
| | |  Xem nguồn trên GitHub Xem nguồn trên GitHub | |
Hướng dẫn này sử dụng máy học để phân loại hoa Iris theo loài. Nó sử dụng TensorFlow để:
- Xây dựng một mô hình,
- Đào tạo mô hình này trên dữ liệu mẫu và
- Sử dụng mô hình để đưa ra dự đoán về dữ liệu chưa biết.
Lập trình TensorFlow
Hướng dẫn này sử dụng các khái niệm TensorFlow cấp cao sau:
- Sử dụng môi trường phát triển thực thi háo hức mặc định của TensorFlow,
- Nhập dữ liệu bằng API tập dữ liệu,
- Xây dựng mô hình và lớp với API Keras của TensorFlow.
Hướng dẫn này có cấu trúc giống như nhiều chương trình TensorFlow:
- Nhập và phân tích cú pháp tập dữ liệu.
- Chọn loại mô hình.
- Huấn luyện mô hình.
- Đánh giá hiệu quả của mô hình.
- Sử dụng mô hình được đào tạo để đưa ra dự đoán.
Thiết lập chương trình
Định cấu hình nhập khẩu
Nhập TensorFlow và các mô-đun Python bắt buộc khác. Theo mặc định, TensorFlow sử dụng việc thực thi háo hức để đánh giá các hoạt động ngay lập tức, trả về các giá trị cụ thể thay vì tạo một đồ thị tính toán được thực thi sau đó. Nếu bạn đã quen với REPL hoặc bảng điều khiển tương tác python , điều này cảm thấy quen thuộc.
import os
import matplotlib.pyplot as plt
import tensorflow as tf
print("TensorFlow version: {}".format(tf.__version__))
print("Eager execution: {}".format(tf.executing_eagerly()))
TensorFlow version: 2.8.0-rc1 Eager execution: True
Vấn đề phân loại Iris
Hãy tưởng tượng bạn là một nhà thực vật học đang tìm kiếm một cách tự động để phân loại từng bông Iris mà bạn tìm thấy. Máy học cung cấp nhiều thuật toán để phân loại hoa một cách thống kê. Ví dụ, một chương trình máy học tinh vi có thể phân loại hoa dựa trên các bức ảnh. Tham vọng của chúng tôi khiêm tốn hơn — chúng tôi sẽ phân loại hoa Iris dựa trên số đo chiều dài và chiều rộng của các đài hoa và cánh hoa của chúng.
Chi Iris có khoảng 300 loài, nhưng chương trình của chúng tôi sẽ chỉ phân loại ba loài sau:
- Iris setosa
- Iris virginica
- Iris versicolor
 |
| Hình 1. Iris setosa (bởi Radomil , CC BY-SA 3.0), Iris versicolor , (bởi Dlanglois , CC BY-SA 3.0) và Iris virginica (bởi Frank Mayfield , CC BY-SA 2.0). |
May mắn thay, ai đó đã tạo ra một tập dữ liệu gồm 120 bông hoa Iris với các số đo đài hoa và cánh hoa. Đây là tập dữ liệu cổ điển phổ biến cho các vấn đề phân loại học máy mới bắt đầu.
Nhập và phân tích cú pháp tập dữ liệu đào tạo
Tải xuống tệp tập dữ liệu và chuyển đổi nó thành một cấu trúc có thể được sử dụng bởi chương trình Python này.
Tải xuống tập dữ liệu
Tải xuống tệp tập dữ liệu đào tạo bằng hàm tf.keras.utils.get_file . Thao tác này trả về đường dẫn tệp của tệp đã tải xuống:
train_dataset_url = "https://storage.googleapis.com/download.tensorflow.org/data/iris_training.csv"
train_dataset_fp = tf.keras.utils.get_file(fname=os.path.basename(train_dataset_url),
origin=train_dataset_url)
print("Local copy of the dataset file: {}".format(train_dataset_fp))
Local copy of the dataset file: /home/kbuilder/.keras/datasets/iris_training.csv
Kiểm tra dữ liệu
Tập dữ liệu này, iris_training.csv , là một tệp văn bản thuần túy lưu trữ dữ liệu dạng bảng được định dạng dưới dạng các giá trị được phân tách bằng dấu phẩy (CSV). Sử dụng lệnh head -n5 để xem qua năm mục đầu tiên:
head -n5 {train_dataset_fp}
120,4,setosa,versicolor,virginica 6.4,2.8,5.6,2.2,2 5.0,2.3,3.3,1.0,1 4.9,2.5,4.5,1.7,2 4.9,3.1,1.5,0.1,0
Từ chế độ xem tập dữ liệu này, hãy lưu ý những điều sau:
- Dòng đầu tiên là tiêu đề chứa thông tin về tập dữ liệu:
- Có tổng cộng 120 ví dụ. Mỗi ví dụ có bốn tính năng và một trong ba tên nhãn có thể có.
- Các hàng tiếp theo là các bản ghi dữ liệu, một ví dụ trên mỗi dòng, trong đó:
- Bốn trường đầu tiên là các tính năng : đây là các đặc điểm của một ví dụ. Ở đây, các trường chứa các số thực thể hiện số đo hoa.
- Cột cuối cùng là nhãn : đây là giá trị chúng ta muốn dự đoán. Đối với tập dữ liệu này, đó là một giá trị nguyên 0, 1 hoặc 2 tương ứng với tên hoa.
Hãy viết điều đó ra mã:
# column order in CSV file
column_names = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species']
feature_names = column_names[:-1]
label_name = column_names[-1]
print("Features: {}".format(feature_names))
print("Label: {}".format(label_name))
Features: ['sepal_length', 'sepal_width', 'petal_length', 'petal_width'] Label: species
Mỗi nhãn được liên kết với tên chuỗi (ví dụ: "setosa"), nhưng học máy thường dựa vào các giá trị số. Các số nhãn được ánh xạ tới một đại diện được đặt tên, chẳng hạn như:
-
0: Iris setosa -
1: Màu mống mắt -
2: Iris virginica
Để biết thêm thông tin về các tính năng và nhãn, hãy xem phần Thuật ngữ ML của Khóa học về sự cố học máy .
class_names = ['Iris setosa', 'Iris versicolor', 'Iris virginica']
Tạo tf.data.Dataset
API tập dữ liệu của TensorFlow xử lý nhiều trường hợp phổ biến để tải dữ liệu vào một mô hình. Đây là một API cấp cao để đọc dữ liệu và chuyển đổi nó thành một biểu mẫu được sử dụng để đào tạo.
Vì tập dữ liệu là tệp văn bản có định dạng CSV, hãy sử dụng hàm tf.data.experimental.make_csv_dataset để phân tích cú pháp dữ liệu thành định dạng phù hợp. Vì hàm này tạo dữ liệu cho các mô hình huấn luyện, hành vi mặc định là xáo trộn dữ liệu ( shuffle=True, shuffle_buffer_size=10000 ) và lặp lại tập dữ liệu mãi mãi ( num_epochs=None ). Chúng tôi cũng đặt tham số batch_size :
batch_size = 32
train_dataset = tf.data.experimental.make_csv_dataset(
train_dataset_fp,
batch_size,
column_names=column_names,
label_name=label_name,
num_epochs=1)
Hàm make_csv_dataset trả về một tf.data.Dataset của các cặp (features, label) , trong đó features đối tượng địa lý là một từ điển: {'feature_name': value}
Các đối tượng Dataset này có thể lặp lại. Hãy xem xét một loạt các tính năng:
features, labels = next(iter(train_dataset))
print(features)
OrderedDict([('sepal_length', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([5. , 7.4, 6. , 7.2, 5.9, 5.8, 5. , 5. , 7.7, 5.7, 6.3, 5.8, 5. ,
4.8, 6.6, 6.3, 5.4, 6.9, 4.8, 6.6, 5.8, 7.7, 6.7, 7.6, 5.5, 6.4,
5.6, 6.4, 4.4, 4.5, 6.5, 6.3], dtype=float32)>), ('sepal_width', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([3.5, 2.8, 2.7, 3.2, 3. , 2.6, 2. , 3.4, 3. , 2.8, 2.3, 2.7, 3.6,
3.1, 2.9, 3.3, 3. , 3.1, 3. , 3. , 4. , 2.6, 3. , 3. , 2.4, 2.7,
2.7, 2.8, 3. , 2.3, 2.8, 2.5], dtype=float32)>), ('petal_length', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([1.6, 6.1, 5.1, 6. , 5.1, 4. , 3.5, 1.6, 6.1, 4.5, 4.4, 5.1, 1.4,
1.6, 4.6, 4.7, 4.5, 5.1, 1.4, 4.4, 1.2, 6.9, 5. , 6.6, 3.7, 5.3,
4.2, 5.6, 1.3, 1.3, 4.6, 5. ], dtype=float32)>), ('petal_width', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([0.6, 1.9, 1.6, 1.8, 1.8, 1.2, 1. , 0.4, 2.3, 1.3, 1.3, 1.9, 0.2,
0.2, 1.3, 1.6, 1.5, 2.3, 0.3, 1.4, 0.2, 2.3, 1.7, 2.1, 1. , 1.9,
1.3, 2.1, 0.2, 0.3, 1.5, 1.9], dtype=float32)>)])
Lưu ý rằng các tính năng tương tự được nhóm lại với nhau hoặc theo nhóm . Các trường của mỗi hàng ví dụ được nối vào mảng tính năng tương ứng. Thay đổi batch_size để đặt số lượng ví dụ được lưu trữ trong các mảng tính năng này.
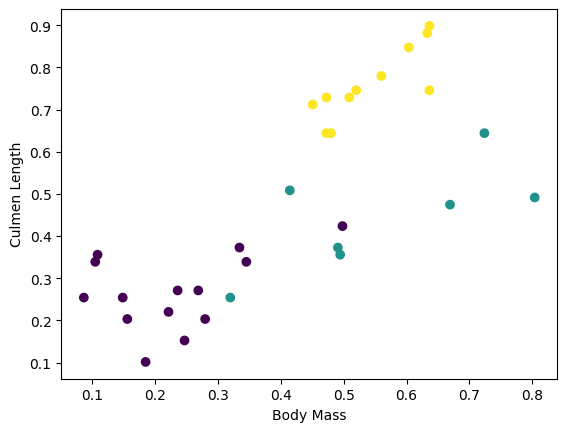
Bạn có thể bắt đầu thấy một số cụm bằng cách vẽ một vài tính năng từ lô:
plt.scatter(features['petal_length'],
features['sepal_length'],
c=labels,
cmap='viridis')
plt.xlabel("Petal length")
plt.ylabel("Sepal length")
plt.show()
Để đơn giản hóa bước xây dựng mô hình, hãy tạo một hàm để đóng gói lại từ điển tính năng thành một mảng duy nhất có hình dạng: (batch_size, num_features) .
Hàm này sử dụng phương thức tf.stack lấy các giá trị từ danh sách các tensor và tạo ra tensor kết hợp ở kích thước được chỉ định:
def pack_features_vector(features, labels):
"""Pack the features into a single array."""
features = tf.stack(list(features.values()), axis=1)
return features, labels
Sau đó, sử dụng phương thức tf.data.Dataset#map để đóng gói các features của từng cặp (features,label) vào tập dữ liệu đào tạo:
train_dataset = train_dataset.map(pack_features_vector)
Phần tử tính năng của Dataset bây giờ là các mảng có hình dạng (batch_size, num_features) . Hãy xem xét một số ví dụ đầu tiên:
features, labels = next(iter(train_dataset))
print(features[:5])
tf.Tensor( [[4.9 3. 1.4 0.2] [6.1 3. 4.9 1.8] [6.1 2.6 5.6 1.4] [6.9 3.2 5.7 2.3] [6.7 3.1 4.4 1.4]], shape=(5, 4), dtype=float32)
Chọn loại mô hình
Tại sao mô hình?
Mô hình là mối quan hệ giữa các tính năng và nhãn. Đối với bài toán phân loại Iris, mô hình xác định mối quan hệ giữa số đo đài hoa và cánh hoa và loài Iris dự đoán. Một số mô hình đơn giản có thể được mô tả bằng một vài dòng đại số, nhưng các mô hình học máy phức tạp có một số lượng lớn các tham số rất khó để tóm tắt.
Bạn có thể xác định mối quan hệ giữa bốn đặc điểm và loài Iris mà không sử dụng máy học không? Đó là, bạn có thể sử dụng các kỹ thuật lập trình truyền thống (ví dụ, rất nhiều câu lệnh điều kiện) để tạo một mô hình không? Có lẽ — nếu bạn đã phân tích tập dữ liệu đủ lâu để xác định mối quan hệ giữa các phép đo của cánh hoa và lá đài đối với một loài cụ thể. Và điều này trở nên khó khăn - có thể là không thể - trên các bộ dữ liệu phức tạp hơn. Một cách tiếp cận máy học tốt sẽ xác định mô hình cho bạn . Nếu bạn cung cấp đủ các ví dụ đại diện vào loại mô hình học máy phù hợp, chương trình sẽ tìm ra các mối quan hệ cho bạn.
Chọn mô hình
Chúng ta cần chọn loại mô hình để đào tạo. Có rất nhiều loại mô hình và chọn một mô hình tốt cần có kinh nghiệm. Hướng dẫn này sử dụng mạng nơ-ron để giải quyết vấn đề phân loại Iris. Mạng nơron có thể tìm thấy các mối quan hệ phức tạp giữa các đối tượng địa lý và nhãn. Nó là một biểu đồ có cấu trúc cao, được tổ chức thành một hoặc nhiều lớp ẩn . Mỗi lớp ẩn bao gồm một hoặc nhiều nơ-ron . Có một số loại mạng nơ-ron và chương trình này sử dụng một mạng nơ-ron dày đặc hoặc được kết nối đầy đủ : các nơ-ron trong một lớp nhận các kết nối đầu vào từ mọi nơ-ron trong lớp trước đó. Ví dụ, Hình 2 minh họa một mạng nơ-ron dày đặc bao gồm một lớp đầu vào, hai lớp ẩn và một lớp đầu ra:
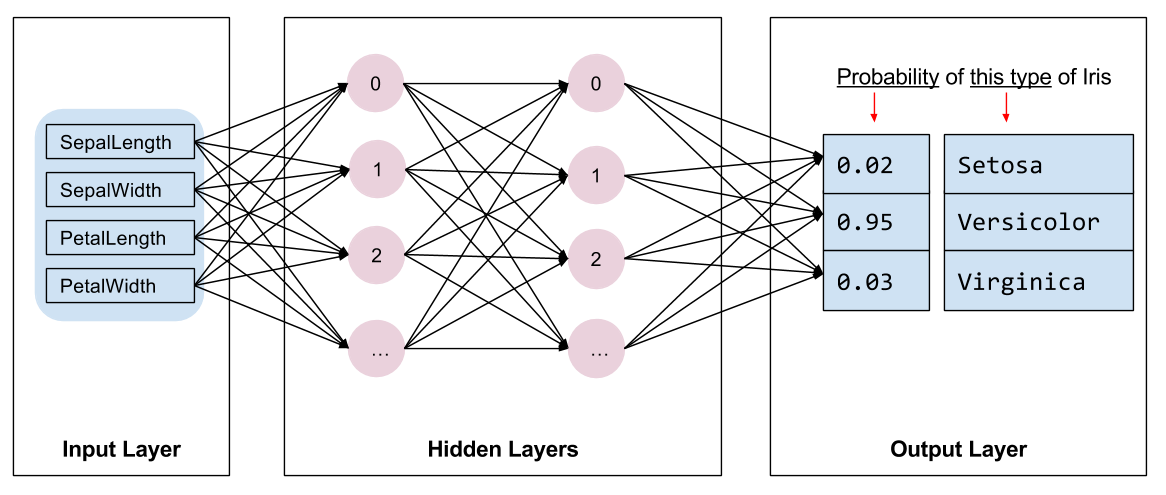 |
| Hình 2. Một mạng nơ-ron với các tính năng, lớp ẩn và dự đoán. |
Khi mô hình từ Hình 2 được huấn luyện và cung cấp một ví dụ không gắn nhãn, nó sẽ đưa ra ba dự đoán: khả năng bông hoa này là loài Iris đã cho. Dự đoán này được gọi là suy luận . Đối với ví dụ này, tổng các dự đoán đầu ra là 1,0. Trong Hình 2, dự đoán này được chia thành: 0.02 cho Iris setosa , 0.95 cho Iris versicolor và 0.03 cho Iris virginica . Điều này có nghĩa là mô hình dự đoán - với xác suất 95% - rằng một bông hoa mẫu không được dán nhãn là một loài hoa có màu Iris .
Tạo mô hình bằng Keras
API TensorFlow tf.keras là cách ưa thích để tạo các mô hình và lớp. Điều này giúp bạn dễ dàng xây dựng mô hình và thử nghiệm trong khi Keras xử lý sự phức tạp của việc kết nối mọi thứ với nhau.
Mô hình tf.keras.Sequential là một chồng các lớp tuyến tính. Hàm tạo của nó lấy một danh sách các cá thể lớp, trong trường hợp này là hai lớp tf.keras.layers.Dense với 10 nút mỗi lớp và một lớp đầu ra với 3 nút đại diện cho các dự đoán nhãn của chúng ta. Tham số input_shape của lớp đầu tiên tương ứng với số lượng tính năng từ tập dữ liệu và được yêu cầu:
model = tf.keras.Sequential([
tf.keras.layers.Dense(10, activation=tf.nn.relu, input_shape=(4,)), # input shape required
tf.keras.layers.Dense(10, activation=tf.nn.relu),
tf.keras.layers.Dense(3)
])
Hàm kích hoạt xác định hình dạng đầu ra của mỗi nút trong lớp. Những điểm phi tuyến tính này rất quan trọng — nếu không có chúng, mô hình sẽ tương đương với một lớp duy nhất. Có nhiều tf.keras.activations , nhưng ReLU là phổ biến cho các lớp ẩn.
Số lượng lớp ẩn và nơ-ron lý tưởng phụ thuộc vào vấn đề và tập dữ liệu. Giống như nhiều khía cạnh của học máy, việc chọn ra hình dạng tốt nhất của mạng nơ-ron đòi hỏi sự kết hợp giữa kiến thức và thử nghiệm. Theo quy luật chung, việc tăng số lượng lớp ẩn và tế bào thần kinh thường tạo ra một mô hình mạnh mẽ hơn, đòi hỏi nhiều dữ liệu hơn để đào tạo hiệu quả.
Sử dụng mô hình
Chúng ta hãy xem nhanh những gì mô hình này làm với một loạt các tính năng:
predictions = model(features)
predictions[:5]
<tf.Tensor: shape=(5, 3), dtype=float32, numpy=
array([[-4.0874639e+00, 1.5199981e-03, -9.9991310e-01],
[-5.3246369e+00, -1.8366380e-01, -1.3161827e+00],
[-5.1154275e+00, -2.8129923e-01, -1.3305402e+00],
[-6.0694785e+00, -2.1251860e-01, -1.5091233e+00],
[-5.6730523e+00, -1.4321266e-01, -1.4437559e+00]], dtype=float32)>
Ở đây, mỗi ví dụ trả về một logit cho mỗi lớp.
Để chuyển đổi các logits này thành xác suất cho mỗi lớp, hãy sử dụng hàm softmax :
tf.nn.softmax(predictions[:5])
<tf.Tensor: shape=(5, 3), dtype=float32, numpy=
array([[0.01210616, 0.7224865 , 0.26540732],
[0.00440638, 0.75297093, 0.24262273],
[0.00585618, 0.7362918 , 0.25785193],
[0.00224076, 0.7835035 , 0.21425581],
[0.00310779, 0.7834839 , 0.21340834]], dtype=float32)>
Lấy tf.argmax giữa các lớp cho chúng ta chỉ số lớp được dự đoán. Tuy nhiên, mô hình vẫn chưa được đào tạo, vì vậy đây không phải là những dự đoán tốt:
print("Prediction: {}".format(tf.argmax(predictions, axis=1)))
print(" Labels: {}".format(labels))
Prediction: [1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1]
Labels: [0 2 2 2 1 1 0 1 1 2 2 1 0 2 2 2 1 0 2 2 1 0 2 1 2 0 1 1 2 2 1 2]
Đào tạo mô hình
Huấn luyện là giai đoạn học máy khi mô hình được tối ưu hóa dần dần, hoặc mô hình học tập dữ liệu. Mục tiêu là tìm hiểu đủ về cấu trúc của tập dữ liệu đào tạo để đưa ra dự đoán về dữ liệu không nhìn thấy. Nếu bạn tìm hiểu quá nhiều về tập dữ liệu đào tạo, thì các dự đoán chỉ hoạt động đối với dữ liệu mà nó đã thấy và sẽ không thể tổng quát hóa được. Vấn đề này được gọi là overfitting — nó giống như ghi nhớ các câu trả lời thay vì hiểu cách giải quyết một vấn đề.
Bài toán phân loại Iris là một ví dụ về học máy có giám sát : mô hình được đào tạo từ các ví dụ có chứa nhãn. Trong học máy không giám sát , các ví dụ không chứa nhãn. Thay vào đó, mô hình thường tìm thấy các mẫu trong số các tính năng.
Xác định hàm mất mát và độ dốc
Cả hai giai đoạn đào tạo và đánh giá đều cần tính toán mức độ hao hụt của mô hình. Điều này đo lường mức độ dự đoán của một mô hình khác với nhãn mong muốn, nói cách khác, mô hình hoạt động tồi tệ như thế nào. Chúng tôi muốn giảm thiểu hoặc tối ưu hóa giá trị này.
Mô hình của chúng tôi sẽ tính toán tổn thất của nó bằng cách sử dụng hàm tf.keras.losses.SparseCategoricalCrossentropy , hàm này nhận các dự đoán xác suất lớp của mô hình và nhãn mong muốn và trả về tổn thất trung bình trên các ví dụ.
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
def loss(model, x, y, training):
# training=training is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
y_ = model(x, training=training)
return loss_object(y_true=y, y_pred=y_)
l = loss(model, features, labels, training=False)
print("Loss test: {}".format(l))
Loss test: 1.6059828996658325
Sử dụng ngữ cảnh tf.GradientTape để tính toán độ dốc được sử dụng để tối ưu hóa mô hình của bạn:
def grad(model, inputs, targets):
with tf.GradientTape() as tape:
loss_value = loss(model, inputs, targets, training=True)
return loss_value, tape.gradient(loss_value, model.trainable_variables)
Tạo một trình tối ưu hóa
Trình tối ưu hóa áp dụng các gradient được tính toán cho các biến của mô hình để giảm thiểu hàm loss . Bạn có thể coi hàm mất mát như một bề mặt cong (xem Hình 3) và chúng tôi muốn tìm điểm thấp nhất của nó bằng cách đi vòng quanh. Các gradient hướng theo hướng đi lên dốc nhất — vì vậy chúng ta sẽ đi theo hướng ngược lại và di chuyển xuống đồi. Bằng cách tính toán lặp đi lặp lại tổn thất và độ dốc cho từng lô, chúng tôi sẽ điều chỉnh mô hình trong quá trình đào tạo. Dần dần, mô hình sẽ tìm ra sự kết hợp tốt nhất giữa trọng lượng và độ lệch để giảm thiểu sự mất mát. Và tổn thất càng thấp, dự đoán của mô hình càng tốt.
 |
| Hình 3. Các thuật toán tối ưu hóa được hiển thị theo thời gian trong không gian 3D. (Nguồn: Lớp Stanford CS231n , Giấy phép MIT, Tín dụng hình ảnh: Alec Radford ) |
TensorFlow có nhiều thuật toán tối ưu hóa có sẵn để đào tạo. Mô hình này sử dụng tf.keras.optimizers.SGD thực hiện thuật toán giảm độ dốc ngẫu nhiên (SGD). learning_rate đặt kích thước bước cần thực hiện cho mỗi lần lặp xuống dưới. Đây là một siêu thông số mà bạn sẽ thường điều chỉnh để đạt được kết quả tốt hơn.
Hãy thiết lập trình tối ưu hóa:
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
Chúng tôi sẽ sử dụng điều này để tính toán một bước tối ưu hóa duy nhất:
loss_value, grads = grad(model, features, labels)
print("Step: {}, Initial Loss: {}".format(optimizer.iterations.numpy(),
loss_value.numpy()))
optimizer.apply_gradients(zip(grads, model.trainable_variables))
print("Step: {}, Loss: {}".format(optimizer.iterations.numpy(),
loss(model, features, labels, training=True).numpy()))
Step: 0, Initial Loss: 1.6059828996658325 Step: 1, Loss: 1.3759253025054932
Vòng lặp đào tạo
Với tất cả các mảnh ở vị trí, mô hình đã sẵn sàng để đào tạo! Vòng lặp đào tạo cung cấp các ví dụ về tập dữ liệu vào mô hình để giúp mô hình đưa ra các dự đoán tốt hơn. Khối mã sau đây thiết lập các bước đào tạo sau:
- Lặp lại từng kỷ nguyên . Một kỷ nguyên là một lần đi qua tập dữ liệu.
- Trong một khoảng thời gian, hãy lặp lại từng ví dụ trong
Datasetđào tạo lấy các tính năng của nó (x) và nhãn (y). - Sử dụng các tính năng của ví dụ, đưa ra dự đoán và so sánh với nhãn. Đo lường mức độ không chính xác của dự đoán và sử dụng nó để tính toán độ mất và độ dốc của mô hình.
- Sử dụng trình
optimizerđể cập nhật các biến của mô hình. - Theo dõi một số thống kê để dễ hình dung.
- Lặp lại cho mỗi kỷ nguyên.
Biến num_epochs là số lần lặp qua tập hợp dữ liệu. Theo trực giác, đào tạo một mô hình lâu hơn không đảm bảo một mô hình tốt hơn. num_epochs là một siêu tham số mà bạn có thể điều chỉnh. Việc chọn đúng số thường đòi hỏi cả kinh nghiệm và thử nghiệm:
## Note: Rerunning this cell uses the same model variables
# Keep results for plotting
train_loss_results = []
train_accuracy_results = []
num_epochs = 201
for epoch in range(num_epochs):
epoch_loss_avg = tf.keras.metrics.Mean()
epoch_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()
# Training loop - using batches of 32
for x, y in train_dataset:
# Optimize the model
loss_value, grads = grad(model, x, y)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
# Track progress
epoch_loss_avg.update_state(loss_value) # Add current batch loss
# Compare predicted label to actual label
# training=True is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
epoch_accuracy.update_state(y, model(x, training=True))
# End epoch
train_loss_results.append(epoch_loss_avg.result())
train_accuracy_results.append(epoch_accuracy.result())
if epoch % 50 == 0:
print("Epoch {:03d}: Loss: {:.3f}, Accuracy: {:.3%}".format(epoch,
epoch_loss_avg.result(),
epoch_accuracy.result()))
Epoch 000: Loss: 1.766, Accuracy: 43.333% Epoch 050: Loss: 0.579, Accuracy: 71.667% Epoch 100: Loss: 0.398, Accuracy: 82.500% Epoch 150: Loss: 0.307, Accuracy: 92.500% Epoch 200: Loss: 0.224, Accuracy: 95.833%
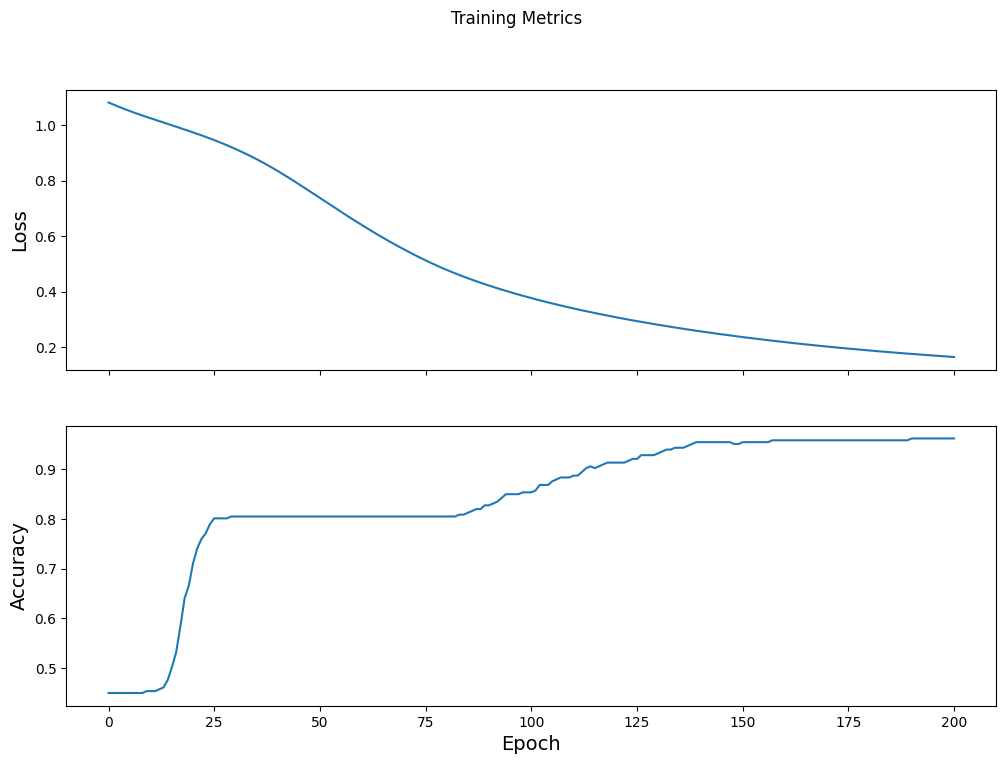
Hình dung hàm mất mát theo thời gian
Mặc dù việc in ra tiến trình đào tạo của mô hình là hữu ích, nhưng việc xem tiến trình này thường hữu ích hơn . TensorBoard là một công cụ trực quan hóa đẹp mắt được đóng gói với TensorFlow, nhưng chúng ta có thể tạo các biểu đồ cơ bản bằng cách sử dụng mô-đun matplotlib .
Việc diễn giải các biểu đồ này cần một số kinh nghiệm, nhưng bạn thực sự muốn thấy khoản lỗ giảm xuống và độ chính xác tăng lên:
fig, axes = plt.subplots(2, sharex=True, figsize=(12, 8))
fig.suptitle('Training Metrics')
axes[0].set_ylabel("Loss", fontsize=14)
axes[0].plot(train_loss_results)
axes[1].set_ylabel("Accuracy", fontsize=14)
axes[1].set_xlabel("Epoch", fontsize=14)
axes[1].plot(train_accuracy_results)
plt.show()
Đánh giá hiệu quả của mô hình
Bây giờ mô hình đã được đào tạo, chúng tôi có thể nhận được một số thống kê về hiệu suất của nó.
Đánh giá có nghĩa là xác định mức độ hiệu quả của mô hình đưa ra các dự đoán. Để xác định hiệu quả của mô hình trong việc phân loại Iris, hãy chuyển một số phép đo đài hoa và cánh hoa cho mô hình và yêu cầu mô hình dự đoán loài Iris mà chúng đại diện. Sau đó, so sánh các dự đoán của mô hình với nhãn thực tế. Ví dụ: một mô hình đã chọn đúng loài trên một nửa số ví dụ đầu vào có độ chính xác là 0.5 . Hình 4 cho thấy một mô hình hiệu quả hơn một chút, nhận được 4 trong số 5 dự đoán chính xác với độ chính xác 80%:
| Các tính năng ví dụ | Nhãn mác | Dự đoán mô hình | |||
|---|---|---|---|---|---|
| 5.9 | 3.0 | 4.3 | 1,5 | 1 | 1 |
| 6.9 | 3.1 | 5,4 | 2.1 | 2 | 2 |
| 5.1 | 3,3 | 1,7 | 0,5 | 0 | 0 |
| 6.0 | 3,4 | 4,5 | 1,6 | 1 | 2 |
| 5.5 | 2,5 | 4.0 | 1,3 | 1 | 1 |
| Hình 4. Một bộ phân loại Iris có độ chính xác 80%. | |||||
Thiết lập tập dữ liệu thử nghiệm
Đánh giá mô hình tương tự như đào tạo mô hình. Sự khác biệt lớn nhất là các ví dụ đến từ một tập thử nghiệm riêng biệt chứ không phải tập huấn luyện. Để đánh giá một cách công bằng hiệu quả của một mô hình, các ví dụ được sử dụng để đánh giá một mô hình phải khác với các ví dụ được sử dụng để đào tạo mô hình.
Thiết lập cho Dataset kiểm tra tương tự như thiết lập cho Dataset huấn luyện. Tải xuống tệp văn bản CSV và phân tích cú pháp các giá trị đó, sau đó xáo trộn một chút:
test_url = "https://storage.googleapis.com/download.tensorflow.org/data/iris_test.csv"
test_fp = tf.keras.utils.get_file(fname=os.path.basename(test_url),
origin=test_url)
test_dataset = tf.data.experimental.make_csv_dataset(
test_fp,
batch_size,
column_names=column_names,
label_name='species',
num_epochs=1,
shuffle=False)
test_dataset = test_dataset.map(pack_features_vector)
Đánh giá mô hình trên tập dữ liệu thử nghiệm
Không giống như giai đoạn đào tạo, mô hình chỉ đánh giá một kỷ nguyên duy nhất của dữ liệu thử nghiệm. Trong ô mã sau, chúng tôi lặp lại từng ví dụ trong bộ thử nghiệm và so sánh dự đoán của mô hình với nhãn thực tế. Điều này được sử dụng để đo độ chính xác của mô hình trên toàn bộ bộ thử nghiệm:
test_accuracy = tf.keras.metrics.Accuracy()
for (x, y) in test_dataset:
# training=False is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
logits = model(x, training=False)
prediction = tf.argmax(logits, axis=1, output_type=tf.int32)
test_accuracy(prediction, y)
print("Test set accuracy: {:.3%}".format(test_accuracy.result()))
Test set accuracy: 96.667%
Ví dụ, chúng ta có thể thấy trên lô cuối cùng, mô hình thường đúng:
tf.stack([y,prediction],axis=1)
<tf.Tensor: shape=(30, 2), dtype=int32, numpy=
array([[1, 1],
[2, 2],
[0, 0],
[1, 1],
[1, 1],
[1, 1],
[0, 0],
[2, 2],
[1, 1],
[2, 2],
[2, 2],
[0, 0],
[2, 2],
[1, 1],
[1, 1],
[0, 0],
[1, 1],
[0, 0],
[0, 0],
[2, 2],
[0, 0],
[1, 1],
[2, 2],
[1, 2],
[1, 1],
[1, 1],
[0, 0],
[1, 1],
[2, 2],
[1, 1]], dtype=int32)>
Sử dụng mô hình được đào tạo để đưa ra dự đoán
Chúng tôi đã đào tạo một mô hình và "chứng minh" rằng nó tốt - nhưng không hoàn hảo - trong việc phân loại các loài Iris. Bây giờ, hãy sử dụng mô hình đã đào tạo để đưa ra một số dự đoán về các ví dụ không được gắn nhãn ; nghĩa là, trên các ví dụ có chứa các tính năng nhưng không chứa nhãn.
Trong thực tế, các ví dụ không được gắn nhãn có thể đến từ nhiều nguồn khác nhau bao gồm ứng dụng, tệp CSV và nguồn cấp dữ liệu. Hiện tại, chúng tôi sẽ cung cấp thủ công ba ví dụ không được gắn nhãn để dự đoán nhãn của chúng. Nhớ lại, các số nhãn được ánh xạ tới một biểu diễn được đặt tên là:
-
0: Iris setosa -
1: Màu mống mắt -
2: Iris virginica
predict_dataset = tf.convert_to_tensor([
[5.1, 3.3, 1.7, 0.5,],
[5.9, 3.0, 4.2, 1.5,],
[6.9, 3.1, 5.4, 2.1]
])
# training=False is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
predictions = model(predict_dataset, training=False)
for i, logits in enumerate(predictions):
class_idx = tf.argmax(logits).numpy()
p = tf.nn.softmax(logits)[class_idx]
name = class_names[class_idx]
print("Example {} prediction: {} ({:4.1f}%)".format(i, name, 100*p))
Example 0 prediction: Iris setosa (97.6%) Example 1 prediction: Iris versicolor (82.0%) Example 2 prediction: Iris virginica (56.4%)