
| | |  Ver en GitHub Ver en GitHub | | |
YAMNet es una red neuronal profunda preentrenada que puede predecir eventos de audio de 521 clases , como risas, ladridos o sirenas.
En este tutorial aprenderá a:
- Cargue y use el modelo YAMNet para la inferencia.
- Cree un nuevo modelo utilizando las incrustaciones de YAMNet para clasificar los sonidos de perros y gatos.
- Evalúe y exporte su modelo.
Importar TensorFlow y otras bibliotecas
Comience instalando TensorFlow I/O , lo que le facilitará la carga de archivos de audio desde el disco.
pip install tensorflow_io
import os
from IPython import display
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_io as tfio
Acerca de YAMNet
YAMNet es una red neuronal preentrenada que emplea la arquitectura de convolución separable en profundidad MobileNetV1 . Puede usar una forma de onda de audio como entrada y hacer predicciones independientes para cada uno de los 521 eventos de audio del corpus AudioSet .
Internamente, el modelo extrae "cuadros" de la señal de audio y procesa lotes de estos cuadros. Esta versión del modelo utiliza fotogramas de 0,96 segundos de duración y extrae un fotograma cada 0,48 segundos.
El modelo acepta una matriz 1-D float32 Tensor o NumPy que contiene una forma de onda de longitud arbitraria, representada como muestras de un solo canal (mono) de 16 kHz en el rango [-1.0, +1.0] . Este tutorial contiene código para ayudarlo a convertir archivos WAV al formato compatible.
El modelo devuelve 3 salidas, incluidos los puntajes de clase, las incrustaciones (que usará para el aprendizaje de transferencia) y el espectrograma log mel. Puede encontrar más detalles aquí .
Un uso específico de YAMNet es como un extractor de funciones de alto nivel: la salida de incrustación de 1024 dimensiones. Utilizará las características de entrada del modelo base (YAMNet) y las introducirá en su modelo menos profundo que consta de una capa oculta tf.keras.layers.Dense . Luego, entrenará la red en una pequeña cantidad de datos para la clasificación de audio sin requerir una gran cantidad de datos etiquetados y entrenamiento de extremo a extremo. (Esto es similar a la transferencia de aprendizaje para la clasificación de imágenes con TensorFlow Hub para obtener más información).
Primero, probará el modelo y verá los resultados de clasificar el audio. A continuación, construirá la canalización de preprocesamiento de datos.
Cargando YAMNet desde TensorFlow Hub
Vas a usar una YAMNet preentrenada de Tensorflow Hub para extraer las incrustaciones de los archivos de sonido.
Cargar un modelo desde TensorFlow Hub es sencillo: elija el modelo, copie su URL y use la función de load .
yamnet_model_handle = 'https://tfhub.dev/google/yamnet/1'
yamnet_model = hub.load(yamnet_model_handle)
Con el modelo cargado, puede seguir el tutorial de uso básico de YAMNet y descargar un archivo WAV de muestra para ejecutar la inferencia.
testing_wav_file_name = tf.keras.utils.get_file('miaow_16k.wav',
'https://storage.googleapis.com/audioset/miaow_16k.wav',
cache_dir='./',
cache_subdir='test_data')
print(testing_wav_file_name)
Downloading data from https://storage.googleapis.com/audioset/miaow_16k.wav 221184/215546 [==============================] - 0s 0us/step 229376/215546 [===============================] - 0s 0us/step ./test_data/miaow_16k.wav
Necesitará una función para cargar archivos de audio, que también se usará más adelante cuando trabaje con los datos de entrenamiento. (Obtenga más información sobre la lectura de archivos de audio y sus etiquetas en Reconocimiento de audio simple .
# Utility functions for loading audio files and making sure the sample rate is correct.
@tf.function
def load_wav_16k_mono(filename):
""" Load a WAV file, convert it to a float tensor, resample to 16 kHz single-channel audio. """
file_contents = tf.io.read_file(filename)
wav, sample_rate = tf.audio.decode_wav(
file_contents,
desired_channels=1)
wav = tf.squeeze(wav, axis=-1)
sample_rate = tf.cast(sample_rate, dtype=tf.int64)
wav = tfio.audio.resample(wav, rate_in=sample_rate, rate_out=16000)
return wav
testing_wav_data = load_wav_16k_mono(testing_wav_file_name)
_ = plt.plot(testing_wav_data)
# Play the audio file.
display.Audio(testing_wav_data,rate=16000)
2022-01-26 08:07:19.084427: W tensorflow_io/core/kernels/audio_video_mp3_kernels.cc:271] libmp3lame.so.0 or lame functions are not available WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample

Cargue el mapeo de clases
Es importante cargar los nombres de clase que YAMNet puede reconocer. El archivo de mapeo está presente en yamnet_model.class_map_path() en formato CSV.
class_map_path = yamnet_model.class_map_path().numpy().decode('utf-8')
class_names =list(pd.read_csv(class_map_path)['display_name'])
for name in class_names[:20]:
print(name)
print('...')
Speech Child speech, kid speaking Conversation Narration, monologue Babbling Speech synthesizer Shout Bellow Whoop Yell Children shouting Screaming Whispering Laughter Baby laughter Giggle Snicker Belly laugh Chuckle, chortle Crying, sobbing ...
Ejecutar inferencia
YAMNet proporciona puntajes de clase a nivel de marco (es decir, 521 puntajes para cada marco). Para determinar las predicciones a nivel de clip, las puntuaciones se pueden agregar por clase a través de fotogramas (p. ej., utilizando la agregación media o máxima). Esto se hace a continuación mediante scores_np.mean(axis=0) . Finalmente, para encontrar la clase con la puntuación más alta a nivel de clip, se toma el máximo de las 521 puntuaciones agregadas.
scores, embeddings, spectrogram = yamnet_model(testing_wav_data)
class_scores = tf.reduce_mean(scores, axis=0)
top_class = tf.argmax(class_scores)
inferred_class = class_names[top_class]
print(f'The main sound is: {inferred_class}')
print(f'The embeddings shape: {embeddings.shape}')
The main sound is: Animal The embeddings shape: (13, 1024)
Conjunto de datos ESC-50
El conjunto de datos ESC-50 ( Piczak, 2015 ) es una colección etiquetada de 2000 grabaciones de audio ambientales de cinco segundos de duración. El conjunto de datos consta de 50 clases, con 40 ejemplos por clase.
Descargue el conjunto de datos y extráigalo.
_ = tf.keras.utils.get_file('esc-50.zip',
'https://github.com/karoldvl/ESC-50/archive/master.zip',
cache_dir='./',
cache_subdir='datasets',
extract=True)
Downloading data from https://github.com/karoldvl/ESC-50/archive/master.zip 645103616/Unknown - 47s 0us/step
Explora los datos
Los metadatos de cada archivo se especifican en el archivo csv en ./datasets/ESC-50-master/meta/esc50.csv
y todos los archivos de audio están en ./datasets/ESC-50-master/audio/
Creará un DataFrame de pandas con el mapeo y lo usará para tener una vista más clara de los datos.
esc50_csv = './datasets/ESC-50-master/meta/esc50.csv'
base_data_path = './datasets/ESC-50-master/audio/'
pd_data = pd.read_csv(esc50_csv)
pd_data.head()
Filtrar los datos
Ahora que los datos están almacenados en DataFrame , aplique algunas transformaciones:
- Filtre las filas y use solo las clases seleccionadas:
dogycat. Si desea utilizar otras clases, aquí es donde puede elegirlas. - Modifique el nombre del archivo para tener la ruta completa. Esto facilitará la carga más adelante.
- Cambie los objetivos para que estén dentro de un rango específico. En este ejemplo,
dogpermanecerá en0, perocatse convertirá en1en lugar de su valor original de5.
my_classes = ['dog', 'cat']
map_class_to_id = {'dog':0, 'cat':1}
filtered_pd = pd_data[pd_data.category.isin(my_classes)]
class_id = filtered_pd['category'].apply(lambda name: map_class_to_id[name])
filtered_pd = filtered_pd.assign(target=class_id)
full_path = filtered_pd['filename'].apply(lambda row: os.path.join(base_data_path, row))
filtered_pd = filtered_pd.assign(filename=full_path)
filtered_pd.head(10)
Cargue los archivos de audio y recupere incrustaciones
Aquí aplicará load_wav_16k_mono y preparará los datos WAV para el modelo.
Al extraer incrustaciones de los datos WAV, obtiene una matriz de forma (N, 1024) donde N es la cantidad de fotogramas que encontró YAMNet (uno por cada 0,48 segundos de audio).
Su modelo usará cada cuadro como una entrada. Por lo tanto, debe crear una nueva columna que tenga un marco por fila. También debe expandir las etiquetas y la columna de fold para reflejar correctamente estas nuevas filas.
La columna de fold expandida mantiene los valores originales. No puede mezclar cuadros porque, al realizar las divisiones, podría terminar teniendo partes del mismo audio en diferentes divisiones, lo que haría que sus pasos de validación y prueba fueran menos efectivos.
filenames = filtered_pd['filename']
targets = filtered_pd['target']
folds = filtered_pd['fold']
main_ds = tf.data.Dataset.from_tensor_slices((filenames, targets, folds))
main_ds.element_spec
(TensorSpec(shape=(), dtype=tf.string, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
def load_wav_for_map(filename, label, fold):
return load_wav_16k_mono(filename), label, fold
main_ds = main_ds.map(load_wav_for_map)
main_ds.element_spec
WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample (TensorSpec(shape=<unknown>, dtype=tf.float32, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
# applies the embedding extraction model to a wav data
def extract_embedding(wav_data, label, fold):
''' run YAMNet to extract embedding from the wav data '''
scores, embeddings, spectrogram = yamnet_model(wav_data)
num_embeddings = tf.shape(embeddings)[0]
return (embeddings,
tf.repeat(label, num_embeddings),
tf.repeat(fold, num_embeddings))
# extract embedding
main_ds = main_ds.map(extract_embedding).unbatch()
main_ds.element_spec
(TensorSpec(shape=(1024,), dtype=tf.float32, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
dividir los datos
Utilizará la columna de fold para dividir el conjunto de datos en conjuntos de entrenamiento, validación y prueba.
ESC-50 está organizado en cinco fold de validación cruzada de tamaño uniforme, de modo que los clips de la misma fuente original siempre están en el mismo fold ; obtenga más información en el documento ESC: Conjunto de datos para clasificación de sonido ambiental .
El último paso es eliminar la columna de fold del conjunto de datos, ya que no la usará durante el entrenamiento.
cached_ds = main_ds.cache()
train_ds = cached_ds.filter(lambda embedding, label, fold: fold < 4)
val_ds = cached_ds.filter(lambda embedding, label, fold: fold == 4)
test_ds = cached_ds.filter(lambda embedding, label, fold: fold == 5)
# remove the folds column now that it's not needed anymore
remove_fold_column = lambda embedding, label, fold: (embedding, label)
train_ds = train_ds.map(remove_fold_column)
val_ds = val_ds.map(remove_fold_column)
test_ds = test_ds.map(remove_fold_column)
train_ds = train_ds.cache().shuffle(1000).batch(32).prefetch(tf.data.AUTOTUNE)
val_ds = val_ds.cache().batch(32).prefetch(tf.data.AUTOTUNE)
test_ds = test_ds.cache().batch(32).prefetch(tf.data.AUTOTUNE)
Crea tu modelo
¡Hiciste la mayor parte del trabajo! A continuación, defina un modelo secuencial muy simple con una capa oculta y dos salidas para reconocer gatos y perros a partir de sonidos.
my_model = tf.keras.Sequential([
tf.keras.layers.Input(shape=(1024), dtype=tf.float32,
name='input_embedding'),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(len(my_classes))
], name='my_model')
my_model.summary()
Model: "my_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 512) 524800
dense_1 (Dense) (None, 2) 1026
=================================================================
Total params: 525,826
Trainable params: 525,826
Non-trainable params: 0
_________________________________________________________________
my_model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer="adam",
metrics=['accuracy'])
callback = tf.keras.callbacks.EarlyStopping(monitor='loss',
patience=3,
restore_best_weights=True)
history = my_model.fit(train_ds,
epochs=20,
validation_data=val_ds,
callbacks=callback)
Epoch 1/20 15/15 [==============================] - 6s 49ms/step - loss: 0.7811 - accuracy: 0.8229 - val_loss: 0.4866 - val_accuracy: 0.9125 Epoch 2/20 15/15 [==============================] - 0s 18ms/step - loss: 0.3385 - accuracy: 0.8938 - val_loss: 0.2185 - val_accuracy: 0.8813 Epoch 3/20 15/15 [==============================] - 0s 18ms/step - loss: 0.3091 - accuracy: 0.9021 - val_loss: 0.4290 - val_accuracy: 0.8813 Epoch 4/20 15/15 [==============================] - 0s 18ms/step - loss: 0.5354 - accuracy: 0.9062 - val_loss: 0.2074 - val_accuracy: 0.9125 Epoch 5/20 15/15 [==============================] - 0s 18ms/step - loss: 0.4651 - accuracy: 0.9333 - val_loss: 0.6857 - val_accuracy: 0.8813 Epoch 6/20 15/15 [==============================] - 0s 18ms/step - loss: 0.2489 - accuracy: 0.9167 - val_loss: 0.3640 - val_accuracy: 0.8750 Epoch 7/20 15/15 [==============================] - 0s 17ms/step - loss: 0.2020 - accuracy: 0.9292 - val_loss: 0.2158 - val_accuracy: 0.9125 Epoch 8/20 15/15 [==============================] - 0s 16ms/step - loss: 0.4550 - accuracy: 0.9208 - val_loss: 0.9893 - val_accuracy: 0.8750 Epoch 9/20 15/15 [==============================] - 0s 17ms/step - loss: 0.3434 - accuracy: 0.9354 - val_loss: 0.2670 - val_accuracy: 0.8813 Epoch 10/20 15/15 [==============================] - 0s 17ms/step - loss: 0.2864 - accuracy: 0.9208 - val_loss: 0.5122 - val_accuracy: 0.8813
Ejecutemos el método de evaluate en los datos de prueba solo para asegurarnos de que no haya sobreajuste.
loss, accuracy = my_model.evaluate(test_ds)
print("Loss: ", loss)
print("Accuracy: ", accuracy)
5/5 [==============================] - 0s 9ms/step - loss: 0.2526 - accuracy: 0.9000 Loss: 0.25257644057273865 Accuracy: 0.8999999761581421
¡Lo hiciste!
Prueba tu modelo
A continuación, pruebe su modelo en la incrustación de la prueba anterior usando solo YAMNet.
scores, embeddings, spectrogram = yamnet_model(testing_wav_data)
result = my_model(embeddings).numpy()
inferred_class = my_classes[result.mean(axis=0).argmax()]
print(f'The main sound is: {inferred_class}')
The main sound is: cat
Guarde un modelo que pueda tomar directamente un archivo WAV como entrada
Su modelo funciona cuando le da las incrustaciones como entrada.
En un escenario del mundo real, querrá usar datos de audio como entrada directa.
Para hacer eso, combinará YAMNet con su modelo en un solo modelo que puede exportar para otras aplicaciones.
Para facilitar el uso del resultado del modelo, la capa final será una operación reduce_mean . Cuando use este modelo para servir (sobre el cual aprenderá más adelante en el tutorial), necesitará el nombre de la capa final. Si no define uno, TensorFlow definirá automáticamente uno incremental que dificulta la prueba, ya que seguirá cambiando cada vez que entrene el modelo. Al usar una operación de TensorFlow sin procesar, no puede asignarle un nombre. Para solucionar este problema, creará una capa personalizada que aplique reduce_mean y la llamará 'classifier' .
class ReduceMeanLayer(tf.keras.layers.Layer):
def __init__(self, axis=0, **kwargs):
super(ReduceMeanLayer, self).__init__(**kwargs)
self.axis = axis
def call(self, input):
return tf.math.reduce_mean(input, axis=self.axis)
saved_model_path = './dogs_and_cats_yamnet'
input_segment = tf.keras.layers.Input(shape=(), dtype=tf.float32, name='audio')
embedding_extraction_layer = hub.KerasLayer(yamnet_model_handle,
trainable=False, name='yamnet')
_, embeddings_output, _ = embedding_extraction_layer(input_segment)
serving_outputs = my_model(embeddings_output)
serving_outputs = ReduceMeanLayer(axis=0, name='classifier')(serving_outputs)
serving_model = tf.keras.Model(input_segment, serving_outputs)
serving_model.save(saved_model_path, include_optimizer=False)
WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. 2022-01-26 08:08:33.807036: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: ./dogs_and_cats_yamnet/assets INFO:tensorflow:Assets written to: ./dogs_and_cats_yamnet/assets
tf.keras.utils.plot_model(serving_model)
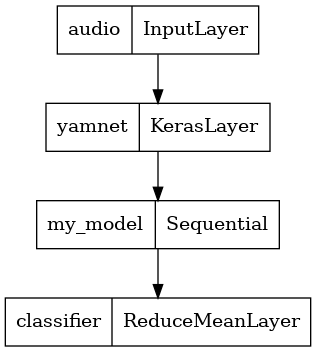
Cargue su modelo guardado para verificar que funciona como se esperaba.
reloaded_model = tf.saved_model.load(saved_model_path)
Y para la prueba final: dados algunos datos de sonido, ¿tu modelo devuelve el resultado correcto?
reloaded_results = reloaded_model(testing_wav_data)
cat_or_dog = my_classes[tf.argmax(reloaded_results)]
print(f'The main sound is: {cat_or_dog}')
The main sound is: cat
Si desea probar su nuevo modelo en una configuración de servicio, puede usar la firma 'serving_default'.
serving_results = reloaded_model.signatures['serving_default'](testing_wav_data)
cat_or_dog = my_classes[tf.argmax(serving_results['classifier'])]
print(f'The main sound is: {cat_or_dog}')
The main sound is: cat
(Opcional) Algunas pruebas más
El modelo está listo.
Comparémoslo con YAMNet en el conjunto de datos de prueba.
test_pd = filtered_pd.loc[filtered_pd['fold'] == 5]
row = test_pd.sample(1)
filename = row['filename'].item()
print(filename)
waveform = load_wav_16k_mono(filename)
print(f'Waveform values: {waveform}')
_ = plt.plot(waveform)
display.Audio(waveform, rate=16000)
./datasets/ESC-50-master/audio/5-214759-A-5.wav WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample Waveform values: [ 3.2084468e-09 -7.7704687e-09 -1.2222010e-08 ... 2.2788899e-02 1.0315948e-02 -3.4766860e-02]
# Run the model, check the output.
scores, embeddings, spectrogram = yamnet_model(waveform)
class_scores = tf.reduce_mean(scores, axis=0)
top_class = tf.argmax(class_scores)
inferred_class = class_names[top_class]
top_score = class_scores[top_class]
print(f'[YAMNet] The main sound is: {inferred_class} ({top_score})')
reloaded_results = reloaded_model(waveform)
your_top_class = tf.argmax(reloaded_results)
your_inferred_class = my_classes[your_top_class]
class_probabilities = tf.nn.softmax(reloaded_results, axis=-1)
your_top_score = class_probabilities[your_top_class]
print(f'[Your model] The main sound is: {your_inferred_class} ({your_top_score})')
[YAMNet] The main sound is: Silence (0.500638484954834) [Your model] The main sound is: cat (0.9981643557548523)
Próximos pasos
Ha creado un modelo que puede clasificar los sonidos de perros o gatos. Con la misma idea y un conjunto de datos diferente, puede intentar, por ejemplo, construir un identificador acústico de pájaros basado en su canto.
¡Comparta su proyecto con el equipo de TensorFlow en las redes sociales!