| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub | |
بررسی اجمالی
یکی از بزرگترین چالش ها در تشخیص خودکار گفتار، آماده سازی و تقویت داده های صوتی است. تجزیه و تحلیل داده های صوتی می تواند در حوزه زمان یا فرکانس باشد، که در مقایسه با سایر منابع داده مانند تصاویر، پیچیده تر می کند.
به عنوان بخشی از اکوسیستم TensorFlow، به tensorflow-io بسته فراهم کاملا چند API های مربوط به صوتی مفید است که کمک می کند تا کاهش آماده سازی و تقویت داده های صوتی.
برپایی
بسته های مورد نیاز را نصب کنید و زمان اجرا را مجددا راه اندازی کنید
pip install tensorflow-io
استفاده
یک فایل صوتی را بخوانید
در TensorFlow IO، کلاس tfio.audio.AudioIOTensor اجازه می دهد تا شما را به خواندن یک فایل صوتی را به یک تنبل لود IOTensor :
import tensorflow as tf
import tensorflow_io as tfio
audio = tfio.audio.AudioIOTensor('gs://cloud-samples-tests/speech/brooklyn.flac')
print(audio)
<AudioIOTensor: shape=[28979 1], dtype=<dtype: 'int16'>, rate=16000>
در مثال بالا، فایل FLAC brooklyn.flac از یک کلیپ صوتی عمومی در دسترس است گوگل ابر .
سیستم محاکم دولتی آدرس gs://cloud-samples-tests/speech/brooklyn.flac به طور مستقیم استفاده می شود زیرا GCS یک سیستم فایل پشتیبانی در TensorFlow است. علاوه بر Flac فرمت، WAV ، Ogg ، MP3 ، و MP4A نیز با حمایت AudioIOTensor با تشخیص فرمت فایل به صورت خودکار.
AudioIOTensor تنبل لود شده به طوری که تنها شکل، dtype است، و نرخ نمونه در ابتدا نشان داده شده است. شکل AudioIOTensor به عنوان نمایندگی [samples, channels] ، که به معنی کلیپ صوتی شما لود تک کانال با 28979 نمونه ها در int16 .
محتوای فایل های صوتی تنها، یا با تبدیل خواهد خوانده شود به عنوان مورد نیاز AudioIOTensor به Tensor از طریق to_tensor() ، و یا هر چند برش. برش دادن به ویژه زمانی مفید است که فقط به بخش کوچکی از یک کلیپ صوتی بزرگ نیاز باشد:
audio_slice = audio[100:]
# remove last dimension
audio_tensor = tf.squeeze(audio_slice, axis=[-1])
print(audio_tensor)
tf.Tensor([16 39 66 ... 56 81 83], shape=(28879,), dtype=int16)
صدا را می توان از طریق:
from IPython.display import Audio
Audio(audio_tensor.numpy(), rate=audio.rate.numpy())
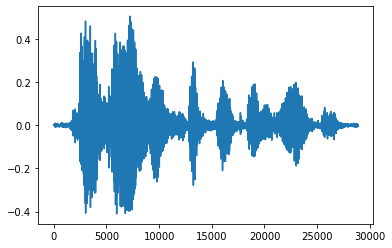
تبدیل تانسور به اعداد شناور و نمایش کلیپ صوتی در نمودار راحت تر است:
import matplotlib.pyplot as plt
tensor = tf.cast(audio_tensor, tf.float32) / 32768.0
plt.figure()
plt.plot(tensor.numpy())
[<matplotlib.lines.Line2D at 0x7fbdd3eb72d0>]
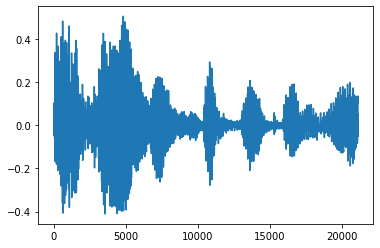
سر و صدا را کم کنید
گاهی اوقات آن را حس می کند به قدم زدن سر و صدا از صدا، که می تواند از طریق API انجام tfio.audio.trim . بازگشت از API یک جفت است [start, stop] موقعیت segement:
position = tfio.audio.trim(tensor, axis=0, epsilon=0.1)
print(position)
start = position[0]
stop = position[1]
print(start, stop)
processed = tensor[start:stop]
plt.figure()
plt.plot(processed.numpy())
tf.Tensor([ 2398 23546], shape=(2,), dtype=int64) tf.Tensor(2398, shape=(), dtype=int64) tf.Tensor(23546, shape=(), dtype=int64) [<matplotlib.lines.Line2D at 0x7fbdd3dce9d0>]
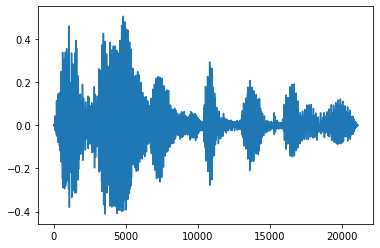
محو شدن و محو شدن
یکی از تکنیک های مفید مهندسی صدا، محو شدن است که به تدریج سیگنال های صوتی را افزایش یا کاهش می دهد. این را می توان از طریق انجام tfio.audio.fade . tfio.audio.fade از اشکال مختلف از محو مانند linear ، logarithmic ، و یا exponential :
fade = tfio.audio.fade(
processed, fade_in=1000, fade_out=2000, mode="logarithmic")
plt.figure()
plt.plot(fade.numpy())
[<matplotlib.lines.Line2D at 0x7fbdd00d9b10>]
طیف نگار
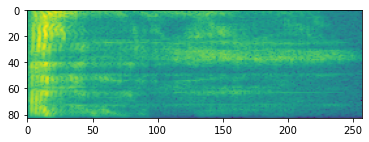
پردازش صوتی پیشرفته اغلب بر روی تغییرات فرکانس در طول زمان کار می کند. در tensorflow-io یک شکل موج را می توان به طیف از طریق تبدیل tfio.audio.spectrogram :
# Convert to spectrogram
spectrogram = tfio.audio.spectrogram(
fade, nfft=512, window=512, stride=256)
plt.figure()
plt.imshow(tf.math.log(spectrogram).numpy())
<matplotlib.image.AxesImage at 0x7fbdd005add0>
تبدیل اضافی به مقیاس های مختلف نیز امکان پذیر است:
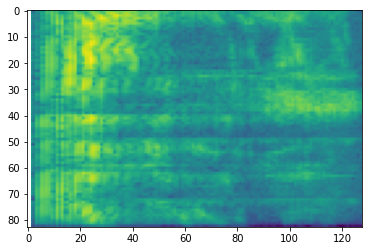
# Convert to mel-spectrogram
mel_spectrogram = tfio.audio.melscale(
spectrogram, rate=16000, mels=128, fmin=0, fmax=8000)
plt.figure()
plt.imshow(tf.math.log(mel_spectrogram).numpy())
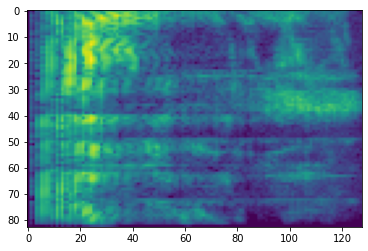
# Convert to db scale mel-spectrogram
dbscale_mel_spectrogram = tfio.audio.dbscale(
mel_spectrogram, top_db=80)
plt.figure()
plt.imshow(dbscale_mel_spectrogram.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb20bd10>
SpecAugment
در علاوه بر موارد فوق آماده سازی داده ها و تقویت رابط های برنامه کاربردی ذکر شد، tensorflow-io بسته نیز فراهم می کند تقویت طیف نگاره پیشرفته، به ویژه فرکانس و زمان پوشش در بحث SpecAugment: (پارک و همکاران، 2019) روش ساده داده تقویت برای تشخیص گفتار خودکار .
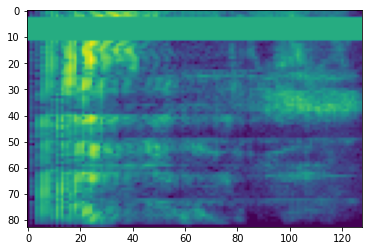
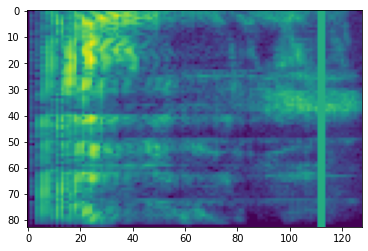
پوشش فرکانس
در پوشش فرکانس، کانال های فرکانس [f0, f0 + f) می پوشانده که در آن f از یک توزیع یکنواخت از انتخاب 0 به ماسک فرکانس پارامتر F و f0 از انتخاب (0, ν − f) که در آن ν تعداد است کانال های فرکانس
# Freq masking
freq_mask = tfio.audio.freq_mask(dbscale_mel_spectrogram, param=10)
plt.figure()
plt.imshow(freq_mask.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb155cd0>
پوشش زمان
در زمان پوشش، t مراحل متوالی [t0, t0 + t) پوشانده می شوند که در آن t از یک توزیع یکنواخت از انتخاب 0 به ماسک زمان پارامتر T و t0 از انتخاب [0, τ − t) که در آن τ است مراحل زمانی
# Time masking
time_mask = tfio.audio.time_mask(dbscale_mel_spectrogram, param=10)
plt.figure()
plt.imshow(time_mask.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb0d9bd0>