
| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub | |
این آموزش بهترین روش توصیه شده را برای مدلهای آموزشی با حریم خصوصی متفاوت در سطح کاربر با استفاده از Tensorflow Federated نشان میدهد. ما در بر الگوریتم DP-SGD استفاده خواهد کرد آبادی و همکاران، "یادگیری عمیق در حریم خصوصی دیفرانسیل" برای سطح کاربر DP در زمینه فدرال اصلاح شده در مکماهان و همکاران، "مدل های یادگیری متفاوت شخصی راجعه زبان" .
حریم خصوصی دیفرانسیل (DP) یک روش پرکاربرد برای محدود کردن و تعیین کمیت نشت حریم خصوصی داده های حساس در هنگام انجام وظایف یادگیری است. آموزش یک مدل با DP در سطح کاربر تضمین میکند که بعید است مدل چیز مهمی در مورد دادههای هر فردی بیاموزد، اما همچنان (امیدوارم!) میتواند الگوهایی را که در دادههای بسیاری از مشتریان وجود دارد، یاد بگیرد.
ما مدلی را بر روی مجموعه داده های فدرال EMNIST آموزش خواهیم داد. یک معاوضه ذاتی بین ابزار و حریم خصوصی وجود دارد، و ممکن است آموزش مدلی با حریم خصوصی بالا که به خوبی یک مدل غیرخصوصی پیشرفته عمل کند، دشوار باشد. برای مصلحت در این آموزش، ما فقط 100 راند تمرین می کنیم و کیفیتی را قربانی می کنیم تا نشان دهیم چگونه با حریم خصوصی بالا تمرین کنیم. اگر از دورهای آموزشی بیشتری استفاده می کردیم، مطمئناً می توانستیم یک مدل خصوصی با دقت بالاتر داشته باشیم، اما نه به اندازه مدلی که بدون DP آموزش دیده است.
قبل از اینکه شروع کنیم
ابتدا، اجازه دهید مطمئن شویم که نوت بوک به پشتیبانی متصل است که اجزای مربوطه را کامپایل کرده است.
!pip install --quiet --upgrade tensorflow_federated_nightly
!pip install --quiet --upgrade nest-asyncio
import nest_asyncio
nest_asyncio.apply()
مقداری واردات برای آموزش نیاز داریم. ما استفاده از tensorflow_federated ، چارچوب منبع باز برای یادگیری ماشین و محاسبات دیگر بر روی داده های غیر متمرکز، و همچنین tensorflow_privacy ، کتابخانه منبع باز برای پیاده سازی و تجزیه و تحلیل الگوریتم متفاوت خصوصی در tensorflow.
import collections
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_federated as tff
import tensorflow_privacy as tfp
مثال "Hello World" زیر را اجرا کنید تا مطمئن شوید که محیط TFF به درستی تنظیم شده است. اگر آن کار نمی کند، لطفا به مراجعه نصب و راه اندازی راهنمای دستورالعمل.
@tff.federated_computation
def hello_world():
return 'Hello, World!'
hello_world()
b'Hello, World!'
مجموعه داده فدرال EMNIST را دانلود و پیش پردازش کنید.
def get_emnist_dataset():
emnist_train, emnist_test = tff.simulation.datasets.emnist.load_data(
only_digits=True)
def element_fn(element):
return collections.OrderedDict(
x=tf.expand_dims(element['pixels'], -1), y=element['label'])
def preprocess_train_dataset(dataset):
# Use buffer_size same as the maximum client dataset size,
# 418 for Federated EMNIST
return (dataset.map(element_fn)
.shuffle(buffer_size=418)
.repeat(1)
.batch(32, drop_remainder=False))
def preprocess_test_dataset(dataset):
return dataset.map(element_fn).batch(128, drop_remainder=False)
emnist_train = emnist_train.preprocess(preprocess_train_dataset)
emnist_test = preprocess_test_dataset(
emnist_test.create_tf_dataset_from_all_clients())
return emnist_train, emnist_test
train_data, test_data = get_emnist_dataset()
مدل ما را تعریف کنید.
def my_model_fn():
model = tf.keras.models.Sequential([
tf.keras.layers.Reshape(input_shape=(28, 28, 1), target_shape=(28 * 28,)),
tf.keras.layers.Dense(200, activation=tf.nn.relu),
tf.keras.layers.Dense(200, activation=tf.nn.relu),
tf.keras.layers.Dense(10)])
return tff.learning.from_keras_model(
keras_model=model,
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
input_spec=test_data.element_spec,
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()])
حساسیت نویز مدل را تعیین کنید.
برای دریافت ضمانتهای DP در سطح کاربر، باید الگوریتم اصلی میانگین فدرال را به دو صورت تغییر دهیم. ابتدا، بهروزرسانیهای مدل کلاینتها باید قبل از انتقال به سرور بریده شوند و حداکثر تأثیر هر کلاینت را محدود کند. دوم، سرور باید نویز کافی را به مجموع بهروزرسانیهای کاربر قبل از میانگینگیری اضافه کند تا بدترین حالت نفوذ مشتری را پنهان کند.
برای قطع، ما با استفاده از روش قطع تطبیقی از اندرو و همکاران 2021، متفاوت آموزش خصوصی با تطبیقی قطع ، بنابراین هیچ هنجار قطع باید به صراحت تعیین شده است.
اضافه کردن نویز به طور کلی کاربرد مدل را کاهش میدهد، اما میتوانیم میزان نویز را در بهروزرسانی متوسط در هر دور با دو دکمه کنترل کنیم: انحراف استاندارد نویز گاوسی که به مجموع اضافه میشود، و تعداد کلاینتها در میانگین. استراتژی ما این خواهد بود که ابتدا تعیین کنیم که مدل چقدر نویز را با تعداد نسبتاً کمی مشتری در هر دور با ضرر قابل قبول برای مطلوبیت مدل تحمل می کند. سپس برای آموزش مدل نهایی، میتوانیم مقدار نویز را در مجموع افزایش دهیم، در حالی که بهطور متناسب تعداد کلاینتها در هر دور را افزایش میدهیم (با فرض اینکه مجموعه داده به اندازه کافی بزرگ باشد که تعداد مشتریان در هر دور را پشتیبانی کند). بعید است که این به طور قابل توجهی بر کیفیت مدل تأثیر بگذارد، زیرا تنها اثر کاهش واریانس به دلیل نمونه گیری مشتری است (در واقع ما تأیید می کنیم که در مورد ما اینطور نیست).
برای این منظور، ابتدا مجموعهای از مدلها را با 50 مشتری در هر دور آموزش میدهیم، با افزایش نویز. به طور خاص، "noise_multiplier" را افزایش می دهیم که نسبت انحراف استاندارد نویز به هنجار برش است. از آنجایی که ما از برش تطبیقی استفاده می کنیم، به این معنی است که بزرگی واقعی نویز از دور به دور تغییر می کند.
# Run five clients per thread. Increase this if your runtime is running out of
# memory. Decrease it if you have the resources and want to speed up execution.
tff.backends.native.set_local_python_execution_context(clients_per_thread=5)
total_clients = len(train_data.client_ids)
def train(rounds, noise_multiplier, clients_per_round, data_frame):
# Using the `dp_aggregator` here turns on differential privacy with adaptive
# clipping.
aggregation_factory = tff.learning.model_update_aggregator.dp_aggregator(
noise_multiplier, clients_per_round)
# We use Poisson subsampling which gives slightly tighter privacy guarantees
# compared to having a fixed number of clients per round. The actual number of
# clients per round is stochastic with mean clients_per_round.
sampling_prob = clients_per_round / total_clients
# Build a federated averaging process.
# Typically a non-adaptive server optimizer is used because the noise in the
# updates can cause the second moment accumulators to become very large
# prematurely.
learning_process = tff.learning.build_federated_averaging_process(
my_model_fn,
client_optimizer_fn=lambda: tf.keras.optimizers.SGD(0.01),
server_optimizer_fn=lambda: tf.keras.optimizers.SGD(1.0, momentum=0.9),
model_update_aggregation_factory=aggregation_factory)
eval_process = tff.learning.build_federated_evaluation(my_model_fn)
# Training loop.
state = learning_process.initialize()
for round in range(rounds):
if round % 5 == 0:
metrics = eval_process(state.model, [test_data])['eval']
if round < 25 or round % 25 == 0:
print(f'Round {round:3d}: {metrics}')
data_frame = data_frame.append({'Round': round,
'NoiseMultiplier': noise_multiplier,
**metrics}, ignore_index=True)
# Sample clients for a round. Note that if your dataset is large and
# sampling_prob is small, it would be faster to use gap sampling.
x = np.random.uniform(size=total_clients)
sampled_clients = [
train_data.client_ids[i] for i in range(total_clients)
if x[i] < sampling_prob]
sampled_train_data = [
train_data.create_tf_dataset_for_client(client)
for client in sampled_clients]
# Use selected clients for update.
state, metrics = learning_process.next(state, sampled_train_data)
metrics = eval_process(state.model, [test_data])['eval']
print(f'Round {rounds:3d}: {metrics}')
data_frame = data_frame.append({'Round': rounds,
'NoiseMultiplier': noise_multiplier,
**metrics}, ignore_index=True)
return data_frame
data_frame = pd.DataFrame()
rounds = 100
clients_per_round = 50
for noise_multiplier in [0.0, 0.5, 0.75, 1.0]:
print(f'Starting training with noise multiplier: {noise_multiplier}')
data_frame = train(rounds, noise_multiplier, clients_per_round, data_frame)
print()
Starting training with noise multiplier: 0.0
Round 0: OrderedDict([('sparse_categorical_accuracy', 0.112289384), ('loss', 2.5190482)])
Round 5: OrderedDict([('sparse_categorical_accuracy', 0.19075724), ('loss', 2.2449977)])
Round 10: OrderedDict([('sparse_categorical_accuracy', 0.18115693), ('loss', 2.163907)])
Round 15: OrderedDict([('sparse_categorical_accuracy', 0.49970612), ('loss', 2.01017)])
Round 20: OrderedDict([('sparse_categorical_accuracy', 0.5333317), ('loss', 1.8350543)])
Round 25: OrderedDict([('sparse_categorical_accuracy', 0.5828517), ('loss', 1.6551636)])
Round 50: OrderedDict([('sparse_categorical_accuracy', 0.7352077), ('loss', 0.8700141)])
Round 75: OrderedDict([('sparse_categorical_accuracy', 0.7769152), ('loss', 0.6992781)])
Round 100: OrderedDict([('sparse_categorical_accuracy', 0.8049814), ('loss', 0.62453026)])
Starting training with noise multiplier: 0.5
Round 0: OrderedDict([('sparse_categorical_accuracy', 0.09526841), ('loss', 2.4332638)])
Round 5: OrderedDict([('sparse_categorical_accuracy', 0.20128821), ('loss', 2.2664592)])
Round 10: OrderedDict([('sparse_categorical_accuracy', 0.35472178), ('loss', 2.130336)])
Round 15: OrderedDict([('sparse_categorical_accuracy', 0.5480995), ('loss', 1.9713942)])
Round 20: OrderedDict([('sparse_categorical_accuracy', 0.42246276), ('loss', 1.8045483)])
Round 25: OrderedDict([('sparse_categorical_accuracy', 0.624902), ('loss', 1.4785467)])
Round 50: OrderedDict([('sparse_categorical_accuracy', 0.7265625), ('loss', 0.85801566)])
Round 75: OrderedDict([('sparse_categorical_accuracy', 0.77720904), ('loss', 0.70615387)])
Round 100: OrderedDict([('sparse_categorical_accuracy', 0.7702537), ('loss', 0.72331005)])
Starting training with noise multiplier: 0.75
Round 0: OrderedDict([('sparse_categorical_accuracy', 0.098672606), ('loss', 2.422002)])
Round 5: OrderedDict([('sparse_categorical_accuracy', 0.11794671), ('loss', 2.2227976)])
Round 10: OrderedDict([('sparse_categorical_accuracy', 0.3208513), ('loss', 2.083766)])
Round 15: OrderedDict([('sparse_categorical_accuracy', 0.49752644), ('loss', 1.8728142)])
Round 20: OrderedDict([('sparse_categorical_accuracy', 0.5816761), ('loss', 1.6084186)])
Round 25: OrderedDict([('sparse_categorical_accuracy', 0.62896746), ('loss', 1.378527)])
Round 50: OrderedDict([('sparse_categorical_accuracy', 0.73153406), ('loss', 0.8705139)])
Round 75: OrderedDict([('sparse_categorical_accuracy', 0.7789724), ('loss', 0.7113147)])
Round 100: OrderedDict([('sparse_categorical_accuracy', 0.70944357), ('loss', 0.89495045)])
Starting training with noise multiplier: 1.0
Round 0: OrderedDict([('sparse_categorical_accuracy', 0.12002841), ('loss', 2.60482)])
Round 5: OrderedDict([('sparse_categorical_accuracy', 0.104574844), ('loss', 2.3388205)])
Round 10: OrderedDict([('sparse_categorical_accuracy', 0.29966694), ('loss', 2.089262)])
Round 15: OrderedDict([('sparse_categorical_accuracy', 0.4067398), ('loss', 1.9109797)])
Round 20: OrderedDict([('sparse_categorical_accuracy', 0.5123677), ('loss', 1.6472703)])
Round 25: OrderedDict([('sparse_categorical_accuracy', 0.56416535), ('loss', 1.4362282)])
Round 50: OrderedDict([('sparse_categorical_accuracy', 0.62323666), ('loss', 1.1682972)])
Round 75: OrderedDict([('sparse_categorical_accuracy', 0.55968356), ('loss', 1.4779186)])
Round 100: OrderedDict([('sparse_categorical_accuracy', 0.382837), ('loss', 1.9680436)])
اکنون میتوانیم دقت مجموعه ارزیابی و از دست دادن آن اجراها را تجسم کنیم.
import matplotlib.pyplot as plt
import seaborn as sns
def make_plot(data_frame):
plt.figure(figsize=(15, 5))
dff = data_frame.rename(
columns={'sparse_categorical_accuracy': 'Accuracy', 'loss': 'Loss'})
plt.subplot(121)
sns.lineplot(data=dff, x='Round', y='Accuracy', hue='NoiseMultiplier', palette='dark')
plt.subplot(122)
sns.lineplot(data=dff, x='Round', y='Loss', hue='NoiseMultiplier', palette='dark')
make_plot(data_frame)
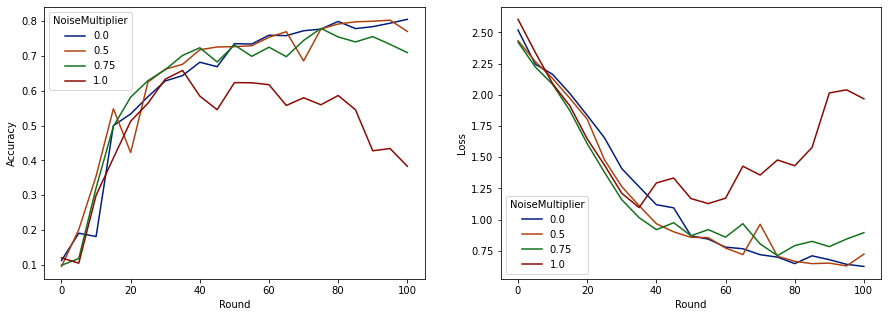
به نظر می رسد که با 50 مشتری مورد انتظار در هر دور، این مدل می تواند ضریب نویز تا 0.5 را بدون کاهش کیفیت مدل تحمل کند. به نظر می رسد ضریب نویز 0.75 کمی باعث کاهش مدل می شود و 1.0 باعث واگرایی مدل می شود.
معمولاً بین کیفیت مدل و حفظ حریم خصوصی تعادل وجود دارد. هرچه از نویز بالاتری استفاده کنیم، میتوانیم حریم خصوصی بیشتری را برای مدت زمان آموزش و تعداد مشتریان مشابه داشته باشیم. برعکس، با سر و صدای کمتر، ممکن است مدل دقیق تری داشته باشیم، اما باید با مشتریان بیشتری در هر دور تمرین کنیم تا به سطح حریم خصوصی مورد نظر خود برسیم.
با آزمایش بالا، ممکن است تصمیم بگیریم که مقدار کمی از زوال مدل در 0.75 قابل قبول است تا مدل نهایی را سریع تر آموزش دهیم، اما فرض کنیم می خواهیم عملکرد مدل 0.5 نویز ضرب کننده را مطابقت دهیم.
اکنون میتوانیم از توابع tensorflow_privacy برای تعیین تعداد مشتری مورد انتظار در هر دور برای به دست آوردن حریم خصوصی قابل قبول استفاده کنیم. روش استاندارد این است که دلتا را تا حدودی کوچکتر از یک از تعداد رکوردهای مجموعه داده انتخاب کنید. این مجموعه داده کل 3383 کاربر آموزشی دارد، بنابراین بیایید (2, 1e-5)-DP را هدف قرار دهیم.
ما از یک جستجوی باینری ساده بر روی تعداد مشتریان در هر دور استفاده می کنیم. تابع tensorflow_privacy ما با استفاده از برآورد اپسیلون بر اساس وانگ و همکاران (2018) و میرونوف و همکاران (2019) .
rdp_orders = ([1.25, 1.5, 1.75, 2., 2.25, 2.5, 3., 3.5, 4., 4.5] +
list(range(5, 64)) + [128, 256, 512])
total_clients = 3383
base_noise_multiplier = 0.5
base_clients_per_round = 50
target_delta = 1e-5
target_eps = 2
def get_epsilon(clients_per_round):
# If we use this number of clients per round and proportionally
# scale up the noise multiplier, what epsilon do we achieve?
q = clients_per_round / total_clients
noise_multiplier = base_noise_multiplier
noise_multiplier *= clients_per_round / base_clients_per_round
rdp = tfp.compute_rdp(
q, noise_multiplier=noise_multiplier, steps=rounds, orders=rdp_orders)
eps, _, _ = tfp.get_privacy_spent(rdp_orders, rdp, target_delta=target_delta)
return clients_per_round, eps, noise_multiplier
def find_needed_clients_per_round():
hi = get_epsilon(base_clients_per_round)
if hi[1] < target_eps:
return hi
# Grow interval exponentially until target_eps is exceeded.
while True:
lo = hi
hi = get_epsilon(2 * lo[0])
if hi[1] < target_eps:
break
# Binary search.
while hi[0] - lo[0] > 1:
mid = get_epsilon((lo[0] + hi[0]) // 2)
if mid[1] > target_eps:
lo = mid
else:
hi = mid
return hi
clients_per_round, _, noise_multiplier = find_needed_clients_per_round()
print(f'To get ({target_eps}, {target_delta})-DP, use {clients_per_round} '
f'clients with noise multiplier {noise_multiplier}.')
To get (2, 1e-05)-DP, use 120 clients with noise multiplier 1.2.
اکنون می توانیم مدل خصوصی نهایی خود را برای انتشار آموزش دهیم.
rounds = 100
noise_multiplier = 1.2
clients_per_round = 120
data_frame = pd.DataFrame()
data_frame = train(rounds, noise_multiplier, clients_per_round, data_frame)
make_plot(data_frame)
Round 0: OrderedDict([('sparse_categorical_accuracy', 0.08260678), ('loss', 2.6334999)])
Round 5: OrderedDict([('sparse_categorical_accuracy', 0.1492212), ('loss', 2.259542)])
Round 10: OrderedDict([('sparse_categorical_accuracy', 0.28847474), ('loss', 2.155699)])
Round 15: OrderedDict([('sparse_categorical_accuracy', 0.3989518), ('loss', 2.0156953)])
Round 20: OrderedDict([('sparse_categorical_accuracy', 0.5086697), ('loss', 1.8261365)])
Round 25: OrderedDict([('sparse_categorical_accuracy', 0.6204692), ('loss', 1.5602393)])
Round 50: OrderedDict([('sparse_categorical_accuracy', 0.70008814), ('loss', 0.91155165)])
Round 75: OrderedDict([('sparse_categorical_accuracy', 0.78421336), ('loss', 0.6820159)])
Round 100: OrderedDict([('sparse_categorical_accuracy', 0.7955525), ('loss', 0.6585961)])
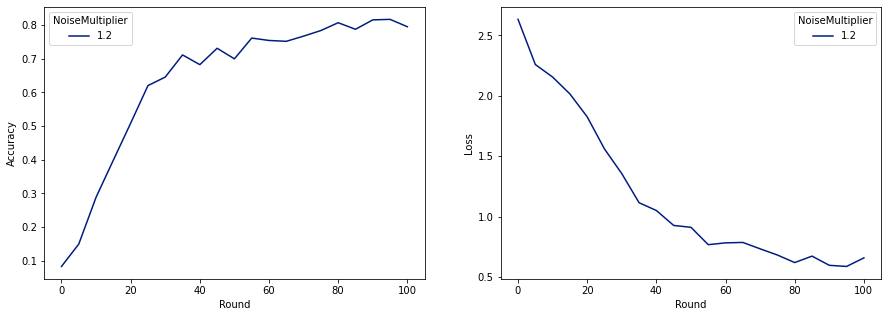
همانطور که می بینیم، مدل نهایی از دست دادن و دقت مشابه مدل آموزش دیده بدون نویز است، اما این مدل (2, 1e-5)-DP را برآورده می کند.