
ลิขสิทธิ์ 2021 The TF-Agents Authors.
เริ่ม
| | |  ดูแหล่งที่มาบน GitHub ดูแหล่งที่มาบน GitHub | |
บทช่วยสอนนี้เป็นคำแนะนำทีละขั้นตอนเกี่ยวกับวิธีใช้ไลบรารี TF-Agents สำหรับปัญหาโจรกรรมตามบริบทที่การกระทำ (อาวุธ) มีคุณสมบัติของตัวเอง เช่น รายชื่อภาพยนตร์ที่แสดงโดยคุณสมบัติ (ประเภท ปีที่เผยแพร่ ...)
วิชาบังคับก่อน
มันจะสันนิษฐานว่าผู้อ่านจะค่อนข้างคุ้นเคยกับห้องสมุดโจรของตัวแทน TF, โดยเฉพาะอย่างยิ่งที่ได้ทำงานผ่าน การสอนสำหรับโจรตัวแทน TF ก่อนที่จะอ่านการกวดวิชานี้
โจรหลายแขนที่มีคุณสมบัติแขน
ในการตั้งค่ากลุ่มโจรติดอาวุธตามบริบท "คลาสสิก" ตัวแทนจะได้รับเวกเตอร์บริบท (หรือที่เรียกว่าการสังเกต) ในทุกขั้นตอนของเวลา และต้องเลือกจากชุดการกระทำที่มีหมายเลขจำกัด (อาวุธ) เพื่อเพิ่มรางวัลสะสมสูงสุด
ตอนนี้ให้พิจารณาสถานการณ์สมมติที่ตัวแทนแนะนำให้ผู้ใช้ดูหนังเรื่องต่อไป ทุกครั้งที่ต้องทำการตัดสินใจ เจ้าหน้าที่จะได้รับข้อมูลบางอย่างเกี่ยวกับผู้ใช้เป็นบริบท (ประวัติการดู การตั้งค่าประเภท ฯลฯ...) รวมถึงรายชื่อภาพยนตร์ให้เลือก
เราได้พยายามที่จะกำหนดปัญหานี้โดยการมีข้อมูลที่ผู้ใช้เป็นบริบทและแขนจะ movie_1, movie_2, ..., movie_K แต่วิธีนี้มีข้อบกพร่องหลาย
- จำนวนการกระทำจะต้องเป็นภาพยนตร์ทั้งหมดในระบบและเป็นการยากที่จะเพิ่มภาพยนตร์ใหม่
- ตัวแทนต้องเรียนรู้รูปแบบสำหรับภาพยนตร์ทุกเรื่อง
- ไม่คำนึงถึงความคล้ายคลึงกันระหว่างภาพยนตร์
แทนที่จะนับจำนวนภาพยนตร์ เราสามารถทำบางสิ่งที่เข้าใจง่ายขึ้น: เราสามารถแสดงภาพยนตร์ด้วยชุดคุณสมบัติต่างๆ เช่น ประเภท ความยาว นักแสดง เรตติ้ง ปี ฯลฯ ข้อดีของวิธีนี้มีมากมาย:
- ลักษณะทั่วไปในภาพยนตร์
- ตัวแทนเรียนรู้ฟังก์ชันการให้รางวัลเพียงฟังก์ชันเดียวที่แบบจำลองให้รางวัลด้วยคุณลักษณะผู้ใช้และภาพยนตร์
- ง่ายต่อการลบหรือแนะนำภาพยนตร์ใหม่เข้าสู่ระบบ
ในการตั้งค่าใหม่นี้ จำนวนการดำเนินการไม่จำเป็นต้องเท่ากันในทุกขั้นตอน
Per-Arm Bandits ใน TF-Agents
ชุด TF-Agents Bandit ได้รับการพัฒนาเพื่อให้สามารถใช้กับเคสแบบต่อแขนได้เช่นกัน มีสภาพแวดล้อมแบบต่อแขน และนโยบายและตัวแทนส่วนใหญ่สามารถทำงานในโหมดต่อแขนได้
ก่อนที่เราจะลงลึกในตัวอย่างโค้ด เราจำเป็นต้องมีการนำเข้าที่จำเป็น
การติดตั้ง
pip install tf-agents
นำเข้า
import functools
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tf_agents.bandits.agents import lin_ucb_agent
from tf_agents.bandits.environments import stationary_stochastic_per_arm_py_environment as p_a_env
from tf_agents.bandits.metrics import tf_metrics as tf_bandit_metrics
from tf_agents.drivers import dynamic_step_driver
from tf_agents.environments import tf_py_environment
from tf_agents.replay_buffers import tf_uniform_replay_buffer
from tf_agents.specs import tensor_spec
from tf_agents.trajectories import time_step as ts
nest = tf.nest
พารามิเตอร์ -- รู้สึกอิสระที่จะเล่นรอบๆ
# The dimension of the global features.
GLOBAL_DIM = 40
# The elements of the global feature will be integers in [-GLOBAL_BOUND, GLOBAL_BOUND).
GLOBAL_BOUND = 10
# The dimension of the per-arm features.
PER_ARM_DIM = 50
# The elements of the PER-ARM feature will be integers in [-PER_ARM_BOUND, PER_ARM_BOUND).
PER_ARM_BOUND = 6
# The variance of the Gaussian distribution that generates the rewards.
VARIANCE = 100.0
# The elements of the linear reward parameter will be integers in [-PARAM_BOUND, PARAM_BOUND).
PARAM_BOUND = 10
NUM_ACTIONS = 70
BATCH_SIZE = 20
# Parameter for linear reward function acting on the
# concatenation of global and per-arm features.
reward_param = list(np.random.randint(
-PARAM_BOUND, PARAM_BOUND, [GLOBAL_DIM + PER_ARM_DIM]))
สภาพแวดล้อมที่เรียบง่ายต่อแขน
สภาพแวดล้อม stochastic คงอธิบายในอื่น ๆ กวดวิชา มีคู่ต่อแขน
ในการเริ่มต้นสภาพแวดล้อมต่อแขน เราต้องกำหนดฟังก์ชันที่สร้าง
- ทั่วโลกและคุณลักษณะต่อแขน: ฟังก์ชั่นเหล่านี้มีป้อนพารามิเตอร์และไม่สร้างความเป็นหนึ่งเดียว (ทั่วโลกหรือต่อแขน) เวกเตอร์คุณลักษณะเมื่อเรียก
- รางวัล: ฟังก์ชั่นนี้จะใช้เวลาเป็นพารามิเตอร์เรียงต่อกันของทั่วโลกและคุณลักษณะเวกเตอร์ต่อแขนและสร้างรางวัล โดยทั่วไปนี่คือฟังก์ชันที่เอเจนต์จะต้อง "เดา" เป็นที่น่าสังเกตว่าในกรณีต่อแขน ฟังก์ชันการให้รางวัลจะเหมือนกันทุกแขน นี่เป็นข้อแตกต่างพื้นฐานจากกรณีโจรแบบคลาสสิก ซึ่งตัวแทนต้องประเมินฟังก์ชันการให้รางวัลสำหรับแต่ละแขนอย่างอิสระ
def global_context_sampling_fn():
"""This function generates a single global observation vector."""
return np.random.randint(
-GLOBAL_BOUND, GLOBAL_BOUND, [GLOBAL_DIM]).astype(np.float32)
def per_arm_context_sampling_fn():
""""This function generates a single per-arm observation vector."""
return np.random.randint(
-PER_ARM_BOUND, PER_ARM_BOUND, [PER_ARM_DIM]).astype(np.float32)
def linear_normal_reward_fn(x):
"""This function generates a reward from the concatenated global and per-arm observations."""
mu = np.dot(x, reward_param)
return np.random.normal(mu, VARIANCE)
ตอนนี้เราพร้อมที่จะเริ่มต้นสภาพแวดล้อมของเราแล้ว
per_arm_py_env = p_a_env.StationaryStochasticPerArmPyEnvironment(
global_context_sampling_fn,
per_arm_context_sampling_fn,
NUM_ACTIONS,
linear_normal_reward_fn,
batch_size=BATCH_SIZE
)
per_arm_tf_env = tf_py_environment.TFPyEnvironment(per_arm_py_env)
ด้านล่างเราสามารถตรวจสอบว่าสภาพแวดล้อมนี้ก่อให้เกิดอะไร
print('observation spec: ', per_arm_tf_env.observation_spec())
print('\nAn observation: ', per_arm_tf_env.reset().observation)
action = tf.zeros(BATCH_SIZE, dtype=tf.int32)
time_step = per_arm_tf_env.step(action)
print('\nRewards after taking an action: ', time_step.reward)
observation spec: {'global': TensorSpec(shape=(40,), dtype=tf.float32, name=None), 'per_arm': TensorSpec(shape=(70, 50), dtype=tf.float32, name=None)}
An observation: {'global': <tf.Tensor: shape=(20, 40), dtype=float32, numpy=
array([[ -9., -4., -3., 3., 5., -9., 6., -5., 4., -8., -6.,
-1., -7., -5., 7., 8., 2., 5., -8., 0., -4., 4.,
-1., -1., -4., 6., 8., 6., 9., -5., -1., -1., 2.,
5., -1., -8., 1., 0., 0., 5.],
[ 5., 7., 0., 3., -8., -7., -5., -2., -8., -7., -7.,
-8., 5., -3., 5., 4., -5., 2., -6., -10., -4., -2.,
2., -1., -1., 8., -7., 7., 2., -3., -10., -1., -4.,
-7., 3., 4., 8., -2., 9., 5.],
[ -6., -2., -1., -1., 6., -3., 4., 9., 2., -2., 3.,
1., 0., -7., 5., 5., -8., -4., 5., 7., -10., -4.,
5., 6., 8., -10., 7., -1., -8., -8., -6., -6., 4.,
-10., -8., 3., 8., -9., -5., 8.],
[ -1., 8., -8., -7., 9., 2., -6., 8., 4., -2., 1.,
8., -4., 3., 1., -6., -9., 3., -5., 7., -9., 6.,
6., -3., 1., 2., -1., 3., 7., 4., -8., 1., 1.,
3., -4., 1., -4., -5., -9., 4.],
[ -9., 8., 9., -8., 2., 9., -1., -9., -1., 9., -8.,
-4., 1., 1., 9., 6., -6., -10., -6., 2., 6., -4.,
-7., -2., -7., -8., -4., 5., -6., -1., 8., -3., -7.,
4., -9., -9., 6., -9., 6., -2.],
[ 0., -6., -5., -8., -10., 2., -4., 9., 9., -1., 5.,
-7., -1., -3., -10., -10., 3., -2., -7., -9., -4., -8.,
-4., -1., 7., -2., -4., -4., 9., 2., -2., -8., 6.,
5., -4., 7., 0., 6., -3., 2.],
[ 8., 5., 3., 5., 9., 4., -10., -5., -4., -4., -5.,
3., 5., -4., 9., -2., -7., -6., -2., -8., -7., -10.,
0., -2., 3., 1., -10., -8., 3., 9., -5., -6., 1.,
-7., -1., 3., -7., -2., 1., -1.],
[ 3., 9., 8., 6., -2., 9., 9., 7., 0., 5., -5.,
6., 9., 3., 2., 9., 4., -1., -3., 3., -1., -4.,
-9., -1., -3., 8., 0., 4., -1., 4., -3., 4., -5.,
-3., -6., -4., 7., -9., -7., -1.],
[ 5., -1., 9., -5., 8., 7., -7., -5., 0., -4., -5.,
6., -3., -1., 7., 3., -7., -9., 6., 4., 9., 6.,
-3., 3., -2., -6., -4., -7., -5., -6., -2., -1., -9.,
-4., -9., -2., -7., -6., -3., 6.],
[ -7., 1., -8., 1., -8., -9., 5., 1., -4., -2., -5.,
3., -1., -4., -4., 5., 0., -10., -4., -1., -5., 3.,
8., -5., -4., -10., -8., -6., -10., -1., -6., 1., 7.,
8., 6., -2., -4., -9., 7., -1.],
[ -2., 3., 8., -5., 0., 5., 8., -5., 6., -8., 5.,
8., -5., -5., -5., -10., 4., 8., -4., -7., 4., -6.,
-9., -8., -5., 4., -1., -2., -7., -10., -6., -8., -6.,
3., 1., 6., 9., 6., -8., -3.],
[ 9., -6., -2., -10., 2., -8., 8., -7., -5., 8., -10.,
4., -5., 9., 7., 9., -2., -9., -5., -2., 9., 0.,
-6., 2., 4., 6., -7., -4., -5., -7., -8., -8., 8.,
-7., -1., -5., 0., -7., 7., -6.],
[ -1., -3., 1., 8., 4., 7., -1., -8., -4., 6., 9.,
5., -10., 4., -4., 5., -2., 0., 3., 4., 3., -5.,
-2., 7., 4., -4., -9., 9., -6., -5., -8., 4., -10.,
-6., 3., 0., 6., -10., 4., 3.],
[ 8., 8., -5., 0., -7., 5., -6., -8., 2., -3., -5.,
5., 0., 6., -10., 3., -4., 1., -8., -9., 6., -5.,
5., -10., 1., 0., 3., 5., 2., -9., -6., 9., 7.,
9., -10., 4., -4., -10., -5., 1.],
[ 8., 3., -5., -2., -8., -6., 6., -7., 8., 1., -8.,
0., -2., 3., -6., 0., -10., 6., -8., -2., -5., 4.,
-1., -9., -7., 3., -1., -4., -1., -10., -3., -7., -3.,
4., -7., -6., -1., 9., -3., 2.],
[ 8., 7., 6., -5., -3., 0., 1., -2., 0., -3., 9.,
-8., 5., 1., 1., 1., -5., 4., -4., 0., -4., -3.,
7., -10., 3., 6., 4., 5., 2., -7., 0., -3., -5.,
2., -6., 4., 5., 8., -1., -3.],
[ 8., -9., -4., 8., -2., 9., 5., 5., -3., -4., 0.,
-5., 5., -2., -10., -4., -3., 5., 8., 6., -2., -2.,
-1., -8., -5., -9., 1., -1., 5., 6., 4., 9., -5.,
6., -2., 7., -7., -9., 4., 2.],
[ 2., 4., 6., 2., 6., -6., -2., 5., 8., 1., 3.,
8., 6., 9., -3., -1., 4., 7., -5., 7., 0., -10.,
9., -6., -4., -7., 1., -2., -2., 3., -1., 2., 5.,
8., 4., -9., 1., -4., 9., 6.],
[ -8., -5., 9., 3., 9., -10., -8., 3., -8., 0., -4.,
-8., -3., -4., -3., 0., 8., 3., -10., 7., 7., -3.,
8., 4., -3., 9., 3., 7., 2., 7., -8., -3., -4.,
-7., 3., -9., -10., 2., 5., 7.],
[ 5., -7., -8., 6., -8., 1., -8., 4., 2., 6., -6.,
-5., 4., -1., 3., -8., -3., 6., 5., -5., 1., -7.,
8., -10., 8., 1., 3., 7., 2., 2., -1., 1., -3.,
7., 1., 6., -6., 0., -9., 6.]], dtype=float32)>, 'per_arm': <tf.Tensor: shape=(20, 70, 50), dtype=float32, numpy=
array([[[ 5., -6., 4., ..., -3., 3., 4.],
[-5., -6., -4., ..., 3., 4., -4.],
[ 1., -1., 5., ..., -1., -3., 1.],
...,
[ 3., 3., -5., ..., 4., 4., 0.],
[ 5., 1., -3., ..., -2., -2., -3.],
[-6., 4., 2., ..., 4., 5., -5.]],
[[-5., -3., 1., ..., -2., -1., 1.],
[ 1., 4., -1., ..., -1., -4., -4.],
[ 4., -6., 5., ..., 2., -2., 4.],
...,
[ 0., 4., -4., ..., -1., -3., 1.],
[ 3., 4., 5., ..., -5., -2., -2.],
[ 0., 4., -3., ..., 5., 1., 3.]],
[[-2., -6., -6., ..., -6., 1., -5.],
[ 4., 5., 5., ..., 1., 4., -4.],
[ 0., 0., -3., ..., -5., 0., -2.],
...,
[-3., -1., 4., ..., 5., -2., 5.],
[-3., -6., -2., ..., 3., 1., -5.],
[ 5., -3., -5., ..., -4., 4., -5.]],
...,
[[ 4., 3., 0., ..., 1., -6., 4.],
[-5., -3., 5., ..., 0., -1., -5.],
[ 0., 4., 3., ..., -2., 1., -3.],
...,
[-5., -2., -5., ..., -5., -5., -2.],
[-2., 5., 4., ..., -2., -2., 2.],
[-1., -4., 4., ..., -5., 2., -3.]],
[[-1., -4., 4., ..., -3., -5., 4.],
[-4., -6., -2., ..., -1., -6., 0.],
[ 0., 0., 5., ..., 4., -4., 0.],
...,
[ 2., 3., 5., ..., -6., -5., 5.],
[-5., -5., 2., ..., 0., 4., -2.],
[ 4., -5., -4., ..., -5., -5., -1.]],
[[ 3., 0., 2., ..., 2., 1., -3.],
[-5., -4., 3., ..., -6., 0., -2.],
[-4., -5., 3., ..., -6., -3., 0.],
...,
[-6., -6., 4., ..., -1., -5., -2.],
[-4., 3., -1., ..., 1., 4., 4.],
[ 5., 2., 2., ..., -3., 1., -4.]]], dtype=float32)>}
Rewards after taking an action: tf.Tensor(
[-130.17787 344.98013 371.39893 75.433975 396.35742
-176.46881 56.62174 -158.03278 491.3239 -156.10696
-1.0527252 -264.42285 22.356699 -395.89832 125.951546
142.99467 -322.3012 -24.547596 -159.47539 -44.123775 ], shape=(20,), dtype=float32)
เราเห็นว่าข้อกำหนดการสังเกตเป็นพจนานุกรมที่มีสององค์ประกอบ:
- หนึ่งที่มีคีย์
'global': นี่คือส่วนหนึ่งบริบทของโลกที่มีรูปร่างที่ตรงกับพารามิเตอร์GLOBAL_DIM - หนึ่งที่มีคีย์
'per_arm': นี่คือบริบทต่อแขนและรูปร่างของมันคือ[NUM_ACTIONS, PER_ARM_DIM]ส่วนนี้เป็นตัวยึดสำหรับคุณลักษณะแขนของแขนทุกข้างในขั้นตอนเวลา
ตัวแทน LinUCB
เอเจนต์ LinUCB ใช้อัลกอริธึม Bandit ที่มีชื่อเหมือนกัน ซึ่งประเมินพารามิเตอร์ของฟังก์ชันการให้รางวัลแบบเส้นตรงในขณะที่ยังรักษาความมั่นใจในวงรีรอบการประมาณการ ตัวแทนเลือกแขนที่มีรางวัลที่คาดไว้สูงสุด สมมติว่าพารามิเตอร์อยู่ภายในวงรีความเชื่อมั่น
การสร้างเอเจนต์ต้องใช้ความรู้เกี่ยวกับการสังเกตและข้อกำหนดการดำเนินการ เมื่อกำหนดตัวแทนที่เราตั้งค่าพารามิเตอร์บูล accepts_per_arm_features ตั้งค่าให้ True
observation_spec = per_arm_tf_env.observation_spec()
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
dtype=tf.int32, shape=(), minimum=0, maximum=NUM_ACTIONS - 1)
agent = lin_ucb_agent.LinearUCBAgent(time_step_spec=time_step_spec,
action_spec=action_spec,
accepts_per_arm_features=True)
การไหลของข้อมูลการฝึกอบรม
ส่วนนี้จะให้ข้อมูลคร่าวๆ เกี่ยวกับกลไกการทำงานของฟีเจอร์ต่อแขนตั้งแต่นโยบายไปจนถึงการฝึกอบรม ข้ามไปยังส่วนถัดไปได้ตามสบาย (การกำหนดตัววัดความเสียใจ) และกลับมาที่นี่ในภายหลังหากสนใจ
ขั้นแรก ให้เราดูที่ข้อมูลจำเพาะของข้อมูลในเอเจนต์ training_data_spec แอตทริบิวต์ระบุตัวแทนสิ่งองค์ประกอบและโครงสร้างข้อมูลการฝึกอบรมควรมี
print('training data spec: ', agent.training_data_spec)
training data spec: Trajectory(
{'action': BoundedTensorSpec(shape=(), dtype=tf.int32, name=None, minimum=array(0, dtype=int32), maximum=array(69, dtype=int32)),
'discount': BoundedTensorSpec(shape=(), dtype=tf.float32, name='discount', minimum=array(0., dtype=float32), maximum=array(1., dtype=float32)),
'next_step_type': TensorSpec(shape=(), dtype=tf.int32, name='step_type'),
'observation': {'global': TensorSpec(shape=(40,), dtype=tf.float32, name=None)},
'policy_info': PerArmPolicyInfo(log_probability=(), predicted_rewards_mean=(), multiobjective_scalarized_predicted_rewards_mean=(), predicted_rewards_optimistic=(), predicted_rewards_sampled=(), bandit_policy_type=(), chosen_arm_features=TensorSpec(shape=(50,), dtype=tf.float32, name=None)),
'reward': TensorSpec(shape=(), dtype=tf.float32, name='reward'),
'step_type': TensorSpec(shape=(), dtype=tf.int32, name='step_type')})
ถ้าเรามีลักษณะที่ใกล้ชิดกับ observation ส่วนหนึ่งของข้อมูลจำเพาะเราจะเห็นว่ามันไม่ได้มีคุณสมบัติต่อแขน!
print('observation spec in training: ', agent.training_data_spec.observation)
observation spec in training: {'global': TensorSpec(shape=(40,), dtype=tf.float32, name=None)}
เกิดอะไรขึ้นกับคุณสมบัติต่อแขน ที่จะตอบคำถามนี้เป็นครั้งแรกที่เราทราบว่าเมื่อรถไฟตัวแทน LinUCB ก็ไม่จำเป็นต้องมีคุณสมบัติต่อแขนแขนทั้งหมดก็เพียงความต้องการของผู้ที่แขนได้รับการแต่งตั้ง จึงทำให้ความรู้สึกที่จะลดลงเมตริกซ์ของรูปร่าง [BATCH_SIZE, NUM_ACTIONS, PER_ARM_DIM] มันเป็นสิ้นเปลืองมากโดยเฉพาะถ้าจำนวนของการกระทำที่มีขนาดใหญ่
แต่คุณสมบัติต่อแขนของแขนที่เลือกต้องอยู่ที่ไหนสักแห่ง! ด้วยเหตุนี้เราให้แน่ใจว่าร้านค้านโยบาย LinUCB คุณสมบัติของแขนได้รับการแต่งตั้งภายในที่ policy_info ฟิลด์ของข้อมูลการฝึกอบรม:
print('chosen arm features: ', agent.training_data_spec.policy_info.chosen_arm_features)
chosen arm features: TensorSpec(shape=(50,), dtype=tf.float32, name=None)
เรามาดูจากรูปร่างที่ chosen_arm_features ฟิลด์มีเพียงเวกเตอร์คุณสมบัติของแขนข้างหนึ่งและที่จะเป็นแขนที่เลือก หมายเหตุว่า policy_info และกับมัน chosen_arm_features เป็นส่วนหนึ่งของข้อมูลการฝึกอบรมอย่างที่เราเห็นจากการตรวจสอบการฝึกอบรมข้อมูลจำเพาะข้อมูลและทำให้มันสามารถใช้ได้ในเวลาการฝึกอบรม
การกำหนดตัวชี้วัดความเสียใจ
ก่อนเริ่มการวนรอบการฝึก เรากำหนดฟังก์ชันยูทิลิตี้บางอย่างที่ช่วยคำนวณความเสียใจของตัวแทนของเรา ฟังก์ชันเหล่านี้ช่วยกำหนดรางวัลที่คาดหวังอย่างเหมาะสมที่สุดโดยพิจารณาจากชุดของการกระทำ (กำหนดโดยคุณสมบัติของแขน) และพารามิเตอร์เชิงเส้นที่ซ่อนอยู่จากเอเจนต์
def _all_rewards(observation, hidden_param):
"""Outputs rewards for all actions, given an observation."""
hidden_param = tf.cast(hidden_param, dtype=tf.float32)
global_obs = observation['global']
per_arm_obs = observation['per_arm']
num_actions = tf.shape(per_arm_obs)[1]
tiled_global = tf.tile(
tf.expand_dims(global_obs, axis=1), [1, num_actions, 1])
concatenated = tf.concat([tiled_global, per_arm_obs], axis=-1)
rewards = tf.linalg.matvec(concatenated, hidden_param)
return rewards
def optimal_reward(observation):
"""Outputs the maximum expected reward for every element in the batch."""
return tf.reduce_max(_all_rewards(observation, reward_param), axis=1)
regret_metric = tf_bandit_metrics.RegretMetric(optimal_reward)
ตอนนี้เราพร้อมแล้วที่จะเริ่มการฝึกวนรอบโจรของเรา โปรแกรมควบคุมด้านล่างดูแลการเลือกการดำเนินการโดยใช้นโยบาย จัดเก็บรางวัลของการกระทำที่เลือกไว้ในบัฟเฟอร์การเล่นซ้ำ คำนวณเมตริกการเสียใจที่กำหนดไว้ล่วงหน้า และดำเนินการขั้นตอนการฝึกอบรมของตัวแทน
num_iterations = 20 # @param
steps_per_loop = 1 # @param
replay_buffer = tf_uniform_replay_buffer.TFUniformReplayBuffer(
data_spec=agent.policy.trajectory_spec,
batch_size=BATCH_SIZE,
max_length=steps_per_loop)
observers = [replay_buffer.add_batch, regret_metric]
driver = dynamic_step_driver.DynamicStepDriver(
env=per_arm_tf_env,
policy=agent.collect_policy,
num_steps=steps_per_loop * BATCH_SIZE,
observers=observers)
regret_values = []
for _ in range(num_iterations):
driver.run()
loss_info = agent.train(replay_buffer.gather_all())
replay_buffer.clear()
regret_values.append(regret_metric.result())
WARNING:tensorflow:From /tmp/ipykernel_12052/1190294793.py:21: ReplayBuffer.gather_all (from tf_agents.replay_buffers.replay_buffer) is deprecated and will be removed in a future version. Instructions for updating: Use `as_dataset(..., single_deterministic_pass=True)` instead.
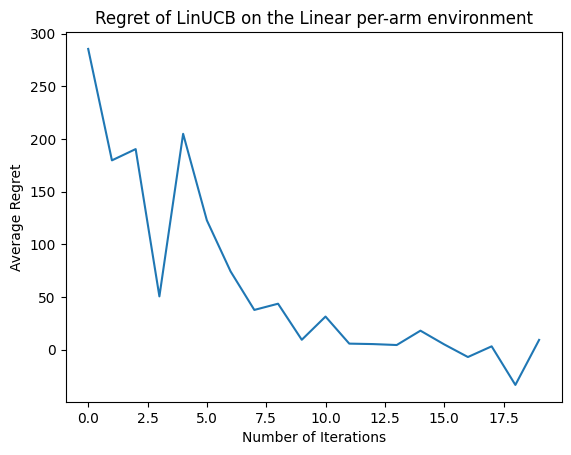
ทีนี้มาดูผลลัพธ์กัน หากเราทำทุกอย่างถูกต้อง ตัวแทนสามารถประเมินฟังก์ชันการให้รางวัลเชิงเส้นได้ดี และทำให้นโยบายสามารถเลือกการดำเนินการที่ผลตอบแทนที่คาดหวังได้ใกล้เคียงกับการกระทำที่เหมาะสมที่สุด ซึ่งระบุโดยเมตริกการเสียใจที่กำหนดไว้ข้างต้น ซึ่งลดลงและเข้าใกล้ศูนย์
plt.plot(regret_values)
plt.title('Regret of LinUCB on the Linear per-arm environment')
plt.xlabel('Number of Iterations')
_ = plt.ylabel('Average Regret')
อะไรต่อไป?
ตัวอย่างข้างต้นจะถูก นำมาใช้ ใน codebase ของเราที่คุณสามารถเลือกได้จากตัวแทนอื่น ๆ เช่นกันรวมทั้ง ตัวแทน epsilon-โลภประสาท