
| | |  Ver fonte no GitHub Ver fonte no GitHub | |
Visão geral
Este tutorial demonstra o aumento de dados: uma técnica para aumentar a diversidade de seu conjunto de treinamento aplicando transformações aleatórias (mas realistas), como rotação de imagem.
Você aprenderá como aplicar o aumento de dados de duas maneiras:
- Use as camadas de pré-processamento Keras, como
tf.keras.layers.Resizing,tf.keras.layers.Rescaling,tf.keras.layers.RandomFlipetf.keras.layers.RandomRotation. - Use os métodos
tf.image, comotf.image.flip_left_right,tf.image.rgb_to_grayscale,tf.image.adjust_brightness,tf.image.central_cropetf.image.stateless_random*.
Configurar
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow.keras import layers
Baixar um conjunto de dados
Este tutorial usa o conjunto de dados tf_flowers . Por conveniência, baixe o conjunto de dados usando TensorFlow Datasets . Se você quiser aprender sobre outras formas de importar dados, confira o tutorial de carregamento de imagens .
(train_ds, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
O conjunto de dados de flores tem cinco classes.
num_classes = metadata.features['label'].num_classes
print(num_classes)
5
Vamos recuperar uma imagem do conjunto de dados e usá-la para demonstrar o aumento de dados.
get_label_name = metadata.features['label'].int2str
image, label = next(iter(train_ds))
_ = plt.imshow(image)
_ = plt.title(get_label_name(label))
2022-01-26 05:09:18.712477: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.

Usar camadas de pré-processamento Keras
Redimensionando e redimensionando
Você pode usar as camadas de pré-processamento Keras para redimensionar suas imagens para uma forma consistente (com tf.keras.layers.Resizing ) e para redimensionar valores de pixel (com tf.keras.layers.Rescaling ).
IMG_SIZE = 180
resize_and_rescale = tf.keras.Sequential([
layers.Resizing(IMG_SIZE, IMG_SIZE),
layers.Rescaling(1./255)
])
Você pode visualizar o resultado da aplicação dessas camadas a uma imagem.
result = resize_and_rescale(image)
_ = plt.imshow(result)
Verifique se os pixels estão no intervalo [0, 1] :
print("Min and max pixel values:", result.numpy().min(), result.numpy().max())
Min and max pixel values: 0.0 1.0
Aumento de dados
Você também pode usar as camadas de pré-processamento Keras para aumento de dados, como tf.keras.layers.RandomFlip e tf.keras.layers.RandomRotation .
Vamos criar algumas camadas de pré-processamento e aplicá-las repetidamente na mesma imagem.
data_augmentation = tf.keras.Sequential([
layers.RandomFlip("horizontal_and_vertical"),
layers.RandomRotation(0.2),
])
# Add the image to a batch.
image = tf.expand_dims(image, 0)
plt.figure(figsize=(10, 10))
for i in range(9):
augmented_image = data_augmentation(image)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_image[0])
plt.axis("off")
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

Há uma variedade de camadas de pré-processamento que você pode usar para aumento de dados, incluindo tf.keras.layers.RandomContrast , tf.keras.layers.RandomCrop , tf.keras.layers.RandomZoom e outras.
Duas opções para usar as camadas de pré-processamento Keras
Existem duas maneiras de usar essas camadas de pré-processamento, com importantes compensações.
Opção 1: tornar as camadas de pré-processamento parte do seu modelo
model = tf.keras.Sequential([
# Add the preprocessing layers you created earlier.
resize_and_rescale,
data_augmentation,
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
# Rest of your model.
])
Há dois pontos importantes a serem observados neste caso:
O aumento de dados será executado no dispositivo, de forma síncrona com o restante de suas camadas e se beneficiará da aceleração da GPU.
Quando você exporta seu modelo usando
model.save, as camadas de pré-processamento serão salvas junto com o restante do seu modelo. Se você implantar esse modelo posteriormente, ele padronizará automaticamente as imagens (de acordo com a configuração de suas camadas). Isso pode poupar você do esforço de ter que reimplementar essa lógica do lado do servidor.
Opção 2: aplique as camadas de pré-processamento ao seu conjunto de dados
aug_ds = train_ds.map(
lambda x, y: (resize_and_rescale(x, training=True), y))
Com essa abordagem, você usa Dataset.map para criar um conjunto de dados que produz lotes de imagens aumentadas. Nesse caso:
- O aumento de dados acontecerá de forma assíncrona na CPU e não é bloqueante. Você pode sobrepor o treinamento do seu modelo na GPU com o pré-processamento de dados, usando
Dataset.prefetch, mostrado abaixo. - Nesse caso, as camadas de pré-processamento não serão exportadas com o modelo quando você chamar
Model.save. Você precisará anexá-los ao seu modelo antes de salvá-lo ou reimplementá-los no lado do servidor. Após o treinamento, você pode anexar as camadas de pré-processamento antes da exportação.
Você pode encontrar um exemplo da primeira opção no tutorial Classificação de imagens . Vamos demonstrar a segunda opção aqui.
Aplique as camadas de pré-processamento aos conjuntos de dados
Configure os conjuntos de dados de treinamento, validação e teste com as camadas de pré-processamento Keras que você criou anteriormente. Você também configurará os conjuntos de dados para desempenho, usando leituras paralelas e pré-busca em buffer para gerar lotes do disco sem bloqueio de E/S. (Saiba mais sobre o desempenho do conjunto de dados no guia Melhor desempenho com a API tf.data .)
batch_size = 32
AUTOTUNE = tf.data.AUTOTUNE
def prepare(ds, shuffle=False, augment=False):
# Resize and rescale all datasets.
ds = ds.map(lambda x, y: (resize_and_rescale(x), y),
num_parallel_calls=AUTOTUNE)
if shuffle:
ds = ds.shuffle(1000)
# Batch all datasets.
ds = ds.batch(batch_size)
# Use data augmentation only on the training set.
if augment:
ds = ds.map(lambda x, y: (data_augmentation(x, training=True), y),
num_parallel_calls=AUTOTUNE)
# Use buffered prefetching on all datasets.
return ds.prefetch(buffer_size=AUTOTUNE)
train_ds = prepare(train_ds, shuffle=True, augment=True)
val_ds = prepare(val_ds)
test_ds = prepare(test_ds)
Treinar um modelo
Para completar, agora você treinará um modelo usando os conjuntos de dados que acabou de preparar.
O modelo Sequencial consiste em três blocos de convolução ( tf.keras.layers.Conv2D ) com uma camada de agrupamento máximo ( tf.keras.layers.MaxPooling2D ) em cada um deles. Há uma camada totalmente conectada ( tf.keras.layers.Dense ) com 128 unidades em cima dela que é ativada por uma função de ativação ReLU ( 'relu' ). Este modelo não foi ajustado para precisão (o objetivo é mostrar a mecânica).
model = tf.keras.Sequential([
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(num_classes)
])
Escolha o otimizador tf.keras.optimizers.Adam e a função de perda tf.keras.losses.SparseCategoricalCrossentropy . Para visualizar a precisão do treinamento e da validação para cada época de treinamento, passe o argumento de metrics para Model.compile .
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
Treine por algumas épocas:
epochs=5
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
Epoch 1/5 92/92 [==============================] - 13s 110ms/step - loss: 1.2768 - accuracy: 0.4622 - val_loss: 1.0929 - val_accuracy: 0.5640 Epoch 2/5 92/92 [==============================] - 3s 25ms/step - loss: 1.0579 - accuracy: 0.5749 - val_loss: 0.9711 - val_accuracy: 0.6349 Epoch 3/5 92/92 [==============================] - 3s 26ms/step - loss: 0.9677 - accuracy: 0.6291 - val_loss: 0.9764 - val_accuracy: 0.6431 Epoch 4/5 92/92 [==============================] - 3s 25ms/step - loss: 0.9150 - accuracy: 0.6468 - val_loss: 0.8906 - val_accuracy: 0.6431 Epoch 5/5 92/92 [==============================] - 3s 25ms/step - loss: 0.8636 - accuracy: 0.6604 - val_loss: 0.8233 - val_accuracy: 0.6730
loss, acc = model.evaluate(test_ds)
print("Accuracy", acc)
12/12 [==============================] - 5s 14ms/step - loss: 0.7922 - accuracy: 0.6948 Accuracy 0.6948229074478149
Aumento de dados personalizados
Você também pode criar camadas de aumento de dados personalizadas.
Esta seção do tutorial mostra duas maneiras de fazer isso:
- Primeiro, você criará uma camada
tf.keras.layers.Lambda. Esta é uma boa maneira de escrever código conciso. - Em seguida, você escreverá uma nova camada via subclassing , o que lhe dará mais controle.
Ambas as camadas inverterão aleatoriamente as cores em uma imagem, de acordo com alguma probabilidade.
def random_invert_img(x, p=0.5):
if tf.random.uniform([]) < p:
x = (255-x)
else:
x
return x
def random_invert(factor=0.5):
return layers.Lambda(lambda x: random_invert_img(x, factor))
random_invert = random_invert()
plt.figure(figsize=(10, 10))
for i in range(9):
augmented_image = random_invert(image)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_image[0].numpy().astype("uint8"))
plt.axis("off")
2022-01-26 05:09:53.045204: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045264: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045312: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045369: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045418: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045467: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045511: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.047630: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module

Em seguida, implemente uma camada personalizada por subclasses :
class RandomInvert(layers.Layer):
def __init__(self, factor=0.5, **kwargs):
super().__init__(**kwargs)
self.factor = factor
def call(self, x):
return random_invert_img(x)
_ = plt.imshow(RandomInvert()(image)[0])

Ambas as camadas podem ser usadas conforme descrito nas opções 1 e 2 acima.
Usando tf.image
Os utilitários de pré-processamento Keras acima são convenientes. Mas, para um controle mais preciso, você pode escrever seus próprios pipelines ou camadas de aumento de dados usando tf.data e tf.image . (Você também pode conferir Imagem de complementos do TensorFlow: Operations and TensorFlow I/O: Color Space Conversions .)
Como o conjunto de dados de flores foi configurado anteriormente com aumento de dados, vamos reimportá-lo para começar do zero:
(train_ds, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
Recupere uma imagem para trabalhar:
image, label = next(iter(train_ds))
_ = plt.imshow(image)
_ = plt.title(get_label_name(label))
2022-01-26 05:09:59.918847: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.

Vamos usar a seguinte função para visualizar e comparar as imagens originais e aumentadas lado a lado:
def visualize(original, augmented):
fig = plt.figure()
plt.subplot(1,2,1)
plt.title('Original image')
plt.imshow(original)
plt.subplot(1,2,2)
plt.title('Augmented image')
plt.imshow(augmented)
Aumento de dados
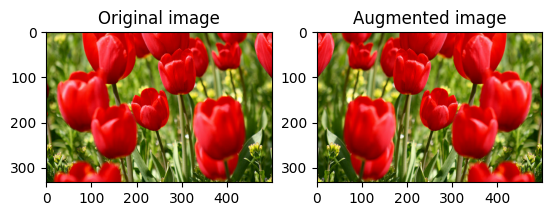
Virar uma imagem
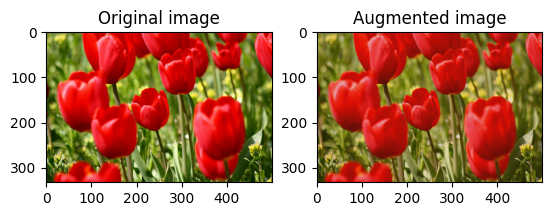
Vire uma imagem verticalmente ou horizontalmente com tf.image.flip_left_right :
flipped = tf.image.flip_left_right(image)
visualize(image, flipped)
Escala de cinza de uma imagem
Você pode escalar uma imagem em escala de cinza com tf.image.rgb_to_grayscale :
grayscaled = tf.image.rgb_to_grayscale(image)
visualize(image, tf.squeeze(grayscaled))
_ = plt.colorbar()

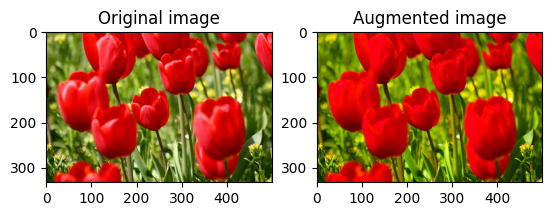
Saturar uma imagem
Sature uma imagem com tf.image.adjust_saturation fornecendo um fator de saturação:
saturated = tf.image.adjust_saturation(image, 3)
visualize(image, saturated)
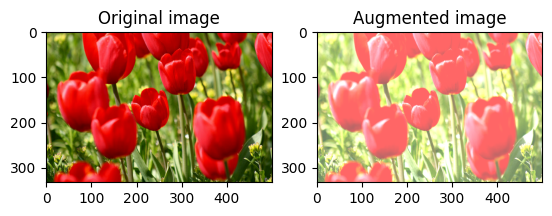
Alterar o brilho da imagem
Altere o brilho da imagem com tf.image.adjust_brightness fornecendo um fator de brilho:
bright = tf.image.adjust_brightness(image, 0.4)
visualize(image, bright)
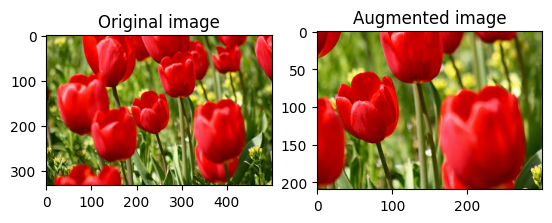
Centralizar o recorte de uma imagem
Corte a imagem do centro até a parte da imagem que você deseja usando tf.image.central_crop :
cropped = tf.image.central_crop(image, central_fraction=0.5)
visualize(image, cropped)
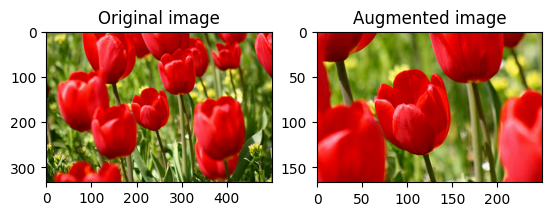
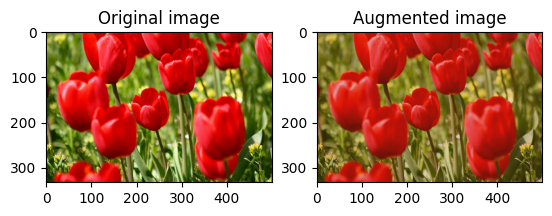
Girar uma imagem
Gire uma imagem em 90 graus com tf.image.rot90 :
rotated = tf.image.rot90(image)
visualize(image, rotated)

Transformações aleatórias
A aplicação de transformações aleatórias às imagens pode ajudar a generalizar e expandir ainda mais o conjunto de dados. A API tf.image atual fornece oito dessas operações de imagem aleatórias (ops):
-
tf.image.stateless_random_brightness -
tf.image.stateless_random_contrast -
tf.image.stateless_random_crop -
tf.image.stateless_random_flip_left_right -
tf.image.stateless_random_flip_up_down -
tf.image.stateless_random_hue -
tf.image.stateless_random_jpeg_quality -
tf.image.stateless_random_saturation
Essas operações de imagem aleatórias são puramente funcionais: a saída depende apenas da entrada. Isso os torna simples de usar em pipelines de entrada determinísticos e de alto desempenho. Eles exigem que um valor de seed seja inserido em cada etapa. Dada a mesma seed , eles retornam os mesmos resultados independentemente de quantas vezes são chamados.
Nas seções a seguir, você:
- Veja exemplos de uso de operações de imagem aleatórias para transformar uma imagem.
- Demonstre como aplicar transformações aleatórias a um conjunto de dados de treinamento.
Alterar aleatoriamente o brilho da imagem
Altere aleatoriamente o brilho da image usando tf.image.stateless_random_brightness fornecendo um fator de brilho e seed . O fator de brilho é escolhido aleatoriamente na faixa [-max_delta, max_delta) e está associado à seed fornecida.
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_brightness = tf.image.stateless_random_brightness(
image, max_delta=0.95, seed=seed)
visualize(image, stateless_random_brightness)
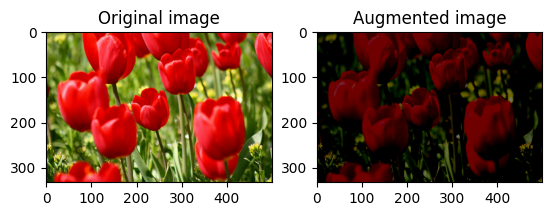
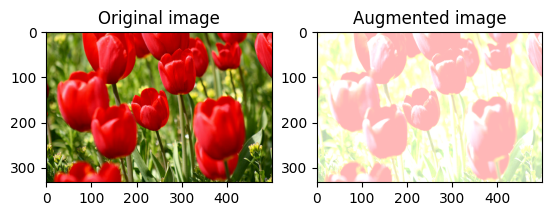
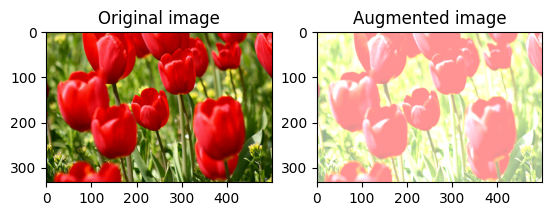
Alterar aleatoriamente o contraste da imagem
Altere aleatoriamente o contraste da image usando tf.image.stateless_random_contrast fornecendo um intervalo de contraste e seed . A faixa de contraste é escolhida aleatoriamente no intervalo [lower, upper] e está associada à seed fornecida.
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_contrast = tf.image.stateless_random_contrast(
image, lower=0.1, upper=0.9, seed=seed)
visualize(image, stateless_random_contrast)
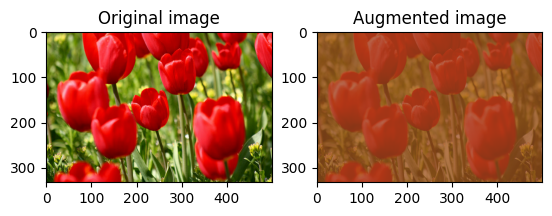
Recortar uma imagem aleatoriamente
Corte a image aleatoriamente usando tf.image.stateless_random_crop fornecendo size de destino e seed . A parte que é cortada da image está em um deslocamento escolhido aleatoriamente e está associada à seed fornecida.
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_crop = tf.image.stateless_random_crop(
image, size=[210, 300, 3], seed=seed)
visualize(image, stateless_random_crop)
Aplicar aumento a um conjunto de dados
Vamos primeiro fazer o download do conjunto de dados de imagem novamente, caso eles sejam modificados nas seções anteriores.
(train_datasets, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
Em seguida, defina uma função de utilitário para redimensionar e redimensionar as imagens. Esta função será usada para unificar o tamanho e a escala das imagens no conjunto de dados:
def resize_and_rescale(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, [IMG_SIZE, IMG_SIZE])
image = (image / 255.0)
return image, label
Vamos também definir a função de augment que pode aplicar as transformações aleatórias nas imagens. Esta função será usada no conjunto de dados na próxima etapa.
def augment(image_label, seed):
image, label = image_label
image, label = resize_and_rescale(image, label)
image = tf.image.resize_with_crop_or_pad(image, IMG_SIZE + 6, IMG_SIZE + 6)
# Make a new seed.
new_seed = tf.random.experimental.stateless_split(seed, num=1)[0, :]
# Random crop back to the original size.
image = tf.image.stateless_random_crop(
image, size=[IMG_SIZE, IMG_SIZE, 3], seed=seed)
# Random brightness.
image = tf.image.stateless_random_brightness(
image, max_delta=0.5, seed=new_seed)
image = tf.clip_by_value(image, 0, 1)
return image, label
Opção 1: usando tf.data.experimental.Counter
Crie um objeto tf.data.experimental.Counter (vamos chamá-lo de counter ) e Dataset.zip o conjunto de dados com (counter, counter) . Isso garantirá que cada imagem no conjunto de dados seja associada a um valor exclusivo (de forma (2,) ) com base no counter que posteriormente pode ser passado para a função de augment como o valor seed para transformações aleatórias.
# Create a `Counter` object and `Dataset.zip` it together with the training set.
counter = tf.data.experimental.Counter()
train_ds = tf.data.Dataset.zip((train_datasets, (counter, counter)))
Mapeie a função de augment para o conjunto de dados de treinamento:
train_ds = (
train_ds
.shuffle(1000)
.map(augment, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
val_ds = (
val_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
test_ds = (
test_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
Opção 2: usando tf.random.Generator
- Crie um objeto
tf.random.Generatorcom um valorseedinicial. Chamar a funçãomake_seedsno mesmo objeto gerador sempre retorna um valor deseednovo e exclusivo. - Defina uma função wrapper que: 1) chame a função
make_seeds; e 2) passa o valorseedrecém-gerado para a função deaugmentpara transformações aleatórias.
# Create a generator.
rng = tf.random.Generator.from_seed(123, alg='philox')
# Create a wrapper function for updating seeds.
def f(x, y):
seed = rng.make_seeds(2)[0]
image, label = augment((x, y), seed)
return image, label
Mapeie a função wrapper f para o conjunto de dados de treinamento e a função resize_and_rescale — para os conjuntos de validação e teste:
train_ds = (
train_datasets
.shuffle(1000)
.map(f, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
val_ds = (
val_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
test_ds = (
test_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
Esses conjuntos de dados agora podem ser usados para treinar um modelo conforme mostrado anteriormente.
Próximos passos
Este tutorial demonstrou o aumento de dados usando camadas de pré-processamento Keras e tf.image .
- Para saber como incluir camadas de pré-processamento em seu modelo, consulte o tutorial Classificação de imagens .
- Você também pode estar interessado em aprender como as camadas de pré-processamento podem ajudá-lo a classificar o texto, conforme mostrado no tutorial Classificação básica de texto .
- Você pode aprender mais sobre
tf.dataneste guia e aprender como configurar seus pipelines de entrada para desempenho aqui .