
| | |  ดูแหล่งที่มาบน GitHub ดูแหล่งที่มาบน GitHub | |
ในตัวอย่างนี้ คุณจะสำรวจผลลัพธ์ของ McClean ปี 2019 ที่บอกว่าไม่ใช่แค่โครงสร้างเครือข่ายนิวรัลควอนตัมเท่านั้นที่จะทำได้ดีเมื่อพูดถึงการเรียนรู้ โดยเฉพาะอย่างยิ่ง คุณจะเห็นว่าวงจรควอนตัมสุ่มกลุ่มใหญ่บางกลุ่มไม่ได้ทำหน้าที่เป็นเครือข่ายนิวรัลควอนตัมที่ดี เพราะมันมีการไล่ระดับสีที่หายไปเกือบทุกที่ ในตัวอย่างนี้ คุณจะไม่ได้ฝึกแบบจำลองใดๆ สำหรับปัญหาการเรียนรู้ที่เฉพาะเจาะจง แต่ให้เน้นที่ปัญหาที่ง่ายกว่าในการทำความเข้าใจพฤติกรรมของการไล่ระดับสี
ติดตั้ง
pip install tensorflow==2.7.0
ติดตั้ง TensorFlow Quantum:
pip install tensorflow-quantum
# Update package resources to account for version changes.
import importlib, pkg_resources
importlib.reload(pkg_resources)
<module 'pkg_resources' from '/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py'>
ตอนนี้นำเข้า TensorFlow และการพึ่งพาโมดูล:
import tensorflow as tf
import tensorflow_quantum as tfq
import cirq
import sympy
import numpy as np
# visualization tools
%matplotlib inline
import matplotlib.pyplot as plt
from cirq.contrib.svg import SVGCircuit
np.random.seed(1234)
2022-02-04 12:15:43.355568: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
1. สรุป
วงจรควอนตัมสุ่มที่มีบล็อกจำนวนมากที่มีลักษณะเช่นนี้ (\(R_{P}(\theta)\) คือการหมุน Pauli แบบสุ่ม):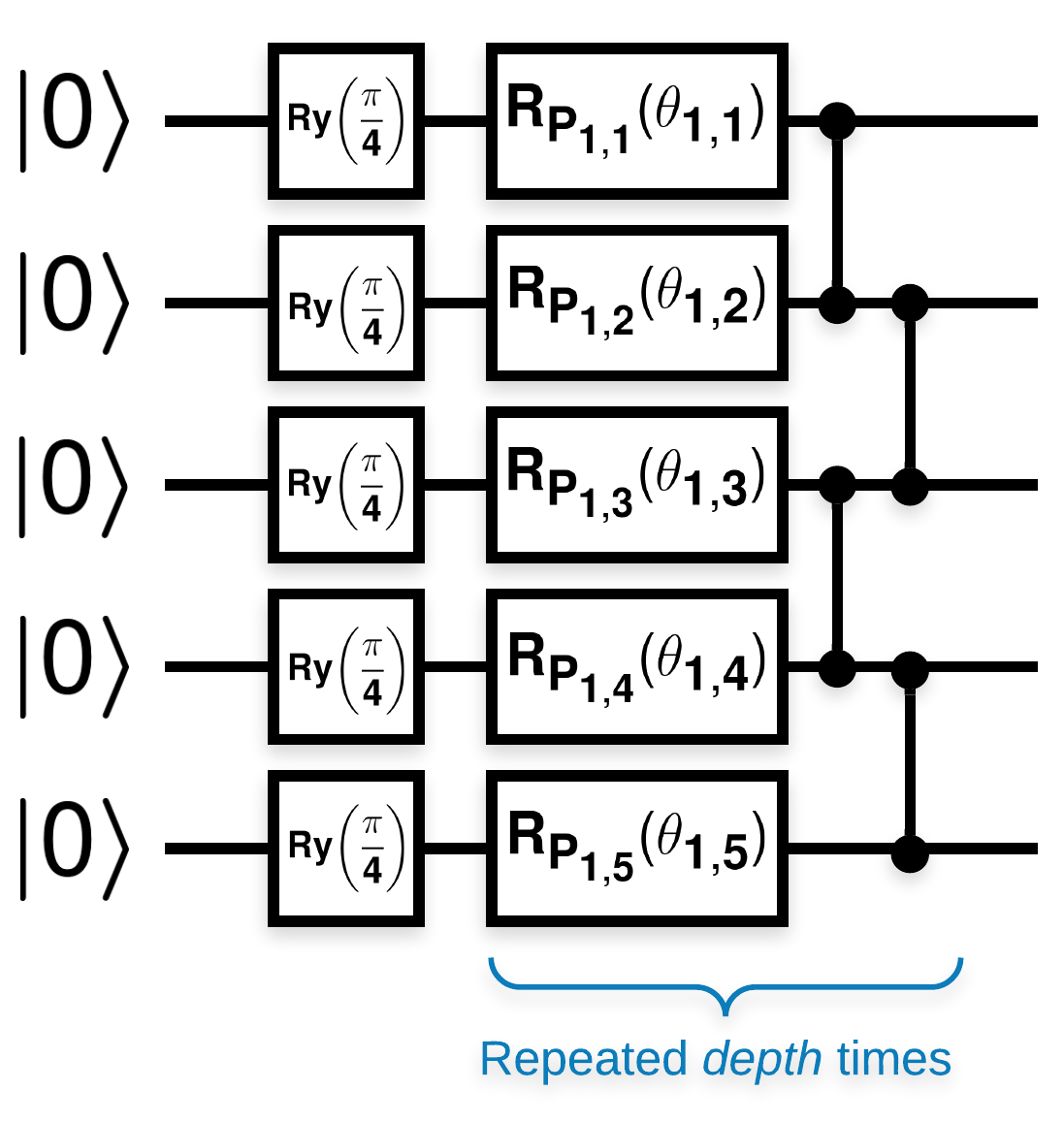
โดยที่ \(f(x)\) ถูกกำหนดให้เป็นค่าความคาดหวัง wrt \(Z_{a}Z_{b}\) สำหรับ qubits ใด ๆ \(a\) และ \(b\)แสดงว่ามีปัญหาที่ \(f'(x)\) มีค่าเฉลี่ยใกล้เคียงกับ 0 มาก และไม่แตกต่างกันมากนัก คุณจะเห็นสิ่งนี้ด้านล่าง:
2. การสร้างวงจรสุ่ม
การก่อสร้างจากกระดาษนั้นตรงไปตรงมา ต่อไปนี้ใช้ฟังก์ชันง่าย ๆ ที่สร้างวงจรควอนตัมแบบสุ่ม ซึ่งบางครั้งเรียกว่า เครือข่ายประสาทควอนตัม (QNN) ด้วยความลึกที่กำหนดในชุดของ qubits:
def generate_random_qnn(qubits, symbol, depth):
"""Generate random QNN's with the same structure from McClean et al."""
circuit = cirq.Circuit()
for qubit in qubits:
circuit += cirq.ry(np.pi / 4.0)(qubit)
for d in range(depth):
# Add a series of single qubit rotations.
for i, qubit in enumerate(qubits):
random_n = np.random.uniform()
random_rot = np.random.uniform(
) * 2.0 * np.pi if i != 0 or d != 0 else symbol
if random_n > 2. / 3.:
# Add a Z.
circuit += cirq.rz(random_rot)(qubit)
elif random_n > 1. / 3.:
# Add a Y.
circuit += cirq.ry(random_rot)(qubit)
else:
# Add a X.
circuit += cirq.rx(random_rot)(qubit)
# Add CZ ladder.
for src, dest in zip(qubits, qubits[1:]):
circuit += cirq.CZ(src, dest)
return circuit
generate_random_qnn(cirq.GridQubit.rect(1, 3), sympy.Symbol('theta'), 2)
ผู้เขียนตรวจสอบความลาดชันของพารามิเตอร์เดียว \(\theta_{1,1}\)ตามด้วยการวาง sympy.Symbol ในวงจรที่ \(\theta_{1,1}\) จะเป็น เนื่องจากผู้เขียนไม่ได้วิเคราะห์สถิติสำหรับสัญลักษณ์อื่นใดในวงจร เรามาแทนที่ด้วยค่าสุ่มตอนนี้แทนในภายหลัง
3. การเดินวงจร
สร้างวงจรเหล่านี้บางส่วนพร้อมกับสิ่งที่สังเกตได้เพื่อทดสอบการอ้างสิทธิ์ว่าการไล่ระดับสีไม่แตกต่างกันมากนัก ขั้นแรก สร้างชุดของวงจรสุ่ม เลือกสุ่ม ZZ ที่สังเกตได้และคำนวณแบทช์และความแปรปรวนโดยใช้ TensorFlow Quantum
3.1 การคำนวณความแปรปรวนแบบแบตช์
มาเขียนฟังก์ชันตัวช่วยที่คำนวณความแปรปรวนของการไล่ระดับของค่าที่สังเกตได้ผ่านชุดของวงจร:
def process_batch(circuits, symbol, op):
"""Compute the variance of a batch of expectations w.r.t. op on each circuit that
contains `symbol`. Note that this method sets up a new compute graph every time it is
called so it isn't as performant as possible."""
# Setup a simple layer to batch compute the expectation gradients.
expectation = tfq.layers.Expectation()
# Prep the inputs as tensors
circuit_tensor = tfq.convert_to_tensor(circuits)
values_tensor = tf.convert_to_tensor(
np.random.uniform(0, 2 * np.pi, (n_circuits, 1)).astype(np.float32))
# Use TensorFlow GradientTape to track gradients.
with tf.GradientTape() as g:
g.watch(values_tensor)
forward = expectation(circuit_tensor,
operators=op,
symbol_names=[symbol],
symbol_values=values_tensor)
# Return variance of gradients across all circuits.
grads = g.gradient(forward, values_tensor)
grad_var = tf.math.reduce_std(grads, axis=0)
return grad_var.numpy()[0]
3.1 ตั้งค่าและเรียกใช้
เลือกจำนวนวงจรสุ่มเพื่อสร้างพร้อมกับความลึกและจำนวน qubit ที่ควรดำเนินการ จากนั้นพล็อตผลลัพธ์
n_qubits = [2 * i for i in range(2, 7)
] # Ranges studied in paper are between 2 and 24.
depth = 50 # Ranges studied in paper are between 50 and 500.
n_circuits = 200
theta_var = []
for n in n_qubits:
# Generate the random circuits and observable for the given n.
qubits = cirq.GridQubit.rect(1, n)
symbol = sympy.Symbol('theta')
circuits = [
generate_random_qnn(qubits, symbol, depth) for _ in range(n_circuits)
]
op = cirq.Z(qubits[0]) * cirq.Z(qubits[1])
theta_var.append(process_batch(circuits, symbol, op))
plt.semilogy(n_qubits, theta_var)
plt.title('Gradient Variance in QNNs')
plt.xlabel('n_qubits')
plt.xticks(n_qubits)
plt.ylabel('$\\partial \\theta$ variance')
plt.show()
WARNING:tensorflow:5 out of the last 5 calls to <function Adjoint.differentiate_analytic at 0x7f9e3b5c68c0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.ตัวยึดตำแหน่ง22
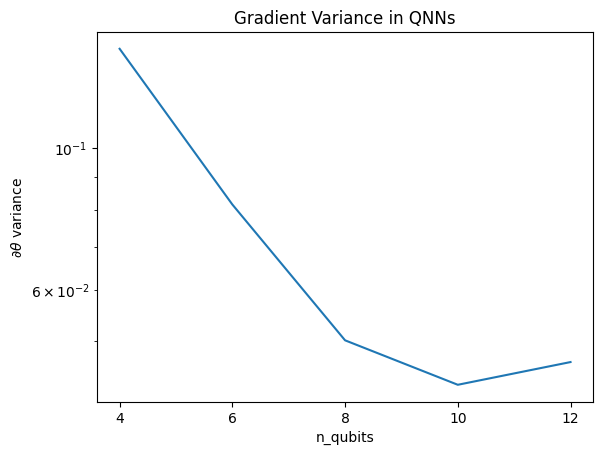
พล็อตนี้แสดงให้เห็นว่าสำหรับปัญหาการเรียนรู้ของเครื่องควอนตัม คุณไม่สามารถเดาสุ่ม QNN ansatz และหวังว่าจะดีที่สุด โครงสร้างบางอย่างต้องมีอยู่ในวงจรแบบจำลองเพื่อให้การไล่ระดับสีแปรผันจนถึงจุดที่การเรียนรู้สามารถเกิดขึ้นได้
4. ฮิวริสติก
ฮิวริสติกที่น่าสนใจโดย Grant ปี 2019 เปิดโอกาสให้ผู้ใช้เริ่มสุ่มได้ใกล้เคียงกันมาก แต่ก็ไม่ทั้งหมด การใช้วงจรเดียวกันกับ McClean et al. ผู้เขียนเสนอเทคนิคการเริ่มต้นที่แตกต่างกันสำหรับพารามิเตอร์การควบคุมแบบคลาสสิกเพื่อหลีกเลี่ยงที่ราบสูงที่แห้งแล้ง เทคนิคการเริ่มต้นจะเริ่มต้นบางเลเยอร์ด้วยพารามิเตอร์ควบคุมแบบสุ่มทั้งหมด—แต่ในเลเยอร์ที่ตามมาทันที ให้เลือกพารามิเตอร์เพื่อที่การเปลี่ยนแปลงเริ่มต้นที่ทำโดยสองสามเลเยอร์แรกจะถูกยกเลิก ผู้เขียนเรียกสิ่งนี้ว่า บล็อกข้อมูลประจำตัว
ข้อได้เปรียบของฮิวริสติกนี้คือการเปลี่ยนเพียงพารามิเตอร์เดียว บล็อกอื่นๆ ทั้งหมดที่อยู่นอกบล็อกปัจจุบันจะยังคงเป็นเอกลักษณ์—และสัญญาณเกรเดียนต์จะแข็งแกร่งกว่าเมื่อก่อนมาก ซึ่งช่วยให้ผู้ใช้สามารถเลือกและเลือกตัวแปรและบล็อกที่จะปรับเปลี่ยนเพื่อรับสัญญาณเกรเดียนต์ที่แรงได้ การวิเคราะห์พฤติกรรมนี้ไม่ได้ป้องกันผู้ใช้จากการตกสู่ที่ราบสูงที่แห้งแล้งในระหว่างขั้นตอนการฝึก (และจำกัดการอัปเดตพร้อมกันอย่างสมบูรณ์) เพียงแต่รับประกันว่าคุณสามารถเริ่มต้นนอกที่ราบสูงได้
4.1 การก่อสร้าง QNN ใหม่
ตอนนี้สร้างฟังก์ชันเพื่อสร้าง QNN บล็อกข้อมูลประจำตัว การใช้งานนี้แตกต่างไปจากเอกสารเล็กน้อย สำหรับตอนนี้ ให้ดูพฤติกรรมของการไล่ระดับของพารามิเตอร์เดียวเพื่อให้สอดคล้องกับ McClean et al ดังนั้นจึงทำให้เข้าใจง่ายขึ้น
ในการสร้างบล็อคข้อมูลประจำตัวและฝึกโมเดล โดยทั่วไปคุณต้องมี \(U1(\theta_{1a}) U1(\theta_{1b})^{\dagger}\) ไม่ใช่ \(U1(\theta_1) U1(\theta_1)^{\dagger}\)เริ่มแรก \(\theta_{1a}\) และ \(\theta_{1b}\) เป็นมุมเดียวกัน แต่เรียนรู้อย่างอิสระ มิฉะนั้น คุณจะได้รับข้อมูลประจำตัวเสมอแม้หลังจากการฝึก ทางเลือกสำหรับจำนวนบล็อคข้อมูลประจำตัวนั้นเป็นแบบประจักษ์ ยิ่งบล็อกลึก ความแปรปรวนตรงกลางบล็อกยิ่งเล็กลง แต่ที่จุดเริ่มต้นและจุดสิ้นสุดของบล็อก ความแปรปรวนของการไล่ระดับพารามิเตอร์ควรมีขนาดใหญ่
def generate_identity_qnn(qubits, symbol, block_depth, total_depth):
"""Generate random QNN's with the same structure from Grant et al."""
circuit = cirq.Circuit()
# Generate initial block with symbol.
prep_and_U = generate_random_qnn(qubits, symbol, block_depth)
circuit += prep_and_U
# Generate dagger of initial block without symbol.
U_dagger = (prep_and_U[1:])**-1
circuit += cirq.resolve_parameters(
U_dagger, param_resolver={symbol: np.random.uniform() * 2 * np.pi})
for d in range(total_depth - 1):
# Get a random QNN.
prep_and_U_circuit = generate_random_qnn(
qubits,
np.random.uniform() * 2 * np.pi, block_depth)
# Remove the state-prep component
U_circuit = prep_and_U_circuit[1:]
# Add U
circuit += U_circuit
# Add U^dagger
circuit += U_circuit**-1
return circuit
generate_identity_qnn(cirq.GridQubit.rect(1, 3), sympy.Symbol('theta'), 2, 2)
4.2 การเปรียบเทียบ
ที่นี่คุณจะเห็นว่าฮิวริสติกช่วยรักษาความแปรปรวนของการไล่ระดับสีไม่ให้หายไปอย่างรวดเร็ว:
block_depth = 10
total_depth = 5
heuristic_theta_var = []
for n in n_qubits:
# Generate the identity block circuits and observable for the given n.
qubits = cirq.GridQubit.rect(1, n)
symbol = sympy.Symbol('theta')
circuits = [
generate_identity_qnn(qubits, symbol, block_depth, total_depth)
for _ in range(n_circuits)
]
op = cirq.Z(qubits[0]) * cirq.Z(qubits[1])
heuristic_theta_var.append(process_batch(circuits, symbol, op))
plt.semilogy(n_qubits, theta_var)
plt.semilogy(n_qubits, heuristic_theta_var)
plt.title('Heuristic vs. Random')
plt.xlabel('n_qubits')
plt.xticks(n_qubits)
plt.ylabel('$\\partial \\theta$ variance')
plt.show()
WARNING:tensorflow:6 out of the last 6 calls to <function Adjoint.differentiate_analytic at 0x7f9e3b5c68c0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.
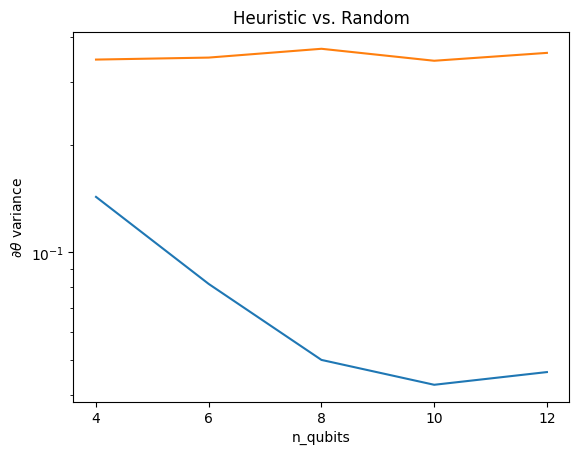
นี่เป็นการปรับปรุงที่ยอดเยี่ยมในการรับสัญญาณเกรเดียนต์ที่แรงขึ้นจาก (ใกล้) QNN แบบสุ่ม