
| |
|
 GitHub에서 소스 보기 GitHub에서 소스 보기 |
제로 값을 많이 포함하는 텐서로 작업할 경우에는 공간 및 시간 효율적인 방식으로 저장하는 것이 중요합니다. 희소 텐서는 제로 값을 많이 포함하는 텐서를 효율적으로 저장하고 처리할 수 있도록 합니다. 희소 텐서는 NLP 애플리케이션에서 데이터 전처리의 일부로 TF-IDF와 같은 인코딩 체계와, 컴퓨터 비전 애플리케이션에서 어두운 픽셀이 많은 이미지를 전처리하는 경우 등에 광범위하게 사용됩니다.
TensorFlow의 희소 텐서
TensorFlow는 tf.sparse.SparseTensor 객체를 통해 희소 텐서를 나타냅니다. 현재 TensorFlow의 희소 텐서는 좌표 목록(COO) 형식을 사용하여 인코딩됩니다. 이 인코딩 형식은 임베딩과 같은 초희소(hyper-sparse) 행렬에 최적화되어 있습니다.
희소 텐서에서 COO 인코딩은 다음으로 구성되어 있습니다.
values: 제로가 아닌 모든 값을 포함하는[N]형상의 1D 텐서indices: 제로가 아닌 값의 엔덱스를 포함하는[N, rank]형상의 2D 텐서dense_shape: 텐서의 형상을 지정하는[rank]형상의 1D 텐서
tf.sparse.SparseTensor 컨텍스트에서 제로가 아닌 값은 명시적으로 인코딩하지 않은 값입니다. COO 희소 행렬의 values에 제로 값을 명시적으로 포함할 수 있지만 이러한 "명시적 제로"는 일반적으로 희소 텐서에서 제로가 아닌 값을 참조할 때 포함하지 않습니다.
참고: tf.sparse.SparseTensor는 인덱스/값이 특정 순서로 되어 있을 것을 요구하지 않지만 여러 연산에서는 행 우선 순서로 되어 있다고 가정합니다. 기준 행 우선 순서로 정렬된 희소 텐서의 사본을 생성하려면 tf.sparse.reorder를 사용합니다.
tf.sparse.SparseTensor 생성하기
values, indices 및 dense_shape를 직접 지정하여 희소 텐서를 구성합니다.
import tensorflow as tf
2022-12-14 21:26:26.424010: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory 2022-12-14 21:26:26.424111: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory 2022-12-14 21:26:26.424122: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
st1 = tf.sparse.SparseTensor(indices=[[0, 3], [2, 4]],
values=[10, 20],
dense_shape=[3, 10])
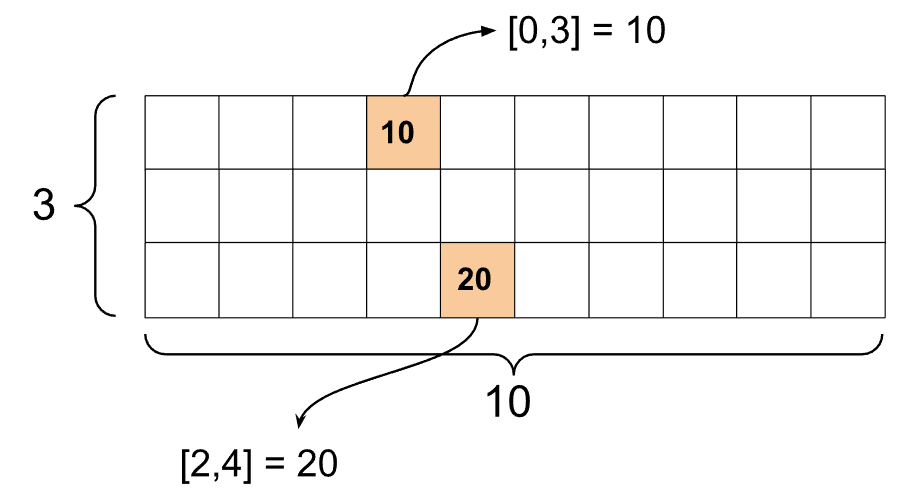
print() 함수를 사용하여 희소 텐서를 출력하면 세 가지 구성 요소 텐서의 콘텐츠를 표시합니다.
print(st1)
SparseTensor(indices=tf.Tensor( [[0 3] [2 4]], shape=(2, 2), dtype=int64), values=tf.Tensor([10 20], shape=(2,), dtype=int32), dense_shape=tf.Tensor([ 3 10], shape=(2,), dtype=int64))
제로가 아닌 values가 해당 indices에 맞추어 정렬되어 있으면 희소 텐서의 콘텐츠를 더 쉽게 이해할 수 있습니다. 제로가 아닌 각 값이 자체 행에 표시되도록 희소 텐서를 예쁘게 출력하는 도우미 함수를 정의합니다.
def pprint_sparse_tensor(st):
s = "<SparseTensor shape=%s \n values={" % (st.dense_shape.numpy().tolist(),)
for (index, value) in zip(st.indices, st.values):
s += f"\n %s: %s" % (index.numpy().tolist(), value.numpy().tolist())
return s + "}>"
print(pprint_sparse_tensor(st1))
<SparseTensor shape=[3, 10]
values={
[0, 3]: 10
[2, 4]: 20}>
tf.sparse.from_dense를 사용하여 밀집 텐서를 희소 텐서를 구성하고 tf.sparse.to_dense를 사용하여 밀집 텐서로 다시 변환할 수도 있습니다.
st2 = tf.sparse.from_dense([[1, 0, 0, 8], [0, 0, 0, 0], [0, 0, 3, 0]])
print(pprint_sparse_tensor(st2))
<SparseTensor shape=[3, 4]
values={
[0, 0]: 1
[0, 3]: 8
[2, 2]: 3}>
st3 = tf.sparse.to_dense(st2)
print(st3)
tf.Tensor( [[1 0 0 8] [0 0 0 0] [0 0 3 0]], shape=(3, 4), dtype=int32)
희소 텐서 조작하기
tf.sparse 패키지의 유틸리티를 사용하여 희소 텐서를 조작합니다. 밀집 텐서의 산술 조작에 사용할 수 있는 tf.math.add와 같은 연산은 희소 텐서에서 작동하지 않습니다.
동일한 형상의 희소 텐서를 추가하려면 tf.sparse.add를 사용합니다.
st_a = tf.sparse.SparseTensor(indices=[[0, 2], [3, 4]],
values=[31, 2],
dense_shape=[4, 10])
st_b = tf.sparse.SparseTensor(indices=[[0, 2], [7, 0]],
values=[56, 38],
dense_shape=[4, 10])
st_sum = tf.sparse.add(st_a, st_b)
print(pprint_sparse_tensor(st_sum))
<SparseTensor shape=[4, 10]
values={
[0, 2]: 87
[3, 4]: 2
[7, 0]: 38}>
희소 텐서와 밀집 행렬을 곱하려면 tf.sparse.sparse_dense_matmul을 사용합니다.
st_c = tf.sparse.SparseTensor(indices=([0, 1], [1, 0], [1, 1]),
values=[13, 15, 17],
dense_shape=(2,2))
mb = tf.constant([[4], [6]])
product = tf.sparse.sparse_dense_matmul(st_c, mb)
print(product)
tf.Tensor( [[ 78] [162]], shape=(2, 1), dtype=int32)
희소 텐서를 결합하려면 tf.sparse.concat를 사용하고 분리하려면 tf.sparse.slice를 사용합니다.
sparse_pattern_A = tf.sparse.SparseTensor(indices = [[2,4], [3,3], [3,4], [4,3], [4,4], [5,4]],
values = [1,1,1,1,1,1],
dense_shape = [8,5])
sparse_pattern_B = tf.sparse.SparseTensor(indices = [[0,2], [1,1], [1,3], [2,0], [2,4], [2,5], [3,5],
[4,5], [5,0], [5,4], [5,5], [6,1], [6,3], [7,2]],
values = [1,1,1,1,1,1,1,1,1,1,1,1,1,1],
dense_shape = [8,6])
sparse_pattern_C = tf.sparse.SparseTensor(indices = [[3,0], [4,0]],
values = [1,1],
dense_shape = [8,6])
sparse_patterns_list = [sparse_pattern_A, sparse_pattern_B, sparse_pattern_C]
sparse_pattern = tf.sparse.concat(axis=1, sp_inputs=sparse_patterns_list)
print(tf.sparse.to_dense(sparse_pattern))
tf.Tensor( [[0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0] [0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 0] [0 0 0 0 1 1 0 0 0 1 1 0 0 0 0 0 0] [0 0 0 1 1 0 0 0 0 0 1 1 0 0 0 0 0] [0 0 0 1 1 0 0 0 0 0 1 1 0 0 0 0 0] [0 0 0 0 1 1 0 0 0 1 1 0 0 0 0 0 0] [0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 0] [0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0]], shape=(8, 17), dtype=int32)
sparse_slice_A = tf.sparse.slice(sparse_pattern_A, start = [0,0], size = [8,5])
sparse_slice_B = tf.sparse.slice(sparse_pattern_B, start = [0,5], size = [8,6])
sparse_slice_C = tf.sparse.slice(sparse_pattern_C, start = [0,10], size = [8,6])
print(tf.sparse.to_dense(sparse_slice_A))
print(tf.sparse.to_dense(sparse_slice_B))
print(tf.sparse.to_dense(sparse_slice_C))
tf.Tensor( [[0 0 0 0 0] [0 0 0 0 0] [0 0 0 0 1] [0 0 0 1 1] [0 0 0 1 1] [0 0 0 0 1] [0 0 0 0 0] [0 0 0 0 0]], shape=(8, 5), dtype=int32) tf.Tensor( [[0] [0] [1] [1] [1] [1] [0] [0]], shape=(8, 1), dtype=int32) tf.Tensor([], shape=(8, 0), dtype=int32)
TensorFlow 2.4 이상을 사용하는 경우 희소 텐서에서 제로가 아닌 값에 대한 요소별 연산에 tf.sparse.map_values를 사용합니다.
st2_plus_5 = tf.sparse.map_values(tf.add, st2, 5)
print(tf.sparse.to_dense(st2_plus_5))
tf.Tensor( [[ 6 0 0 13] [ 0 0 0 0] [ 0 0 8 0]], shape=(3, 4), dtype=int32)
제로가 아닌 값만 수정되었습니다. 제로 값은 제로로 유지합니다.
마찬가지로 아래의 이전 TensorFlow 버전의 디자인 패턴을 따를 수 있습니다.
st2_plus_5 = tf.sparse.SparseTensor(
st2.indices,
st2.values + 5,
st2.dense_shape)
print(tf.sparse.to_dense(st2_plus_5))
tf.Tensor( [[ 6 0 0 13] [ 0 0 0 0] [ 0 0 8 0]], shape=(3, 4), dtype=int32)
다른 TensorFlow API와 함께 tf.sparse.SparseTensor 사용하기
희소 텐서는 다음 TensorFlow API와 분명하게 작동합니다.
tf.kerastf.datatf.Train.Exampleprotobuftf.functiontf.while_looptf.condtf.identitytf.casttf.printtf.saved_modeltf.io.serialize_sparsetf.io.serialize_many_sparsetf.io.deserialize_many_sparsetf.math.abstf.math.negativetf.math.signtf.math.squaretf.math.sqrttf.math.erftf.math.tanhtf.math.bessel_i0etf.math.bessel_i1e
위의 API 중 일부에 대한 예제가 아래에 있습니다.
tf.keras
tf.keras API의 하위 집합은 값비싼 캐스팅 또는 변환 연산 없이 희소 텐서를 지원합니다. Keras API를 사용하면 희소 텐서를 Keras 모델에 입력으로 전달할 수 있습니다. tf.keras.Input 또는 tf.keras.layers.InputLayer를 호출하는 경우 sparse=True를 설정합니다. Keras 레이어 간에 희소 텐서를 전달할 수 있으며 Keras 모델이 이를 출력으로 반환하도록 할 수도 있습니다. 모델의 tf.keras.layers.Dense 레이어에서 희소 텐서를 사용하면 밀집 텐서를출력합니다.
아래의 예제는 희소 입력을 지원하는 레이어만 사용하는 경우 희소 텐서를 Keras 모델에 입력으로 전달하는 방법을 보여줍니다.
x = tf.keras.Input(shape=(4,), sparse=True)
y = tf.keras.layers.Dense(4)(x)
model = tf.keras.Model(x, y)
sparse_data = tf.sparse.SparseTensor(
indices = [(0,0),(0,1),(0,2),
(4,3),(5,0),(5,1)],
values = [1,1,1,1,1,1],
dense_shape = (6,4)
)
model(sparse_data)
model.predict(sparse_data)
1/1 [==============================] - 0s 85ms/step
array([[-0.57966304, 1.4536092 , -0.06411386, 0.36353213],
[ 0. , 0. , 0. , 0. ],
[ 0. , 0. , 0. , 0. ],
[ 0. , 0. , 0. , 0. ],
[ 0.06421006, -0.63212836, 0.37713164, -0.26001573],
[-0.5782192 , 1.2230618 , -0.05696172, 0.02738976]],
dtype=float32)
tf.data
tf.data API를 사용하면 간단하고 재사용 가능한 조각을 복합 입력 파이프라인으로 빌드할 수 있습니다. 핵심 데이터 구조는 tf.data.Dataset이며, 각 요소는 하나 이상의 구성 요소로 구성된 일련의 요소를 나타냅니다.
희소 텐서로 데이터세트 빌드하기
tf.data.Dataset.from_tensor_slices와 같이 tf.Tensor 또는 NumPy 배열로부터 빌드하는 데 사용하는 방법과 동일한 방법을 사용하여 희소 텐서로부터 데이터세트를 빌드합니다. 이 연산은 데이터의 희소성(또는 희소 성향)을 보존합니다.
dataset = tf.data.Dataset.from_tensor_slices(sparse_data)
for element in dataset:
print(pprint_sparse_tensor(element))
<SparseTensor shape=[4]
values={
[0]: 1
[1]: 1
[2]: 1}>
<SparseTensor shape=[4]
values={}>
<SparseTensor shape=[4]
values={}>
<SparseTensor shape=[4]
values={}>
<SparseTensor shape=[4]
values={
[3]: 1}>
<SparseTensor shape=[4]
values={
[0]: 1
[1]: 1}>
희소 텐서를 사용하여 데이터세트 배치 및 배치 해제하기
Dataset.batch 및 Dataset.unbatch 메서드를 각각 사용하여 희소 텐서로 데이터세트를 배치 처리(연속 요소를 단일 요소로 결합)하고 배치 처리를 해제할 수 있습니다.
batched_dataset = dataset.batch(2)
for element in batched_dataset:
print (pprint_sparse_tensor(element))
<SparseTensor shape=[2, 4]
values={
[0, 0]: 1
[0, 1]: 1
[0, 2]: 1}>
<SparseTensor shape=[2, 4]
values={}>
<SparseTensor shape=[2, 4]
values={
[0, 3]: 1
[1, 0]: 1
[1, 1]: 1}>
unbatched_dataset = batched_dataset.unbatch()
for element in unbatched_dataset:
print (pprint_sparse_tensor(element))
<SparseTensor shape=[4]
values={
[0]: 1
[1]: 1
[2]: 1}>
<SparseTensor shape=[4]
values={}>
<SparseTensor shape=[4]
values={}>
<SparseTensor shape=[4]
values={}>
<SparseTensor shape=[4]
values={
[3]: 1}>
<SparseTensor shape=[4]
values={
[0]: 1
[1]: 1}>
또한 tf.data.experimental.dense_to_sparse_batch를 사용하여 다양한 형상의 데이터세트 요소를 희소 텐서로 배치 처리할 수도 있습니다.
희소 텐서를 사용하여 데이터세트 변환하기
Dataset.map을 사용하여 데이터세트에서 희소 텐서를 변환하고 생성합니다.
transform_dataset = dataset.map(lambda x: x*2)
for i in transform_dataset:
print(pprint_sparse_tensor(i))
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow/python/autograph/pyct/static_analysis/liveness.py:83: Analyzer.lamba_check (from tensorflow.python.autograph.pyct.static_analysis.liveness) is deprecated and will be removed after 2023-09-23.
Instructions for updating:
Lambda fuctions will be no more assumed to be used in the statement where they are used, or at least in the same block. https://github.com/tensorflow/tensorflow/issues/56089
<SparseTensor shape=[4]
values={
[0]: 2
[1]: 2
[2]: 2}>
<SparseTensor shape=[4]
values={}>
<SparseTensor shape=[4]
values={}>
<SparseTensor shape=[4]
values={}>
<SparseTensor shape=[4]
values={
[3]: 2}>
<SparseTensor shape=[4]
values={
[0]: 2
[1]: 2}>
tf.train.Example
tf.train.Example은 TensorFlow 데이터용 표준 protobuf 인코딩입니다. tf.train.Example과 함께 희소 텐서를 사용할 때 다음을 수행할 수 있습니다.
tf.io.VarLenFeature를 사용하여 가변 길이 데이터를tf.sparse.SparseTensor로 읽습니다. 다만 대신tf.io.RaggedFeature를 사용하는 것이 좋습니다.indices,values,dense_shape를 저장하기 위해 3개의 개별 특성 키를 사용하는tf.io.SparseFeature를 사용하여 임의의 희소 데이터를tf.sparse.SparseTensor로 읽습니다.
tf.function
tf.function 데코레이터는 Python 함수용 TensorFlow 그래프를 미리 계산하여 TensorFlow 코드의 성능을 크게 향상시킬 수 있습니다. 희소 텐서는 tf.function 및 콘크리트 함수 모두에서 분명하게 작동합니다.
@tf.function
def f(x,y):
return tf.sparse.sparse_dense_matmul(x,y)
a = tf.sparse.SparseTensor(indices=[[0, 3], [2, 4]],
values=[15, 25],
dense_shape=[3, 10])
b = tf.sparse.to_dense(tf.sparse.transpose(a))
c = f(a,b)
print(c)
tf.Tensor( [[225 0 0] [ 0 0 0] [ 0 0 625]], shape=(3, 3), dtype=int32)
제로(0) 값에서 누락 값 구분하기
tf.sparse.SparseTensor에 대한 대부분의 연산은 누락 값과 명시적 제로(0) 값을 동일하게 취급합니다. 이것은 의도적으로 설계된 것입니다. tf.sparse.SparseTensor는 밀집 텐서처럼 작동하도록 되어 있습니다.
다만 누락 값에서 제로 값을 구분하는 것이 유용할 수 있는 몇 가지 경우가 있습니다. 특히, 이것은 훈련 데이터에서 누락/알 수 없는 데이터를 인코딩하는 한 가지 방법을 허용합니다. 예를 들어, 일부 누락 점수와 함께 점수의 텐서(-Inf에서 +Inf까지의 부동 소수점 값을 가질 수 있음)가 있는 사용 사례를 고려할 수 있습니다. 명시적 제로는 알려진 제로 점수이지만 암시적 제로 값이 실제로 제로가 아니라 누락 데이터를 나타내는 희소 텐서를 사용하여 이 텐서를 인코딩할 수 있습니다.
참고: 이는 일반적으로 tf.sparse.SparseTensor의 의도된 용도가 아닙니다. 예를 들어 알려진/알 수 없는 값의 위치를 식별하는 별도의 마스크 텐서를 사용하는 것과 같이 이를 인코딩하기 위한 다른 기술도 고려하고 싶어할 수 있습니다. 그러나 대부분의 희소 연산은 명시적 및 암시적 제로 값을 동일하게 취급하므로 이 접근 방식을 사용하는 동안 주의해야 합니다.
tf.sparse.reduce_max와 같은 일부 연산은 누락 값을 제로처럼 취급하지 않습니다. 예를 들어 아래의 코드 블록을 실행할 때 예상되는 출력은 0입니다. 그러나 이 예외로 인해 출력이 -3이 됩니다.
print(tf.sparse.reduce_max(tf.sparse.from_dense([-5, 0, -3])))
tf.Tensor(-3, shape=(), dtype=int32)
반대로 tf.math.reduce_max를 밀집 텐서에 적용하면 예상대로 출력이 0이 됩니다.
print(tf.math.reduce_max([-5, 0, -3]))
tf.Tensor(0, shape=(), dtype=int32)
추가 자료 및 리소스
- 텐서에 대한 자세한 내용은 텐서 가이드를 참고하세요.
- 균일하지 않은 데이터로 작업할 수 있도록 하는 텐서 유형인 비정형 텐서로 작업하는 방법에 대해 알아보려면 비정형 텐서 가이드를 읽어 보세요.
tf.Example데이터 디코더에서 희소 텐서를 사용하는 TensorFlow Model Garden의 이 객체 감지 모델을 확인하세요.