
| | |  Wyświetl źródło na GitHub Wyświetl źródło na GitHub | |
Ten samouczek skupia się na zadaniu segmentacji obrazu przy użyciu zmodyfikowanego U-Net .
Co to jest segmentacja obrazu?
W zadaniu klasyfikacji obrazów sieć przypisuje etykietę (lub klasę) do każdego obrazu wejściowego. Załóżmy jednak, że chcesz poznać kształt tego obiektu, który piksel należy do jakiego obiektu itd. W tym przypadku będziesz chciał przypisać klasę do każdego piksela obrazu. To zadanie nazywa się segmentacją. Model segmentacji zwraca znacznie bardziej szczegółowe informacje o obrazie. Segmentacja obrazu ma wiele zastosowań w obrazowaniu medycznym, autonomicznych samochodach i obrazowaniu satelitarnym, aby wymienić tylko kilka.
Ten samouczek wykorzystuje zbiór danych zwierząt domowych Oxford-IIIT ( Parkhi et al, 2012 ). Zestaw danych składa się z obrazów 37 ras zwierząt domowych, z 200 obrazami na rasę (po ok. 100 w podziałach treningowych i testowych). Każdy obraz zawiera odpowiednie etykiety i maski pikselowe. Maski są etykietami klas dla każdego piksela. Każdy piksel jest przypisany do jednej z trzech kategorii:
- Klasa 1: Piksel należący do zwierzaka.
- Klasa 2: Piksel graniczący ze zwierzęciem.
- Klasa 3: Żadne z powyższych / otaczający piksel.
pip install git+https://github.com/tensorflow/examples.git
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow_examples.models.pix2pix import pix2pix
from IPython.display import clear_output
import matplotlib.pyplot as plt
Pobierz zbiór danych Oxford-IIIT Pets
Zestaw danych jest dostępny w TensorFlow Datasets . Maski segmentacyjne są zawarte w wersji 3+.
dataset, info = tfds.load('oxford_iiit_pet:3.*.*', with_info=True)
Ponadto wartości kolorów obrazu są znormalizowane do zakresu [0,1] . Wreszcie, jak wspomniano powyżej, piksele w masce segmentacji są oznaczone jako {1, 2, 3}. Dla wygody odejmij 1 od maski segmentacji, w wyniku czego uzyskasz etykiety: {0, 1, 2}.
def normalize(input_image, input_mask):
input_image = tf.cast(input_image, tf.float32) / 255.0
input_mask -= 1
return input_image, input_mask
def load_image(datapoint):
input_image = tf.image.resize(datapoint['image'], (128, 128))
input_mask = tf.image.resize(datapoint['segmentation_mask'], (128, 128))
input_image, input_mask = normalize(input_image, input_mask)
return input_image, input_mask
Zestaw danych zawiera już wymagane podziały treningowe i testowe, więc nadal używaj tych samych podziałów.
TRAIN_LENGTH = info.splits['train'].num_examples
BATCH_SIZE = 64
BUFFER_SIZE = 1000
STEPS_PER_EPOCH = TRAIN_LENGTH // BATCH_SIZE
train_images = dataset['train'].map(load_image, num_parallel_calls=tf.data.AUTOTUNE)
test_images = dataset['test'].map(load_image, num_parallel_calls=tf.data.AUTOTUNE)
Poniższa klasa wykonuje proste rozszerzenie, losowo odwracając obraz. Przejdź do samouczka dotyczącego powiększania obrazu , aby dowiedzieć się więcej.
class Augment(tf.keras.layers.Layer):
def __init__(self, seed=42):
super().__init__()
# both use the same seed, so they'll make the same random changes.
self.augment_inputs = tf.keras.layers.RandomFlip(mode="horizontal", seed=seed)
self.augment_labels = tf.keras.layers.RandomFlip(mode="horizontal", seed=seed)
def call(self, inputs, labels):
inputs = self.augment_inputs(inputs)
labels = self.augment_labels(labels)
return inputs, labels
Skompiluj potok wejściowy, stosując rozszerzenie po partiach danych wejściowych.
train_batches = (
train_images
.cache()
.shuffle(BUFFER_SIZE)
.batch(BATCH_SIZE)
.repeat()
.map(Augment())
.prefetch(buffer_size=tf.data.AUTOTUNE))
test_batches = test_images.batch(BATCH_SIZE)
Wizualizuj przykład obrazu i odpowiadającą mu maskę z zestawu danych.
def display(display_list):
plt.figure(figsize=(15, 15))
title = ['Input Image', 'True Mask', 'Predicted Mask']
for i in range(len(display_list)):
plt.subplot(1, len(display_list), i+1)
plt.title(title[i])
plt.imshow(tf.keras.utils.array_to_img(display_list[i]))
plt.axis('off')
plt.show()
for images, masks in train_batches.take(2):
sample_image, sample_mask = images[0], masks[0]
display([sample_image, sample_mask])
Corrupt JPEG data: 240 extraneous bytes before marker 0xd9 Corrupt JPEG data: premature end of data segment


2022-01-26 05:14:45.972101: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
Zdefiniuj model
Zastosowany tutaj model to zmodyfikowany U-Net . Sieć U-Net składa się z kodera (downsamplera) i dekodera (upsamplera). Aby nauczyć się niezawodnych funkcji i zmniejszyć liczbę parametrów, które można trenować, użyjesz wstępnie wytrenowanego modelu — MobileNetV2 — jako kodera. Dla dekodera użyjesz bloku upsample, który jest już zaimplementowany w przykładzie pix2pix w repozytorium TensorFlow Example. (Sprawdź pix2pix: Tłumaczenie obrazu na obraz z warunkowym samouczkiem GAN w notatniku.)
Jak wspomniano, koder będzie wstępnie wytrenowanym modelem MobileNetV2, który jest przygotowany i gotowy do użycia w tf.keras.applications . Koder składa się z określonych danych wyjściowych z warstw pośrednich w modelu. Pamiętaj, że koder nie będzie szkolony podczas procesu uczenia.
base_model = tf.keras.applications.MobileNetV2(input_shape=[128, 128, 3], include_top=False)
# Use the activations of these layers
layer_names = [
'block_1_expand_relu', # 64x64
'block_3_expand_relu', # 32x32
'block_6_expand_relu', # 16x16
'block_13_expand_relu', # 8x8
'block_16_project', # 4x4
]
base_model_outputs = [base_model.get_layer(name).output for name in layer_names]
# Create the feature extraction model
down_stack = tf.keras.Model(inputs=base_model.input, outputs=base_model_outputs)
down_stack.trainable = False
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/mobilenet_v2/mobilenet_v2_weights_tf_dim_ordering_tf_kernels_1.0_128_no_top.h5 9412608/9406464 [==============================] - 0s 0us/step 9420800/9406464 [==============================] - 0s 0us/step
Dekoder/upsampler to po prostu seria bloków upsamplingu zaimplementowanych w przykładach TensorFlow.
up_stack = [
pix2pix.upsample(512, 3), # 4x4 -> 8x8
pix2pix.upsample(256, 3), # 8x8 -> 16x16
pix2pix.upsample(128, 3), # 16x16 -> 32x32
pix2pix.upsample(64, 3), # 32x32 -> 64x64
]
def unet_model(output_channels:int):
inputs = tf.keras.layers.Input(shape=[128, 128, 3])
# Downsampling through the model
skips = down_stack(inputs)
x = skips[-1]
skips = reversed(skips[:-1])
# Upsampling and establishing the skip connections
for up, skip in zip(up_stack, skips):
x = up(x)
concat = tf.keras.layers.Concatenate()
x = concat([x, skip])
# This is the last layer of the model
last = tf.keras.layers.Conv2DTranspose(
filters=output_channels, kernel_size=3, strides=2,
padding='same') #64x64 -> 128x128
x = last(x)
return tf.keras.Model(inputs=inputs, outputs=x)
Zauważ, że liczba filtrów na ostatniej warstwie jest ustawiona na liczbę output_channels . Będzie to jeden kanał wyjściowy na klasę.
Trenuj modelkę
Teraz pozostaje tylko skompilować i wytrenować model.
Ponieważ jest to problem klasyfikacji wieloklasowej, użyj funkcji straty tf.keras.losses.CategoricalCrossentropy z argumentem from_logits ustawionym na True , ponieważ etykiety są skalarnymi liczbami całkowitymi, a nie wektorami wyników dla każdego piksela każdej klasy.
Podczas wnioskowania etykietą przypisaną do piksela jest kanał o najwyższej wartości. To właśnie robi funkcja create_mask .
OUTPUT_CLASSES = 3
model = unet_model(output_channels=OUTPUT_CLASSES)
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
Rzuć okiem na powstałą architekturę modelu:
tf.keras.utils.plot_model(model, show_shapes=True)

Wypróbuj model, aby sprawdzić, co przewiduje przed treningiem.
def create_mask(pred_mask):
pred_mask = tf.argmax(pred_mask, axis=-1)
pred_mask = pred_mask[..., tf.newaxis]
return pred_mask[0]
def show_predictions(dataset=None, num=1):
if dataset:
for image, mask in dataset.take(num):
pred_mask = model.predict(image)
display([image[0], mask[0], create_mask(pred_mask)])
else:
display([sample_image, sample_mask,
create_mask(model.predict(sample_image[tf.newaxis, ...]))])
show_predictions()

Zdefiniowane poniżej wywołanie zwrotne służy do obserwowania, jak model poprawia się podczas uczenia.
class DisplayCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
clear_output(wait=True)
show_predictions()
print ('\nSample Prediction after epoch {}\n'.format(epoch+1))
EPOCHS = 20
VAL_SUBSPLITS = 5
VALIDATION_STEPS = info.splits['test'].num_examples//BATCH_SIZE//VAL_SUBSPLITS
model_history = model.fit(train_batches, epochs=EPOCHS,
steps_per_epoch=STEPS_PER_EPOCH,
validation_steps=VALIDATION_STEPS,
validation_data=test_batches,
callbacks=[DisplayCallback()])

Sample Prediction after epoch 20 57/57 [==============================] - 4s 62ms/step - loss: 0.1838 - accuracy: 0.9187 - val_loss: 0.2797 - val_accuracy: 0.8955
loss = model_history.history['loss']
val_loss = model_history.history['val_loss']
plt.figure()
plt.plot(model_history.epoch, loss, 'r', label='Training loss')
plt.plot(model_history.epoch, val_loss, 'bo', label='Validation loss')
plt.title('Training and Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss Value')
plt.ylim([0, 1])
plt.legend()
plt.show()
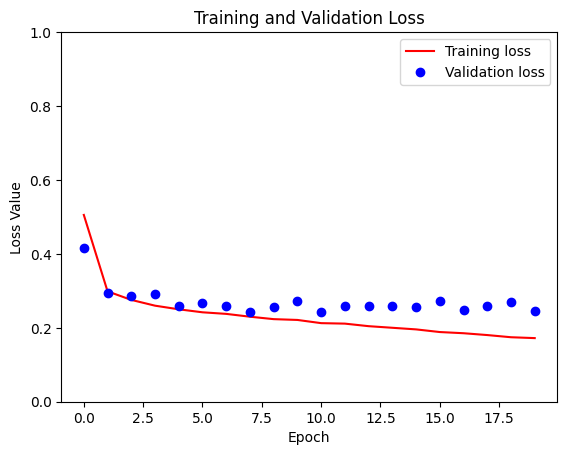
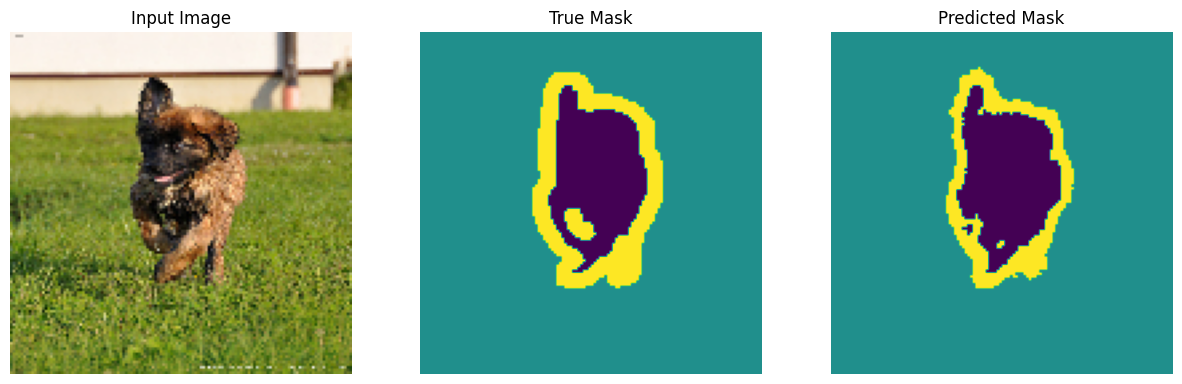
Prognozować
Teraz zrób kilka prognoz. W celu zaoszczędzenia czasu liczba epok była niewielka, ale można ją ustawić wyżej, aby uzyskać dokładniejsze wyniki.
show_predictions(test_batches, 3)


Opcjonalnie: niezrównoważone klasy i wagi klas
Zestawy danych segmentacji semantycznej mogą być bardzo niezrównoważone, co oznacza, że piksele określonej klasy mogą być obecne w większej liczbie obrazów wewnątrz niż w przypadku innych klas. Ponieważ problemy z segmentacją można traktować jako problemy z klasyfikacją na piksel, można poradzić sobie z problemem nierównowagi poprzez ważenie funkcji straty, aby to uwzględnić. To prosty i elegancki sposób na poradzenie sobie z tym problemem. Aby dowiedzieć się więcej, zapoznaj się z samouczkiem Klasyfikacja w przypadku niezrównoważonych danych .
Aby uniknąć niejednoznaczności , Model.fit nie obsługuje argumentu class_weight dla danych wejściowych z 3+ wymiarami.
try:
model_history = model.fit(train_batches, epochs=EPOCHS,
steps_per_epoch=STEPS_PER_EPOCH,
class_weight = {0:2.0, 1:2.0, 2:1.0})
assert False
except Exception as e:
print(f"Expected {type(e).__name__}: {e}")
Expected ValueError: `class_weight` not supported for 3+ dimensional targets.
Tak więc w tym przypadku musisz sam wprowadzić ważenie. Zrobisz to za pomocą wag próbek: Oprócz par (data, label) , Model.fit akceptuje również trójki (data, label, sample_weight) .
Model.fit propaguje sample_weight do strat i metryk, które również akceptują argument sample_weight . Masa próbki jest mnożona przez wartość próbki przed etapem redukcji. Na przykład:
label = [0,0]
prediction = [[-3., 0], [-3, 0]]
sample_weight = [1, 10]
loss = tf.losses.SparseCategoricalCrossentropy(from_logits=True,
reduction=tf.losses.Reduction.NONE)
loss(label, prediction, sample_weight).numpy()
array([ 3.0485873, 30.485874 ], dtype=float32)
Tak więc, aby utworzyć wagi próbek dla tego samouczka, potrzebujesz funkcji, która pobiera parę (data, label) i zwraca potrójną (data, label, sample_weight) . Gdzie sample_weight to 1-kanałowy obraz zawierający wagę klasy dla każdego piksela.
Najprostszą możliwą implementacją jest użycie etykiety jako indeksu w liście class_weight :
def add_sample_weights(image, label):
# The weights for each class, with the constraint that:
# sum(class_weights) == 1.0
class_weights = tf.constant([2.0, 2.0, 1.0])
class_weights = class_weights/tf.reduce_sum(class_weights)
# Create an image of `sample_weights` by using the label at each pixel as an
# index into the `class weights` .
sample_weights = tf.gather(class_weights, indices=tf.cast(label, tf.int32))
return image, label, sample_weights
Wynikowe elementy zbioru danych zawierają po 3 obrazy:
train_batches.map(add_sample_weights).element_spec
(TensorSpec(shape=(None, 128, 128, 3), dtype=tf.float32, name=None), TensorSpec(shape=(None, 128, 128, 1), dtype=tf.float32, name=None), TensorSpec(shape=(None, 128, 128, 1), dtype=tf.float32, name=None))
Teraz możesz trenować model na tym ważonym zbiorze danych:
weighted_model = unet_model(OUTPUT_CLASSES)
weighted_model.compile(
optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
weighted_model.fit(
train_batches.map(add_sample_weights),
epochs=1,
steps_per_epoch=10)
10/10 [==============================] - 3s 44ms/step - loss: 0.3099 - accuracy: 0.6063 <keras.callbacks.History at 0x7fa75d0f3e50>
Następne kroki
Teraz, gdy już wiesz, czym jest segmentacja obrazu i jak działa, możesz wypróbować ten samouczek z różnymi wynikami warstwy pośredniej, a nawet różnymi wstępnie wytrenowanymi modelami. Możesz także rzucić sobie wyzwanie, wypróbowując wyzwanie maskowania obrazu Carvana hostowane na Kaggle.
Możesz także chcieć zobaczyć API Tensorflow Object Detection dla innego modelu, który możesz przeszkolić na własnych danych. Wstępnie przeszkolone modele są dostępne w TensorFlow Hub