
ประสิทธิภาพของ TensorFlow Serving ขึ้นอยู่กับแอปพลิเคชันที่รัน สภาพแวดล้อมที่ใช้งาน และซอฟต์แวร์อื่นๆ ที่แชร์การเข้าถึงทรัพยากรฮาร์ดแวร์ที่เกี่ยวข้อง ด้วยเหตุนี้ การปรับแต่งประสิทธิภาพจึงขึ้นอยู่กับตัวพิมพ์เล็กและใหญ่ และมีกฎสากลเพียงไม่กี่ข้อที่รับประกันว่าจะให้ประสิทธิภาพสูงสุดในทุกการตั้งค่า ด้วยเหตุนี้ เอกสารนี้จึงมีจุดมุ่งหมายเพื่อรวบรวมหลักการทั่วไปและแนวทางปฏิบัติที่ดีที่สุดสำหรับการเรียกใช้ TensorFlow Serving
โปรดใช้คำแนะนำ Profile Inference Requests with TensorBoard เพื่อทำความเข้าใจพฤติกรรมพื้นฐานของการคำนวณของโมเดลในคำขออนุมาน และใช้คู่มือนี้เพื่อปรับปรุงประสิทธิภาพของโมเดลซ้ำๆ
เคล็ดลับด่วน
- เวลาแฝงของคำขอแรกสูงเกินไป? เปิดใช้งาน การวอร์มอัพโมเดล
- สนใจการใช้ทรัพยากรหรือปริมาณงานที่สูงขึ้นหรือไม่? กำหนด ค่าแบทช์
การปรับแต่งประสิทธิภาพ: วัตถุประสงค์และพารามิเตอร์
เมื่อปรับแต่งประสิทธิภาพของ TensorFlow Serving โดยปกติแล้วจะมีวัตถุประสงค์ 2 ประเภทที่คุณอาจมี และพารามิเตอร์ 3 กลุ่มที่ต้องปรับแต่งเพื่อปรับปรุงตามวัตถุประสงค์เหล่านั้น
วัตถุประสงค์
TensorFlow Serving คือ ระบบการให้บริการออนไลน์ สำหรับโมเดลแมชชีนเลิร์นนิง เช่นเดียวกับระบบการให้บริการออนไลน์อื่นๆ วัตถุประสงค์ด้านประสิทธิภาพหลักคือการ เพิ่มปริมาณงานสูงสุดในขณะที่รักษาเวลาแฝงให้ต่ำกว่าขอบเขตที่กำหนด ขึ้นอยู่กับรายละเอียดและความสมบูรณ์ของแอปพลิเคชันของคุณ คุณอาจสนใจเวลาแฝงโดยเฉลี่ยมากกว่า เวลาแฝง ส่วนท้าย แต่แนวคิดบางประการเกี่ยวกับ เวลาแฝง และ ปริมาณงาน มักจะเป็นตัวชี้วัดที่คุณตั้งวัตถุประสงค์ด้านประสิทธิภาพ โปรดทราบว่าเราไม่ได้กล่าวถึงความพร้อมใช้งานในคู่มือนี้ เนื่องจากเป็นฟังก์ชันของสภาพแวดล้อมการปรับใช้มากกว่า
พารามิเตอร์
เราสามารถคิดคร่าวๆ เกี่ยวกับพารามิเตอร์ 3 กลุ่มที่การกำหนดค่ากำหนดประสิทธิภาพที่สังเกตได้: 1) โมเดล TensorFlow 2) คำขอการอนุมาน และ 3) เซิร์ฟเวอร์ (ฮาร์ดแวร์และไบนารี)
1) โมเดลเทนเซอร์โฟลว์
โมเดลนี้จะกำหนดการคำนวณที่ TensorFlow Serving จะดำเนินการเมื่อได้รับคำขอที่เข้ามาแต่ละรายการ
ภายใต้ประทุน TensorFlow Serving ใช้รันไทม์ TensorFlow เพื่อทำการอนุมานตามจริงกับคำขอของคุณ ซึ่งหมายความว่า เวลาแฝงโดยเฉลี่ย ในการให้บริการคำขอด้วย TensorFlow Serving โดยปกติแล้ว จะเป็นเวลาอย่างน้อยในการอนุมานโดยตรงกับ TensorFlow ซึ่งหมายความว่าหากบนเครื่องที่กำหนด การอนุมานตัวอย่างเดียวใช้เวลา 2 วินาที และคุณมีเป้าหมายแฝงวินาที คุณต้องโปรไฟล์คำขออนุมาน ทำความเข้าใจว่าการดำเนินการของ TensorFlow และกราฟย่อยของโมเดลของคุณมีส่วนทำให้เกิดเวลาแฝงนั้นมากที่สุดอย่างไร และออกแบบโมเดลของคุณใหม่โดยคำนึงถึงเวลาแฝงในการอนุมานเป็นข้อจำกัดในการออกแบบ
โปรดทราบว่าในขณะที่เวลาแฝงโดยเฉลี่ยของการดำเนินการอนุมานด้วย TensorFlow Serving มักจะไม่ต่ำกว่าการใช้ TensorFlow โดยตรง โดยที่ TensorFlow Serving โดดเด่นจะช่วยลด เวลาแฝงส่วนท้าย ลงสำหรับไคลเอนต์จำนวนมากที่สืบค้นโมเดลที่แตกต่างกันจำนวนมาก ทั้งหมดนี้ใช้ฮาร์ดแวร์พื้นฐานเพื่อเพิ่มปริมาณงานอย่างมีประสิทธิภาพ ขณะเดียวกันก็ใช้ฮาร์ดแวร์พื้นฐานเพื่อเพิ่มปริมาณงานให้สูงสุด .
2) คำขออนุมาน
พื้นผิว API
TensorFlow Serving มี API 2 แบบ (HTTP และ gRPC) ซึ่งทั้งสองแบบใช้ PredictionService API (ยกเว้นเซิร์ฟเวอร์ HTTP ที่ไม่เปิดเผยตำแหน่ง MultiInference ) พื้นผิว API ทั้งสองได้รับการปรับแต่งอย่างดีและเพิ่มเวลาแฝงน้อยที่สุด แต่ในทางปฏิบัติ พื้นผิว gRPC มีประสิทธิภาพมากกว่าเล็กน้อย
วิธีการ API
โดยทั่วไป ขอแนะนำให้ใช้ตำแหน่งข้อมูล Classify และ Regress เนื่องจากยอมรับ tf.Example ซึ่งเป็นนามธรรมระดับที่สูงกว่า อย่างไรก็ตาม ในบางกรณีซึ่งเกิดขึ้นไม่บ่อยนักของคำขอที่มีโครงสร้างขนาดใหญ่ (O(Mb)) ผู้ใช้ที่เชี่ยวชาญอาจพบว่าใช้ PredictRequest และเข้ารหัสข้อความ Protobuf โดยตรงลงใน TensorProto และข้ามการทำให้เป็นอนุกรมและดีซีเรียลไลซ์จาก tf ตัวอย่างแหล่งที่มาของประสิทธิภาพที่เพิ่มขึ้นเล็กน้อย
ขนาดแบทช์
มีสองวิธีหลักที่การแบทช์สามารถช่วยประสิทธิภาพของคุณได้ คุณสามารถกำหนดค่าไคลเอ็นต์ของคุณให้ส่งคำขอเป็นชุดไปยัง TensorFlow Serving หรือคุณอาจส่งคำขอแต่ละรายการและกำหนดค่า TensorFlow Serving ให้รอจนถึงระยะเวลาที่กำหนดไว้ล่วงหน้า และดำเนินการอนุมานคำขอทั้งหมดที่มาถึงในช่วงเวลานั้นในชุดเดียว การกำหนดค่าการแบทช์ประเภทหลังช่วยให้คุณสามารถเข้าถึง TensorFlow Serving ที่ QPS ที่สูงมาก ในขณะเดียวกันก็อนุญาตให้ปรับขนาดทรัพยากรการประมวลผลย่อยเชิงเส้นที่จำเป็นเพื่อตามทันได้ จะมีการอธิบายเพิ่มเติมใน คู่มือการกำหนดค่า และ ชุด README
3) เซิร์ฟเวอร์ (ฮาร์ดแวร์และไบนารี)
ไบนารี TensorFlow Serving ทำการบัญชีฮาร์ดแวร์ที่ใช้งานได้อย่างแม่นยำ ด้วยเหตุนี้ คุณควรหลีกเลี่ยงการเรียกใช้แอปพลิเคชันอื่นที่ใช้การประมวลผลหรือหน่วยความจำมากบนเครื่องเดียวกัน โดยเฉพาะแอปพลิเคชันที่มีการใช้ทรัพยากรแบบไดนามิก
เช่นเดียวกับปริมาณงานประเภทอื่นๆ TensorFlow Serving จะมีประสิทธิภาพมากขึ้นเมื่อใช้งานบนเครื่องที่น้อยลงและใหญ่กว่า (CPU และ RAM มากกว่า) (เช่น Deployment ที่มี replicas ที่ต่ำกว่าในแง่ Kubernetes) นี่เป็นเพราะศักยภาพที่ดีกว่าในการปรับใช้ผู้เช่าหลายรายเพื่อใช้ฮาร์ดแวร์และลดต้นทุนคงที่ (เซิร์ฟเวอร์ RPC, รันไทม์ TensorFlow ฯลฯ)
ตัวเร่งความเร็ว
หากโฮสต์ของคุณมีสิทธิ์เข้าถึงตัวเร่งความเร็ว ตรวจสอบให้แน่ใจว่าคุณได้ใช้โมเดลของคุณเพื่อวางการคำนวณหนาแน่นบนตัวเร่งความเร็ว ซึ่งควรทำโดยอัตโนมัติหากคุณใช้ TensorFlow API ระดับสูง แต่หากคุณสร้างกราฟแบบกำหนดเอง หรือต้องการปักหมุด เฉพาะส่วนของกราฟบนตัวเร่งความเร็วบางตัว คุณอาจต้องวางกราฟย่อยบางตัวบนตัวเร่งความเร็วด้วยตนเอง (เช่น การใช้ with tf.device('/device:GPU:0'): ... )
ซีพียูสมัยใหม่
CPU สมัยใหม่ได้ขยายสถาปัตยกรรมชุดคำสั่ง x86 อย่างต่อเนื่องเพื่อปรับปรุงการรองรับ SIMD (Single Instruction Multiple Data) และคุณสมบัติอื่นๆ ที่สำคัญสำหรับการคำนวณที่มีความหนาแน่นสูง (เช่น การคูณและการบวกในรอบสัญญาณนาฬิกาหนึ่งรอบ) อย่างไรก็ตาม เพื่อที่จะทำงานบนเครื่องที่เก่ากว่าเล็กน้อย TensorFlow และ TensorFlow Serving ถูกสร้างขึ้นโดยมีสมมติฐานที่เรียบง่ายว่าฟีเจอร์ใหม่ล่าสุดเหล่านี้ไม่ได้รับการสนับสนุนจาก CPU ของโฮสต์
Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
หากคุณเห็นรายการบันทึกนี้ (อาจเป็นส่วนขยายที่แตกต่างจาก 2 รายการที่แสดง) ที่การเริ่มต้นใช้งาน TensorFlow Serving นั่นหมายความว่าคุณสามารถสร้าง TensorFlow Serving ขึ้นมาใหม่และกำหนดเป้าหมายแพลตฟอร์มของโฮสต์เฉพาะของคุณและเพลิดเพลินกับประสิทธิภาพที่ดีขึ้น การสร้าง TensorFlow การให้บริการจากแหล่งที่มานั้นค่อนข้างง่ายโดยใช้ Docker และมีบันทึกไว้ ที่นี่
การกำหนดค่าไบนารี
TensorFlow Serving มีปุ่มกำหนดค่าจำนวนหนึ่งที่ควบคุมพฤติกรรมรันไทม์ ซึ่งส่วนใหญ่ตั้งค่าผ่าน แฟล็กบรรทัดคำสั่ง สิ่งเหล่านี้บางส่วน (โดยเฉพาะอย่างยิ่ง tensorflow_intra_op_parallelism และ tensorflow_inter_op_parallelism ) ถูกส่งลงมาเพื่อกำหนดค่ารันไทม์ TensorFlow และมีการกำหนดค่าอัตโนมัติ ซึ่งผู้ใช้ที่เชี่ยวชาญอาจแทนที่ด้วยการทำการทดลองหลายครั้งและค้นหาการกำหนดค่าที่เหมาะสมสำหรับปริมาณงานและสภาพแวดล้อมเฉพาะของตน
อายุการใช้งานของคำขออนุมานที่ให้บริการ TensorFlow
มาดูชีวิตของตัวอย่างต้นแบบของคำขอการอนุมาน TensorFlow Serving กันสั้นๆ เพื่อดูการเดินทางที่คำขอทั่วไปดำเนินไป สำหรับตัวอย่างของเรา เราจะเจาะลึกคำขอการคาดการณ์ที่ได้รับจากพื้นผิว 2.0.0 TensorFlow Serving gRPC API
ขั้นแรกเรามาดูไดอะแกรมลำดับระดับส่วนประกอบ จากนั้นข้ามไปที่โค้ดที่ใช้การโต้ตอบชุดนี้
แผนภาพลำดับ
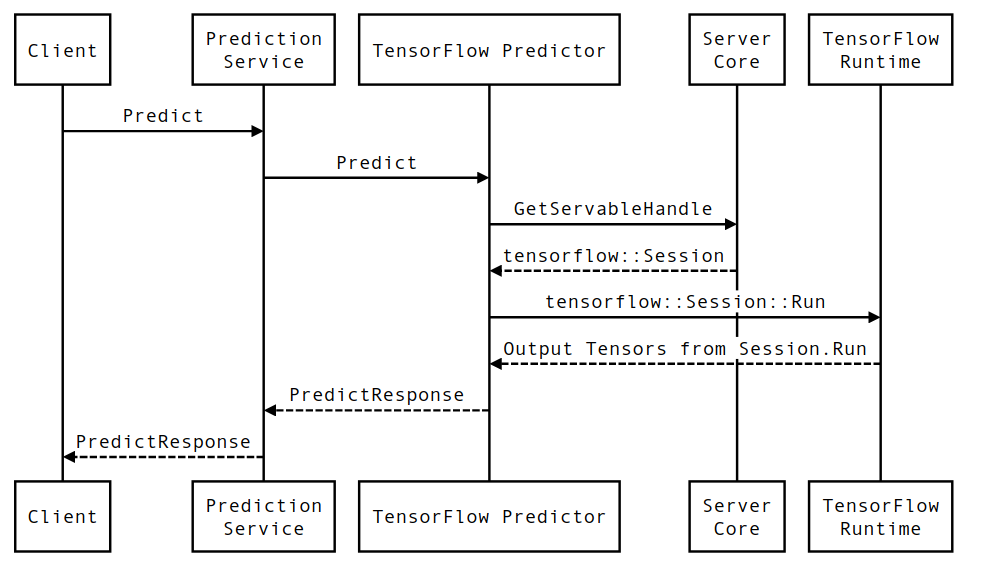
โปรดทราบว่าไคลเอ็นต์เป็นส่วนประกอบของผู้ใช้ ส่วน Prediction Service, Servables และ Server Core เป็นเจ้าของโดย TensorFlow Serving และ TensorFlow Runtime เป็นเจ้าของโดย Core TensorFlow
รายละเอียดลำดับ
-
PredictionServiceImpl::Predictได้รับPredictRequest - เราเรียกใช้
TensorflowPredictor::Predictโดยเผยแพร่กำหนดเวลาคำขอจากคำขอ gRPC (หากมีการตั้งค่าไว้) - ภายใน
TensorflowPredictor::Predictเรา ค้นหา Servable (โมเดล) ที่คำขอต้องการทำการอนุมาน ซึ่งเราดึงข้อมูลเกี่ยวกับ SavedModel และที่สำคัญกว่านั้นคือตัวจัดการไปยังอ็อบเจ็กต์Sessionซึ่งมีกราฟโมเดลอยู่ (อาจเป็นบางส่วน) โหลดแล้ว ออบเจ็กต์ที่ให้บริการนี้ถูกสร้างขึ้นและคอมมิตในหน่วยความจำเมื่อโมเดลถูกโหลดโดย TensorFlow Serving จากนั้นเราจะเรียกใช้ Internal::RunPredict เพื่อดำเนินการทำนาย - ใน
internal::RunPredictหลังจากตรวจสอบและประมวลผลคำขอล่วงหน้าแล้ว เราจะใช้อ็อบเจ็กต์Sessionเพื่อทำการอนุมานโดยใช้การเรียกแบบบล็อกไปยัง Session::Run ณ จุดนี้ เราจะป้อนโค้ดเบสของ core TensorFlow หลังจากSession::Runส่งคืนและเทนเซอร์outputsของเราถูกเติม เรา จะแปลง เอาต์พุตเป็นPredictionResponseและส่งคืนผลลัพธ์ขึ้นไปบน call stack