
| | |  در GitHub مشاهده کنید در GitHub مشاهده کنید | |
هنگام کار با تانسورهایی که حاوی مقادیر زیادی صفر هستند، مهم است که آنها را به روشی کارآمد از نظر مکان و زمان ذخیره کنید. تانسورهای پراکنده ذخیره و پردازش کارآمد تانسورهایی را که حاوی مقادیر زیادی صفر هستند را امکان پذیر می کند. تانسورهای پراکنده به طور گسترده در طرح های رمزگذاری مانند TF-IDF به عنوان بخشی از پیش پردازش داده در برنامه های کاربردی NLP و برای پیش پردازش تصاویر با تعداد زیادی پیکسل تیره در برنامه های بینایی کامپیوتر استفاده می شود.
تانسورهای پراکنده در TensorFlow
TensorFlow تانسورهای پراکنده را از طریق شی tf.SparseTensor می دهد. در حال حاضر، تانسورهای پراکنده در TensorFlow با استفاده از فرمت فهرست مختصات (COO) کدگذاری میشوند. این قالب کدگذاری برای ماتریس های بسیار پراکنده مانند جاسازی ها بهینه شده است.
کدگذاری COO برای تانسورهای پراکنده شامل موارد زیر است:
-
values: یک تانسور 1 بعدی با شکل[N]که حاوی همه مقادیر غیر صفر است. -
indicesها: یک تانسور دوبعدی با شکل[N, rank]، حاوی شاخص های مقادیر غیر صفر. -
dense_shape: یک تانسور 1 بعدی با شکل[rank]که شکل تانسور را مشخص می کند.
یک مقدار غیر صفر در زمینه یک tf.SparseTensor مقداری است که به صراحت کدگذاری نشده است. ممکن است به طور صریح مقادیر صفر را در values یک ماتریس پراکنده COO لحاظ کرد، اما این "صفرهای صریح" معمولاً هنگام ارجاع به مقادیر غیرصفر در یک تانسور پراکنده شامل نمی شوند.
ایجاد tf.SparseTensor
تانسورهای پراکنده را با مشخص کردن مستقیم values ، indices و dense_shape .
import tensorflow as tf
st1 = tf.SparseTensor(indices=[[0, 3], [2, 4]],
values=[10, 20],
dense_shape=[3, 10])
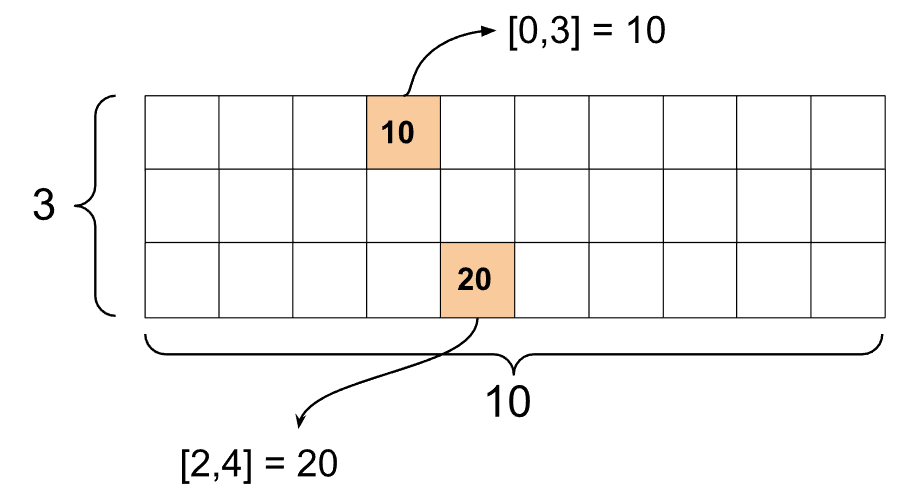
هنگامی که از تابع print() برای چاپ یک تانسور پراکنده استفاده می کنید، محتویات سه تانسور جزء را نشان می دهد:
print(st1)
SparseTensor(indices=tf.Tensor( [[0 3] [2 4]], shape=(2, 2), dtype=int64), values=tf.Tensor([10 20], shape=(2,), dtype=int32), dense_shape=tf.Tensor([ 3 10], shape=(2,), dtype=int64))
درک محتویات یک تانسور پراکنده آسانتر است اگر values غیرصفر با indices مربوطه خود تراز باشند. یک تابع کمکی برای چاپ تانسورهای پراکنده زیبا تعریف کنید به طوری که هر مقدار غیر صفر در خط خودش نشان داده شود.
def pprint_sparse_tensor(st):
s = "<SparseTensor shape=%s \n values={" % (st.dense_shape.numpy().tolist(),)
for (index, value) in zip(st.indices, st.values):
s += f"\n %s: %s" % (index.numpy().tolist(), value.numpy().tolist())
return s + "}>"
print(pprint_sparse_tensor(st1))
<SparseTensor shape=[3, 10]
values={
[0, 3]: 10
[2, 4]: 20}>
همچنین می توانید با استفاده از tf.sparse.from_dense تانسورهای پراکنده را از تانسورهای متراکم بسازید و با استفاده از tf.sparse.from_dense آنها را به تانسورهای متراکم tf.sparse.to_dense کنید.
st2 = tf.sparse.from_dense([[1, 0, 0, 8], [0, 0, 0, 0], [0, 0, 3, 0]])
print(pprint_sparse_tensor(st2))
<SparseTensor shape=[3, 4]
values={
[0, 0]: 1
[0, 3]: 8
[2, 2]: 3}>
st3 = tf.sparse.to_dense(st2)
print(st3)
tf.Tensor( [[1 0 0 8] [0 0 0 0] [0 0 3 0]], shape=(3, 4), dtype=int32)
دستکاری تانسورهای پراکنده
از ابزارهای کاربردی موجود در بسته tf.sparse برای دستکاری تانسورهای پراکنده استفاده کنید. عملیات هایی مانند tf.math.add که می توانید برای دستکاری حسابی تانسورهای متراکم استفاده کنید، با تانسورهای پراکنده کار نمی کنند.
با استفاده از tf.sparse.add تانسورهای پراکنده هم شکل را اضافه کنید.
st_a = tf.SparseTensor(indices=[[0, 2], [3, 4]],
values=[31, 2],
dense_shape=[4, 10])
st_b = tf.SparseTensor(indices=[[0, 2], [7, 0]],
values=[56, 38],
dense_shape=[4, 10])
st_sum = tf.sparse.add(st_a, st_b)
print(pprint_sparse_tensor(st_sum))
<SparseTensor shape=[4, 10]
values={
[0, 2]: 87
[3, 4]: 2
[7, 0]: 38}>
از tf.sparse.sparse_dense_matmul برای ضرب تانسورهای پراکنده با ماتریس های متراکم استفاده کنید.
st_c = tf.SparseTensor(indices=([0, 1], [1, 0], [1, 1]),
values=[13, 15, 17],
dense_shape=(2,2))
mb = tf.constant([[4], [6]])
product = tf.sparse.sparse_dense_matmul(st_c, mb)
print(product)
tf.Tensor( [[ 78] [162]], shape=(2, 1), dtype=int32)
تانسورهای پراکنده را با استفاده از tf.sparse.concat کنار هم قرار دهید و با استفاده از tf.sparse.slice آنها را از هم جدا کنید.
sparse_pattern_A = tf.SparseTensor(indices = [[2,4], [3,3], [3,4], [4,3], [4,4], [5,4]],
values = [1,1,1,1,1,1],
dense_shape = [8,5])
sparse_pattern_B = tf.SparseTensor(indices = [[0,2], [1,1], [1,3], [2,0], [2,4], [2,5], [3,5],
[4,5], [5,0], [5,4], [5,5], [6,1], [6,3], [7,2]],
values = [1,1,1,1,1,1,1,1,1,1,1,1,1,1],
dense_shape = [8,6])
sparse_pattern_C = tf.SparseTensor(indices = [[3,0], [4,0]],
values = [1,1],
dense_shape = [8,6])
sparse_patterns_list = [sparse_pattern_A, sparse_pattern_B, sparse_pattern_C]
sparse_pattern = tf.sparse.concat(axis=1, sp_inputs=sparse_patterns_list)
print(tf.sparse.to_dense(sparse_pattern))
tf.Tensor( [[0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0] [0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 0] [0 0 0 0 1 1 0 0 0 1 1 0 0 0 0 0 0] [0 0 0 1 1 0 0 0 0 0 1 1 0 0 0 0 0] [0 0 0 1 1 0 0 0 0 0 1 1 0 0 0 0 0] [0 0 0 0 1 1 0 0 0 1 1 0 0 0 0 0 0] [0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 0] [0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0]], shape=(8, 17), dtype=int32)
sparse_slice_A = tf.sparse.slice(sparse_pattern_A, start = [0,0], size = [8,5])
sparse_slice_B = tf.sparse.slice(sparse_pattern_B, start = [0,5], size = [8,6])
sparse_slice_C = tf.sparse.slice(sparse_pattern_C, start = [0,10], size = [8,6])
print(tf.sparse.to_dense(sparse_slice_A))
print(tf.sparse.to_dense(sparse_slice_B))
print(tf.sparse.to_dense(sparse_slice_C))
tf.Tensor( [[0 0 0 0 0] [0 0 0 0 0] [0 0 0 0 1] [0 0 0 1 1] [0 0 0 1 1] [0 0 0 0 1] [0 0 0 0 0] [0 0 0 0 0]], shape=(8, 5), dtype=int32) tf.Tensor( [[0] [0] [1] [1] [1] [1] [0] [0]], shape=(8, 1), dtype=int32) tf.Tensor([], shape=(8, 0), dtype=int32)
اگر از TensorFlow 2.4 یا بالاتر استفاده می کنید، از tf.sparse.map_values برای عملیات عنصری روی مقادیر غیر صفر در تانسورهای پراکنده استفاده کنید.
st2_plus_5 = tf.sparse.map_values(tf.add, st2, 5)
print(tf.sparse.to_dense(st2_plus_5))
tf.Tensor( [[ 6 0 0 13] [ 0 0 0 0] [ 0 0 8 0]], shape=(3, 4), dtype=int32)
توجه داشته باشید که فقط مقادیر غیر صفر اصلاح شده اند - مقادیر صفر صفر می مانند.
به همین ترتیب، می توانید الگوی طراحی زیر را برای نسخه های قبلی TensorFlow دنبال کنید:
st2_plus_5 = tf.SparseTensor(
st2.indices,
st2.values + 5,
st2.dense_shape)
print(tf.sparse.to_dense(st2_plus_5))
tf.Tensor( [[ 6 0 0 13] [ 0 0 0 0] [ 0 0 8 0]], shape=(3, 4), dtype=int32)
استفاده از tf.SparseTensor با سایر API های TensorFlow
تانسورهای Sparse با این API های TensorFlow به طور شفاف کار می کنند:
-
tf.keras -
tf.data -
tf.Train.Example -
tf.function -
tf.while_loop -
tf.cond -
tf.identity -
tf.cast -
tf.print -
tf.saved_model -
tf.io.serialize_sparse -
tf.io.serialize_many_sparse -
tf.io.deserialize_many_sparse -
tf.math.abs -
tf.math.negative -
tf.math.sign -
tf.math.square -
tf.math.sqrt -
tf.math.erf -
tf.math.tanh -
tf.math.bessel_i0e -
tf.math.bessel_i1e
نمونه هایی در زیر برای تعدادی از API های بالا نشان داده شده است.
tf.keras
زیر مجموعه ای از tf.keras API از تانسورهای پراکنده بدون عملیات ریخته گری یا تبدیل گران قیمت پشتیبانی می کند. Keras API به شما امکان می دهد تانسورهای پراکنده را به عنوان ورودی به مدل Keras ارسال کنید. هنگام فراخوانی tf.keras.Input یا tf.keras.layers.InputLayer sparse=True را تنظیم کنید. میتوانید تانسورهای پراکنده را بین لایههای Keras ارسال کنید و همچنین از مدلهای Keras آنها را به عنوان خروجی برگردانید. اگر از تانسورهای پراکنده در لایههای tf.keras.layers.Dense در مدل خود استفاده کنید، آنها تانسورهای متراکم را تولید میکنند.
مثال زیر به شما نشان میدهد که اگر فقط از لایههایی استفاده میکنید که ورودیهای پراکنده را پشتیبانی میکنند، چگونه یک تانسور پراکنده را به عنوان ورودی به مدل Keras ارسال کنید.
x = tf.keras.Input(shape=(4,), sparse=True)
y = tf.keras.layers.Dense(4)(x)
model = tf.keras.Model(x, y)
sparse_data = tf.SparseTensor(
indices = [(0,0),(0,1),(0,2),
(4,3),(5,0),(5,1)],
values = [1,1,1,1,1,1],
dense_shape = (6,4)
)
model(sparse_data)
model.predict(sparse_data)
array([[-1.3111044 , -1.7598825 , 0.07225233, -0.44544357],
[ 0. , 0. , 0. , 0. ],
[ 0. , 0. , 0. , 0. ],
[ 0. , 0. , 0. , 0. ],
[ 0.8517609 , -0.16835624, 0.7307872 , -0.14531797],
[-0.8916302 , -0.9417639 , 0.24563438, -0.9029659 ]],
dtype=float32)
tf.data
tf.data API شما را قادر می سازد خطوط لوله ورودی پیچیده ای را از قطعات ساده و قابل استفاده مجدد بسازید. ساختار داده اصلی آن tf.data.Dataset است که نشان دهنده دنباله ای از عناصر است که در آن هر عنصر از یک یا چند جزء تشکیل شده است.
ساخت مجموعه داده با تانسورهای پراکنده
با استفاده از همان روشهایی که برای ساخت آنها از tf.Tensor s یا NumPy، مانند tf.data.Dataset.from_tensor_slices ، مجموعه دادهها را از تانسورهای پراکنده بسازید. این عملیات پراکندگی (یا ماهیت پراکنده) داده ها را حفظ می کند.
dataset = tf.data.Dataset.from_tensor_slices(sparse_data)
for element in dataset:
print(pprint_sparse_tensor(element))
<SparseTensor shape=[4]
values={
[0]: 1
[1]: 1
[2]: 1}>
<SparseTensor shape=[4]
values={}>
<SparseTensor shape=[4]
values={}>
<SparseTensor shape=[4]
values={}>
<SparseTensor shape=[4]
values={
[3]: 1}>
<SparseTensor shape=[4]
values={
[0]: 1
[1]: 1}>
دستهبندی و جداسازی مجموعههای داده با تانسورهای پراکنده
میتوانید به ترتیب با استفاده از روشهای Dataset.batch و Dataset.unbatch ، مجموعههای داده را با تانسورهای پراکنده دستهای (ترکیب عناصر متوالی در یک عنصر واحد) و جداسازی دستهای انجام دهید.
batched_dataset = dataset.batch(2)
for element in batched_dataset:
print (pprint_sparse_tensor(element))
<SparseTensor shape=[2, 4]
values={
[0, 0]: 1
[0, 1]: 1
[0, 2]: 1}>
<SparseTensor shape=[2, 4]
values={}>
<SparseTensor shape=[2, 4]
values={
[0, 3]: 1
[1, 0]: 1
[1, 1]: 1}>
unbatched_dataset = batched_dataset.unbatch()
for element in unbatched_dataset:
print (pprint_sparse_tensor(element))
<SparseTensor shape=[4]
values={
[0]: 1
[1]: 1
[2]: 1}>
<SparseTensor shape=[4]
values={}>
<SparseTensor shape=[4]
values={}>
<SparseTensor shape=[4]
values={}>
<SparseTensor shape=[4]
values={
[3]: 1}>
<SparseTensor shape=[4]
values={
[0]: 1
[1]: 1}>
همچنین می توانید از tf.data.experimental.dense_to_sparse_batch برای دسته بندی عناصر مجموعه داده با اشکال مختلف به تانسورهای پراکنده استفاده کنید.
تبدیل مجموعه داده ها با تانسورهای پراکنده
با استفاده از Dataset.map تانسورهای پراکنده را در Datasets تغییر دهید و ایجاد کنید.
transform_dataset = dataset.map(lambda x: x*2)
for i in transform_dataset:
print(pprint_sparse_tensor(i))
<SparseTensor shape=[4]
values={
[0]: 2
[1]: 2
[2]: 2}>
<SparseTensor shape=[4]
values={}>
<SparseTensor shape=[4]
values={}>
<SparseTensor shape=[4]
values={}>
<SparseTensor shape=[4]
values={
[3]: 2}>
<SparseTensor shape=[4]
values={
[0]: 2
[1]: 2}>
tf.train.Example
tf.train.Example یک پروتوباف استاندارد برای داده های TensorFlow است. هنگام استفاده از تانسورهای پراکنده با tf.train.Example ، می توانید:
دادههای طول متغیر را با استفاده از
tf.SparseTensorدرtf.io.VarLenFeature. با این حال، باید به جای آن ازtf.io.RaggedFeatureاستفاده کنید.دادههای پراکنده دلخواه را در
tf.SparseTensorبا استفاده ازtf.io.SparseFeatureکه از سه کلید ویژگی جداگانه برای ذخیرهindices،valuesوdense_shapeاستفاده میکند.
tf.function
دکوراتور tf.function نمودارهای TensorFlow را برای توابع پایتون از قبل محاسبه می کند، که می تواند عملکرد کد TensorFlow شما را به طور قابل ملاحظه ای بهبود بخشد. تانسورهای پراکنده با tf.function و بتن شفاف کار می کنند.
@tf.function
def f(x,y):
return tf.sparse.sparse_dense_matmul(x,y)
a = tf.SparseTensor(indices=[[0, 3], [2, 4]],
values=[15, 25],
dense_shape=[3, 10])
b = tf.sparse.to_dense(tf.sparse.transpose(a))
c = f(a,b)
print(c)
tf.Tensor( [[225 0 0] [ 0 0 0] [ 0 0 625]], shape=(3, 3), dtype=int32)
تشخیص مقادیر گمشده از مقادیر صفر
اکثر عملیاتهای موجود در tf.SparseTensor مقادیر از دست رفته و مقادیر صریح صفر را یکسان رفتار میکنند. این بر اساس طراحی است - یک tf.SparseTensor قرار است درست مانند یک تانسور متراکم عمل کند.
با این حال، چند مورد وجود دارد که تشخیص مقادیر صفر از مقادیر گمشده می تواند مفید باشد. به طور خاص، این امکان را برای یک راه برای رمزگذاری داده های گمشده/ناشناخته در داده های آموزشی شما فراهم می کند. به عنوان مثال، یک مورد استفاده را در نظر بگیرید که در آن شما یک تانسور از امتیازها (که می تواند هر مقدار ممیز شناور از -Inf تا +Inf داشته باشد)، با تعدادی امتیاز از دست رفته را در نظر بگیرید. شما می توانید این تانسور را با استفاده از یک تانسور پراکنده رمزگذاری کنید که در آن صفرهای صریح به عنوان صفر شناخته می شوند اما مقادیر صفر ضمنی در واقع نشان دهنده داده های از دست رفته هستند و نه صفر.
توجه داشته باشید که برخی از عملیاتها مانند tf.sparse.reduce_max با مقادیر از دست رفته مانند صفر برخورد نمیکنند. به عنوان مثال، وقتی بلوک کد زیر را اجرا می کنید، خروجی مورد انتظار 0 است. با این حال، به دلیل این استثنا، خروجی -3 است.
print(tf.sparse.reduce_max(tf.sparse.from_dense([-5, 0, -3])))
tf.Tensor(-3, shape=(), dtype=int32)
در مقابل، وقتی tf.math.reduce_max را روی یک تانسور متراکم اعمال میکنید، خروجی مطابق انتظار 0 است.
print(tf.math.reduce_max([-5, 0, -3]))
tf.Tensor(0, shape=(), dtype=int32)
مطالعه بیشتر و منابع
- برای آشنایی با تانسورها به راهنمای تانسور مراجعه کنید.
- راهنمای تانسور ناهموار را بخوانید تا نحوه کار با تانسورهای ناهموار را بیاموزید، نوعی تانسور که به شما امکان می دهد با داده های غیریکنواخت کار کنید.
- این مدل تشخیص شی را در باغ مدل
tf.Exampleبررسی کنید که از تانسورهای پراکنده در رمزگشای داده tf استفاده می کند .