
| | |  Ver fuente en GitHub Ver fuente en GitHub | |
Este tutorial crea un ejemplo contradictorio mediante el ataque del método firmado de gradiente rápido (FGSM) como se describe en Explicación y aprovechamiento de ejemplos contradictorios por Goodfellow et al . Este fue uno de los primeros y más populares ataques para engañar a una red neuronal.
¿Qué es un ejemplo contradictorio?
Los ejemplos adversarios son entradas especializadas creadas con el propósito de confundir una red neuronal, lo que resulta en la clasificación errónea de una entrada dada. Estas entradas notorias son indistinguibles para el ojo humano, pero hacen que la red no pueda identificar el contenido de la imagen. Hay varios tipos de este tipo de ataques, sin embargo, aquí el foco está en el ataque del método de signo de gradiente rápido, que es un ataque de caja blanca cuyo objetivo es asegurar la clasificación errónea. Un ataque de caja blanca es donde el atacante tiene acceso completo al modelo que está siendo atacado. Uno de los ejemplos más famosos de una imagen contradictoria que se muestra a continuación está tomado del documento mencionado anteriormente.

Aquí, comenzando con la imagen de un panda, el atacante agrega pequeñas perturbaciones (distorsiones) a la imagen original, lo que da como resultado que el modelo etiquete esta imagen como un gibón, con mucha confianza. El proceso de agregar estas perturbaciones se explica a continuación.
Método de signo de gradiente rápido
El método de señal de gradiente rápido funciona utilizando los gradientes de la red neuronal para crear un ejemplo contradictorio. Para una imagen de entrada, el método usa los gradientes de la pérdida con respecto a la imagen de entrada para crear una nueva imagen que maximiza la pérdida. Esta nueva imagen se llama la imagen contradictoria. Esto se puede resumir usando la siguiente expresión:
\[adv\_x = x + \epsilon*\text{sign}(\nabla_xJ(\theta, x, y))\]
donde
- adv_x : Imagen adversaria.
- x : Imagen de entrada original.
- y : Etiqueta de entrada original.
- \(\epsilon\) : Multiplicador para asegurar que las perturbaciones sean pequeñas.
- \(\theta\) : Parámetros del modelo.
- \(J\) : Pérdida.
Una propiedad intrigante aquí es el hecho de que los gradientes se toman con respecto a la imagen de entrada. Esto se hace porque el objetivo es crear una imagen que maximice la pérdida. Un método para lograr esto es encontrar cuánto contribuye cada píxel de la imagen al valor de pérdida y agregar una perturbación en consecuencia. Esto funciona bastante rápido porque es fácil encontrar cómo cada píxel de entrada contribuye a la pérdida usando la regla de la cadena y encontrando los gradientes requeridos. Por lo tanto, los gradientes se toman con respecto a la imagen. Además, dado que ya no se está entrenando el modelo (por lo que no se toma el gradiente con respecto a las variables entrenables, es decir, los parámetros del modelo), por lo que los parámetros del modelo se mantienen constantes. El único objetivo es engañar a un modelo ya entrenado.
Así que intentemos engañar a un modelo previamente entrenado. En este tutorial, el modelo es el modelo MobileNetV2 , entrenado previamente en ImageNet .
import tensorflow as tf
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rcParams['figure.figsize'] = (8, 8)
mpl.rcParams['axes.grid'] = False
Carguemos el modelo MobileNetV2 preentrenado y los nombres de clase de ImageNet.
pretrained_model = tf.keras.applications.MobileNetV2(include_top=True,
weights='imagenet')
pretrained_model.trainable = False
# ImageNet labels
decode_predictions = tf.keras.applications.mobilenet_v2.decode_predictions
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/mobilenet_v2/mobilenet_v2_weights_tf_dim_ordering_tf_kernels_1.0_224.h5 14540800/14536120 [==============================] - 0s 0us/step 14548992/14536120 [==============================] - 0s 0us/step
# Helper function to preprocess the image so that it can be inputted in MobileNetV2
def preprocess(image):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, (224, 224))
image = tf.keras.applications.mobilenet_v2.preprocess_input(image)
image = image[None, ...]
return image
# Helper function to extract labels from probability vector
def get_imagenet_label(probs):
return decode_predictions(probs, top=1)[0][0]
Imagen original
Usemos una imagen de muestra de un Labrador Retriever de Mirko CC-BY-SA 3.0 de Wikimedia Common y creemos ejemplos contradictorios a partir de ella. El primer paso es preprocesarlo para que pueda alimentarse como entrada al modelo MobileNetV2.
{kind=link}
image_path = tf.keras.utils.get_file('YellowLabradorLooking_new.jpg', 'https://storage.googleapis.com/download.tensorflow.org/example_images/YellowLabradorLooking_new.jpg')
image_raw = tf.io.read_file(image_path)
image = tf.image.decode_image(image_raw)
image = preprocess(image)
image_probs = pretrained_model.predict(image)
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/YellowLabradorLooking_new.jpg 90112/83281 [================================] - 0s 0us/step 98304/83281 [===================================] - 0s 0us/step
Echemos un vistazo a la imagen.
plt.figure()
plt.imshow(image[0] * 0.5 + 0.5) # To change [-1, 1] to [0,1]
_, image_class, class_confidence = get_imagenet_label(image_probs)
plt.title('{} : {:.2f}% Confidence'.format(image_class, class_confidence*100))
plt.show()
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/imagenet_class_index.json 40960/35363 [==================================] - 0s 0us/step 49152/35363 [=========================================] - 0s 0us/step

Crear la imagen adversaria
Implementando el método de señal de gradiente rápido
El primer paso es crear perturbaciones que se utilizarán para distorsionar la imagen original y dar como resultado una imagen antagónica. Como se mencionó, para esta tarea, los gradientes se toman con respecto a la imagen.
loss_object = tf.keras.losses.CategoricalCrossentropy()
def create_adversarial_pattern(input_image, input_label):
with tf.GradientTape() as tape:
tape.watch(input_image)
prediction = pretrained_model(input_image)
loss = loss_object(input_label, prediction)
# Get the gradients of the loss w.r.t to the input image.
gradient = tape.gradient(loss, input_image)
# Get the sign of the gradients to create the perturbation
signed_grad = tf.sign(gradient)
return signed_grad
Las perturbaciones resultantes también se pueden visualizar.
# Get the input label of the image.
labrador_retriever_index = 208
label = tf.one_hot(labrador_retriever_index, image_probs.shape[-1])
label = tf.reshape(label, (1, image_probs.shape[-1]))
perturbations = create_adversarial_pattern(image, label)
plt.imshow(perturbations[0] * 0.5 + 0.5); # To change [-1, 1] to [0,1]
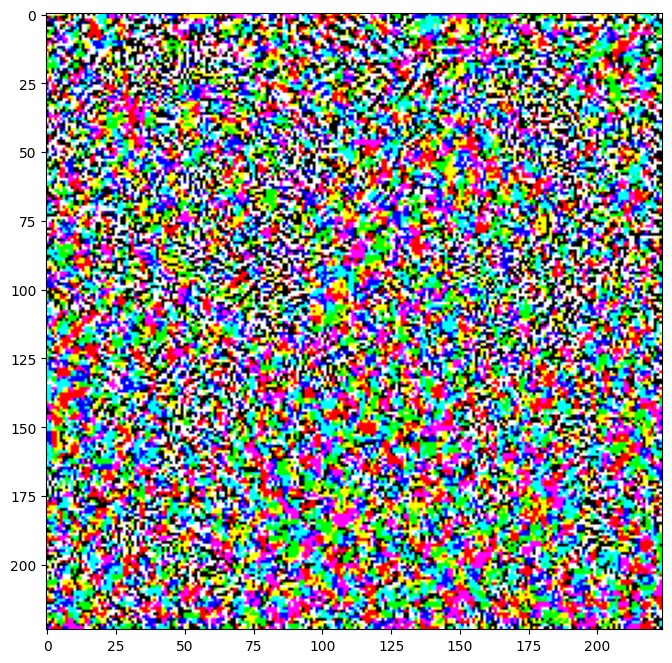
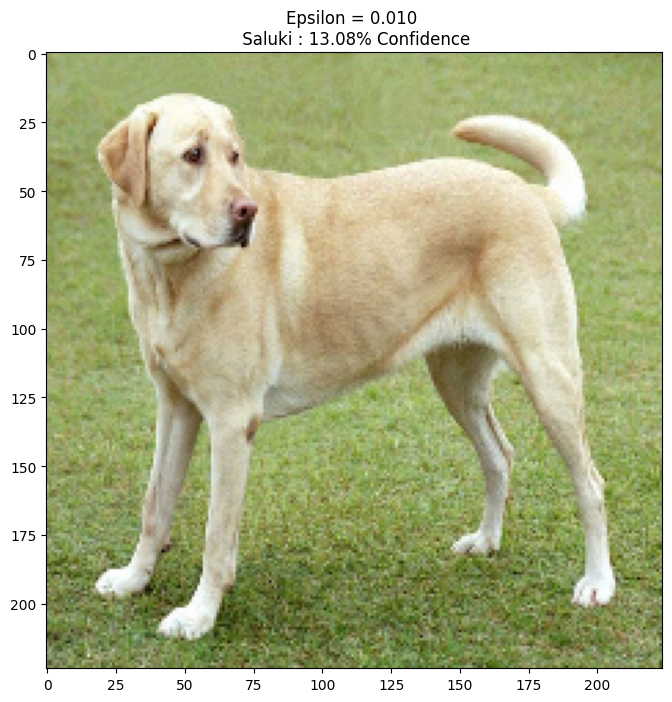
Probemos esto para diferentes valores de épsilon y observemos la imagen resultante. Notará que a medida que aumenta el valor de épsilon, se vuelve más fácil engañar a la red. Sin embargo, esto se presenta como una compensación que da como resultado que las perturbaciones se vuelvan más identificables.
def display_images(image, description):
_, label, confidence = get_imagenet_label(pretrained_model.predict(image))
plt.figure()
plt.imshow(image[0]*0.5+0.5)
plt.title('{} \n {} : {:.2f}% Confidence'.format(description,
label, confidence*100))
plt.show()
epsilons = [0, 0.01, 0.1, 0.15]
descriptions = [('Epsilon = {:0.3f}'.format(eps) if eps else 'Input')
for eps in epsilons]
for i, eps in enumerate(epsilons):
adv_x = image + eps*perturbations
adv_x = tf.clip_by_value(adv_x, -1, 1)
display_images(adv_x, descriptions[i])



Próximos pasos
Ahora que conoce los ataques de adversarios, pruebe esto en diferentes conjuntos de datos y diferentes arquitecturas. También puede crear y entrenar su propio modelo y luego intentar engañarlo usando el mismo método. También puede probar y ver cómo varía la confianza en las predicciones a medida que cambia de épsilon.
Aunque poderoso, el ataque que se muestra en este tutorial fue solo el comienzo de la investigación sobre los ataques adversarios, y desde entonces ha habido varios documentos que crean ataques más poderosos. Además de los ataques adversarios, la investigación también ha llevado a la creación de defensas, cuyo objetivo es crear modelos robustos de aprendizaje automático. Puede revisar este documento de encuesta para obtener una lista completa de los ataques y defensas adversarios.
Para muchas más implementaciones de ataques y defensas contradictorios, es posible que desee ver la biblioteca de ejemplos contradictorios CleverHans .