
רכיב TFX Pipeline של ExampleGen קולט נתונים לתוך צינורות TFX. הוא צורך קבצים/שירותים חיצוניים כדי ליצור דוגמאות שייקראו על ידי רכיבי TFX אחרים. זה גם מספק מחיצה עקבית וניתנת להגדרה, ומערבב את מערך הנתונים עבור שיטות עבודה מומלצות של ML.
- צורך: נתונים ממקורות נתונים חיצוניים כגון CSV,
TFRecord, Avro, Parquet ו-BigQuery. - פולטות: רשומות
tf.Example, רשומותtf.SequenceExample, או פורמט פרוטו, בהתאם לפורמט המטען.
ExampleGen ורכיבים אחרים
ExampleGen מספק נתונים לרכיבים שעושים שימוש בספריית TensorFlow Data Validation , כגון SchemaGen , StatisticsGen ו- Example Validator . הוא גם מספק נתונים ל- Transform , שעושה שימוש בספריית TensorFlow Transform , ובסופו של דבר למטרות פריסה במהלך הסקת מסקנות.
מקורות נתונים ופורמטים
נכון לעכשיו, התקנה סטנדרטית של TFX כוללת רכיבים מלאים של ExampleGen עבור מקורות הנתונים והפורמטים האלה:
מבצעים מותאמים אישית זמינים גם המאפשרים פיתוח של רכיבי ExampleGen עבור מקורות נתונים ופורמטים אלה:
עיין בדוגמאות השימוש בקוד המקור ובדיון זה למידע נוסף על אופן השימוש והפיתוח של מבצעים מותאמים אישית.
בנוסף, מקורות הנתונים והפורמטים האלה זמינים כדוגמאות לרכיבים מותאמים אישית :
הטמעת פורמטים של נתונים הנתמכים על ידי Apache Beam
Apache Beam תומך בהטמעת נתונים ממגוון רחב של מקורות נתונים ופורמטים , ( ראה להלן ). ניתן להשתמש ביכולות אלו ליצירת רכיבי ExampleGen מותאמים אישית עבור TFX, אשר מודגמים על ידי כמה רכיבים קיימים של ExampleGen ( ראה להלן ).
כיצד להשתמש ברכיב ExampleGen
עבור מקורות נתונים נתמכים (כרגע, קבצי CSV, קבצי TFRecord עם tf.Example , tf.SequenceExample ופורמט פרוטו, ותוצאות של שאילתות BigQuery) ניתן להשתמש ברכיב הצינור של ExampleGen ישירות בפריסה ודורש מעט התאמה אישית. לְדוּגמָה:
example_gen = CsvExampleGen(input_base='data_root')
או כמו למטה לייבוא TFRecord חיצוני עם tf.Example ישירות:
example_gen = ImportExampleGen(input_base=path_to_tfrecord_dir)
טווח, גרסה ופיצול
טווח הוא קיבוץ של דוגמאות אימון. אם הנתונים שלך נשמרים במערכת קבצים, כל Span עשוי להיות מאוחסן בספרייה נפרדת. הסמנטיקה של Span אינה מקודדת ב-TFX; טווח עשוי להתאים ליום של נתונים, לשעה של נתונים או כל קיבוץ אחר בעל משמעות למשימה שלך.
כל טווח יכול להכיל גרסאות מרובות של נתונים. כדי לתת דוגמה, אם תסיר כמה דוגמאות מטווח כדי לנקות נתונים באיכות ירודה, הדבר עלול לגרום לגרסה חדשה של טווח זה. כברירת מחדל, רכיבי TFX פועלים על הגרסה העדכנית ביותר בתוך טווח.
ניתן לחלק כל גרסה בתוך טווח נוסף למספר פיצולים. מקרה השימוש הנפוץ ביותר לפיצול Span הוא לפצל אותו לנתוני אימון והערכה.
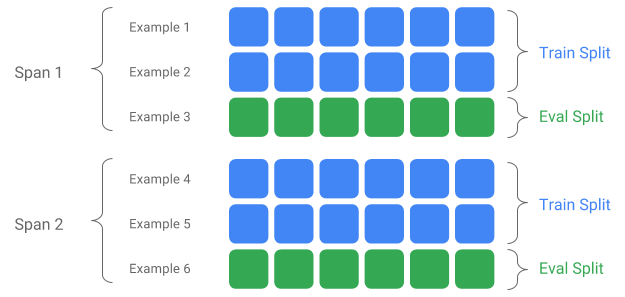
פיצול קלט/פלט מותאם אישית
כדי להתאים אישית את יחס הפיצול של רכבת/eval ש-ExampleGen יפיק פלט, הגדר את output_config עבור רכיב ExampleGen. לְדוּגמָה:
# Input has a single split 'input_dir/*'.
# Output 2 splits: train:eval=3:1.
output = proto.Output(
split_config=example_gen_pb2.SplitConfig(splits=[
proto.SplitConfig.Split(name='train', hash_buckets=3),
proto.SplitConfig.Split(name='eval', hash_buckets=1)
]))
example_gen = CsvExampleGen(input_base=input_dir, output_config=output)
שימו לב כיצד הוגדרו ה- hash_buckets בדוגמה זו.
עבור מקור קלט שכבר פוצל, הגדר את input_config עבור רכיב ExampleGen:
# Input train split is 'input_dir/train/*', eval split is 'input_dir/eval/*'.
# Output splits are generated one-to-one mapping from input splits.
input = proto.Input(splits=[
example_gen_pb2.Input.Split(name='train', pattern='train/*'),
example_gen_pb2.Input.Split(name='eval', pattern='eval/*')
])
example_gen = CsvExampleGen(input_base=input_dir, input_config=input)
עבור gen לדוגמה מבוסס קבצים (למשל CsvExampleGen ו- ImportExampleGen), pattern הוא דפוס קובץ יחסי גלוב שממפה לקבצי קלט עם ספריית שורש הניתנת על ידי נתיב בסיס קלט. עבור gen לדוגמה מבוסס שאילתה (למשל BigQueryExampleGen, PrestoExampleGen), pattern היא שאילתת SQL.
כברירת מחדל, כל ה-dir בסיס הקלט מטופל כפיצול קלט בודד, וחלוקת הפלט של הרכבת וה-eval נוצר ביחס של 2:1.
אנא עיין ב- proto/example_gen.proto עבור תצורת פיצול הקלט והפלט של ExampleGen. ועיין במדריך הרכיבים במורד הזרם לשימוש בפיצולים המותאמים אישית במורד הזרם.
שיטת פיצול
כאשר משתמשים בשיטת פיצול hash_buckets , במקום הרשומה כולה, אפשר להשתמש בתכונה לחלוקת הדוגמאות. אם קיימת תכונה, ExampleGen ישתמש בטביעת אצבע של אותה תכונה כמפתח המחיצה.
ניתן להשתמש בתכונה זו כדי לשמור על פיצול יציב עם מאפיינים מסוימים של דוגמאות: לדוגמה, משתמש תמיד יוכנס לאותו פיצול אם "user_id" נבחר כשם תכונת המחיצה.
הפרשנות של המשמעות של "תכונה" וכיצד להתאים "תכונה" עם השם שצוין תלויה ביישום ExampleGen ובסוג הדוגמאות.
להטמעות מוכנות של ExampleGen:
- אם הוא יוצר tf.Example, אז "פיצ'ר" פירושו ערך ב-tf.Example.features.feature.
- אם הוא יוצר tf.SequenceExample, אז "פיצ'ר" פירושו ערך ב-tf.SequenceExample.context.feature.
- רק תכונות int64 ו-bytes נתמכות.
במקרים הבאים, ExampleGen זורק שגיאות זמן ריצה:
- שם התכונה שצוין לא קיים בדוגמה.
- תכונה ריקה:
tf.train.Feature(). - סוגי תכונות לא נתמכים, למשל, תכונות צפות.
כדי להוציא את פיצול הרכבת/השוואה על סמך תכונה בדוגמאות, הגדר את output_config עבור רכיב ExampleGen. לְדוּגמָה:
# Input has a single split 'input_dir/*'.
# Output 2 splits based on 'user_id' features: train:eval=3:1.
output = proto.Output(
split_config=proto.SplitConfig(splits=[
proto.SplitConfig.Split(name='train', hash_buckets=3),
proto.SplitConfig.Split(name='eval', hash_buckets=1)
],
partition_feature_name='user_id'))
example_gen = CsvExampleGen(input_base=input_dir, output_config=output)
שימו לב כיצד הוגדר partition_feature_name בדוגמה זו.
לְהַקִיף
ניתן לאחזר טווח על ידי שימוש במפרט '{SPAN}' בדפוס גלוב הקלט :
- מפרט זה תואם ספרות וממפה את הנתונים למספרי SPAN הרלוונטיים. לדוגמה, 'data_{SPAN}-*.tfrecord' יאסוף קבצים כמו 'data_12-a.tfrecord', 'data_12-b.tfrecord'.
- לחלופין, ניתן לציין מפרט זה עם רוחב המספרים השלמים בעת מיפוי. לדוגמה, 'data_{SPAN:2}.file' ממפה לקבצים כמו 'data_02.file' ו-'data_27.file' (כקלט עבור Span-2 ו-Span-27 בהתאמה), אך אינו ממפה ל-'data_1. file' ולא 'data_123.file'.
- כאשר מפרט SPAN חסר, ההנחה היא שהוא תמיד טווח '0'.
- אם צוין SPAN, pipeline יעבד את הטווח האחרון, ויאחסן את מספר הטווח במטא נתונים.
לדוגמה, נניח שיש נתוני קלט:
- '/tmp/span-1/train/data'
- '/tmp/span-1/eval/data'
- '/tmp/span-2/train/data'
- '/tmp/span-2/eval/data'
ותצורת הקלט מוצגת כדלקמן:
splits {
name: 'train'
pattern: 'span-{SPAN}/train/*'
}
splits {
name: 'eval'
pattern: 'span-{SPAN}/eval/*'
}
בעת הפעלת הצינור, הוא יעבד:
- '/tmp/span-2/train/data' כפיצול רכבת
- '/tmp/span-2/eval/data' כפיצול eval
עם מספר טווח כמו '2'. אם מאוחר יותר '/tmp/span-3/...' מוכנים, פשוט הפעל את הצינור שוב והוא יקלוט את טווח '3' לעיבוד. להלן דוגמה לקוד לשימוש במפרט span:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
אחזור טווח מסוים יכול להיעשות עם RangeConfig, אשר מפורט להלן.
תַאֲרִיך
אם מקור הנתונים שלך מאורגן על מערכת הקבצים לפי תאריך, TFX תומך במיפוי תאריכים ישירות למספרים. ישנם שלושה מפרטים המייצגים מיפוי מתאריכים לטווחים: {YYYY}, {MM} ו-{DD}:
- שלושת המפרטים צריכים להיות נוכחים לחלוטין בדפוס גלוב הקלט אם צוין כזה:
- ניתן לציין באופן בלעדי מפרט {SPAN} או סט זה של מפרט תאריכים.
- מחושב תאריך לוח שנה עם השנה מ-YYYY, החודש מ-MM ויום החודש מ-DD, ואז מספר הטווח מחושב כמספר הימים מאז עידן יוניקס (כלומר 1970-01-01). לדוגמה, 'log-{YYYY}{MM}{DD}.data' תואם לקובץ 'log-19700101.data' וצורך אותו כקלט עבור Span-0, ו-'log-20170101.data' כקלט עבור ספאן-17167.
- אם קבוצה זו של מפרט תאריכים צוין, צינור יעבד את התאריך האחרון האחרון, ויאחסן את מספר הטווח המתאים במטא נתונים.
לדוגמה, נניח שיש נתוני קלט המאורגנים לפי תאריך לוח שנה:
- '/tmp/1970-01-02/train/data'
- '/tmp/1970-01-02/eval/data'
- '/tmp/1970-01-03/train/data'
- '/tmp/1970-01-03/eval/data'
ותצורת הקלט מוצגת כדלקמן:
splits {
name: 'train'
pattern: '{YYYY}-{MM}-{DD}/train/*'
}
splits {
name: 'eval'
pattern: '{YYYY}-{MM}-{DD}/eval/*'
}
בעת הפעלת הצינור, הוא יעבד:
- '/tmp/1970-01-03/train/data' כפיצול רכבת
- '/tmp/1970-01-03/eval/data' כפיצול eval
עם מספר טווח כמו '2'. אם מאוחר יותר '/tmp/1970-01-04/...' מוכנים, פשוט הפעל את הצינור שוב והוא יקלוט את טווח '3' לעיבוד. להלן דוגמה לקוד לשימוש במפרט תאריך:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='{YYYY}-{MM}-{DD}/train/*'),
proto.Input.Split(name='eval',
pattern='{YYYY}-{MM}-{DD}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
גִרְסָה
ניתן לאחזר את הגרסה על ידי שימוש במפרט '{VERSION}' בדפוס גלוב הקלט :
- מפרט זה תואם ספרות וממפה את הנתונים למספרי VERSION הרלוונטיים תחת SPAN. שים לב שניתן להשתמש במפרט הגרסה בשילוב עם מפרט טווח או תאריך.
- ניתן גם לציין מפרט זה באופן אופציונלי עם הרוחב באותו אופן כמו מפרט SPAN. למשל 'span-{SPAN}/version-{VERSION:4}/data-*'.
- כאשר מפרט VERSION חסר, הגרסה מוגדרת להיות ללא.
- אם SPAN ו-VERSION צוינו שניהם, pipeline תעבד את הגרסה העדכנית ביותר עבור הטווח האחרון, ויאחסן את מספר הגרסה במטא נתונים.
- אם צוין VERSION, אך לא SPAN (או מפרט תאריך), תופיע שגיאה.
לדוגמה, נניח שיש נתוני קלט:
- '/tmp/span-1/ver-1/train/data'
- '/tmp/span-1/ver-1/eval/data'
- '/tmp/span-2/ver-1/train/data'
- '/tmp/span-2/ver-1/eval/data'
- '/tmp/span-2/ver-2/train/data'
- '/tmp/span-2/ver-2/eval/data'
ותצורת הקלט מוצגת כדלקמן:
splits {
name: 'train'
pattern: 'span-{SPAN}/ver-{VERSION}/train/*'
}
splits {
name: 'eval'
pattern: 'span-{SPAN}/ver-{VERSION}/eval/*'
}
בעת הפעלת הצינור, הוא יעבד:
- '/tmp/span-2/ver-2/train/data' כפיצול רכבת
- '/tmp/span-2/ver-2/eval/data' כפיצול eval
עם מספר טווח כ'2' ומספר גרסה כ'2'. אם מאוחר יותר '/tmp/span-2/ver-3/...' מוכנים, פשוט הפעל את הצינור שוב והוא יקלוט את טווח '2' וגרסה '3' לעיבוד. להלן דוגמה לקוד לשימוש במפרט הגרסה:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN}/ver-{VERSION}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN}/ver-{VERSION}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
תצורת טווח
TFX תומך באחזור ועיבוד של טווח ספציפי ב-ExampleGen מבוסס קבצים באמצעות תצורת טווח, תצורה מופשטת המשמשת לתיאור טווחים עבור ישויות TFX שונות. כדי לאחזר טווח ספציפי, הגדר את range_config עבור רכיב ExampleGen המבוסס על קבצים. לדוגמה, נניח שיש נתוני קלט:
- '/tmp/span-01/train/data'
- '/tmp/span-01/eval/data'
- '/tmp/span-02/train/data'
- '/tmp/span-02/eval/data'
כדי לאחזר ולעבד נתונים ספציפיים עם טווח '1', אנו מציינים תצורת טווח בנוסף לתצורת הקלט. שים לב ש-ExampleGen תומך רק בטווחים סטטיים של טווח יחיד (כדי לציין עיבוד של טווחים בודדים ספציפיים). לפיכך, עבור StaticRange, start_span_number חייב להיות end_span_number. באמצעות הטווח המסופק, ומידע על רוחב הטווח (אם מסופק) עבור ריפוד אפס, ExampleGen יחליף את מפרט ה-SPAN בתבניות המפוצלות שסופקו במספר הטווח הרצוי. דוגמה לשימוש מוצגת להלן:
# In cases where files have zero-padding, the width modifier in SPAN spec is
# required so TFX can correctly substitute spec with zero-padded span number.
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN:2}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN:2}/eval/*')
])
# Specify the span number to be processed here using StaticRange.
range = proto.RangeConfig(
static_range=proto.StaticRange(
start_span_number=1, end_span_number=1)
)
# After substitution, the train and eval split patterns will be
# 'input_dir/span-01/train/*' and 'input_dir/span-01/eval/*', respectively.
example_gen = CsvExampleGen(input_base=input_dir, input_config=input,
range_config=range)
ניתן להשתמש בתצורת טווח גם לעיבוד תאריכים ספציפיים, אם משתמשים במפרט התאריך במקום במפרט SPAN. לדוגמה, נניח שיש נתוני קלט המאורגנים לפי תאריך לוח שנה:
- '/tmp/1970-01-02/train/data'
- '/tmp/1970-01-02/eval/data'
- '/tmp/1970-01-03/train/data'
- '/tmp/1970-01-03/eval/data'
כדי לאחזר ולעבד נתונים ספציפיים ב-2 בינואר 1970, אנו עושים את הפעולות הבאות:
from tfx.components.example_gen import utils
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='{YYYY}-{MM}-{DD}/train/*'),
proto.Input.Split(name='eval',
pattern='{YYYY}-{MM}-{DD}/eval/*')
])
# Specify date to be converted to span number to be processed using StaticRange.
span = utils.date_to_span_number(1970, 1, 2)
range = proto.RangeConfig(
static_range=range_config_pb2.StaticRange(
start_span_number=span, end_span_number=span)
)
# After substitution, the train and eval split patterns will be
# 'input_dir/1970-01-02/train/*' and 'input_dir/1970-01-02/eval/*',
# respectively.
example_gen = CsvExampleGen(input_base=input_dir, input_config=input,
range_config=range)
דוגמה מותאמת אישיתGen
אם רכיבי ExampleGen הזמינים כעת אינם מתאימים לצרכים שלך, אתה יכול ליצור ExampleGen מותאם אישית, שיאפשר לך לקרוא ממקורות נתונים שונים או בפורמטים שונים של נתונים.
התאמה אישית מבוססת קבצים לדוגמה (ניסיוני)
ראשית, הרחב את BaseExampleGenExecutor עם Beam PTransform מותאם אישית, המספק את ההמרה מפיצול קלט הרכבת/eval שלך לדוגמאות TF. לדוגמה, ה- executor CsvExampleGen מספק את ההמרה מפיצול CSV קלט לדוגמאות TF.
לאחר מכן, צור רכיב עם ה-executor שלמעלה, כפי שנעשה ב- CsvExampleGen component . לחלופין, העבירו מבצע מותאם אישית לרכיב ה-ExampleGen הסטנדרטי כפי שמוצג להלן.
from tfx.components.base import executor_spec
from tfx.components.example_gen.csv_example_gen import executor
example_gen = FileBasedExampleGen(
input_base=os.path.join(base_dir, 'data/simple'),
custom_executor_spec=executor_spec.ExecutorClassSpec(executor.Executor))
כעת, אנו תומכים גם בקריאת קבצי Avro ופרקט בשיטה זו.
פורמטים נוספים של נתונים
Apache Beam תומך בקריאת מספר פורמטי נתונים נוספים . באמצעות טרנספורמציות קלט/פלט קרן. אתה יכול ליצור רכיבי ExampleGen מותאמים אישית על ידי מינוף ה-Beam I/O Transforms באמצעות תבנית דומה לדוגמא של Avro
return (pipeline
| 'ReadFromAvro' >> beam.io.ReadFromAvro(avro_pattern)
| 'ToTFExample' >> beam.Map(utils.dict_to_example))
נכון לכתיבת שורות אלה, הפורמטים ומקורות הנתונים הנתמכים כעת עבור Beam Python SDK כוללים:
- אמזון S3
- אפאצ'י אברו
- Apache Hadoop
- אפאצ'י קפקא
- פרקט אפאצ'י
- Google Cloud BigQuery
- Google Cloud BigTable
- Google Cloud Datastore
- Google Cloud Pub/Sub
- Google Cloud Storage (GCS)
- MongoDB
עיין במסמכי Beam לקבלת הרשימה העדכנית ביותר.
התאמה אישית מבוססת שאילתה (ניסוי)
ראשית, הרחב את BaseExampleGenExecutor עם Beam PTransform מותאם אישית, הקורא ממקור הנתונים החיצוני. לאחר מכן, צור רכיב פשוט על ידי הרחבת QueryBasedExampleGen.
זה עשוי לדרוש או לא לדרוש תצורות חיבור נוספות. לדוגמה, המבצע של BigQuery קורא באמצעות מחבר ברירת מחדל beam.io, אשר מופשט את פרטי תצורת החיבור. ה- Presto executor , דורש Beam PTransform מותאם אישית ופרוטובוף של תצורת חיבור מותאם אישית כקלט.
אם נדרשת תצורת חיבור עבור רכיב ExampleGen מותאם אישית, צור פרוטובוף חדש והעביר אותו דרך custom_config, שהוא כעת פרמטר הפעלה אופציונלי. להלן דוגמה כיצד להשתמש ברכיב מוגדר.
from tfx.examples.custom_components.presto_example_gen.proto import presto_config_pb2
from tfx.examples.custom_components.presto_example_gen.presto_component.component import PrestoExampleGen
presto_config = presto_config_pb2.PrestoConnConfig(host='localhost', port=8080)
example_gen = PrestoExampleGen(presto_config, query='SELECT * FROM chicago_taxi_trips')
רכיבי מורד זרם לדוגמה
תצורה מפוצלת מותאמת אישית נתמכת עבור רכיבים במורד הזרם.
סטטיסטיקה
התנהגות ברירת המחדל היא לבצע יצירת נתונים סטטיסטיים עבור כל הפיצולים.
כדי לא לכלול פיצולים כלשהם, הגדר את exclude_splits עבור רכיב StatisticsGen. לְדוּגמָה:
# Exclude the 'eval' split.
statistics_gen = StatisticsGen(
examples=example_gen.outputs['examples'],
exclude_splits=['eval'])
SchemaGen
התנהגות ברירת המחדל היא יצירת סכימה המבוססת על כל הפיצולים.
כדי לא לכלול פיצולים כלשהם, הגדר את exclude_splits עבור רכיב SchemaGen. לְדוּגמָה:
# Exclude the 'eval' split.
schema_gen = SchemaGen(
statistics=statistics_gen.outputs['statistics'],
exclude_splits=['eval'])
Validator לדוגמה
התנהגות ברירת המחדל היא לאמת את הסטטיסטיקה של כל הפיצולים על דוגמאות קלט מול סכימה.
כדי לא לכלול פיצולים כלשהם, הגדר את exclude_splits עבור רכיב ExampleValidator. לְדוּגמָה:
# Exclude the 'eval' split.
example_validator = ExampleValidator(
statistics=statistics_gen.outputs['statistics'],
schema=schema_gen.outputs['schema'],
exclude_splits=['eval'])
לְשַׁנוֹת
התנהגות ברירת המחדל היא לנתח ולהפיק את המטא נתונים מפיצול 'הרכבת' ולהמיר את כל הפיצולים.
כדי לציין את פיצולי הניתוח ואת פיצולי ההמרה, הגדר את splits_config עבור רכיב Transform. לְדוּגמָה:
# Analyze the 'train' split and transform all splits.
transform = Transform(
examples=example_gen.outputs['examples'],
schema=schema_gen.outputs['schema'],
module_file=_taxi_module_file,
splits_config=proto.SplitsConfig(analyze=['train'],
transform=['train', 'eval']))
מאמן וטיונר
התנהגות ברירת המחדל היא רכבת על פיצול 'רכבת' והערכת על פיצול 'eval'.
כדי לציין את פיצולי הרכבת ולהעריך פיצולים, הגדר את הרכיב train_args ו- eval_args עבור Trainer. לְדוּגמָה:
# Train on the 'train' split and evaluate on the 'eval' split.
Trainer = Trainer(
module_file=_taxi_module_file,
examples=transform.outputs['transformed_examples'],
schema=schema_gen.outputs['schema'],
transform_graph=transform.outputs['transform_graph'],
train_args=proto.TrainArgs(splits=['train'], num_steps=10000),
eval_args=proto.EvalArgs(splits=['eval'], num_steps=5000))
מעריך
התנהגות ברירת המחדל היא לספק מדדים המחושבים על פיצול 'השוואה'.
כדי לחשב סטטיסטיקות הערכה על פיצולים מותאמים אישית, הגדר את הרכיב example_splits עבור רכיב Evaluator. לְדוּגמָה:
# Compute metrics on the 'eval1' split and the 'eval2' split.
evaluator = Evaluator(
examples=example_gen.outputs['examples'],
model=trainer.outputs['model'],
example_splits=['eval1', 'eval2'])
פרטים נוספים זמינים בהפניה ל-CsvExampleGen API , ביישום FileBasedExampleGen API וב- ImportExampleGen API .