
| | |  GitHub এ দেখুন GitHub এ দেখুন | |
এই Colab ব্যবহারের একটি বিক্ষোভ Tensorflow হাব অ ইংরেজি / স্থানীয় ভাষায় টেক্সট শ্রেণীবিভাগ জন্য। এখানে আমরা চয়ন বাংলা স্থানীয় ভাষা হিসেবে এবং একটি multiclass শ্রেণীবিন্যাস টাস্ক যেখানে আমরা 5 শ্রেণিবিভাগ বাংলা সংবাদ নিবন্ধ শ্রেণীভুক্ত সমাধানের শব্দ embeddings pretrained ব্যবহার। বাংলা ভাষার pretrained embeddings থেকে আসে fastText যা 157 ভাষার জন্য মুক্তি pretrained শব্দ ভেক্টর দিয়ে ফেসবুক দ্বারা একটি লাইব্রেরী।
আমরা প্রথম একটি টেক্সট এম্বেডিং মডিউল শব্দ embeddings রূপান্তরের জন্য মেমরি-হাব এর pretrained এম্বেডিং রপ্তানিকারক ব্যবহার করব এবং তারপর সঙ্গে একটি ক্লাসিফায়ার প্রশিক্ষণের মডিউল ব্যবহার tf.keras , Tensorflow এর উচ্চ স্তর ব্যবহারকারী বন্ধুত্বপূর্ণ এপিআই গভীর লার্নিং মডেল তৈরিতে। এমনকি আমরা এখানে ফাস্ট টেক্সট এম্বেডিং ব্যবহার করলেও, অন্যান্য কাজ থেকে প্রশিক্ষিত অন্য যেকোনো এমবেডিং রপ্তানি করা এবং Tensorflow হাবের মাধ্যমে দ্রুত ফলাফল পাওয়া সম্ভব।
সেটআপ
# https://github.com/pypa/setuptools/issues/1694#issuecomment-466010982pip install gdown --no-use-pep517
sudo apt-get install -y unzip
Reading package lists... Building dependency tree... Reading state information... unzip is already the newest version (6.0-21ubuntu1.1). The following packages were automatically installed and are no longer required: linux-gcp-5.4-headers-5.4.0-1040 linux-gcp-5.4-headers-5.4.0-1043 linux-gcp-5.4-headers-5.4.0-1044 linux-gcp-5.4-headers-5.4.0-1049 linux-headers-5.4.0-1049-gcp linux-image-5.4.0-1049-gcp linux-modules-5.4.0-1049-gcp linux-modules-extra-5.4.0-1049-gcp Use 'sudo apt autoremove' to remove them. 0 upgraded, 0 newly installed, 0 to remove and 143 not upgraded.
import os
import tensorflow as tf
import tensorflow_hub as hub
import gdown
import numpy as np
from sklearn.metrics import classification_report
import matplotlib.pyplot as plt
import seaborn as sns
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py:119: PkgResourcesDeprecationWarning: 0.18ubuntu0.18.04.1 is an invalid version and will not be supported in a future release PkgResourcesDeprecationWarning,
ডেটাসেট
আমরা ব্যবহার করবে বার্ড অর্থনীতি, রাষ্ট্র, আন্তর্জাতিক, ক্রীড়া, ও বিনোদন: (বাংলা আর্টিকেল ডেটা সেটটি) যা প্রায় 376.226 প্রবন্ধ বিভিন্ন বাংলা নিউজ পোর্টাল থেকে সংগৃহীত এবং 5 বিভাগ দিয়ে লেবেল হয়েছে। আমরা এই (যেমন Google ড্রাইভ থেকে ফাইল ডাউনলোড bit.ly/BARD_DATASET ) লিঙ্ক থেকে উল্লেখ করা হয় এই GitHub সংগ্রহস্থল।
gdown.download(
url='https://drive.google.com/uc?id=1Ag0jd21oRwJhVFIBohmX_ogeojVtapLy',
output='bard.zip',
quiet=True
)
'bard.zip'
unzip -qo bard.zip
TF-Hub মডিউলে পূর্বপ্রশিক্ষিত শব্দ ভেক্টর রপ্তানি করুন
মেমরি-হাব মেমরি-হাব টেক্সট এম্বেড মডিউল শব্দ embeddings রূপান্তরের জন্য কিছু দরকারী স্ক্রিপ্ট প্রদান করে এখানে । বাংলা বা অন্য কোন ভাষার জন্য মডিউল করতে, আমরা কেবল শব্দ এম্বেডিং ডাউনলোড করতে হবে .txt বা .vec হিসাবে একই ডিরেক্টরির ফাইল export_v2.py এবং স্ক্রিপ্ট চালানো।
রপ্তানিকারক এম্বেডিং ভেক্টর পড়ে এবং একটি Tensorflow তা রপ্তানি SavedModel । একটি সংরক্ষিত মডেলে ওজন এবং গ্রাফ সহ একটি সম্পূর্ণ টেনসরফ্লো প্রোগ্রাম রয়েছে। মেমরি-হাব হিসেবে SavedModel লোড করতে পারেন মডিউল , যা আমরা পাঠ শ্রেণীবিভাগ জন্য মডেল গড়ে তুলতে ব্যবহার করা হবে। আমরা ব্যবহার যেহেতু tf.keras মডেল নির্মাণ করতে, আমরা ব্যবহার করবে hub.KerasLayer , যা একটি Keras লেয়ার হিসাবে ব্যবহার করার জন্য একটি TF-হাব মডিউলের জন্য একটি লেফাফা প্রদান করে।
আমরা প্রথমে মেমরি-হাব থেকে fastText থেকে আমাদের শব্দ embeddings এবং এমবেডিং রপ্তানিকারক পাবেন রেপো ।
curl -O https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.bn.300.vec.gzcurl -O https://raw.githubusercontent.com/tensorflow/hub/master/examples/text_embeddings_v2/export_v2.pygunzip -qf cc.bn.300.vec.gz --k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 840M 100 840M 0 0 11.6M 0 0:01:12 0:01:12 --:--:-- 12.0M
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 7469 100 7469 0 0 19053 0 --:--:-- --:--:-- --:--:-- 19005
তারপর, আমরা আমাদের এমবেডিং ফাইলে রপ্তানিকারক স্ক্রিপ্ট চালাব। যেহেতু ফাস্ট টেক্সট এম্বেডিং-এর একটি হেডার লাইন রয়েছে এবং এটি বেশ বড় (একটি মডিউলে রূপান্তর করার পর বাংলার জন্য প্রায় 3.3 জিবি) আমরা প্রথম লাইনটিকে উপেক্ষা করি এবং টেক্সট এমবেডিং মডিউলে শুধুমাত্র প্রথম 100,000 টোকেন রপ্তানি করি।
python export_v2.py --embedding_file=cc.bn.300.vec --export_path=text_module --num_lines_to_ignore=1 --num_lines_to_use=100000
INFO:tensorflow:Assets written to: text_module/assets I1105 11:55:29.817717 140238757988160 builder_impl.py:784] Assets written to: text_module/assets
module_path = "text_module"
embedding_layer = hub.KerasLayer(module_path, trainable=False)
টেক্সট এমবেডিং মডিউল ইনপুট হিসাবে স্ট্রিংগুলির একটি 1D টেনসরে বাক্যগুলির একটি ব্যাচ নেয় এবং বাক্যগুলির সাথে সম্পর্কিত আকৃতির এমবেডিং ভেক্টর (ব্যাচ_সাইজ, এমবেডিং_ডিম) আউটপুট করে। এটি স্পেসগুলিতে বিভক্ত করে ইনপুটকে পূর্বে প্রক্রিয়াকরণ করে। ওয়ার্ড embeddings সঙ্গে বাক্য embeddings করতে একত্রিত করা হয় sqrtn combiner (দেখুন এখানে )। প্রদর্শনের জন্য আমরা ইনপুট হিসাবে বাংলা শব্দের একটি তালিকা পাস করি এবং সংশ্লিষ্ট এমবেডিং ভেক্টর পাই।
embedding_layer(['বাস', 'বসবাস', 'ট্রেন', 'যাত্রী', 'ট্রাক'])
<tf.Tensor: shape=(5, 300), dtype=float64, numpy=
array([[ 0.0462, -0.0355, 0.0129, ..., 0.0025, -0.0966, 0.0216],
[-0.0631, -0.0051, 0.085 , ..., 0.0249, -0.0149, 0.0203],
[ 0.1371, -0.069 , -0.1176, ..., 0.029 , 0.0508, -0.026 ],
[ 0.0532, -0.0465, -0.0504, ..., 0.02 , -0.0023, 0.0011],
[ 0.0908, -0.0404, -0.0536, ..., -0.0275, 0.0528, 0.0253]])>
টেনসরফ্লো ডেটাসেটে রূপান্তর করুন
যেহেতু ডেটা সেটটি সত্যিই পরিবর্তে মেমরি সমগ্র ডেটা সেটটি লোড বড় আমরা ব্যবহার ব্যাচে রান টাইমে নমুনা উত্পাদ করার জন্য একটি জেনারেটর ব্যবহার করবে Tensorflow ডেটা সেটটি ফাংশন। ডেটাসেটটিও খুব ভারসাম্যহীন, তাই, জেনারেটর ব্যবহার করার আগে, আমরা ডেটাসেটটি এলোমেলো করে দেব।
dir_names = ['economy', 'sports', 'entertainment', 'state', 'international']
file_paths = []
labels = []
for i, dir in enumerate(dir_names):
file_names = ["/".join([dir, name]) for name in os.listdir(dir)]
file_paths += file_names
labels += [i] * len(os.listdir(dir))
np.random.seed(42)
permutation = np.random.permutation(len(file_paths))
file_paths = np.array(file_paths)[permutation]
labels = np.array(labels)[permutation]
আমরা শাফলিং করার পরে প্রশিক্ষণ এবং বৈধতা উদাহরণগুলিতে লেবেলের বিতরণ পরীক্ষা করতে পারি।
train_frac = 0.8
train_size = int(len(file_paths) * train_frac)
# plot training vs validation distribution
plt.subplot(1, 2, 1)
plt.hist(labels[0:train_size])
plt.title("Train labels")
plt.subplot(1, 2, 2)
plt.hist(labels[train_size:])
plt.title("Validation labels")
plt.tight_layout()
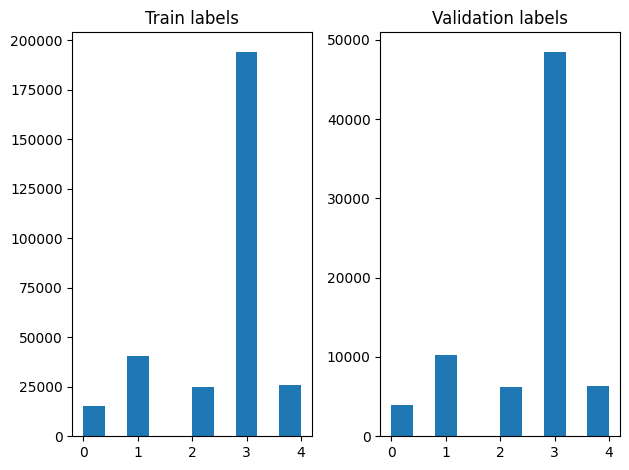
একটি তৈরি করতে ডেটা সেটটি জেনারেটরের ব্যবহার করে, আমরা প্রথমে একটি উত্পাদক ফাংশন যা থেকে প্রবন্ধ প্রতিটি সার্চ লিখতে file_paths ট্যাগ অ্যারে থেকে এবং লেবেল এবং উৎপাদনের প্রতিটি ধাপের এক প্রশিক্ষণ উদাহরণ। আমরা এই উত্পাদক ফাংশন পাস tf.data.Dataset.from_generator পদ্ধতি এবং আউটপুট ধরনের উল্লেখ করুন। প্রতিটি প্রশিক্ষণ উদাহরণস্বরূপ একটি নিবন্ধ সম্বলিত একটি tuple হয় tf.string ডাটা টাইপ এবং এক গরম এনকোডেড লেবেল। আমরা ব্যবহার 80-20 একটি ট্রেন-বৈধতা বিভক্ত সঙ্গে ডেটা সেটটি বিভক্ত tf.data.Dataset.skip এবং tf.data.Dataset.take পদ্ধতি।
def load_file(path, label):
return tf.io.read_file(path), label
def make_datasets(train_size):
batch_size = 256
train_files = file_paths[:train_size]
train_labels = labels[:train_size]
train_ds = tf.data.Dataset.from_tensor_slices((train_files, train_labels))
train_ds = train_ds.map(load_file).shuffle(5000)
train_ds = train_ds.batch(batch_size).prefetch(tf.data.AUTOTUNE)
test_files = file_paths[train_size:]
test_labels = labels[train_size:]
test_ds = tf.data.Dataset.from_tensor_slices((test_files, test_labels))
test_ds = test_ds.map(load_file)
test_ds = test_ds.batch(batch_size).prefetch(tf.data.AUTOTUNE)
return train_ds, test_ds
train_data, validation_data = make_datasets(train_size)
মডেল প্রশিক্ষণ এবং মূল্যায়ন
যেহেতু আমরা ইতিমধ্যে আমাদের মডিউল Keras অন্য কোন স্তর হিসাবে এটি ব্যবহার কাছাকাছি একটি লেফাফা যুক্ত করেছেন, আমরা একটি ছোট তৈরি করতে পারেন অনুক্রমিক মডেল যা স্তর একটি রৈখিক স্ট্যাক হয়। আমরা সঙ্গে আমাদের টেক্সট এম্বেডিং মডিউল যোগ করতে পারেন model.add শুধু অন্য কোন স্তর নেই। আমরা ক্ষতি এবং অপ্টিমাইজার নির্দিষ্ট করে মডেলটি কম্পাইল করি এবং 10টি যুগের জন্য এটিকে প্রশিক্ষণ দিই। tf.keras এপিআই, ইনপুট হিসাবে Tensorflow ডেটাসেটস সব ব্যবস্থা করতে সক্ষম তাই আমরা মডেল প্রশিক্ষণের জন্য ফিট পদ্ধতি একটি ডেটাসেটের উদাহরণস্বরূপ পাস করতে পারেন। আমরা উত্পাদক ফাংশন ব্যবহার করছেন থেকে, tf.data , নমুনা উৎপাদিত তাদের Batching এবং তাদের মডেলের খাওয়ানোর হ্যান্ডেল করবে।
মডেল
def create_model():
model = tf.keras.Sequential([
tf.keras.layers.Input(shape=[], dtype=tf.string),
embedding_layer,
tf.keras.layers.Dense(64, activation="relu"),
tf.keras.layers.Dense(16, activation="relu"),
tf.keras.layers.Dense(5),
])
model.compile(loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer="adam", metrics=['accuracy'])
return model
model = create_model()
# Create earlystopping callback
early_stopping_callback = tf.keras.callbacks.EarlyStopping(monitor='val_loss', min_delta=0, patience=3)
প্রশিক্ষণ
history = model.fit(train_data,
validation_data=validation_data,
epochs=5,
callbacks=[early_stopping_callback])
Epoch 1/5 1176/1176 [==============================] - 34s 28ms/step - loss: 0.2181 - accuracy: 0.9279 - val_loss: 0.1580 - val_accuracy: 0.9449 Epoch 2/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1411 - accuracy: 0.9505 - val_loss: 0.1411 - val_accuracy: 0.9503 Epoch 3/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1307 - accuracy: 0.9534 - val_loss: 0.1359 - val_accuracy: 0.9524 Epoch 4/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1248 - accuracy: 0.9555 - val_loss: 0.1318 - val_accuracy: 0.9527 Epoch 5/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1196 - accuracy: 0.9567 - val_loss: 0.1247 - val_accuracy: 0.9555
মূল্যায়ন
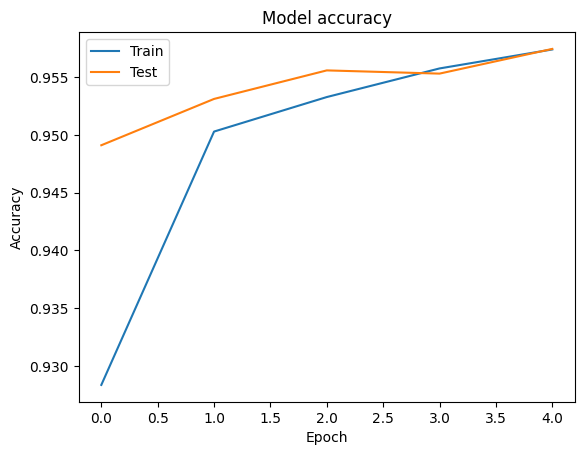
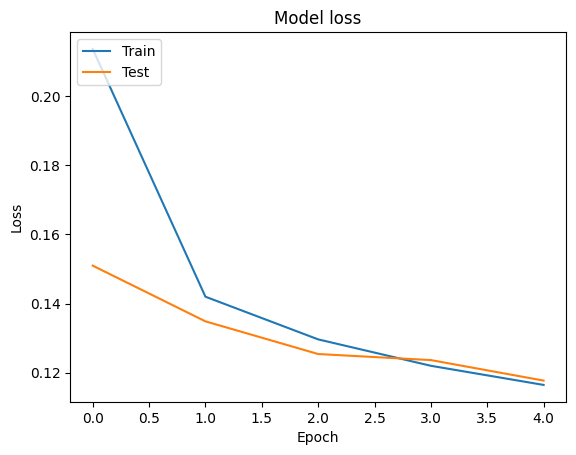
আমরা ব্যবহার প্রশিক্ষণ ও বৈধতা ডেটার জন্য সঠিকতা এবং ক্ষয় রেখাচিত্র দৃশ্য কল্পনা করতে পারেন tf.keras.callbacks.History বস্তু দ্বারা ফিরে tf.keras.Model.fit পদ্ধতি, যা প্রতিটি যুগে জন্য কমে যাওয়া এবং সঠিকতা মান রয়েছে।
# Plot training & validation accuracy values
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
# Plot training & validation loss values
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
ভবিষ্যদ্বাণী
আমরা বৈধতা ডেটার জন্য ভবিষ্যদ্বাণী পেতে পারি এবং 5টি ক্লাসের প্রতিটির জন্য মডেলের কার্যকারিতা দেখতে বিভ্রান্তি ম্যাট্রিক্স পরীক্ষা করতে পারি। কারণ tf.keras.Model.predict পদ্ধতি প্রতিটি বর্গ জন্য সম্ভাব্যতা জন্য একটি য় অ্যারের ফেরৎ, তারা ব্যবহার বর্গ লেবেলে পরিবর্তিত করা যায় np.argmax ।
y_pred = model.predict(validation_data)
y_pred = np.argmax(y_pred, axis=1)
samples = file_paths[0:3]
for i, sample in enumerate(samples):
f = open(sample)
text = f.read()
print(text[0:100])
print("True Class: ", sample.split("/")[0])
print("Predicted Class: ", dir_names[y_pred[i]])
f.close()
রবিন উইলিয়ামস তাঁর হ্যাপি ফিট ছবিতে মজা করে বলেছিলেন, ‘আমি শুনতে পাচ্ছি, মানুষ কিছু একটা চাইছে...সে True Class: entertainment Predicted Class: state নির্মাণ শেষে ফিতা কেটে মন্ত্রী ভবন উদ্বোধন করেছেন বহু আগেই। তবে এখনো চালু করা যায়নি খাগড়াছড়ি জেল True Class: state Predicted Class: state কমলাপুর বীরশ্রেষ্ঠ মোস্তফা কামাল স্টেডিয়ামে কাল ফকিরেরপুল ইয়ংমেন্স ক্লাব ৩-০ গোলে হারিয়েছে স্বাধ True Class: sports Predicted Class: state
কর্মক্ষমতা তুলনা
এখন আমরা থেকে বৈধতা ডেটার জন্য সঠিক লেবেল গ্রহণ করতে পারেন labels এবং পাওয়ার জন্য আমাদের পূর্বানুমান সহ তাদের তুলনা classification_report ।
y_true = np.array(labels[train_size:])
print(classification_report(y_true, y_pred, target_names=dir_names))
precision recall f1-score support
economy 0.83 0.76 0.79 3897
sports 0.99 0.98 0.98 10204
entertainment 0.90 0.94 0.92 6256
state 0.97 0.97 0.97 48512
international 0.92 0.93 0.93 6377
accuracy 0.96 75246
macro avg 0.92 0.92 0.92 75246
weighted avg 0.96 0.96 0.96 75246
আমরা মূল প্রাপ্ত প্রকাশিত ফলাফল নিয়ে আমাদের মডেল এর পারফরম্যান্সের তুলনা করতে পারবেন কাগজ , যা একটি 0.96 স্পষ্টতা লোকের মূল লেখক অনেক প্রাক-প্রক্রিয়াকরণ পদক্ষেপ যেমন যতিচিহ্ন ও স w খ্যা ড্রপ শীর্ষ 25 সবচেয়ে frequest স্টপ শব্দ সরানোর হিসাবে, ডেটা সেটটি সম্পাদনা বর্ণনা ছিল। আমরা দেখতে পারেন classification_report , আমরা কোনো প্রাক-প্রক্রিয়াকরণ ছাড়া মাত্র 5 সময়কাল প্রশিক্ষণ পর 0.96 স্পষ্টতা এবং সঠিকতা প্রাপ্ত পরিচালনা!
এই উদাহরণে, যখন আমরা আমাদের এম্বেড মডিউল থেকে Keras স্তর সৃষ্টি আমরা প্যারামিটার সেট trainable=False , যা এম্বেডিং ওজন প্রশিক্ষণের সময় আপডেট করা হবে না মানে। এটা সেট করার চেষ্টা True শুধুমাত্র 2 সময়কাল পরে এই ডেটা সেটটি ব্যবহার প্রায় 97% সঠিকতা পৌঁছানোর।