
คู่มือนี้สาธิตวิธีใช้เครื่องมือที่มาพร้อมกับ TensorFlow Profiler เพื่อติดตามประสิทธิภาพของโมเดล TensorFlow ของคุณ คุณจะได้เรียนรู้วิธีทำความเข้าใจว่าโมเดลของคุณทำงานอย่างไรบนโฮสต์ (CPU) อุปกรณ์ (GPU) หรือทั้งโฮสต์และอุปกรณ์รวมกัน
การทำโปรไฟล์ช่วยให้เข้าใจการใช้ทรัพยากรฮาร์ดแวร์ (เวลาและหน่วยความจำ) ของการดำเนินการ (การดำเนินการ) ของ TensorFlow ต่างๆ ในโมเดลของคุณ และแก้ไขคอขวดของประสิทธิภาพ และทำให้โมเดลดำเนินการเร็วขึ้นในท้ายที่สุด
คู่มือนี้จะแนะนำวิธีการติดตั้ง Profiler เครื่องมือต่างๆ ที่ใช้งานได้ โหมดต่างๆ ของวิธีที่ Profiler รวบรวมข้อมูลประสิทธิภาพ และแนวทางปฏิบัติที่ดีที่สุดที่แนะนำเพื่อเพิ่มประสิทธิภาพการทำงานของโมเดล
หากคุณต้องการโปรไฟล์ประสิทธิภาพของโมเดลบน Cloud TPU โปรดดู คำแนะนำ Cloud TPU
ติดตั้งข้อกำหนดเบื้องต้นของ Profiler และ GPU
ติดตั้งปลั๊กอิน Profiler สำหรับ TensorBoard ด้วย pip โปรดทราบว่า Profiler ต้องใช้ TensorFlow และ TensorBoard เวอร์ชันล่าสุด (>=2.2)
pip install -U tensorboard_plugin_profile
หากต้องการทำโปรไฟล์บน GPU คุณต้อง:
- ตรงตามข้อกำหนดไดรเวอร์ NVIDIA® GPU และชุดเครื่องมือ CUDA® Toolkit ที่ระบุไว้ใน ข้อกำหนดซอฟต์แวร์รองรับ TensorFlow GPU
ตรวจสอบให้แน่ใจว่า NVIDIA® CUDA® Profiling Tools Interface (CUPTI) มีอยู่บนเส้นทาง:
/sbin/ldconfig -N -v $(sed 's/:/ /g' <<< $LD_LIBRARY_PATH) | \ grep libcupti
หากคุณไม่มี CUPTI บนพาธ ให้เพิ่มไดเร็กทอรีการติดตั้งไว้หน้าตัวแปรสภาพแวดล้อม $LD_LIBRARY_PATH โดยเรียกใช้:
export LD_LIBRARY_PATH=/usr/local/cuda/extras/CUPTI/lib64:$LD_LIBRARY_PATH
จากนั้นรันคำสั่ง ldconfig ด้านบนอีกครั้งเพื่อตรวจสอบว่าพบไลบรารี CUPTI หรือไม่
แก้ไขปัญหาสิทธิพิเศษ
เมื่อคุณรันการสร้างโปรไฟล์ด้วย CUDA® Toolkit ในสภาพแวดล้อม Docker หรือบน Linux คุณอาจประสบปัญหาที่เกี่ยวข้องกับสิทธิ์ CUPTI ที่ไม่เพียงพอ ( CUPTI_ERROR_INSUFFICIENT_PRIVILEGES ) ไปที่ เอกสารสำหรับนักพัฒนา NVIDIA เพื่อเรียนรู้เพิ่มเติมเกี่ยวกับวิธีที่คุณสามารถแก้ไขปัญหาเหล่านี้บน Linux
หากต้องการแก้ไขปัญหาสิทธิ์ CUPTI ในสภาพแวดล้อม Docker ให้เรียกใช้
docker run option '--privileged=true'
เครื่องมือสร้างโปรไฟล์
เข้าถึง Profiler จากแท็บ Profile ใน TensorBoard ซึ่งจะปรากฏขึ้นหลังจากที่คุณบันทึกข้อมูลโมเดลบางส่วนแล้วเท่านั้น
Profiler มีเครื่องมือให้เลือกมากมายเพื่อช่วยในการวิเคราะห์ประสิทธิภาพ:
- หน้าภาพรวม
- เครื่องวิเคราะห์ไปป์ไลน์อินพุต
- สถิติเทนเซอร์โฟลว์
- โปรแกรมดูการติดตาม
- สถิติเคอร์เนล GPU
- เครื่องมือโปรไฟล์หน่วยความจำ
- โปรแกรมดูพ็อด
หน้าภาพรวม
หน้าภาพรวมจะแสดงมุมมองระดับบนสุดว่าโมเดลของคุณทำงานอย่างไรระหว่างการเรียกใช้โปรไฟล์ หน้าดังกล่าวจะแสดงหน้าภาพรวมโดยรวมสำหรับโฮสต์และอุปกรณ์ทั้งหมดของคุณ และคำแนะนำบางประการเพื่อปรับปรุงประสิทธิภาพการฝึกโมเดลของคุณ คุณยังสามารถเลือกแต่ละโฮสต์ได้ในเมนูแบบเลื่อนลงโฮสต์
หน้าภาพรวมจะแสดงข้อมูลดังนี้:
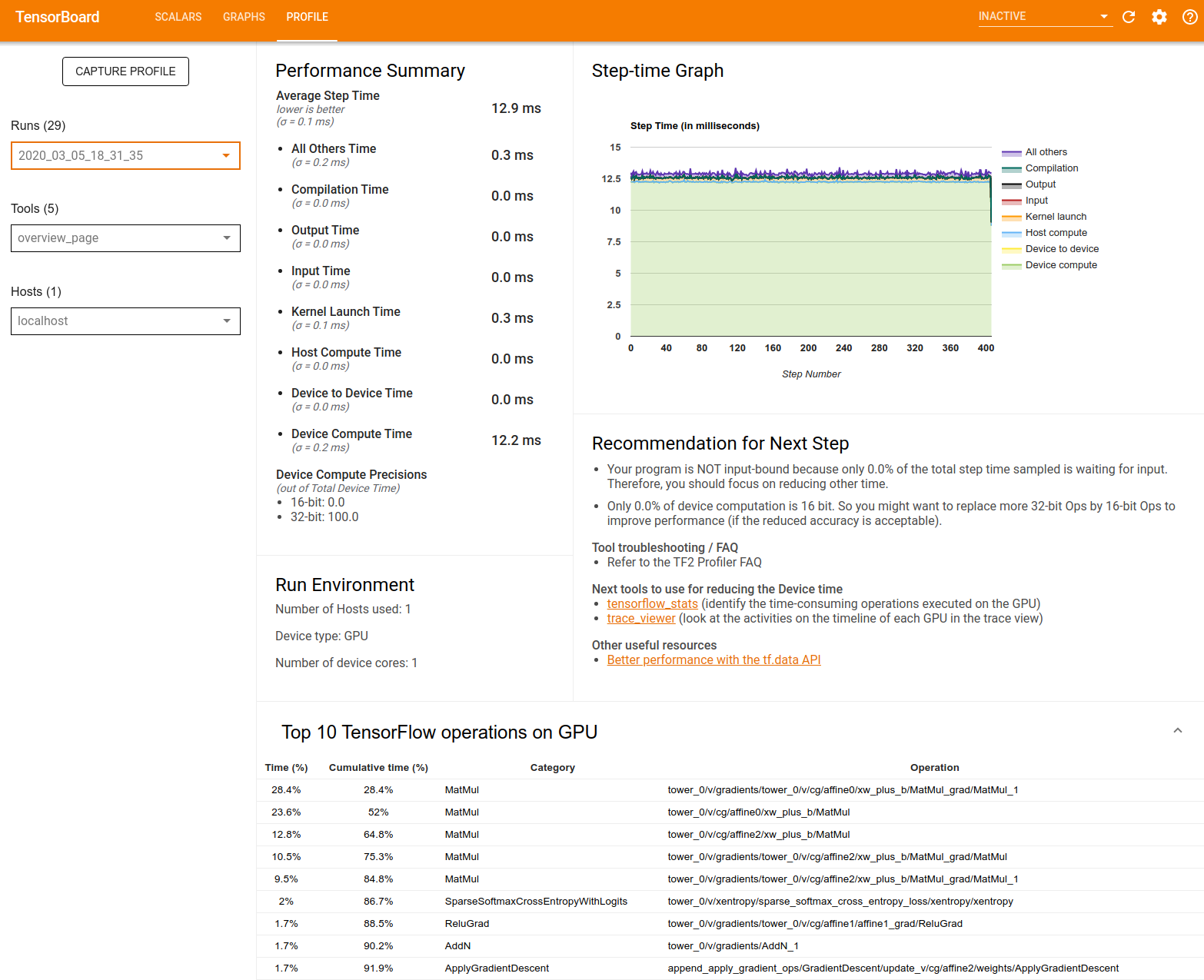
สรุปประสิทธิภาพ : แสดงสรุประดับสูงของประสิทธิภาพของโมเดลของคุณ สรุปประสิทธิภาพมีสองส่วน:
การแบ่งเวลาเป็นขั้นตอน: แบ่งเวลาเฉลี่ยของขั้นตอนออกเป็นหลายประเภทของเวลาที่ใช้ไป:
- การรวบรวม: เวลาที่ใช้ในการรวบรวมเมล็ดพืช
- อินพุต: เวลาที่ใช้ในการอ่านข้อมูลอินพุต
- เอาท์พุต: เวลาที่ใช้ในการอ่านข้อมูลเอาท์พุต
- การเปิดเคอร์เนล: เวลาที่โฮสต์ใช้ในการเปิดเคอร์เนล
- เวลาประมวลผลโฮสต์..
- เวลาการสื่อสารระหว่างอุปกรณ์กับอุปกรณ์
- เวลาคำนวณบนอุปกรณ์
- อื่นๆ ทั้งหมด รวมถึงโอเวอร์เฮดของ Python
ความแม่นยำในการประมวลผลของอุปกรณ์ - รายงานเปอร์เซ็นต์ของเวลาในการประมวลผลของอุปกรณ์ที่ใช้การคำนวณ 16 และ 32 บิต
กราฟขั้นตอน : แสดงกราฟของเวลาขั้นตอนของอุปกรณ์ (หน่วยเป็นมิลลิวินาที) สำหรับขั้นตอนทั้งหมดที่สุ่มตัวอย่าง แต่ละขั้นตอนจะแบ่งออกเป็นหลายหมวดหมู่ (มีสีต่างกัน) ของเวลาที่ใช้ไป พื้นที่สีแดงสอดคล้องกับส่วนของเวลาขั้นตอนที่อุปกรณ์ไม่ได้ใช้งานเพื่อรอข้อมูลอินพุตจากโฮสต์ พื้นที่สีเขียวแสดงระยะเวลาที่อุปกรณ์ใช้งานได้จริง
การดำเนินการ TensorFlow 10 อันดับแรกบนอุปกรณ์ (เช่น GPU) : แสดงการดำเนินการบนอุปกรณ์ที่ทำงานนานที่สุด
แต่ละแถวจะแสดงเวลาของตนเองของ op (เป็นเปอร์เซ็นต์ของเวลาที่ใช้โดย ops ทั้งหมด) เวลาสะสม หมวดหมู่ และชื่อ
Run Environment : แสดงข้อมูลสรุประดับสูงของสภาพแวดล้อมการรันโมเดล ได้แก่:
- จำนวนโฮสต์ที่ใช้
- ประเภทอุปกรณ์ (GPU/TPU)
- จำนวนแกนของอุปกรณ์
คำแนะนำสำหรับขั้นตอนถัดไป : รายงานเมื่อโมเดลถูกผูกเข้ากับอินพุต และแนะนำเครื่องมือที่คุณสามารถใช้เพื่อค้นหาและแก้ไขคอขวดของประสิทธิภาพของโมเดล
เครื่องวิเคราะห์ไปป์ไลน์อินพุต
เมื่อโปรแกรม TensorFlow อ่านข้อมูลจากไฟล์ โปรแกรมจะเริ่มต้นที่ด้านบนของกราฟ TensorFlow ในลักษณะไปป์ไลน์ กระบวนการอ่านแบ่งออกเป็นขั้นตอนการประมวลผลข้อมูลหลายขั้นตอนที่เชื่อมต่อกันเป็นอนุกรม โดยที่เอาต์พุตของสเตจหนึ่งจะเป็นอินพุตไปยังสเตจถัดไป ระบบการอ่านข้อมูลนี้เรียกว่า ไปป์ไลน์อินพุต
ไปป์ไลน์ทั่วไปสำหรับการอ่านบันทึกจากไฟล์มีขั้นตอนต่อไปนี้:
- การอ่านไฟล์.
- การประมวลผลไฟล์ล่วงหน้า (ไม่จำเป็น)
- การถ่ายโอนไฟล์จากโฮสต์ไปยังอุปกรณ์
ไปป์ไลน์อินพุตที่ไม่มีประสิทธิภาพอาจทำให้แอปพลิเคชันของคุณช้าลงอย่างมาก แอปพลิเคชันจะถือเป็น อินพุตที่ถูกผูกไว้ เมื่อใช้เวลาส่วนสำคัญในไปป์ไลน์อินพุต ใช้ข้อมูลเชิงลึกที่ได้รับจากเครื่องวิเคราะห์ไปป์ไลน์อินพุตเพื่อทำความเข้าใจว่าไปป์ไลน์อินพุตตรงจุดใดที่ไม่มีประสิทธิภาพ
ตัววิเคราะห์ไปป์ไลน์อินพุตจะแจ้งให้คุณทราบทันทีว่าโปรแกรมของคุณถูกผูกเข้ากับอินพุตหรือไม่ และจะแนะนำคุณผ่านการวิเคราะห์อุปกรณ์และฝั่งโฮสต์เพื่อแก้ไขจุดบกพร่องของคอขวดของประสิทธิภาพในทุกขั้นตอนในไปป์ไลน์อินพุต
ตรวจสอบคำแนะนำเกี่ยวกับประสิทธิภาพของไปป์ไลน์อินพุตเพื่อดูแนวทางปฏิบัติที่ดีที่สุดที่แนะนำเพื่อเพิ่มประสิทธิภาพไปป์ไลน์อินพุตข้อมูลของคุณ
แดชบอร์ดไปป์ไลน์อินพุต
หากต้องการเปิดตัววิเคราะห์ไปป์ไลน์อินพุต ให้เลือก โปรไฟล์ จากนั้นเลือก input_pipeline_analyzer จากเมนูดรอปดาวน์ เครื่องมือ
แดชบอร์ดประกอบด้วยสามส่วน:
- สรุป : สรุปไปป์ไลน์อินพุตโดยรวมพร้อมข้อมูลว่าแอปพลิเคชันของคุณถูกผูกเข้ากับอินพุตหรือไม่ และหากเป็นเช่นนั้น จะอยู่ที่เท่าใด
- การวิเคราะห์ฝั่งอุปกรณ์ : แสดงผลการวิเคราะห์ฝั่งอุปกรณ์โดยละเอียด รวมถึงเวลาขั้นตอนของอุปกรณ์และช่วงเวลาของอุปกรณ์ที่ใช้ในการรอข้อมูลอินพุตข้ามคอร์ในแต่ละขั้นตอน
- การวิเคราะห์ฝั่งโฮสต์ : แสดงการวิเคราะห์โดยละเอียดในฝั่งโฮสต์ รวมถึงรายละเอียดเวลาประมวลผลอินพุตบนโฮสต์
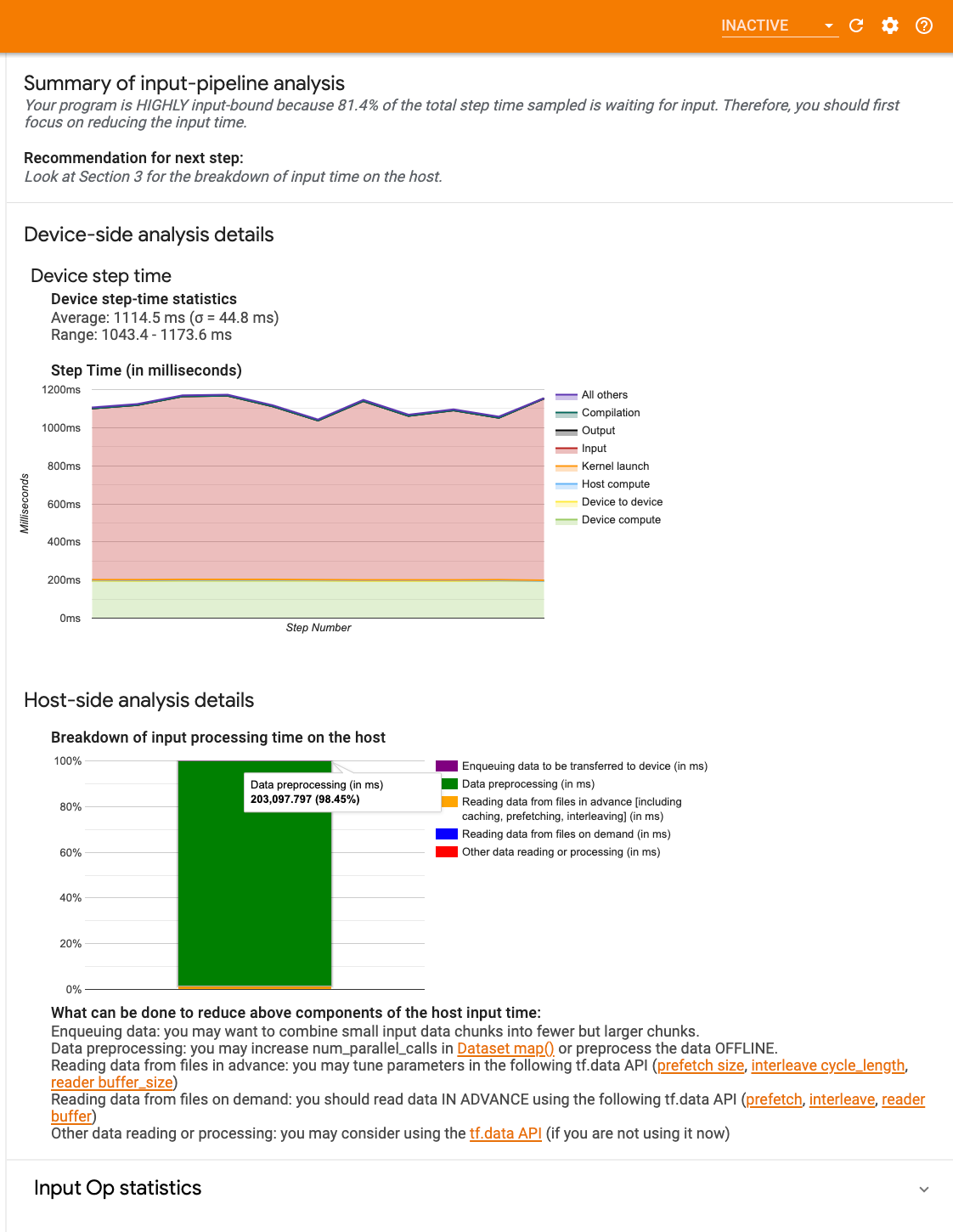
สรุปไปป์ไลน์อินพุต
สรุป จะรายงานว่าโปรแกรมของคุณถูกผูกเข้ากับอินพุตโดยแสดงเปอร์เซ็นต์ของเวลาของอุปกรณ์ที่ใช้ในการรออินพุตจากโฮสต์ หากคุณกำลังใช้ไปป์ไลน์อินพุตมาตรฐานที่ได้รับการอินสตรูเมนต์ เครื่องมือจะรายงานว่าใช้เวลาประมวลผลอินพุตส่วนใหญ่ไปที่ใด
การวิเคราะห์ด้านอุปกรณ์
การวิเคราะห์ฝั่งอุปกรณ์ให้ข้อมูลเชิงลึกเกี่ยวกับเวลาที่ใช้บนอุปกรณ์เทียบกับโฮสต์ และระยะเวลาของอุปกรณ์ที่ใช้ในการรอข้อมูลอินพุตจากโฮสต์
- เวลาของขั้นตอนที่พล็อตเทียบกับหมายเลขขั้นตอน : แสดงกราฟของเวลาขั้นตอนของอุปกรณ์ (เป็นมิลลิวินาที) ของขั้นตอนทั้งหมดที่สุ่มตัวอย่าง แต่ละขั้นตอนจะแบ่งออกเป็นหลายหมวดหมู่ (มีสีต่างกัน) ของเวลาที่ใช้ไป พื้นที่สีแดงสอดคล้องกับส่วนของเวลาขั้นตอนที่อุปกรณ์ไม่ได้ใช้งานเพื่อรอข้อมูลอินพุตจากโฮสต์ พื้นที่สีเขียวแสดงระยะเวลาที่อุปกรณ์ใช้งานได้จริง
- สถิติเวลาขั้นตอน : รายงานค่าเฉลี่ย ส่วนเบี่ยงเบนมาตรฐาน และช่วง ([ขั้นต่ำ สูงสุด]) ของเวลาขั้นตอนของอุปกรณ์
การวิเคราะห์ฝั่งโฮสต์
การวิเคราะห์ฝั่งโฮสต์จะรายงานรายละเอียดเวลาประมวลผลอินพุต (เวลาที่ใช้ในการดำเนินการ tf.data API) บนโฮสต์ออกเป็นหลายประเภท:
- การอ่านข้อมูลจากไฟล์ตามต้องการ : เวลาที่ใช้ในการอ่านข้อมูลจากไฟล์โดยไม่ต้องแคช การดึงข้อมูลล่วงหน้า และการแทรกแซง
- การอ่านข้อมูลจากไฟล์ล่วงหน้า : เวลาที่ใช้ในการอ่านไฟล์ รวมถึงการแคช การดึงข้อมูลล่วงหน้า และการแทรกข้อมูล
- การประมวลผลข้อมูลล่วงหน้า : เวลาที่ใช้ในการประมวลผลล่วงหน้า เช่น การบีบอัดรูปภาพ
- การจัดคิวข้อมูลที่จะถ่ายโอนไปยังอุปกรณ์ : เวลาที่ใช้ในการวางข้อมูลลงในคิวป้อนข้อมูลก่อนที่จะถ่ายโอนข้อมูลไปยังอุปกรณ์
ขยาย สถิติ Input Op เพื่อตรวจสอบสถิติสำหรับ Ops อินพุตแต่ละรายการและหมวดหมู่แยกตามเวลาดำเนินการ
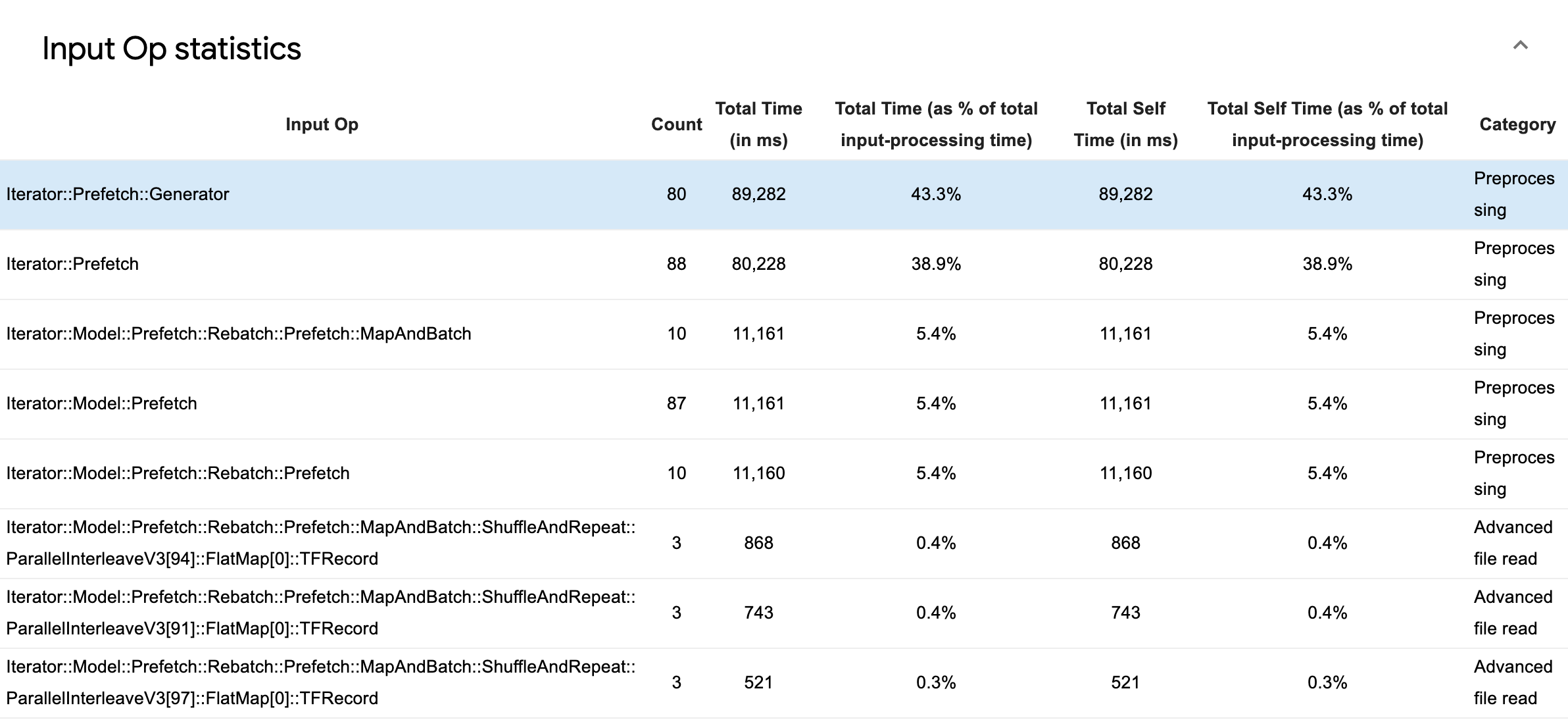
ตารางข้อมูลต้นฉบับจะปรากฏขึ้นพร้อมกับแต่ละรายการที่มีข้อมูลต่อไปนี้:
- Input Op : แสดงชื่อ TensorFlow op ของ input op
- จำนวน : แสดงจำนวนอินสแตนซ์ทั้งหมดของการดำเนินการ op ในช่วงระยะเวลาการทำโปรไฟล์
- เวลาทั้งหมด (เป็นมิลลิวินาที) : แสดงผลรวมสะสมของเวลาที่ใช้ในแต่ละอินสแตนซ์เหล่านั้น
- เวลาทั้งหมด % : แสดงเวลาทั้งหมดที่ใช้ใน op เป็นเศษส่วนของเวลาทั้งหมดที่ใช้ในการประมวลผลอินพุต
- เวลาตนเองทั้งหมด (เป็นมิลลิวินาที) : แสดงผลรวมสะสมของเวลาตนเองที่ใช้ในแต่ละกรณีเหล่านั้น เวลาของตัวเองที่นี่จะวัดเวลาที่ใช้ภายในเนื้อหาของฟังก์ชัน ไม่รวมเวลาที่ใช้ในฟังก์ชันที่เรียกใช้
- เวลาตนเองทั้งหมด % แสดงเวลาของตัวเองทั้งหมดเป็นเศษส่วนของเวลาทั้งหมดที่ใช้ในการประมวลผลอินพุต
- หมวดหมู่ . แสดงหมวดหมู่การประมวลผลของอินพุต op
สถิติ TensorFlow
เครื่องมือ TensorFlow Stats จะแสดงประสิทธิภาพของ TensorFlow op (op) ทุกตัวที่ดำเนินการบนโฮสต์หรืออุปกรณ์ระหว่างเซสชันการทำโปรไฟล์
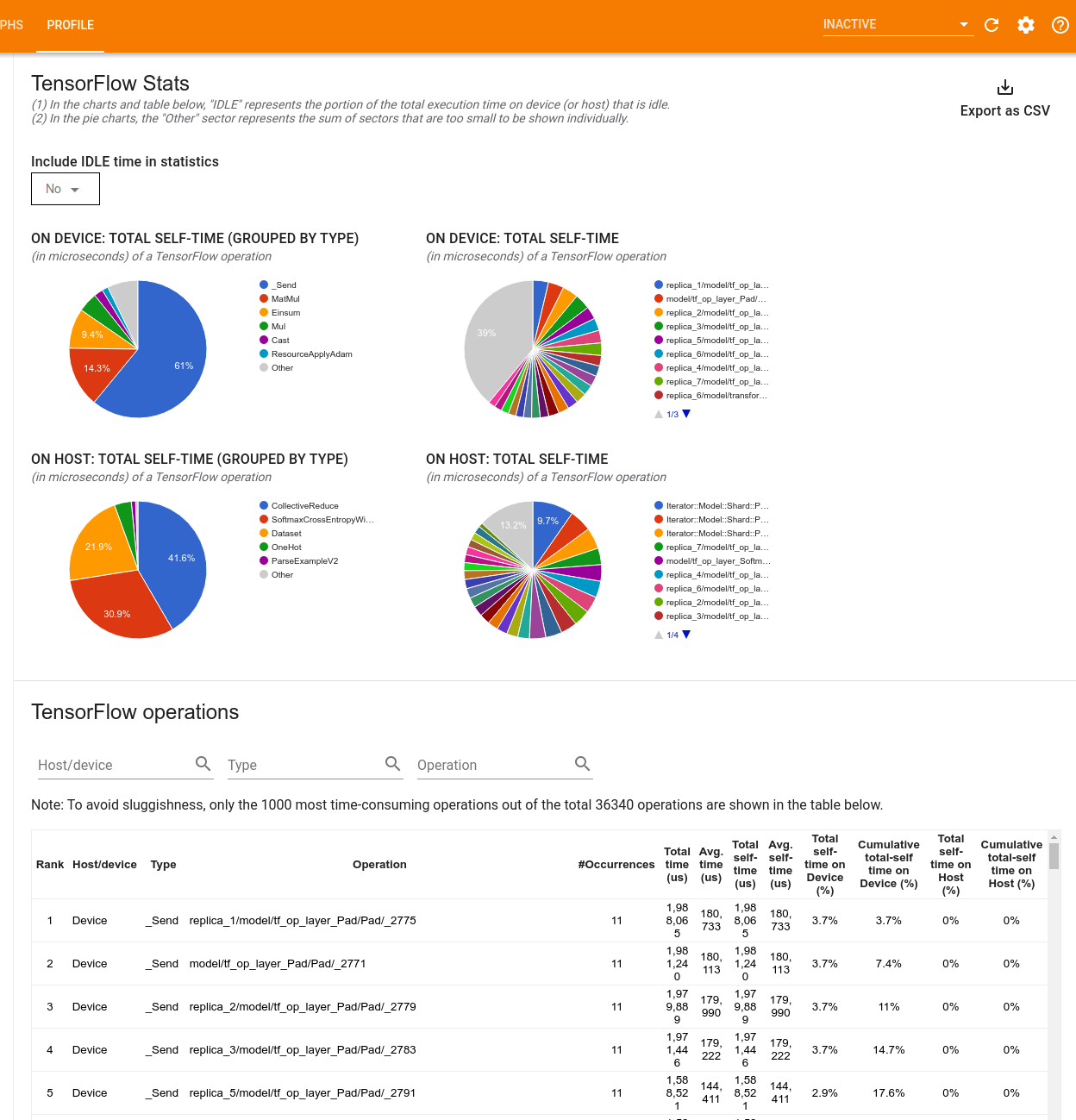
เครื่องมือจะแสดงข้อมูลประสิทธิภาพในสองบานหน้าต่าง:
บานหน้าต่างด้านบนจะแสดงแผนภูมิวงกลมสูงสุดสี่แผนภูมิ:
- การกระจายเวลาดำเนินการด้วยตนเองของแต่ละ op บนโฮสต์
- การกระจายเวลาดำเนินการด้วยตนเองของประเภทปฏิบัติการแต่ละประเภทบนโฮสต์
- การกระจายเวลาดำเนินการด้วยตนเองของแต่ละปฏิบัติการบนอุปกรณ์
- การกระจายเวลาดำเนินการด้วยตนเองของประเภทปฏิบัติการแต่ละประเภทบนอุปกรณ์
บานหน้าต่างด้านล่างแสดงตารางที่รายงานข้อมูลเกี่ยวกับการดำเนินการของ TensorFlow โดยมีหนึ่งแถวสำหรับแต่ละการดำเนินการและหนึ่งคอลัมน์สำหรับข้อมูลแต่ละประเภท (จัดเรียงคอลัมน์โดยคลิกที่ส่วนหัวของคอลัมน์) คลิก ปุ่มส่งออกเป็น CSV ที่ด้านขวาของบานหน้าต่างด้านบนเพื่อส่งออกข้อมูลจากตารางนี้เป็นไฟล์ CSV
โปรดทราบว่า:
หากปฏิบัติการใดมีปฏิบัติการย่อย:
- เวลา "สะสม" ทั้งหมดของปฏิบัติการจะรวมเวลาที่ใช้ในปฏิบัติการย่อยด้วย
- เวลา "ตนเอง" ทั้งหมดของปฏิบัติการไม่รวมเวลาที่ใช้ในปฏิบัติการย่อย
หาก op ดำเนินการบนโฮสต์:
- เปอร์เซ็นต์ของเวลาตัวเองทั้งหมดบนอุปกรณ์ที่เกิดขึ้นจากการดำเนินการจะเป็น 0
- เปอร์เซ็นต์สะสมของเวลาตัวเองทั้งหมดบนอุปกรณ์จนถึงและรวมการดำเนินการนี้จะเป็น 0
หาก op ดำเนินการบนอุปกรณ์:
- เปอร์เซ็นต์ของเวลาตนเองทั้งหมดบนโฮสต์ที่เกิดขึ้นโดยการดำเนินการนี้จะเป็น 0
- เปอร์เซ็นต์สะสมของเวลาตัวเองทั้งหมดบนโฮสต์จนถึงและรวม op นี้จะเป็น 0
คุณสามารถเลือกที่จะรวมหรือไม่รวมเวลาว่างในแผนภูมิวงกลมและตารางได้
โปรแกรมดูการติดตาม
โปรแกรมดูการติดตามจะแสดงไทม์ไลน์ที่แสดง:
- ระยะเวลาสำหรับการดำเนินการที่ดำเนินการโดยโมเดล TensorFlow ของคุณ
- ส่วนใดของระบบ (โฮสต์หรืออุปกรณ์) ดำเนินการปฏิบัติการ โดยทั่วไปแล้ว โฮสต์จะดำเนินการป้อนข้อมูล ประมวลผลข้อมูลการฝึกล่วงหน้า และถ่ายโอนไปยังอุปกรณ์ ในขณะที่อุปกรณ์ดำเนินการฝึกโมเดลจริง
โปรแกรมดูการติดตามช่วยให้คุณระบุปัญหาด้านประสิทธิภาพในโมเดลของคุณ จากนั้นดำเนินการแก้ไข ตัวอย่างเช่น ในระดับสูง คุณสามารถระบุได้ว่าการฝึกอินพุตหรือโมเดลใช้เวลาส่วนใหญ่หรือไม่ เมื่อเจาะลึก คุณจะระบุได้ว่าปฏิบัติการใดใช้เวลาดำเนินการนานที่สุด โปรดทราบว่าโปรแกรมดูการติดตามถูกจำกัดไว้ที่ 1 ล้านเหตุการณ์ต่ออุปกรณ์
อินเทอร์เฟซผู้ดูการติดตาม
เมื่อคุณเปิดโปรแกรมดูการติดตาม มันจะปรากฏขึ้นเพื่อแสดงการทำงานล่าสุดของคุณ:
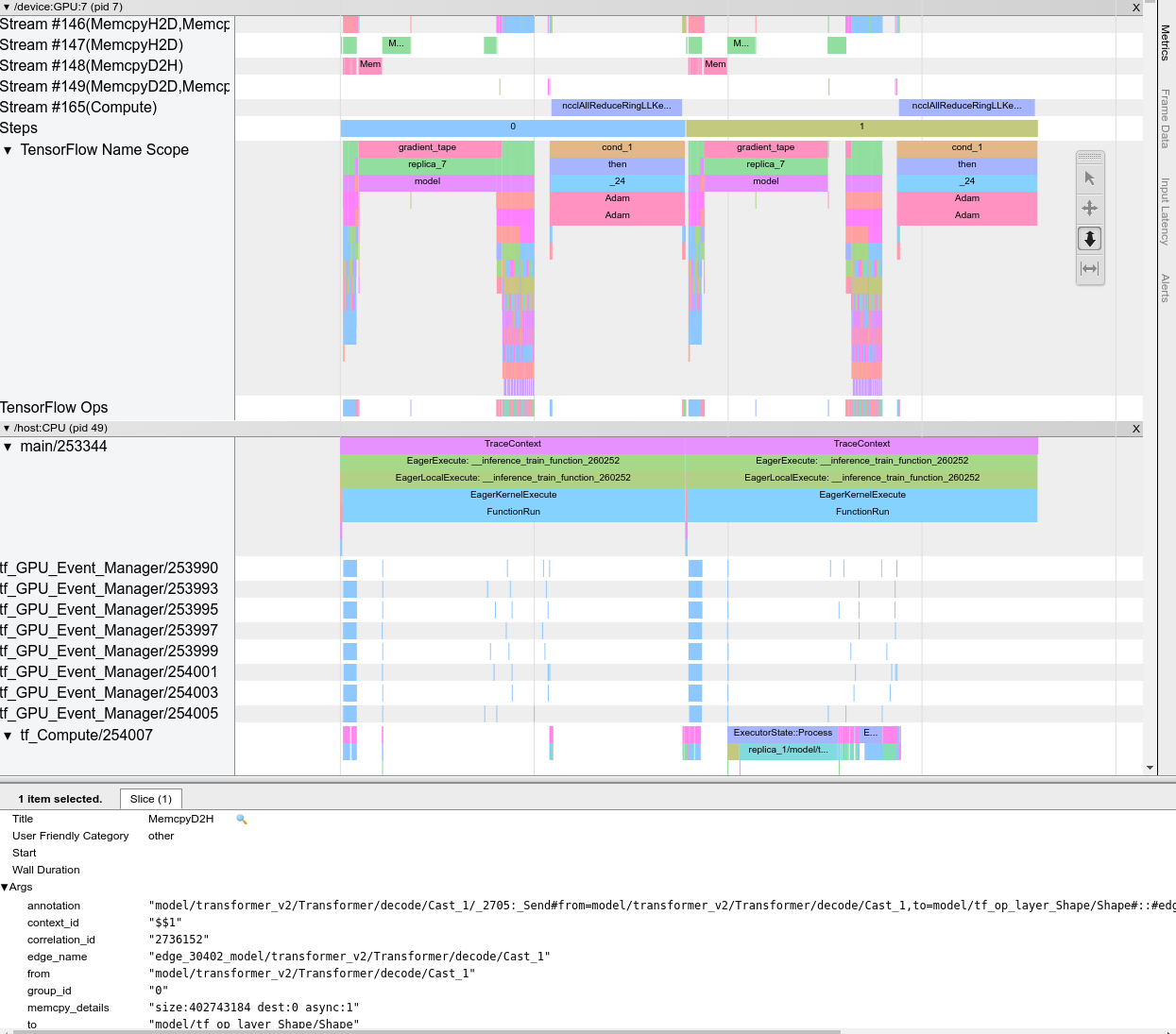
หน้าจอนี้ประกอบด้วยองค์ประกอบหลักดังต่อไปนี้:
- บานหน้าต่างไทม์ไลน์ : แสดงการดำเนินการที่อุปกรณ์และโฮสต์ดำเนินการเมื่อเวลาผ่านไป
- บานหน้าต่างรายละเอียด : แสดงข้อมูลเพิ่มเติมสำหรับการดำเนินการที่เลือกในบานหน้าต่างไทม์ไลน์
บานหน้าต่างไทม์ไลน์ประกอบด้วยองค์ประกอบต่อไปนี้:
- แถบด้านบน : ประกอบด้วยส่วนควบคุมเสริมต่างๆ
- แกนเวลา : แสดงเวลาที่สัมพันธ์กับจุดเริ่มต้นของการติดตาม
- ป้ายกำกับส่วนและแทร็ก : แต่ละส่วนประกอบด้วยแทร็กหลายแทร็กและมีรูปสามเหลี่ยมทางด้านซ้ายซึ่งคุณสามารถคลิกเพื่อขยายและยุบส่วนนั้นได้ มีหนึ่งส่วนสำหรับทุกองค์ประกอบการประมวลผลในระบบ
- ตัวเลือกเครื่องมือ : ประกอบด้วยเครื่องมือต่างๆ สำหรับการโต้ตอบกับโปรแกรมดูการติดตาม เช่น ซูม แพน เลือก และกำหนดเวลา ใช้เครื่องมือจับเวลาเพื่อทำเครื่องหมายช่วงเวลา
- เหตุการณ์ : ข้อมูลเหล่านี้แสดงเวลาที่ดำเนินการปฏิบัติการหรือระยะเวลาของเหตุการณ์เมตา เช่น ขั้นตอนการฝึกอบรม
ส่วนและแทร็ก
โปรแกรมดูการติดตามประกอบด้วยส่วนต่อไปนี้:
- ส่วนหนึ่งสำหรับแต่ละโหนดอุปกรณ์ ซึ่งมีป้ายกำกับด้วยหมายเลขชิปอุปกรณ์และโหนดอุปกรณ์ภายในชิป (เช่น
/device:GPU:0 (pid 0)) ส่วนโหนดอุปกรณ์แต่ละส่วนประกอบด้วยแทร็กต่อไปนี้:- ขั้นตอน : แสดงระยะเวลาของขั้นตอนการฝึกที่ทำงานบนอุปกรณ์
- TensorFlow Ops : แสดงการดำเนินการที่ดำเนินการบนอุปกรณ์
- XLA Ops : แสดงการทำงานของ XLA (ops) ที่ทำงานบนอุปกรณ์หาก XLA เป็นคอมไพเลอร์ที่ใช้ (ops TensorFlow แต่ละตัวถูกแปลเป็น XLA ops เดียวหรือหลายตัว คอมไพเลอร์ XLA แปล XLA ops เป็นโค้ดที่ทำงานบนอุปกรณ์)
- ส่วนหนึ่งสำหรับเธรดที่ทำงานบน CPU ของเครื่องโฮสต์ ซึ่งมีป้ายกำกับว่า "Host Threads" ส่วนนี้ประกอบด้วยหนึ่งแทร็กสำหรับแต่ละเธรด CPU โปรดทราบว่าคุณสามารถละเว้นข้อมูลที่แสดงข้างป้ายกำกับส่วนได้
กิจกรรม
กิจกรรมภายในไทม์ไลน์จะแสดงเป็นสีที่ต่างกัน สีเหล่านั้นไม่มีความหมายเฉพาะเจาะจง
โปรแกรมดูการติดตามยังสามารถแสดงการติดตามการเรียกใช้ฟังก์ชัน Python ในโปรแกรม TensorFlow ของคุณได้ หากคุณใช้ tf.profiler.experimental.start API คุณสามารถเปิดใช้งานการติดตาม Python ได้โดยใช้ ProfilerOptions ที่ชื่อ tuple เมื่อเริ่มต้นการทำโปรไฟล์ อีกทางหนึ่ง หากคุณใช้โหมดสุ่มตัวอย่างสำหรับการจัดทำโปรไฟล์ คุณสามารถเลือกระดับการติดตามได้โดยใช้ตัวเลือกแบบเลื่อนลงในกล่องโต้ตอบ การจับภาพโปรไฟล์
สถิติเคอร์เนล GPU
เครื่องมือนี้แสดงสถิติประสิทธิภาพและการดำเนินการเริ่มต้นสำหรับเคอร์เนลเร่ง GPU ทุกตัว
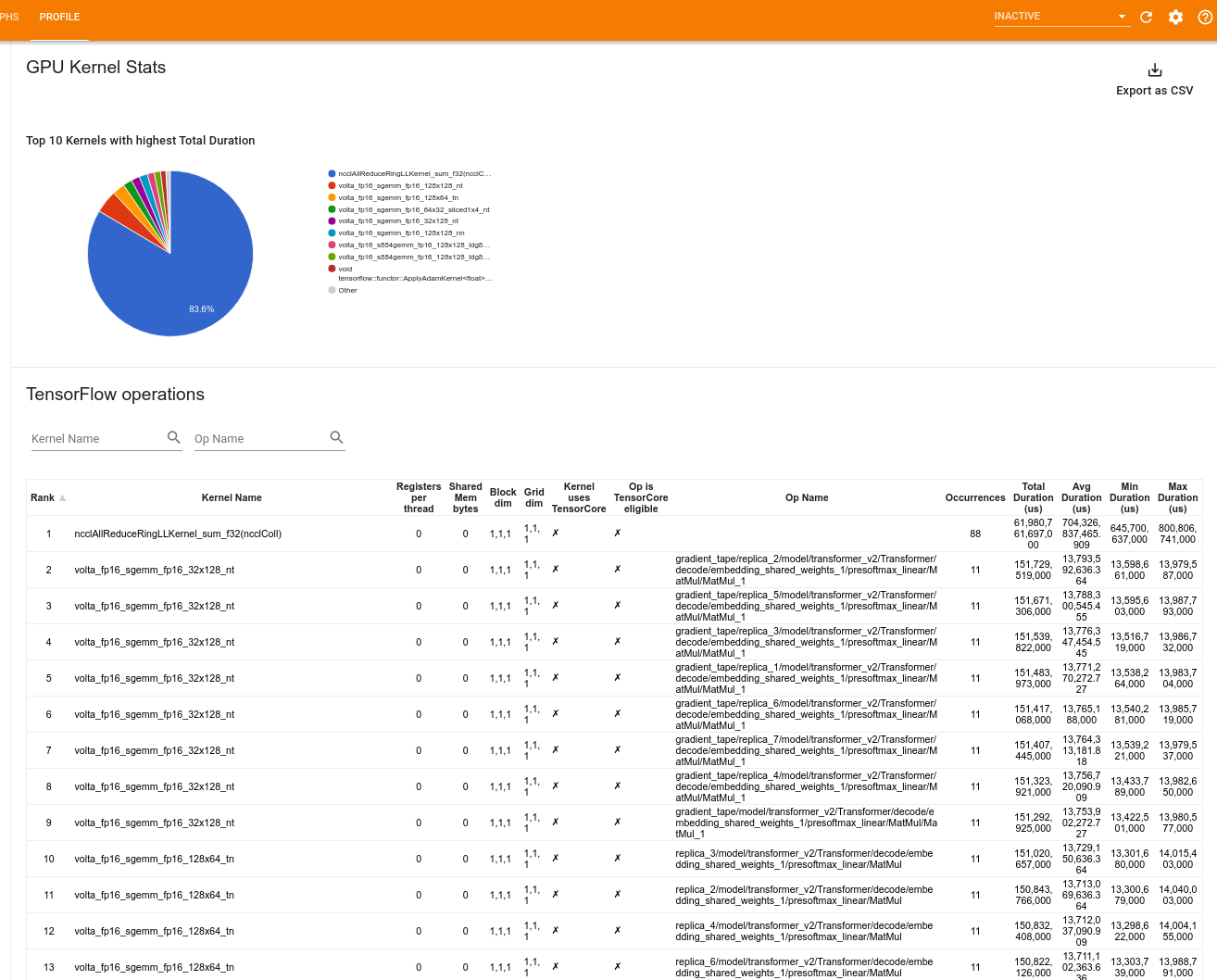
เครื่องมือจะแสดงข้อมูลในสองบานหน้าต่าง:
บานหน้าต่างด้านบนแสดงแผนภูมิวงกลมซึ่งแสดงเคอร์เนล CUDA ที่มีเวลารวมสูงสุดที่ผ่านไป
บานหน้าต่างด้านล่างจะแสดงตารางพร้อมข้อมูลต่อไปนี้สำหรับคู่เคอร์เนล-op ที่ไม่ซ้ำกันแต่ละคู่:
- ลำดับจากมากไปน้อยของระยะเวลา GPU ที่ผ่านไปทั้งหมดซึ่งจัดกลุ่มตามคู่เคอร์เนล-op
- ชื่อของเคอร์เนลที่เปิดใช้
- จำนวนการลงทะเบียน GPU ที่เคอร์เนลใช้
- ขนาดรวมของหน่วยความจำที่แชร์ (สแตติก + ไดนามิกแชร์) ที่ใช้ในหน่วยไบต์
- มิติข้อมูลบล็อกแสดงเป็น
blockDim.x, blockDim.y, blockDim.z - ขนาดกริดที่แสดงเป็น
gridDim.x, gridDim.y, gridDim.z - op มีสิทธิ์ใช้ Tensor Cores หรือไม่
- ไม่ว่าเคอร์เนลจะมีคำสั่ง Tensor Core หรือไม่
- ชื่อของ op ที่เปิดตัวเคอร์เนลนี้
- จำนวนครั้งของคู่เคอร์เนล-op นี้
- เวลา GPU ที่ผ่านไปทั้งหมดเป็นไมโครวินาที
- เวลา GPU ที่ผ่านไปโดยเฉลี่ยในหน่วยไมโครวินาที
- เวลา GPU ที่ผ่านไปขั้นต่ำในหน่วยไมโครวินาที
- เวลา GPU ที่ผ่านไปสูงสุดในหน่วยไมโครวินาที
เครื่องมือโปรไฟล์หน่วยความจำ
เครื่องมือ โปรไฟล์หน่วยความจำ จะตรวจสอบการใช้หน่วยความจำของอุปกรณ์ของคุณในระหว่างช่วงเวลาการทำโปรไฟล์ คุณสามารถใช้เครื่องมือนี้เพื่อ:
- แก้ปัญหาหน่วยความจำไม่เพียงพอ (OOM) โดยระบุการใช้งานหน่วยความจำสูงสุดและการจัดสรรหน่วยความจำที่สอดคล้องกันให้กับการดำเนินการของ TensorFlow คุณยังสามารถแก้ไขปัญหา OOM ที่อาจเกิดขึ้นเมื่อคุณเรียกใช้การอนุมาน หลายผู้เช่า ได้
- แก้ไขปัญหาการกระจายตัวของหน่วยความจำ
เครื่องมือโปรไฟล์หน่วยความจำจะแสดงข้อมูลเป็นสามส่วน:
- สรุปโปรไฟล์หน่วยความจำ
- กราฟไทม์ไลน์หน่วยความจำ
- ตารางสลายหน่วยความจำ
สรุปโปรไฟล์หน่วยความจำ
ส่วนนี้จะแสดงข้อมูลสรุประดับสูงของโปรไฟล์หน่วยความจำของโปรแกรม TensorFlow ของคุณดังที่แสดงด้านล่าง:

สรุปโปรไฟล์หน่วยความจำมีหกฟิลด์:
- รหัสหน่วยความจำ : ดรอปดาวน์ซึ่งแสดงรายการระบบหน่วยความจำอุปกรณ์ที่มีอยู่ทั้งหมด เลือกระบบหน่วยความจำที่คุณต้องการดูจากเมนูแบบเลื่อนลง
- #Allocation : จำนวนการจัดสรรหน่วยความจำที่เกิดขึ้นระหว่างช่วงเวลาการทำโปรไฟล์
- #Deallocation : จำนวนการจัดสรรหน่วยความจำในช่วงเวลาการทำโปรไฟล์
- ความจุหน่วยความจำ : ความจุทั้งหมด (ในหน่วย GiB) ของระบบหน่วยความจำที่คุณเลือก
- การใช้งาน Peak Heap : การใช้งานหน่วยความจำสูงสุด (ในหน่วย GiB) นับตั้งแต่โมเดลเริ่มทำงาน
- การใช้งานหน่วยความจำสูงสุด : การใช้งานหน่วยความจำสูงสุด (ในหน่วย GiB) ในช่วงการทำโปรไฟล์ ฟิลด์นี้ประกอบด้วยฟิลด์ย่อยต่อไปนี้:
- การประทับเวลา : การประทับเวลาที่มีการใช้งานหน่วยความจำสูงสุดบนกราฟไทม์ไลน์
- การสำรองสแต็ก : จำนวนหน่วยความจำที่สงวนไว้บนสแต็ก (ในหน่วย GiB)
- การจัดสรรฮีป : จำนวนหน่วยความจำที่จัดสรรบนฮีป (ในหน่วย GiB)
- หน่วยความจำว่าง : จำนวนหน่วยความจำว่าง (ในหน่วย GiB) ความจุหน่วยความจำคือผลรวมของการสำรองสแต็ก การจัดสรรฮีป และหน่วยความจำว่าง
- Fragmentation : เปอร์เซ็นต์ของการกระจายตัว (ต่ำกว่าดีกว่า) โดยคำนวณเป็นเปอร์เซ็นต์ของ
(1 - Size of the largest chunk of free memory / Total free memory)
กราฟไทม์ไลน์ของหน่วยความจำ
ส่วนนี้แสดงโครงเรื่องของการใช้หน่วยความจำ (ในหน่วย GiB) และเปอร์เซ็นต์ของการกระจายตัวเทียบกับเวลา (ในหน่วยมิลลิวินาที)
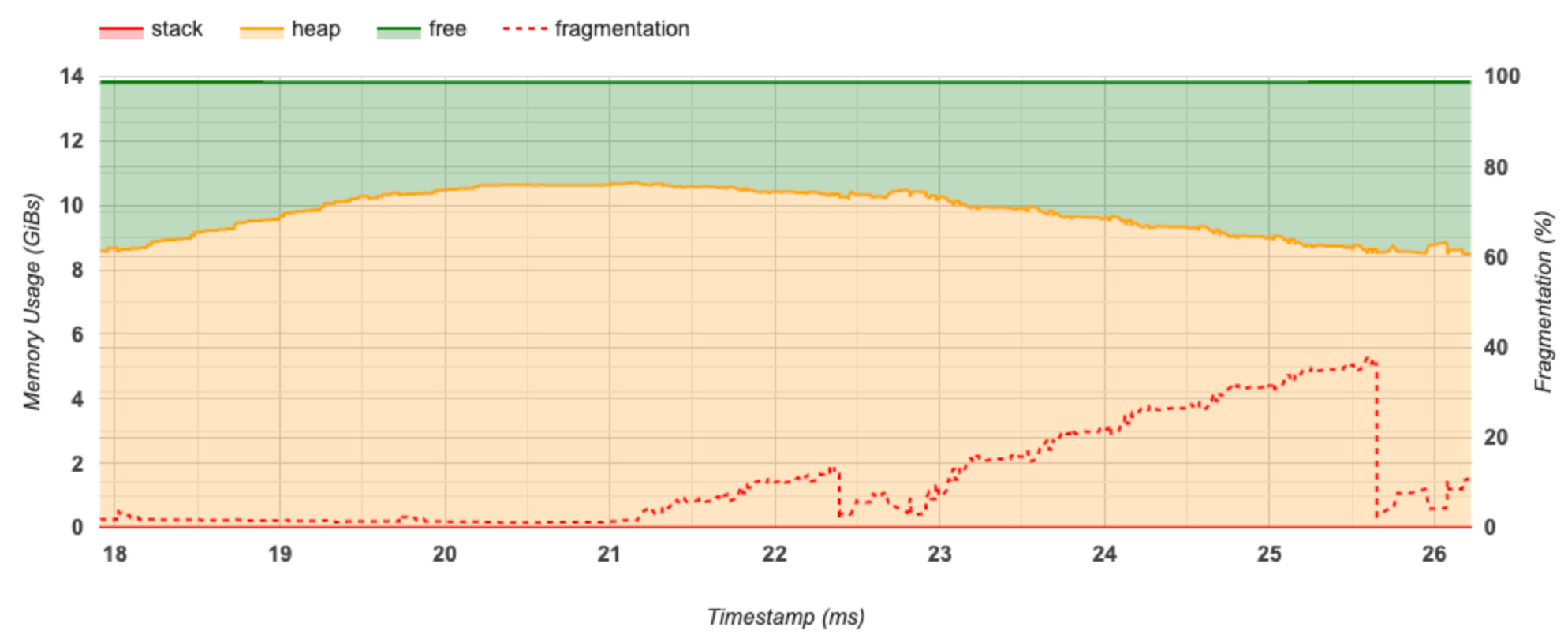
แกน X แสดงถึงไทม์ไลน์ (เป็น ms) ของช่วงเวลาการทำโปรไฟล์ แกน Y ทางด้านซ้ายแสดงถึงการใช้หน่วยความจำ (ในหน่วย GiB) และแกน Y ทางด้านขวาแสดงถึงเปอร์เซ็นต์ของการกระจายตัว ในแต่ละจุดของเวลาบนแกน X หน่วยความจำทั้งหมดจะถูกแบ่งออกเป็นสามประเภท: สแต็ก (สีแดง) ฮีป (สีส้ม) และว่าง (สีเขียว) วางเมาส์เหนือการประทับเวลาที่เฉพาะเจาะจงเพื่อดูรายละเอียดเกี่ยวกับเหตุการณ์การจัดสรรหน่วยความจำ/การจัดสรรคืน ณ จุดนั้นดังนี้:
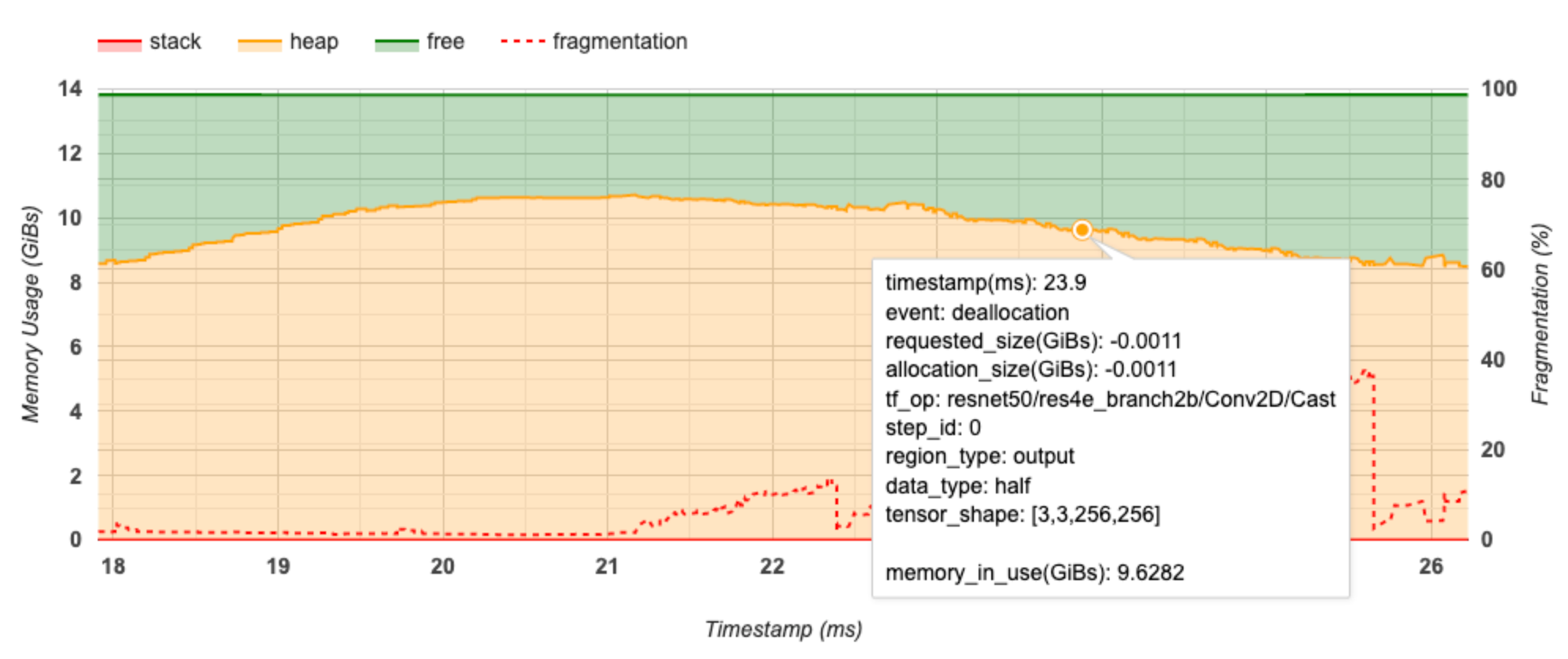
หน้าต่างป๊อปอัปจะแสดงข้อมูลต่อไปนี้:
- timestamp(ms) : ตำแหน่งของเหตุการณ์ที่เลือกบนไทม์ไลน์
- เหตุการณ์ : ประเภทของเหตุการณ์ (การจัดสรรหรือการจัดสรรคืน)
- Request_size(GiBs) : จำนวนหน่วยความจำที่ร้องขอ นี่จะเป็นจำนวนลบสำหรับเหตุการณ์การจัดสรรคืน
- allocation_size(GiBs) : จำนวนหน่วยความจำจริงที่จัดสรร นี่จะเป็นจำนวนลบสำหรับเหตุการณ์การจัดสรรคืน
- tf_op : op TensorFlow ที่ร้องขอการจัดสรร/การจัดสรรคืน
- step_id : ขั้นตอนการฝึกอบรมที่เกิดเหตุการณ์นี้
- Region_type : ประเภทเอนทิตีข้อมูลที่จัดสรรหน่วยความจำนี้ไว้ ค่าที่เป็นไปได้ ได้แก่
tempสำหรับค่าชั่วคราวoutputสำหรับการเปิดใช้งานและการไล่ระดับสี และค่าpersist/dynamicสำหรับน้ำหนักและค่าคงที่ - data_type : ประเภทองค์ประกอบเทนเซอร์ (เช่น uint8 สำหรับจำนวนเต็ม 8 บิตที่ไม่ได้ลงนาม)
- tensor_shape : รูปร่างของเทนเซอร์ที่กำลังจัดสรร/จัดสรรคืน
- memory_in_use(GiBs) : หน่วยความจำทั้งหมดที่ใช้งาน ณ จุดนี้
ตารางสลายหน่วยความจำ
ตารางนี้แสดงการจัดสรรหน่วยความจำที่ใช้งานอยู่ ณ จุดที่มีการใช้งานหน่วยความจำสูงสุดในช่วงเวลาการทำโปรไฟล์
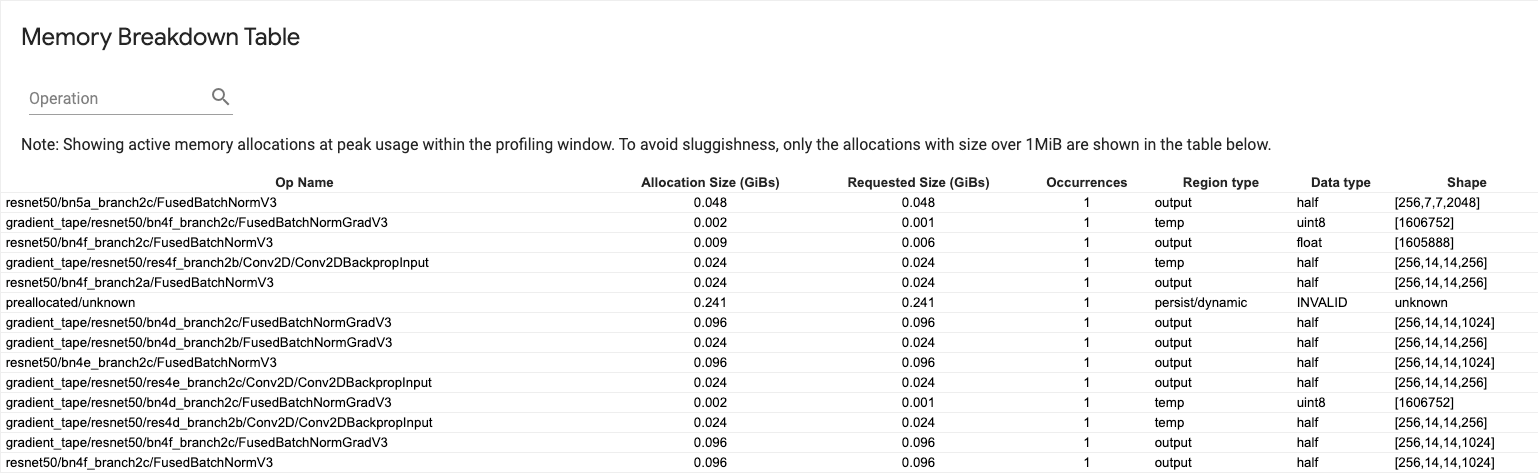
มีหนึ่งแถวสำหรับแต่ละ TensorFlow Op และแต่ละแถวมีคอลัมน์ต่อไปนี้:
- ชื่อ Op : ชื่อของ TensorFlow op
- ขนาดการจัดสรร (GiBs) : จำนวนหน่วยความจำทั้งหมดที่จัดสรรให้กับ op นี้
- ขนาดที่ร้องขอ (GiBs) : จำนวนหน่วยความจำทั้งหมดที่ร้องขอสำหรับการดำเนินการนี้
- การเกิดขึ้น : จำนวนของการจัดสรรสำหรับการดำเนินการนี้
- ประเภทภูมิภาค : ประเภทเอนทิตีข้อมูลที่จัดสรรหน่วยความจำนี้ไว้ ค่าที่เป็นไปได้ ได้แก่
tempสำหรับค่าชั่วคราวoutputสำหรับการเปิดใช้งานและการไล่ระดับสี และค่าpersist/dynamicสำหรับน้ำหนักและค่าคงที่ - ประเภทข้อมูล : ประเภทองค์ประกอบเทนเซอร์
- รูปร่าง : รูปร่างของเทนเซอร์ที่จัดสรร
โปรแกรมดูพ็อด
เครื่องมือ Pod Viewer จะแสดงรายละเอียดขั้นตอนการฝึกอบรมสำหรับพนักงานทั้งหมด
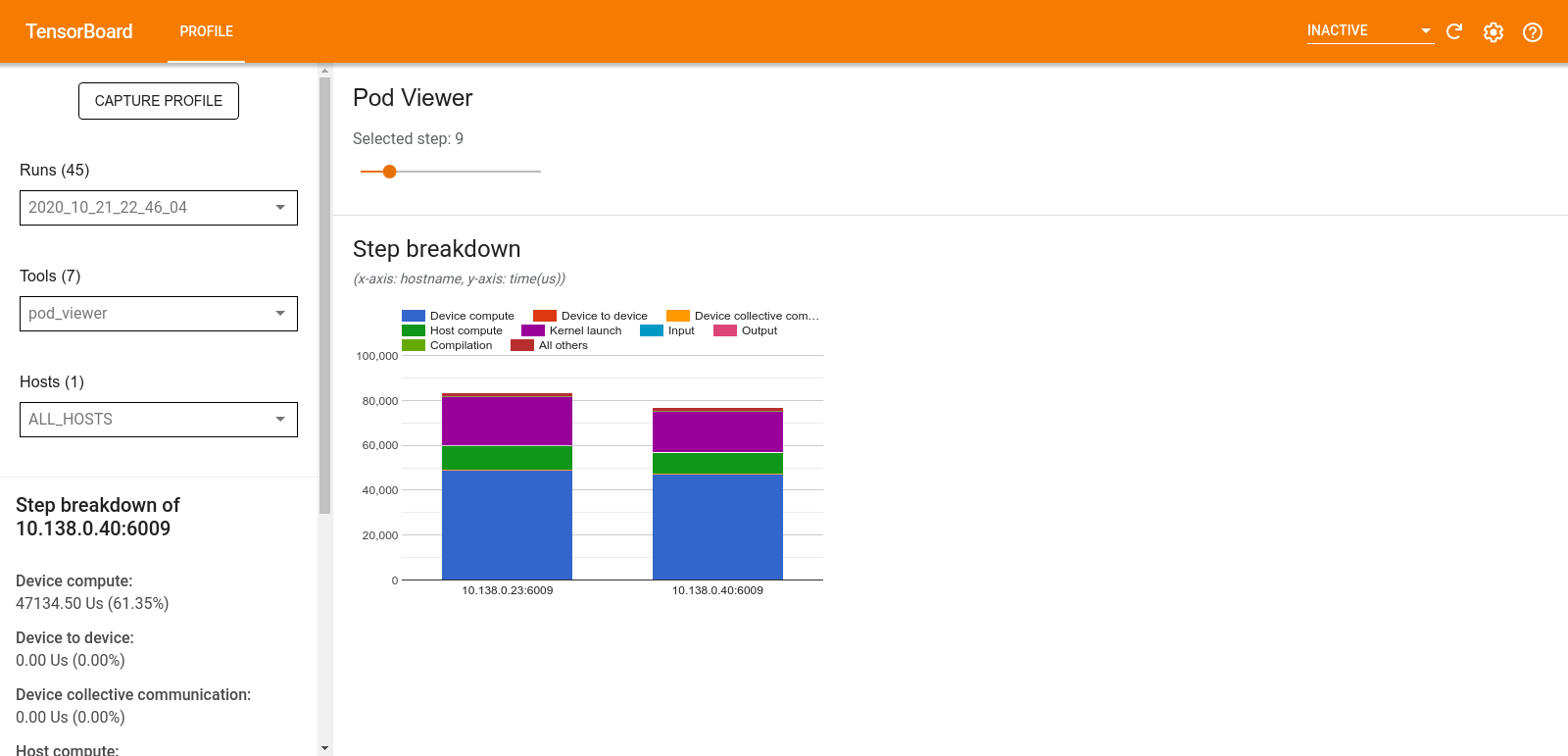
- บานหน้าต่างด้านบนมีแถบเลื่อนสำหรับเลือกหมายเลขขั้นตอน
- บานหน้าต่างด้านล่างแสดงแผนภูมิคอลัมน์แบบเรียงซ้อน นี่คือมุมมองระดับสูงของหมวดหมู่เวลาแบบแยกย่อยที่วางซ้อนกัน แต่ละคอลัมน์แบบเรียงซ้อนแสดงถึงผู้ปฏิบัติงานที่ไม่ซ้ำกัน
- เมื่อคุณวางเมาส์เหนือคอลัมน์แบบเรียงซ้อน การ์ดทางด้านซ้ายจะแสดงรายละเอียดเพิ่มเติมเกี่ยวกับการแบ่งขั้นตอน
การวิเคราะห์คอขวดของ tf.data
เครื่องมือวิเคราะห์คอขวด tf.data จะตรวจจับปัญหาคอขวดในไปป์ไลน์อินพุต tf.data ในโปรแกรมของคุณโดยอัตโนมัติ และให้คำแนะนำเกี่ยวกับวิธีการแก้ไข ใช้งานได้กับทุกโปรแกรมที่ใช้ tf.data โดยไม่คำนึงถึงแพลตฟอร์ม (CPU/GPU/TPU) การวิเคราะห์และคำแนะนำเป็นไปตาม คู่มือ นี้
ตรวจพบปัญหาคอขวดโดยทำตามขั้นตอนเหล่านี้:
- ค้นหาโฮสต์ที่ถูกผูกไว้กับอินพุตมากที่สุด
- ค้นหาการดำเนินการที่ช้าที่สุดของไปป์ไลน์อินพุต
tf.data - สร้างกราฟไปป์ไลน์อินพุตใหม่จากการติดตามตัวสร้างโปรไฟล์
- ค้นหาเส้นทางวิกฤตในกราฟไปป์ไลน์อินพุต
- ระบุการเปลี่ยนแปลงที่ช้าที่สุดบนเส้นทางวิกฤตว่าเป็นคอขวด
UI แบ่งออกเป็นสามส่วน: สรุปการวิเคราะห์ประสิทธิภาพ , สรุปไปป์ไลน์อินพุตทั้งหมด และ กราฟไปป์ไลน์อินพุต
สรุปการวิเคราะห์ประสิทธิภาพ

ส่วนนี้จะให้ข้อมูลสรุปของการวิเคราะห์ รายงานเกี่ยวกับไปป์ไลน์อินพุต tf.data ที่ช้าที่ตรวจพบในโปรไฟล์ ส่วนนี้ยังแสดงโฮสต์ที่ถูกผูกเข้ากับอินพุตมากที่สุดและไปป์ไลน์อินพุตที่ช้าที่สุดพร้อมเวลาแฝงสูงสุด สิ่งสำคัญที่สุดคือระบุว่าส่วนใดของไปป์ไลน์อินพุตที่เป็นคอขวดและวิธีแก้ไข ข้อมูลคอขวดมาพร้อมกับประเภทตัววนซ้ำและชื่อแบบยาว
วิธีอ่านชื่อยาวของ tf.data iterator
ชื่อยาวถูกจัดรูปแบบเป็น Iterator::<Dataset_1>::...::<Dataset_n> ในชื่อแบบยาว <Dataset_n> จะตรงกับประเภทตัววนซ้ำ และชุดข้อมูลอื่นๆ ในชื่อแบบยาวแสดงถึงการแปลงดาวน์สตรีม
ตัวอย่างเช่น พิจารณาชุดข้อมูลไปป์ไลน์อินพุตต่อไปนี้:
dataset = tf.data.Dataset.range(10).map(lambda x: x).repeat(2).batch(5)
ชื่อยาวสำหรับตัววนซ้ำจากชุดข้อมูลด้านบนจะเป็น:
| ประเภทตัววนซ้ำ | ชื่อยาว |
|---|---|
| พิสัย | ตัววนซ้ำ::ชุด::ทำซ้ำ::แผนที่::ช่วง |
| แผนที่ | ตัววนซ้ำ::ชุด::ทำซ้ำ::แผนที่ |
| ทำซ้ำ | ตัววนซ้ำ::แบทช์::ทำซ้ำ |
| แบทช์ | ตัววนซ้ำ::Batch |
สรุปท่อนำเข้าทั้งหมด
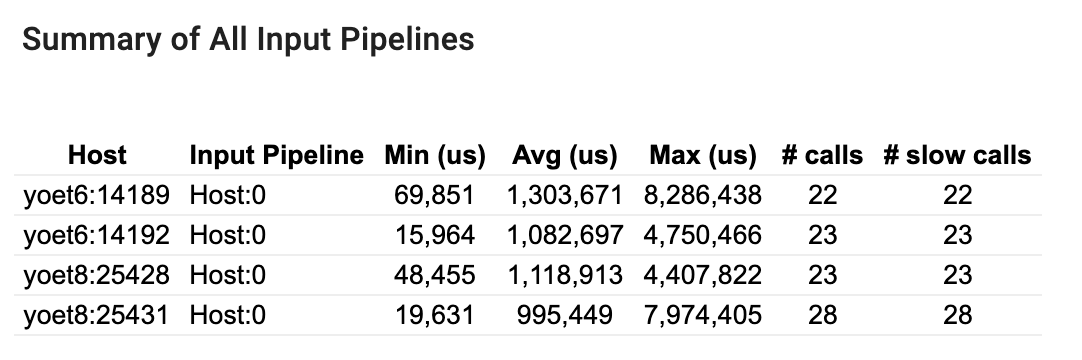
ส่วนนี้จะให้ข้อมูลสรุปของไปป์ไลน์อินพุตทั้งหมดทั่วทั้งโฮสต์ทั้งหมด โดยทั่วไปจะมีไปป์ไลน์อินพุตหนึ่งรายการ เมื่อใช้กลยุทธ์การกระจาย จะมีไปป์ไลน์อินพุตโฮสต์หนึ่งรันโค้ด tf.data ของโปรแกรมและไปป์ไลน์อินพุตของอุปกรณ์หลายตัวดึงข้อมูลจากไปป์ไลน์อินพุตโฮสต์และถ่ายโอนไปยังอุปกรณ์
สำหรับแต่ละไปป์ไลน์อินพุต จะแสดงสถิติของเวลาดำเนินการ การโทรจะนับว่าช้าหากใช้เวลานานกว่า 50 μs
กราฟไปป์ไลน์อินพุต

ส่วนนี้จะแสดงกราฟไปป์ไลน์อินพุตพร้อมข้อมูลเวลาดำเนินการ คุณสามารถใช้ "Host" และ "Input Pipeline" เพื่อเลือกโฮสต์และไปป์ไลน์อินพุตที่ต้องการดู การดำเนินการไปป์ไลน์อินพุตจะถูกจัดเรียงตามเวลาดำเนินการตามลำดับจากมากไปน้อย ซึ่งคุณสามารถเลือกได้โดยใช้เมนูแบบเลื่อนลง อันดับ
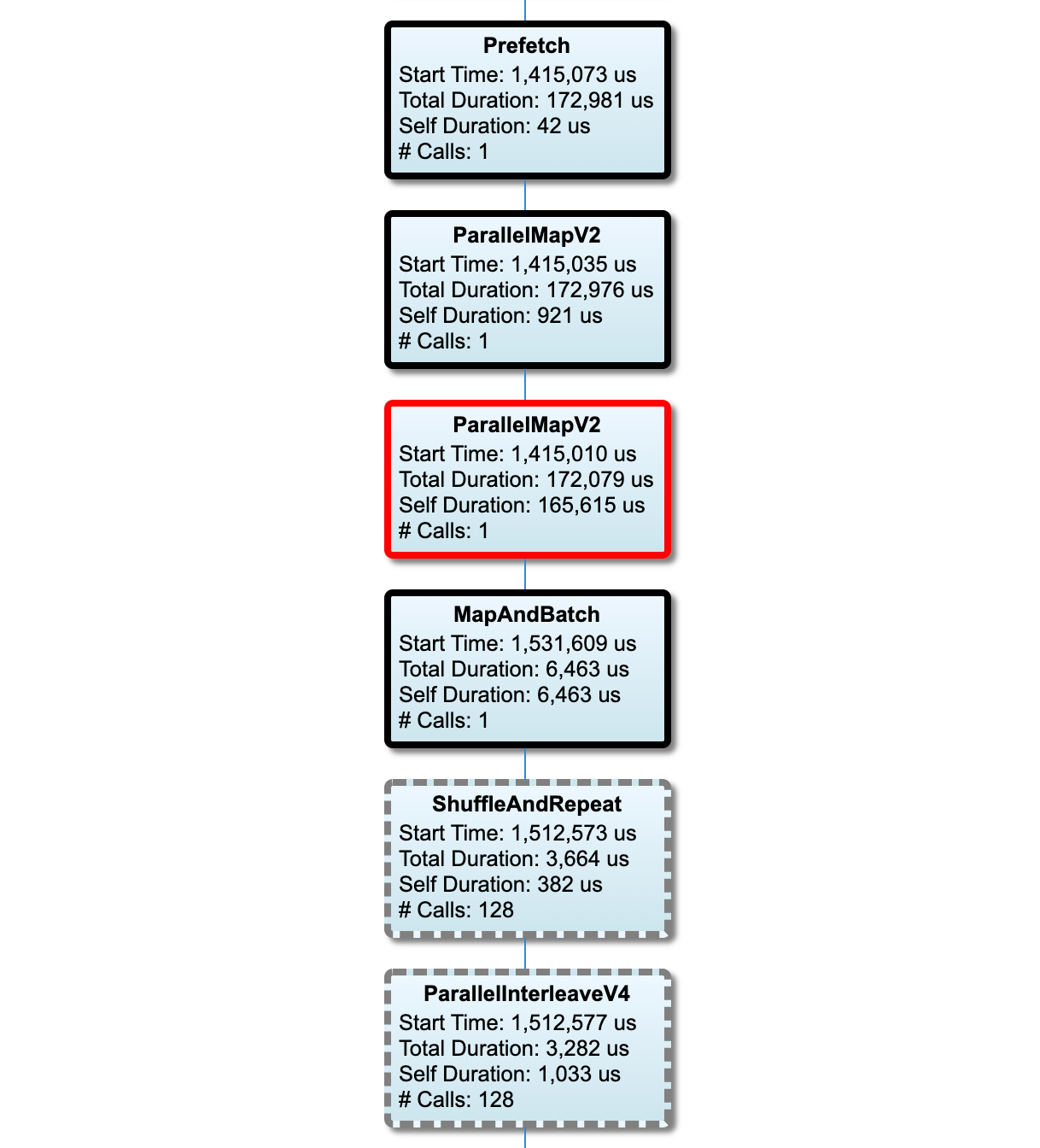
โหนดบนเส้นทางวิกฤตมีโครงร่างที่หนา โหนดคอขวด ซึ่งเป็นโหนดที่มีเวลาตัวเองนานที่สุดบนเส้นทางวิกฤติ มีโครงร่างสีแดง โหนดที่ไม่สำคัญอื่นๆ จะมีเส้นประสีเทา
ในแต่ละโหนด เวลาเริ่มต้น ระบุเวลาเริ่มต้นของการดำเนินการ โหนดเดียวกันอาจถูกดำเนินการหลายครั้ง เช่น หากมี Batch op ในไปป์ไลน์อินพุต หากมีการดำเนินการหลายครั้ง จะเป็นเวลาเริ่มต้นของการดำเนินการครั้งแรก
Total Duration คือเวลาวอลล์ของการดำเนินการ หากมีการดำเนินการหลายครั้ง จะเป็นผลรวมของเวลาติดผนังของการดำเนินการทั้งหมด
เวลาตนเอง คือ เวลาทั้งหมด โดยไม่มีเวลาที่ทับซ้อนกันกับโหนดย่อยที่อยู่ติดกัน
"# Calls" คือจำนวนครั้งที่ไปป์ไลน์อินพุตถูกดำเนินการ
รวบรวมข้อมูลประสิทธิภาพ
TensorFlow Profiler รวบรวมกิจกรรมโฮสต์และการติดตาม GPU ของโมเดล TensorFlow ของคุณ คุณสามารถกำหนดค่า Profiler เพื่อรวบรวมข้อมูลประสิทธิภาพผ่านโหมดทางโปรแกรมหรือโหมดสุ่มตัวอย่าง
API การทำโปรไฟล์
คุณสามารถใช้ API ต่อไปนี้เพื่อดำเนินการโปรไฟล์ได้
โหมดแบบเป็นโปรแกรมโดยใช้ TensorBoard Keras Callback (
tf.keras.callbacks.TensorBoard)# Profile from batches 10 to 15 tb_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, profile_batch='10, 15') # Train the model and use the TensorBoard Keras callback to collect # performance profiling data model.fit(train_data, steps_per_epoch=20, epochs=5, callbacks=[tb_callback])โหมดแบบเป็นโปรแกรมโดยใช้
tf.profilerFunction APItf.profiler.experimental.start('logdir') # Train the model here tf.profiler.experimental.stop()โหมดทางโปรแกรมโดยใช้ตัวจัดการบริบท
with tf.profiler.experimental.Profile('logdir'): # Train the model here pass
โหมดสุ่มตัวอย่าง: ดำเนินการโปรไฟล์ตามความต้องการโดยใช้
tf.profiler.experimental.server.startเพื่อเริ่มต้นเซิร์ฟเวอร์ gRPC ด้วยการรันโมเดล TensorFlow ของคุณ หลังจากเริ่มต้นเซิร์ฟเวอร์ gRPC และเรียกใช้โมเดลของคุณ คุณสามารถจับภาพโปรไฟล์ผ่านปุ่ม จับภาพโปรไฟล์ ในปลั๊กอินโปรไฟล์ TensorBoard ใช้สคริปต์ในส่วนติดตั้งตัวสร้างโปรไฟล์ด้านบนเพื่อเปิดใช้อินสแตนซ์ TensorBoard หากยังไม่ได้ทำงานอยู่ตัวอย่างเช่น
# Start a profiler server before your model runs. tf.profiler.experimental.server.start(6009) # (Model code goes here). # Send a request to the profiler server to collect a trace of your model. tf.profiler.experimental.client.trace('grpc://localhost:6009', 'gs://your_tb_logdir', 2000)ตัวอย่างสำหรับการจัดทำโปรไฟล์ผู้ปฏิบัติงานหลายคน:
# E.g., your worker IP addresses are 10.0.0.2, 10.0.0.3, 10.0.0.4, and you # would like to profile for a duration of 2 seconds. tf.profiler.experimental.client.trace( 'grpc://10.0.0.2:8466,grpc://10.0.0.3:8466,grpc://10.0.0.4:8466', 'gs://your_tb_logdir', 2000)

ใช้กล่องโต้ตอบ จับภาพโปรไฟล์ เพื่อระบุ:
- รายการ URL บริการโปรไฟล์หรือชื่อ TPU ที่คั่นด้วยเครื่องหมายจุลภาค
- ระยะเวลาการทำโปรไฟล์
- ระดับของอุปกรณ์ โฮสต์ และการติดตามการโทรของฟังก์ชัน Python
- มีกี่ครั้งที่คุณต้องการให้ Profiler ลองบันทึกโปรไฟล์อีกครั้งหากไม่สำเร็จในตอนแรก
การทำโปรไฟล์ลูปการฝึกอบรมแบบกำหนดเอง
หากต้องการกำหนดโปรไฟล์ลูปการฝึกแบบกำหนดเองในโค้ด TensorFlow ให้ติดตั้งลูปการฝึกด้วย tf.profiler.experimental.Trace API เพื่อทำเครื่องหมายขอบเขตขั้นตอนสำหรับ Profiler
อาร์กิวเมนต์ name ถูกใช้เป็นคำนำหน้าสำหรับชื่อขั้นตอน อาร์กิวเมนต์คีย์เวิร์ด step_num จะถูกต่อท้ายชื่อขั้นตอน และอาร์กิวเมนต์คีย์เวิร์ด _r ทำให้เหตุการณ์การติดตามนี้ได้รับการประมวลผลเป็นเหตุการณ์ขั้นตอนโดย Profiler
ตัวอย่างเช่น
for step in range(NUM_STEPS):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_data = next(dataset)
train_step(train_data)
สิ่งนี้จะเปิดใช้งานการวิเคราะห์ประสิทธิภาพตามขั้นตอนของ Profiler และทำให้เหตุการณ์ขั้นตอนแสดงในโปรแกรมดูการติดตาม
ตรวจสอบให้แน่ใจว่าคุณรวมตัววนซ้ำชุดข้อมูลภายในบริบท tf.profiler.experimental.Trace เพื่อการวิเคราะห์ไปป์ไลน์อินพุตที่แม่นยำ
ข้อมูลโค้ดด้านล่างนี้เป็นรูปแบบการต่อต้าน:
for step, train_data in enumerate(dataset):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_step(train_data)
กรณีการใช้งานการทำโปรไฟล์
เครื่องมือสร้างโปรไฟล์ครอบคลุมกรณีการใช้งานจำนวนหนึ่งตามแกนที่แตกต่างกันสี่แกน ปัจจุบันรองรับชุดค่าผสมบางส่วนแล้ว และชุดค่าผสมอื่นๆ จะถูกเพิ่มในอนาคต กรณีการใช้งานบางส่วน ได้แก่:
- การทำโปรไฟล์เฉพาะที่และระยะไกล : นี่เป็นวิธีทั่วไปสองวิธีในการตั้งค่าสภาพแวดล้อมการทำโปรไฟล์ของคุณ ในการจัดทำโปรไฟล์เฉพาะที่ API การทำโปรไฟล์จะถูกเรียกบนเครื่องเดียวกับที่โมเดลของคุณกำลังดำเนินการอยู่ เช่น เวิร์กสเตชันเฉพาะที่ที่มี GPU ในการจัดทำโปรไฟล์ระยะไกล API การทำโปรไฟล์จะถูกเรียกบนเครื่องอื่นจากที่โมเดลของคุณดำเนินการอยู่ เช่น บน Cloud TPU
- การทำโปรไฟล์พนักงานหลายคน : คุณสามารถทำโปรไฟล์เครื่องจักรหลายเครื่องได้ เมื่อใช้ความสามารถในการฝึกอบรมแบบกระจายของ TensorFlow
- แพลตฟอร์มฮาร์ดแวร์ : โปรไฟล์ CPU, GPU และ TPU
ตารางด้านล่างแสดงภาพรวมโดยย่อของกรณีการใช้งานที่รองรับ TensorFlow ที่กล่าวถึงข้างต้น:
| API การทำโปรไฟล์ | ท้องถิ่น | ระยะไกล | คนงานหลายคน | แพลตฟอร์มฮาร์ดแวร์ |
|---|---|---|---|---|
| TensorBoard Keras โทรกลับ | รองรับ | ไม่รองรับ | ไม่รองรับ | ซีพียู, จีพียู |
tf.profiler.experimental เริ่มต้น/หยุด การทดลอง | รองรับ | ไม่รองรับ | ไม่รองรับ | ซีพียู, จีพียู |
tf.profiler.experimental client.trace API | รองรับ | รองรับ | รองรับ | ซีพียู, GPU, ทีพียู |
| API ตัวจัดการบริบท | รองรับ | ไม่รองรับ | ไม่รองรับ | ซีพียู, จีพียู |
แนวทางปฏิบัติที่ดีที่สุดสำหรับประสิทธิภาพของโมเดลที่เหมาะสมที่สุด
ใช้คำแนะนำต่อไปนี้ตามที่เกี่ยวข้องกับโมเดล TensorFlow ของคุณเพื่อให้ได้ประสิทธิภาพสูงสุด
โดยทั่วไป ให้ทำการเปลี่ยนแปลงทั้งหมดบนอุปกรณ์และตรวจสอบให้แน่ใจว่าคุณใช้ไลบรารีเวอร์ชันล่าสุดที่เข้ากันได้ เช่น cuDNN และ Intel MKL สำหรับแพลตฟอร์มของคุณ
ปรับไปป์ไลน์ข้อมูลอินพุตให้เหมาะสม
ใช้ข้อมูลจาก [#input_pipeline_analyzer] เพื่อเพิ่มประสิทธิภาพไปป์ไลน์อินพุตข้อมูลของคุณ ไปป์ไลน์ป้อนข้อมูลที่มีประสิทธิภาพสามารถปรับปรุงความเร็วการดำเนินการโมเดลของคุณได้อย่างมากโดยการลดเวลาว่างของอุปกรณ์ พยายามรวมแนวทางปฏิบัติที่ดีที่สุดซึ่งมีรายละเอียดอยู่ใน Better Performance เข้ากับคำแนะนำ tf.data API และด้านล่างเพื่อทำให้ไปป์ไลน์อินพุตข้อมูลของคุณมีประสิทธิภาพมากขึ้น
โดยทั่วไป การทำการดำเนินการใดๆ แบบขนานที่ไม่จำเป็นต้องดำเนินการตามลำดับสามารถเพิ่มประสิทธิภาพไปป์ไลน์อินพุตข้อมูลได้อย่างมาก
ในหลายกรณี การเปลี่ยนลำดับของการเรียกหรือปรับแต่งอาร์กิวเมนต์เพื่อให้ทำงานได้ดีที่สุดสำหรับโมเดลของคุณจะช่วยได้ ในขณะที่ปรับไปป์ไลน์ข้อมูลอินพุตให้เหมาะสม ให้เปรียบเทียบเฉพาะตัวโหลดข้อมูลโดยไม่ต้องมีการฝึกอบรมและขั้นตอนการเผยแพร่กลับเพื่อวัดปริมาณผลกระทบของการปรับให้เหมาะสมอย่างอิสระ
ลองรันโมเดลของคุณด้วยข้อมูลสังเคราะห์เพื่อตรวจสอบว่าไปป์ไลน์อินพุตเป็นปัญหาคอขวดของประสิทธิภาพหรือไม่
ใช้
tf.data.Dataset.shardสำหรับการฝึก Multi-GPU ตรวจสอบให้แน่ใจว่าคุณแบ่งส่วนข้อมูลตั้งแต่เนิ่นๆ ในลูปอินพุตเพื่อป้องกันการลดปริมาณงาน เมื่อทำงานกับ TFRecords ตรวจสอบให้แน่ใจว่าคุณได้แยกรายการ TFRecords ไม่ใช่เนื้อหาของ TFRecordsทำให้ ops หลายรายการขนานกันโดยการตั้งค่า
num_parallel_callsแบบไดนามิกโดยใช้tf.data.AUTOTUNEพิจารณาจำกัดการใช้งาน
tf.data.Dataset.from_generatorเนื่องจากช้ากว่าเมื่อเทียบกับตัวเลือก TensorFlow ล้วนๆพิจารณาจำกัดการใช้
tf.py_functionเนื่องจากไม่สามารถทำให้เป็นอนุกรมได้ และไม่รองรับการทำงานใน TensorFlow แบบกระจายใช้
tf.data.Optionsเพื่อควบคุมการเพิ่มประสิทธิภาพแบบคงที่ให้กับไปป์ไลน์อินพุต
โปรดอ่าน คู่มือ การวิเคราะห์ประสิทธิภาพ tf.data เพื่อดูคำแนะนำเพิ่มเติมเกี่ยวกับการเพิ่มประสิทธิภาพไปป์ไลน์อินพุตของคุณ
เพิ่มประสิทธิภาพการเพิ่มข้อมูล
เมื่อทำงานกับข้อมูลรูปภาพ ทำให้ การเพิ่มข้อมูล ของคุณมีประสิทธิภาพมากขึ้นโดยการแคสต์ไปยังข้อมูลประเภทต่างๆ หลังจาก ใช้การแปลงเชิงพื้นที่ เช่น การพลิก การครอบตัด การหมุน ฯลฯ
ใช้ NVIDIA® DALI
ในบางกรณี เช่น เมื่อคุณมีระบบที่มีอัตราส่วน GPU ต่อ CPU สูง การเพิ่มประสิทธิภาพข้างต้นทั้งหมดอาจไม่เพียงพอที่จะกำจัดปัญหาคอขวดในตัวโหลดข้อมูลที่เกิดจากข้อจำกัดของวงจร CPU
หากคุณใช้ NVIDIA® GPU สำหรับคอมพิวเตอร์วิทัศน์และแอปพลิเคชันการเรียนรู้เชิงลึกด้านเสียง ให้พิจารณาใช้ Data Loading Library ( DALI ) เพื่อเร่งไปป์ไลน์ข้อมูล
ตรวจสอบเอกสาร NVIDIA® DALI: Operations เพื่อดูรายการการดำเนินการของ DALI ที่รองรับ
ใช้เธรดและการดำเนินการแบบขนาน
เรียกใช้ Ops บนเธรด CPU หลายเธรดด้วย tf.config.threading API เพื่อดำเนินการได้เร็วขึ้น
TensorFlow จะตั้งค่าจำนวนเธรดแบบขนานโดยอัตโนมัติตามค่าเริ่มต้น เธรดพูลที่พร้อมใช้งานสำหรับการเรียกใช้การดำเนินการ TensorFlow ขึ้นอยู่กับจำนวนเธรด CPU ที่พร้อมใช้งาน
ควบคุมการเร่งความเร็วแบบขนานสูงสุดสำหรับ op เดียวโดยใช้ tf.config.threading.set_intra_op_parallelism_threads โปรดทราบว่าหากคุณเรียกใช้หลาย ops พร้อมกัน การดำเนินการทั้งหมดจะแชร์เธรดพูลที่มีอยู่
หากคุณมี ops อิสระที่ไม่มีการบล็อก (ops ที่ไม่มีเส้นทางกำกับระหว่างตัวเลือกเหล่านั้นบนกราฟ) ให้ใช้ tf.config.threading.set_inter_op_parallelism_threads เพื่อรันพร้อมกันโดยใช้เธรดพูลที่มีอยู่
เบ็ดเตล็ด
เมื่อทำงานกับโมเดลขนาดเล็กบน NVIDIA® GPU คุณสามารถตั้งค่า tf.compat.v1.ConfigProto.force_gpu_compatible=True เพื่อบังคับให้เทนเซอร์ CPU ทั้งหมดได้รับการจัดสรรด้วยหน่วยความจำที่ปักหมุด CUDA เพื่อเพิ่มประสิทธิภาพการทำงานของโมเดลอย่างมีนัยสำคัญ อย่างไรก็ตาม ควรใช้ความระมัดระวังขณะใช้ตัวเลือกนี้สำหรับรุ่นที่ไม่รู้จัก/มีขนาดใหญ่มาก เนื่องจากอาจส่งผลเสียต่อประสิทธิภาพของโฮสต์ (CPU)
ปรับปรุงประสิทธิภาพของอุปกรณ์
ปฏิบัติตามแนวทางปฏิบัติที่ดีที่สุดซึ่งมีรายละเอียดอยู่ที่นี่และใน คู่มือการเพิ่มประสิทธิภาพ GPU เพื่อเพิ่มประสิทธิภาพโมเดล TensorFlow บนอุปกรณ์
หากคุณใช้ NVIDIA GPU ให้บันทึกการใช้งาน GPU และหน่วยความจำเป็นไฟล์ CSV โดยเรียกใช้:
nvidia-smi
--query-gpu=utilization.gpu,utilization.memory,memory.total,
memory.free,memory.used --format=csv
กำหนดค่าโครงร่างข้อมูล
เมื่อทำงานกับข้อมูลที่มีข้อมูลช่อง (เช่น รูปภาพ) ให้ปรับรูปแบบเค้าโครงข้อมูลให้เหมาะสมเพื่อให้ช่องอยู่หลังที่สุด (NHWC มากกว่า NCHW)
รูปแบบข้อมูลสุดท้ายของแชนเนลช่วยปรับปรุงการใช้งาน Tensor Core และให้การปรับปรุงประสิทธิภาพที่สำคัญ โดยเฉพาะอย่างยิ่งในโมเดลแบบสลับเมื่อใช้ร่วมกับ AMP เค้าโครงข้อมูล NCHW ยังคงสามารถใช้งานได้โดย Tensor Cores แต่จะมีค่าใช้จ่ายเพิ่มเติมเนื่องจากการดำเนินการย้ายอัตโนมัติ
คุณสามารถปรับเค้าโครงข้อมูลให้เหมาะสมเพื่อให้เหมาะกับเค้าโครง NHWC ได้โดยการตั้งค่า data_format="channels_last" สำหรับเลเยอร์ต่างๆ เช่น tf.keras.layers.Conv2D , tf.keras.layers.Conv3D และ tf.keras.layers.RandomRotation
ใช้ tf.keras.backend.set_image_data_format เพื่อตั้งค่ารูปแบบเค้าโครงข้อมูลเริ่มต้นสำหรับ Keras แบ็กเอนด์ API
เพิ่มแคช L2 สูงสุด
เมื่อทำงานกับ NVIDIA® GPU ให้รันโค้ดด้านล่างก่อนลูปการฝึกเพื่อเพิ่มความละเอียดในการดึง L2 สูงสุดเป็น 128 ไบต์
import ctypes
_libcudart = ctypes.CDLL('libcudart.so')
# Set device limit on the current device
# cudaLimitMaxL2FetchGranularity = 0x05
pValue = ctypes.cast((ctypes.c_int*1)(), ctypes.POINTER(ctypes.c_int))
_libcudart.cudaDeviceSetLimit(ctypes.c_int(0x05), ctypes.c_int(128))
_libcudart.cudaDeviceGetLimit(pValue, ctypes.c_int(0x05))
assert pValue.contents.value == 128
กำหนดค่าการใช้งานเธรด GPU
โหมดเธรด GPU เป็นตัวกำหนดว่าจะใช้เธรด GPU อย่างไร
ตั้งค่าโหมดเธรดเป็น gpu_private เพื่อให้แน่ใจว่าการประมวลผลล่วงหน้าไม่ได้ขโมยเธรด GPU ทั้งหมด สิ่งนี้จะลดความล่าช้าในการเปิดตัวเคอร์เนลในระหว่างการฝึกอบรม คุณยังสามารถตั้งค่าจำนวนเธรดต่อ GPU ตั้งค่าเหล่านี้โดยใช้ตัวแปรสภาพแวดล้อม
import os
os.environ['TF_GPU_THREAD_MODE']='gpu_private'
os.environ['TF_GPU_THREAD_COUNT']='1'
กำหนดค่าตัวเลือกหน่วยความจำ GPU
โดยทั่วไปเพิ่มขนาดแบทช์และปรับขนาดโมเดลเพื่อใช้ GPU ที่ดีขึ้นและรับปริมาณงานที่สูงขึ้น โปรดทราบว่าการเพิ่มขนาดแบทช์จะเปลี่ยนความแม่นยำของโมเดลดังนั้นโมเดลจะต้องปรับขนาดโดยการปรับพารามิเตอร์ไฮเปอร์พารามิเตอร์เช่นอัตราการเรียนรู้เพื่อให้ตรงกับความแม่นยำของเป้าหมาย
นอกจากนี้ให้ใช้ tf.config.experimental.set_memory_growth เพื่อให้หน่วยความจำ GPU เติบโตเพื่อป้องกันไม่ให้หน่วยความจำที่มีอยู่ทั้งหมดได้รับการจัดสรรให้กับ OPS อย่างเต็มที่ซึ่งต้องการเพียงเศษเสี้ยวของหน่วยความจำ สิ่งนี้จะช่วยให้กระบวนการอื่น ๆ ที่ใช้หน่วยความจำ GPU ทำงานบนอุปกรณ์เดียวกัน
หากต้องการเรียนรู้เพิ่มเติมลองดูคำแนะนำ การเติบโตของหน่วยความจำ GPU ที่ จำกัด ในคู่มือ GPU เพื่อเรียนรู้เพิ่มเติม
เบ็ดเตล็ด
เพิ่มขนาดมินิแบทช์การฝึกอบรม (จำนวนตัวอย่างการฝึกอบรมที่ใช้ต่ออุปกรณ์ในการวนซ้ำครั้งเดียวของลูปการฝึกอบรม) เป็นจำนวนสูงสุดที่เหมาะกับข้อผิดพลาดโดยไม่มีข้อผิดพลาดจากหน่วยความจำ (OOM) บน GPU การเพิ่มขนาดแบทช์ส่งผลกระทบต่อความแม่นยำของโมเดล - ดังนั้นให้แน่ใจว่าคุณปรับขนาดโมเดลโดยการปรับพารามิเตอร์ไฮเปอร์พารามิเตอร์เพื่อให้ตรงกับความแม่นยำของเป้าหมาย
ปิดใช้งานการรายงานข้อผิดพลาด OOM ระหว่างการจัดสรรเทนเซอร์ในรหัสการผลิต ตั้ง
report_tensor_allocations_upon_oom=Falseในtf.compat.v1.RunOptionsสำหรับแบบจำลองที่มีเลเยอร์ convolution ให้ลบการเพิ่มอคติหากใช้การทำให้เป็นมาตรฐานเป็นชุด การทำให้เป็นมาตรฐานเป็นชุดเปลี่ยนค่าโดยค่าเฉลี่ยของพวกเขาและสิ่งนี้จะช่วยขจัดความจำเป็นในการมีคำอคติคงที่
ใช้สถิติ TF เพื่อค้นหาว่า OPS บนอุปกรณ์ทำงานได้อย่างมีประสิทธิภาพ
ใช้
tf.functionเพื่อทำการคำนวณและเป็นทางเลือกเปิดใช้งานjit_compile=True(tf.function(jit_compile=True) หากต้องการเรียนรู้เพิ่มเติมให้ ใช้ xla tf.functionลดการดำเนินการของ Host Python ระหว่างขั้นตอนและลดการโทรกลับ คำนวณตัวชี้วัดทุกขั้นตอนแทนที่จะเป็นทุกขั้นตอน
ทำให้อุปกรณ์คำนวณอุปกรณ์ไม่ว่าง
ส่งข้อมูลไปยังอุปกรณ์หลายเครื่องในแบบขนาน
พิจารณา ใช้การเป็นตัวแทนเชิงตัวเลข 16 บิต เช่น
fp16รูปแบบจุดลอยตัวแบบครึ่งความแม่นยำที่ระบุโดย IEEE-หรือรูปแบบ Bloat-Point Bfloat16
แหล่งข้อมูลเพิ่มเติม
- TensorFlow Profiler: Profile Model Performance Tutorial กับ Keras และ Tensorboard ซึ่งคุณสามารถใช้คำแนะนำในคู่มือนี้ได้
- การทำโปรไฟล์ประสิทธิภาพใน TensorFlow 2 พูดคุยจาก Tensorflow Dev Summit 2020
- การสาธิต Tensorflow Profiler จาก Tensorflow Dev Summit 2020
ข้อ จำกัด ที่รู้จัก
การทำโปรไฟล์ GPU หลายตัวบน TensorFlow 2.2 และ TensorFlow 2.3
TensorFlow 2.2 และ 2.3 รองรับการทำโปรไฟล์ GPU หลายตัวสำหรับระบบโฮสต์เดียวเท่านั้น ไม่รองรับการทำโปรไฟล์ GPU หลายรายการสำหรับระบบหลายโฮสต์ ในการกำหนดค่าการกำหนดค่า GPU ของคนงานหลายคนคนงานแต่ละคนจะต้องทำโปรไฟล์อย่างอิสระ จาก Tensorflow 2.4 คนงานหลายคนสามารถทำโปรไฟล์ได้โดยใช้ tf.profiler.experimental.client.trace API
CUDA® Toolkit 10.2 หรือใหม่กว่านั้นจำเป็นต้องมีโปรไฟล์ GPU หลายตัว ในฐานะที่เป็น TensorFlow 2.2 และ 2.3 รองรับCUDA® Toolkit เวอร์ชันสูงถึง 10.1 คุณต้องสร้างลิงก์สัญลักษณ์ไปยัง libcudart.so.10.1 และ libcupti.so.10.1 :
sudo ln -s /usr/local/cuda/lib64/libcudart.so.10.2 /usr/local/cuda/lib64/libcudart.so.10.1
sudo ln -s /usr/local/cuda/extras/CUPTI/lib64/libcupti.so.10.2 /usr/local/cuda/extras/CUPTI/lib64/libcupti.so.10.1