
| | |  Wyświetl źródło na GitHub Wyświetl źródło na GitHub | |
Ten przewodnik wykorzystuje uczenie maszynowe do kategoryzowania kwiatów tęczówki według gatunków. Wykorzystuje TensorFlow do:
- Zbudować model,
- Wytrenuj ten model na przykładowych danych i
- Użyj modelu do przewidywania nieznanych danych.
Programowanie TensorFlow
W tym przewodniku wykorzystano następujące wysokopoziomowe koncepcje TensorFlow:
- Korzystaj z domyślnego środowiska programistycznego z chęcią wykonywania egzekucji TensorFlow,
- Importuj dane za pomocą Datasets API ,
- Twórz modele i warstwy za pomocą interfejsu API Keras firmy TensorFlow.
Ten samouczek ma strukturę podobną do wielu programów TensorFlow:
- Zaimportuj i przeanalizuj zbiór danych.
- Wybierz typ modelu.
- Trenuj modelkę.
- Oceń skuteczność modelu.
- Użyj wytrenowanego modelu, aby dokonać prognoz.
Program instalacyjny
Konfiguruj importy
Importuj TensorFlow i inne wymagane moduły Pythona. Domyślnie TensorFlow używa szybkiego wykonania do natychmiastowej oceny operacji, zwracając konkretne wartości zamiast tworzenia wykresu obliczeniowego, który jest wykonywany później. Jeśli jesteś przyzwyczajony do REPL lub interaktywnej konsoli python , wydaje się to znajome.
import os
import matplotlib.pyplot as plt
import tensorflow as tf
print("TensorFlow version: {}".format(tf.__version__))
print("Eager execution: {}".format(tf.executing_eagerly()))
TensorFlow version: 2.8.0-rc1 Eager execution: True
Problem klasyfikacji tęczówki
Wyobraź sobie, że jesteś botanikiem szukającym zautomatyzowanego sposobu kategoryzowania każdego znalezionego kwiatu tęczówki. Uczenie maszynowe zapewnia wiele algorytmów do statystycznej klasyfikacji kwiatów. Na przykład zaawansowany program do uczenia maszynowego może klasyfikować kwiaty na podstawie zdjęć. Nasze ambicje są skromniejsze — zamierzamy sklasyfikować kwiaty irysa na podstawie pomiarów długości i szerokości ich działek kielicha i płatków .
Rodzaj Iris obejmuje około 300 gatunków, ale nasz program zaklasyfikuje tylko następujące trzy:
- Irys setosa
- Iris virginica
- Iris versicolor
 |
| Rysunek 1. Iris setosa (autorstwa Radomil , CC BY-SA 3.0), Iris versicolor , (autorstwa Dlanglois , CC BY-SA 3.0) i Iris virginica (autorstwa Frank Mayfield , CC BY-SA 2.0). |
Na szczęście ktoś już stworzył zbiór danych 120 kwiatów tęczówki z pomiarami działek i płatków. Jest to klasyczny zbiór danych, który jest popularny w przypadku problemów z klasyfikacją uczenia maszynowego dla początkujących.
Importuj i analizuj treningowy zestaw danych
Pobierz plik zestawu danych i przekonwertuj go na strukturę, która może być używana przez ten program w języku Python.
Pobierz zbiór danych
Pobierz plik treningowego zestawu danych za pomocą funkcji tf.keras.utils.get_file . Zwraca ścieżkę do pobranego pliku:
train_dataset_url = "https://storage.googleapis.com/download.tensorflow.org/data/iris_training.csv"
train_dataset_fp = tf.keras.utils.get_file(fname=os.path.basename(train_dataset_url),
origin=train_dataset_url)
print("Local copy of the dataset file: {}".format(train_dataset_fp))
Local copy of the dataset file: /home/kbuilder/.keras/datasets/iris_training.csv
Sprawdź dane
Ten zestaw danych, iris_training.csv , to zwykły plik tekstowy, który przechowuje dane tabelaryczne sformatowane jako wartości rozdzielane przecinkami (CSV). Użyj polecenia head -n5 , aby zerknąć na pierwsze pięć wpisów:
head -n5 {train_dataset_fp}
120,4,setosa,versicolor,virginica 6.4,2.8,5.6,2.2,2 5.0,2.3,3.3,1.0,1 4.9,2.5,4.5,1.7,2 4.9,3.1,1.5,0.1,0
Z tego widoku zestawu danych zwróć uwagę na następujące kwestie:
- Pierwsza linia to nagłówek zawierający informacje o zestawie danych:
- Jest łącznie 120 przykładów. Każdy przykład ma cztery cechy i jedną z trzech możliwych nazw etykiet.
- Kolejne wiersze to rekordy danych, po jednym przykładzie w wierszu, gdzie:
- Pierwsze cztery pola to cechy : są to cechy charakterystyczne przykładu. W tym przypadku pola zawierają liczby zmiennoprzecinkowe reprezentujące pomiary kwiatów.
- Ostatnia kolumna to label : jest to wartość, którą chcemy przewidzieć. W przypadku tego zestawu danych jest to liczba całkowita 0, 1 lub 2, która odpowiada nazwie kwiatu.
Napiszmy to w kodzie:
# column order in CSV file
column_names = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species']
feature_names = column_names[:-1]
label_name = column_names[-1]
print("Features: {}".format(feature_names))
print("Label: {}".format(label_name))
Features: ['sepal_length', 'sepal_width', 'petal_length', 'petal_width'] Label: species
Każda etykieta jest powiązana z nazwą ciągu (na przykład „setosa”), ale uczenie maszynowe zazwyczaj opiera się na wartościach liczbowych. Numery etykiet są mapowane do nazwanej reprezentacji, takiej jak:
-
0: Irys setosa -
1: Iris versicolor -
2: Iris virginica
Aby uzyskać więcej informacji o funkcjach i etykietach, zobacz sekcję Terminologia ML w kursie awarii uczenia maszynowego .
class_names = ['Iris setosa', 'Iris versicolor', 'Iris virginica']
Utwórz tf.data.Dataset
Dataset API TensorFlow obsługuje wiele typowych przypadków ładowania danych do modelu. Jest to interfejs API wysokiego poziomu do odczytywania danych i przekształcania ich w formularz używany do szkolenia.
Ponieważ zbiór danych jest plikiem tekstowym w formacie CSV, użyj funkcji tf.data.experimental.make_csv_dataset , aby przeanalizować dane do odpowiedniego formatu. Ponieważ ta funkcja generuje dane dla modeli szkoleniowych, domyślnym zachowaniem jest tasowanie danych ( shuffle=True, shuffle_buffer_size=10000 ) i powtarzanie zestawu danych w nieskończoność ( num_epochs=None ). Ustawiamy również parametr batch_size :
batch_size = 32
train_dataset = tf.data.experimental.make_csv_dataset(
train_dataset_fp,
batch_size,
column_names=column_names,
label_name=label_name,
num_epochs=1)
Funkcja make_csv_dataset zwraca zestaw tf.data.Dataset się z par (features, label) , gdzie features to słownik: {'feature_name': value}
Te obiekty Dataset są iterowalne. Spójrzmy na zestaw funkcji:
features, labels = next(iter(train_dataset))
print(features)
OrderedDict([('sepal_length', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([5. , 7.4, 6. , 7.2, 5.9, 5.8, 5. , 5. , 7.7, 5.7, 6.3, 5.8, 5. ,
4.8, 6.6, 6.3, 5.4, 6.9, 4.8, 6.6, 5.8, 7.7, 6.7, 7.6, 5.5, 6.4,
5.6, 6.4, 4.4, 4.5, 6.5, 6.3], dtype=float32)>), ('sepal_width', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([3.5, 2.8, 2.7, 3.2, 3. , 2.6, 2. , 3.4, 3. , 2.8, 2.3, 2.7, 3.6,
3.1, 2.9, 3.3, 3. , 3.1, 3. , 3. , 4. , 2.6, 3. , 3. , 2.4, 2.7,
2.7, 2.8, 3. , 2.3, 2.8, 2.5], dtype=float32)>), ('petal_length', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([1.6, 6.1, 5.1, 6. , 5.1, 4. , 3.5, 1.6, 6.1, 4.5, 4.4, 5.1, 1.4,
1.6, 4.6, 4.7, 4.5, 5.1, 1.4, 4.4, 1.2, 6.9, 5. , 6.6, 3.7, 5.3,
4.2, 5.6, 1.3, 1.3, 4.6, 5. ], dtype=float32)>), ('petal_width', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([0.6, 1.9, 1.6, 1.8, 1.8, 1.2, 1. , 0.4, 2.3, 1.3, 1.3, 1.9, 0.2,
0.2, 1.3, 1.6, 1.5, 2.3, 0.3, 1.4, 0.2, 2.3, 1.7, 2.1, 1. , 1.9,
1.3, 2.1, 0.2, 0.3, 1.5, 1.9], dtype=float32)>)])
Zwróć uwagę, że podobne funkcje są grupowane lub grupowane . Pola każdego przykładowego wiersza są dołączane do odpowiedniej tablicy elementów. Zmień batch_size , aby ustawić liczbę przykładów przechowywanych w tych tablicach funkcji.
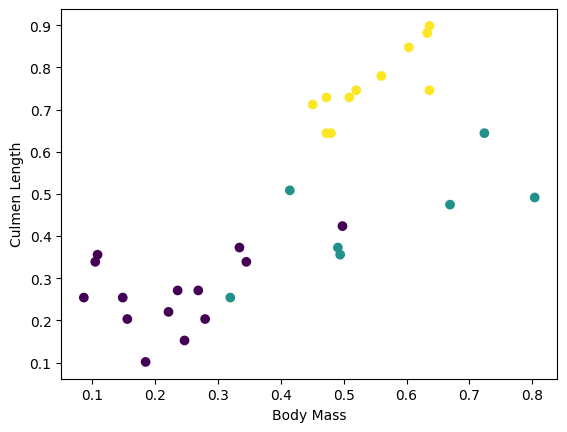
Możesz zacząć widzieć niektóre klastry, wykreślając kilka funkcji z partii:
plt.scatter(features['petal_length'],
features['sepal_length'],
c=labels,
cmap='viridis')
plt.xlabel("Petal length")
plt.ylabel("Sepal length")
plt.show()
Aby uprościć etap budowania modelu, utwórz funkcję, która przepakuje słownik funkcji do pojedynczej tablicy o kształcie: (batch_size, num_features) .
Ta funkcja wykorzystuje metodę tf.stack , która pobiera wartości z listy tensorów i tworzy połączony tensor o określonym wymiarze:
def pack_features_vector(features, labels):
"""Pack the features into a single array."""
features = tf.stack(list(features.values()), axis=1)
return features, labels
Następnie użyj metody tf.data.Dataset#map , aby spakować features każdej pary (features,label) do uczącego zbioru danych:
train_dataset = train_dataset.map(pack_features_vector)
Element features Dataset to teraz tablice z shape (batch_size, num_features) . Spójrzmy na kilka pierwszych przykładów:
features, labels = next(iter(train_dataset))
print(features[:5])
tf.Tensor( [[4.9 3. 1.4 0.2] [6.1 3. 4.9 1.8] [6.1 2.6 5.6 1.4] [6.9 3.2 5.7 2.3] [6.7 3.1 4.4 1.4]], shape=(5, 4), dtype=float32)
Wybierz typ modelu
Dlaczego modelować?
Model to relacja między elementami a etykietą. W przypadku problemu klasyfikacji tęczówki model określa zależność między pomiarami działek i płatków a przewidywanymi gatunkami tęczówki. Niektóre proste modele można opisać za pomocą kilku linii algebry, ale złożone modele uczenia maszynowego mają dużą liczbę parametrów, które trudno podsumować.
Czy możesz określić związek między czterema cechami a gatunkiem tęczówki bez użycia uczenia maszynowego? To znaczy, czy możesz użyć tradycyjnych technik programowania (na przykład wielu instrukcji warunkowych) do stworzenia modelu? Być może — jeśli przeanalizujesz zbiór danych wystarczająco długo, aby określić relacje między pomiarami płatków i działek w przypadku konkretnego gatunku. A to staje się trudne – może niemożliwe – w przypadku bardziej skomplikowanych zbiorów danych. Dobre podejście do uczenia maszynowego określa model za Ciebie . Jeśli wprowadzisz wystarczającą liczbę reprezentatywnych przykładów do odpowiedniego typu modelu uczenia maszynowego, program określi zależności za Ciebie.
Wybierz model
Musimy wybrać rodzaj modelu do trenowania. Istnieje wiele rodzajów modeli, a wybór dobrego wymaga doświadczenia. Ten samouczek wykorzystuje sieć neuronową do rozwiązania problemu klasyfikacji tęczówki. Sieci neuronowe mogą znaleźć złożone relacje między cechami a etykietą. Jest to wykres o wysokiej strukturze, zorganizowany w jedną lub więcej ukrytych warstw . Każda warstwa ukryta składa się z jednego lub więcej neuronów . Istnieje kilka kategorii sieci neuronowych, a ten program używa gęstej lub w pełni połączonej sieci neuronowej : neurony w jednej warstwie otrzymują połączenia wejściowe od każdego neuronu w poprzedniej warstwie. Na przykład rysunek 2 ilustruje gęstą sieć neuronową składającą się z warstwy wejściowej, dwóch warstw ukrytych i warstwy wyjściowej:
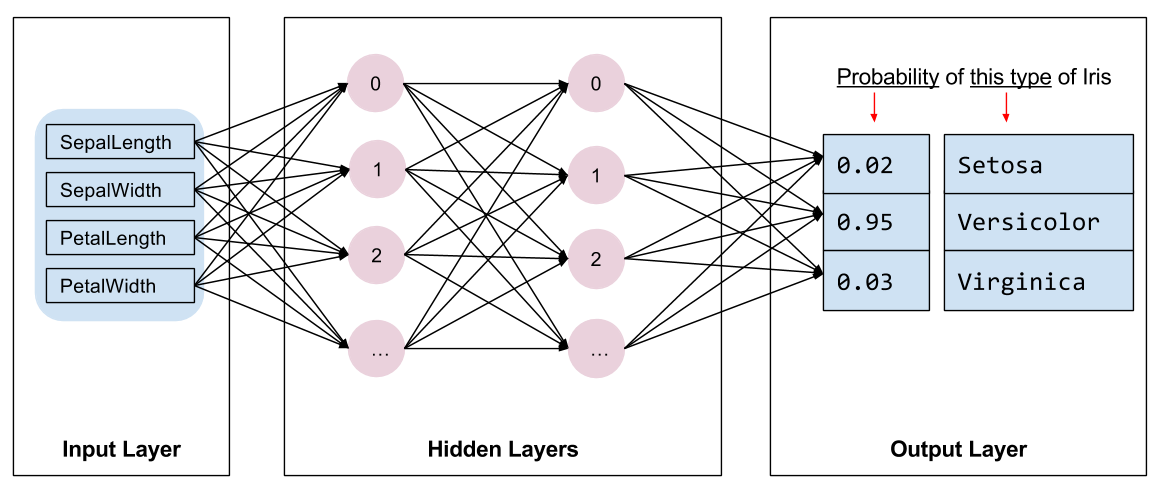 |
| Rysunek 2. Sieć neuronowa z funkcjami, ukrytymi warstwami i predykcjami. |
Kiedy model z ryciny 2 jest wytrenowany i zasilany nieoznakowanym przykładem, daje trzy przewidywania: prawdopodobieństwo, że ten kwiat jest danym gatunkiem tęczówki. To przewidywanie nazywa się wnioskowaniem . W tym przykładzie suma przewidywań wyjściowych wynosi 1,0. Na Ryc. 2 ta prognoza przedstawia się następująco: 0.02 dla Iris setosa , 0.95 dla Iris versicolor i 0.03 dla Iris virginica . Oznacza to, że model przewiduje — z 95% prawdopodobieństwem — że nieoznakowany przykładowy kwiat to Iris versicolor .
Stwórz model za pomocą Keras
TensorFlow tf.keras API jest preferowanym sposobem tworzenia modeli i warstw. Ułatwia to budowanie modeli i eksperymentowanie, podczas gdy Keras radzi sobie ze złożonością łączenia wszystkiego razem.
Model tf.keras.Sequential to liniowy stos warstw. Jego konstruktor pobiera listę instancji warstwy, w tym przypadku dwie warstwy tf.keras.layers.Dense z 10 węzłami każda oraz warstwę wyjściową z 3 węzłami reprezentującymi nasze przewidywania etykiet. Parametr input_shape pierwszej warstwy odpowiada liczbie obiektów ze zbioru danych i jest wymagany:
model = tf.keras.Sequential([
tf.keras.layers.Dense(10, activation=tf.nn.relu, input_shape=(4,)), # input shape required
tf.keras.layers.Dense(10, activation=tf.nn.relu),
tf.keras.layers.Dense(3)
])
Funkcja aktywacji określa wyjściowy kształt każdego węzła w warstwie. Te nieliniowości są ważne — bez nich model byłby równoważny pojedynczej warstwie. Istnieje wiele tf.keras.activations . , ale ReLU jest wspólne dla warstw ukrytych.
Idealna liczba ukrytych warstw i neuronów zależy od problemu i zestawu danych. Podobnie jak w przypadku wielu aspektów uczenia maszynowego, wybranie najlepszego kształtu sieci neuronowej wymaga połączenia wiedzy i eksperymentów. Z reguły zwiększenie liczby ukrytych warstw i neuronów zazwyczaj tworzy bardziej wydajny model, który do efektywnego trenowania wymaga większej ilości danych.
Korzystanie z modelu
Rzućmy okiem na to, co ten model robi z zestawem funkcji:
predictions = model(features)
predictions[:5]
<tf.Tensor: shape=(5, 3), dtype=float32, numpy=
array([[-4.0874639e+00, 1.5199981e-03, -9.9991310e-01],
[-5.3246369e+00, -1.8366380e-01, -1.3161827e+00],
[-5.1154275e+00, -2.8129923e-01, -1.3305402e+00],
[-6.0694785e+00, -2.1251860e-01, -1.5091233e+00],
[-5.6730523e+00, -1.4321266e-01, -1.4437559e+00]], dtype=float32)>
Tutaj każdy przykład zwraca logit dla każdej klasy.
Aby przekonwertować te logity na prawdopodobieństwo dla każdej klasy, użyj funkcji softmax :
tf.nn.softmax(predictions[:5])
<tf.Tensor: shape=(5, 3), dtype=float32, numpy=
array([[0.01210616, 0.7224865 , 0.26540732],
[0.00440638, 0.75297093, 0.24262273],
[0.00585618, 0.7362918 , 0.25785193],
[0.00224076, 0.7835035 , 0.21425581],
[0.00310779, 0.7834839 , 0.21340834]], dtype=float32)>
Biorąc tf.argmax dla różnych klas, otrzymujemy przewidywany indeks klasy. Ale model nie został jeszcze przeszkolony, więc nie są to dobre prognozy:
print("Prediction: {}".format(tf.argmax(predictions, axis=1)))
print(" Labels: {}".format(labels))
Prediction: [1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1]
Labels: [0 2 2 2 1 1 0 1 1 2 2 1 0 2 2 2 1 0 2 2 1 0 2 1 2 0 1 1 2 2 1 2]
Trenuj modelkę
Uczenie to etap uczenia maszynowego, na którym model jest stopniowo optymalizowany lub model uczy się zestawu danych. Celem jest uzyskanie wystarczającej wiedzy o strukturze treningowego zestawu danych, aby móc przewidywać niewidoczne dane. Jeśli dowiesz się zbyt wiele o uczącym zbiorze danych, prognozy działają tylko dla danych, które widział i nie można ich uogólniać. Ten problem nazywa się overfitting — to tak, jakby zapamiętywać odpowiedzi zamiast rozumieć, jak rozwiązać problem.
Problem klasyfikacji tęczówki jest przykładem nadzorowanego uczenia maszynowego : model jest szkolony na podstawie przykładów zawierających etykiety. W przypadku nienadzorowanego uczenia maszynowego przykłady nie zawierają etykiet. Zamiast tego model zazwyczaj znajduje wzorce wśród cech.
Zdefiniuj funkcję straty i gradientu
Zarówno szkolenie, jak i etapy oceny wymagają obliczenia utraty modelu. Mierzy to, jak daleko prognozy modelu są od pożądanej etykiety, innymi słowy, jak źle działa model. Chcemy zminimalizować lub zoptymalizować tę wartość.
Nasz model obliczy jego stratę za pomocą funkcji tf.keras.losses.SparseCategoricalCrossentropy , która pobiera przewidywania prawdopodobieństwa klasy modelu i żądaną etykietę oraz zwraca średnią stratę w przykładach.
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
def loss(model, x, y, training):
# training=training is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
y_ = model(x, training=training)
return loss_object(y_true=y, y_pred=y_)
l = loss(model, features, labels, training=False)
print("Loss test: {}".format(l))
Loss test: 1.6059828996658325
Użyj kontekstu tf.GradientTape , aby obliczyć gradienty używane do optymalizacji modelu:
def grad(model, inputs, targets):
with tf.GradientTape() as tape:
loss_value = loss(model, inputs, targets, training=True)
return loss_value, tape.gradient(loss_value, model.trainable_variables)
Utwórz optymalizator
Optymalizator stosuje obliczone gradienty do zmiennych modelu, aby zminimalizować funkcję loss . Możesz myśleć o funkcji straty jako o zakrzywionej powierzchni (patrz rysunek 3), a my chcemy znaleźć jej najniższy punkt, spacerując. Gradienty wskazują w kierunku najbardziej stromego podjazdu, więc pojedziemy w przeciwną stronę i zejdziemy w dół wzgórza. Iteracyjnie obliczając stratę i gradient dla każdej partii, dostosujemy model podczas uczenia. Stopniowo model znajdzie najlepszą kombinację wag i odchylenia, aby zminimalizować straty. A im mniejsza strata, tym lepsze prognozy modelu.
 |
| Rysunek 3. Algorytmy optymalizacji wizualizowane w czasie w przestrzeni 3D. (Źródło: Stanford class CS231n , Licencja MIT, Źródło: Alec Radford ) |
TensorFlow oferuje wiele algorytmów optymalizacji dostępnych do szkolenia. Model ten wykorzystuje tf.keras.optimizers.SGD , który implementuje algorytm stochastycznego gradientu (SGD). learning_rate określa rozmiar kroku, jaki należy wykonać dla każdej iteracji w dół wzgórza. Jest to hiperparametr , który często będziesz dostosowywać, aby osiągnąć lepsze wyniki.
Ustawmy optymalizator:
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
Użyjemy tego do obliczenia pojedynczego kroku optymalizacji:
loss_value, grads = grad(model, features, labels)
print("Step: {}, Initial Loss: {}".format(optimizer.iterations.numpy(),
loss_value.numpy()))
optimizer.apply_gradients(zip(grads, model.trainable_variables))
print("Step: {}, Loss: {}".format(optimizer.iterations.numpy(),
loss(model, features, labels, training=True).numpy()))
Step: 0, Initial Loss: 1.6059828996658325 Step: 1, Loss: 1.3759253025054932
Pętla treningowa
Po założeniu wszystkich elementów model jest gotowy do treningu! Pętla szkoleniowa przesyła przykłady zestawu danych do modelu, aby pomóc mu w tworzeniu lepszych prognoz. Poniższy blok kodu konfiguruje te kroki szkoleniowe:
- Powtórz każdą epokę . Epoka to jedno przejście przez zbiór danych.
- W obrębie epoki przeprowadź iterację każdego przykładu w uczącym zbiorze
Dataset, chwytając jego cechy (x) i etykietę (y). - Korzystając z funkcji przykładu, dokonaj prognozy i porównaj ją z etykietą. Zmierz niedokładność prognozy i użyj jej do obliczenia strat i gradientów modelu.
- Użyj
optimizer, aby zaktualizować zmienne modelu. - Śledź niektóre statystyki do wizualizacji.
- Powtórz dla każdej epoki.
Zmienna num_epochs to liczba powtórzeń pętli w zbiorze danych. Wbrew intuicji, dłuższe trenowanie modelu nie gwarantuje lepszego modelu. num_epochs to hiperparametr , który możesz dostroić. Wybór odpowiedniej liczby zwykle wymaga zarówno doświadczenia, jak i eksperymentowania:
## Note: Rerunning this cell uses the same model variables
# Keep results for plotting
train_loss_results = []
train_accuracy_results = []
num_epochs = 201
for epoch in range(num_epochs):
epoch_loss_avg = tf.keras.metrics.Mean()
epoch_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()
# Training loop - using batches of 32
for x, y in train_dataset:
# Optimize the model
loss_value, grads = grad(model, x, y)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
# Track progress
epoch_loss_avg.update_state(loss_value) # Add current batch loss
# Compare predicted label to actual label
# training=True is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
epoch_accuracy.update_state(y, model(x, training=True))
# End epoch
train_loss_results.append(epoch_loss_avg.result())
train_accuracy_results.append(epoch_accuracy.result())
if epoch % 50 == 0:
print("Epoch {:03d}: Loss: {:.3f}, Accuracy: {:.3%}".format(epoch,
epoch_loss_avg.result(),
epoch_accuracy.result()))
Epoch 000: Loss: 1.766, Accuracy: 43.333% Epoch 050: Loss: 0.579, Accuracy: 71.667% Epoch 100: Loss: 0.398, Accuracy: 82.500% Epoch 150: Loss: 0.307, Accuracy: 92.500% Epoch 200: Loss: 0.224, Accuracy: 95.833%
Wizualizuj funkcję utraty w czasie
Chociaż pomocne jest wydrukowanie postępu szkolenia modelu, często bardziej pomocne jest zobaczenie tego postępu. TensorBoard to ładne narzędzie do wizualizacji, które jest dostarczane z TensorFlow, ale możemy tworzyć podstawowe wykresy za pomocą modułu matplotlib .
Interpretowanie tych wykresów wymaga pewnego doświadczenia, ale naprawdę chcesz, aby strata spadała, a dokładność wzrastała:
fig, axes = plt.subplots(2, sharex=True, figsize=(12, 8))
fig.suptitle('Training Metrics')
axes[0].set_ylabel("Loss", fontsize=14)
axes[0].plot(train_loss_results)
axes[1].set_ylabel("Accuracy", fontsize=14)
axes[1].set_xlabel("Epoch", fontsize=14)
axes[1].plot(train_accuracy_results)
plt.show()
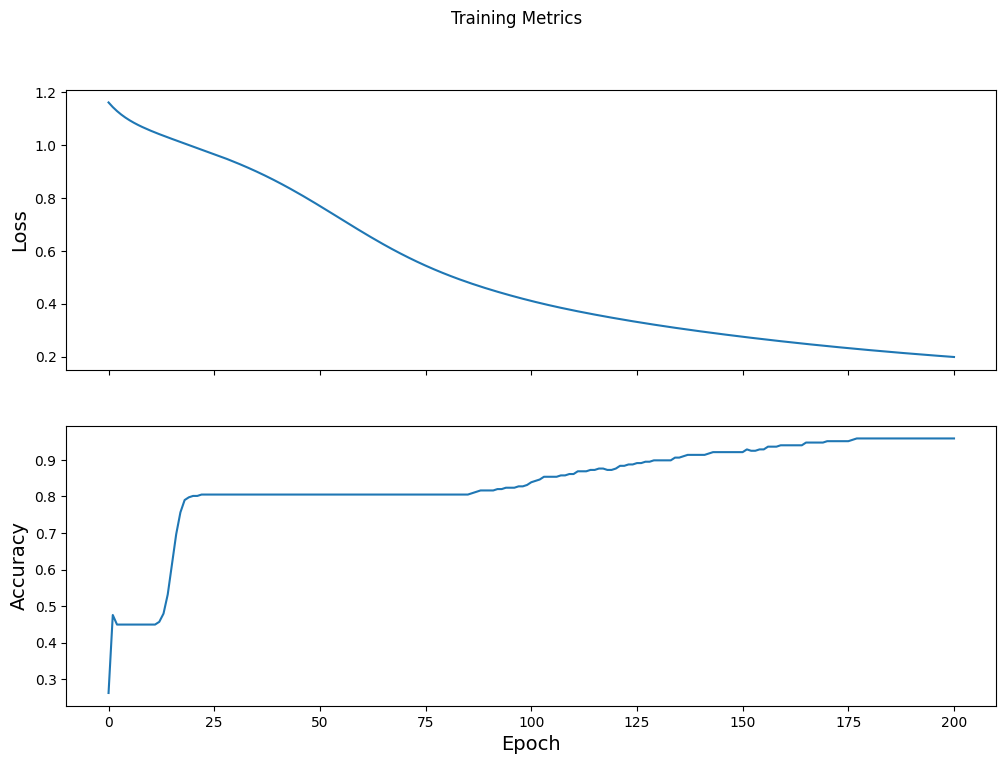
Oceń skuteczność modelu
Teraz, gdy model jest wytrenowany, możemy uzyskać statystyki dotyczące jego wydajności.
Ocena oznacza określenie, jak skutecznie model wykonuje prognozy. Aby określić skuteczność modelu w klasyfikacji tęczówki, przekaż kilka pomiarów działek i płatków do modelu i poproś model o przewidzenie, jakie gatunki tęczówki reprezentują. Następnie porównaj przewidywania modelu z rzeczywistą etykietą. Na przykład model, który wybrał właściwy gatunek na połowie przykładów wejściowych, ma dokładność 0.5 . Rysunek 4 przedstawia nieco bardziej efektywny model, w którym 4 z 5 prognoz są poprawne z dokładnością 80%:
| Przykładowe funkcje | Etykieta | Przewidywanie modelu | |||
|---|---|---|---|---|---|
| 5,9 | 3,0 | 4.3 | 1,5 | 1 | 1 |
| 6,9 | 3.1 | 5.4 | 2,1 | 2 | 2 |
| 5.1 | 3,3 | 1,7 | 0,5 | 0 | 0 |
| 6,0 | 3.4 | 4,5 | 1,6 | 1 | 2 |
| 5,5 | 2,5 | 4.0 | 1,3 | 1 | 1 |
| Rysunek 4. Klasyfikator Iris, który jest dokładny w 80%. | |||||
Skonfiguruj testowy zestaw danych
Ocena modelu jest podobna do uczenia modelu. Największą różnicą jest to, że przykłady pochodzą z oddzielnego zestawu testowego, a nie zestawu uczącego. Aby rzetelnie ocenić skuteczność modelu, przykłady użyte do oceny modelu muszą różnić się od przykładów użytych do uczenia modelu.
Konfiguracja testowego Dataset jest podobna do konfiguracji Dataset . Pobierz plik tekstowy CSV i przeanalizuj te wartości, a następnie trochę przetasuj:
test_url = "https://storage.googleapis.com/download.tensorflow.org/data/iris_test.csv"
test_fp = tf.keras.utils.get_file(fname=os.path.basename(test_url),
origin=test_url)
test_dataset = tf.data.experimental.make_csv_dataset(
test_fp,
batch_size,
column_names=column_names,
label_name='species',
num_epochs=1,
shuffle=False)
test_dataset = test_dataset.map(pack_features_vector)
Oceń model na testowym zbiorze danych
W przeciwieństwie do etapu uczenia, model ocenia tylko jedną epokę danych testowych. W poniższej komórce kodu wykonujemy iterację każdego przykładu w zestawie testowym i porównujemy przewidywanie modelu z rzeczywistą etykietą. Służy do pomiaru dokładności modelu w całym zestawie testowym:
test_accuracy = tf.keras.metrics.Accuracy()
for (x, y) in test_dataset:
# training=False is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
logits = model(x, training=False)
prediction = tf.argmax(logits, axis=1, output_type=tf.int32)
test_accuracy(prediction, y)
print("Test set accuracy: {:.3%}".format(test_accuracy.result()))
Test set accuracy: 96.667%
Na ostatniej partii widzimy na przykład, że model jest zazwyczaj poprawny:
tf.stack([y,prediction],axis=1)
<tf.Tensor: shape=(30, 2), dtype=int32, numpy=
array([[1, 1],
[2, 2],
[0, 0],
[1, 1],
[1, 1],
[1, 1],
[0, 0],
[2, 2],
[1, 1],
[2, 2],
[2, 2],
[0, 0],
[2, 2],
[1, 1],
[1, 1],
[0, 0],
[1, 1],
[0, 0],
[0, 0],
[2, 2],
[0, 0],
[1, 1],
[2, 2],
[1, 2],
[1, 1],
[1, 1],
[0, 0],
[1, 1],
[2, 2],
[1, 1]], dtype=int32)>
Użyj wytrenowanego modelu do prognozowania
Wyszkoliliśmy model i „udowodniliśmy”, że jest dobry – ale nie doskonały – w klasyfikowaniu gatunków Iris. Teraz użyjmy wytrenowanego modelu, aby wykonać pewne prognozy na przykładach nieoznaczonych ; to znaczy na przykładach, które zawierają cechy, ale nie zawierają etykiety.
W rzeczywistości nieoznaczone przykłady mogą pochodzić z wielu różnych źródeł, w tym aplikacji, plików CSV i źródeł danych. Na razie ręcznie przedstawimy trzy przykłady bez etykiet, aby przewidzieć ich etykiety. Przypomnijmy, numery etykiet są mapowane do nazwanej reprezentacji jako:
-
0: Irys setosa -
1: Iris versicolor -
2: Iris virginica
predict_dataset = tf.convert_to_tensor([
[5.1, 3.3, 1.7, 0.5,],
[5.9, 3.0, 4.2, 1.5,],
[6.9, 3.1, 5.4, 2.1]
])
# training=False is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
predictions = model(predict_dataset, training=False)
for i, logits in enumerate(predictions):
class_idx = tf.argmax(logits).numpy()
p = tf.nn.softmax(logits)[class_idx]
name = class_names[class_idx]
print("Example {} prediction: {} ({:4.1f}%)".format(i, name, 100*p))
Example 0 prediction: Iris setosa (97.6%) Example 1 prediction: Iris versicolor (82.0%) Example 2 prediction: Iris virginica (56.4%)