
| | |  Ver fuente en GitHub Ver fuente en GitHub | |
Este cuaderno demuestra la traducción de imagen a imagen no emparejada usando GAN condicionales, como se describe en Traducción de imagen a imagen no emparejada usando redes antagónicas coherentes con el ciclo , también conocido como CycleGAN. El documento propone un método que puede capturar las características de un dominio de imagen y descubrir cómo estas características podrían traducirse a otro dominio de imagen, todo en ausencia de ejemplos de entrenamiento emparejados.
Este cuaderno asume que está familiarizado con Pix2Pix, sobre el cual puede aprender en el tutorial de Pix2Pix . El código para CycleGAN es similar, la principal diferencia es una función de pérdida adicional y el uso de datos de entrenamiento no emparejados.
CycleGAN utiliza una pérdida de consistencia de ciclo para permitir el entrenamiento sin necesidad de datos emparejados. En otras palabras, puede traducirse de un dominio a otro sin un mapeo uno a uno entre el dominio de origen y el de destino.
Esto abre la posibilidad de realizar muchas tareas interesantes como mejora de fotografías, colorización de imágenes, transferencia de estilo, etc. Todo lo que necesita es el conjunto de datos de origen y de destino (que es simplemente un directorio de imágenes).


Configurar la canalización de entrada
Instale el paquete tensorflow_examples que permite importar el generador y el discriminador.
pip install git+https://github.com/tensorflow/examples.git
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow_examples.models.pix2pix import pix2pix
import os
import time
import matplotlib.pyplot as plt
from IPython.display import clear_output
AUTOTUNE = tf.data.AUTOTUNE
Canalización de entrada
Este tutorial entrena a un modelo para traducir de imágenes de caballos a imágenes de cebras. Puede encontrar este conjunto de datos y otros similares aquí .
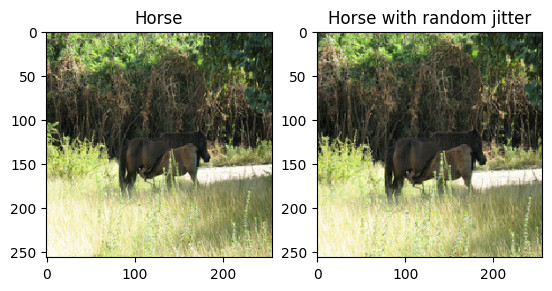
Como se menciona en el documento , aplique fluctuaciones aleatorias y reflejos al conjunto de datos de entrenamiento. Estas son algunas de las técnicas de aumento de imagen que evitan el sobreajuste.
Esto es similar a lo que se hizo en pix2pix
- En la fluctuación aleatoria, la imagen cambia de tamaño a
286 x 286y luego se recorta aleatoriamente a256 x 256. - En la duplicación aleatoria, la imagen se voltea aleatoriamente de forma horizontal, es decir, de izquierda a derecha.
dataset, metadata = tfds.load('cycle_gan/horse2zebra',
with_info=True, as_supervised=True)
train_horses, train_zebras = dataset['trainA'], dataset['trainB']
test_horses, test_zebras = dataset['testA'], dataset['testB']
BUFFER_SIZE = 1000
BATCH_SIZE = 1
IMG_WIDTH = 256
IMG_HEIGHT = 256
def random_crop(image):
cropped_image = tf.image.random_crop(
image, size=[IMG_HEIGHT, IMG_WIDTH, 3])
return cropped_image
# normalizing the images to [-1, 1]
def normalize(image):
image = tf.cast(image, tf.float32)
image = (image / 127.5) - 1
return image
def random_jitter(image):
# resizing to 286 x 286 x 3
image = tf.image.resize(image, [286, 286],
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
# randomly cropping to 256 x 256 x 3
image = random_crop(image)
# random mirroring
image = tf.image.random_flip_left_right(image)
return image
def preprocess_image_train(image, label):
image = random_jitter(image)
image = normalize(image)
return image
def preprocess_image_test(image, label):
image = normalize(image)
return image
train_horses = train_horses.cache().map(
preprocess_image_train, num_parallel_calls=AUTOTUNE).shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
train_zebras = train_zebras.cache().map(
preprocess_image_train, num_parallel_calls=AUTOTUNE).shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
test_horses = test_horses.map(
preprocess_image_test, num_parallel_calls=AUTOTUNE).cache().shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
test_zebras = test_zebras.map(
preprocess_image_test, num_parallel_calls=AUTOTUNE).cache().shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
sample_horse = next(iter(train_horses))
sample_zebra = next(iter(train_zebras))
2022-01-26 02:38:15.762422: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead. 2022-01-26 02:38:19.927846: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
plt.subplot(121)
plt.title('Horse')
plt.imshow(sample_horse[0] * 0.5 + 0.5)
plt.subplot(122)
plt.title('Horse with random jitter')
plt.imshow(random_jitter(sample_horse[0]) * 0.5 + 0.5)
<matplotlib.image.AxesImage at 0x7f7cf83e0050>
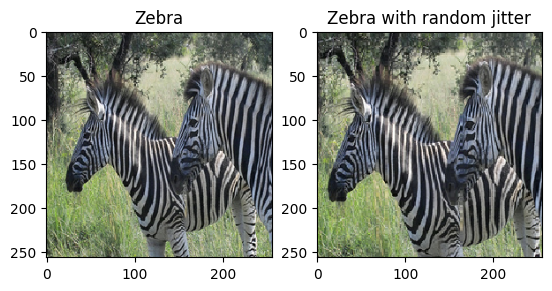
plt.subplot(121)
plt.title('Zebra')
plt.imshow(sample_zebra[0] * 0.5 + 0.5)
plt.subplot(122)
plt.title('Zebra with random jitter')
plt.imshow(random_jitter(sample_zebra[0]) * 0.5 + 0.5)
<matplotlib.image.AxesImage at 0x7f7cf8139490>
Importe y reutilice los modelos Pix2Pix
Importe el generador y el discriminador utilizados en Pix2Pix a través del paquete tensorflow_examples instalado.
La arquitectura modelo usada en este tutorial es muy similar a la que se usó en pix2pix . Algunas de las diferencias son:
- Cyclegan utiliza la normalización de instancias en lugar de la normalización por lotes .
- El documento CycleGAN utiliza un generador basado en
resnetmodificado. Este tutorial utiliza un generadorunetmodificado para simplificar.
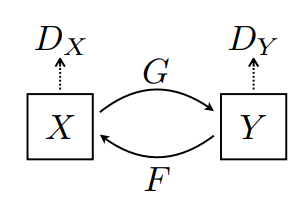
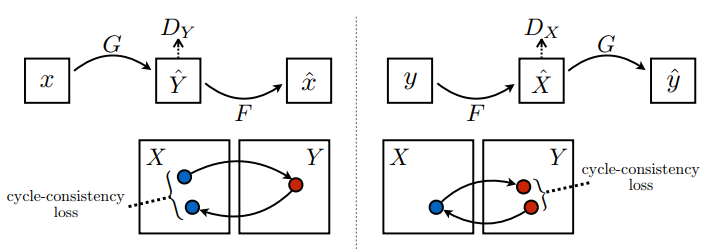
Hay 2 generadores (G y F) y 2 discriminadores (X e Y) que se entrenan aquí.
- El generador
Gaprende a transformar la imagenXen la imagenY\((G: X -> Y)\) - El generador
Faprende a transformar la imagenYen la imagenX\((F: Y -> X)\) - El discriminador
D_Xaprende a diferenciar entre la imagenXy la imagen generadaX(F(Y)). - El discriminador
D_Yaprende a diferenciar entre la imagenYy la imagen generadaY(G(X)).
OUTPUT_CHANNELS = 3
generator_g = pix2pix.unet_generator(OUTPUT_CHANNELS, norm_type='instancenorm')
generator_f = pix2pix.unet_generator(OUTPUT_CHANNELS, norm_type='instancenorm')
discriminator_x = pix2pix.discriminator(norm_type='instancenorm', target=False)
discriminator_y = pix2pix.discriminator(norm_type='instancenorm', target=False)
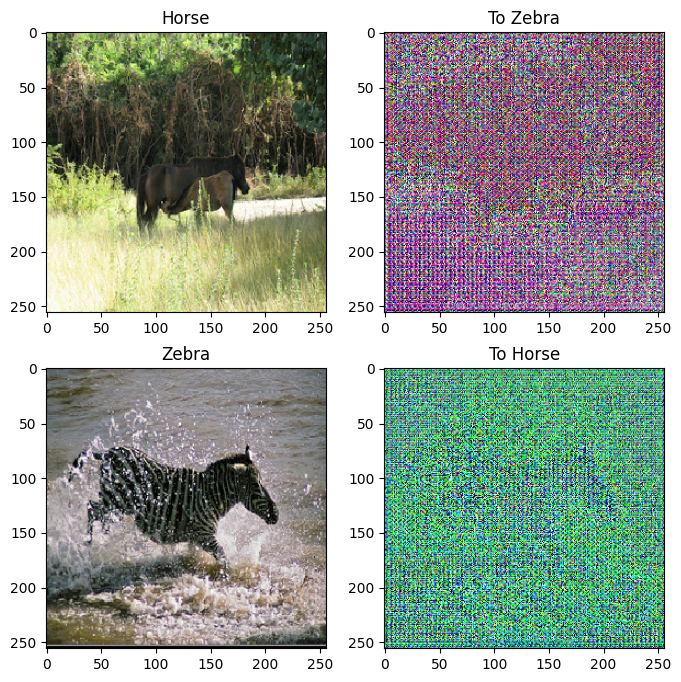
to_zebra = generator_g(sample_horse)
to_horse = generator_f(sample_zebra)
plt.figure(figsize=(8, 8))
contrast = 8
imgs = [sample_horse, to_zebra, sample_zebra, to_horse]
title = ['Horse', 'To Zebra', 'Zebra', 'To Horse']
for i in range(len(imgs)):
plt.subplot(2, 2, i+1)
plt.title(title[i])
if i % 2 == 0:
plt.imshow(imgs[i][0] * 0.5 + 0.5)
else:
plt.imshow(imgs[i][0] * 0.5 * contrast + 0.5)
plt.show()
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
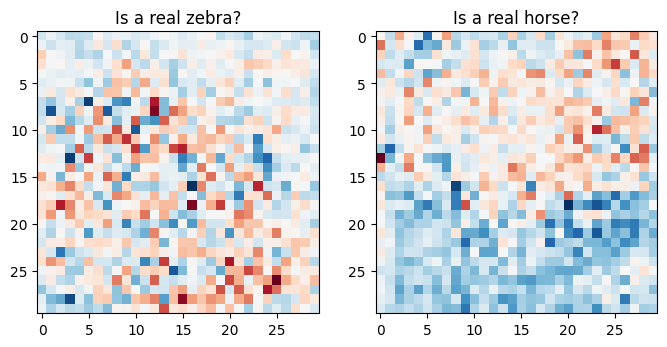
plt.figure(figsize=(8, 8))
plt.subplot(121)
plt.title('Is a real zebra?')
plt.imshow(discriminator_y(sample_zebra)[0, ..., -1], cmap='RdBu_r')
plt.subplot(122)
plt.title('Is a real horse?')
plt.imshow(discriminator_x(sample_horse)[0, ..., -1], cmap='RdBu_r')
plt.show()
Funciones de pérdida
En CycleGAN, no hay datos emparejados para entrenar, por lo tanto, no hay garantía de que la entrada x y el par objetivo y sean significativos durante el entrenamiento. Por lo tanto, para hacer cumplir que la red aprenda el mapeo correcto, los autores proponen la pérdida de consistencia del ciclo.
La pérdida del discriminador y la pérdida del generador son similares a las utilizadas en pix2pix .
LAMBDA = 10
loss_obj = tf.keras.losses.BinaryCrossentropy(from_logits=True)
def discriminator_loss(real, generated):
real_loss = loss_obj(tf.ones_like(real), real)
generated_loss = loss_obj(tf.zeros_like(generated), generated)
total_disc_loss = real_loss + generated_loss
return total_disc_loss * 0.5
def generator_loss(generated):
return loss_obj(tf.ones_like(generated), generated)
La consistencia del ciclo significa que el resultado debe estar cerca de la entrada original. Por ejemplo, si uno traduce una oración del inglés al francés y luego la vuelve a traducir del francés al inglés, la oración resultante debe ser la misma que la oración original.
En la pérdida de consistencia del ciclo,
- La imagen \(X\) se pasa a través del generador \(G\) que produce la imagen generada \(\hat{Y}\).
- La imagen generada \(\hat{Y}\) se pasa a través del generador \(F\) que produce la imagen \(\hat{X}\).
- El error absoluto medio se calcula entre \(X\) y \(\hat{X}\).
\[forward\ cycle\ consistency\ loss: X -> G(X) -> F(G(X)) \sim \hat{X}\]
\[backward\ cycle\ consistency\ loss: Y -> F(Y) -> G(F(Y)) \sim \hat{Y}\]
def calc_cycle_loss(real_image, cycled_image):
loss1 = tf.reduce_mean(tf.abs(real_image - cycled_image))
return LAMBDA * loss1
Como se muestra arriba, el generador \(G\) es responsable de traducir la imagen \(X\) a la imagen \(Y\). La pérdida de identidad dice que, si alimentó la imagen \(Y\) al generador \(G\), debería producir la imagen real \(Y\) o algo parecido a la imagen \(Y\).
Si ejecuta el modelo de cebra a caballo en un caballo o el modelo de caballo a cebra en una cebra, no debería modificar mucho la imagen, ya que la imagen ya contiene la clase de destino.
\[Identity\ loss = |G(Y) - Y| + |F(X) - X|\]
def identity_loss(real_image, same_image):
loss = tf.reduce_mean(tf.abs(real_image - same_image))
return LAMBDA * 0.5 * loss
Inicialice los optimizadores para todos los generadores y los discriminadores.
generator_g_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
generator_f_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_x_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_y_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
puntos de control
checkpoint_path = "./checkpoints/train"
ckpt = tf.train.Checkpoint(generator_g=generator_g,
generator_f=generator_f,
discriminator_x=discriminator_x,
discriminator_y=discriminator_y,
generator_g_optimizer=generator_g_optimizer,
generator_f_optimizer=generator_f_optimizer,
discriminator_x_optimizer=discriminator_x_optimizer,
discriminator_y_optimizer=discriminator_y_optimizer)
ckpt_manager = tf.train.CheckpointManager(ckpt, checkpoint_path, max_to_keep=5)
# if a checkpoint exists, restore the latest checkpoint.
if ckpt_manager.latest_checkpoint:
ckpt.restore(ckpt_manager.latest_checkpoint)
print ('Latest checkpoint restored!!')
Capacitación
EPOCHS = 40
def generate_images(model, test_input):
prediction = model(test_input)
plt.figure(figsize=(12, 12))
display_list = [test_input[0], prediction[0]]
title = ['Input Image', 'Predicted Image']
for i in range(2):
plt.subplot(1, 2, i+1)
plt.title(title[i])
# getting the pixel values between [0, 1] to plot it.
plt.imshow(display_list[i] * 0.5 + 0.5)
plt.axis('off')
plt.show()
Aunque el ciclo de entrenamiento parece complicado, consta de cuatro pasos básicos:
- Obtenga las predicciones.
- Calcular la pérdida.
- Calcule los gradientes usando retropropagación.
- Aplicar los degradados al optimizador.
@tf.function
def train_step(real_x, real_y):
# persistent is set to True because the tape is used more than
# once to calculate the gradients.
with tf.GradientTape(persistent=True) as tape:
# Generator G translates X -> Y
# Generator F translates Y -> X.
fake_y = generator_g(real_x, training=True)
cycled_x = generator_f(fake_y, training=True)
fake_x = generator_f(real_y, training=True)
cycled_y = generator_g(fake_x, training=True)
# same_x and same_y are used for identity loss.
same_x = generator_f(real_x, training=True)
same_y = generator_g(real_y, training=True)
disc_real_x = discriminator_x(real_x, training=True)
disc_real_y = discriminator_y(real_y, training=True)
disc_fake_x = discriminator_x(fake_x, training=True)
disc_fake_y = discriminator_y(fake_y, training=True)
# calculate the loss
gen_g_loss = generator_loss(disc_fake_y)
gen_f_loss = generator_loss(disc_fake_x)
total_cycle_loss = calc_cycle_loss(real_x, cycled_x) + calc_cycle_loss(real_y, cycled_y)
# Total generator loss = adversarial loss + cycle loss
total_gen_g_loss = gen_g_loss + total_cycle_loss + identity_loss(real_y, same_y)
total_gen_f_loss = gen_f_loss + total_cycle_loss + identity_loss(real_x, same_x)
disc_x_loss = discriminator_loss(disc_real_x, disc_fake_x)
disc_y_loss = discriminator_loss(disc_real_y, disc_fake_y)
# Calculate the gradients for generator and discriminator
generator_g_gradients = tape.gradient(total_gen_g_loss,
generator_g.trainable_variables)
generator_f_gradients = tape.gradient(total_gen_f_loss,
generator_f.trainable_variables)
discriminator_x_gradients = tape.gradient(disc_x_loss,
discriminator_x.trainable_variables)
discriminator_y_gradients = tape.gradient(disc_y_loss,
discriminator_y.trainable_variables)
# Apply the gradients to the optimizer
generator_g_optimizer.apply_gradients(zip(generator_g_gradients,
generator_g.trainable_variables))
generator_f_optimizer.apply_gradients(zip(generator_f_gradients,
generator_f.trainable_variables))
discriminator_x_optimizer.apply_gradients(zip(discriminator_x_gradients,
discriminator_x.trainable_variables))
discriminator_y_optimizer.apply_gradients(zip(discriminator_y_gradients,
discriminator_y.trainable_variables))
for epoch in range(EPOCHS):
start = time.time()
n = 0
for image_x, image_y in tf.data.Dataset.zip((train_horses, train_zebras)):
train_step(image_x, image_y)
if n % 10 == 0:
print ('.', end='')
n += 1
clear_output(wait=True)
# Using a consistent image (sample_horse) so that the progress of the model
# is clearly visible.
generate_images(generator_g, sample_horse)
if (epoch + 1) % 5 == 0:
ckpt_save_path = ckpt_manager.save()
print ('Saving checkpoint for epoch {} at {}'.format(epoch+1,
ckpt_save_path))
print ('Time taken for epoch {} is {} sec\n'.format(epoch + 1,
time.time()-start))

Saving checkpoint for epoch 40 at ./checkpoints/train/ckpt-8 Time taken for epoch 40 is 166.64579939842224 sec
Generar usando un conjunto de datos de prueba
# Run the trained model on the test dataset
for inp in test_horses.take(5):
generate_images(generator_g, inp)





Próximos pasos
Este tutorial ha mostrado cómo implementar CycleGAN a partir del generador y el discriminador implementados en el tutorial de Pix2Pix . Como siguiente paso, podría intentar usar un conjunto de datos diferente de TensorFlow Datasets .
También podría entrenar para una mayor cantidad de épocas para mejorar los resultados, o podría implementar el generador ResNet modificado que se usa en el documento en lugar del generador U-Net que se usa aquí.