
| | |  Ver fuente en GitHub Ver fuente en GitHub | |
Esta guía utiliza el aprendizaje automático para clasificar las flores de iris por especies. Utiliza TensorFlow para:
- Construir un modelo,
- Entrene este modelo con datos de ejemplo y
- Usa el modelo para hacer predicciones sobre datos desconocidos.
Programación TensorFlow
Esta guía utiliza estos conceptos de TensorFlow de alto nivel:
- Utilice el entorno de desarrollo de ejecución impaciente predeterminado de TensorFlow,
- Importar datos con la API de conjuntos de datos,
- Cree modelos y capas con la API de Keras de TensorFlow.
Este tutorial está estructurado como muchos programas de TensorFlow:
- Importe y analice el conjunto de datos.
- Seleccione el tipo de modelo.
- Entrena al modelo.
- Evaluar la eficacia del modelo.
- Utilice el modelo entrenado para hacer predicciones.
programa de instalación
Configurar importaciones
Importe TensorFlow y los demás módulos de Python necesarios. De manera predeterminada, TensorFlow usa una ejecución entusiasta para evaluar las operaciones de inmediato, devolviendo valores concretos en lugar de crear un gráfico computacional que se ejecuta más tarde. Si está acostumbrado a REPL o a la consola interactiva de python , le resultará familiar.
import os
import matplotlib.pyplot as plt
import tensorflow as tf
print("TensorFlow version: {}".format(tf.__version__))
print("Eager execution: {}".format(tf.executing_eagerly()))
TensorFlow version: 2.8.0-rc1 Eager execution: True
El problema de clasificación del iris
Imagina que eres un botánico que busca una forma automatizada de categorizar cada flor de Iris que encuentras. El aprendizaje automático proporciona muchos algoritmos para clasificar las flores estadísticamente. Por ejemplo, un sofisticado programa de aprendizaje automático podría clasificar flores basándose en fotografías. Nuestras ambiciones son más modestas: vamos a clasificar las flores de iris según las medidas de largo y ancho de sus sépalos y pétalos .
El género Iris comprende alrededor de 300 especies, pero nuestro programa solo clasificará las siguientes tres:
- Iris setosa
- Iris virgen
- Iris versicolor
 |
| Figura 1. Iris setosa (por Radomil , CC BY-SA 3.0), Iris versicolor , (por Dlanglois , CC BY-SA 3.0) e Iris virginica (por Frank Mayfield , CC BY-SA 2.0). |
Afortunadamente, alguien ya ha creado un conjunto de datos de 120 flores de iris con las medidas de sépalos y pétalos. Este es un conjunto de datos clásico que es popular para los problemas de clasificación de aprendizaje automático para principiantes.
Importar y analizar el conjunto de datos de entrenamiento
Descargue el archivo del conjunto de datos y conviértalo en una estructura que pueda ser utilizada por este programa de Python.
Descargar el conjunto de datos
Descargue el archivo del conjunto de datos de entrenamiento mediante la función tf.keras.utils.get_file . Esto devuelve la ruta del archivo del archivo descargado:
train_dataset_url = "https://storage.googleapis.com/download.tensorflow.org/data/iris_training.csv"
train_dataset_fp = tf.keras.utils.get_file(fname=os.path.basename(train_dataset_url),
origin=train_dataset_url)
print("Local copy of the dataset file: {}".format(train_dataset_fp))
Local copy of the dataset file: /home/kbuilder/.keras/datasets/iris_training.csv
Inspeccionar los datos
Este conjunto de datos, iris_training.csv , es un archivo de texto sin formato que almacena datos tabulares formateados como valores separados por comas (CSV). Use el comando head -n5 para echar un vistazo a las primeras cinco entradas:
head -n5 {train_dataset_fp}
120,4,setosa,versicolor,virginica 6.4,2.8,5.6,2.2,2 5.0,2.3,3.3,1.0,1 4.9,2.5,4.5,1.7,2 4.9,3.1,1.5,0.1,0
Desde esta vista del conjunto de datos, observe lo siguiente:
- La primera línea es un encabezado que contiene información sobre el conjunto de datos:
- Hay 120 ejemplos en total. Cada ejemplo tiene cuatro características y uno de los tres posibles nombres de etiquetas.
- Las filas subsiguientes son registros de datos, un ejemplo por línea, donde:
- Los primeros cuatro campos son características : estas son las características de un ejemplo. Aquí, los campos contienen números flotantes que representan las medidas de las flores.
- La última columna es la etiqueta : este es el valor que queremos predecir. Para este conjunto de datos, es un valor entero de 0, 1 o 2 que corresponde al nombre de una flor.
Escribámoslo en código:
# column order in CSV file
column_names = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species']
feature_names = column_names[:-1]
label_name = column_names[-1]
print("Features: {}".format(feature_names))
print("Label: {}".format(label_name))
Features: ['sepal_length', 'sepal_width', 'petal_length', 'petal_width'] Label: species
Cada etiqueta está asociada con un nombre de cadena (por ejemplo, "setosa"), pero el aprendizaje automático generalmente se basa en valores numéricos. Los números de etiqueta se asignan a una representación con nombre, como:
-
0: Iris setosa -
1: Iris versicolor -
2: Iris virgen
Para obtener más información sobre funciones y etiquetas, consulte la sección Terminología de ML del Curso intensivo de aprendizaje automático .
class_names = ['Iris setosa', 'Iris versicolor', 'Iris virginica']
Crear un tf.data.Dataset
La API de conjunto de datos de TensorFlow maneja muchos casos comunes para cargar datos en un modelo. Esta es una API de alto nivel para leer datos y transformarlos en un formulario utilizado para el entrenamiento.
Dado que el conjunto de datos es un archivo de texto con formato CSV, use la función tf.data.experimental.make_csv_dataset para analizar los datos en un formato adecuado. Dado que esta función genera datos para los modelos de entrenamiento, el comportamiento predeterminado es mezclar los datos ( shuffle=True, shuffle_buffer_size=10000 ) y repetir el conjunto de datos para siempre ( num_epochs=None ). También configuramos el parámetro batch_size :
batch_size = 32
train_dataset = tf.data.experimental.make_csv_dataset(
train_dataset_fp,
batch_size,
column_names=column_names,
label_name=label_name,
num_epochs=1)
La función make_csv_dataset devuelve un tf.data.Dataset de (features, label) pares, donde features es un diccionario: {'feature_name': value}
Estos objetos de conjunto de Dataset son iterables. Veamos un lote de características:
features, labels = next(iter(train_dataset))
print(features)
OrderedDict([('sepal_length', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([5. , 7.4, 6. , 7.2, 5.9, 5.8, 5. , 5. , 7.7, 5.7, 6.3, 5.8, 5. ,
4.8, 6.6, 6.3, 5.4, 6.9, 4.8, 6.6, 5.8, 7.7, 6.7, 7.6, 5.5, 6.4,
5.6, 6.4, 4.4, 4.5, 6.5, 6.3], dtype=float32)>), ('sepal_width', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([3.5, 2.8, 2.7, 3.2, 3. , 2.6, 2. , 3.4, 3. , 2.8, 2.3, 2.7, 3.6,
3.1, 2.9, 3.3, 3. , 3.1, 3. , 3. , 4. , 2.6, 3. , 3. , 2.4, 2.7,
2.7, 2.8, 3. , 2.3, 2.8, 2.5], dtype=float32)>), ('petal_length', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([1.6, 6.1, 5.1, 6. , 5.1, 4. , 3.5, 1.6, 6.1, 4.5, 4.4, 5.1, 1.4,
1.6, 4.6, 4.7, 4.5, 5.1, 1.4, 4.4, 1.2, 6.9, 5. , 6.6, 3.7, 5.3,
4.2, 5.6, 1.3, 1.3, 4.6, 5. ], dtype=float32)>), ('petal_width', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([0.6, 1.9, 1.6, 1.8, 1.8, 1.2, 1. , 0.4, 2.3, 1.3, 1.3, 1.9, 0.2,
0.2, 1.3, 1.6, 1.5, 2.3, 0.3, 1.4, 0.2, 2.3, 1.7, 2.1, 1. , 1.9,
1.3, 2.1, 0.2, 0.3, 1.5, 1.9], dtype=float32)>)])
Tenga en cuenta que las características similares se agrupan o se agrupan por lotes . Los campos de cada fila de ejemplo se agregan a la matriz de características correspondiente. Cambie el tamaño de batch_size para establecer la cantidad de ejemplos almacenados en estas matrices de características.
Puede comenzar a ver algunos clústeres trazando algunas características del lote:
plt.scatter(features['petal_length'],
features['sepal_length'],
c=labels,
cmap='viridis')
plt.xlabel("Petal length")
plt.ylabel("Sepal length")
plt.show()
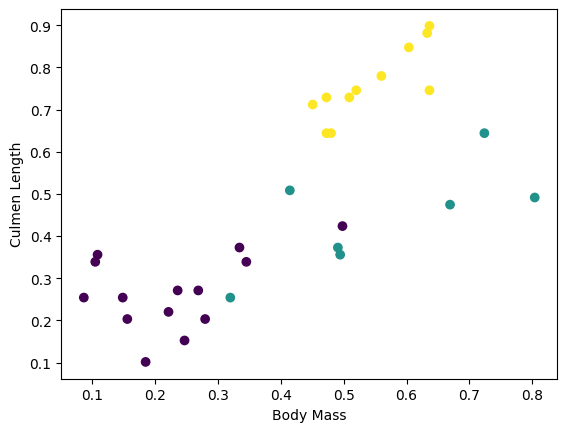
Para simplificar el paso de creación del modelo, cree una función para volver a empaquetar el diccionario de funciones en una sola matriz con forma: (batch_size, num_features) .
Esta función usa el método tf.stack que toma valores de una lista de tensores y crea un tensor combinado en la dimensión especificada:
def pack_features_vector(features, labels):
"""Pack the features into a single array."""
features = tf.stack(list(features.values()), axis=1)
return features, labels
Luego use el método tf.data.Dataset#map para empaquetar las features de cada par (features,label) en el conjunto de datos de entrenamiento:
train_dataset = train_dataset.map(pack_features_vector)
El elemento de características del conjunto de Dataset ahora son matrices con forma (batch_size, num_features) . Veamos los primeros ejemplos:
features, labels = next(iter(train_dataset))
print(features[:5])
tf.Tensor( [[4.9 3. 1.4 0.2] [6.1 3. 4.9 1.8] [6.1 2.6 5.6 1.4] [6.9 3.2 5.7 2.3] [6.7 3.1 4.4 1.4]], shape=(5, 4), dtype=float32)
Seleccione el tipo de modelo
¿Por qué modelo?
Un modelo es una relación entre las características y la etiqueta. Para el problema de clasificación de Iris, el modelo define la relación entre las medidas de sépalos y pétalos y las especies de Iris pronosticadas. Algunos modelos simples se pueden describir con unas pocas líneas de álgebra, pero los modelos complejos de aprendizaje automático tienen una gran cantidad de parámetros que son difíciles de resumir.
¿Podría determinar la relación entre las cuatro características y la especie Iris sin usar el aprendizaje automático? Es decir, ¿podría usar técnicas de programación tradicionales (por ejemplo, muchas declaraciones condicionales) para crear un modelo? Tal vez, si analizó el conjunto de datos el tiempo suficiente para determinar las relaciones entre las medidas de pétalos y sépalos para una especie en particular. Y esto se vuelve difícil, tal vez imposible, en conjuntos de datos más complicados. Un buen enfoque de aprendizaje automático determina el modelo para usted . Si introduce suficientes ejemplos representativos en el tipo de modelo de aprendizaje automático correcto, el programa descubrirá las relaciones por usted.
Seleccione el modelo
Necesitamos seleccionar el tipo de modelo a entrenar. Hay muchos tipos de modelos y elegir uno bueno requiere experiencia. Este tutorial utiliza una red neuronal para resolver el problema de clasificación de Iris. Las redes neuronales pueden encontrar relaciones complejas entre las características y la etiqueta. Es un gráfico altamente estructurado, organizado en una o más capas ocultas . Cada capa oculta consta de una o más neuronas . Hay varias categorías de redes neuronales y este programa utiliza una red neuronal densa o totalmente conectada : las neuronas en una capa reciben conexiones de entrada de cada neurona en la capa anterior. Por ejemplo, la figura 2 ilustra una red neuronal densa que consta de una capa de entrada, dos capas ocultas y una capa de salida:
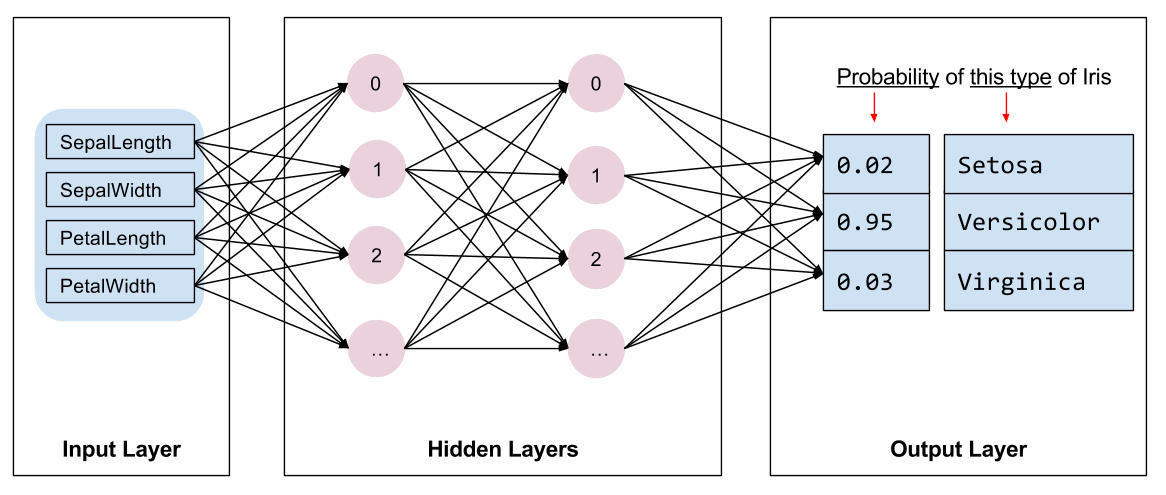 |
| Figura 2. Una red neuronal con funciones, capas ocultas y predicciones. |
Cuando el modelo de la Figura 2 se entrena y alimenta con un ejemplo sin etiquetar, produce tres predicciones: la probabilidad de que esta flor sea la especie de Iris dada. Esta predicción se llama inferencia . Para este ejemplo, la suma de las predicciones de salida es 1,0. En la Figura 2, esta predicción se desglosa como: 0.02 para Iris setosa , 0.95 para Iris versicolor y 0.03 para Iris virginica . Esto significa que el modelo predice, con un 95 % de probabilidad, que una flor de ejemplo sin etiquetar es una Iris versicolor .
Crear un modelo usando Keras
La API TensorFlow tf.keras es la forma preferida de crear modelos y capas. Esto facilita la creación de modelos y la experimentación, mientras que Keras maneja la complejidad de conectar todo.
El modelo tf.keras.Sequential es una pila lineal de capas. Su constructor toma una lista de instancias de capa, en este caso, dos capas tf.keras.layers.Dense con 10 nodos cada una y una capa de salida con 3 nodos que representan nuestras predicciones de etiquetas. El parámetro input_shape de la primera capa corresponde a la cantidad de entidades del conjunto de datos y es obligatorio:
model = tf.keras.Sequential([
tf.keras.layers.Dense(10, activation=tf.nn.relu, input_shape=(4,)), # input shape required
tf.keras.layers.Dense(10, activation=tf.nn.relu),
tf.keras.layers.Dense(3)
])
La función de activación determina la forma de salida de cada nodo en la capa. Estas no linealidades son importantes; sin ellas, el modelo sería equivalente a una sola capa. Hay muchas tf.keras.activations , pero ReLU es común para capas ocultas.
El número ideal de capas y neuronas ocultas depende del problema y del conjunto de datos. Al igual que muchos aspectos del aprendizaje automático, elegir la mejor forma de la red neuronal requiere una combinación de conocimiento y experimentación. Como regla general, aumentar la cantidad de capas y neuronas ocultas generalmente crea un modelo más poderoso, que requiere más datos para entrenar de manera efectiva.
Usando el modelo
Echemos un vistazo rápido a lo que este modelo le hace a un lote de características:
predictions = model(features)
predictions[:5]
<tf.Tensor: shape=(5, 3), dtype=float32, numpy=
array([[-4.0874639e+00, 1.5199981e-03, -9.9991310e-01],
[-5.3246369e+00, -1.8366380e-01, -1.3161827e+00],
[-5.1154275e+00, -2.8129923e-01, -1.3305402e+00],
[-6.0694785e+00, -2.1251860e-01, -1.5091233e+00],
[-5.6730523e+00, -1.4321266e-01, -1.4437559e+00]], dtype=float32)>
Aquí, cada ejemplo devuelve un logit para cada clase.
Para convertir estos logits en una probabilidad para cada clase, use la función softmax :
tf.nn.softmax(predictions[:5])
<tf.Tensor: shape=(5, 3), dtype=float32, numpy=
array([[0.01210616, 0.7224865 , 0.26540732],
[0.00440638, 0.75297093, 0.24262273],
[0.00585618, 0.7362918 , 0.25785193],
[0.00224076, 0.7835035 , 0.21425581],
[0.00310779, 0.7834839 , 0.21340834]], dtype=float32)>
Tomar el tf.argmax entre clases nos da el índice de clase predicho. Sin embargo, el modelo aún no ha sido entrenado, por lo que estas no son buenas predicciones:
print("Prediction: {}".format(tf.argmax(predictions, axis=1)))
print(" Labels: {}".format(labels))
Prediction: [1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1]
Labels: [0 2 2 2 1 1 0 1 1 2 2 1 0 2 2 2 1 0 2 2 1 0 2 1 2 0 1 1 2 2 1 2]
entrenar al modelo
El entrenamiento es la etapa del aprendizaje automático cuando el modelo se optimiza gradualmente o el modelo aprende el conjunto de datos. El objetivo es aprender lo suficiente sobre la estructura del conjunto de datos de entrenamiento para hacer predicciones sobre datos no vistos. Si aprende demasiado sobre el conjunto de datos de entrenamiento, las predicciones solo funcionarán para los datos que ha visto y no serán generalizables. Este problema se llama sobreajuste ; es como memorizar las respuestas en lugar de entender cómo resolver un problema.
El problema de clasificación de Iris es un ejemplo de aprendizaje automático supervisado : el modelo se entrena a partir de ejemplos que contienen etiquetas. En el aprendizaje automático no supervisado , los ejemplos no contienen etiquetas. En su lugar, el modelo normalmente encuentra patrones entre las características.
Definir la función de pérdida y gradiente
Tanto las etapas de entrenamiento como las de evaluación necesitan calcular la pérdida del modelo. Esto mide qué tan lejos están las predicciones de un modelo de la etiqueta deseada, en otras palabras, qué tan mal se está desempeñando el modelo. Queremos minimizar u optimizar este valor.
Nuestro modelo calculará su pérdida usando la función tf.keras.losses.SparseCategoricalCrossentropy que toma las predicciones de probabilidad de clase del modelo y la etiqueta deseada, y devuelve la pérdida promedio en los ejemplos.
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
def loss(model, x, y, training):
# training=training is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
y_ = model(x, training=training)
return loss_object(y_true=y, y_pred=y_)
l = loss(model, features, labels, training=False)
print("Loss test: {}".format(l))
Loss test: 1.6059828996658325
Use el contexto tf.GradientTape para calcular los gradientes utilizados para optimizar su modelo:
def grad(model, inputs, targets):
with tf.GradientTape() as tape:
loss_value = loss(model, inputs, targets, training=True)
return loss_value, tape.gradient(loss_value, model.trainable_variables)
Crear un optimizador
Un optimizador aplica los gradientes calculados a las variables del modelo para minimizar la función de loss . Puedes pensar en la función de pérdida como una superficie curva (ver Figura 3) y queremos encontrar su punto más bajo caminando. Las pendientes apuntan en la dirección del ascenso más empinado, por lo que viajaremos en dirección opuesta y descenderemos la colina. Mediante el cálculo iterativo de la pérdida y el gradiente de cada lote, ajustaremos el modelo durante el entrenamiento. Gradualmente, el modelo encontrará la mejor combinación de pesos y sesgos para minimizar la pérdida. Y cuanto menor sea la pérdida, mejores serán las predicciones del modelo.
 |
| Figura 3. Algoritmos de optimización visualizados a lo largo del tiempo en el espacio 3D. (Fuente: clase CS231n de Stanford , licencia MIT, crédito de la imagen: Alec Radford ) |
TensorFlow tiene muchos algoritmos de optimización disponibles para el entrenamiento. Este modelo utiliza tf.keras.optimizers.SGD que implementa el algoritmo de descenso de gradiente estocástico (SGD). learning_rate establece el tamaño del paso a tomar para cada iteración cuesta abajo. Este es un hiperparámetro que normalmente ajustará para lograr mejores resultados.
Configuremos el optimizador:
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
Usaremos esto para calcular un solo paso de optimización:
loss_value, grads = grad(model, features, labels)
print("Step: {}, Initial Loss: {}".format(optimizer.iterations.numpy(),
loss_value.numpy()))
optimizer.apply_gradients(zip(grads, model.trainable_variables))
print("Step: {}, Loss: {}".format(optimizer.iterations.numpy(),
loss(model, features, labels, training=True).numpy()))
Step: 0, Initial Loss: 1.6059828996658325 Step: 1, Loss: 1.3759253025054932
Bucle de entrenamiento
¡Con todas las piezas en su lugar, el modelo está listo para entrenar! Un ciclo de entrenamiento alimenta los ejemplos del conjunto de datos en el modelo para ayudarlo a hacer mejores predicciones. El siguiente bloque de código configura estos pasos de entrenamiento:
- Iterar cada época . Una época es un paso a través del conjunto de datos.
- Dentro de una época, itere sobre cada ejemplo en el conjunto de
Datasetde entrenamiento tomando sus características (x) y etiqueta (y). - Usando las características del ejemplo, haz una predicción y compárala con la etiqueta. Mida la imprecisión de la predicción y utilícela para calcular la pérdida y los gradientes del modelo.
- Utilice un
optimizerpara actualizar las variables del modelo. - Mantenga un registro de algunas estadísticas para su visualización.
- Repita para cada época.
La variable num_epochs es la cantidad de veces que se repite la recopilación del conjunto de datos. Contrariamente a la intuición, entrenar un modelo por más tiempo no garantiza un mejor modelo. num_epochs es un hiperparámetro que puede ajustar. Elegir el número correcto generalmente requiere experiencia y experimentación:
## Note: Rerunning this cell uses the same model variables
# Keep results for plotting
train_loss_results = []
train_accuracy_results = []
num_epochs = 201
for epoch in range(num_epochs):
epoch_loss_avg = tf.keras.metrics.Mean()
epoch_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()
# Training loop - using batches of 32
for x, y in train_dataset:
# Optimize the model
loss_value, grads = grad(model, x, y)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
# Track progress
epoch_loss_avg.update_state(loss_value) # Add current batch loss
# Compare predicted label to actual label
# training=True is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
epoch_accuracy.update_state(y, model(x, training=True))
# End epoch
train_loss_results.append(epoch_loss_avg.result())
train_accuracy_results.append(epoch_accuracy.result())
if epoch % 50 == 0:
print("Epoch {:03d}: Loss: {:.3f}, Accuracy: {:.3%}".format(epoch,
epoch_loss_avg.result(),
epoch_accuracy.result()))
Epoch 000: Loss: 1.766, Accuracy: 43.333% Epoch 050: Loss: 0.579, Accuracy: 71.667% Epoch 100: Loss: 0.398, Accuracy: 82.500% Epoch 150: Loss: 0.307, Accuracy: 92.500% Epoch 200: Loss: 0.224, Accuracy: 95.833%
Visualizar la función de pérdida a lo largo del tiempo
Si bien es útil imprimir el progreso de entrenamiento del modelo, a menudo es más útil ver este progreso. TensorBoard es una buena herramienta de visualización que viene con TensorFlow, pero podemos crear gráficos básicos usando el módulo matplotlib .
Interpretar estos gráficos requiere algo de experiencia, pero realmente desea ver que la pérdida disminuya y la precisión aumente:
fig, axes = plt.subplots(2, sharex=True, figsize=(12, 8))
fig.suptitle('Training Metrics')
axes[0].set_ylabel("Loss", fontsize=14)
axes[0].plot(train_loss_results)
axes[1].set_ylabel("Accuracy", fontsize=14)
axes[1].set_xlabel("Epoch", fontsize=14)
axes[1].plot(train_accuracy_results)
plt.show()
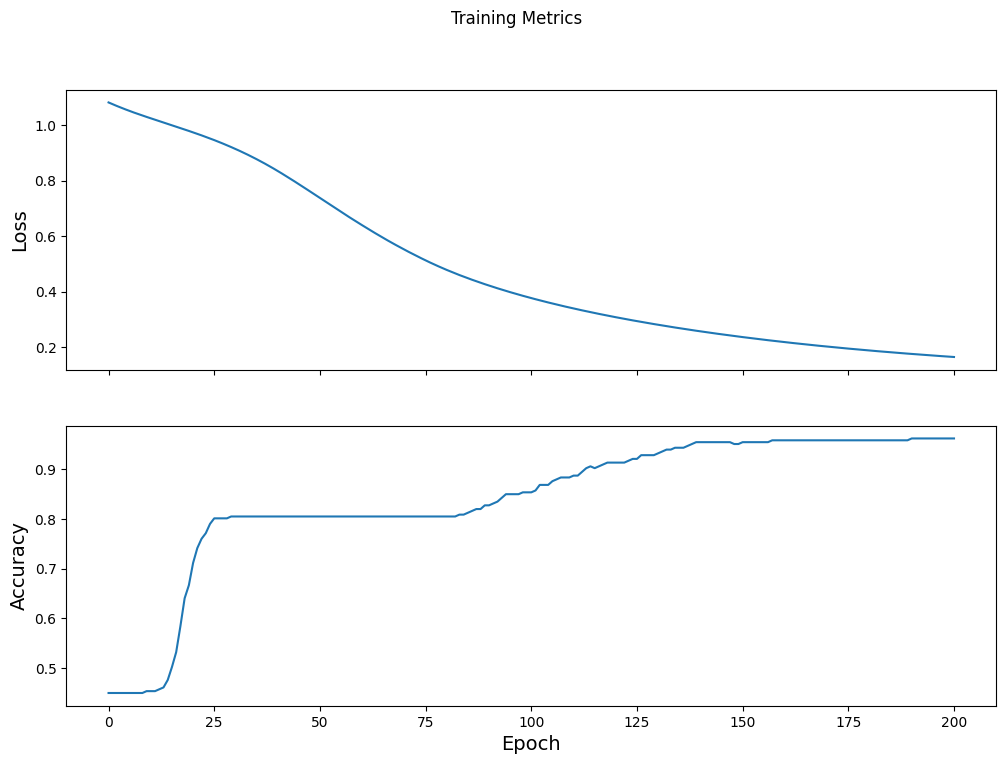
Evaluar la eficacia del modelo.
Ahora que el modelo está entrenado, podemos obtener algunas estadísticas sobre su rendimiento.
Evaluar significa determinar qué tan efectivamente el modelo hace predicciones. Para determinar la efectividad del modelo en la clasificación de Iris, pase algunas medidas de sépalos y pétalos al modelo y pídale que prediga qué especies de Iris representan. Luego compare las predicciones del modelo con la etiqueta real. Por ejemplo, un modelo que eligió la especie correcta en la mitad de los ejemplos de entrada tiene una precisión de 0.5 . La Figura 4 muestra un modelo un poco más efectivo, consiguiendo 4 de 5 predicciones correctas con un 80 % de precisión:
| Características de ejemplo | Etiqueta | Predicción del modelo | |||
|---|---|---|---|---|---|
| 5.9 | 3.0 | 4.3 | 1.5 | 1 | 1 |
| 6.9 | 3.1 | 5.4 | 2.1 | 2 | 2 |
| 5.1 | 3.3 | 1.7 | 0.5 | 0 | 0 |
| 6.0 | 3.4 | 4.5 | 1.6 | 1 | 2 |
| 5.5 | 2.5 | 4.0 | 1.3 | 1 | 1 |
| Figura 4. Un clasificador Iris con una precisión del 80 %. | |||||
Configurar el conjunto de datos de prueba
Evaluar el modelo es similar a entrenar el modelo. La mayor diferencia es que los ejemplos provienen de un conjunto de prueba separado en lugar del conjunto de entrenamiento. Para evaluar de manera justa la eficacia de un modelo, los ejemplos utilizados para evaluar un modelo deben ser diferentes de los ejemplos utilizados para entrenar el modelo.
La configuración para el conjunto de Dataset de prueba es similar a la configuración para el conjunto de Dataset de entrenamiento. Descargue el archivo de texto CSV y analice esos valores, luego mezcle un poco:
test_url = "https://storage.googleapis.com/download.tensorflow.org/data/iris_test.csv"
test_fp = tf.keras.utils.get_file(fname=os.path.basename(test_url),
origin=test_url)
test_dataset = tf.data.experimental.make_csv_dataset(
test_fp,
batch_size,
column_names=column_names,
label_name='species',
num_epochs=1,
shuffle=False)
test_dataset = test_dataset.map(pack_features_vector)
Evaluar el modelo en el conjunto de datos de prueba
A diferencia de la etapa de entrenamiento, el modelo solo evalúa una sola época de los datos de prueba. En la siguiente celda de código, iteramos sobre cada ejemplo en el conjunto de prueba y comparamos la predicción del modelo con la etiqueta real. Esto se utiliza para medir la precisión del modelo en todo el conjunto de pruebas:
test_accuracy = tf.keras.metrics.Accuracy()
for (x, y) in test_dataset:
# training=False is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
logits = model(x, training=False)
prediction = tf.argmax(logits, axis=1, output_type=tf.int32)
test_accuracy(prediction, y)
print("Test set accuracy: {:.3%}".format(test_accuracy.result()))
Test set accuracy: 96.667%
Podemos ver en el último lote, por ejemplo, el modelo suele ser correcto:
tf.stack([y,prediction],axis=1)
<tf.Tensor: shape=(30, 2), dtype=int32, numpy=
array([[1, 1],
[2, 2],
[0, 0],
[1, 1],
[1, 1],
[1, 1],
[0, 0],
[2, 2],
[1, 1],
[2, 2],
[2, 2],
[0, 0],
[2, 2],
[1, 1],
[1, 1],
[0, 0],
[1, 1],
[0, 0],
[0, 0],
[2, 2],
[0, 0],
[1, 1],
[2, 2],
[1, 2],
[1, 1],
[1, 1],
[0, 0],
[1, 1],
[2, 2],
[1, 1]], dtype=int32)>
Usar el modelo entrenado para hacer predicciones
Hemos entrenado un modelo y "probado" que es bueno, pero no perfecto, para clasificar las especies de Iris. Ahora usemos el modelo entrenado para hacer algunas predicciones en ejemplos sin etiqueta ; es decir, en ejemplos que contienen características pero no una etiqueta.
En la vida real, los ejemplos sin etiquetar podrían provenir de muchas fuentes diferentes, incluidas aplicaciones, archivos CSV y fuentes de datos. Por ahora, proporcionaremos manualmente tres ejemplos sin etiquetar para predecir sus etiquetas. Recuerde, los números de etiqueta se asignan a una representación nombrada como:
-
0: Iris setosa -
1: Iris versicolor -
2: Iris virgen
predict_dataset = tf.convert_to_tensor([
[5.1, 3.3, 1.7, 0.5,],
[5.9, 3.0, 4.2, 1.5,],
[6.9, 3.1, 5.4, 2.1]
])
# training=False is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
predictions = model(predict_dataset, training=False)
for i, logits in enumerate(predictions):
class_idx = tf.argmax(logits).numpy()
p = tf.nn.softmax(logits)[class_idx]
name = class_names[class_idx]
print("Example {} prediction: {} ({:4.1f}%)".format(i, name, 100*p))
Example 0 prediction: Iris setosa (97.6%) Example 1 prediction: Iris versicolor (82.0%) Example 2 prediction: Iris virginica (56.4%)