
حق چاپ 2021 نویسندگان TF-Agents.
| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub | |
معرفی
این مثال نشان می دهد که چگونه برای آموزش تقویت عامل بر روی محیط زیست Cartpole با استفاده از کتابخانه TF-نمایندگی، شبیه به آموزش DQN .
ما شما را از طریق تمام اجزای یک خط لوله یادگیری تقویتی (RL) برای آموزش، ارزیابی و جمع آوری داده ها راهنمایی می کنیم.
برپایی
اگر وابستگی های زیر را نصب نکرده اید، اجرا کنید:
sudo apt-get updatesudo apt-get install -y xvfb ffmpeg freeglut3-devpip install 'imageio==2.4.0'pip install pyvirtualdisplaypip install tf-agents[reverb]pip install pyglet xvfbwrapper
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import base64
import imageio
import IPython
import matplotlib.pyplot as plt
import numpy as np
import PIL.Image
import pyvirtualdisplay
import reverb
import tensorflow as tf
from tf_agents.agents.reinforce import reinforce_agent
from tf_agents.drivers import py_driver
from tf_agents.environments import suite_gym
from tf_agents.environments import tf_py_environment
from tf_agents.networks import actor_distribution_network
from tf_agents.policies import py_tf_eager_policy
from tf_agents.replay_buffers import reverb_replay_buffer
from tf_agents.replay_buffers import reverb_utils
from tf_agents.specs import tensor_spec
from tf_agents.trajectories import trajectory
from tf_agents.utils import common
# Set up a virtual display for rendering OpenAI gym environments.
display = pyvirtualdisplay.Display(visible=0, size=(1400, 900)).start()
فراپارامترها
env_name = "CartPole-v0" # @param {type:"string"}
num_iterations = 250 # @param {type:"integer"}
collect_episodes_per_iteration = 2 # @param {type:"integer"}
replay_buffer_capacity = 2000 # @param {type:"integer"}
fc_layer_params = (100,)
learning_rate = 1e-3 # @param {type:"number"}
log_interval = 25 # @param {type:"integer"}
num_eval_episodes = 10 # @param {type:"integer"}
eval_interval = 50 # @param {type:"integer"}
محیط
محیطها در RL نشاندهنده وظیفه یا مشکلی است که ما سعی در حل آن داریم. محیط های استاندارد را می توان به راحتی در TF-نمایندگی با استفاده از ایجاد suites . ما مختلف suites برای بارگذاری محیط از منابع مانند OpenAI بدنسازی، آتاری، DM کنترل، و غیره، با توجه به نام محیط زیست رشته.
حال اجازه دهید محیط CartPole را از مجموعه OpenAI Gym بارگیری کنیم.
env = suite_gym.load(env_name)
ما می توانیم این محیط را رندر کنیم تا ببینیم چگونه به نظر می رسد. یک میله چرخان آزاد به یک گاری وصل شده است. هدف این است که چرخ دستی را به سمت راست یا چپ حرکت دهید تا قطب را به سمت بالا نگه دارید.
env.reset()
PIL.Image.fromarray(env.render())
time_step = environment.step(action) بیانیه طول می کشد action در محیط زیست است. TimeStep تاپل بازگشت شامل مشاهدات بعدی محیط زیست و پاداش که برای عمل. time_step_spec() و action_spec() روش در محیط بازگشت مشخصات (انواع، اشکال، محدوده) از time_step و action است.
print('Observation Spec:')
print(env.time_step_spec().observation)
print('Action Spec:')
print(env.action_spec())
Observation Spec:
BoundedArraySpec(shape=(4,), dtype=dtype('float32'), name='observation', minimum=[-4.8000002e+00 -3.4028235e+38 -4.1887903e-01 -3.4028235e+38], maximum=[4.8000002e+00 3.4028235e+38 4.1887903e-01 3.4028235e+38])
Action Spec:
BoundedArraySpec(shape=(), dtype=dtype('int64'), name='action', minimum=0, maximum=1)
بنابراین، می بینیم که مشاهده آرایه ای از 4 شناور است: موقعیت و سرعت گاری، و موقعیت زاویه ای و سرعت قطب. از آنجا که تنها دو عمل امکان پذیر است (حرکت به سمت چپ یا راست حرکت می کند)، به action_spec یک اسکالر که در آن 0 به معنی "حرکت به سمت چپ" و 1 معنی "حق حرکت کند."
time_step = env.reset()
print('Time step:')
print(time_step)
action = np.array(1, dtype=np.int32)
next_time_step = env.step(action)
print('Next time step:')
print(next_time_step)
Time step:
TimeStep(
{'discount': array(1., dtype=float32),
'observation': array([ 0.02284177, -0.04785635, 0.04171623, 0.04942273], dtype=float32),
'reward': array(0., dtype=float32),
'step_type': array(0, dtype=int32)})
Next time step:
TimeStep(
{'discount': array(1., dtype=float32),
'observation': array([ 0.02188464, 0.14664337, 0.04270469, -0.22981201], dtype=float32),
'reward': array(1., dtype=float32),
'step_type': array(1, dtype=int32)})
معمولا ما دو محیط ایجاد می کنیم: یکی برای آموزش و دیگری برای ارزیابی. اکثر محیط در پایتون خالص نوشته شده است، اما می توان آنها را به راحتی به TensorFlow با استفاده از تبدیل TFPyEnvironment لفاف بسته بندی. API محیط اصلی را با استفاده از آرایه های نامپای از TFPyEnvironment این تبدیل به / از Tensors برای شما به راحتی بیشتر تعامل با سیاست های TensorFlow و عوامل.
train_py_env = suite_gym.load(env_name)
eval_py_env = suite_gym.load(env_name)
train_env = tf_py_environment.TFPyEnvironment(train_py_env)
eval_env = tf_py_environment.TFPyEnvironment(eval_py_env)
عامل
الگوریتمی که استفاده می کنیم برای حل یک مشکل RL به عنوان یک نشان Agent . علاوه بر عامل تقویت، TF-نمایندگی فراهم می کند پیاده سازی استاندارد از انواع Agents مانند DQN ، DDPG ، TD3 ، PPO و SAC .
برای ایجاد یک تقویت کننده، ما برای اولین بار نیاز به یک Actor Network که می توانند یاد بگیرند برای پیش بینی عمل با توجه به مشاهدات از محیط زیست است.
ما به راحتی می توانید ایجاد Actor Network با استفاده از مشخصات از مشاهدات و اقدامات. ما می توانیم لایه ها در شبکه که در این مثال، مشخص می fc_layer_params مجموعه آرگومان به یک تاپل از ints به نمایندگی از اندازه از هر یک از لایه های پنهان (بخش Hyperparameters بالا را ببینید).
actor_net = actor_distribution_network.ActorDistributionNetwork(
train_env.observation_spec(),
train_env.action_spec(),
fc_layer_params=fc_layer_params)
ما همچنین نیاز به یک optimizer برای آموزش شبکه ما فقط ایجاد و train_step_counter متغیر برای پیگیری چند بار شبکه به روز شد.
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
train_step_counter = tf.Variable(0)
tf_agent = reinforce_agent.ReinforceAgent(
train_env.time_step_spec(),
train_env.action_spec(),
actor_network=actor_net,
optimizer=optimizer,
normalize_returns=True,
train_step_counter=train_step_counter)
tf_agent.initialize()
سیاست های
در TF-عوامل، سیاست های نشان دهنده مفهوم استاندارد از سیاست در RL: با توجه به time_step تولید یک عمل یا یک توزیع بیش از اقدامات. روش اصلی است policy_step = policy.action(time_step) که در آن policy_step یک تاپل به نام PolicyStep(action, state, info) . policy_step.action است action به به محیط زیست استفاده شود، state نشان دهنده دولت برای stateful به (RNN) سیاست ها و info ممکن است مانند احتمال ورود به سیستم از اقدامات حاوی اطلاعات کمکی.
عامل ها شامل دو خط مشی هستند: خط مشی اصلی که برای ارزیابی/استقرار استفاده می شود (agent.policy) و خط مشی دیگری که برای جمع آوری داده ها استفاده می شود (agent.collect_policy).
eval_policy = tf_agent.policy
collect_policy = tf_agent.collect_policy
معیارها و ارزیابی
رایج ترین معیاری که برای ارزیابی یک سیاست استفاده می شود، میانگین بازده است. بازده مجموع پاداشهایی است که هنگام اجرای یک سیاست در یک محیط برای یک قسمت به دست میآید، و معمولاً این مقدار را در چند قسمت به طور میانگین میگیریم. میتوانیم میانگین بازدهی را به صورت زیر محاسبه کنیم.
def compute_avg_return(environment, policy, num_episodes=10):
total_return = 0.0
for _ in range(num_episodes):
time_step = environment.reset()
episode_return = 0.0
while not time_step.is_last():
action_step = policy.action(time_step)
time_step = environment.step(action_step.action)
episode_return += time_step.reward
total_return += episode_return
avg_return = total_return / num_episodes
return avg_return.numpy()[0]
# Please also see the metrics module for standard implementations of different
# metrics.
پخش مجدد بافر
به منظور پیگیری از داده های جمع آوری شده از محیط زیست، ما استفاده ی Reverb ، یک سیستم پخش کارآمد، توسعه، و آسان برای استفاده توسط Deepmind. هنگامی که ما مسیرها را جمع آوری می کنیم، داده های تجربه را ذخیره می کند و در طول آموزش مصرف می شود.
این بافر پخش با استفاده از مشخصات توصیف تانسورها که به ذخیره می شود، که می تواند از عامل با استفاده از به دست آمده ساخته شده است tf_agent.collect_data_spec .
table_name = 'uniform_table'
replay_buffer_signature = tensor_spec.from_spec(
tf_agent.collect_data_spec)
replay_buffer_signature = tensor_spec.add_outer_dim(
replay_buffer_signature)
table = reverb.Table(
table_name,
max_size=replay_buffer_capacity,
sampler=reverb.selectors.Uniform(),
remover=reverb.selectors.Fifo(),
rate_limiter=reverb.rate_limiters.MinSize(1),
signature=replay_buffer_signature)
reverb_server = reverb.Server([table])
replay_buffer = reverb_replay_buffer.ReverbReplayBuffer(
tf_agent.collect_data_spec,
table_name=table_name,
sequence_length=None,
local_server=reverb_server)
rb_observer = reverb_utils.ReverbAddEpisodeObserver(
replay_buffer.py_client,
table_name,
replay_buffer_capacity
)
[reverb/cc/platform/tfrecord_checkpointer.cc:150] Initializing TFRecordCheckpointer in /tmp/tmpem6la471. [reverb/cc/platform/tfrecord_checkpointer.cc:385] Loading latest checkpoint from /tmp/tmpem6la471 [reverb/cc/platform/default/server.cc:71] Started replay server on port 19822
برای بسیاری از عوامل، collect_data_spec است Trajectory به نام تاپل حاوی مشاهده، عمل، پاداش و غیره
جمع آوری داده ها
همانطور که REINFORCE از کل قسمت ها یاد می گیرد، ما تابعی را برای جمع آوری یک قسمت با استفاده از خط مشی جمع آوری داده های داده شده تعریف می کنیم و داده ها (مشاهدات، اقدامات، پاداش ها و غیره) را به عنوان مسیرها در بافر پخش مجدد ذخیره می کنیم. در اینجا ما از PyDriver برای اجرای حلقه جمع آوری تجربه استفاده می کنیم. شما می توانید اطلاعات بیشتر در مورد راننده TF نمایندگی ها در ما یاد بگیرند آموزش رانندگان .
def collect_episode(environment, policy, num_episodes):
driver = py_driver.PyDriver(
environment,
py_tf_eager_policy.PyTFEagerPolicy(
policy, use_tf_function=True),
[rb_observer],
max_episodes=num_episodes)
initial_time_step = environment.reset()
driver.run(initial_time_step)
آموزش عامل
حلقه آموزشی هم شامل جمع آوری داده ها از محیط و هم بهینه سازی شبکه های عامل است. در طول مسیر، ما گاهی اوقات خط مشی نماینده را ارزیابی می کنیم تا ببینیم که چگونه کار می کنیم.
اجرای موارد زیر 3 دقیقه طول می کشد.
try:
%%time
except:
pass
# (Optional) Optimize by wrapping some of the code in a graph using TF function.
tf_agent.train = common.function(tf_agent.train)
# Reset the train step
tf_agent.train_step_counter.assign(0)
# Evaluate the agent's policy once before training.
avg_return = compute_avg_return(eval_env, tf_agent.policy, num_eval_episodes)
returns = [avg_return]
for _ in range(num_iterations):
# Collect a few episodes using collect_policy and save to the replay buffer.
collect_episode(
train_py_env, tf_agent.collect_policy, collect_episodes_per_iteration)
# Use data from the buffer and update the agent's network.
iterator = iter(replay_buffer.as_dataset(sample_batch_size=1))
trajectories, _ = next(iterator)
train_loss = tf_agent.train(experience=trajectories)
replay_buffer.clear()
step = tf_agent.train_step_counter.numpy()
if step % log_interval == 0:
print('step = {0}: loss = {1}'.format(step, train_loss.loss))
if step % eval_interval == 0:
avg_return = compute_avg_return(eval_env, tf_agent.policy, num_eval_episodes)
print('step = {0}: Average Return = {1}'.format(step, avg_return))
returns.append(avg_return)
[reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 25: loss = 0.8549901247024536 [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 50: loss = 1.0025296211242676 step = 50: Average Return = 23.200000762939453 [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 75: loss = 1.1377763748168945 step = 100: loss = 1.318871021270752 step = 100: Average Return = 159.89999389648438 step = 125: loss = 1.5053682327270508 [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 150: loss = 0.8051948547363281 step = 150: Average Return = 184.89999389648438 step = 175: loss = 0.6872963905334473 step = 200: loss = 2.7238712310791016 step = 200: Average Return = 186.8000030517578 step = 225: loss = 0.7495002746582031 step = 250: loss = -0.3333401679992676 step = 250: Average Return = 200.0
تجسم
توطئه ها
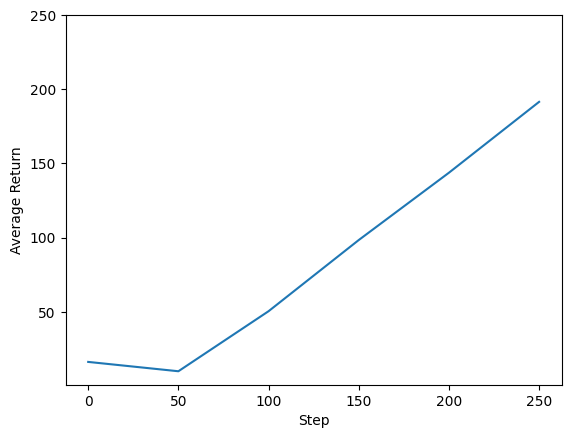
ما میتوانیم مراحل بازگشت را در مقابل مراحل جهانی ترسیم کنیم تا عملکرد نماینده خود را ببینیم. در Cartpole-v0 ، محیط زیست می دهد جایزه از 1 برای هر مرحله زمان باقی می ماند قطب، و از حداکثر تعداد مراحل 200، حداکثر بازگشت نیز امکان پذیر است 200.
steps = range(0, num_iterations + 1, eval_interval)
plt.plot(steps, returns)
plt.ylabel('Average Return')
plt.xlabel('Step')
plt.ylim(top=250)
(-0.2349997997283939, 250.0)
فیلم های
تجسم عملکرد یک عامل با رندر کردن محیط در هر مرحله مفید است. قبل از انجام این کار، اجازه دهید ابتدا یک تابع برای جاسازی ویدیوها در این colab ایجاد کنیم.
def embed_mp4(filename):
"""Embeds an mp4 file in the notebook."""
video = open(filename,'rb').read()
b64 = base64.b64encode(video)
tag = '''
<video width="640" height="480" controls>
<source src="data:video/mp4;base64,{0}" type="video/mp4">
Your browser does not support the video tag.
</video>'''.format(b64.decode())
return IPython.display.HTML(tag)
کد زیر خط مشی عامل را برای چند قسمت به تصویر می کشد:
num_episodes = 3
video_filename = 'imageio.mp4'
with imageio.get_writer(video_filename, fps=60) as video:
for _ in range(num_episodes):
time_step = eval_env.reset()
video.append_data(eval_py_env.render())
while not time_step.is_last():
action_step = tf_agent.policy.action(time_step)
time_step = eval_env.step(action_step.action)
video.append_data(eval_py_env.render())
embed_mp4(video_filename)
WARNING:root:IMAGEIO FFMPEG_WRITER WARNING: input image is not divisible by macro_block_size=16, resizing from (400, 600) to (400, 608) to ensure video compatibility with most codecs and players. To prevent resizing, make your input image divisible by the macro_block_size or set the macro_block_size to None (risking incompatibility). You may also see a FFMPEG warning concerning speedloss due to data not being aligned. [swscaler @ 0x5604d224f3c0] Warning: data is not aligned! This can lead to a speed loss