
หลังจากปรับใช้ TensorFlow Serving และออกคำขอจากไคลเอ็นต์ของคุณ คุณอาจสังเกตเห็นว่าคำขอใช้เวลานานกว่าที่คุณคาดไว้ หรือคุณไม่บรรลุปริมาณการประมวลผลตามที่คุณต้องการ
ในคู่มือนี้ เราจะใช้ Profiler ของ TensorBoard ซึ่งคุณอาจใช้ใน โปรไฟล์การฝึกโมเดล อยู่แล้ว เพื่อติดตามคำขอการอนุมานเพื่อช่วยเราแก้ไขข้อบกพร่องและปรับปรุงประสิทธิภาพการอนุมาน
คุณควรใช้คู่มือนี้ร่วมกับแนวทางปฏิบัติที่ดีที่สุดที่ระบุไว้ใน คู่มือประสิทธิภาพ เพื่อเพิ่มประสิทธิภาพโมเดล คำขอ และอินสแตนซ์ TensorFlow Serving ของคุณ
ภาพรวม
ในระดับสูง เราจะชี้เครื่องมือสร้างโปรไฟล์ของ TensorBoard ไปที่เซิร์ฟเวอร์ gRPC ของ TensorFlow Serving เมื่อเราส่งคำขอการอนุมานไปยัง Tensorflow Serving เราจะใช้ TensorBoard UI ไปพร้อมกันเพื่อขอให้จับร่องรอยของคำขอนี้ เบื้องหลัง TensorBoard จะพูดคุยกับ TensorFlow Serving ผ่าน gRPC และขอให้ส่งรายละเอียดการติดตามอายุการใช้งานของคำขอการอนุมาน จากนั้น TensorBoard จะแสดงภาพกิจกรรมของทุกเธรดบนอุปกรณ์ประมวลผลทุกเครื่อง (โค้ดที่รันอยู่ซึ่งรวมเข้ากับ profiler::TraceMe ) ตลอดอายุการใช้งานของคำขอบน TensorBoard UI เพื่อให้เราใช้งาน
ข้อกำหนดเบื้องต้น
-
Tensorflow>=2.0.0 - TensorBoard (ควรติดตั้งหากติดตั้ง TF ผ่าน
pip) - นักเทียบท่า (ซึ่งเราจะใช้เพื่อดาวน์โหลดและเรียกใช้การแสดง TF>=2.1.0 รูปภาพ)
ทำให้โมเดลใช้งานได้ด้วย TensorFlow Serving
สำหรับตัวอย่างนี้ เราจะใช้ Docker ซึ่งเป็นวิธีที่แนะนำในการปรับใช้ Tensorflow Serving เพื่อโฮสต์โมเดลของเล่นที่คำนวณ f(x) = x / 2 + 2 ที่พบใน พื้นที่เก็บข้อมูล Tensorflow Serving Github
ดาวน์โหลดแหล่งที่มาของ TensorFlow Serving
git clone https://github.com/tensorflow/serving /tmp/serving
cd /tmp/serving
เปิดใช้ TensorFlow Serving ผ่าน Docker และปรับใช้โมเดล half_plus_two
docker pull tensorflow/serving
MODELS_DIR="$(pwd)/tensorflow_serving/servables/tensorflow/testdata"
docker run -it --rm -p 8500:8500 -p 8501:8501 \
-v $MODELS_DIR/saved_model_half_plus_two_cpu:/models/half_plus_two \
-v /tmp/tensorboard:/tmp/tensorboard \
-e MODEL_NAME=half_plus_two \
tensorflow/serving
ในเทอร์มินัลอื่น ให้สอบถามโมเดลเพื่อให้แน่ใจว่ามีการใช้โมเดลอย่างถูกต้อง
curl -d '{"instances": [1.0, 2.0, 5.0]}' \
-X POST http://localhost:8501/v1/models/half_plus_two:predict
# Returns => { "predictions": [2.5, 3.0, 4.5] }
ตั้งค่า Profiler ของ TensorBoard
ในเทอร์มินัลอื่น ให้เปิดเครื่องมือ TensorBoard บนเครื่องของคุณ โดยจัดเตรียมไดเร็กทอรีสำหรับบันทึกเหตุการณ์การติดตามการอนุมานไปที่:
mkdir -p /tmp/tensorboard
tensorboard --logdir /tmp/tensorboard --port 6006
ไปที่ http://localhost:6006/ เพื่อดู TensorBoard UI ใช้เมนูแบบเลื่อนลงที่ด้านบนเพื่อไปยังแท็บโปรไฟล์ คลิกจับภาพโปรไฟล์แล้วระบุที่อยู่ของเซิร์ฟเวอร์ gRPC ของ Tensorflow Serving
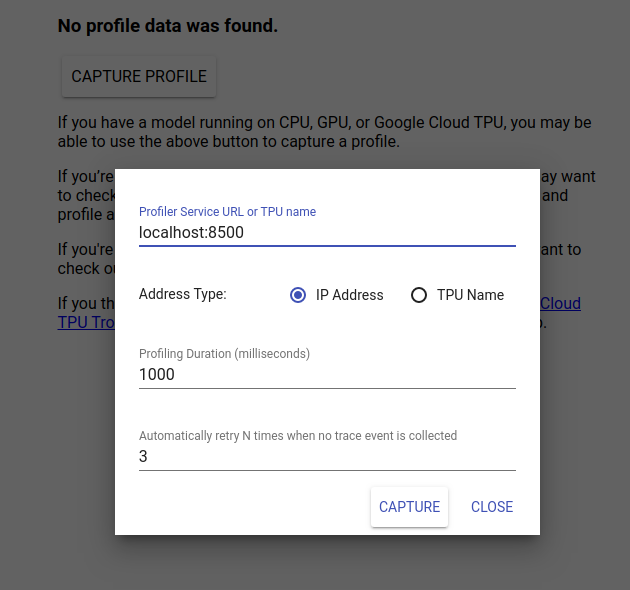
ทันทีที่คุณกด "จับภาพ" TensorBoard จะเริ่มส่งคำขอโปรไฟล์ไปยังเซิร์ฟเวอร์โมเดล ในกล่องโต้ตอบด้านบน คุณสามารถกำหนดทั้งกำหนดเวลาสำหรับคำขอแต่ละรายการและจำนวนครั้งทั้งหมดที่ Tensorboard จะพยายามอีกครั้งหากไม่มีการรวบรวมเหตุการณ์การติดตาม หากคุณกำลังสร้างโปรไฟล์โมเดลราคาแพง คุณอาจต้องการเพิ่มกำหนดเวลาเพื่อให้แน่ใจว่าคำขอโปรไฟล์จะไม่หมดเวลาก่อนที่คำขอการอนุมานจะเสร็จสมบูรณ์
ส่งและโปรไฟล์คำขอการอนุมาน
กด Capture บน TensorBoard UI และส่งคำขอการอนุมานไปยัง TF Serving อย่างรวดเร็วหลังจากนั้น
curl -d '{"instances": [1.0, 2.0, 5.0]}' -X POST \
http://localhost:8501/v1/models/half_plus_two:predict
คุณควรเห็นข้อความ "จับภาพโปรไฟล์เรียบร้อยแล้ว โปรดรีเฟรช" ขนมปังปิ้งปรากฏที่ด้านล่างของหน้าจอ ซึ่งหมายความว่า TensorBoard สามารถดึงเหตุการณ์การติดตามจาก TensorFlow Serving และบันทึกไว้ใน logdir ของคุณ รีเฟรชเพจเพื่อแสดงภาพคำขอการอนุมานด้วย The Profiler's Trace Viewer ดังที่เห็นในส่วนถัดไป
วิเคราะห์การติดตามคำขอการอนุมาน

ตอนนี้คุณสามารถดูได้อย่างง่ายดายว่าการคำนวณใดเกิดขึ้นอันเป็นผลมาจากคำขออนุมานของคุณ คุณสามารถซูมและคลิกสี่เหลี่ยมใดๆ (ติดตามเหตุการณ์) เพื่อดูข้อมูลเพิ่มเติม เช่น เวลาเริ่มต้นและระยะเวลาของกำแพงที่แน่นอน
ในระดับสูง เราเห็นสองเธรดที่เป็นของรันไทม์ TensorFlow และเธรดที่สามที่เป็นของเซิร์ฟเวอร์ REST ซึ่งจัดการการรับคำขอ HTTP และสร้างเซสชัน TensorFlow
เราสามารถซูมเข้าเพื่อดูว่าเกิดอะไรขึ้นภายใน SessionRun

ในเธรดที่สอง เราเห็นการเรียกใช้ ExecutorState::Process เริ่มต้นซึ่งไม่มีการทำงานของ TensorFlow แต่มีการดำเนินการตามขั้นตอนการเริ่มต้น
ในเธรดแรก เราเห็นการเรียกให้อ่านตัวแปรแรก และเมื่อมีตัวแปรตัวที่สองด้วย เราจะดำเนินการคูณและเพิ่มเคอร์เนลตามลำดับ ในที่สุด Executor จะส่งสัญญาณว่าการคำนวณเสร็จสิ้นโดยการเรียก DoneCallback และสามารถปิดเซสชันได้
ขั้นตอนต่อไป
แม้ว่านี่จะเป็นตัวอย่างง่ายๆ แต่คุณสามารถใช้กระบวนการเดียวกันนี้เพื่อสร้างโปรไฟล์โมเดลที่ซับซ้อนมากขึ้นได้ ซึ่งช่วยให้คุณสามารถระบุการดำเนินการที่ช้าหรือปัญหาคอขวดในสถาปัตยกรรมโมเดลของคุณเพื่อปรับปรุงประสิทธิภาพได้
โปรดดู คู่มือ TensorBoard Profiler สำหรับบทช่วยสอนที่สมบูรณ์ยิ่งขึ้นเกี่ยวกับฟีเจอร์ของ Profiler ของ TensorBoard และ คู่มือประสิทธิภาพการให้บริการ TensorFlow เพื่อเรียนรู้เพิ่มเติมเกี่ยวกับการเพิ่มประสิทธิภาพการอนุมาน