
| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub | |
تمایز خودکار و گرادیان
تمایز خودکار برای پیاده سازی الگوریتم های یادگیری ماشین مانند انتشار پس زمینه برای آموزش شبکه های عصبی مفید است.
در این راهنما، راههایی برای محاسبه گرادیان با TensorFlow، بهویژه در اجرای مشتاق، بررسی خواهید کرد.
برپایی
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
شیب محاسباتی
برای تمایز خودکار، TensorFlow باید به خاطر داشته باشد که در طول پاس رو به جلو چه عملیاتی به چه ترتیبی اتفاق میافتد. سپس، در طول گذر به عقب ، TensorFlow این لیست از عملیات را به ترتیب معکوس طی می کند تا گرادیان ها را محاسبه کند.
نوارهای گرادیان
tf.GradientTape API tf.GradientTape را برای تمایز خودکار فراهم می کند. یعنی محاسبه گرادیان یک محاسبات با توجه به برخی ورودیها، معمولا tf.Variable . متغیر s. TensorFlow عملیات مربوطه اجرا شده در متن یک tf.GradientTape را روی یک نوار "ضبط" می کند. سپس TensorFlow از آن نوار برای محاسبه گرادیان یک محاسبات "ضبط شده" با استفاده از تمایز حالت معکوس استفاده می کند.
در اینجا یک مثال ساده است:
x = tf.Variable(3.0)
with tf.GradientTape() as tape:
y = x**2
هنگامی که برخی از عملیات را ضبط کردید، از GradientTape.gradient(target, sources) برای محاسبه گرادیان برخی از اهداف (اغلب ضرر) نسبت به منبعی (اغلب متغیرهای مدل) استفاده کنید:
# dy = 2x * dx
dy_dx = tape.gradient(y, x)
dy_dx.numpy()
6.0
مثال بالا از اسکالر استفاده می کند، اما tf.GradientTape به راحتی روی هر تانسوری کار می کند:
w = tf.Variable(tf.random.normal((3, 2)), name='w')
b = tf.Variable(tf.zeros(2, dtype=tf.float32), name='b')
x = [[1., 2., 3.]]
with tf.GradientTape(persistent=True) as tape:
y = x @ w + b
loss = tf.reduce_mean(y**2)
برای بدست آوردن گرادیان از loss با توجه به هر دو متغیر، می توانید هر دو را به عنوان منبع به روش gradient منتقل کنید. نوار در مورد نحوه ارسال منابع انعطافپذیر است و هر ترکیب تودرتو از فهرستها یا فرهنگ لغتها را میپذیرد و گرادیان را با ساختاری مشابه برمیگرداند (به tf.nest مراجعه کنید).
[dl_dw, dl_db] = tape.gradient(loss, [w, b])
گرادیان نسبت به هر منبع شکل منبع را دارد:
print(w.shape)
print(dl_dw.shape)
(3, 2) (3, 2)
در اینجا دوباره محاسبه گرادیان آمده است، این بار از فرهنگ لغت متغیرها عبور می کند:
my_vars = {
'w': w,
'b': b
}
grad = tape.gradient(loss, my_vars)
grad['b']
<tf.Tensor: shape=(2,), dtype=float32, numpy=array([-1.6920902, -3.2363236], dtype=float32)>
گرادیان ها با توجه به یک مدل
معمولاً tf.Variables را در یک tf.Module یا یکی از زیر کلاسهای آن (لایهها. لایه، layers.Layer ) برای keras.Model و صادرات جمعآوری میکنیم.
در بیشتر موارد، شما می خواهید گرادیان ها را با توجه به متغیرهای آموزش پذیر مدل محاسبه کنید. از آنجایی که همه زیر کلاس های tf.Module متغیرهای خود را در ویژگی Module.trainable_variables جمع می کنند، می توانید این گرادیان ها را در چند خط کد محاسبه کنید:
layer = tf.keras.layers.Dense(2, activation='relu')
x = tf.constant([[1., 2., 3.]])
with tf.GradientTape() as tape:
# Forward pass
y = layer(x)
loss = tf.reduce_mean(y**2)
# Calculate gradients with respect to every trainable variable
grad = tape.gradient(loss, layer.trainable_variables)
for var, g in zip(layer.trainable_variables, grad):
print(f'{var.name}, shape: {g.shape}')
dense/kernel:0, shape: (3, 2) dense/bias:0, shape: (2,)
کنترل آنچه که نوار تماشا می کند
رفتار پیشفرض این است که پس از دسترسی به tf.Variable قابل آموزش، همه عملیاتها را ضبط میکند. دلایل این امر عبارتند از:
- نوار باید بداند که کدام عملیات را در گذر به جلو ضبط کند تا گرادیان ها در گذر به عقب محاسبه شود.
- نوار ارجاعاتی به خروجی های میانی دارد، بنابراین شما نمی خواهید عملیات غیر ضروری را ضبط کنید.
- رایج ترین مورد استفاده شامل محاسبه گرادیان ضرر با توجه به همه متغیرهای آموزش پذیر مدل است.
به عنوان مثال، موارد زیر قادر به محاسبه یک گرادیان نیستند زیرا tf.Tensor به طور پیش فرض "watched" نمی شود و tf.Variable قابل آموزش نیست:
# A trainable variable
x0 = tf.Variable(3.0, name='x0')
# Not trainable
x1 = tf.Variable(3.0, name='x1', trainable=False)
# Not a Variable: A variable + tensor returns a tensor.
x2 = tf.Variable(2.0, name='x2') + 1.0
# Not a variable
x3 = tf.constant(3.0, name='x3')
with tf.GradientTape() as tape:
y = (x0**2) + (x1**2) + (x2**2)
grad = tape.gradient(y, [x0, x1, x2, x3])
for g in grad:
print(g)
tf.Tensor(6.0, shape=(), dtype=float32) None None None
با استفاده از روش GradientTape.watched_variables میتوانید متغیرهایی را که توسط نوار تماشا میشوند فهرست کنید:
[var.name for var in tape.watched_variables()]
['x0:0']
tf.GradientTape را ارائه میکند که به کاربر اجازه میدهد بر آنچه که تماشا میشود یا نمیشود کنترل داشته باشد.
برای ضبط گرادیان با توجه به tf.Tensor ، باید GradientTape.watch(x) را فراخوانی کنید:
x = tf.constant(3.0)
with tf.GradientTape() as tape:
tape.watch(x)
y = x**2
# dy = 2x * dx
dy_dx = tape.gradient(y, x)
print(dy_dx.numpy())
6.0
برعکس، برای غیرفعال کردن رفتار پیشفرض تماشای همه tf.Variables ، هنگام ایجاد نوار گرادیان، watch_accessed_variables=False را تنظیم کنید. این محاسبه از دو متغیر استفاده می کند، اما فقط گرادیان یکی از متغیرها را به هم متصل می کند:
x0 = tf.Variable(0.0)
x1 = tf.Variable(10.0)
with tf.GradientTape(watch_accessed_variables=False) as tape:
tape.watch(x1)
y0 = tf.math.sin(x0)
y1 = tf.nn.softplus(x1)
y = y0 + y1
ys = tf.reduce_sum(y)
از آنجایی که GradientTape.watch روی x0 فراخوانی نشده است، هیچ گرادیانی با توجه به آن محاسبه نمی شود:
# dys/dx1 = exp(x1) / (1 + exp(x1)) = sigmoid(x1)
grad = tape.gradient(ys, {'x0': x0, 'x1': x1})
print('dy/dx0:', grad['x0'])
print('dy/dx1:', grad['x1'].numpy())
dy/dx0: None dy/dx1: 0.9999546
نتایج متوسط
همچنین میتوانید گرادیانهای خروجی را با توجه به مقادیر میانی محاسبهشده در زمینه tf.GradientTape کنید.
x = tf.constant(3.0)
with tf.GradientTape() as tape:
tape.watch(x)
y = x * x
z = y * y
# Use the tape to compute the gradient of z with respect to the
# intermediate value y.
# dz_dy = 2 * y and y = x ** 2 = 9
print(tape.gradient(z, y).numpy())
18.0
بهطور پیشفرض، منابع نگهداری شده توسط GradientTape به محض فراخوانی متد GradientTape.gradient آزاد میشوند. برای محاسبه چندین گرادیان روی یک محاسبات، یک نوار گرادیان با persistent=True ایجاد کنید. این اجازه می دهد تا چندین فراخوانی را به روش gradient انجام دهید، زیرا منابع زمانی که شی نوار جمع آوری می شود، آزاد می شوند. مثلا:
x = tf.constant([1, 3.0])
with tf.GradientTape(persistent=True) as tape:
tape.watch(x)
y = x * x
z = y * y
print(tape.gradient(z, x).numpy()) # [4.0, 108.0] (4 * x**3 at x = [1.0, 3.0])
print(tape.gradient(y, x).numpy()) # [2.0, 6.0] (2 * x at x = [1.0, 3.0])
[ 4. 108.] [2. 6.]
del tape # Drop the reference to the tape
نکاتی در مورد عملکرد
یک سربار کوچک در ارتباط با انجام عملیات در یک زمینه نوار گرادیان وجود دارد. برای اکثر اجراهای مشتاق، این هزینه قابل توجهی نخواهد بود، اما همچنان باید از نوار نواری در اطراف مناطقی استفاده کنید که نیاز است.
نوارهای گرادیان از حافظه برای ذخیره نتایج میانی، از جمله ورودی و خروجی، برای استفاده در حین عبور به عقب استفاده می کنند.
برای کارایی، برخی از عملیات ها (مانند
ReLU) نیازی به حفظ نتایج متوسط خود ندارند و در طول پاس رو به جلو هرس می شوند. با این حال، اگر روی نوار خود ازpersistent=Trueاستفاده کنید، هیچ چیز کنار گذاشته نمیشود و حداکثر استفاده از حافظه شما بیشتر خواهد بود.
گرادیان اهداف غیر اسکالر
گرادیان اساساً عملیاتی بر روی یک اسکالر است.
x = tf.Variable(2.0)
with tf.GradientTape(persistent=True) as tape:
y0 = x**2
y1 = 1 / x
print(tape.gradient(y0, x).numpy())
print(tape.gradient(y1, x).numpy())
4.0 -0.25
بنابراین، اگر گرادیان چندین هدف را بخواهید، نتیجه برای هر منبع این است:
- گرادیان مجموع اهداف یا معادل آن
- مجموع گرادیان های هر هدف.
x = tf.Variable(2.0)
with tf.GradientTape() as tape:
y0 = x**2
y1 = 1 / x
print(tape.gradient({'y0': y0, 'y1': y1}, x).numpy())
3.75
به طور مشابه، اگر هدف(ها) اسکالر نباشند، گرادیان مجموع محاسبه می شود:
x = tf.Variable(2.)
with tf.GradientTape() as tape:
y = x * [3., 4.]
print(tape.gradient(y, x).numpy())
7.0
این امر، گرفتن گرادیان مجموع مجموعه ای از تلفات، یا گرادیان مجموع محاسبه تلفات از نظر عنصر را ساده می کند.
اگر برای هر مورد به یک گرادیان جداگانه نیاز دارید، به Jacobians مراجعه کنید.
در برخی موارد می توانید ژاکوبین را نادیده بگیرید. برای یک محاسبه از نظر عنصر، گرادیان مجموع مشتق هر عنصر را با توجه به عنصر ورودی آن نشان میدهد، زیرا هر عنصر مستقل است:
x = tf.linspace(-10.0, 10.0, 200+1)
with tf.GradientTape() as tape:
tape.watch(x)
y = tf.nn.sigmoid(x)
dy_dx = tape.gradient(y, x)
plt.plot(x, y, label='y')
plt.plot(x, dy_dx, label='dy/dx')
plt.legend()
_ = plt.xlabel('x')
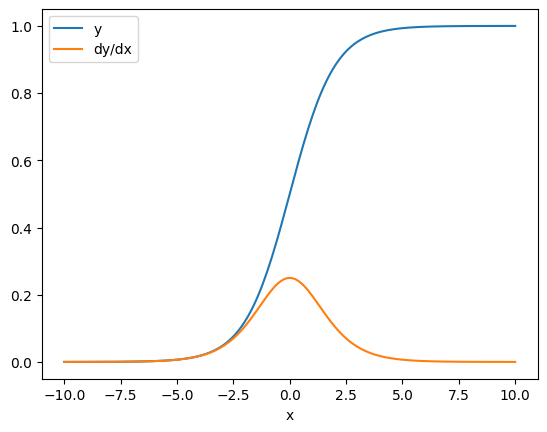
کنترل جریان
از آنجایی که نوار گرادیان عملیات ها را هنگام اجرا ثبت می کند، جریان کنترل پایتون به طور طبیعی مدیریت می شود (مثلاً دستورات if و while ).
در اینجا یک متغیر متفاوت برای هر شاخه از if استفاده می شود. گرادیان فقط به متغیری که استفاده شده است متصل می شود:
x = tf.constant(1.0)
v0 = tf.Variable(2.0)
v1 = tf.Variable(2.0)
with tf.GradientTape(persistent=True) as tape:
tape.watch(x)
if x > 0.0:
result = v0
else:
result = v1**2
dv0, dv1 = tape.gradient(result, [v0, v1])
print(dv0)
print(dv1)
tf.Tensor(1.0, shape=(), dtype=float32) None
فقط به یاد داشته باشید که خود دستورات کنترلی قابل تمایز نیستند، بنابراین برای بهینه سازهای مبتنی بر گرادیان نامرئی هستند.
بسته به مقدار x در مثال بالا، نوار یا result = v0 یا result = v1**2 را ثبت می کند. گرادیان نسبت به x همیشه None است.
dx = tape.gradient(result, x)
print(dx)
None
گرفتن گرادیان None
وقتی هدفی به منبعی متصل نیست، گرادیان None را دریافت خواهید کرد.
x = tf.Variable(2.)
y = tf.Variable(3.)
with tf.GradientTape() as tape:
z = y * y
print(tape.gradient(z, x))
None
در اینجا z به وضوح به x متصل نیست، اما چندین روش کمتر واضح وجود دارد که یک گرادیان را می توان قطع کرد.
1. یک متغیر را با یک تانسور جایگزین کرد
در بخش "کنترل آنچه که نوار تماشا می کند" مشاهده کردید که نوار به طور خودکار یک tf.Variable را تماشا می کند اما یک tf.Variable را نمی tf.Tensor .
یکی از خطاهای رایج این است که به جای استفاده از Variable.assign برای به روز رسانی tf.Tensor ، سهواً یک tf.Variable با tf.Tensor جایگزین می tf.Variable . به عنوان مثال:
x = tf.Variable(2.0)
for epoch in range(2):
with tf.GradientTape() as tape:
y = x+1
print(type(x).__name__, ":", tape.gradient(y, x))
x = x + 1 # This should be `x.assign_add(1)`
ResourceVariable : tf.Tensor(1.0, shape=(), dtype=float32) EagerTensor : None
2. محاسبات خارج از TensorFlow انجام داد
اگر محاسبه از TensorFlow خارج شود، نوار نمی تواند مسیر گرادیان را ضبط کند. مثلا:
x = tf.Variable([[1.0, 2.0],
[3.0, 4.0]], dtype=tf.float32)
with tf.GradientTape() as tape:
x2 = x**2
# This step is calculated with NumPy
y = np.mean(x2, axis=0)
# Like most ops, reduce_mean will cast the NumPy array to a constant tensor
# using `tf.convert_to_tensor`.
y = tf.reduce_mean(y, axis=0)
print(tape.gradient(y, x))
None
3. گرادیان ها را از طریق یک عدد صحیح یا رشته در نظر گرفت
اعداد صحیح و رشته ها قابل تمایز نیستند. اگر یک مسیر محاسباتی از این نوع داده ها استفاده کند، گرادیان وجود نخواهد داشت.
هیچ کس انتظار ندارد رشته ها قابل تمایز باشند، اما اگر dtype را مشخص نکنید، ایجاد تصادفی ثابت یا متغیر int آسان است.
x = tf.constant(10)
with tf.GradientTape() as g:
g.watch(x)
y = x * x
print(g.gradient(y, x))
WARNING:tensorflow:The dtype of the watched tensor must be floating (e.g. tf.float32), got tf.int32 WARNING:tensorflow:The dtype of the target tensor must be floating (e.g. tf.float32) when calling GradientTape.gradient, got tf.int32 WARNING:tensorflow:The dtype of the source tensor must be floating (e.g. tf.float32) when calling GradientTape.gradient, got tf.int32 None
TensorFlow به طور خودکار بین انواع ارسال نمی شود، بنابراین، در عمل، اغلب به جای یک گرادیان از دست رفته، یک خطای نوع دریافت خواهید کرد.
4. گرادیان ها را از طریق یک شی حالت دار گرفت
حالت شیب ها را متوقف می کند. وقتی از یک شیء حالت دار می خوانید، نوار فقط می تواند وضعیت فعلی را مشاهده کند، نه تاریخچه ای را که منجر به آن می شود.
یک tf.Tensor تغییرناپذیر است. وقتی یک تانسور ساخته شد نمی توانید آن را تغییر دهید. ارزش دارد اما حالت ندارد. تمام عملیاتهایی که تاکنون مورد بحث قرار گرفتهاند نیز بدون حالت هستند: خروجی یک tf.matmul فقط به ورودیهای آن بستگی دارد.
یک tf.Variable حالت داخلی دارد—مقدار آن. وقتی از متغیر استفاده می کنید، حالت خوانده می شود. محاسبه گرادیان با توجه به یک متغیر طبیعی است، اما حالت متغیر، محاسبات گرادیان را از عقبتر رفتن مسدود میکند. مثلا:
x0 = tf.Variable(3.0)
x1 = tf.Variable(0.0)
with tf.GradientTape() as tape:
# Update x1 = x1 + x0.
x1.assign_add(x0)
# The tape starts recording from x1.
y = x1**2 # y = (x1 + x0)**2
# This doesn't work.
print(tape.gradient(y, x0)) #dy/dx0 = 2*(x1 + x0)
None
به طور مشابه، تکرار کننده های tf.data.Dataset و tf.queue s حالت دارند و تمام گرادیان های تانسورهایی را که از آنها عبور می کنند متوقف می کنند.
شیب ثبت نشده است
برخی از tf.Operation بهعنوان غیرقابل تمایز ثبت شدهاند و None را برمیگردانند. دیگران هیچ گرادیانی ثبت نشده اند .
صفحه tf.raw_ops نشان می دهد که کدام عملیات سطح پایین دارای گرادیان ثبت شده است.
اگر سعی کنید یک گرادیانت را از طریق یک عملیات شناور که هیچ گرادیانی ثبت نشده است عبور دهید، نوار به جای اینکه بیصدا None را برگرداند، خطایی ایجاد میکند. به این ترتیب متوجه می شوید که مشکلی پیش آمده است.
به عنوان مثال، تابع tf.image.adjust_contrast raw_ops.AdjustContrastv2 را می پوشاند، که می تواند یک گرادیان داشته باشد اما گرادیان پیاده سازی نشده است:
image = tf.Variable([[[0.5, 0.0, 0.0]]])
delta = tf.Variable(0.1)
with tf.GradientTape() as tape:
new_image = tf.image.adjust_contrast(image, delta)
try:
print(tape.gradient(new_image, [image, delta]))
assert False # This should not happen.
except LookupError as e:
print(f'{type(e).__name__}: {e}')
LookupError: gradient registry has no entry for: AdjustContrastv2
اگر میخواهید از طریق این عملیات متمایز شوید، یا باید گرادیان را پیادهسازی کنید و آن را ثبت کنید (با استفاده از tf.RegisterGradient ) یا تابع را با استفاده از سایر عملیاتها دوباره پیادهسازی کنید.
صفر به جای هیچ
در برخی موارد، گرفتن 0 به جای None برای گرادیان های غیر متصل راحت است. با استفاده از آرگومان unconnected_gradients میتوانید تصمیم بگیرید که وقتی گرادینتهای غیر متصل دارید چه چیزی را برگردانید:
x = tf.Variable([2., 2.])
y = tf.Variable(3.)
with tf.GradientTape() as tape:
z = y**2
print(tape.gradient(z, x, unconnected_gradients=tf.UnconnectedGradients.ZERO))
tf.Tensor([0. 0.], shape=(2,), dtype=float32)