
บทช่วยสอนนี้จะแสดงวิธีใช้ TensorFlow Transform (ไลบรารี tf.Transform ) เพื่อนำการประมวลผลข้อมูลล่วงหน้าสำหรับ Machine Learning (ML) ไปใช้งาน ไลบรารี tf.Transform สำหรับ TensorFlow ช่วยให้คุณกำหนดการแปลงข้อมูลทั้งระดับอินสแตนซ์และแบบเต็มพาสผ่านไปป์ไลน์การประมวลผลข้อมูลล่วงหน้า ไปป์ไลน์เหล่านี้ดำเนินการอย่างมีประสิทธิภาพด้วย Apache Beam และสร้างกราฟ TensorFlow เป็นผลพลอยได้เพื่อใช้การแปลงแบบเดียวกันระหว่างการคาดการณ์เหมือนกับเมื่อมีการให้บริการโมเดล
บทช่วยสอนนี้ให้ตัวอย่างตั้งแต่ต้นจนจบโดยใช้ Dataflow เป็นตัวดำเนินการสำหรับ Apache Beam โดยถือว่าคุณคุ้นเคยกับ BigQuery , Dataflow, Vertex AI และ TensorFlow Keras API นอกจากนี้ยังถือว่าคุณมีประสบการณ์ในการใช้ Jupyter Notebooks เช่น Vertex AI Workbench
บทแนะนำนี้ยังถือว่าคุณคุ้นเคยกับแนวคิดเกี่ยวกับประเภทการประมวลผลล่วงหน้า ความท้าทาย และตัวเลือกบน Google Cloud ดังที่อธิบายไว้ใน การประมวลผลข้อมูลล่วงหน้าสำหรับ ML: ตัวเลือกและคำแนะนำ
วัตถุประสงค์
- ใช้งานไปป์ไลน์ Apache Beam โดยใช้ไลบรารี
tf.Transform - เรียกใช้ไปป์ไลน์ใน Dataflow
- ใช้โมเดล TensorFlow โดยใช้ไลบรารี
tf.Transform - ฝึกฝนและใช้แบบจำลองเพื่อการทำนาย
ค่าใช้จ่าย
บทแนะนำนี้ใช้องค์ประกอบที่เรียกเก็บเงินได้ต่อไปนี้ของ Google Cloud:
หากต้องการประมาณค่าใช้จ่ายในการเรียกใช้บทช่วยสอนนี้ โดยสมมติว่าคุณใช้ทรัพยากรทั้งหมดตลอดทั้งวัน ให้ใช้ เครื่องคำนวณราคา ที่กำหนดค่าไว้ล่วงหน้า
ก่อนที่คุณจะเริ่ม
ในคอนโซล Google Cloud บนหน้าตัวเลือกโปรเจ็กต์ ให้เลือกหรือ สร้างโปรเจ็กต์ Google Cloud
ตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินสำหรับโปรเจ็กต์ระบบคลาวด์ของคุณ เรียนรู้วิธี ตรวจสอบว่ามีการเปิดใช้งานการเรียกเก็บเงินในโครงการหรือไม่
เปิดใช้งาน Dataflow, Vertex AI และ Notebooks API เปิดใช้งาน API
สมุดบันทึก Jupyter สำหรับโซลูชันนี้
สมุดบันทึก Jupyter ต่อไปนี้แสดงตัวอย่างการใช้งาน:
- Notebook 1 ครอบคลุมการประมวลผลข้อมูลล่วงหน้า รายละเอียดมีให้ในส่วน การนำไปป์ไลน์ Apache Beam ไปใช้ ในภายหลัง
- โน๊ตบุ๊ค 2 ครอบคลุมการฝึกอบรมโมเดล รายละเอียดจะมีให้ในส่วน การนำโมเดล TensorFlow ไปใช้ ในภายหลัง
ในส่วนต่อไปนี้ คุณจะโคลนสมุดบันทึกเหล่านี้ จากนั้นคุณดำเนินการสมุดบันทึกเพื่อเรียนรู้วิธีการทำงานของตัวอย่างการใช้งาน
เปิดใช้งานอินสแตนซ์สมุดบันทึกที่จัดการโดยผู้ใช้
ในคอนโซล Google Cloud ให้ไปที่หน้า Vertex AI Workbench
บนแท็บ สมุดบันทึกที่จัดการโดยผู้ใช้ คลิก +สมุดบันทึกใหม่
เลือก TensorFlow Enterprise 2.8 (พร้อม LTS) ที่ไม่มี GPU สำหรับประเภทอินสแตนซ์
คลิก สร้าง
หลังจากที่คุณสร้างสมุดบันทึกแล้ว ให้รอให้พร็อกซีไปที่ JupyterLab เพื่อเริ่มต้นให้เสร็จสิ้น เมื่อพร้อม Open JupyterLab จะแสดงถัดจากชื่อสมุดบันทึก
โคลนสมุดบันทึก
บน แท็บสมุดบันทึกที่จัดการโดยผู้ใช้ ถัดจากชื่อสมุดบันทึก ให้คลิก Open JupyterLab อินเทอร์เฟซ JupyterLab จะเปิดขึ้นในแท็บใหม่
หาก JupyterLab แสดงกล่องโต้ตอบ ที่แนะนำสำหรับการสร้าง ให้คลิก ยกเลิก เพื่อปฏิเสธบิลด์ที่แนะนำ
บนแท็บ Launcher ให้คลิก Terminal
ในหน้าต่างเทอร์มินัล ให้โคลนโน้ตบุ๊ก:
git clone https://github.com/GoogleCloudPlatform/training-data-analyst
ใช้งานไปป์ไลน์ Apache Beam
ส่วนนี้และส่วนถัดไป เรียกใช้ไปป์ไลน์ใน Dataflow จะให้ภาพรวมและบริบทสำหรับ Notebook 1 สมุดบันทึกจะมีตัวอย่างที่เป็นประโยชน์เพื่ออธิบายวิธีใช้ไลบรารี tf.Transform เพื่อประมวลผลข้อมูลล่วงหน้า ตัวอย่างนี้ใช้ชุดข้อมูล Natality ซึ่งใช้ในการทำนายน้ำหนักทารกโดยอิงจากอินพุตต่างๆ ข้อมูลจะถูกจัดเก็บไว้ในตาราง การเกิด สาธารณะใน BigQuery
เรียกใช้โน้ตบุ๊ก 1
ในอินเทอร์เฟซ JupyterLab คลิก File > Open from path จากนั้นป้อนเส้นทางต่อไปนี้:
training-data-analyst/blogs/babyweight_tft/babyweight_tft_keras_01.ipynbคลิก แก้ไข > ล้างเอาต์พุตทั้งหมด
ในส่วน ติดตั้งแพ็คเกจที่จำเป็น ให้ดำเนินการเซลล์แรกเพื่อรันคำสั่ง
pip install apache-beamส่วนสุดท้ายของผลลัพธ์มีดังต่อไปนี้:
Successfully installed ...คุณสามารถละเว้นข้อผิดพลาดในการขึ้นต่อกันในเอาต์พุตได้ คุณไม่จำเป็นต้องรีสตาร์ทเคอร์เนล
ดำเนินการเซลล์ที่สองเพื่อรันคำสั่ง
pip install tensorflow-transformส่วนสุดท้ายของผลลัพธ์มีดังต่อไปนี้:Successfully installed ... Note: you may need to restart the kernel to use updated packages.คุณสามารถละเว้นข้อผิดพลาดในการขึ้นต่อกันในเอาต์พุตได้
คลิก เคอร์เนล > รีสตาร์ทเคอร์เนล
ดำเนินการเซลล์ในส่วน ยืนยันแพ็คเกจที่ติดตั้ง และ สร้าง setup.py เพื่อติดตั้งแพ็คเกจไปยังคอนเทนเนอร์ Dataflow
ในส่วน Set global flags ถัดจาก
PROJECTและBUCKETให้แทนที่your-projectด้วยรหัสโปรเจ็กต์ Cloud ของคุณ จากนั้นดำเนินการเซลล์ดำเนินการเซลล์ที่เหลือทั้งหมดผ่านเซลล์สุดท้ายในสมุดบันทึก สำหรับข้อมูลเกี่ยวกับสิ่งที่ต้องทำในแต่ละเซลล์ ให้ดูคำแนะนำในสมุดบันทึก
ภาพรวมของไปป์ไลน์
ในตัวอย่างสมุดบันทึก Dataflow เรียกใช้ไปป์ไลน์ tf.Transform ในระดับใหญ่เพื่อเตรียมข้อมูลและสร้างอาร์ติแฟกต์ของการแปลง ส่วนต่อๆ ไปในเอกสารนี้จะอธิบายฟังก์ชันที่ดำเนินการแต่ละขั้นตอนในไปป์ไลน์ ขั้นตอนไปป์ไลน์โดยรวมมีดังนี้:
- อ่านข้อมูลการฝึกอบรมจาก BigQuery
- วิเคราะห์และแปลงข้อมูลการฝึกอบรมโดยใช้ไลบรารี
tf.Transform - เขียนข้อมูลการฝึกอบรมที่แปลงแล้วไปยัง Cloud Storage ในรูปแบบ TFRecord
- อ่านข้อมูลการประเมินจาก BigQuery
- แปลงข้อมูลการประเมินโดยใช้กราฟ
transform_fnที่สร้างขึ้นในขั้นตอนที่ 2 - เขียนข้อมูลการฝึกอบรมที่แปลงแล้วไปยัง Cloud Storage ในรูปแบบ TFRecord
- เขียนอาร์ติแฟกต์การเปลี่ยนแปลงลงใน Cloud Storage ซึ่งจะใช้ในการสร้างและส่งออกโมเดลในภายหลัง
ตัวอย่างต่อไปนี้แสดงโค้ด Python สำหรับไปป์ไลน์โดยรวม ส่วนที่ตามมาจะมีคำอธิบายและรายการรหัสสำหรับแต่ละขั้นตอน
def run_transformation_pipeline(args):
pipeline_options = beam.pipeline.PipelineOptions(flags=[], **args)
runner = args['runner']
data_size = args['data_size']
transformed_data_location = args['transformed_data_location']
transform_artefact_location = args['transform_artefact_location']
temporary_dir = args['temporary_dir']
debug = args['debug']
# Instantiate the pipeline
with beam.Pipeline(runner, options=pipeline_options) as pipeline:
with impl.Context(temporary_dir):
# Preprocess train data
step = 'train'
# Read raw train data from BigQuery
raw_train_dataset = read_from_bq(pipeline, step, data_size)
# Analyze and transform raw_train_dataset
transformed_train_dataset, transform_fn = analyze_and_transform(raw_train_dataset, step)
# Write transformed train data to sink as tfrecords
write_tfrecords(transformed_train_dataset, transformed_data_location, step)
# Preprocess evaluation data
step = 'eval'
# Read raw eval data from BigQuery
raw_eval_dataset = read_from_bq(pipeline, step, data_size)
# Transform eval data based on produced transform_fn
transformed_eval_dataset = transform(raw_eval_dataset, transform_fn, step)
# Write transformed eval data to sink as tfrecords
write_tfrecords(transformed_eval_dataset, transformed_data_location, step)
# Write transformation artefacts
write_transform_artefacts(transform_fn, transform_artefact_location)
# (Optional) for debugging, write transformed data as text
step = 'debug'
# Write transformed train data as text if debug enabled
if debug == True:
write_text(transformed_train_dataset, transformed_data_location, step)
อ่านข้อมูลการฝึกอบรมดิบจาก BigQuery
ขั้นตอนแรกคือการอ่านข้อมูลการฝึกดิบจาก BigQuery โดยใช้ฟังก์ชัน read_from_bq ฟังก์ชันนี้ส่งคืนวัตถุ raw_dataset ที่แยกจาก BigQuery คุณส่งค่า data_size และส่งค่า step ของ train หรือ eval คำค้นหาแหล่งที่มา BigQuery สร้างขึ้นโดยใช้ฟังก์ชัน get_source_query ดังที่แสดงในตัวอย่างต่อไปนี้
def read_from_bq(pipeline, step, data_size):
source_query = get_source_query(step, data_size)
raw_data = (
pipeline
| '{} - Read Data from BigQuery'.format(step) >> beam.io.Read(
beam.io.BigQuerySource(query=source_query, use_standard_sql=True))
| '{} - Clean up Data'.format(step) >> beam.Map(prep_bq_row)
)
raw_metadata = create_raw_metadata()
raw_dataset = (raw_data, raw_metadata)
return raw_dataset
ก่อนที่คุณจะดำเนินการประมวลผลล่วงหน้า tf.Transform คุณอาจต้องดำเนินการประมวลผลตาม Apache Beam ทั่วไป รวมถึงการประมวลผลแผนที่ ตัวกรอง กลุ่ม และหน้าต่าง ในตัวอย่าง โค้ดจะล้างบันทึกที่อ่านจาก BigQuery โดยใช้เมธอด beam.Map(prep_bq_row) โดยที่ prep_bq_row เป็นฟังก์ชันที่กำหนดเอง ฟังก์ชันแบบกำหนดเองนี้จะแปลงรหัสตัวเลขสำหรับคุณลักษณะที่เป็นหมวดหมู่ให้เป็นป้ายกำกับที่มนุษย์สามารถอ่านได้
นอกจากนี้ หากต้องการใช้ไลบรารี tf.Transform เพื่อวิเคราะห์และแปลงออบเจ็กต์ raw_data ที่แยกมาจาก BigQuery คุณจะต้องสร้างออบเจ็กต์ raw_dataset ซึ่งเป็นทูเพิลของออบเจ็กต์ raw_data และ raw_metadata ออบเจ็กต์ raw_metadata ถูกสร้างขึ้นโดยใช้ฟังก์ชัน create_raw_metadata ดังต่อไปนี้:
CATEGORICAL_FEATURE_NAMES = ['is_male', 'mother_race']
NUMERIC_FEATURE_NAMES = ['mother_age', 'plurality', 'gestation_weeks']
TARGET_FEATURE_NAME = 'weight_pounds'
def create_raw_metadata():
feature_spec = dict(
[(name, tf.io.FixedLenFeature([], tf.string)) for name in CATEGORICAL_FEATURE_NAMES] +
[(name, tf.io.FixedLenFeature([], tf.float32)) for name in NUMERIC_FEATURE_NAMES] +
[(TARGET_FEATURE_NAME, tf.io.FixedLenFeature([], tf.float32))])
raw_metadata = dataset_metadata.DatasetMetadata(
schema_utils.schema_from_feature_spec(feature_spec))
return raw_metadata
เมื่อคุณดำเนินการเซลล์ในสมุดบันทึกที่ตามหลังเซลล์ที่กำหนดวิธีการนี้ทันที เนื้อหาของออบเจ็กต์ raw_metadata.schema จะปรากฏขึ้น ประกอบด้วยคอลัมน์ต่อไปนี้:
-
gestation_weeks(ประเภท:FLOAT) -
is_male(ประเภท:BYTES) -
mother_age(ประเภท:FLOAT) -
mother_race(ประเภท:BYTES) -
plurality(ประเภท:FLOAT) -
weight_pounds(ประเภท:FLOAT)
แปลงข้อมูลดิบการฝึกอบรม
ลองนึกภาพว่าคุณต้องการใช้การแปลงการประมวลผลล่วงหน้าทั่วไปกับคุณสมบัติดิบอินพุตของข้อมูลการฝึกเพื่อเตรียมสำหรับ ML การเปลี่ยนแปลงเหล่านี้มีทั้งการดำเนินการแบบเต็มและระดับอินสแตนซ์ ดังที่แสดงในตารางต่อไปนี้:
| คุณสมบัติการป้อนข้อมูล | การเปลี่ยนแปลง | สถิติที่จำเป็น | พิมพ์ | คุณสมบัติเอาท์พุต |
|---|---|---|---|---|
weight_pound | ไม่มี | ไม่มี | นา | weight_pound |
mother_age | ทำให้เป็นมาตรฐาน | หมายความว่า var | เต็มผ่าน | mother_age_normalized |
mother_age | การจัดเก็บข้อมูลขนาดเท่ากัน | ปริมาณ | เต็มผ่าน | mother_age_bucketized |
mother_age | คำนวณบันทึก | ไม่มี | ระดับอินสแตนซ์ | mother_age_log |
plurality | ระบุว่าเป็นทารกเดี่ยวหรือหลายคน | ไม่มี | ระดับอินสแตนซ์ | is_multiple |
is_multiple | แปลงค่าที่ระบุเป็นดัชนีตัวเลข | คำศัพท์ | เต็มผ่าน | is_multiple_index |
gestation_weeks | มาตราส่วนระหว่าง 0 ถึง 1 | นาทีสูงสุด | เต็มผ่าน | gestation_weeks_scaled |
mother_race | แปลงค่าที่ระบุเป็นดัชนีตัวเลข | คำศัพท์ | เต็มผ่าน | mother_race_index |
is_male | แปลงค่าที่ระบุเป็นดัชนีตัวเลข | คำศัพท์ | เต็มผ่าน | is_male_index |
การแปลงเหล่านี้ถูกนำไปใช้ในฟังก์ชัน preprocess_fn ซึ่งคาดว่าจะมีพจนานุกรมเทนเซอร์ ( input_features ) และส่งคืนพจนานุกรมของคุณสมบัติที่ประมวลผล ( output_features )
โค้ดต่อไปนี้แสดงการใช้งานฟังก์ชัน preprocess_fn โดยใช้ API การแปลงแบบเต็มพาส tf.Transform (นำหน้าด้วย tft. ) และการดำเนินการระดับอินสแตนซ์ TensorFlow (นำหน้าด้วย tf. )
def preprocess_fn(input_features):
output_features = {}
# target feature
output_features['weight_pounds'] = input_features['weight_pounds']
# normalization
output_features['mother_age_normalized'] = tft.scale_to_z_score(input_features['mother_age'])
# scaling
output_features['gestation_weeks_scaled'] = tft.scale_to_0_1(input_features['gestation_weeks'])
# bucketization based on quantiles
output_features['mother_age_bucketized'] = tft.bucketize(input_features['mother_age'], num_buckets=5)
# you can compute new features based on custom formulas
output_features['mother_age_log'] = tf.math.log(input_features['mother_age'])
# or create flags/indicators
is_multiple = tf.as_string(input_features['plurality'] > tf.constant(1.0))
# convert categorical features to indexed vocab
output_features['mother_race_index'] = tft.compute_and_apply_vocabulary(input_features['mother_race'], vocab_filename='mother_race')
output_features['is_male_index'] = tft.compute_and_apply_vocabulary(input_features['is_male'], vocab_filename='is_male')
output_features['is_multiple_index'] = tft.compute_and_apply_vocabulary(is_multiple, vocab_filename='is_multiple')
return output_features
กรอบงาน tf.Transform มีการแปลงอื่นๆ อีกหลายรายการนอกเหนือจากในตัวอย่างก่อนหน้านี้ ซึ่งรวมถึงรายการในตารางต่อไปนี้:
| การเปลี่ยนแปลง | นำไปใช้กับ | คำอธิบาย |
|---|---|---|
scale_by_min_max | คุณสมบัติตัวเลข | ปรับขนาดคอลัมน์ตัวเลขให้อยู่ในช่วง [ output_min , output_max ] |
scale_to_0_1 | คุณสมบัติตัวเลข | ส่งกลับคอลัมน์ซึ่งเป็นคอลัมน์อินพุตที่ปรับขนาดให้มีช่วง [ 0 , 1 ] |
scale_to_z_score | คุณสมบัติตัวเลข | ส่งกลับคอลัมน์มาตรฐานที่มีค่าเฉลี่ย 0 และความแปรปรวน 1 |
tfidf | คุณสมบัติข้อความ | จับคู่คำศัพท์ใน x กับความถี่ของคำศัพท์ * ความถี่ของเอกสารผกผัน |
compute_and_apply_vocabulary | คุณสมบัติหมวดหมู่ | สร้างคำศัพท์สำหรับคุณลักษณะที่เป็นหมวดหมู่และจับคู่คำศัพท์นี้เป็นจำนวนเต็ม |
ngrams | คุณสมบัติข้อความ | สร้าง SparseTensor ของ n-gram |
hash_strings | คุณสมบัติหมวดหมู่ | แฮชสตริงลงในที่เก็บข้อมูล |
pca | คุณสมบัติตัวเลข | คำนวณ PCA บนชุดข้อมูลโดยใช้ความแปรปรวนร่วมแบบเอนเอียง |
bucketize | คุณสมบัติตัวเลข | ส่งกลับคอลัมน์ที่เก็บข้อมูลที่มีขนาดเท่ากัน (ตามควอนไทล์) โดยมีดัชนีบัคเก็ตที่กำหนดให้กับแต่ละอินพุต |
ในการใช้การแปลงที่ใช้ในฟังก์ชัน preprocess_fn กับอ็อบเจ็กต์ raw_train_dataset ที่ผลิตในขั้นตอนก่อนหน้าของไปป์ไลน์ คุณใช้เมธอด AnalyzeAndTransformDataset เมธอดนี้คาดหวังให้อ็อบเจ็กต์ raw_dataset เป็นอินพุต ใช้ฟังก์ชัน preprocess_fn และสร้างอ็อบเจ็กต์ transformed_dataset และกราฟ transform_fn รหัสต่อไปนี้แสดงให้เห็นถึงการประมวลผลนี้:
def analyze_and_transform(raw_dataset, step):
transformed_dataset, transform_fn = (
raw_dataset
| '{} - Analyze & Transform'.format(step) >> tft_beam.AnalyzeAndTransformDataset(
preprocess_fn, output_record_batches=True)
)
return transformed_dataset, transform_fn
การแปลงจะนำไปใช้กับข้อมูลดิบในสองระยะ: ระยะการวิเคราะห์และระยะการแปลง รูปที่ 3 ภายหลังในเอกสารนี้แสดงวิธีการแยกส่วนวิธี AnalyzeAndTransformDataset ไปเป็นวิธี AnalyzeDataset และวิธี TransformDataset
ขั้นตอนการวิเคราะห์
ในขั้นตอนการวิเคราะห์ ข้อมูลการฝึกอบรมดิบจะได้รับการวิเคราะห์ในกระบวนการแบบเต็มขั้นตอนเพื่อคำนวณสถิติที่จำเป็นสำหรับการเปลี่ยนแปลง ซึ่งรวมถึงการคำนวณค่าเฉลี่ย ความแปรปรวน ต่ำสุด สูงสุด ควอนไทล์ และคำศัพท์ กระบวนการวิเคราะห์คาดว่าจะมีชุดข้อมูลดิบ (ข้อมูลดิบบวกกับข้อมูลเมตาดิบ) และจะสร้างเอาต์พุต 2 รายการ:
-
transform_fn: กราฟ TensorFlow ที่มีสถิติที่คำนวณจากขั้นตอนการวิเคราะห์และตรรกะการเปลี่ยนแปลง (ซึ่งใช้สถิติ) เป็นการดำเนินการระดับอินสแตนซ์ ตามที่กล่าวไว้ในภายหลังใน บันทึกกราฟ กราฟtransform_fnจะถูกบันทึกเพื่อแนบกับฟังก์ชันserving_fnโมเดล ซึ่งทำให้สามารถใช้การแปลงเดียวกันกับจุดข้อมูลการทำนายออนไลน์ได้ -
transform_metadata: ออบเจ็กต์ที่อธิบายสคีมาที่คาดหวังของข้อมูลหลังการแปลง
ขั้นตอนการวิเคราะห์แสดงไว้ในแผนภาพต่อไปนี้ รูปที่ 1:

tf.Transform เครื่องวิเคราะห์ tf.Transform ประกอบด้วย min , max , sum , size , mean , var , covariance , quantiles , vocabulary และ pca
ขั้นตอนการแปลงร่าง
ในขั้นตอนการเปลี่ยนแปลง กราฟ transform_fn ที่สร้างโดยขั้นตอนการวิเคราะห์จะใช้ในการแปลงข้อมูลการฝึกดิบในกระบวนการระดับอินสแตนซ์เพื่อสร้างข้อมูลการฝึกที่ได้รับการเปลี่ยนแปลง ข้อมูลการฝึกที่ได้รับการแปลงจะจับคู่กับข้อมูลเมตาที่ถูกแปลงแล้ว (สร้างโดยขั้นตอนการวิเคราะห์) เพื่อสร้างชุดข้อมูลชุดข้อมูล transformed_train_dataset
ขั้นตอนการแปลงแสดงไว้ในแผนภาพต่อไปนี้ รูปที่ 2:

tf.Transform ในการประมวลผลคุณสมบัติล่วงหน้า คุณจะต้องเรียกใช้การแปลง tensorflow_transform ที่จำเป็น (นำเข้าเป็น tft ในโค้ด) ในการใช้งานฟังก์ชัน preprocess_fn ตัวอย่างเช่น เมื่อคุณเรียกใช้การดำเนินการ tft.scale_to_z_score ไลบรารี tf.Transform จะแปลการเรียกใช้ฟังก์ชันนี้เป็นตัววิเคราะห์ค่าเฉลี่ยและความแปรปรวน คำนวณสถิติในขั้นตอนการวิเคราะห์ จากนั้นใช้สถิติเหล่านี้เพื่อทำให้คุณสมบัติตัวเลขเป็นมาตรฐานในเฟสการแปลง ทั้งหมดนี้เสร็จสิ้นโดยอัตโนมัติโดยการเรียกเมธอด AnalyzeAndTransformDataset(preprocess_fn)
เอนทิตี transformed_metadata.schema ที่สร้างโดยการเรียกนี้ประกอบด้วยคอลัมน์ต่อไปนี้:
-
gestation_weeks_scaled(ประเภท:FLOAT) -
is_male_index(ประเภท:INT, is_categorical:True) -
is_multiple_index(ประเภท:INT, is_categorical:True) -
mother_age_bucketized(ประเภท:INT, is_categorical:True) -
mother_age_log(ประเภท:FLOAT) -
mother_age_normalized(ประเภท:FLOAT) -
mother_race_index(ประเภท:INT, is_categorical:True) -
weight_pounds(ประเภท:FLOAT)
ตามที่อธิบายไว้ใน การดำเนินการประมวลผลล่วงหน้า ในส่วนแรกของชุดข้อมูลนี้ การแปลงคุณลักษณะจะแปลงคุณลักษณะเชิงหมวดหมู่เป็นการแสดงตัวเลข หลังจากการแปลง คุณลักษณะเชิงหมวดหมู่จะแสดงด้วยค่าจำนวนเต็ม ในเอนทิตี transformed_metadata.schema แฟล็ก is_categorical สำหรับคอลัมน์ประเภท INT จะระบุว่าคอลัมน์นั้นแสดงถึงคุณลักษณะที่เป็นหมวดหมู่หรือเป็นคุณลักษณะที่เป็นตัวเลขจริง
เขียนข้อมูลการฝึกอบรมที่ได้รับการเปลี่ยนแปลง
หลังจากที่ข้อมูลการฝึกได้รับการประมวลผลล่วงหน้าด้วยฟังก์ชัน preprocess_fn ผ่านขั้นตอนการวิเคราะห์และการแปลงแล้ว คุณสามารถเขียนข้อมูลลงในซิงก์เพื่อใช้สำหรับการฝึกโมเดล TensorFlow เมื่อคุณดำเนินการไปป์ไลน์ Apache Beam โดยใช้ Dataflow ซิงก์จะเป็น Cloud Storage มิฉะนั้น sink จะเป็นดิสก์ภายในเครื่อง แม้ว่าคุณจะสามารถเขียนข้อมูลเป็นไฟล์ CSV ของไฟล์ที่มีรูปแบบความกว้างคงที่ได้ แต่รูปแบบไฟล์ที่แนะนำสำหรับชุดข้อมูล TensorFlow คือรูปแบบ TFRecord นี่คือรูปแบบไบนารีเชิงบันทึกอย่างง่ายที่ประกอบด้วยข้อความบัฟเฟอร์โปรโตคอล tf.train.Example
แต่ละบันทึก tf.train.Example มีคุณลักษณะอย่างน้อย 1 รายการ สิ่งเหล่านี้จะถูกแปลงเป็นเทนเซอร์เมื่อป้อนเข้ากับโมเดลสำหรับการฝึก รหัสต่อไปนี้เขียนชุดข้อมูลที่แปลงแล้วเป็นไฟล์ TFRecord ในตำแหน่งที่ระบุ:
def write_tfrecords(transformed_dataset, location, step):
from tfx_bsl.coders import example_coder
transformed_data, transformed_metadata = transformed_dataset
(
transformed_data
| '{} - Encode Transformed Data'.format(step) >> beam.FlatMapTuple(
lambda batch, _: example_coder.RecordBatchToExamples(batch))
| '{} - Write Transformed Data'.format(step) >> beam.io.WriteToTFRecord(
file_path_prefix=os.path.join(location,'{}'.format(step)),
file_name_suffix='.tfrecords')
)
อ่าน แปลง และเขียนข้อมูลการประเมิน
หลังจากที่คุณแปลงข้อมูลการฝึกและสร้างกราฟ transform_fn แล้ว คุณจะสามารถใช้เพื่อแปลงข้อมูลการประเมินได้ ขั้นแรก คุณอ่านและล้างข้อมูลการประเมินจาก BigQuery โดยใช้ฟังก์ชัน read_from_bq ที่อธิบายไว้ก่อนหน้าใน การอ่านข้อมูลการฝึกดิบจาก BigQuery และส่งค่า eval สำหรับพารามิเตอร์ step จากนั้น คุณใช้โค้ดต่อไปนี้เพื่อแปลงชุดข้อมูลการประเมินดิบ ( raw_dataset ) เป็นรูปแบบการแปลงที่คาดหวัง ( transformed_dataset ):
def transform(raw_dataset, transform_fn, step):
transformed_dataset = (
(raw_dataset, transform_fn)
| '{} - Transform'.format(step) >> tft_beam.TransformDataset(output_record_batches=True)
)
return transformed_dataset
เมื่อคุณแปลงข้อมูลการประเมิน ระบบจะใช้เฉพาะการดำเนินการระดับอินสแตนซ์เท่านั้น โดยใช้ทั้งตรรกะในกราฟ transform_fn และสถิติที่คำนวณจากขั้นตอนการวิเคราะห์ในข้อมูลการฝึก กล่าวอีกนัยหนึ่ง คุณไม่ได้วิเคราะห์ข้อมูลการประเมินในรูปแบบแบบเต็มเพื่อคำนวณสถิติใหม่ เช่น ค่าเฉลี่ยและความแปรปรวนสำหรับการปรับมาตรฐานคะแนน z ของคุณลักษณะตัวเลขในข้อมูลการประเมิน แต่คุณใช้สถิติที่คำนวณจากข้อมูลการฝึกอบรมเพื่อแปลงข้อมูลการประเมินในระดับอินสแตนซ์แทน
ดังนั้น คุณใช้เมธอด AnalyzeAndTransform ในบริบทของข้อมูลการฝึกเพื่อคำนวณสถิติและแปลงข้อมูล ในเวลาเดียวกัน คุณใช้เมธอด TransformDataset ในบริบทของการแปลงข้อมูลการประเมินเพื่อแปลงข้อมูลโดยใช้สถิติที่คำนวณจากข้อมูลการฝึกเท่านั้น
จากนั้นคุณเขียนข้อมูลลงในซิงก์ (Cloud Storage หรือดิสก์ในเครื่อง ขึ้นอยู่กับรันเนอร์) ในรูปแบบ TFRecord สำหรับการประเมินโมเดล TensorFlow ในระหว่างกระบวนการฝึก ในการดำเนินการนี้ คุณต้องใช้ฟังก์ชัน write_tfrecords ที่กล่าวถึงใน Write Transformered Training Data แผนภาพต่อไปนี้ รูปที่ 3 แสดงให้เห็นว่ากราฟ transform_fn ที่สร้างขึ้นในขั้นตอนการวิเคราะห์ของข้อมูลการฝึกอบรมถูกนำมาใช้ในการแปลงข้อมูลการประเมินอย่างไร

transform_fnบันทึกกราฟ
ขั้นตอนสุดท้ายในไปป์ไลน์การประมวลผลล่วงหน้า tf.Transform คือการจัดเก็บส่วนต่างๆ ซึ่งรวมถึงกราฟ transform_fn ที่สร้างโดยขั้นตอนการวิเคราะห์ในข้อมูลการฝึก รหัสสำหรับการจัดเก็บสิ่งประดิษฐ์จะแสดงอยู่ในฟังก์ชัน write_transform_artefacts ต่อไปนี้:
def write_transform_artefacts(transform_fn, location):
(
transform_fn
| 'Write Transform Artifacts' >> transform_fn_io.WriteTransformFn(location)
)
อาร์ติแฟกต์เหล่านี้จะถูกนำมาใช้ในภายหลังสำหรับการฝึกโมเดลและส่งออกเพื่อให้บริการ นอกจากนี้ ยังมีการสร้างสิ่งประดิษฐ์ต่อไปนี้ ดังแสดงในส่วนถัดไป:
-
saved_model.pb: แสดงถึงกราฟ TensorFlow ที่มีตรรกะการแปลง (กราฟtransform_fn) ซึ่งจะแนบไปกับอินเทอร์เฟซการแสดงโมเดลเพื่อแปลงจุดข้อมูลดิบเป็นรูปแบบที่แปลงแล้ว -
variables: รวมสถิติที่คำนวณระหว่างขั้นตอนการวิเคราะห์ของข้อมูลการฝึก และใช้ในลอจิกการแปลงในอาร์ทิแฟกต์saved_model.pb -
assets: รวมไฟล์คำศัพท์ หนึ่งไฟล์สำหรับแต่ละคุณลักษณะหมวดหมู่ที่ประมวลผลด้วยวิธีcompute_and_apply_vocabularyที่จะใช้ระหว่างการให้บริการเพื่อแปลงค่าที่ระบุดิบของอินพุตเป็นดัชนีตัวเลข -
transformed_metadata: ไดเร็กทอรีที่มีไฟล์schema.jsonที่อธิบายสคีมาของข้อมูลที่แปลงแล้ว
เรียกใช้ไปป์ไลน์ใน Dataflow
หลังจากที่คุณกำหนดไปป์ไลน์ tf.Transform แล้ว คุณจะเรียกใช้ไปป์ไลน์โดยใช้ Dataflow แผนภาพต่อไปนี้ รูปที่ 4 แสดงกราฟการดำเนินการ Dataflow ของไปป์ไลน์ tf.Transform ที่อธิบายไว้ในตัวอย่าง
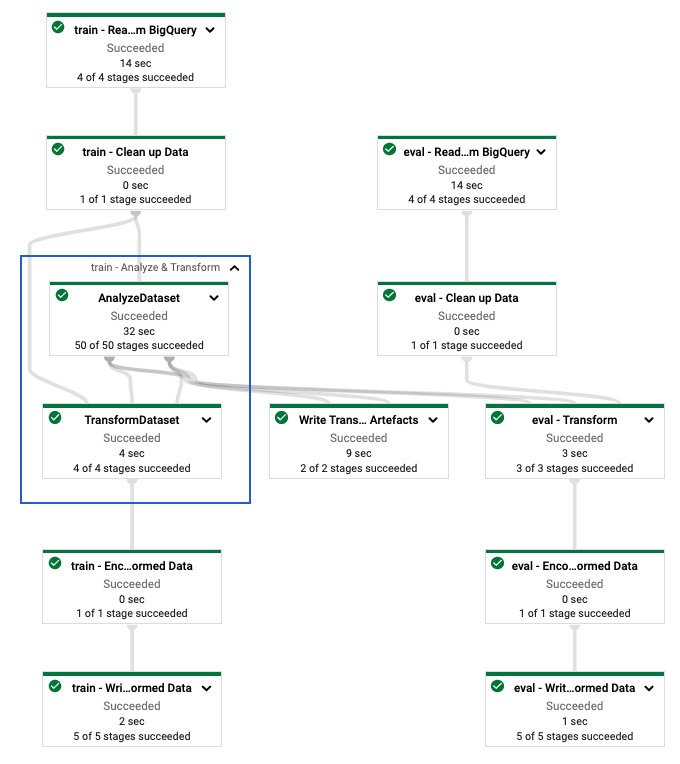
tf.Transform หลังจากที่คุณดำเนินการไปป์ไลน์ Dataflow เพื่อประมวลผลข้อมูลการฝึกอบรมและการประเมินผลล่วงหน้า คุณจะสำรวจออบเจ็กต์ที่สร้างขึ้นใน Cloud Storage ได้โดยดำเนินการเซลล์สุดท้ายในสมุดบันทึก ข้อมูลโค้ดในส่วนนี้จะแสดงผลลัพธ์ โดยที่ YOUR_BUCKET_NAME คือชื่อของที่เก็บข้อมูล Cloud Storage ของคุณ
ข้อมูลการฝึกอบรมและการประเมินผลที่ได้รับการเปลี่ยนแปลงในรูปแบบ TFRecord จะถูกจัดเก็บไว้ในตำแหน่งต่อไปนี้:
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed
อาร์ติแฟกต์การแปลงถูกสร้างขึ้นที่ตำแหน่งต่อไปนี้:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform
รายการต่อไปนี้คือเอาต์พุตของไปป์ไลน์ ซึ่งแสดงออบเจ็กต์ข้อมูลและอาร์ติแฟกต์ที่สร้างขึ้น:
transformed data:
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/eval-00000-of-00001.tfrecords
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/train-00000-of-00002.tfrecords
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/train-00001-of-00002.tfrecords
transformed metadata:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/asset_map
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/schema.pbtxt
transform artefact:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/saved_model.pb
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/variables/
transform assets:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/is_male
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/is_multiple
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/mother_race
ใช้โมเดล TensorFlow
ส่วนนี้และส่วนถัดไป ฝึกอบรมและใช้แบบจำลองสำหรับการทำนาย ให้ภาพรวมและบริบทสำหรับ Notebook 2 สมุดบันทึกมีตัวอย่างโมเดล ML เพื่อทำนายน้ำหนักทารก ในตัวอย่างนี้ โมเดล TensorFlow ได้รับการปรับใช้โดยใช้ Keras API โมเดลใช้ข้อมูลและอาร์ติแฟกต์ที่สร้างขึ้นโดยไปป์ไลน์การประมวลผลล่วงหน้า tf.Transform ที่อธิบายไว้ก่อนหน้านี้
เรียกใช้โน้ตบุ๊ก 2
ในอินเทอร์เฟซ JupyterLab คลิก File > Open from path จากนั้นป้อนเส้นทางต่อไปนี้:
training-data-analyst/blogs/babyweight_tft/babyweight_tft_keras_02.ipynbคลิก แก้ไข > ล้างเอาต์พุตทั้งหมด
ในส่วน ติดตั้งแพ็คเกจที่จำเป็น ให้ดำเนินการเซลล์แรกเพื่อรันคำสั่ง
pip install tensorflow-transformส่วนสุดท้ายของผลลัพธ์มีดังต่อไปนี้:
Successfully installed ... Note: you may need to restart the kernel to use updated packages.คุณสามารถละเว้นข้อผิดพลาดในการขึ้นต่อกันในเอาต์พุตได้
ในเมนู เคอร์เนล เลือก รีสตาร์ทเคอร์เนล
ดำเนินการเซลล์ในส่วน ยืนยันแพ็คเกจที่ติดตั้ง และ สร้าง setup.py เพื่อติดตั้งแพ็คเกจไปยังคอนเทนเนอร์ Dataflow
ในส่วน Set global flags ถัดจาก
PROJECTและBUCKETให้แทนที่your-projectด้วยรหัสโปรเจ็กต์ Cloud ของคุณ จากนั้นดำเนินการเซลล์ดำเนินการเซลล์ที่เหลือทั้งหมดผ่านเซลล์สุดท้ายในสมุดบันทึก สำหรับข้อมูลเกี่ยวกับสิ่งที่ต้องทำในแต่ละเซลล์ ให้ดูคำแนะนำในสมุดบันทึก
ภาพรวมของการสร้างแบบจำลอง
ขั้นตอนในการสร้างแบบจำลองมีดังนี้:
- สร้างคอลัมน์คุณลักษณะโดยใช้ข้อมูลสคีมาที่จัดเก็บไว้ในไดเร็กทอรี
transformed_metadata - สร้างโมเดลแบบกว้างและลึกด้วย Keras API โดยใช้คอลัมน์ฟีเจอร์เป็นอินพุตให้กับโมเดล
- สร้างฟังก์ชัน
tfrecords_input_fnเพื่ออ่านและแยกวิเคราะห์ข้อมูลการฝึกอบรมและการประเมินผลโดยใช้ส่วนการแปลง - ฝึกอบรมและประเมินแบบจำลอง
- ส่งออกโมเดลที่ได้รับการฝึกโดยกำหนดฟังก์ชัน
serving_fnที่มีกราฟtransform_fnแนบอยู่ - ตรวจสอบโมเดลที่ส่งออกโดยใช้เครื่องมือ
saved_model_cli - ใช้แบบจำลองที่ส่งออกเพื่อการคาดการณ์
เอกสารนี้ไม่ได้อธิบายวิธีการสร้างแบบจำลอง ดังนั้นจึงไม่ได้กล่าวถึงรายละเอียดวิธีสร้างหรือฝึกแบบจำลอง อย่างไรก็ตาม ส่วนต่อไปนี้จะแสดงวิธีการใช้ข้อมูลที่จัดเก็บไว้ในไดเร็กทอรี transform_metadata ซึ่งสร้างโดยกระบวนการ tf.Transform เพื่อสร้างคอลัมน์คุณลักษณะของโมเดล เอกสารยังแสดงวิธีการใช้กราฟ transform_fn ซึ่งสร้างโดยกระบวนการ tf.Transform ในฟังก์ชัน serving_fn เมื่อโมเดลถูกส่งออกเพื่อให้บริการ
ใช้สิ่งประดิษฐ์การแปลงที่สร้างขึ้นในการฝึกโมเดล
เมื่อคุณฝึกโมเดล TensorFlow คุณจะใช้ train ที่แปลงแล้วและ eval ผลที่สร้างขึ้นในขั้นตอนการประมวลผลข้อมูลก่อนหน้า ออบเจ็กต์เหล่านี้จะถูกจัดเก็บเป็นไฟล์ที่แบ่งส่วนในรูปแบบ TFRecord ข้อมูลสคีมาในไดเร็กทอรี transformed_metadata ที่สร้างขึ้นในขั้นตอนก่อนหน้าอาจมีประโยชน์ในการแยกวิเคราะห์ข้อมูล (อ็อบเจ็กต์ tf.train.Example ) เพื่อป้อนเข้าสู่โมเดลสำหรับการฝึกอบรมและการประเมินผล
แยกวิเคราะห์ข้อมูล
เนื่องจากคุณอ่านไฟล์ในรูปแบบ TFRecord เพื่อป้อนโมเดลด้วยข้อมูลการฝึกอบรมและการประเมินผล คุณจึงต้องแยกวิเคราะห์ออบเจ็กต์ tf.train.Example แต่ละรายการในไฟล์เพื่อสร้างพจนานุกรมของคุณสมบัติ (เทนเซอร์) เพื่อให้แน่ใจว่าคุณลักษณะต่างๆ ได้รับการแมปกับเลเยอร์อินพุตโมเดลโดยใช้คอลัมน์คุณลักษณะ ซึ่งทำหน้าที่เป็นอินเทอร์เฟซการฝึกอบรมโมเดลและการประเมินผล หากต้องการแยกวิเคราะห์ข้อมูล คุณใช้วัตถุ TFTransformOutput ที่สร้างขึ้นจากส่วนที่สร้างขึ้นในขั้นตอนก่อนหน้า:
สร้างออบเจ็กต์
TFTransformOutputจากส่วนที่สร้างขึ้นและบันทึกในขั้นตอนการประมวลผลล่วงหน้าก่อนหน้านี้ ตามที่อธิบายไว้ในส่วน บันทึกกราฟ :tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)แยกวัตถุ
feature_specออกจากวัตถุTFTransformOutput:tf_transform_output.transformed_feature_spec()ใช้วัตถุ
feature_specเพื่อระบุคุณลักษณะที่มีอยู่ในวัตถุtf.train.Exampleเช่นเดียวกับในฟังก์ชันtfrecords_input_fn:def tfrecords_input_fn(files_name_pattern, batch_size=512): tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR) TARGET_FEATURE_NAME = 'weight_pounds' batched_dataset = tf.data.experimental.make_batched_features_dataset( file_pattern=files_name_pattern, batch_size=batch_size, features=tf_transform_output.transformed_feature_spec(), reader=tf.data.TFRecordDataset, label_key=TARGET_FEATURE_NAME, shuffle=True).prefetch(tf.data.experimental.AUTOTUNE) return batched_dataset
สร้างคอลัมน์คุณลักษณะ
ไปป์ไลน์สร้างข้อมูลสคีมาในไดเร็กทอรี transformed_metadata ที่อธิบายสคีมาของข้อมูลที่แปลงแล้วซึ่งคาดว่าจะได้รับจากโมเดลสำหรับการฝึกอบรมและการประเมินผล สคีมาประกอบด้วยชื่อคุณลักษณะและประเภทข้อมูล ดังต่อไปนี้:
-
gestation_weeks_scaled(ประเภท:FLOAT) -
is_male_index(ประเภท:INT, is_categorical:True) -
is_multiple_index(ประเภท:INT, is_categorical:True) -
mother_age_bucketized(ประเภท:INT, is_categorical:True) -
mother_age_log(ประเภท:FLOAT) -
mother_age_normalized(ประเภท:FLOAT) -
mother_race_index(ประเภท:INT, is_categorical:True) -
weight_pounds(ประเภท:FLOAT)
หากต้องการดูข้อมูลนี้ ให้ใช้คำสั่งต่อไปนี้:
transformed_metadata = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR).transformed_metadata
transformed_metadata.schema
รหัสต่อไปนี้แสดงวิธีที่คุณใช้ชื่อคุณลักษณะเพื่อสร้างคอลัมน์คุณลักษณะ:
def create_wide_and_deep_feature_columns():
deep_feature_columns = []
wide_feature_columns = []
inputs = {}
categorical_columns = {}
# Select features you've checked from the metadata
# Categorical features are associated with the vocabulary size (starting from 0)
numeric_features = ['mother_age_log', 'mother_age_normalized', 'gestation_weeks_scaled']
categorical_features = [('is_male_index', 1), ('is_multiple_index', 1),
('mother_age_bucketized', 4), ('mother_race_index', 10)]
for feature in numeric_features:
deep_feature_columns.append(tf.feature_column.numeric_column(feature))
inputs[feature] = layers.Input(shape=(), name=feature, dtype='float32')
for feature, vocab_size in categorical_features:
categorical_columns[feature] = (
tf.feature_column.categorical_column_with_identity(feature, num_buckets=vocab_size+1))
wide_feature_columns.append(tf.feature_column.indicator_column(categorical_columns[feature]))
inputs[feature] = layers.Input(shape=(), name=feature, dtype='int64')
mother_race_X_mother_age_bucketized = tf.feature_column.crossed_column(
[categorical_columns['mother_age_bucketized'],
categorical_columns['mother_race_index']], 55)
wide_feature_columns.append(tf.feature_column.indicator_column(mother_race_X_mother_age_bucketized))
mother_race_X_mother_age_bucketized_embedded = tf.feature_column.embedding_column(
mother_race_X_mother_age_bucketized, 5)
deep_feature_columns.append(mother_race_X_mother_age_bucketized_embedded)
return wide_feature_columns, deep_feature_columns, inputs
โค้ดจะสร้างคอลัมน์ tf.feature_column.numeric_column สำหรับฟีเจอร์ที่เป็นตัวเลข และคอลัมน์ tf.feature_column.categorical_column_with_identity สำหรับฟีเจอร์ที่เป็นหมวดหมู่
คุณยังสามารถสร้างคอลัมน์คุณลักษณะเพิ่มเติมตามที่อธิบายไว้ใน ตัวเลือก C: TensorFlow ในส่วนแรกของซีรี่ส์นี้ ในตัวอย่างที่ใช้สำหรับซีรีส์นี้ คุณลักษณะใหม่จะถูกสร้างขึ้น mother_race_X_mother_age_bucketized โดยการข้ามคุณลักษณะ mother_race และ mother_age_bucketized โดยใช้คอลัมน์คุณลักษณะ tf.feature_column.crossed_column การแสดงจุดสนใจแบบกากบาทในมิติต่ำและหนาแน่นนี้สร้างขึ้นโดยใช้คอลัมน์คุณลักษณะ tf.feature_column.embedding_column
แผนภาพต่อไปนี้ รูปที่ 5 แสดงข้อมูลที่แปลงแล้วและวิธีการใช้ข้อมูลเมตาที่แปลงแล้วเพื่อกำหนดและฝึกโมเดล TensorFlow:

ส่งออกแบบจำลองสำหรับการแสดงการคาดการณ์
หลังจากที่คุณฝึกโมเดล TensorFlow ด้วย Keras API คุณจะส่งออกโมเดลที่ได้รับการฝึกเป็นอ็อบเจ็กต์ SavedModel เพื่อให้สามารถให้บริการจุดข้อมูลใหม่สำหรับการคาดการณ์ เมื่อคุณส่งออกโมเดล คุณต้องกำหนดอินเทอร์เฟซของโมเดล ซึ่งก็คือสกีมาคุณลักษณะอินพุตที่คาดหวังระหว่างการแสดงผล สคีมาคุณลักษณะอินพุตนี้ถูกกำหนดไว้ในฟังก์ชัน serving_fn ดังที่แสดงในโค้ดต่อไปนี้:
def export_serving_model(model, output_dir):
tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)
# The layer has to be saved to the model for Keras tracking purposes.
model.tft_layer = tf_transform_output.transform_features_layer()
@tf.function
def serveing_fn(uid, is_male, mother_race, mother_age, plurality, gestation_weeks):
features = {
'is_male': is_male,
'mother_race': mother_race,
'mother_age': mother_age,
'plurality': plurality,
'gestation_weeks': gestation_weeks
}
transformed_features = model.tft_layer(features)
outputs = model(transformed_features)
# The prediction results have multiple elements in general.
# But we need only the first element in our case.
outputs = tf.map_fn(lambda item: item[0], outputs)
return {'uid': uid, 'weight': outputs}
concrete_serving_fn = serveing_fn.get_concrete_function(
tf.TensorSpec(shape=[None], dtype=tf.string, name='uid'),
tf.TensorSpec(shape=[None], dtype=tf.string, name='is_male'),
tf.TensorSpec(shape=[None], dtype=tf.string, name='mother_race'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='mother_age'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='plurality'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='gestation_weeks')
)
signatures = {'serving_default': concrete_serving_fn}
model.save(output_dir, save_format='tf', signatures=signatures)
ในระหว่างการให้บริการ โมเดลคาดหวังจุดข้อมูลในรูปแบบดิบ (นั่นคือ คุณลักษณะดิบก่อนการแปลง) ดังนั้นฟังก์ชัน serving_fn จึงได้รับคุณสมบัติดิบและจัดเก็บไว้ในออบเจ็กต์ features เป็นพจนานุกรม Python อย่างไรก็ตาม ตามที่กล่าวไว้ก่อนหน้านี้ โมเดลที่ได้รับการฝึกอบรมคาดหวังจุดข้อมูลในสคีมาที่ได้รับการแปลง ในการแปลงคุณลักษณะดิบเป็นอ็อบเจ็กต์ transformed_features ที่อินเทอร์เฟซโมเดลคาดหวัง คุณใช้กราฟ transform_fn ที่บันทึกไว้กับอ็อบเจ็กต์ features ด้วยขั้นตอนต่อไปนี้:
สร้างออบเจ็กต์
TFTransformOutputจากส่วนที่สร้างขึ้นและบันทึกไว้ในขั้นตอนการประมวลผลล่วงหน้าก่อนหน้านี้:tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)สร้างวัตถุ
TransformFeaturesLayerจากวัตถุTFTransformOutput:model.tft_layer = tf_transform_output.transform_features_layer()ใช้กราฟ
transform_fnโดยใช้วัตถุTransformFeaturesLayer:transformed_features = model.tft_layer(features)
แผนภาพต่อไปนี้ รูปที่ 6 แสดงขั้นตอนสุดท้ายของการส่งออกโมเดลเพื่อให้บริการ:

transform_fn ฝึกฝนและใช้แบบจำลองเพื่อการทำนาย
คุณสามารถฝึกโมเดลภายในเครื่องได้โดยการรันเซลล์ของโน้ตบุ๊ก สำหรับตัวอย่างวิธีจัดแพ็กเกจโค้ดและฝึกโมเดลของคุณตามขนาดโดยใช้ Vertex AI Training โปรดดูตัวอย่างและคำแนะนำในพื้นที่เก็บข้อมูล GitHub ตัวอย่าง cloudml ของ Google Cloud
เมื่อคุณตรวจสอบอ็อบเจ็กต์ SavedModel ที่เอ็กซ์พอร์ตโดยใช้เครื่องมือ saved_model_cli คุณจะเห็นว่าองค์ประกอบ inputs ของคำจำกัดความลายเซ็น signature_def มีคุณลักษณะดิบ ดังที่แสดงในตัวอย่างต่อไปนี้:
signature_def['serving_default']:
The given SavedModel SignatureDef contains the following input(s):
inputs['gestation_weeks'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_gestation_weeks:0
inputs['is_male'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_is_male:0
inputs['mother_age'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_mother_age:0
inputs['mother_race'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_mother_race:0
inputs['plurality'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_plurality:0
inputs['uid'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_uid:0
The given SavedModel SignatureDef contains the following output(s):
outputs['uid'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: StatefulPartitionedCall_6:0
outputs['weight'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: StatefulPartitionedCall_6:1
Method name is: tensorflow/serving/predict
เซลล์ที่เหลือของสมุดบันทึกจะแสดงวิธีใช้โมเดลที่ส่งออกสำหรับการคาดคะเนเฉพาะที่ และวิธีการปรับใช้โมเดลเป็นไมโครเซอร์วิสโดยใช้ Vertex AI Prediction สิ่งสำคัญคือต้องเน้นว่าจุดข้อมูลอินพุต (ตัวอย่าง) อยู่ในสคีมาดิบในทั้งสองกรณี
ทำความสะอาด
เพื่อหลีกเลี่ยงไม่ให้มีการเรียกเก็บเงินเพิ่มเติมในบัญชี Google Cloud ของคุณสำหรับทรัพยากรที่ใช้ในบทแนะนำนี้ ให้ลบโปรเจ็กต์ที่มีทรัพยากรดังกล่าว
ลบโครงการ
ในคอนโซล Google Cloud ให้ไปที่หน้า จัดการทรัพยากร
ในรายการโครงการ ให้เลือกโครงการที่คุณต้องการลบ จากนั้นคลิก ลบ
ในกล่องโต้ตอบ ให้พิมพ์รหัสโปรเจ็กต์ จากนั้นคลิก ปิดเครื่อง เพื่อลบโปรเจ็กต์
อะไรต่อไป
- หากต้องการเรียนรู้เกี่ยวกับแนวคิด ความท้าทาย และตัวเลือกของการประมวลผลข้อมูลล่วงหน้าสำหรับแมชชีนเลิร์นนิงบน Google Cloud โปรดดูบทความแรกในชุดนี้ การประมวลผลข้อมูลล่วงหน้าสำหรับ ML: ตัวเลือกและคำแนะนำ
- สำหรับข้อมูลเพิ่มเติมเกี่ยวกับวิธีการใช้งาน จัดทำแพ็กเกจ และเรียกใช้ไปป์ไลน์ tf.Transform บน Dataflow โปรดดูตัวอย่าง การทำนายรายได้ด้วยชุดข้อมูล Census
- รับความเชี่ยวชาญพิเศษของ Coursera บน ML ด้วย TensorFlow บน Google Cloud
- เรียนรู้เกี่ยวกับแนวทางปฏิบัติที่ดีที่สุดสำหรับวิศวกรรม ML ใน กฎของ ML
- สำหรับสถาปัตยกรรมอ้างอิง ไดอะแกรม และแนวทางปฏิบัติที่ดีที่สุดเพิ่มเติม โปรดสำรวจ Cloud Architecture Center