
| | |  Ver fuente en GitHub Ver fuente en GitHub | |
Este tutorial demuestra cómo entrenar una red neuronal convolucional (CNN) simple para clasificar imágenes CIFAR . Debido a que este tutorial usa la API secuencial de Keras , crear y entrenar su modelo tomará solo unas pocas líneas de código.
Importar TensorFlow
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
Descargue y prepare el conjunto de datos CIFAR10
El conjunto de datos CIFAR10 contiene 60 000 imágenes en color en 10 clases, con 6000 imágenes en cada clase. El conjunto de datos se divide en 50 000 imágenes de entrenamiento y 10 000 imágenes de prueba. Las clases son mutuamente excluyentes y no hay superposición entre ellas.
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
# Normalize pixel values to be between 0 and 1
train_images, test_images = train_images / 255.0, test_images / 255.0
Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz 170500096/170498071 [==============================] - 11s 0us/step 170508288/170498071 [==============================] - 11s 0us/step
Verifica los datos
Para verificar que el conjunto de datos se vea correcto, tracemos las primeras 25 imágenes del conjunto de entrenamiento y mostremos el nombre de la clase debajo de cada imagen:
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i])
# The CIFAR labels happen to be arrays,
# which is why you need the extra index
plt.xlabel(class_names[train_labels[i][0]])
plt.show()

Crear la base convolucional
Las 6 líneas de código a continuación definen la base convolucional utilizando un patrón común: una pila de capas Conv2D y MaxPooling2D .
Como entrada, una CNN toma tensores de forma (altura_imagen, ancho_imagen, canales_color), ignorando el tamaño del lote. Si eres nuevo en estas dimensiones, color_channels se refiere a (R,G,B). En este ejemplo, configurará su CNN para procesar entradas de forma (32, 32, 3), que es el formato de las imágenes CIFAR. Puede hacer esto pasando el argumento input_shape a su primera capa.
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
Vamos a mostrar la arquitectura de su modelo hasta ahora:
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 30, 30, 32) 896
max_pooling2d (MaxPooling2D (None, 15, 15, 32) 0
)
conv2d_1 (Conv2D) (None, 13, 13, 64) 18496
max_pooling2d_1 (MaxPooling (None, 6, 6, 64) 0
2D)
conv2d_2 (Conv2D) (None, 4, 4, 64) 36928
=================================================================
Total params: 56,320
Trainable params: 56,320
Non-trainable params: 0
_________________________________________________________________
Arriba, puede ver que la salida de cada capa Conv2D y MaxPooling2D es un tensor de forma 3D (alto, ancho, canales). Las dimensiones de ancho y alto tienden a reducirse a medida que se profundiza en la red. El número de canales de salida para cada capa Conv2D está controlado por el primer argumento (por ejemplo, 32 o 64). Por lo general, a medida que se reducen el ancho y el alto, puede permitirse (computacionalmente) agregar más canales de salida en cada capa Conv2D.
Agregue capas densas en la parte superior
Para completar el modelo, alimentará el último tensor de salida de la base convolucional (de forma (4, 4, 64)) en una o más capas densas para realizar la clasificación. Las capas densas toman vectores como entrada (que son 1D), mientras que la salida actual es un tensor 3D. Primero, aplanará (o desenrollará) la salida 3D a 1D, luego agregará una o más capas densas en la parte superior. CIFAR tiene 10 clases de salida, por lo que usa una capa Densa final con 10 salidas.
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10))
Aquí está la arquitectura completa de su modelo:
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 30, 30, 32) 896
max_pooling2d (MaxPooling2D (None, 15, 15, 32) 0
)
conv2d_1 (Conv2D) (None, 13, 13, 64) 18496
max_pooling2d_1 (MaxPooling (None, 6, 6, 64) 0
2D)
conv2d_2 (Conv2D) (None, 4, 4, 64) 36928
flatten (Flatten) (None, 1024) 0
dense (Dense) (None, 64) 65600
dense_1 (Dense) (None, 10) 650
=================================================================
Total params: 122,570
Trainable params: 122,570
Non-trainable params: 0
_________________________________________________________________
El resumen de la red muestra que las salidas (4, 4, 64) se aplanaron en vectores de forma (1024) antes de pasar por dos capas densas.
Compilar y entrenar el modelo.
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
history = model.fit(train_images, train_labels, epochs=10,
validation_data=(test_images, test_labels))
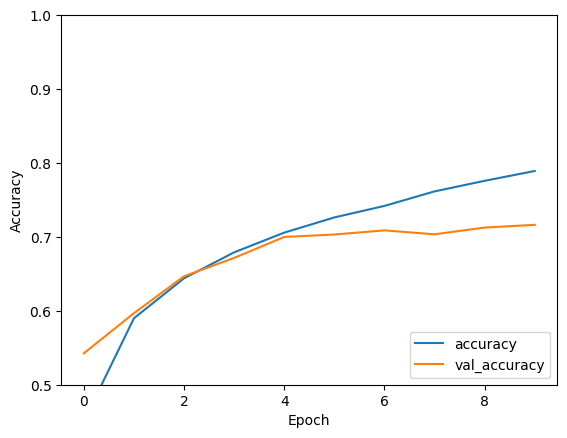
Epoch 1/10 1563/1563 [==============================] - 8s 4ms/step - loss: 1.4971 - accuracy: 0.4553 - val_loss: 1.2659 - val_accuracy: 0.5492 Epoch 2/10 1563/1563 [==============================] - 6s 4ms/step - loss: 1.1424 - accuracy: 0.5966 - val_loss: 1.1025 - val_accuracy: 0.6098 Epoch 3/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.9885 - accuracy: 0.6539 - val_loss: 0.9557 - val_accuracy: 0.6629 Epoch 4/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.8932 - accuracy: 0.6878 - val_loss: 0.8924 - val_accuracy: 0.6935 Epoch 5/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.8222 - accuracy: 0.7130 - val_loss: 0.8679 - val_accuracy: 0.7025 Epoch 6/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.7663 - accuracy: 0.7323 - val_loss: 0.9336 - val_accuracy: 0.6819 Epoch 7/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.7224 - accuracy: 0.7466 - val_loss: 0.8546 - val_accuracy: 0.7086 Epoch 8/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.6726 - accuracy: 0.7611 - val_loss: 0.8777 - val_accuracy: 0.7068 Epoch 9/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.6372 - accuracy: 0.7760 - val_loss: 0.8410 - val_accuracy: 0.7179 Epoch 10/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.6024 - accuracy: 0.7875 - val_loss: 0.8475 - val_accuracy: 0.7192
Evaluar el modelo
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0.5, 1])
plt.legend(loc='lower right')
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
313/313 - 1s - loss: 0.8475 - accuracy: 0.7192 - 634ms/epoch - 2ms/step
print(test_acc)
0.7192000150680542
Su simple CNN ha logrado una precisión de prueba de más del 70%. ¡No está mal para unas pocas líneas de código! Para ver otro estilo de CNN, consulte el ejemplo de inicio rápido de TensorFlow 2 para expertos que usa la API de subclases de Keras y tf.GradientTape .