
| | |  Wyświetl źródło na GitHub Wyświetl źródło na GitHub | |
Ten samouczek pokazuje, jak klasyfikować dane strukturalne, takie jak dane tabelaryczne, przy użyciu uproszczonej wersji zestawu danych PetFinder z konkursu Kaggle przechowywanego w pliku CSV.
Użyjesz Keras do zdefiniowania modelu, a warstwy przetwarzania wstępnego Keras jako pomost do mapowania kolumn w pliku CSV do obiektów używanych do uczenia modelu. Celem jest przewidzenie, czy zwierzę zostanie adoptowane.
Ten samouczek zawiera kompletny kod dla:
- Ładowanie pliku CSV do DataFrame przy użyciu pand .
- Tworzenie potoku wejściowego do partii i tasowania wierszy przy użyciu
tf.data. (Odwiedź tf.data: Buduj potoki wejściowe TensorFlow, aby uzyskać więcej informacji). - Mapowanie z kolumn w pliku CSV do funkcji używanych do trenowania modelu za pomocą warstw przetwarzania wstępnego Keras.
- Budowanie, trenowanie i ocena modelu przy użyciu wbudowanych metod Keras.
Minizestaw danych PetFinder.my
Istnieje kilka tysięcy wierszy w pliku danych CSV PetFinder.my mini, gdzie każdy wiersz opisuje zwierzaka (psa lub kota), a każda kolumna opisuje atrybut, taki jak wiek, rasa, kolor i tak dalej.
Zwróć uwagę, że w poniższym podsumowaniu zbioru danych znajdują się głównie kolumny liczbowe i kategorialne. W tym samouczku będziesz miał do czynienia tylko z tymi dwoma typami funkcji, upuszczając Description (funkcja dowolnego tekstu) i AdoptionSpeed (funkcja klasyfikacji) podczas wstępnego przetwarzania danych.
| Kolumna | Opis zwierzaka | Typ funkcji | Typ danych |
|---|---|---|---|
Type | Rodzaj zwierzęcia ( Dog , Cat ) | Kategoryczny | Strunowy |
Age | Wiek | Liczbowy | Liczba całkowita |
Breed1 | Rasa podstawowa | Kategoryczny | Strunowy |
Color1 | Kolor 1 | Kategoryczny | Strunowy |
Color2 | Kolor 2 | Kategoryczny | Strunowy |
MaturitySize | Rozmiar w terminie dojrzałości | Kategoryczny | Strunowy |
FurLength | Długość futra | Kategoryczny | Strunowy |
Vaccinated | Zwierzę zostało zaszczepione | Kategoryczny | Strunowy |
Sterilized | Zwierzę zostało wysterylizowane | Kategoryczny | Strunowy |
Health | Stan zdrowia | Kategoryczny | Strunowy |
Fee | Opłata adopcyjna | Liczbowy | Liczba całkowita |
Description | Zapis profilu | Tekst | Strunowy |
PhotoAmt | Wszystkie przesłane zdjęcia | Liczbowy | Liczba całkowita |
AdoptionSpeed | Kategoryczna szybkość adopcji | Klasyfikacja | Liczba całkowita |
Importuj TensorFlow i inne biblioteki
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow.keras import layers
tf.__version__
'2.8.0-rc1'
Załaduj zbiór danych i wczytaj go do pandy DataFrame
pandas to biblioteka Pythona z wieloma pomocnymi narzędziami do ładowania i pracy z danymi strukturalnymi. Użyj tf.keras.utils.get_file , aby pobrać i wyodrębnić plik CSV z minizestawem danych PetFinder.my i załaduj go do DataFrame za pomocą pandas.read_csv :
dataset_url = 'http://storage.googleapis.com/download.tensorflow.org/data/petfinder-mini.zip'
csv_file = 'datasets/petfinder-mini/petfinder-mini.csv'
tf.keras.utils.get_file('petfinder_mini.zip', dataset_url,
extract=True, cache_dir='.')
dataframe = pd.read_csv(csv_file)
Downloading data from http://storage.googleapis.com/download.tensorflow.org/data/petfinder-mini.zip 1671168/1668792 [==============================] - 0s 0us/step 1679360/1668792 [==============================] - 0s 0us/step
Sprawdź zestaw danych, sprawdzając pierwsze pięć wierszy DataFrame:
dataframe.head()
Utwórz zmienną docelową
Pierwotnym zadaniem w konkursie Kaggle PetFinder.my Adoption Prediction było przewidzenie szybkości, z jaką zwierzę zostanie adoptowane (np. w pierwszym tygodniu, pierwszym miesiącu, pierwszych trzech miesiącach i tak dalej).
W tym samouczku uprościsz zadanie, przekształcając je w binarny problem klasyfikacji, w którym musisz po prostu przewidzieć, czy zwierzę zostało adoptowane, czy nie.
Po zmodyfikowaniu kolumny AdoptionSpeed , 0 będzie oznaczać, że zwierzę nie zostało adoptowane, a 1 będzie oznaczać, że było.
# In the original dataset, `'AdoptionSpeed'` of `4` indicates
# a pet was not adopted.
dataframe['target'] = np.where(dataframe['AdoptionSpeed']==4, 0, 1)
# Drop unused features.
dataframe = dataframe.drop(columns=['AdoptionSpeed', 'Description'])
Podziel DataFrame na zestawy treningowe, walidacyjne i testowe
Zestaw danych znajduje się w pojedynczej pandzie DataFrame. Podziel go na zestawy treningowe, walidacyjne i testowe, stosując na przykład stosunek 80:10:10, odpowiednio:
train, val, test = np.split(dataframe.sample(frac=1), [int(0.8*len(dataframe)), int(0.9*len(dataframe))])
print(len(train), 'training examples')
print(len(val), 'validation examples')
print(len(test), 'test examples')
9229 training examples 1154 validation examples 1154 test examples
Utwórz potok wejściowy za pomocą tf.data
Następnie utwórz funkcję narzędziową, która konwertuje każdy zestaw danych uczących, walidacyjnych i testowych DataFrame na tf.data.Dataset , a następnie tasuje i grupuje dane.
def df_to_dataset(dataframe, shuffle=True, batch_size=32):
df = dataframe.copy()
labels = df.pop('target')
df = {key: value[:,tf.newaxis] for key, value in dataframe.items()}
ds = tf.data.Dataset.from_tensor_slices((dict(df), labels))
if shuffle:
ds = ds.shuffle(buffer_size=len(dataframe))
ds = ds.batch(batch_size)
ds = ds.prefetch(batch_size)
return ds
Teraz użyj nowo utworzonej funkcji ( df_to_dataset ), aby sprawdzić format danych zwracanych przez funkcję pomocniczą potoku wejściowego, wywołując je na danych uczących, i użyj małego rozmiaru partii, aby dane wyjściowe były czytelne:
batch_size = 5
train_ds = df_to_dataset(train, batch_size=batch_size)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:4: FutureWarning: Support for multi-dimensional indexing (e.g. `obj[:, None]`) is deprecated and will be removed in a future version. Convert to a numpy array before indexing instead. after removing the cwd from sys.path.
[(train_features, label_batch)] = train_ds.take(1)
print('Every feature:', list(train_features.keys()))
print('A batch of ages:', train_features['Age'])
print('A batch of targets:', label_batch )
Every feature: ['Type', 'Age', 'Breed1', 'Gender', 'Color1', 'Color2', 'MaturitySize', 'FurLength', 'Vaccinated', 'Sterilized', 'Health', 'Fee', 'PhotoAmt', 'target'] A batch of ages: tf.Tensor( [[84] [ 1] [ 5] [ 1] [12]], shape=(5, 1), dtype=int64) A batch of targets: tf.Tensor([1 1 0 1 0], shape=(5,), dtype=int64)
Jak pokazują dane wyjściowe, zestaw uczący zwraca słownik nazw kolumn (z DataFrame), które mapują wartości kolumn z wierszy.
Zastosuj warstwy przetwarzania wstępnego Keras
Warstwy przetwarzania wstępnego Keras umożliwiają tworzenie natywnych potoków przetwarzania danych wejściowych Keras, które mogą być używane jako niezależny kod przetwarzania wstępnego w przepływach pracy innych niż Keras, połączone bezpośrednio z modelami Keras i eksportowane jako część Keras SavedModel.
W tym samouczku użyjesz następujących czterech warstw przetwarzania wstępnego, aby zademonstrować, jak wykonać przetwarzanie wstępne, kodowanie danych strukturalnych i inżynierię funkcji:
-
tf.keras.layers.Normalization: Wykonuje pod względem funkcji normalizację funkcji wejściowych. -
tf.keras.layers.CategoryEncoding: zamienia elementy kategorialne w liczbach całkowitych w reprezentacje jednoaktywne, wieloaktywne lub gęste tf-idf . -
tf.keras.layers.StringLookup: Zamienia wartości kategorii ciągów na indeksy liczb całkowitych. -
tf.keras.layers.IntegerLookup: Zamienia całkowite wartości kategoryczne na indeksy całkowite.
Więcej informacji o dostępnych warstwach można znaleźć w przewodniku Praca z warstwami przetwarzania wstępnego .
- W przypadku funkcji numerycznych zestawu danych PetFinder.my mini, użyjesz warstwy
tf.keras.layers.Normalization, aby ujednolicić dystrybucję danych. - W przypadku funkcji kategorycznych , takich jak pet
Types (ciągiDogiCat), przekształcisz je w tensory zakodowane na gorąco za pomocątf.keras.layers.CategoryEncoding.
Kolumny numeryczne
Dla każdej funkcji numerycznej w minizestawie danych PetFinder.my użyjesz warstwy tf.keras.layers.Normalization , aby ujednolicić dystrybucję danych.
Zdefiniuj nową funkcję narzędziową, która zwraca warstwę, która stosuje normalizację funkcji pod kątem funkcji numerycznych przy użyciu tej warstwy przetwarzania wstępnego Keras:
def get_normalization_layer(name, dataset):
# Create a Normalization layer for the feature.
normalizer = layers.Normalization(axis=None)
# Prepare a Dataset that only yields the feature.
feature_ds = dataset.map(lambda x, y: x[name])
# Learn the statistics of the data.
normalizer.adapt(feature_ds)
return normalizer
Następnie przetestuj nową funkcję, wywołując ją na wszystkich przesłanych funkcjach zdjęć zwierząt domowych, aby znormalizować 'PhotoAmt' :
photo_count_col = train_features['PhotoAmt']
layer = get_normalization_layer('PhotoAmt', train_ds)
layer(photo_count_col)
<tf.Tensor: shape=(5, 1), dtype=float32, numpy=
array([[-0.8272058 ],
[-0.19125296],
[ 1.3986291 ],
[-0.19125296],
[-0.50922936]], dtype=float32)>
Kolumny kategorialne
Type zwierząt w zestawie danych są reprezentowane jako ciągi — Dog i Cat — które muszą być zakodowane w trybie multi-hot przed wprowadzeniem do modelu. Funkcja Age
Zdefiniuj kolejną nową funkcję użytkową, która zwraca warstwę, która odwzorowuje wartości ze słownika na indeksy liczb całkowitych i koduje obiekty w trybie multi-hot za pomocą przetwarzania wstępnego tf.keras.layers.StringLookup , tf.keras.layers.IntegerLookup i tf.keras.CategoryEncoding warstwy:
def get_category_encoding_layer(name, dataset, dtype, max_tokens=None):
# Create a layer that turns strings into integer indices.
if dtype == 'string':
index = layers.StringLookup(max_tokens=max_tokens)
# Otherwise, create a layer that turns integer values into integer indices.
else:
index = layers.IntegerLookup(max_tokens=max_tokens)
# Prepare a `tf.data.Dataset` that only yields the feature.
feature_ds = dataset.map(lambda x, y: x[name])
# Learn the set of possible values and assign them a fixed integer index.
index.adapt(feature_ds)
# Encode the integer indices.
encoder = layers.CategoryEncoding(num_tokens=index.vocabulary_size())
# Apply multi-hot encoding to the indices. The lambda function captures the
# layer, so you can use them, or include them in the Keras Functional model later.
return lambda feature: encoder(index(feature))
Przetestuj funkcję get_category_encoding_layer , wywołując ją na funkcjach 'Type' zwierzaka, aby przekształcić je w tensory zakodowane na gorąco:
test_type_col = train_features['Type']
test_type_layer = get_category_encoding_layer(name='Type',
dataset=train_ds,
dtype='string')
test_type_layer(test_type_col)
<tf.Tensor: shape=(5, 3), dtype=float32, numpy=
array([[0., 1., 0.],
[0., 1., 0.],
[0., 1., 0.],
[0., 1., 0.],
[0., 1., 0.]], dtype=float32)>
Powtórz ten proces dla funkcji 'Age' zwierzaka:
test_age_col = train_features['Age']
test_age_layer = get_category_encoding_layer(name='Age',
dataset=train_ds,
dtype='int64',
max_tokens=5)
test_age_layer(test_age_col)
<tf.Tensor: shape=(5, 5), dtype=float32, numpy=
array([[1., 0., 0., 0., 0.],
[0., 0., 0., 1., 0.],
[1., 0., 0., 0., 0.],
[0., 0., 0., 1., 0.],
[1., 0., 0., 0., 0.]], dtype=float32)>
Wstępnie przetwórz wybrane funkcje, aby trenować model
Nauczyłeś się korzystać z kilku rodzajów warstw przetwarzania wstępnego Keras. Następnie będziesz:
- Zastosuj zdefiniowane wcześniej funkcje narzędziowe do przetwarzania wstępnego na 13 numerycznych i kategorycznych funkcjach z mini zbioru danych PetFinder.my.
- Dodaj wszystkie dane wejściowe funkcji do listy.
Jak wspomniano na początku, aby wytrenować model, użyjesz danych liczbowych ( 'PhotoAmt' , 'Fee' ) i kategorycznych ( 'Age' , 'Type' , 'Color1' , 'Color2' , 'Gender' ) PetFinder.my mini zbioru danych 'Gender' , 'MaturitySize' , 'FurLength' , 'Vaccinated' , 'Breed1' , 'Health' , 'Sterilized' ).
Wcześniej użyłeś małego rozmiaru partii do zademonstrowania potoku wejściowego. Utwórzmy teraz nowy potok wejściowy z większym rozmiarem partii 256:
batch_size = 256
train_ds = df_to_dataset(train, batch_size=batch_size)
val_ds = df_to_dataset(val, shuffle=False, batch_size=batch_size)
test_ds = df_to_dataset(test, shuffle=False, batch_size=batch_size)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:4: FutureWarning: Support for multi-dimensional indexing (e.g. `obj[:, None]`) is deprecated and will be removed in a future version. Convert to a numpy array before indexing instead. after removing the cwd from sys.path.
Znormalizuj cechy liczbowe (liczbę zdjęć zwierząt domowych i opłatę adopcyjną) i dodaj je do jednej listy danych wejściowych o nazwie encoded_features :
all_inputs = []
encoded_features = []
# Numerical features.
for header in ['PhotoAmt', 'Fee']:
numeric_col = tf.keras.Input(shape=(1,), name=header)
normalization_layer = get_normalization_layer(header, train_ds)
encoded_numeric_col = normalization_layer(numeric_col)
all_inputs.append(numeric_col)
encoded_features.append(encoded_numeric_col)
Zmień kategoryczne wartości liczb całkowitych ze zbioru danych (wiek zwierząt) na indeksy liczb całkowitych, wykonaj kodowanie multi-hot i dodaj wynikowe dane wejściowe funkcji do encoded_features :
age_col = tf.keras.Input(shape=(1,), name='Age', dtype='int64')
encoding_layer = get_category_encoding_layer(name='Age',
dataset=train_ds,
dtype='int64',
max_tokens=5)
encoded_age_col = encoding_layer(age_col)
all_inputs.append(age_col)
encoded_features.append(encoded_age_col)
Powtórz ten sam krok dla wartości kategorycznych ciągu:
categorical_cols = ['Type', 'Color1', 'Color2', 'Gender', 'MaturitySize',
'FurLength', 'Vaccinated', 'Sterilized', 'Health', 'Breed1']
for header in categorical_cols:
categorical_col = tf.keras.Input(shape=(1,), name=header, dtype='string')
encoding_layer = get_category_encoding_layer(name=header,
dataset=train_ds,
dtype='string',
max_tokens=5)
encoded_categorical_col = encoding_layer(categorical_col)
all_inputs.append(categorical_col)
encoded_features.append(encoded_categorical_col)
Twórz, kompiluj i trenuj model
Następnym krokiem jest stworzenie modelu za pomocą Keras Functional API . W przypadku pierwszej warstwy w modelu połącz listę danych wejściowych encoded_features — w jeden wektor poprzez połączenie z tf.keras.layers.concatenate .
all_features = tf.keras.layers.concatenate(encoded_features)
x = tf.keras.layers.Dense(32, activation="relu")(all_features)
x = tf.keras.layers.Dropout(0.5)(x)
output = tf.keras.layers.Dense(1)(x)
model = tf.keras.Model(all_inputs, output)
Skonfiguruj model za pomocą Keras Model.compile :
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=["accuracy"])
Zwizualizujmy wykres łączności:
# Use `rankdir='LR'` to make the graph horizontal.
tf.keras.utils.plot_model(model, show_shapes=True, rankdir="LR")
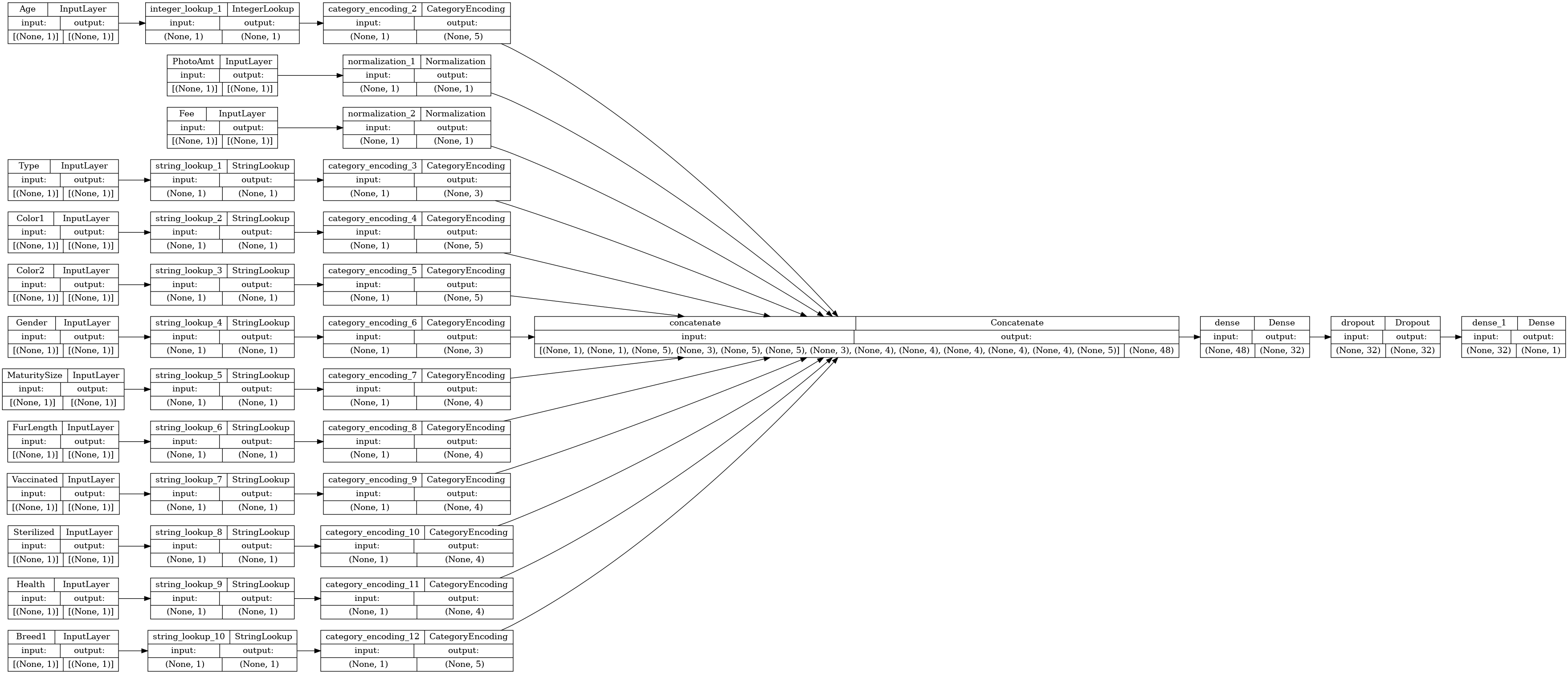
Następnie przeszkol i przetestuj model:
model.fit(train_ds, epochs=10, validation_data=val_ds)
Epoch 1/10 /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/keras/engine/functional.py:559: UserWarning: Input dict contained keys ['target'] which did not match any model input. They will be ignored by the model. inputs = self._flatten_to_reference_inputs(inputs) 37/37 [==============================] - 2s 19ms/step - loss: 0.6524 - accuracy: 0.5034 - val_loss: 0.5887 - val_accuracy: 0.6941 Epoch 2/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5906 - accuracy: 0.6648 - val_loss: 0.5627 - val_accuracy: 0.7218 Epoch 3/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5697 - accuracy: 0.6924 - val_loss: 0.5463 - val_accuracy: 0.7504 Epoch 4/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5558 - accuracy: 0.6978 - val_loss: 0.5346 - val_accuracy: 0.7504 Epoch 5/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5502 - accuracy: 0.7105 - val_loss: 0.5272 - val_accuracy: 0.7487 Epoch 6/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5415 - accuracy: 0.7123 - val_loss: 0.5210 - val_accuracy: 0.7608 Epoch 7/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5354 - accuracy: 0.7171 - val_loss: 0.5152 - val_accuracy: 0.7435 Epoch 8/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5301 - accuracy: 0.7214 - val_loss: 0.5113 - val_accuracy: 0.7513 Epoch 9/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5286 - accuracy: 0.7189 - val_loss: 0.5087 - val_accuracy: 0.7574 Epoch 10/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5252 - accuracy: 0.7260 - val_loss: 0.5058 - val_accuracy: 0.7539 <keras.callbacks.History at 0x7f5f9fa91c50>
loss, accuracy = model.evaluate(test_ds)
print("Accuracy", accuracy)
5/5 [==============================] - 0s 6ms/step - loss: 0.5012 - accuracy: 0.7626 Accuracy 0.762565016746521
Wykonaj wnioskowanie
Opracowany model może teraz klasyfikować wiersz z pliku CSV bezpośrednio po dołączeniu warstw przetwarzania wstępnego do samego modelu.
Możesz teraz zapisać i ponownie wczytać model Keras za pomocą Model.save i Model.load_model przed wykonaniem wnioskowania na nowych danych:
model.save('my_pet_classifier')
reloaded_model = tf.keras.models.load_model('my_pet_classifier')
2022-01-26 06:20:08.013613: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. WARNING:absl:Function `_wrapped_model` contains input name(s) PhotoAmt, Fee, Age, Type, Color1, Color2, Gender, MaturitySize, FurLength, Vaccinated, Sterilized, Health, Breed1 with unsupported characters which will be renamed to photoamt, fee, age, type, color1, color2, gender, maturitysize, furlength, vaccinated, sterilized, health, breed1 in the SavedModel. INFO:tensorflow:Assets written to: my_pet_classifier/assets INFO:tensorflow:Assets written to: my_pet_classifier/assets
Aby uzyskać prognozę dla nowej próbki, wystarczy wywołać metodę Keras Model.predict . Musisz zrobić tylko dwie rzeczy:
- Zawiń skalary w listę, aby mieć wymiar partii (
Modelprzetwarza tylko partie danych, a nie pojedyncze próbki). - Wywołaj
tf.convert_to_tensordla każdej funkcji.
sample = {
'Type': 'Cat',
'Age': 3,
'Breed1': 'Tabby',
'Gender': 'Male',
'Color1': 'Black',
'Color2': 'White',
'MaturitySize': 'Small',
'FurLength': 'Short',
'Vaccinated': 'No',
'Sterilized': 'No',
'Health': 'Healthy',
'Fee': 100,
'PhotoAmt': 2,
}
input_dict = {name: tf.convert_to_tensor([value]) for name, value in sample.items()}
predictions = reloaded_model.predict(input_dict)
prob = tf.nn.sigmoid(predictions[0])
print(
"This particular pet had a %.1f percent probability "
"of getting adopted." % (100 * prob)
)
This particular pet had a 77.7 percent probability of getting adopted.
Następne kroki
Aby dowiedzieć się więcej o klasyfikowaniu uporządkowanych danych, spróbuj pracować z innymi zbiorami danych. Aby poprawić dokładność podczas uczenia i testowania modeli, zastanów się dokładnie, które funkcje należy uwzględnić w modelu i jak powinny być reprezentowane.
Poniżej znajduje się kilka sugestii dotyczących zbiorów danych:
- Zbiory danych TensorFlow: MovieLens : Zestaw ocen filmów z usługi rekomendacji filmów.
- Zestawy danych TensorFlow: Jakość wina : Dwa zestawy danych dotyczące czerwonych i białych wariantów portugalskiego wina „Vinho Verde”. Zestaw danych o jakości czerwonego wina można również znaleźć na Kaggle .
- Kaggle: arXiv Zbiór danych : zbiór 1,7 miliona artykułów naukowych z arXiv, obejmujący fizykę, informatykę, matematykę, statystykę, elektrotechnikę, biologię ilościową i ekonomię.