغرة PetFinder.my.
- أضف جميع مدخلات الميزة إلى القائمة.
كما هو مذكور في البداية ، لتدريب النموذج ، ستستخدم مجموعة البيانات المصغرة PetFinder.my الرقمية ( 'PhotoAmt' ، 'Fee' ) والفئوية ( 'Age' ، 'Type' ، 'Color1' ، 'Color2' ، 'Gender' ، 'MaturitySize' maturitySize" ، 'FurLength' ، "لقاح 'Vaccinated' ، 'Sterilized' ، 'Health' ، 'Breed1' ).
في وقت سابق ، استخدمت حجم دُفعة صغير لتوضيح خط أنابيب الإدخال. لنقم الآن بإنشاء خط أنابيب إدخال جديد بحجم دُفعة أكبر يبلغ 256:
batch_size = 256
train_ds = df_to_dataset(train, batch_size=batch_size)
val_ds = df_to_dataset(val, shuffle=False, batch_size=batch_size)
test_ds = df_to_dataset(test, shuffle=False, batch_size=batch_size)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:4: FutureWarning: Support for multi-dimensional indexing (e.g. `obj[:, None]`) is deprecated and will be removed in a future version. Convert to a numpy array before indexing instead. after removing the cwd from sys.path.
تطبيع الميزات العددية (عدد صور الحيوانات الأليفة ورسوم التبني) ، وإضافتها إلى قائمة واحدة من المدخلات تسمى encoded_features :
all_inputs = []
encoded_features = []
# Numerical features.
for header in ['PhotoAmt', 'Fee']:
numeric_col = tf.keras.Input(shape=(1,), name=header)
normalization_layer = get_normalization_layer(header, train_ds)
encoded_numeric_col = normalization_layer(numeric_col)
all_inputs.append(numeric_col)
encoded_features.append(encoded_numeric_col)
حوّل القيم الفئوية للأعداد الصحيحة من مجموعة البيانات (عمر الحيوانات الأليفة) إلى فهارس أعداد صحيحة ، وقم بإجراء تشفير متعدد النقاط الساخنة ، وأضف مدخلات الميزة الناتجة إلى ميزات encoded_features :
age_col = tf.keras.Input(shape=(1,), name='Age', dtype='int64')
encoding_layer = get_category_encoding_layer(name='Age',
dataset=train_ds,
dtype='int64',
max_tokens=5)
encoded_age_col = encoding_layer(age_col)
all_inputs.append(age_col)
encoded_features.append(encoded_age_col)
كرر نفس الخطوة للقيم الفئوية للسلسلة:
categorical_cols = ['Type', 'Color1', 'Color2', 'Gender', 'MaturitySize',
'FurLength', 'Vaccinated', 'Sterilized', 'Health', 'Breed1']
for header in categorical_cols:
categorical_col = tf.keras.Input(shape=(1,), name=header, dtype='string')
encoding_layer = get_category_encoding_layer(name=header,
dataset=train_ds,
dtype='string',
max_tokens=5)
encoded_categorical_col = encoding_layer(categorical_col)
all_inputs.append(categorical_col)
encoded_features.append(encoded_categorical_col)
إنشاء النموذج وتجميعه وتدريبه
الخطوة التالية هي إنشاء نموذج باستخدام Keras Functional API . بالنسبة للطبقة الأولى في النموذج الخاص بك ، قم بدمج قائمة مدخلات الميزات - المميزات المشفرة - في متجه واحد عبر tf.keras.layers.concatenate encoded_features
all_features = tf.keras.layers.concatenate(encoded_features)
x = tf.keras.layers.Dense(32, activation="relu")(all_features)
x = tf.keras.layers.Dropout(0.5)(x)
output = tf.keras.layers.Dense(1)(x)
model = tf.keras.Model(all_inputs, output)
تكوين النموذج باستخدام Keras Model.compile :
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=["accuracy"])
دعنا نتخيل الرسم البياني للاتصال:
# Use `rankdir='LR'` to make the graph horizontal.
tf.keras.utils.plot_model(model, show_shapes=True, rankdir="LR")
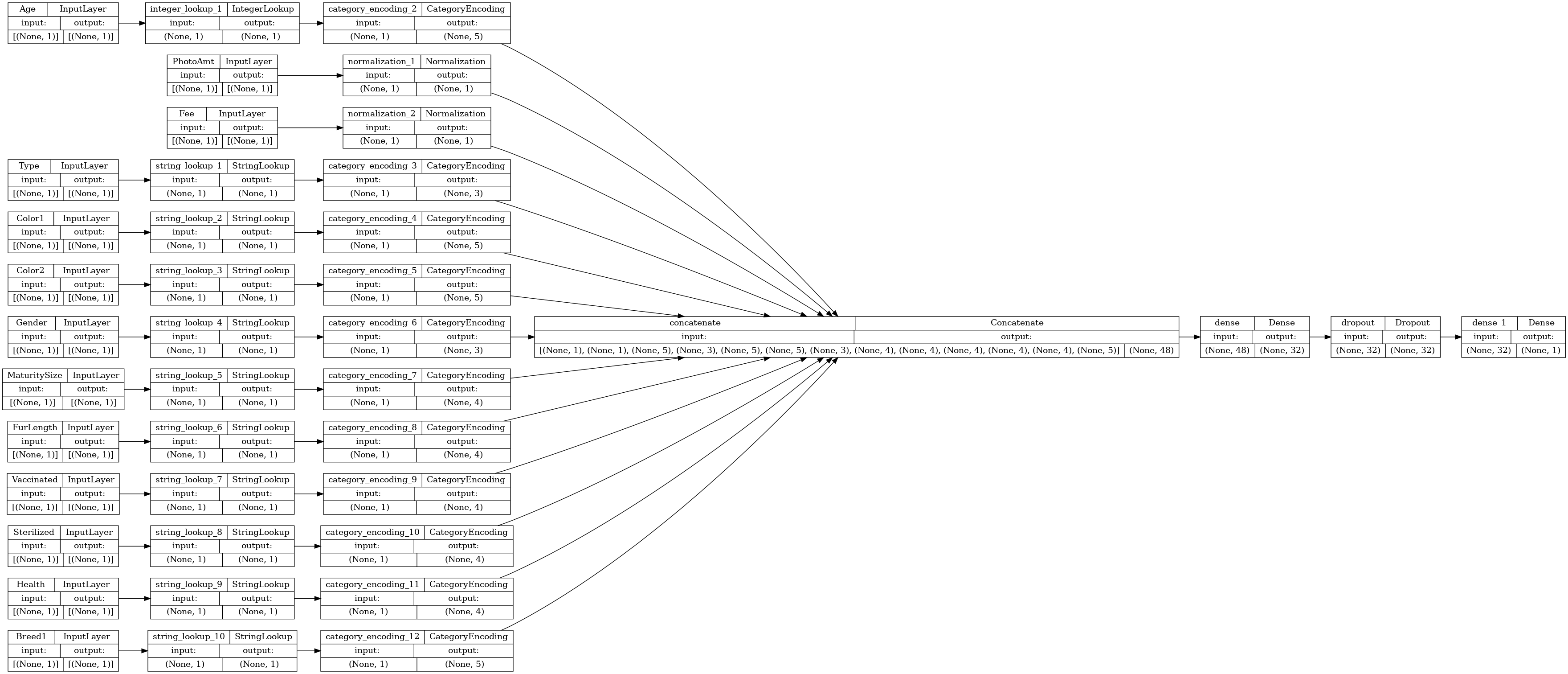
بعد ذلك ، قم بتدريب النموذج واختباره:
model.fit(train_ds, epochs=10, validation_data=val_ds)
Epoch 1/10 /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/keras/engine/functional.py:559: UserWarning: Input dict contained keys ['target'] which did not match any model input. They will be ignored by the model. inputs = self._flatten_to_reference_inputs(inputs) 37/37 [==============================] - 2s 19ms/step - loss: 0.6524 - accuracy: 0.5034 - val_loss: 0.5887 - val_accuracy: 0.6941 Epoch 2/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5906 - accuracy: 0.6648 - val_loss: 0.5627 - val_accuracy: 0.7218 Epoch 3/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5697 - accuracy: 0.6924 - val_loss: 0.5463 - val_accuracy: 0.7504 Epoch 4/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5558 - accuracy: 0.6978 - val_loss: 0.5346 - val_accuracy: 0.7504 Epoch 5/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5502 - accuracy: 0.7105 - val_loss: 0.5272 - val_accuracy: 0.7487 Epoch 6/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5415 - accuracy: 0.7123 - val_loss: 0.5210 - val_accuracy: 0.7608 Epoch 7/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5354 - accuracy: 0.7171 - val_loss: 0.5152 - val_accuracy: 0.7435 Epoch 8/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5301 - accuracy: 0.7214 - val_loss: 0.5113 - val_accuracy: 0.7513 Epoch 9/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5286 - accuracy: 0.7189 - val_loss: 0.5087 - val_accuracy: 0.7574 Epoch 10/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5252 - accuracy: 0.7260 - val_loss: 0.5058 - val_accuracy: 0.7539 <keras.callbacks.History at 0x7f5f9fa91c50>
loss, accuracy = model.evaluate(test_ds)
print("Accuracy", accuracy)
5/5 [==============================] - 0s 6ms/step - loss: 0.5012 - accuracy: 0.7626 Accuracy 0.762565016746521
نفذ الاستدلال
يمكن للنموذج الذي طورته الآن تصنيف صف من ملف CSV مباشرة بعد قيامك بتضمين طبقات المعالجة المسبقة داخل النموذج نفسه.
يمكنك الآن حفظ وإعادة تحميل نموذج Keras باستخدام Model.save و Model.load_model قبل إجراء الاستدلال على البيانات الجديدة:
model.save('my_pet_classifier')
reloaded_model = tf.keras.models.load_model('my_pet_classifier')
2022-01-26 06:20:08.013613: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. WARNING:absl:Function `_wrapped_model` contains input name(s) PhotoAmt, Fee, Age, Type, Color1, Color2, Gender, MaturitySize, FurLength, Vaccinated, Sterilized, Health, Breed1 with unsupported characters which will be renamed to photoamt, fee, age, type, color1, color2, gender, maturitysize, furlength, vaccinated, sterilized, health, breed1 in the SavedModel. INFO:tensorflow:Assets written to: my_pet_classifier/assets INFO:tensorflow:Assets written to: my_pet_classifier/assets
للحصول على تنبؤ لعينة جديدة ، يمكنك ببساطة استدعاء طريقة Model.predict . هناك شيئان فقط عليك القيام بهما:
- قم بلف المقاييس في قائمة بحيث يكون لها بُعد دفعة (تعالج
Modelمجموعات البيانات فقط ، وليس العينات الفردية). - اتصل
tf.convert_to_tensorبشأن كل ميزة.
sample = {
'Type': 'Cat',
'Age': 3,
'Breed1': 'Tabby',
'Gender': 'Male',
'Color1': 'Black',
'Color2': 'White',
'MaturitySize': 'Small',
'FurLength': 'Short',
'Vaccinated': 'No',
'Sterilized': 'No',
'Health': 'Healthy',
'Fee': 100,
'PhotoAmt': 2,
}
input_dict = {name: tf.convert_to_tensor([value]) for name, value in sample.items()}
predictions = reloaded_model.predict(input_dict)
prob = tf.nn.sigmoid(predictions[0])
print(
"This particular pet had a %.1f percent probability "
"of getting adopted." % (100 * prob)
)
This particular pet had a 77.7 percent probability of getting adopted.
الخطوات التالية
لمعرفة المزيد حول تصنيف البيانات المنظمة ، حاول العمل مع مجموعات البيانات الأخرى. لتحسين الدقة أثناء التدريب واختبار النماذج الخاصة بك ، فكر جيدًا في الميزات التي يجب تضمينها في نموذجك وكيف ينبغي تمثيلها.
فيما يلي بعض الاقتراحات لمجموعات البيانات:
- مجموعات بيانات TensorFlow: MovieLens : مجموعة من تصنيفات الأفلام من خدمة التوصية بالأفلام.
- مجموعات بيانات TensorFlow: جودة النبيذ : مجموعتا بيانات تتعلقان بالمتغيرات الحمراء والبيضاء لنبيذ "Vinho Verde" البرتغالي. يمكنك أيضًا العثور على مجموعة بيانات Red Wine Quality على Kaggle .
- Kaggle: مجموعة بيانات arXiv : مجموعة من 1.7 مليون مقال علمي من arXiv ، تغطي الفيزياء وعلوم الكمبيوتر والرياضيات والإحصاء والهندسة الكهربائية وعلم الأحياء الكمي والاقتصاد.