
| | |  عرض المصدر على جيثب عرض المصدر على جيثب | |
يقوم هذا الدليل بتدريب نموذج الشبكة العصبية لتصنيف صور الملابس ، مثل الأحذية الرياضية والقمصان. لا بأس إذا لم تفهم كل التفاصيل ؛ هذه نظرة عامة سريعة على برنامج TensorFlow الكامل مع شرح التفاصيل أثناء التنقل.
يستخدم هذا الدليل tf.keras ، وهو واجهة برمجة تطبيقات عالية المستوى لبناء النماذج وتدريبها في TensorFlow.
# TensorFlow and tf.keras
import tensorflow as tf
# Helper libraries
import numpy as np
import matplotlib.pyplot as plt
print(tf.__version__)
2.8.0-rc1
قم باستيراد مجموعة بيانات Fashion MNIST
يستخدم هذا الدليل مجموعة بيانات Fashion MNIST التي تحتوي على 70000 صورة ذات تدرج رمادي في 10 فئات. تُظهر الصور مقالات فردية من الملابس بدقة منخفضة (28 × 28 بكسل) ، كما هو موضح هنا:
| الشكل 1. عينات أزياء MNIST (بواسطة Zalando ، ترخيص MIT). |
تم تصميم Fashion MNIST كبديل مباشر لمجموعة بيانات MNIST الكلاسيكية - غالبًا ما تستخدم كـ "مرحبًا ، عالم" لبرامج التعلم الآلي لرؤية الكمبيوتر. تحتوي مجموعة بيانات MNIST على صور لأرقام مكتوبة بخط اليد (0 ، 1 ، 2 ، إلخ) بتنسيق مطابق لتنسيق سلع الملابس التي ستستخدمها هنا.
يستخدم هذا الدليل Fashion MNIST للتنوع ، ولأنها مشكلة أكثر تحديًا من MNIST العادية. كلا مجموعتي البيانات صغيرتان نسبيًا ويتم استخدامهما للتحقق من أن الخوارزمية تعمل على النحو المتوقع. إنها نقاط بداية جيدة لاختبار الشفرة وتصحيحها.
هنا ، يتم استخدام 60.000 صورة لتدريب الشبكة و 10000 صورة لتقييم مدى دقة تعلم الشبكة لتصنيف الصور. يمكنك الوصول إلى Fashion MNIST مباشرة من TensorFlow. استيراد وتحميل بيانات Fashion MNIST مباشرة من TensorFlow:
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
يؤدي تحميل مجموعة البيانات إلى إرجاع أربعة مصفوفات NumPy:
-
train_imagesوtrain_labelsهي مجموعة التدريب — البيانات التي يستخدمها النموذج للتعلم. - يتم اختبار النموذج مقابل مجموعة الاختبار ، وصور الاختبار ،
test_imagestest_labels.
الصور 28 × 28 مصفوفات NumPy ، مع قيم بكسل تتراوح من 0 إلى 255. الملصقات عبارة عن مصفوفة من الأعداد الصحيحة ، تتراوح من 0 إلى 9. تتوافق هذه مع فئة الملابس التي تمثلها الصورة:
| ملصق | فصل |
|---|---|
| 0 | تي شيرت / توب |
| 1 | بنطلون |
| 2 | قف بجانب الطريق |
| 3 | فستان |
| 4 | معطف |
| 5 | صندل |
| 6 | قميص |
| 7 | حذاء رياضة |
| 8 | حقيبة |
| 9 | التمهيد الكاحل |
يتم تعيين كل صورة إلى تسمية واحدة. نظرًا لعدم تضمين أسماء الفئات في مجموعة البيانات ، قم بتخزينها هنا لاستخدامها لاحقًا عند رسم الصور:
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
استكشف البيانات
دعنا نستكشف تنسيق مجموعة البيانات قبل تدريب النموذج. يوضح ما يلي أن هناك 60.000 صورة في مجموعة التدريب ، مع تمثيل كل صورة بحجم 28 × 28 بكسل:
train_images.shape
(60000, 28, 28)
وبالمثل ، هناك 60.000 ملصق في مجموعة التدريب:
len(train_labels)
60000
كل تسمية عبارة عن عدد صحيح بين 0 و 9:
train_labels
array([9, 0, 0, ..., 3, 0, 5], dtype=uint8)
هناك 10000 صورة في مجموعة الاختبار. مرة أخرى ، يتم تمثيل كل صورة بحجم 28 × 28 بكسل:
test_images.shape
(10000, 28, 28)
وتحتوي مجموعة الاختبار على 10000 ملصق صورة:
len(test_labels)
10000
المعالجة المسبقة للبيانات
يجب معالجة البيانات مسبقًا قبل تدريب الشبكة. إذا قمت بفحص الصورة الأولى في مجموعة التدريب ، فسترى أن قيم البكسل تقع في النطاق من 0 إلى 255:
plt.figure()
plt.imshow(train_images[0])
plt.colorbar()
plt.grid(False)
plt.show()
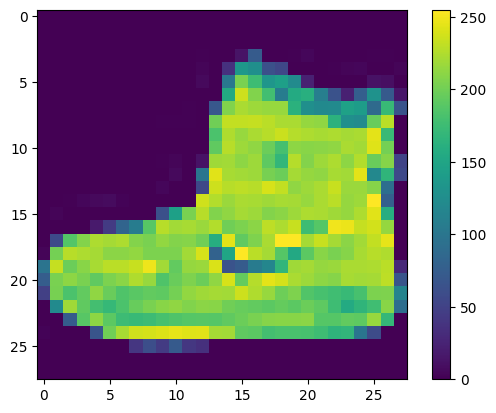
قم بتوسيع هذه القيم إلى نطاق من 0 إلى 1 قبل إطعامها إلى نموذج الشبكة العصبية. للقيام بذلك ، قسّم القيم على 255. من المهم أن تتم معالجة مجموعة التدريب ومجموعة الاختبار بالطريقة نفسها:
train_images = train_images / 255.0
test_images = test_images / 255.0
للتحقق من أن البيانات بالتنسيق الصحيح وأنك مستعد لبناء الشبكة وتدريبها ، دعنا نعرض أول 25 صورة من مجموعة التدريب ونعرض اسم الفصل أسفل كل صورة.
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
plt.show()

بناء النموذج
يتطلب بناء الشبكة العصبية تكوين طبقات النموذج ، ثم تجميع النموذج.
قم بإعداد الطبقات
اللبنة الأساسية للشبكة العصبية هي الطبقة . تستخرج الطبقات تمثيلات من البيانات التي يتم تغذيتها بها. نأمل أن تكون هذه التمثيلات ذات مغزى للمشكلة المطروحة.
يتكون معظم التعلم العميق من ربط الطبقات البسيطة معًا. تحتوي معظم الطبقات ، مثل tf.keras.layers.Dense ، على معلمات يتم تعلمها أثناء التدريب.
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10)
])
الطبقة الأولى في هذه الشبكة ، tf.keras.layers.Flatten ، تحول تنسيق الصور من مصفوفة ثنائية الأبعاد (28 × 28 بكسل) إلى مصفوفة أحادية البعد (28 * 28 = 784 بكسل). فكر في هذه الطبقة على أنها صفوف غير مكدسة من البكسلات في الصورة وتصطفها. هذه الطبقة ليس لديها معلمات لتعلمها ؛ يقوم فقط بإعادة تنسيق البيانات.
بعد تسوية وحدات البكسل ، تتكون الشبكة من سلسلة من طبقتين من طبقات tf.keras.layers.Dense . هذه هي طبقات عصبية متصلة بكثافة أو متصلة بالكامل. تحتوي الطبقة Dense الأولى على 128 عقدة (أو عصبون). تقوم الطبقة الثانية (والأخيرة) بإرجاع مصفوفة سجلات بطول 10. تحتوي كل عقدة على درجة تشير إلى أن الصورة الحالية تنتمي إلى إحدى الفئات العشر.
تجميع النموذج
قبل أن يصبح النموذج جاهزًا للتدريب ، فإنه يحتاج إلى بعض الإعدادات الإضافية. تتم إضافة هذه أثناء خطوة التحويل البرمجي للنموذج:
- وظيفة الخسارة - يقيس هذا مدى دقة النموذج أثناء التدريب. تريد تصغير هذه الوظيفة "لتوجيه" النموذج في الاتجاه الصحيح.
- مُحسِّن - هذه هي الطريقة التي يتم بها تحديث النموذج بناءً على البيانات التي يراها ووظيفة الخسارة.
- المقاييس — تُستخدم لمراقبة خطوات التدريب والاختبار. يستخدم المثال التالي الدقة ، وهي جزء من الصور التي تم تصنيفها بشكل صحيح.
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
تدريب النموذج
يتطلب تدريب نموذج الشبكة العصبية الخطوات التالية:
- تغذية بيانات التدريب للنموذج. في هذا المثال ، توجد بيانات التدريب في
train_imagesوtrain_labels. - يتعلم النموذج ربط الصور والتسميات.
- تطلب من النموذج إجراء تنبؤات حول مجموعة اختبار - في هذا المثال ، مصفوفة
test_images. - تحقق من أن التنبؤات تطابق التسميات من مجموعة
test_labels.
تغذية النموذج
لبدء التدريب ، اتصل بالطريقة model.fit وهذا ما يسمى لأنها "تناسب" النموذج مع بيانات التدريب:
model.fit(train_images, train_labels, epochs=10)
Epoch 1/10 1875/1875 [==============================] - 4s 2ms/step - loss: 0.5014 - accuracy: 0.8232 Epoch 2/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.3770 - accuracy: 0.8636 Epoch 3/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.3376 - accuracy: 0.8770 Epoch 4/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.3148 - accuracy: 0.8841 Epoch 5/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2973 - accuracy: 0.8899 Epoch 6/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2807 - accuracy: 0.8955 Epoch 7/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2707 - accuracy: 0.9002 Epoch 8/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2592 - accuracy: 0.9042 Epoch 9/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2506 - accuracy: 0.9070 Epoch 10/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2419 - accuracy: 0.9090 <keras.callbacks.History at 0x7f730da81c50>
أثناء تدريب النموذج ، يتم عرض مقاييس الخسارة والدقة. يصل هذا النموذج إلى دقة تبلغ حوالي 0.91 (أو 91٪) على بيانات التدريب.
تقييم الدقة
بعد ذلك ، قارن كيفية أداء النموذج في مجموعة بيانات الاختبار:
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('\nTest accuracy:', test_acc)
313/313 - 1s - loss: 0.3347 - accuracy: 0.8837 - 593ms/epoch - 2ms/step Test accuracy: 0.8837000131607056
اتضح أن الدقة في مجموعة بيانات الاختبار أقل قليلاً من الدقة في مجموعة بيانات التدريب. تمثل هذه الفجوة بين دقة التدريب ودقة الاختبار فرطًا في التجهيز. يحدث التجهيز الزائد عندما يكون أداء نموذج التعلم الآلي على المدخلات الجديدة غير المرئية سابقًا أسوأ من أداءه في بيانات التدريب. يحفظ النموذج المجهز بشكل زائد الضوضاء والتفاصيل في مجموعة بيانات التدريب لدرجة أنه يؤثر سلبًا على أداء النموذج على البيانات الجديدة. لمزيد من المعلومات ، راجع ما يلي:
قم بعمل تنبؤات
مع النموذج الذي تم تدريبه ، يمكنك استخدامه لعمل تنبؤات حول بعض الصور. المخرجات الخطية للنموذج ، اللوغاريتمات . قم بإرفاق طبقة softmax لتحويل السجلات إلى احتمالات ، والتي يسهل تفسيرها.
probability_model = tf.keras.Sequential([model,
tf.keras.layers.Softmax()])
predictions = probability_model.predict(test_images)
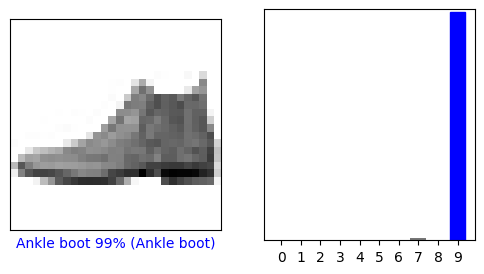
هنا ، توقع النموذج تسمية كل صورة في مجموعة الاختبار. دعنا نلقي نظرة على التوقع الأول:
predictions[0]
array([6.5094389e-07, 1.5681711e-10, 9.0262159e-10, 8.3779689e-10,
9.4969926e-07, 6.7454423e-03, 3.7524345e-08, 1.6792126e-02,
9.9967767e-09, 9.7646081e-01], dtype=float32)
التوقع هو مصفوفة من 10 أرقام. إنها تمثل "ثقة" النموذج في أن الصورة تتوافق مع كل قطعة من الملابس العشرة المختلفة. يمكنك معرفة التصنيف الذي يحتوي على أعلى قيمة ثقة:
np.argmax(predictions[0])
9
لذا ، فإن النموذج أكثر ثقة في أن هذه الصورة عبارة عن حذاء للكاحل أو class_names[9] . يوضح فحص ملصق الاختبار أن هذا التصنيف صحيح:
test_labels[0]
9
ارسم هذا الرسم البياني لإلقاء نظرة على المجموعة الكاملة من تنبؤات الفئات العشرة.
def plot_image(i, predictions_array, true_label, img):
true_label, img = true_label[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label],
100*np.max(predictions_array),
class_names[true_label]),
color=color)
def plot_value_array(i, predictions_array, true_label):
true_label = true_label[i]
plt.grid(False)
plt.xticks(range(10))
plt.yticks([])
thisplot = plt.bar(range(10), predictions_array, color="#777777")
plt.ylim([0, 1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')
تحقق من التوقعات
مع النموذج الذي تم تدريبه ، يمكنك استخدامه لعمل تنبؤات حول بعض الصور.
لنلقِ نظرة على مجموعة الصور والتنبؤات والتنبؤ 0. علامات التنبؤ الصحيحة باللون الأزرق وعلامات التنبؤ غير الصحيحة باللون الأحمر. يعطي الرقم النسبة المئوية (من 100) للتسمية المتوقعة.
i = 0
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions[i], test_labels)
plt.show()
i = 12
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions[i], test_labels)
plt.show()
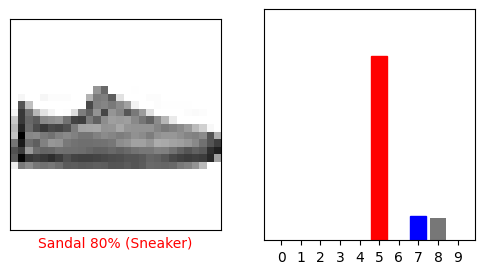
دعونا نرسم عدة صور مع توقعاتهم. لاحظ أن النموذج يمكن أن يكون خاطئًا حتى عندما يكون واثقًا جدًا.
# Plot the first X test images, their predicted labels, and the true labels.
# Color correct predictions in blue and incorrect predictions in red.
num_rows = 5
num_cols = 3
num_images = num_rows*num_cols
plt.figure(figsize=(2*2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, 2*num_cols, 2*i+1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(num_rows, 2*num_cols, 2*i+2)
plot_value_array(i, predictions[i], test_labels)
plt.tight_layout()
plt.show()

استخدم النموذج المدرب
أخيرًا ، استخدم النموذج المدرب لعمل توقع حول صورة واحدة.
# Grab an image from the test dataset.
img = test_images[1]
print(img.shape)
(28, 28)
تم تحسين نماذج tf.keras لعمل تنبؤات حول مجموعة أو مجموعة من الأمثلة في وقت واحد. وفقًا لذلك ، على الرغم من أنك تستخدم صورة واحدة ، فأنت بحاجة إلى إضافتها إلى القائمة:
# Add the image to a batch where it's the only member.
img = (np.expand_dims(img,0))
print(img.shape)
(1, 28, 28)
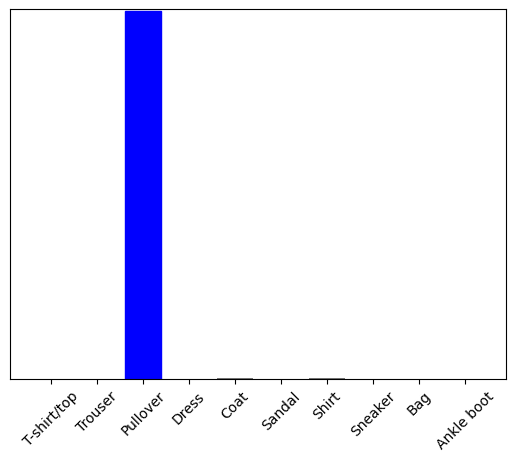
الآن توقع التسمية الصحيحة لهذه الصورة:
predictions_single = probability_model.predict(img)
print(predictions_single)
[[5.2901622e-05 1.1112720e-14 9.9954790e-01 3.9485815e-10 2.0636957e-04 7.8756333e-12 1.9278938e-04 2.9756516e-16 2.2718803e-08 4.3763088e-15]]
plot_value_array(1, predictions_single[0], test_labels)
_ = plt.xticks(range(10), class_names, rotation=45)
plt.show()
tf.keras.Model.predict بإرجاع قائمة من القوائم — قائمة واحدة لكل صورة في مجموعة البيانات. احصل على تنبؤات صورتنا (فقط) في الدفعة:
np.argmax(predictions_single[0])
2
ويتوقع النموذج تسمية كما هو متوقع.
# MIT License
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.