
| | |  Xem nguồn trên GitHub Xem nguồn trên GitHub | |
Hướng dẫn này chỉ ra cách tải và xử lý trước một tập dữ liệu hình ảnh theo ba cách:
- Đầu tiên, bạn sẽ sử dụng các tiện ích tiền xử lý Keras cấp cao (chẳng hạn như
tf.keras.utils.image_dataset_from_directory) và các lớp (chẳng hạn nhưtf.keras.layers.Rescaling) để đọc thư mục hình ảnh trên đĩa. - Tiếp theo, bạn sẽ viết đường dẫn đầu vào của riêng mình từ đầu bằng tf.data .
- Cuối cùng, bạn sẽ tải xuống một tập dữ liệu từ danh mục lớn có sẵn trong TensorFlow Datasets .
Thành lập
import numpy as np
import os
import PIL
import PIL.Image
import tensorflow as tf
import tensorflow_datasets as tfds
print(tf.__version__)
2.8.0-rc1
Tải xuống bộ dữ liệu về hoa
Hướng dẫn này sử dụng tập dữ liệu gồm hàng nghìn bức ảnh về hoa. Tập dữ liệu về hoa chứa năm thư mục con, mỗi thư mục con:
flowers_photos/
daisy/
dandelion/
roses/
sunflowers/
tulips/
import pathlib
dataset_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz"
data_dir = tf.keras.utils.get_file(origin=dataset_url,
fname='flower_photos',
untar=True)
data_dir = pathlib.Path(data_dir)
Sau khi tải xuống (218MB), bây giờ bạn sẽ có sẵn một bản sao của các bức ảnh hoa. Có tổng cộng 3.670 hình ảnh:
image_count = len(list(data_dir.glob('*/*.jpg')))
print(image_count)
3670
Mỗi thư mục chứa hình ảnh của loại hoa đó. Đây là một số loại hoa hồng:
roses = list(data_dir.glob('roses/*'))
PIL.Image.open(str(roses[0]))

roses = list(data_dir.glob('roses/*'))
PIL.Image.open(str(roses[1]))

Tải dữ liệu bằng tiện ích Keras
Hãy tải những hình ảnh này ra đĩa bằng tiện ích tf.keras.utils.image_dataset_from_directory hữu ích.
Tạo tập dữ liệu
Xác định một số tham số cho bộ nạp:
batch_size = 32
img_height = 180
img_width = 180
Bạn nên sử dụng phân tách xác thực khi phát triển mô hình của mình. Bạn sẽ sử dụng 80% hình ảnh để đào tạo và 20% để xác nhận.
train_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 3670 files belonging to 5 classes. Using 2936 files for training.
val_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 3670 files belonging to 5 classes. Using 734 files for validation.
Bạn có thể tìm tên lớp trong thuộc tính class_names trên các tập dữ liệu này.
class_names = train_ds.class_names
print(class_names)
['daisy', 'dandelion', 'roses', 'sunflowers', 'tulips']
Trực quan hóa dữ liệu
Đây là chín hình ảnh đầu tiên từ tập dữ liệu đào tạo.
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 10))
for images, labels in train_ds.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
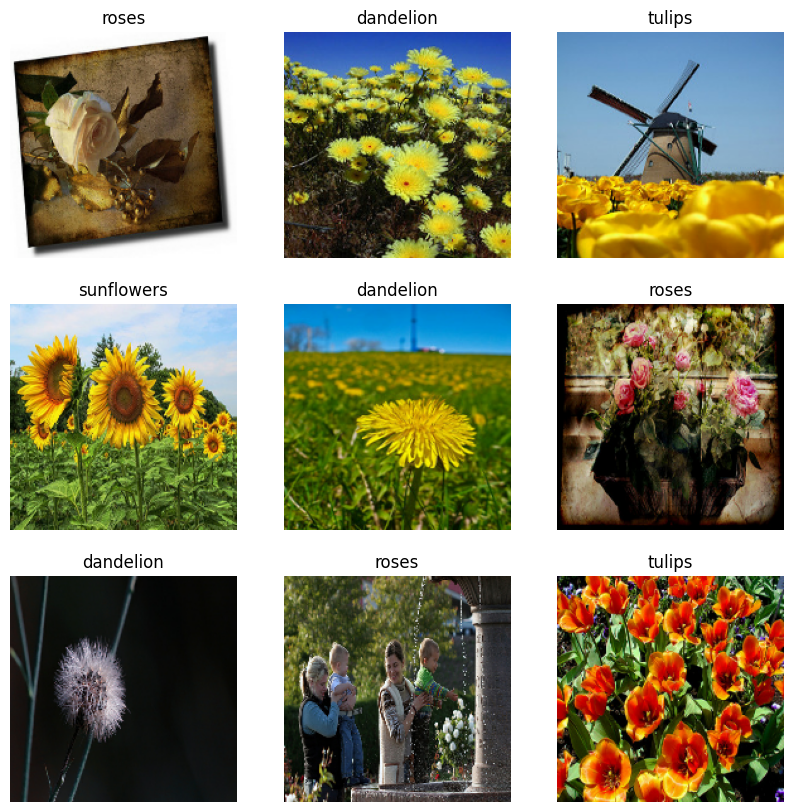
Bạn có thể đào tạo một mô hình bằng cách sử dụng các tập dữ liệu này bằng cách chuyển chúng đến model.fit (được hiển thị sau trong hướng dẫn này). Nếu muốn, bạn cũng có thể lặp lại theo cách thủ công qua tập dữ liệu và truy xuất hàng loạt hình ảnh:
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
(32, 180, 180, 3) (32,)
image_batch là một tenxơ của hình dạng (32, 180, 180, 3) . Đây là một lô gồm 32 hình ảnh có hình dạng 180x180x3 (kích thước cuối cùng đề cập đến các kênh màu RGB). label_batch là một tenxơ của hình (32,) , đây là những nhãn tương ứng với 32 hình ảnh.
Bạn có thể gọi .numpy() trên một trong hai tensor này để chuyển chúng thành numpy.ndarray .
Chuẩn hóa dữ liệu
Giá trị kênh RGB nằm trong phạm vi [0, 255] . Điều này không lý tưởng cho mạng nơ-ron; nói chung, bạn nên tìm cách giảm giá trị đầu vào của mình.
Tại đây, bạn sẽ chuẩn hóa các giá trị nằm trong phạm vi [0, 1] bằng cách sử dụng tf.keras.layers.Rescaling .
normalization_layer = tf.keras.layers.Rescaling(1./255)
Có hai cách để sử dụng lớp này. Bạn có thể áp dụng nó vào tập dữ liệu bằng cách gọi Dataset.map :
normalized_ds = train_ds.map(lambda x, y: (normalization_layer(x), y))
image_batch, labels_batch = next(iter(normalized_ds))
first_image = image_batch[0]
# Notice the pixel values are now in `[0,1]`.
print(np.min(first_image), np.max(first_image))
0.0 0.96902645
Hoặc, bạn có thể bao gồm lớp bên trong định nghĩa mô hình của mình để đơn giản hóa việc triển khai. Bạn sẽ sử dụng cách tiếp cận thứ hai ở đây.
Định cấu hình tập dữ liệu cho hiệu suất
Hãy đảm bảo sử dụng tìm nạp trước có bộ đệm để bạn có thể mang lại dữ liệu từ đĩa mà không bị chặn I / O. Đây là hai phương pháp quan trọng bạn nên sử dụng khi tải dữ liệu:
-
Dataset.cachegiữ các hình ảnh trong bộ nhớ sau khi chúng được tải ra khỏi đĩa trong kỷ nguyên đầu tiên. Điều này sẽ đảm bảo tập dữ liệu không trở thành nút cổ chai trong khi đào tạo mô hình của bạn. Nếu tập dữ liệu của bạn quá lớn để vừa với bộ nhớ, bạn cũng có thể sử dụng phương pháp này để tạo bộ đệm ẩn trên đĩa hoạt động hiệu quả. -
Dataset.prefetchchồng lên quá trình tiền xử lý dữ liệu và thực thi mô hình trong khi đào tạo.
Bạn đọc quan tâm có thể tìm hiểu thêm về cả hai phương pháp cũng như cách lưu dữ liệu vào bộ nhớ cache vào đĩa trong phần Tìm nạp trước của Hiệu suất tốt hơn với hướng dẫn API tf.data .
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
Đào tạo một người mẫu
Để hoàn chỉnh, bạn sẽ chỉ ra cách huấn luyện một mô hình đơn giản bằng cách sử dụng các bộ dữ liệu bạn vừa chuẩn bị.
Mô hình Tuần tự bao gồm ba khối tích chập ( tf.keras.layers.Conv2D ) với một lớp tổng hợp tối đa ( tf.keras.layers.MaxPooling2D ) trong mỗi khối. Có một lớp được kết nối đầy đủ ( tf.keras.layers.Dense ) với 128 đơn vị trên cùng được kích hoạt bởi chức năng kích hoạt ReLU ( 'relu' ). Mô hình này chưa được điều chỉnh theo bất kỳ cách nào — mục đích là để cho bạn thấy cơ chế sử dụng tập dữ liệu bạn vừa tạo. Để tìm hiểu thêm về phân loại hình ảnh, hãy truy cập Hướng dẫn phân loại hình ảnh .
num_classes = 5
model = tf.keras.Sequential([
tf.keras.layers.Rescaling(1./255),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(num_classes)
])
Chọn trình tối ưu hóa tf.keras.optimizers.Adam và chức năng mất mát tf.keras.losses.SparseCategoricalCrossentropy . Để xem độ chính xác của quá trình đào tạo và xác thực cho từng kỷ nguyên đào tạo, hãy chuyển đối metrics vào Model.compile .
model.compile(
optimizer='adam',
loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(
train_ds,
validation_data=val_ds,
epochs=3
)
Epoch 1/3 92/92 [==============================] - 4s 21ms/step - loss: 1.3091 - accuracy: 0.4281 - val_loss: 1.0982 - val_accuracy: 0.5599 Epoch 2/3 92/92 [==============================] - 1s 12ms/step - loss: 1.0196 - accuracy: 0.5879 - val_loss: 0.9572 - val_accuracy: 0.6213 Epoch 3/3 92/92 [==============================] - 1s 12ms/step - loss: 0.8455 - accuracy: 0.6775 - val_loss: 0.8839 - val_accuracy: 0.6512 <keras.callbacks.History at 0x7ff10c168850>
Bạn có thể nhận thấy độ chính xác xác thực thấp so với độ chính xác đào tạo, cho thấy mô hình của bạn đang quá trang bị. Bạn có thể tìm hiểu thêm về trang phục quá mức và cách giảm nó trong hướng dẫn này.
Sử dụng tf.data để kiểm soát tốt hơn
Tiện ích tiền xử lý Keras ở tf.keras.utils.image_dataset_from_directory —là một cách thuận tiện để tạo tf.data.Dataset từ thư mục hình ảnh.
Để kiểm soát hạt tốt hơn, bạn có thể viết đường dẫn đầu vào của riêng mình bằng cách sử dụng tf.data . Phần này chỉ ra cách thực hiện điều đó, bắt đầu với các đường dẫn tệp từ tệp TGZ mà bạn đã tải xuống trước đó.
list_ds = tf.data.Dataset.list_files(str(data_dir/'*/*'), shuffle=False)
list_ds = list_ds.shuffle(image_count, reshuffle_each_iteration=False)
for f in list_ds.take(5):
print(f.numpy())
b'/home/kbuilder/.keras/datasets/flower_photos/roses/14267691818_301aceda07.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/daisy/2641151167_3bf1349606_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/sunflowers/6495554833_86eb8faa8e_n.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/tulips/4578030672_e6aefd45af.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/dandelion/144686365_d7e96941ee_n.jpg'
Cấu trúc cây của tệp có thể được sử dụng để biên dịch danh sách class_names .
class_names = np.array(sorted([item.name for item in data_dir.glob('*') if item.name != "LICENSE.txt"]))
print(class_names)
['daisy' 'dandelion' 'roses' 'sunflowers' 'tulips']
Chia bộ dữ liệu thành các bộ đào tạo và xác nhận:
val_size = int(image_count * 0.2)
train_ds = list_ds.skip(val_size)
val_ds = list_ds.take(val_size)
Bạn có thể in độ dài của mỗi tập dữ liệu như sau:
print(tf.data.experimental.cardinality(train_ds).numpy())
print(tf.data.experimental.cardinality(val_ds).numpy())
2936 734
Viết một hàm ngắn để chuyển đổi đường dẫn tệp thành cặp (img, label) :
def get_label(file_path):
# Convert the path to a list of path components
parts = tf.strings.split(file_path, os.path.sep)
# The second to last is the class-directory
one_hot = parts[-2] == class_names
# Integer encode the label
return tf.argmax(one_hot)
def decode_img(img):
# Convert the compressed string to a 3D uint8 tensor
img = tf.io.decode_jpeg(img, channels=3)
# Resize the image to the desired size
return tf.image.resize(img, [img_height, img_width])
def process_path(file_path):
label = get_label(file_path)
# Load the raw data from the file as a string
img = tf.io.read_file(file_path)
img = decode_img(img)
return img, label
Sử dụng Dataset.map để tạo tập dữ liệu image, label :
# Set `num_parallel_calls` so multiple images are loaded/processed in parallel.
train_ds = train_ds.map(process_path, num_parallel_calls=AUTOTUNE)
val_ds = val_ds.map(process_path, num_parallel_calls=AUTOTUNE)
for image, label in train_ds.take(1):
print("Image shape: ", image.numpy().shape)
print("Label: ", label.numpy())
Image shape: (180, 180, 3) Label: 1
Định cấu hình tập dữ liệu cho hiệu suất
Để đào tạo một mô hình với tập dữ liệu này, bạn sẽ muốn có dữ liệu:
- Để được xáo trộn tốt.
- Để được chia lô.
- Hàng loạt để có sẵn càng sớm càng tốt.
Các tính năng này có thể được thêm vào bằng cách sử dụng API tf.data . Để biết thêm chi tiết, hãy truy cập hướng dẫn Hiệu suất Đường ống Đầu vào .
def configure_for_performance(ds):
ds = ds.cache()
ds = ds.shuffle(buffer_size=1000)
ds = ds.batch(batch_size)
ds = ds.prefetch(buffer_size=AUTOTUNE)
return ds
train_ds = configure_for_performance(train_ds)
val_ds = configure_for_performance(val_ds)
Trực quan hóa dữ liệu
Bạn có thể hình dung tập dữ liệu này tương tự như tập dữ liệu bạn đã tạo trước đó:
image_batch, label_batch = next(iter(train_ds))
plt.figure(figsize=(10, 10))
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(image_batch[i].numpy().astype("uint8"))
label = label_batch[i]
plt.title(class_names[label])
plt.axis("off")
2022-01-26 06:29:45.209901: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
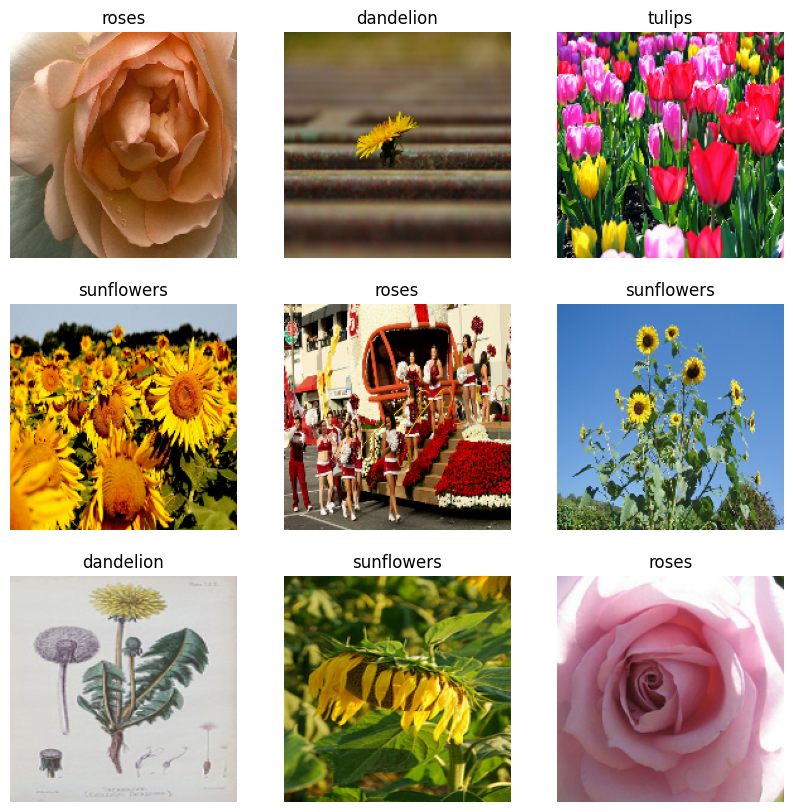
Tiếp tục đào tạo mô hình
Bây giờ bạn đã tạo thủ công một tf.data.Dataset tương tự với tf.keras.utils.image_dataset_from_directory ở trên. Bạn có thể tiếp tục đào tạo mô hình với nó. Như trước đây, bạn sẽ tập luyện chỉ trong một vài kỷ nguyên để giữ cho thời gian chạy ngắn.
model.fit(
train_ds,
validation_data=val_ds,
epochs=3
)
Epoch 1/3 92/92 [==============================] - 3s 21ms/step - loss: 0.7305 - accuracy: 0.7245 - val_loss: 0.7311 - val_accuracy: 0.7139 Epoch 2/3 92/92 [==============================] - 1s 13ms/step - loss: 0.5279 - accuracy: 0.8069 - val_loss: 0.7021 - val_accuracy: 0.7316 Epoch 3/3 92/92 [==============================] - 1s 13ms/step - loss: 0.3739 - accuracy: 0.8644 - val_loss: 0.8266 - val_accuracy: 0.6948 <keras.callbacks.History at 0x7ff0ee071f10>
Sử dụng tập dữ liệu TensorFlow
Cho đến nay, hướng dẫn này tập trung vào việc tải dữ liệu ra đĩa. Bạn cũng có thể tìm thấy một tập dữ liệu để sử dụng bằng cách khám phá danh mục lớn các tập dữ liệu dễ tải xuống tại TensorFlow Datasets .
Như trước đây bạn đã tải tập dữ liệu Flowers ra đĩa, bây giờ hãy nhập tập dữ liệu đó bằng TensorFlow Datasets.
Tải xuống bộ dữ liệu về Hoa bằng Bộ dữ liệu TensorFlow:
(train_ds, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
Tập dữ liệu về hoa có năm lớp:
num_classes = metadata.features['label'].num_classes
print(num_classes)
5
Lấy một hình ảnh từ tập dữ liệu:
get_label_name = metadata.features['label'].int2str
image, label = next(iter(train_ds))
_ = plt.imshow(image)
_ = plt.title(get_label_name(label))
2022-01-26 06:29:54.281352: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.

Như trước đây, hãy nhớ hàng loạt, xáo trộn và định cấu hình các bộ đào tạo, xác thực và kiểm tra cho hiệu suất:
train_ds = configure_for_performance(train_ds)
val_ds = configure_for_performance(val_ds)
test_ds = configure_for_performance(test_ds)
Bạn có thể tìm thấy một ví dụ đầy đủ về cách làm việc với Tập dữ liệu Flowers và Tập dữ liệu TensorFlow bằng cách truy cập hướng dẫn Tăng cường dữ liệu .
Bước tiếp theo
Hướng dẫn này chỉ ra hai cách tải hình ảnh ra đĩa. Đầu tiên, bạn đã học cách tải và xử lý trước một tập dữ liệu hình ảnh bằng cách sử dụng các lớp và tiện ích tiền xử lý của Keras. Tiếp theo, bạn đã học cách viết một đường dẫn đầu vào từ đầu bằng tf.data . Cuối cùng, bạn đã học cách tải xuống tập dữ liệu từ TensorFlow Datasets.
Đối với các bước tiếp theo của bạn:
- Bạn có thể tìm hiểu cách thêm dữ liệu tăng .
- Để tìm hiểu thêm về
tf.data, bạn có thể truy cập tf.data: Hướng dẫn xây dựng đường ống đầu vào TensorFlow .