
| | |  Ver fonte no GitHub Ver fonte no GitHub | |
Este tutorial mostra como carregar e pré-processar um conjunto de dados de imagem de três maneiras:
- Primeiro, você usará utilitários de pré-processamento Keras de alto nível (como
tf.keras.utils.image_dataset_from_directory) e camadas (comotf.keras.layers.Rescaling) para ler um diretório de imagens no disco. - Em seguida, você escreverá seu próprio pipeline de entrada do zero usando tf.data .
- Por fim, você fará o download de um conjunto de dados do grande catálogo disponível em TensorFlow Datasets .
Configurar
import numpy as np
import os
import PIL
import PIL.Image
import tensorflow as tf
import tensorflow_datasets as tfds
print(tf.__version__)
2.8.0-rc1
Baixe o conjunto de dados de flores
Este tutorial usa um conjunto de dados de vários milhares de fotos de flores. O conjunto de dados de flores contém cinco subdiretórios, um por classe:
flowers_photos/
daisy/
dandelion/
roses/
sunflowers/
tulips/
import pathlib
dataset_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz"
data_dir = tf.keras.utils.get_file(origin=dataset_url,
fname='flower_photos',
untar=True)
data_dir = pathlib.Path(data_dir)
Após o download (218 MB), você deverá ter uma cópia das fotos das flores disponíveis. Há 3.670 imagens no total:
image_count = len(list(data_dir.glob('*/*.jpg')))
print(image_count)
3670
Cada diretório contém imagens desse tipo de flor. Aqui estão algumas rosas:
roses = list(data_dir.glob('roses/*'))
PIL.Image.open(str(roses[0]))

roses = list(data_dir.glob('roses/*'))
PIL.Image.open(str(roses[1]))

Carregar dados usando um utilitário Keras
Vamos carregar essas imagens do disco usando o útil utilitário tf.keras.utils.image_dataset_from_directory .
Criar um conjunto de dados
Defina alguns parâmetros para o carregador:
batch_size = 32
img_height = 180
img_width = 180
É uma boa prática usar uma divisão de validação ao desenvolver seu modelo. Você usará 80% das imagens para treinamento e 20% para validação.
train_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 3670 files belonging to 5 classes. Using 2936 files for training.
val_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 3670 files belonging to 5 classes. Using 734 files for validation.
Você pode encontrar os nomes das classes no atributo class_names nesses conjuntos de dados.
class_names = train_ds.class_names
print(class_names)
['daisy', 'dandelion', 'roses', 'sunflowers', 'tulips']
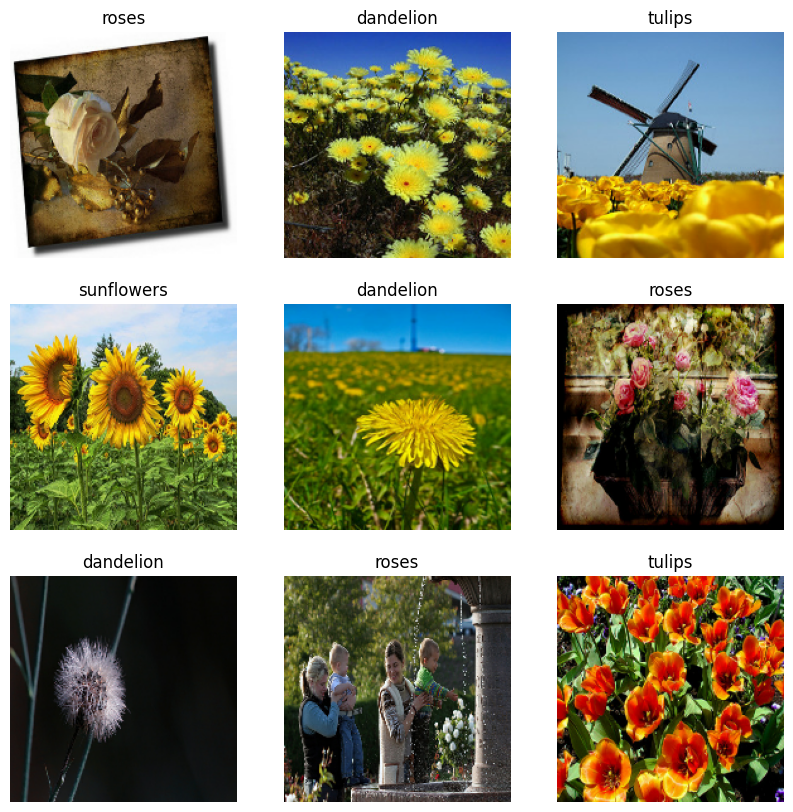
Visualize os dados
Aqui estão as primeiras nove imagens do conjunto de dados de treinamento.
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 10))
for images, labels in train_ds.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
Você pode treinar um modelo usando esses conjuntos de dados passando-os para model.fit (mostrado posteriormente neste tutorial). Se desejar, você também pode iterar manualmente no conjunto de dados e recuperar lotes de imagens:
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
(32, 180, 180, 3) (32,)
O image_batch é um tensor da forma (32, 180, 180, 3) . Este é um lote de 32 imagens de formato 180x180x3 (a última dimensão refere-se aos canais de cores RGB). O label_batch é um tensor da forma (32,) , estes são os rótulos correspondentes às 32 imagens.
Você pode chamar .numpy() em qualquer um desses tensores para convertê-los em um numpy.ndarray .
Padronize os dados
Os valores do canal RGB estão na faixa [0, 255] . Isso não é ideal para uma rede neural; em geral, você deve procurar tornar seus valores de entrada pequenos.
Aqui, você padronizará os valores para estarem no intervalo [0, 1] usando tf.keras.layers.Rescaling :
normalization_layer = tf.keras.layers.Rescaling(1./255)
Existem duas maneiras de usar essa camada. Você pode aplicá-lo ao conjunto de dados chamando Dataset.map :
normalized_ds = train_ds.map(lambda x, y: (normalization_layer(x), y))
image_batch, labels_batch = next(iter(normalized_ds))
first_image = image_batch[0]
# Notice the pixel values are now in `[0,1]`.
print(np.min(first_image), np.max(first_image))
0.0 0.96902645
Ou você pode incluir a camada dentro de sua definição de modelo para simplificar a implantação. Você usará a segunda abordagem aqui.
Configurar o conjunto de dados para desempenho
Vamos nos certificar de usar a pré-busca em buffer para que você possa produzir dados do disco sem que a E/S se torne um bloqueio. Estes são dois métodos importantes que você deve usar ao carregar dados:
-
Dataset.cachemantém as imagens na memória depois de serem carregadas fora do disco durante a primeira época. Isso garantirá que o conjunto de dados não se torne um gargalo ao treinar seu modelo. Se seu conjunto de dados for muito grande para caber na memória, você também poderá usar esse método para criar um cache em disco de alto desempenho. -
Dataset.prefetchsobrepõe o pré-processamento de dados e a execução do modelo durante o treinamento.
Os leitores interessados podem aprender mais sobre os dois métodos, bem como sobre como armazenar dados em cache no disco na seção Pré -busca do guia Melhor desempenho com a API tf.data .
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
Treinar um modelo
Para completar, você mostrará como treinar um modelo simples usando os conjuntos de dados que acabou de preparar.
O modelo Sequencial consiste em três blocos de convolução ( tf.keras.layers.Conv2D ) com uma camada de agrupamento máximo ( tf.keras.layers.MaxPooling2D ) em cada um deles. Há uma camada totalmente conectada ( tf.keras.layers.Dense ) com 128 unidades em cima dela que é ativada por uma função de ativação ReLU ( 'relu' ). Este modelo não foi ajustado de forma alguma - o objetivo é mostrar a mecânica usando os conjuntos de dados que você acabou de criar. Para saber mais sobre classificação de imagens, visite o tutorial Classificação de imagens.
num_classes = 5
model = tf.keras.Sequential([
tf.keras.layers.Rescaling(1./255),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(num_classes)
])
Escolha o otimizador tf.keras.optimizers.Adam e a função de perda tf.keras.losses.SparseCategoricalCrossentropy . Para visualizar a precisão do treinamento e da validação para cada época de treinamento, passe o argumento de metrics para Model.compile .
model.compile(
optimizer='adam',
loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(
train_ds,
validation_data=val_ds,
epochs=3
)
Epoch 1/3 92/92 [==============================] - 4s 21ms/step - loss: 1.3091 - accuracy: 0.4281 - val_loss: 1.0982 - val_accuracy: 0.5599 Epoch 2/3 92/92 [==============================] - 1s 12ms/step - loss: 1.0196 - accuracy: 0.5879 - val_loss: 0.9572 - val_accuracy: 0.6213 Epoch 3/3 92/92 [==============================] - 1s 12ms/step - loss: 0.8455 - accuracy: 0.6775 - val_loss: 0.8839 - val_accuracy: 0.6512 <keras.callbacks.History at 0x7ff10c168850>
Você pode notar que a precisão da validação é baixa em comparação com a precisão do treinamento, indicando que seu modelo está superajustado. Você pode aprender mais sobre overfitting e como reduzi-lo neste tutorial .
Usando tf.data para um controle mais preciso
O utilitário de pré-processamento Keras acima — tf.keras.utils.image_dataset_from_directory — é uma maneira conveniente de criar um tf.data.Dataset a partir de um diretório de imagens.
Para um controle de granulação mais preciso, você pode escrever seu próprio pipeline de entrada usando tf.data . Esta seção mostra como fazer exatamente isso, começando com os caminhos de arquivo do arquivo TGZ que você baixou anteriormente.
list_ds = tf.data.Dataset.list_files(str(data_dir/'*/*'), shuffle=False)
list_ds = list_ds.shuffle(image_count, reshuffle_each_iteration=False)
for f in list_ds.take(5):
print(f.numpy())
b'/home/kbuilder/.keras/datasets/flower_photos/roses/14267691818_301aceda07.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/daisy/2641151167_3bf1349606_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/sunflowers/6495554833_86eb8faa8e_n.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/tulips/4578030672_e6aefd45af.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/dandelion/144686365_d7e96941ee_n.jpg'
A estrutura em árvore dos arquivos pode ser usada para compilar uma lista class_names .
class_names = np.array(sorted([item.name for item in data_dir.glob('*') if item.name != "LICENSE.txt"]))
print(class_names)
['daisy' 'dandelion' 'roses' 'sunflowers' 'tulips']
Divida o conjunto de dados em conjuntos de treinamento e validação:
val_size = int(image_count * 0.2)
train_ds = list_ds.skip(val_size)
val_ds = list_ds.take(val_size)
Você pode imprimir o comprimento de cada conjunto de dados da seguinte forma:
print(tf.data.experimental.cardinality(train_ds).numpy())
print(tf.data.experimental.cardinality(val_ds).numpy())
2936 734
Escreva uma função curta que converta um caminho de arquivo em um par (img, label) :
def get_label(file_path):
# Convert the path to a list of path components
parts = tf.strings.split(file_path, os.path.sep)
# The second to last is the class-directory
one_hot = parts[-2] == class_names
# Integer encode the label
return tf.argmax(one_hot)
def decode_img(img):
# Convert the compressed string to a 3D uint8 tensor
img = tf.io.decode_jpeg(img, channels=3)
# Resize the image to the desired size
return tf.image.resize(img, [img_height, img_width])
def process_path(file_path):
label = get_label(file_path)
# Load the raw data from the file as a string
img = tf.io.read_file(file_path)
img = decode_img(img)
return img, label
Use Dataset.map para criar um conjunto de dados de image, label :
# Set `num_parallel_calls` so multiple images are loaded/processed in parallel.
train_ds = train_ds.map(process_path, num_parallel_calls=AUTOTUNE)
val_ds = val_ds.map(process_path, num_parallel_calls=AUTOTUNE)
for image, label in train_ds.take(1):
print("Image shape: ", image.numpy().shape)
print("Label: ", label.numpy())
Image shape: (180, 180, 3) Label: 1
Configurar conjunto de dados para desempenho
Para treinar um modelo com esse conjunto de dados, você precisará dos dados:
- Para ser bem embaralhado.
- A ser em lote.
- Lotes a serem disponibilizados o mais rápido possível.
Esses recursos podem ser adicionados usando a API tf.data . Para obter mais detalhes, visite o guia Desempenho do pipeline de entrada .
def configure_for_performance(ds):
ds = ds.cache()
ds = ds.shuffle(buffer_size=1000)
ds = ds.batch(batch_size)
ds = ds.prefetch(buffer_size=AUTOTUNE)
return ds
train_ds = configure_for_performance(train_ds)
val_ds = configure_for_performance(val_ds)
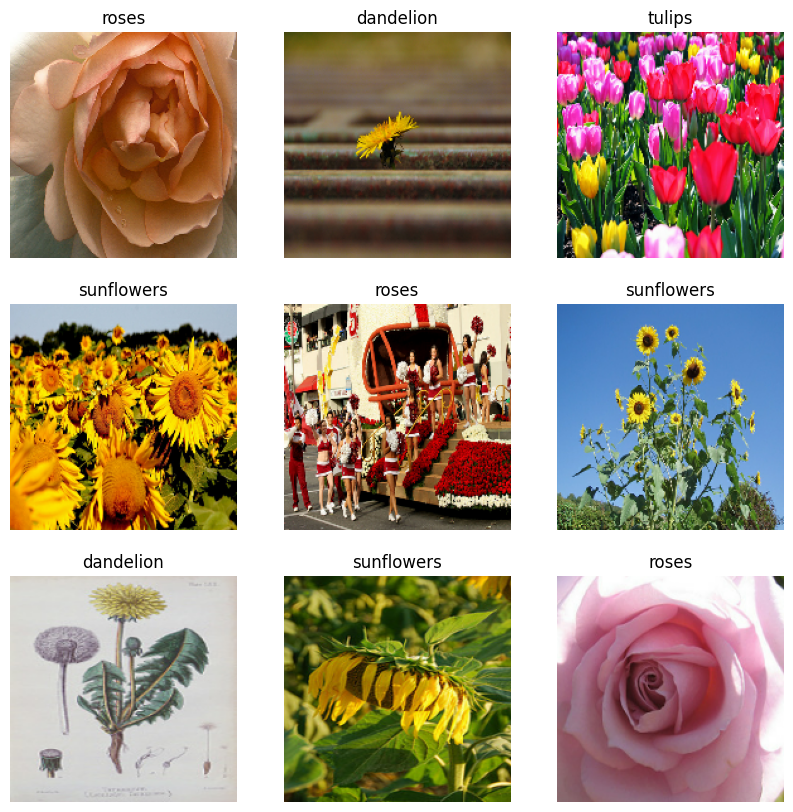
Visualize os dados
Você pode visualizar este conjunto de dados de forma semelhante ao que você criou anteriormente:
image_batch, label_batch = next(iter(train_ds))
plt.figure(figsize=(10, 10))
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(image_batch[i].numpy().astype("uint8"))
label = label_batch[i]
plt.title(class_names[label])
plt.axis("off")
2022-01-26 06:29:45.209901: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
Continue treinando o modelo
Você agora construiu manualmente um tf.data.Dataset semelhante ao criado por tf.keras.utils.image_dataset_from_directory acima. Você pode continuar treinando o modelo com ele. Como antes, você treinará por apenas algumas épocas para manter o tempo de execução curto.
model.fit(
train_ds,
validation_data=val_ds,
epochs=3
)
Epoch 1/3 92/92 [==============================] - 3s 21ms/step - loss: 0.7305 - accuracy: 0.7245 - val_loss: 0.7311 - val_accuracy: 0.7139 Epoch 2/3 92/92 [==============================] - 1s 13ms/step - loss: 0.5279 - accuracy: 0.8069 - val_loss: 0.7021 - val_accuracy: 0.7316 Epoch 3/3 92/92 [==============================] - 1s 13ms/step - loss: 0.3739 - accuracy: 0.8644 - val_loss: 0.8266 - val_accuracy: 0.6948 <keras.callbacks.History at 0x7ff0ee071f10>
Como usar conjuntos de dados do TensorFlow
Até agora, este tutorial se concentrou no carregamento de dados do disco. Você também pode encontrar um conjunto de dados para usar explorando o grande catálogo de conjuntos de dados fáceis de baixar em TensorFlow Datasets .
Como você carregou anteriormente o conjunto de dados Flowers do disco, agora vamos importá-lo com os conjuntos de dados do TensorFlow.
Faça o download do conjunto de dados Flowers usando os conjuntos de dados do TensorFlow:
(train_ds, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
O conjunto de dados de flores tem cinco classes:
num_classes = metadata.features['label'].num_classes
print(num_classes)
5
Recupere uma imagem do conjunto de dados:
get_label_name = metadata.features['label'].int2str
image, label = next(iter(train_ds))
_ = plt.imshow(image)
_ = plt.title(get_label_name(label))
2022-01-26 06:29:54.281352: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.

Como antes, lembre-se de agrupar, embaralhar e configurar os conjuntos de treinamento, validação e teste para desempenho:
train_ds = configure_for_performance(train_ds)
val_ds = configure_for_performance(val_ds)
test_ds = configure_for_performance(test_ds)
Você pode encontrar um exemplo completo de como trabalhar com o conjunto de dados Flowers e o TensorFlow Datasets visitando o tutorial de aumento de dados .
Próximos passos
Este tutorial mostrou duas maneiras de carregar imagens do disco. Primeiro, você aprendeu a carregar e pré-processar um conjunto de dados de imagem usando camadas e utilitários de pré-processamento Keras. Em seguida, você aprendeu a escrever um pipeline de entrada do zero usando tf.data . Por fim, você aprendeu a baixar um conjunto de dados do TensorFlow Datasets.
Para seus próximos passos:
- Você pode aprender como adicionar aumento de dados .
- Para saber mais sobre
tf.data, você pode visitar o guia tf.data: Build TensorFlow input pipelines .