<style> td { text-align: center; } th { text-align: center; } </style>
| |
 GitHub에서 소스 보기 GitHub에서 소스 보기 |
아래 예와 같은 이미지가 주어졌을 때의 목표는 "파도를 타는 서퍼"와 같은 캡션을 생성하는 것입니다.
 |
| 서핑하는 남자, 출처: wikimedia |
|---|
{kind=link}
여기에서 사용된 모델 아키텍처는 Show, Attend and Tell: Neural Image Caption Generation with Visual Attention의 영감을 받았지만 2단 레이어 트랜스포머 디코더를 사용하도록 업데이트되었습니다. 이 튜토리얼을 최대한 활용하려면 텍스트 생성, seq2seq 모델 및 어텐션 또는 트랜스포머를 약간 경험해 보셔야 합니다.
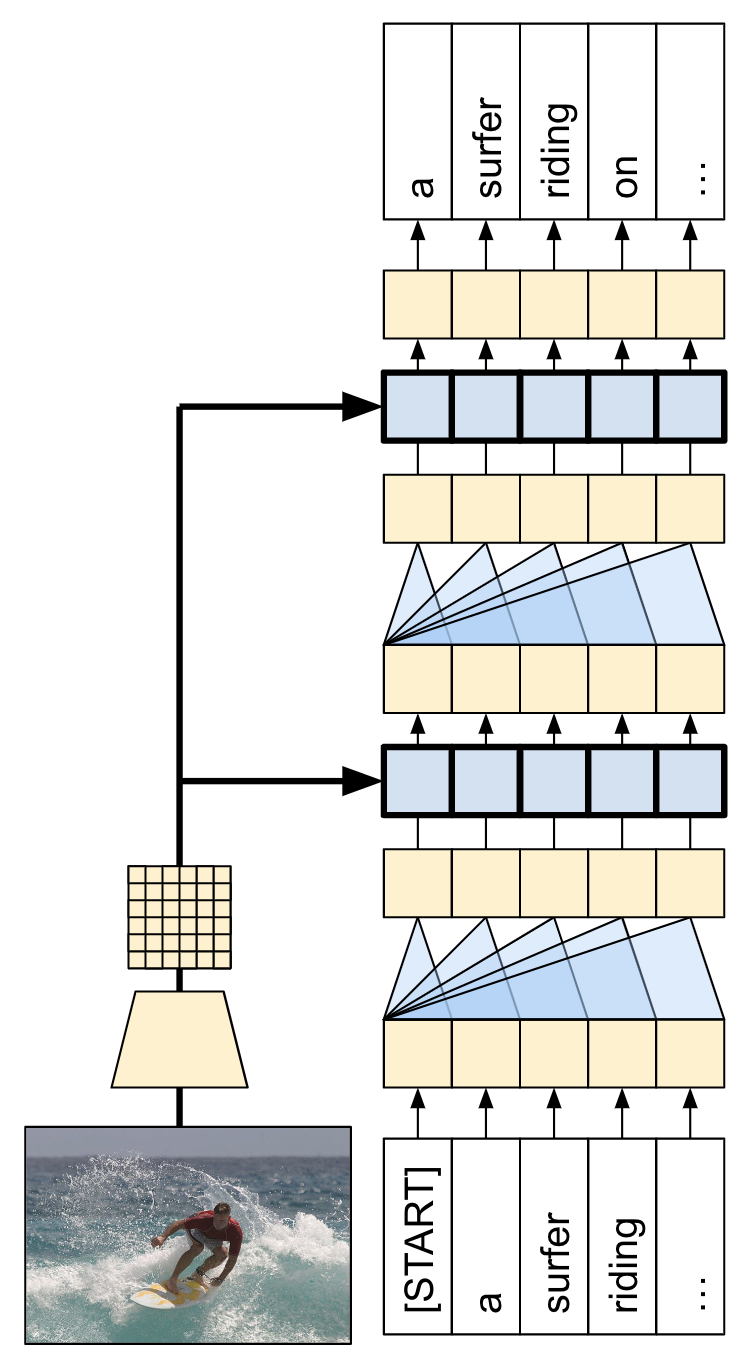
이 튜토리얼에서 빌드된 모델 아키텍처는 아래와 같습니다. 특성은 이미지에서 추출되어 트랜스포머 디코더의 크로스 어텐션 레이어로 전달되었습니다.
| 모델 아키텍처 |
|---|
|
트랜스포머 디코더는 주로 어텐션 레이어에서 빌드됩니다. 이는 셀프 어텐션을 사용하여 생성되는 시퀀스를 처리하고 크로스 어텐션을 사용하여 이미지를 처리합니다.
크로스 어텐션 레이어의 어텐션 가중치를 검사하면 모델이 단어를 생성할 때 이미지의 어떤 부분을 모델이 보고 있는지 알 수 있습니다.

이 노트북은 엔드 투 엔드 예제입니다. 노트북을 실행하면 노트북은 데이터세트를 다운로드하며 이미지 특성을 추출하고 캐싱하여 디코더 모델을 훈련합니다. 그런 다음 모델을 사용하여 새로운 이미지에 캡션을 생성합니다.
설치
apt install --allow-change-held-packages libcudnn8=8.1.0.77-1+cuda11.2E: Could not open lock file /var/lib/dpkg/lock-frontend - open (13: Permission denied) E: Unable to acquire the dpkg frontend lock (/var/lib/dpkg/lock-frontend), are you root?
pip uninstall -y tensorflow estimator keraspip install -U tensorflow_text tensorflow tensorflow_datasetspip install einops이 튜토리얼은 주로 데이터세트를 로딩하기 위해 가져오기를 많이 사용합니다.
import concurrent.futures
import collections
import dataclasses
import hashlib
import itertools
import json
import math
import os
import pathlib
import random
import re
import string
import time
import urllib.request
import einops
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from PIL import Image
import requests
import tqdm
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_text as text
import tensorflow_datasets as tfds
2022-12-14 21:23:54.920413: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory 2022-12-14 21:23:54.920526: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory 2022-12-14 21:23:54.920537: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
[선택 사항] 데이터 처리
이 섹션은 캡션 데이터세트를 다운로드하고 훈련을 위해 이를 준비합니다. 입력 텍스트를 토큰화하고 사전 훈련된 특정 추출 모델을 통해 모든 이미지를 실행한 결과를 캐싱합니다. 이는 이 섹션의 모든 것을 이해하는 데 중요하지는 않습니다.
데이터세트 선택
이 튜토리얼은 데이터세트를 선택할 수 있도록 설정되었습니다. Flickr8k 또는 Conceptual Captions 데이터세트의 작은 슬라이스 중 하나입니다. 이 두 가지는 처음부터 다운로드되고 변환되었지만 TensorFlow Datasets(Coco Captions 및 전체 Conceptual Captions)에서 사용할 수 있는 캡션 데이터세트를 사용하기 위해 튜토리얼을 변환하는 것은 어렵지 않습니다.
Flickr8k
def flickr8k(path='flickr8k'):
path = pathlib.Path(path)
if len(list(path.rglob('*'))) < 16197:
tf.keras.utils.get_file(
origin='https://github.com/jbrownlee/Datasets/releases/download/Flickr8k/Flickr8k_Dataset.zip',
cache_dir='.',
cache_subdir=path,
extract=True)
tf.keras.utils.get_file(
origin='https://github.com/jbrownlee/Datasets/releases/download/Flickr8k/Flickr8k_text.zip',
cache_dir='.',
cache_subdir=path,
extract=True)
captions = (path/"Flickr8k.token.txt").read_text().splitlines()
captions = (line.split('\t') for line in captions)
captions = ((fname.split('#')[0], caption) for (fname, caption) in captions)
cap_dict = collections.defaultdict(list)
for fname, cap in captions:
cap_dict[fname].append(cap)
train_files = (path/'Flickr_8k.trainImages.txt').read_text().splitlines()
train_captions = [(str(path/'Flicker8k_Dataset'/fname), cap_dict[fname]) for fname in train_files]
test_files = (path/'Flickr_8k.testImages.txt').read_text().splitlines()
test_captions = [(str(path/'Flicker8k_Dataset'/fname), cap_dict[fname]) for fname in test_files]
train_ds = tf.data.experimental.from_list(train_captions)
test_ds = tf.data.experimental.from_list(test_captions)
return train_ds, test_ds
Conceptual Captions
def conceptual_captions(*, data_dir="conceptual_captions", num_train, num_val):
def iter_index(index_path):
with open(index_path) as f:
for line in f:
caption, url = line.strip().split('\t')
yield caption, url
def download_image_urls(data_dir, urls):
ex = concurrent.futures.ThreadPoolExecutor(max_workers=100)
def save_image(url):
hash = hashlib.sha1(url.encode())
# Name the files after the hash of the URL.
file_path = data_dir/f'{hash.hexdigest()}.jpeg'
if file_path.exists():
# Only download each file once.
return file_path
try:
result = requests.get(url, timeout=5)
except Exception:
file_path = None
else:
file_path.write_bytes(result.content)
return file_path
result = []
out_paths = ex.map(save_image, urls)
for file_path in tqdm.tqdm(out_paths, total=len(urls)):
result.append(file_path)
return result
def ds_from_index_file(index_path, data_dir, count):
data_dir.mkdir(exist_ok=True)
index = list(itertools.islice(iter_index(index_path), count))
captions = [caption for caption, url in index]
urls = [url for caption, url in index]
paths = download_image_urls(data_dir, urls)
new_captions = []
new_paths = []
for cap, path in zip(captions, paths):
if path is None:
# Download failed, so skip this pair.
continue
new_captions.append(cap)
new_paths.append(path)
new_paths = [str(p) for p in new_paths]
ds = tf.data.Dataset.from_tensor_slices((new_paths, new_captions))
ds = ds.map(lambda path,cap: (path, cap[tf.newaxis])) # 1 caption per image
return ds
data_dir = pathlib.Path(data_dir)
train_index_path = tf.keras.utils.get_file(
origin='https://storage.googleapis.com/gcc-data/Train/GCC-training.tsv',
cache_subdir=data_dir,
cache_dir='.')
val_index_path = tf.keras.utils.get_file(
origin='https://storage.googleapis.com/gcc-data/Validation/GCC-1.1.0-Validation.tsv',
cache_subdir=data_dir,
cache_dir='.')
train_raw = ds_from_index_file(train_index_path, data_dir=data_dir/'train', count=num_train)
test_raw = ds_from_index_file(val_index_path, data_dir=data_dir/'val', count=num_val)
return train_raw, test_raw
데이터세트 다운로드
Flickr8k는 이미지당 5개의 캡션과 더욱 소규모의 다운로드를 위한 더 많은 데이터를 포함하고 있어 좋은 선택입니다.
choose = 'flickr8k'
if choose == 'flickr8k':
train_raw, test_raw = flickr8k()
else:
train_raw, test_raw = conceptual_captions(num_train=10000, num_val=5000)
Downloading data from https://github.com/jbrownlee/Datasets/releases/download/Flickr8k/Flickr8k_Dataset.zip 1115419746/1115419746 [==============================] - 25s 0us/step Downloading data from https://github.com/jbrownlee/Datasets/releases/download/Flickr8k/Flickr8k_text.zip 2340801/2340801 [==============================] - 1s 0us/step
위의 두 데이터세트에 대한 로더는 (image_path, captions) 쌍을 포함하는 tf.data.Dataset를 반환합니다. Conceptual Captions는 이미지당 캡션 1개를 포함하는 한편 Flickr8k는 이미지당 5개의 캡션을 포함합니다.
train_raw.element_spec
(TensorSpec(shape=(), dtype=tf.string, name=None), TensorSpec(shape=(5,), dtype=tf.string, name=None))
for ex_path, ex_captions in train_raw.take(1):
print(ex_path)
print(ex_captions)
tf.Tensor(b'flickr8k/Flicker8k_Dataset/2513260012_03d33305cf.jpg', shape=(), dtype=string) tf.Tensor( [b'A black dog is running after a white dog in the snow .' b'Black dog chasing brown dog through snow' b'Two dogs chase each other across the snowy ground .' b'Two dogs play together in the snow .' b'Two dogs running through a low lying body of water .'], shape=(5,), dtype=string)
이미지 특성 추출기
각 이미지에서 특성을 추출하기 위해 이미지 모델(imagenet에서 사전 훈련됨)을 사용할 것입니다. 모델은 이미지 분류기로 훈련되었지만, 설정 include_top=False는 최종 분류 레이어 없이 모델을 반환하므로 특성 맵의 최종 레이어를 사용할 수 있습니다.
IMAGE_SHAPE=(224, 224, 3)
mobilenet = tf.keras.applications.MobileNetV3Small(
input_shape=IMAGE_SHAPE,
include_top=False,
include_preprocessing=True)
mobilenet.trainable=False
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/mobilenet_v3/weights_mobilenet_v3_small_224_1.0_float_no_top_v2.h5 4334752/4334752 [==============================] - 0s 0us/step
다음은 모델에 맞게 이미지를 로드하고 크기를 조정하는 함수입니다.
def load_image(image_path):
img = tf.io.read_file(image_path)
img = tf.io.decode_jpeg(img, channels=3)
img = tf.image.resize(img, IMAGE_SHAPE[:-1])
return img
모델은 입력 매치의 각 이미지에 대한 특성 맵을 반환합니다.
test_img_batch = load_image(ex_path)[tf.newaxis, :]
print(test_img_batch.shape)
print(mobilenet(test_img_batch).shape)
(1, 224, 224, 3) (1, 7, 7, 576)
텍스트 토크나이저/벡터라이저 설정
TextVectorization 레이어를 사용하여 다음 단계에 따라 텍스트 캡션을 정수 시퀀스로 변환하게 됩니다.
- adapt를 사용하여 모든 캡션을 반복하고 캡션을 단어로 분할하고 상위 단어의 어휘를 계산합니다.
- 각 단어를 어휘의 인덱스에 매핑하여 모든 캡션을 토큰화합니다. 모든 출력 시퀀스는 길이 50으로 채워집니다.
- 단어에서 인덱스로, 인덱스에서 단어로의 매핑을 생성하여 결과를 표시합니다.
def standardize(s):
s = tf.strings.lower(s)
s = tf.strings.regex_replace(s, f'[{re.escape(string.punctuation)}]', '')
s = tf.strings.join(['[START]', s, '[END]'], separator=' ')
return s
# Use the top 5000 words for a vocabulary.
vocabulary_size = 5000
tokenizer = tf.keras.layers.TextVectorization(
max_tokens=vocabulary_size,
standardize=standardize,
ragged=True)
# Learn the vocabulary from the caption data.
tokenizer.adapt(train_raw.map(lambda fp,txt: txt).unbatch().batch(1024))
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow/python/autograph/pyct/static_analysis/liveness.py:83: Analyzer.lamba_check (from tensorflow.python.autograph.pyct.static_analysis.liveness) is deprecated and will be removed after 2023-09-23. Instructions for updating: Lambda fuctions will be no more assumed to be used in the statement where they are used, or at least in the same block. https://github.com/tensorflow/tensorflow/issues/56089
tokenizer.get_vocabulary()[:10]
['', '[UNK]', 'a', '[START]', '[END]', 'in', 'the', 'on', 'is', 'and']
t = tokenizer([['a cat in a hat'], ['a robot dog']])
t
<tf.RaggedTensor [[3, 2, 655, 5, 2, 97, 4], [3, 2, 1937, 10, 4]]>
# Create mappings for words to indices and indices to words.
word_to_index = tf.keras.layers.StringLookup(
mask_token="",
vocabulary=tokenizer.get_vocabulary())
index_to_word = tf.keras.layers.StringLookup(
mask_token="",
vocabulary=tokenizer.get_vocabulary(),
invert=True)
w = index_to_word(t)
w.to_list()
[[b'[START]', b'a', b'cat', b'in', b'a', b'hat', b'[END]'], [b'[START]', b'a', b'robot', b'dog', b'[END]']]
tf.strings.reduce_join(w, separator=' ', axis=-1).numpy()
array([b'[START] a cat in a hat [END]', b'[START] a robot dog [END]'],
dtype=object)
데이터세트 준비
train_raw 및 test_raw 데이터세트는 1:많은 (image, captions) 쌍을 포함합니다.
이 함수는 이미지를 복제하여 캡션에 1:1 이미지가 있게 됩니다.
def match_shapes(images, captions):
caption_shape = einops.parse_shape(captions, 'b c')
captions = einops.rearrange(captions, 'b c -> (b c)')
images = einops.repeat(
images, 'b ... -> (b c) ...',
c = caption_shape['c'])
return images, captions
for ex_paths, ex_captions in train_raw.batch(32).take(1):
break
print('image paths:', ex_paths.shape)
print('captions:', ex_captions.shape)
print()
ex_paths, ex_captions = match_shapes(images=ex_paths, captions=ex_captions)
print('image_paths:', ex_paths.shape)
print('captions:', ex_captions.shape)
image paths: (32,) captions: (32, 5) image_paths: (160,) captions: (160,)
keras 훈련과 호환되려면 데이터세트는 (inputs, labels) 쌍을 포함해야 합니다. 텍스트 생성의 경우 토큰은 한 단계 이동된 입력과 라벨입니다. 이 함수는 (images, texts) 쌍을 ((images, input_tokens), label_tokens) 쌍으로 변환합니다.
def prepare_txt(imgs, txts):
tokens = tokenizer(txts)
input_tokens = tokens[..., :-1]
label_tokens = tokens[..., 1:]
return (imgs, input_tokens), label_tokens
이 함수는 연산을 데이터세트에 추가합니다. 단계는 다음과 같습니다.
- 이미지를 로드합니다(로드에 실패한 이미지는 무시합니다).
- 이미지를 복제하여 캡션의 숫자와 매칭합니다.
image, caption쌍을 섞고 리배치합니다.- 텍스트를 토큰화하고 토큰을 이동하여
label_tokens을 추가합니다. RaggedTensor표현에서 텍스트를 패딩 처리된 밀도 높은Tensor표현으로 변환합니다.
def prepare_dataset(ds, tokenizer, batch_size=32, shuffle_buffer=1000):
# Load the images and make batches.
ds = (ds
.shuffle(10000)
.map(lambda path, caption: (load_image(path), caption))
.apply(tf.data.experimental.ignore_errors())
.batch(batch_size))
def to_tensor(inputs, labels):
(images, in_tok), out_tok = inputs, labels
return (images, in_tok.to_tensor()), out_tok.to_tensor()
return (ds
.map(match_shapes, tf.data.AUTOTUNE)
.unbatch()
.shuffle(shuffle_buffer)
.batch(batch_size)
.map(prepare_txt, tf.data.AUTOTUNE)
.map(to_tensor, tf.data.AUTOTUNE)
)
모델에 특성 추출기를 설치하고 다음과 같이 데이터세트에서 훈련할 수 있습니다.
train_ds = prepare_dataset(train_raw, tokenizer)
train_ds.element_spec
WARNING:tensorflow:From /tmpfs/tmp/ipykernel_676096/1004139779.py:6: ignore_errors (from tensorflow.python.data.experimental.ops.error_ops) is deprecated and will be removed in a future version. Instructions for updating: Use `tf.data.Dataset.ignore_errors` instead. ((TensorSpec(shape=(None, 224, 224, 3), dtype=tf.float32, name=None), TensorSpec(shape=(None, None), dtype=tf.int64, name=None)), TensorSpec(shape=(None, None), dtype=tf.int64, name=None))
test_ds = prepare_dataset(test_raw, tokenizer)
test_ds.element_spec
((TensorSpec(shape=(None, 224, 224, 3), dtype=tf.float32, name=None), TensorSpec(shape=(None, None), dtype=tf.int64, name=None)), TensorSpec(shape=(None, None), dtype=tf.int64, name=None))
[선택 사항] 이미지 특성 캐싱하기
이미지 특성 추출기가 변경되지 않으며 이 튜토리얼은 이미지 증강을 사용하지 않으므로 이미지 특성은 캐싱될 수 있습니다. 텍스트 토큰화의 경우도 동일합니다. 캐시를 설정하는 데 드는 시간은 훈련 및 검증 중 각 epoch에서 다시 획득됩니다. 아래의 코드는 두 개의 함수인 save_dataset 및 load_dataset를 정의합니다.
def save_dataset(ds, save_path, image_model, tokenizer, shards=10, batch_size=32):
# Load the images and make batches.
ds = (ds
.map(lambda path, caption: (load_image(path), caption))
.apply(tf.data.experimental.ignore_errors())
.batch(batch_size))
# Run the feature extractor on each batch
# Don't do this in a .map, because tf.data runs on the CPU.
def gen():
for (images, captions) in tqdm.tqdm(ds):
feature_maps = image_model(images)
feature_maps, captions = match_shapes(feature_maps, captions)
yield feature_maps, captions
# Wrap the generator in a new tf.data.Dataset.
new_ds = tf.data.Dataset.from_generator(
gen,
output_signature=(
tf.TensorSpec(shape=image_model.output_shape),
tf.TensorSpec(shape=(None,), dtype=tf.string)))
# Apply the tokenization
new_ds = (new_ds
.map(prepare_txt, tf.data.AUTOTUNE)
.unbatch()
.shuffle(1000))
# Save the dataset into shard files.
def shard_func(i, item):
return i % shards
new_ds.enumerate().save(save_path, shard_func=shard_func)
def load_dataset(save_path, batch_size=32, shuffle=1000, cycle_length=2):
def custom_reader_func(datasets):
datasets = datasets.shuffle(1000)
return datasets.interleave(lambda x: x, cycle_length=cycle_length)
ds = tf.data.Dataset.load(save_path, reader_func=custom_reader_func)
def drop_index(i, x):
return x
ds = (ds
.map(drop_index, tf.data.AUTOTUNE)
.shuffle(shuffle)
.padded_batch(batch_size)
.prefetch(tf.data.AUTOTUNE))
return ds
save_dataset(train_raw, 'train_cache', mobilenet, tokenizer)
save_dataset(test_raw, 'test_cache', mobilenet, tokenizer)
188it [00:22, 8.53it/s] 32it [00:03, 8.65it/s]
훈련을 위한 데이터 준비
이러한 사전 처리 단계 후, 데이터세트는 다음과 같습니다.
train_ds = load_dataset('train_cache')
test_ds = load_dataset('test_cache')
train_ds.element_spec
((TensorSpec(shape=(None, 7, 7, 576), dtype=tf.float32, name=None), TensorSpec(shape=(None, None), dtype=tf.int64, name=None)), TensorSpec(shape=(None, None), dtype=tf.int64, name=None))
데이터세트는 이제 keras 훈련에 적합한 (input, label) 쌍을 반환합니다. inputs은 (images, input_tokens) 쌍입니다. images는 특성-추출기 모델로 처리됩니다. input_tokens의 각 위치의 경우 모델은 지금까지의 텍스트를 보고 labels의 같은 위치에서 나열된 다음 텍스트를 예측하려고 시도합니다.
for (inputs, ex_labels) in train_ds.take(1):
(ex_img, ex_in_tok) = inputs
print(ex_img.shape)
print(ex_in_tok.shape)
print(ex_labels.shape)
(32, 7, 7, 576) (32, 21) (32, 21)
입력 토큰 및 라벨은 동일하며, 다음과 같이 한 단계만 이동하면 됩니다.
print(ex_in_tok[0].numpy())
print(ex_labels[0].numpy())
[ 3 2 20 364 197 5 6 65 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 2 20 364 197 5 6 65 4 0 0 0 0 0 0 0 0 0 0 0 0 0]
트랜스포머 디코더 모델
이 모델은 사전 훈련된 이미지 인코더가 충분하다고 가정하며 텍스트 디코더를 빌드하는 데만 집중합니다. 이 튜토리얼은 2단 레이어 트렌스포머 디코더를 사용합니다.
이 구현은 Transformers 튜토리얼의 구현과 거의 동일합니다. 더 자세한 내용은 이를 다시 참조하세요.
| 트랜스포머 인코더 및 디코더. |
|---|
| |
모델은 다음과 같은 세 가지 주요 부분으로 구현됩니다.
- 입력 - 토큰 임베딩 및 위치 인코딩(
SeqEmbedding). - 디코더 - 각각 다음을 포함하는 트랜스포머 디코더 레이어(
DecoderLayer)의 스택- 추후에 각 출력 위치가 지금까지 출력에 대해 처리할 수 있는 인과적 셀프 어텐션(
CausalSelfAttention). - 각 출력 위치가 입력 이미지를 추리할 수 있는 크로스 어텐션 레이어(
CrossAttention). - 각 출력 위치를 독립적으로 추가로 처리하는 피드 포워드 네트워크(
FeedForward) 레이어.
- 추후에 각 출력 위치가 지금까지 출력에 대해 처리할 수 있는 인과적 셀프 어텐션(
- 출력 - 출력 어휘에 대한 멀티 클래스 분류.
입력
입력 텍스트는 이미 토큰으로 분할되고 ID 시퀀스로 변환되었습니다.
CNN 또는 RNN와는 다르게 트랜스포머의 어텐션 레이어는 시퀀스의 순서에 대해 변하지 않는다는 점을 기억하세요. 몇몇 위치 입력이 없다면 시퀀스가 아닌 순서 없는 세트만 봅니다. 따라서 각 토큰 ID에 대한 단순한 벡터 임베딩 외에도 임베딩 레이어는 시퀀스 내 각 위치에 대한 임베딩 또한 포함합니다.
SeqEmbedding 레이어는 다음과 같이 정의됩니다.
- 각 토큰에 대한 임베딩 벡터를 검색합니다.
- 각 시퀀스 위치에 대한 임베딩 벡터를 검색합니다.
- 두 개를 모두 합합니다.
mask_zero=True를 사용하여 모델에 대한 keras 마스크를 초기화합니다.
참고: 이 구현은 Transformer 튜토리얼에서와 같이 고정된 임베딩을 사용하는 대신 위치 임베딩을 학습합니다. 임베딩을 학습하는 것은 코드가 약간 적지만 더 긴 시퀀스로 일반화되지는 않습니다.
class SeqEmbedding(tf.keras.layers.Layer):
def __init__(self, vocab_size, max_length, depth):
super().__init__()
self.pos_embedding = tf.keras.layers.Embedding(input_dim=max_length, output_dim=depth)
self.token_embedding = tf.keras.layers.Embedding(
input_dim=vocab_size,
output_dim=depth,
mask_zero=True)
self.add = tf.keras.layers.Add()
def call(self, seq):
seq = self.token_embedding(seq) # (batch, seq, depth)
x = tf.range(tf.shape(seq)[1]) # (seq)
x = x[tf.newaxis, :] # (1, seq)
x = self.pos_embedding(x) # (1, seq, depth)
return self.add([seq,x])
디코더
디코더는 표준 트랜스포머 디코더로, 각 세 개의 하위 레이어인 CausalSelfAttention, CrossAttention 및 FeedForward를 포함하는 DecoderLayers의 스택을 포함합니다. 구현은 Transformer 튜토리얼과 거의 동일하며, 자세한 내용은 이를 참조하세요.
다음은 CausalSelfAttention 레이어입니다.
class CausalSelfAttention(tf.keras.layers.Layer):
def __init__(self, **kwargs):
super().__init__()
self.mha = tf.keras.layers.MultiHeadAttention(**kwargs)
# Use Add instead of + so the keras mask propagates through.
self.add = tf.keras.layers.Add()
self.layernorm = tf.keras.layers.LayerNormalization()
def call(self, x):
attn = self.mha(query=x, value=x,
use_causal_mask=True)
x = self.add([x, attn])
return self.layernorm(x)
아래는 CrossAttention 레이어입니다. return_attention_scores를 사용하는 데 유의하세요.
class CrossAttention(tf.keras.layers.Layer):
def __init__(self,**kwargs):
super().__init__()
self.mha = tf.keras.layers.MultiHeadAttention(**kwargs)
self.add = tf.keras.layers.Add()
self.layernorm = tf.keras.layers.LayerNormalization()
def call(self, x, y, **kwargs):
attn, attention_scores = self.mha(
query=x, value=y,
return_attention_scores=True)
self.last_attention_scores = attention_scores
x = self.add([x, attn])
return self.layernorm(x)
아래는 FeedForward 레이어입니다. layers.Dense 레이어는 입력의 최종 축에 적용된다는 점을 기억하세요. 입력의 형태는 (batch, sequence, channels)이므로 batch 및 sequence 축에 걸쳐 포인트별로 자동으로 적용됩니다.
class FeedForward(tf.keras.layers.Layer):
def __init__(self, units, dropout_rate=0.1):
super().__init__()
self.seq = tf.keras.Sequential([
tf.keras.layers.Dense(units=2*units, activation='relu'),
tf.keras.layers.Dense(units=units),
tf.keras.layers.Dropout(rate=dropout_rate),
])
self.layernorm = tf.keras.layers.LayerNormalization()
def call(self, x):
x = x + self.seq(x)
return self.layernorm(x)
다음으로 이러한 세 가지 레이어를 더 큰 규모의 DecoderLayer에 배열합니다. 각 디코더 레이어는 시퀀스에 세 개의 더 작은 레이어를 적용합니다. 각 하위 레이어 다음의 out_seq 형태는 (batch, sequence, channels)입니다. 디코더 레이어는 또한 추후 시각화를 위한 attention_scores를 반환합니다.
class DecoderLayer(tf.keras.layers.Layer):
def __init__(self, units, num_heads=1, dropout_rate=0.1):
super().__init__()
self.self_attention = CausalSelfAttention(num_heads=num_heads,
key_dim=units,
dropout=dropout_rate)
self.cross_attention = CrossAttention(num_heads=num_heads,
key_dim=units,
dropout=dropout_rate)
self.ff = FeedForward(units=units, dropout_rate=dropout_rate)
def call(self, inputs, training=False):
in_seq, out_seq = inputs
# Text input
out_seq = self.self_attention(out_seq)
out_seq = self.cross_attention(out_seq, in_seq)
self.last_attention_scores = self.cross_attention.last_attention_scores
out_seq = self.ff(out_seq)
return out_seq
출력
출력 레이어는 각 위치에서 각 토큰에 대한 로짓 예측을 생성하려면 최소한 layers.Dense 레이어가 필요합니다.
하지만 이 작업을 좀 더 잘 수행할 수 있도록 추가할 수 있는 몇 가지 다른 특성이 있습니다.
잘못된 토큰 처리: 모델은 텍스트를 생성합니다. 패드, 알 수 없는, 또는 시작 토큰(
'','[UNK]','[START]')을 생성해서는 안됩니다. 따라서 이들에 대한 편향을 큰 음수 값으로 설정합니다.참고: 손실 함수의 이러한 토큰 역시 무시해야 합니다.
스마트 초기화: 밀도가 높은 레이어의 기본 초기화는 거의 균일한 확률로 각 토큰을 초기에 예측하는 모델을 제공합니다. 실제 토큰 분포는 균일한 것과는 거리가 멉니다. 출력 레이어의 초기 편향을 위한 최적값은 각 토큰의 확률 로그입니다. 따라서
adapt메서드를 포함해 토큰의 수를 세고 최적의 초기 편향을 설정합니다. 이는 균일한 분포(log(vocabulary_size))의 엔트로피로부터의 분포의 한계 엔트로피(-p*log(p))로 초기 손실을 줄입니다.
class TokenOutput(tf.keras.layers.Layer):
def __init__(self, tokenizer, banned_tokens=('', '[UNK]', '[START]'), **kwargs):
super().__init__()
self.dense = tf.keras.layers.Dense(
units=tokenizer.vocabulary_size(), **kwargs)
self.tokenizer = tokenizer
self.banned_tokens = banned_tokens
self.bias = None
def adapt(self, ds):
counts = collections.Counter()
vocab_dict = {name: id
for id, name in enumerate(self.tokenizer.get_vocabulary())}
for tokens in tqdm.tqdm(ds):
counts.update(tokens.numpy().flatten())
counts_arr = np.zeros(shape=(self.tokenizer.vocabulary_size(),))
counts_arr[np.array(list(counts.keys()), dtype=np.int32)] = list(counts.values())
counts_arr = counts_arr[:]
for token in self.banned_tokens:
counts_arr[vocab_dict[token]] = 0
total = counts_arr.sum()
p = counts_arr/total
p[counts_arr==0] = 1.0
log_p = np.log(p) # log(1) == 0
entropy = -(log_p*p).sum()
print()
print(f"Uniform entropy: {np.log(self.tokenizer.vocabulary_size()):0.2f}")
print(f"Marginal entropy: {entropy:0.2f}")
self.bias = log_p
self.bias[counts_arr==0] = -1e9
def call(self, x):
x = self.dense(x)
# TODO(b/250038731): Fix this.
# An Add layer doesn't work because of the different shapes.
# This clears the mask, that's okay because it prevents keras from rescaling
# the losses.
return x + self.bias
스마트 초기화는 초기 손실을 다음과 같이 상당히 줄입니다.
output_layer = TokenOutput(tokenizer, banned_tokens=('', '[UNK]', '[START]'))
# This might run a little faster if the dataset didn't also have to load the image data.
output_layer.adapt(train_ds.map(lambda inputs, labels: labels))
100%|██████████| 938/938 [00:02<00:00, 327.80it/s] Uniform entropy: 8.52 Marginal entropy: 5.29
모델 빌드하기
모델을 빌드하려면 몇몇 부분을 조합해야 합니다.
- 이미지
feature_extractor및 텍스트tokenizer. - 토큰 ID의 배치를 벡터
(batch, sequence, channels)로 변환하기 위한seq_embedding레이어. - 텍스트 및 이미지 데이터를 처리할
DecoderLayers레이어의 스택. - 다음 단어가 무엇이어야 하는지에 대한 포인트별 예측을 반환하는
output_layer.
class Captioner(tf.keras.Model):
@classmethod
def add_method(cls, fun):
setattr(cls, fun.__name__, fun)
return fun
def __init__(self, tokenizer, feature_extractor, output_layer, num_layers=1,
units=256, max_length=50, num_heads=1, dropout_rate=0.1):
super().__init__()
self.feature_extractor = feature_extractor
self.tokenizer = tokenizer
self.word_to_index = tf.keras.layers.StringLookup(
mask_token="",
vocabulary=tokenizer.get_vocabulary())
self.index_to_word = tf.keras.layers.StringLookup(
mask_token="",
vocabulary=tokenizer.get_vocabulary(),
invert=True)
self.seq_embedding = SeqEmbedding(
vocab_size=tokenizer.vocabulary_size(),
depth=units,
max_length=max_length)
self.decoder_layers = [
DecoderLayer(units, num_heads=num_heads, dropout_rate=dropout_rate)
for n in range(num_layers)]
self.output_layer = output_layer
훈련을 위해 모델을 호출하면 image, txt 쌍을 수신합니다. 이 함수를 더욱 유용하게 하려면 입력에 대해 더 유연해지세요.
- 이미지에 3개의 채널이 있다면 feature_extractor를 통해 실행합니다. 그렇지 않으면 이미 실행된 것으로 가정합니다.
- 텍스트에 dtype
tf.string이 있다면 토크나이저를 통해 실행하세요.
그런 다음 모델을 실행하는 것은 몇 단계만 수행하면 됩니다.
- 추출된 이미지 특성을 평면화하여 디코더 레이어에 대한 입력이 될 수 있도록 합니다.
- 토큰 임베딩을 검색합니다.
- 이미지 특성 및 텍스트 임베딩에서
DecoderLayer의 스택을 실행합니다. - 출력 레이어를 실행하여 각 위치에서 다음 토큰을 예측합니다.
@Captioner.add_method
def call(self, inputs):
image, txt = inputs
if image.shape[-1] == 3:
# Apply the feature-extractor, if you get an RGB image.
image = self.feature_extractor(image)
# Flatten the feature map
image = einops.rearrange(image, 'b h w c -> b (h w) c')
if txt.dtype == tf.string:
# Apply the tokenizer if you get string inputs.
txt = tokenizer(txt)
txt = self.seq_embedding(txt)
# Look at the image
for dec_layer in self.decoder_layers:
txt = dec_layer(inputs=(image, txt))
txt = self.output_layer(txt)
return txt
model = Captioner(tokenizer, feature_extractor=mobilenet, output_layer=output_layer,
units=256, dropout_rate=0.5, num_layers=2, num_heads=2)
캡션 생성하기
훈련을 시작하기 전에, 코드를 약간 작성해 캡션을 생성합니다. 이를 사용하여 훈련이 어떻게 진행되는지 확인합니다.
다음과 같이 테스트 이미지를 다운로드하여 시작합니다.
image_url = 'https://tensorflow.org/images/surf.jpg'
image_path = tf.keras.utils.get_file('surf.jpg', origin=image_url)
image = load_image(image_path)
Downloading data from https://tensorflow.org/images/surf.jpg 64400/64400 [==============================] - 0s 0us/step
이 모델로 이미지를 캡션하려면 다음을 수행합니다.
img_features추출[START]토큰으로 출력 토큰 목록 초기화.img_features및tokens를 모델로 전달.- 이는 로짓 목록을 반환합니다.
- 이러한 로짓을 기반으로 다음 토큰을 선택합니다.
- 토큰 목록에 이를 추가하고 루프를 계속합니다.
'[END]'토큰이 생성되었다면 루프를 벗어나세요.
이를 위해 "간단한" 메서드를 추가합니다.
@Captioner.add_method
def simple_gen(self, image, temperature=1):
initial = self.word_to_index([['[START]']]) # (batch, sequence)
img_features = self.feature_extractor(image[tf.newaxis, ...])
tokens = initial # (batch, sequence)
for n in range(50):
preds = self((img_features, tokens)).numpy() # (batch, sequence, vocab)
preds = preds[:,-1, :] #(batch, vocab)
if temperature==0:
next = tf.argmax(preds, axis=-1)[:, tf.newaxis] # (batch, 1)
else:
next = tf.random.categorical(preds/temperature, num_samples=1) # (batch, 1)
tokens = tf.concat([tokens, next], axis=1) # (batch, sequence)
if next[0] == self.word_to_index('[END]'):
break
words = index_to_word(tokens[0, 1:-1])
result = tf.strings.reduce_join(words, axis=-1, separator=' ')
return result.numpy().decode()
다음은 모델의 훈련되지 않은, 해당 이미지를 위해 생성된 일부 캡션으로 아직 의미가 그다지 없습니다.
for t in (0.0, 0.5, 1.0):
result = model.simple_gen(image, temperature=t)
print(result)
a a a a a a a a a a a a man a a boy being together
온도 매개변수를 통해 다음 세 모드 사이에 삽입할 수 있습니다.
- 그리디 디코딩(
temperature=0.0) - 각 단계에서 가장 확률이 높은 다음 토큰을 선택합니다. - 로짓(
temperature=1.0)에 따른 랜덤 샘플링. - 균일 랜덤 샘플링(
temperature >> 1.0).
모델이 훈련되지 않았고 빈도 기반 초기화를 사용하였으므로 "그리디" 출력은 (우선) 일반적으로 가장 일반적인 토큰인 ['a', '.', '[END]']만 포함합니다.
훈련
모델을 훈련하려면 다음과 같은 몇몇 추가 컴포넌트가 필요합니다.
- 손실 및 메트릭
- 옵티마이저
- 선택적 콜백
손실 및 메트릭
다음은 마스킹 된 손실 및 정확성에 대한 구현입니다.
손실에 대한 마스크를 계산할 때 loss < 1e8를 주의하세요. 이 항은 banned_tokens에 대한 인공적이고 불가능할 정도로 높은 손실을 버립니다.
def masked_loss(labels, preds):
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(labels, preds)
mask = (labels != 0) & (loss < 1e8)
mask = tf.cast(mask, loss.dtype)
loss = loss*mask
loss = tf.reduce_sum(loss)/tf.reduce_sum(mask)
return loss
def masked_acc(labels, preds):
mask = tf.cast(labels!=0, tf.float32)
preds = tf.argmax(preds, axis=-1)
labels = tf.cast(labels, tf.int64)
match = tf.cast(preds == labels, mask.dtype)
acc = tf.reduce_sum(match*mask)/tf.reduce_sum(mask)
return acc
콜백
훈련 중 피드백을 위해 keras.callbacks.Callback을 설정해 각 epoch의 끝에 서퍼 이미지에 대한 일부 캡션을 생성합니다.
class GenerateText(tf.keras.callbacks.Callback):
def __init__(self):
image_url = 'https://tensorflow.org/images/surf.jpg'
image_path = tf.keras.utils.get_file('surf.jpg', origin=image_url)
self.image = load_image(image_path)
def on_epoch_end(self, epochs=None, logs=None):
print()
print()
for t in (0.0, 0.5, 1.0):
result = self.model.simple_gen(self.image, temperature=t)
print(result)
print()
이는 첫 번째가 "그리디"인 이전과 같은 이전 예시와 같은 세 개의 출력 문자열을 생성하여 각 단계에서 로짓의 argmax를 선택합니다.
g = GenerateText()
g.model = model
g.on_epoch_end(0)
a a a a a a a a the a a a a a a a a a man smiles dog ocean on
또한 callbacks.EarlyStopping을 사용하여 모델이 과적합을 시작할 때 훈련을 중단합니다.
callbacks = [
GenerateText(),
tf.keras.callbacks.EarlyStopping(
patience=5, restore_best_weights=True)]
훈련
훈련을 구성하고 실행합니다.
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=1e-4),
loss=masked_loss,
metrics=[masked_acc])
빈도 보고를 더 많이 하려면, Dataset.repeat() 메서드를 사용하고 steps_per_epoch 및 validation_steps 인수를 Model.fit으로 설정합니다.
Flickr8k에서 이러한 설정을 통해 데이터세트에 대한 전체 전달은 배치가 900개 이상이지만 보고-epoch 아래에는 100개의 단계가 있습니다.
history = model.fit(
train_ds.repeat(),
steps_per_epoch=100,
validation_data=test_ds.repeat(),
validation_steps=20,
epochs=100,
callbacks=callbacks)
Epoch 1/100 99/100 [============================>.] - ETA: 0s - loss: 4.9987 - masked_acc: 0.2017 a man in a man in a man a man in the white in the running a inflatable child parlor crowd in top grinds 100/100 [==============================] - 24s 140ms/step - loss: 4.9973 - masked_acc: 0.2018 - val_loss: 4.6630 - val_masked_acc: 0.2443 Epoch 2/100 100/100 [==============================] - ETA: 0s - loss: 4.6423 - masked_acc: 0.2546 a man in a black dog is in a man a woman in a man of a white white a white yellow in a red in a black a woman her air with black boy run his is players of an another to a towards rides a stand a 100/100 [==============================] - 9s 87ms/step - loss: 4.6423 - masked_acc: 0.2546 - val_loss: 4.3656 - val_masked_acc: 0.2699 Epoch 3/100 98/100 [============================>.] - ETA: 0s - loss: 4.4123 - masked_acc: 0.2763 a man in a red in the water a boy is and a small boy in a brown child two two at a green down a water in the hanging 100/100 [==============================] - 7s 66ms/step - loss: 4.4109 - masked_acc: 0.2766 - val_loss: 4.1544 - val_masked_acc: 0.2931 Epoch 4/100 98/100 [============================>.] - ETA: 0s - loss: 4.2374 - masked_acc: 0.2961 a man in a red shirt is in a red and a red a boy in a yellow through the water a motorcyclist a in front of water 100/100 [==============================] - 6s 57ms/step - loss: 4.2346 - masked_acc: 0.2967 - val_loss: 4.0267 - val_masked_acc: 0.3058 Epoch 5/100 100/100 [==============================] - ETA: 0s - loss: 4.1222 - masked_acc: 0.3088 a man in a red shirt is in the water a man is in the water a woman down the the 100/100 [==============================] - 5s 50ms/step - loss: 4.1222 - masked_acc: 0.3088 - val_loss: 3.9308 - val_masked_acc: 0.3205 Epoch 6/100 100/100 [==============================] - ETA: 0s - loss: 4.0236 - masked_acc: 0.3136 a man in a red shirt is in the water a man is sitting in the water a blue team is playing on the water 100/100 [==============================] - 5s 54ms/step - loss: 4.0236 - masked_acc: 0.3136 - val_loss: 3.8872 - val_masked_acc: 0.3231 Epoch 7/100 100/100 [==============================] - ETA: 0s - loss: 3.9255 - masked_acc: 0.3239 a man in a blue shirt is jumping in the water a man in a large water the on the canoe snowy swinging 100/100 [==============================] - 5s 50ms/step - loss: 3.9255 - masked_acc: 0.3239 - val_loss: 3.8013 - val_masked_acc: 0.3318 Epoch 8/100 98/100 [============================>.] - ETA: 0s - loss: 3.8617 - masked_acc: 0.3311 a man in a blue shirt is jumping in the water a woman in a red shirt is in the water a man on a a holds water on a picture of the water 100/100 [==============================] - 6s 57ms/step - loss: 3.8677 - masked_acc: 0.3308 - val_loss: 3.7248 - val_masked_acc: 0.3376 Epoch 9/100 99/100 [============================>.] - ETA: 0s - loss: 3.8062 - masked_acc: 0.3335 a man in a blue shirt is jumping in the water a man is a yellow shirt is walking through a pool a money a and red shirt in sing in the wave 100/100 [==============================] - 6s 60ms/step - loss: 3.8032 - masked_acc: 0.3338 - val_loss: 3.6805 - val_masked_acc: 0.3426 Epoch 10/100 99/100 [============================>.] - ETA: 0s - loss: 3.7149 - masked_acc: 0.3418 a man in a red shirt is jumping in the water a man in a red shirt is jumping in a red is holding a blue above the water a boy girl in leaves above the ocean 100/100 [==============================] - 6s 60ms/step - loss: 3.7143 - masked_acc: 0.3415 - val_loss: 3.6240 - val_masked_acc: 0.3424 Epoch 11/100 99/100 [============================>.] - ETA: 0s - loss: 3.6224 - masked_acc: 0.3491 a man in a blue shirt is jumping into the water person on a water in the water a woman playing a dock off some waterfall 100/100 [==============================] - 5s 53ms/step - loss: 3.6225 - masked_acc: 0.3489 - val_loss: 3.5840 - val_masked_acc: 0.3431 Epoch 12/100 99/100 [============================>.] - ETA: 0s - loss: 3.5929 - masked_acc: 0.3519 a man in a blue shirt is jumping in the water a man in a blue shirt is jumping over a pool a small boy in beer in a river 100/100 [==============================] - 6s 60ms/step - loss: 3.5916 - masked_acc: 0.3518 - val_loss: 3.4882 - val_masked_acc: 0.3528 Epoch 13/100 100/100 [==============================] - ETA: 0s - loss: 3.5806 - masked_acc: 0.3484 a man in a red shirt is swimming pool a person and a red dog is swimming pool two women pose to a skate in a deck 100/100 [==============================] - 5s 52ms/step - loss: 3.5806 - masked_acc: 0.3484 - val_loss: 3.4243 - val_masked_acc: 0.3611 Epoch 14/100 99/100 [============================>.] - ETA: 0s - loss: 3.5164 - masked_acc: 0.3566 a man in a red shirt is jumping into the water a man in a blue shirt is looking at a wave a skateboarder is performing in the ocean 100/100 [==============================] - 5s 55ms/step - loss: 3.5139 - masked_acc: 0.3570 - val_loss: 3.4775 - val_masked_acc: 0.3508 Epoch 15/100 99/100 [============================>.] - ETA: 0s - loss: 3.5156 - masked_acc: 0.3557 a man in a blue shirt is jumping into the water a young boy in a wave the person and a boy shoveling into the water 100/100 [==============================] - 5s 53ms/step - loss: 3.5120 - masked_acc: 0.3560 - val_loss: 3.4817 - val_masked_acc: 0.3532 Epoch 16/100 99/100 [============================>.] - ETA: 0s - loss: 3.4653 - masked_acc: 0.3603 a man in a red shirt is riding a wave a man in a blue shirt is holding a blue water a person leaps around a rough middle of a pool in his ice 100/100 [==============================] - 6s 58ms/step - loss: 3.4648 - masked_acc: 0.3603 - val_loss: 3.3895 - val_masked_acc: 0.3593 Epoch 17/100 100/100 [==============================] - ETA: 0s - loss: 3.4460 - masked_acc: 0.3639 a man in a red shirt is swimming pool two people are in a pool a yellow clothes is being in a boat with green ocean on a pool 100/100 [==============================] - 6s 58ms/step - loss: 3.4460 - masked_acc: 0.3639 - val_loss: 3.2745 - val_masked_acc: 0.3722 Epoch 18/100 99/100 [============================>.] - ETA: 0s - loss: 3.4242 - masked_acc: 0.3613 a man in a red shirt is swimming pool a man in a blue shirt is swimming pool a man in a white tshirt waves with his head in a orange high in the air 100/100 [==============================] - 6s 55ms/step - loss: 3.4241 - masked_acc: 0.3614 - val_loss: 3.2940 - val_masked_acc: 0.3669 Epoch 19/100 100/100 [==============================] - ETA: 0s - loss: 3.3747 - masked_acc: 0.3667 a man in a red shirt is jumping into the water a man in a red hat and white jacket is jump into a wave a greyhound a young woman standing in a pool 100/100 [==============================] - 6s 57ms/step - loss: 3.3747 - masked_acc: 0.3667 - val_loss: 3.2806 - val_masked_acc: 0.3624 Epoch 20/100 98/100 [============================>.] - ETA: 0s - loss: 3.2628 - masked_acc: 0.3771 a man in a red shirt is swimming pool a man in a red shirt and white jacket is surfing closeup kayak in an orange cast cyclist 100/100 [==============================] - 5s 51ms/step - loss: 3.2634 - masked_acc: 0.3765 - val_loss: 3.3122 - val_masked_acc: 0.3580 Epoch 21/100 100/100 [==============================] - ETA: 0s - loss: 3.2708 - masked_acc: 0.3758 a man in a red shirt is swimming pool a boy is a blue wave on a wave a person is mohawk is pose in a blue 100/100 [==============================] - 5s 52ms/step - loss: 3.2708 - masked_acc: 0.3758 - val_loss: 3.2734 - val_masked_acc: 0.3624 Epoch 22/100 99/100 [============================>.] - ETA: 0s - loss: 3.2577 - masked_acc: 0.3735 a man in a red shirt is swimming pool a person in a blue shirt and white wave a boy with a dog in a black tshirt in the water 100/100 [==============================] - 6s 58ms/step - loss: 3.2566 - masked_acc: 0.3737 - val_loss: 3.2527 - val_masked_acc: 0.3716 Epoch 23/100 99/100 [============================>.] - ETA: 0s - loss: 3.2335 - masked_acc: 0.3788 a man in a blue shirt is swimming pool a boy wearing a blue shirt is in a pool a surfer is surfing 100/100 [==============================] - 5s 50ms/step - loss: 3.2340 - masked_acc: 0.3788 - val_loss: 3.2174 - val_masked_acc: 0.3700 Epoch 24/100 98/100 [============================>.] - ETA: 0s - loss: 3.2065 - masked_acc: 0.3845 a man in a red shirt is riding a wave a man in a red shirt is swimming pool an old boy holds a wave picture at the a swimming pool 100/100 [==============================] - 6s 57ms/step - loss: 3.2100 - masked_acc: 0.3843 - val_loss: 3.1551 - val_masked_acc: 0.3777 Epoch 25/100 100/100 [==============================] - ETA: 0s - loss: 3.2055 - masked_acc: 0.3775 a man in a red and white wave a man in red helmet rides a wave a little child jumps onto the air in the ocean 100/100 [==============================] - 5s 53ms/step - loss: 3.2055 - masked_acc: 0.3775 - val_loss: 3.1546 - val_masked_acc: 0.3791 Epoch 26/100 99/100 [============================>.] - ETA: 0s - loss: 3.1624 - masked_acc: 0.3847 a man in a red shirt is swimming pool a person in a red and yellow surfboard is riding a wave the man is blowing snowmobile in shallow water 100/100 [==============================] - 5s 54ms/step - loss: 3.1614 - masked_acc: 0.3847 - val_loss: 3.1898 - val_masked_acc: 0.3706 Epoch 27/100 99/100 [============================>.] - ETA: 0s - loss: 3.1709 - masked_acc: 0.3834 a man in a red shirt is riding a wave a man in a blue helmet is swimming pool on the ocean two boys in goggles in a wave 100/100 [==============================] - 5s 55ms/step - loss: 3.1709 - masked_acc: 0.3830 - val_loss: 3.0774 - val_masked_acc: 0.3817 Epoch 28/100 100/100 [==============================] - ETA: 0s - loss: 3.1661 - masked_acc: 0.3816 a man in a red shirt is riding a wave a man is being at a wave a man wearing a blue shirt helmet is jumping into a pool 100/100 [==============================] - 5s 53ms/step - loss: 3.1661 - masked_acc: 0.3816 - val_loss: 3.0868 - val_masked_acc: 0.3829 Epoch 29/100 98/100 [============================>.] - ETA: 0s - loss: 3.0804 - masked_acc: 0.3906 a man in a red shirt is swimming in the water a man in a yellow hat is surfing on a wave a surfer in the air from the kayak 100/100 [==============================] - 6s 55ms/step - loss: 3.0812 - masked_acc: 0.3904 - val_loss: 3.0592 - val_masked_acc: 0.3798 Epoch 30/100 100/100 [==============================] - ETA: 0s - loss: 3.0275 - masked_acc: 0.3964 a man in a red shirt is swimming in the ocean a man with a yellow jacket is riding a wave an leather woman wearing orange dress looks down a branch direction and pier in the background 100/100 [==============================] - 6s 59ms/step - loss: 3.0275 - masked_acc: 0.3964 - val_loss: 3.1164 - val_masked_acc: 0.3791 Epoch 31/100 99/100 [============================>.] - ETA: 0s - loss: 3.0601 - masked_acc: 0.3887 a man in a red shirt is riding a wave a man in a blue jacket is splashing in the ocean a teenage girl takes a under a handstand in the water 100/100 [==============================] - 5s 54ms/step - loss: 3.0610 - masked_acc: 0.3887 - val_loss: 3.0967 - val_masked_acc: 0.3784 Epoch 32/100 99/100 [============================>.] - ETA: 0s - loss: 3.0615 - masked_acc: 0.3897 a man in a red shirt is riding a wave a man is surfing on a wave woman in a red shirt biking in brown pink swinging by a in a sleeping 100/100 [==============================] - 6s 56ms/step - loss: 3.0597 - masked_acc: 0.3898 - val_loss: 3.0367 - val_masked_acc: 0.3847 Epoch 33/100 99/100 [============================>.] - ETA: 0s - loss: 3.0125 - masked_acc: 0.3964 a man in a blue wetsuit is riding a wave a man in a red wetsuit is being wave a child in green swim trunks swims in the water 100/100 [==============================] - 5s 52ms/step - loss: 3.0143 - masked_acc: 0.3958 - val_loss: 3.0568 - val_masked_acc: 0.3852 Epoch 34/100 99/100 [============================>.] - ETA: 0s - loss: 2.9823 - masked_acc: 0.3984 a man in a red shirt is riding a wave a man in a yellow shirt is riding a wave a man and goggles on the wave 100/100 [==============================] - 5s 53ms/step - loss: 2.9825 - masked_acc: 0.3985 - val_loss: 3.0075 - val_masked_acc: 0.3875 Epoch 35/100 99/100 [============================>.] - ETA: 0s - loss: 3.0006 - masked_acc: 0.3967 a man in a red wetsuit is riding a wave a surfer is riding a wave a person thrown its santa and blue wetsuit in a wave 100/100 [==============================] - 5s 51ms/step - loss: 3.0028 - masked_acc: 0.3965 - val_loss: 3.0462 - val_masked_acc: 0.3846 Epoch 36/100 99/100 [============================>.] - ETA: 0s - loss: 2.9830 - masked_acc: 0.3976 a man in a yellow shirt is surfing a man is falling into the water an orange and a surfer is riding a wave 100/100 [==============================] - 5s 49ms/step - loss: 2.9798 - masked_acc: 0.3980 - val_loss: 3.0503 - val_masked_acc: 0.3793 Epoch 37/100 99/100 [============================>.] - ETA: 0s - loss: 2.9679 - masked_acc: 0.4021 a man in a yellow kayak is riding a wave a man in a blue wetsuit is riding a wave a child skier 100/100 [==============================] - 5s 49ms/step - loss: 2.9660 - masked_acc: 0.4024 - val_loss: 2.9918 - val_masked_acc: 0.3895 Epoch 38/100 99/100 [============================>.] - ETA: 0s - loss: 2.9519 - masked_acc: 0.3999 a man in a red wetsuit is surfing two people in a surfboard and goggles the two men in the air on the wave 100/100 [==============================] - 5s 51ms/step - loss: 2.9514 - masked_acc: 0.3998 - val_loss: 3.0695 - val_masked_acc: 0.3821 Epoch 39/100 99/100 [============================>.] - ETA: 0s - loss: 2.8850 - masked_acc: 0.4076 a man in a red wetsuit is surfing a surfer is riding a wave this person rides a stunt wave 100/100 [==============================] - 5s 47ms/step - loss: 2.8861 - masked_acc: 0.4074 - val_loss: 3.0209 - val_masked_acc: 0.3845 Epoch 40/100 100/100 [==============================] - ETA: 0s - loss: 2.8455 - masked_acc: 0.4110 a man in a yellow kayak is surfing a man in a yellow kayak is surfing surfer while an child stands in the ocean 100/100 [==============================] - 5s 50ms/step - loss: 2.8455 - masked_acc: 0.4110 - val_loss: 3.0512 - val_masked_acc: 0.3741 Epoch 41/100 99/100 [============================>.] - ETA: 0s - loss: 2.8658 - masked_acc: 0.4102 a man in a yellow kayak is riding a wave a man in a blue surfboard is surfing a surfer is surfing on a wave 100/100 [==============================] - 5s 51ms/step - loss: 2.8632 - masked_acc: 0.4106 - val_loss: 2.9706 - val_masked_acc: 0.3903 Epoch 42/100 100/100 [==============================] - ETA: 0s - loss: 2.8930 - masked_acc: 0.4046 a man in a yellow kayak is surfing a man in a red surfboard is surfing in the ocean the surfer in a yellow helmet is shooting wave 100/100 [==============================] - 5s 54ms/step - loss: 2.8930 - masked_acc: 0.4046 - val_loss: 2.9379 - val_masked_acc: 0.4046 Epoch 43/100 100/100 [==============================] - ETA: 0s - loss: 2.8188 - masked_acc: 0.4140 a man in a yellow kayak is riding a wave a man in a red helmet is surfing a white dog stands down a wave 100/100 [==============================] - 5s 53ms/step - loss: 2.8188 - masked_acc: 0.4140 - val_loss: 2.8918 - val_masked_acc: 0.3988 Epoch 44/100 100/100 [==============================] - ETA: 0s - loss: 2.8512 - masked_acc: 0.4084 a man in a yellow shirt is riding a wave a man in a yellow kayak is doing a wave a man jumps in the green is float on her neck 100/100 [==============================] - 5s 54ms/step - loss: 2.8512 - masked_acc: 0.4084 - val_loss: 2.9555 - val_masked_acc: 0.3926 Epoch 45/100 100/100 [==============================] - ETA: 0s - loss: 2.8523 - masked_acc: 0.4072 a man in a yellow kayak is surfing a man in a blue wave as he is surfing a person is surfing in a wave 100/100 [==============================] - 5s 50ms/step - loss: 2.8523 - masked_acc: 0.4072 - val_loss: 2.9054 - val_masked_acc: 0.3986 Epoch 46/100 99/100 [============================>.] - ETA: 0s - loss: 2.8613 - masked_acc: 0.4111 a man in a yellow kayak is surfing a man in a wetsuit is riding a wave a surfer makes against a wave 100/100 [==============================] - 5s 49ms/step - loss: 2.8594 - masked_acc: 0.4115 - val_loss: 2.9277 - val_masked_acc: 0.3935 Epoch 47/100 100/100 [==============================] - ETA: 0s - loss: 2.8498 - masked_acc: 0.4072 a man in a red wetsuit is riding a wave a surfer in a red life jacket is surfing a man in a wetsuit rides a wave 100/100 [==============================] - 5s 53ms/step - loss: 2.8498 - masked_acc: 0.4072 - val_loss: 2.9910 - val_masked_acc: 0.3846 Epoch 48/100 99/100 [============================>.] - ETA: 0s - loss: 2.7612 - masked_acc: 0.4158 a man in a yellow kayak is riding a wave a person in a yellow life jacket on a surfboard man for road kayaking in the ocean 100/100 [==============================] - 5s 53ms/step - loss: 2.7613 - masked_acc: 0.4158 - val_loss: 2.9676 - val_masked_acc: 0.3871
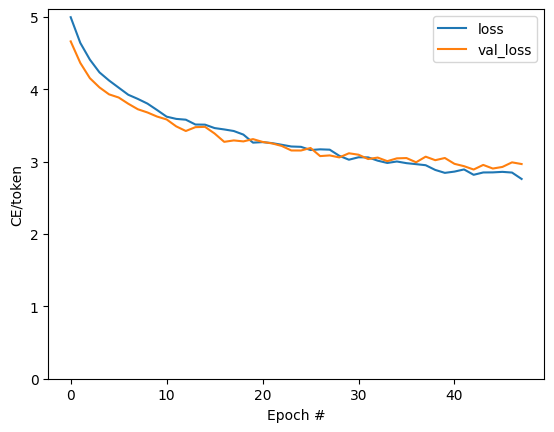
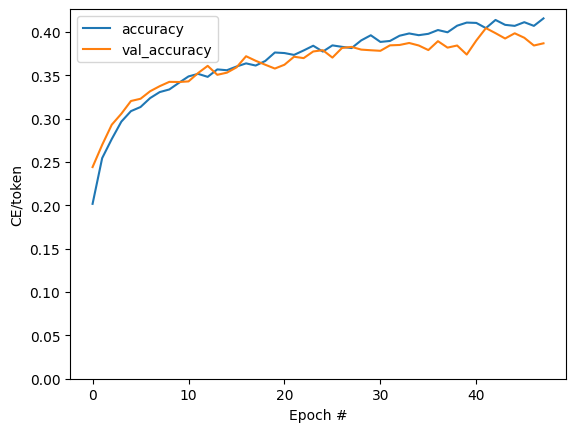
훈련 실행 동안의 손실 및 정확성 플롯:
plt.plot(history.history['loss'], label='loss')
plt.plot(history.history['val_loss'], label='val_loss')
plt.ylim([0, max(plt.ylim())])
plt.xlabel('Epoch #')
plt.ylabel('CE/token')
plt.legend()
<matplotlib.legend.Legend at 0x7fa93c0f73a0>
plt.plot(history.history['masked_acc'], label='accuracy')
plt.plot(history.history['val_masked_acc'], label='val_accuracy')
plt.ylim([0, max(plt.ylim())])
plt.xlabel('Epoch #')
plt.ylabel('CE/token')
plt.legend()
<matplotlib.legend.Legend at 0x7fa930034070>
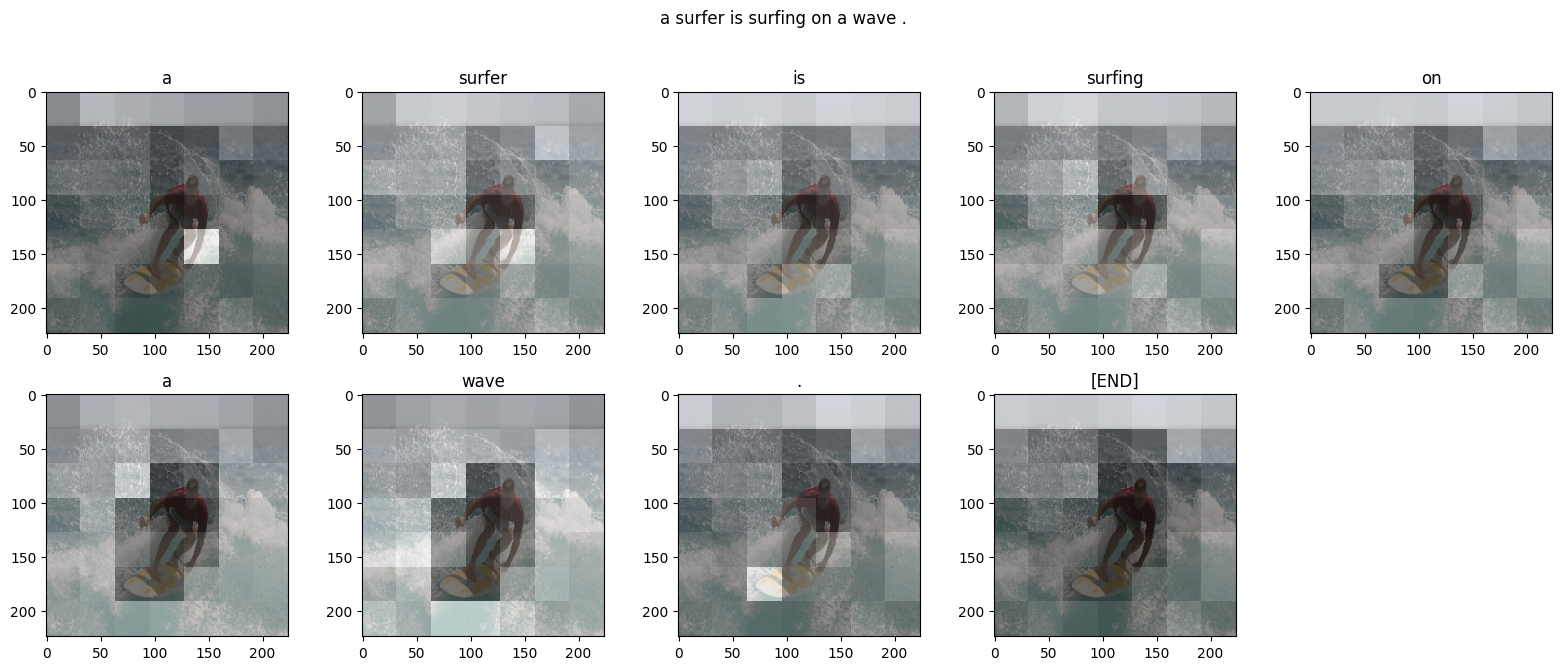
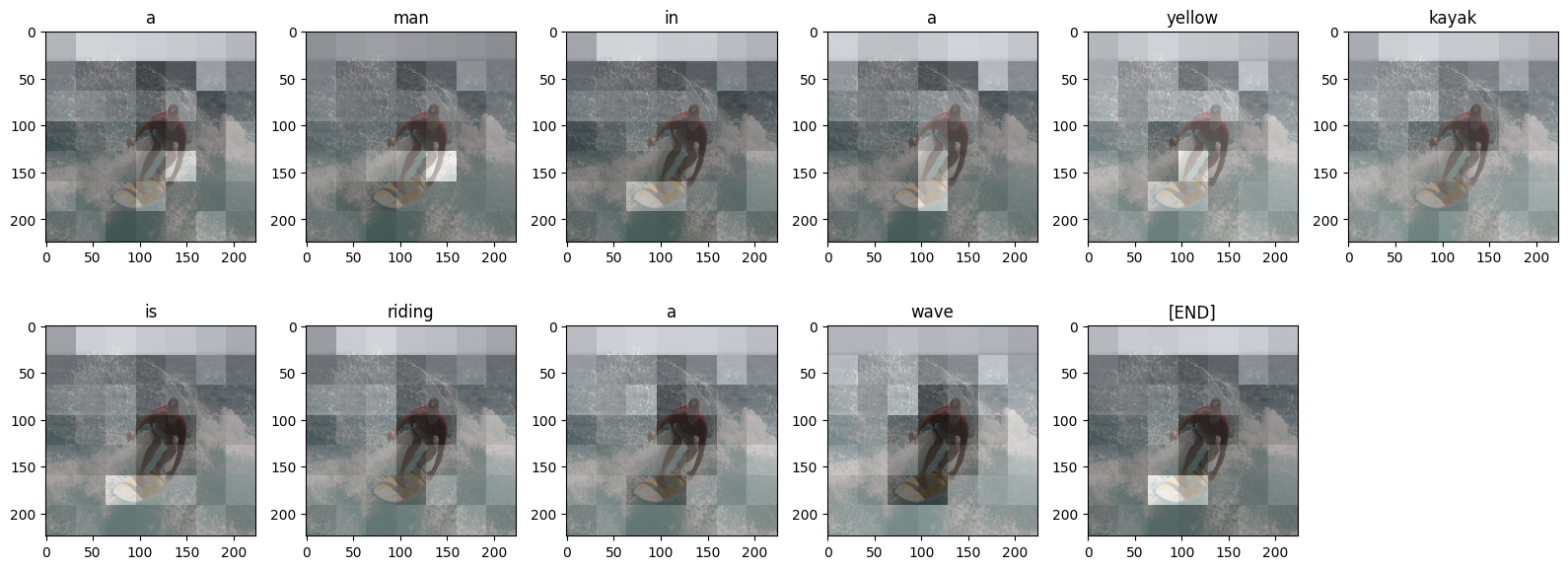
어텐션 플롯
이제 훈련된 모델을 사용하여 이미지에서 해당 simple_gen 메서드를 실행합니다.
result = model.simple_gen(image, temperature=0.0)
result
'a man in a yellow kayak is riding a wave'
출력을 토큰으로 다시 분할합니다.
str_tokens = result.split()
str_tokens.append('[END]')
각 DecoderLayers는 CrossAttention 레이어에 대한 어텐션 스코어를 캐싱합니다. 각 어텐션 맵의 형태는 (batch=1, heads, sequence, image)입니다.
attn_maps = [layer.last_attention_scores for layer in model.decoder_layers]
[map.shape for map in attn_maps]
[TensorShape([1, 2, 11, 49]), TensorShape([1, 2, 11, 49])]
따라서 image 축을 height, width로 다시 분할하는 한편 batch 축을 따라 맵을 스택한 다음 (batch, heads) 축에 대해 평균을 냅니다.
attention_maps = tf.concat(attn_maps, axis=0)
attention_maps = einops.reduce(
attention_maps,
'batch heads sequence (height width) -> sequence height width',
height=7, width=7,
reduction='mean')
이제 각 시퀀스 예측을 위한 단일 어텐션 맵이 하나 있습니다. 각 맵의 값은 합계가 1이어야 합니다.
einops.reduce(attention_maps, 'sequence height width -> sequence', reduction='sum')
<tf.Tensor: shape=(11,), dtype=float32, numpy=
array([1. , 1. , 1. , 1. , 0.9999999, 1. ,
1. , 1. , 1. , 1. , 1. ],
dtype=float32)>
따라서 다음은 출력에 대한 각 토큰을 생성하는 동안 모델이 어텐션에 주목하는 곳입니다.
def plot_attention_maps(image, str_tokens, attention_map):
fig = plt.figure(figsize=(16, 9))
len_result = len(str_tokens)
titles = []
for i in range(len_result):
map = attention_map[i]
grid_size = max(int(np.ceil(len_result/2)), 2)
ax = fig.add_subplot(3, grid_size, i+1)
titles.append(ax.set_title(str_tokens[i]))
img = ax.imshow(image)
ax.imshow(map, cmap='gray', alpha=0.6, extent=img.get_extent(),
clim=[0.0, np.max(map)])
plt.tight_layout()
plot_attention_maps(image/255, str_tokens, attention_maps)
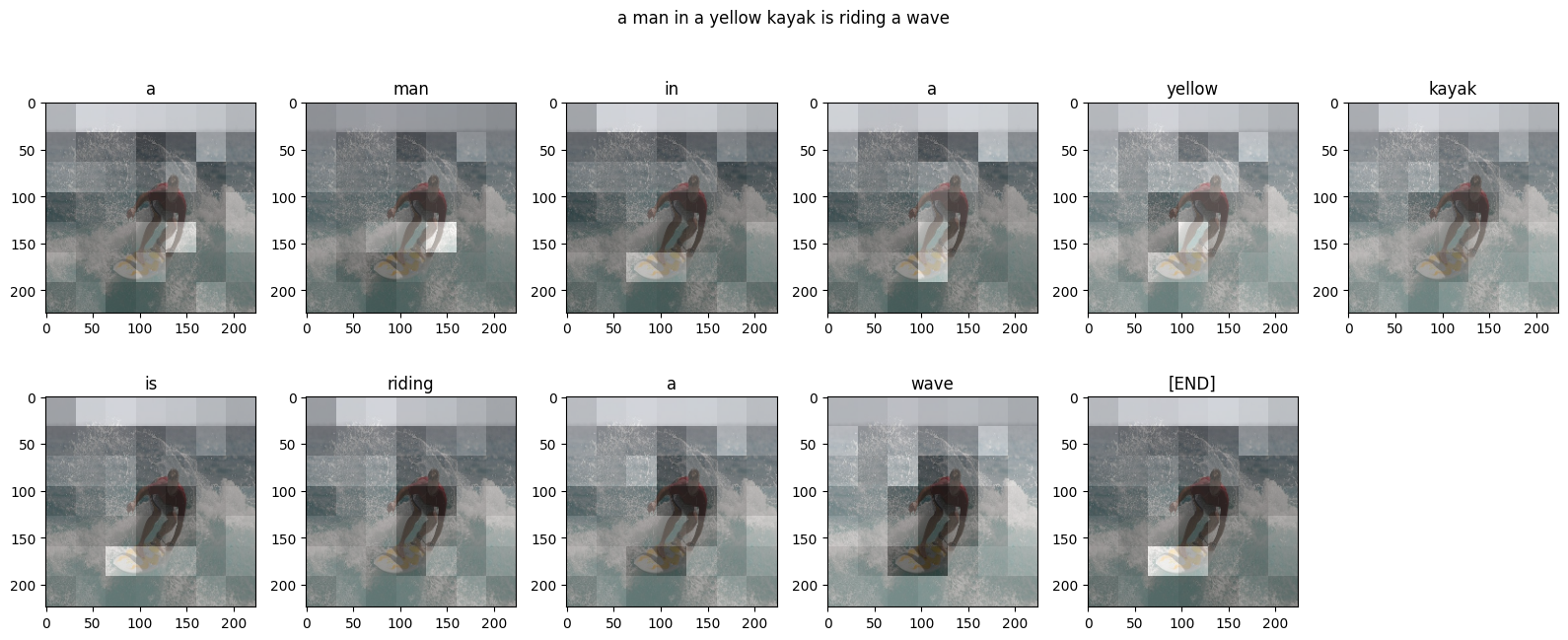
이제 더 유용한 함수로 함께 다음과 같이 통합합니다.
@Captioner.add_method
def run_and_show_attention(self, image, temperature=0.0):
result_txt = self.simple_gen(image, temperature)
str_tokens = result_txt.split()
str_tokens.append('[END]')
attention_maps = [layer.last_attention_scores for layer in self.decoder_layers]
attention_maps = tf.concat(attention_maps, axis=0)
attention_maps = einops.reduce(
attention_maps,
'batch heads sequence (height width) -> sequence height width',
height=7, width=7,
reduction='mean')
plot_attention_maps(image/255, str_tokens, attention_maps)
t = plt.suptitle(result_txt)
t.set_y(1.05)
run_and_show_attention(model, image)
자체 이미지로 시도해보기
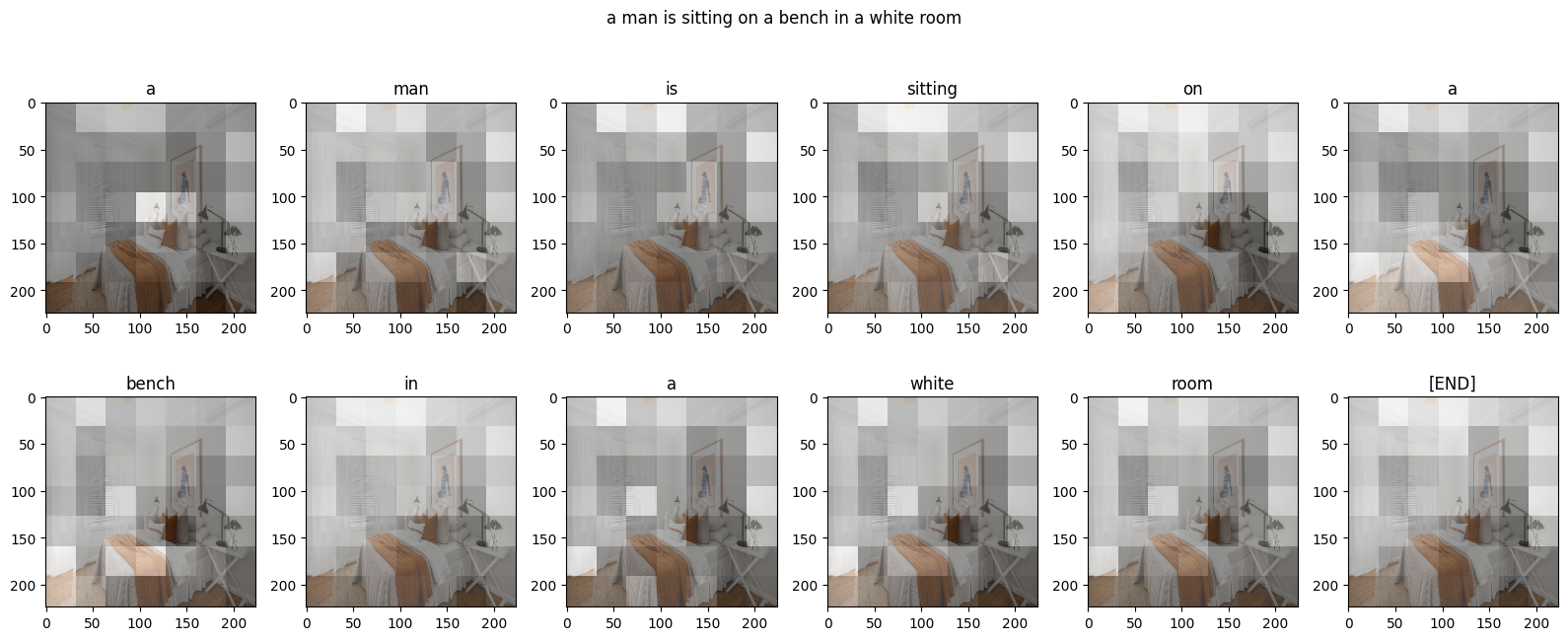
재미를 위해 방금 훈련한 모델로 자체 이미지를 캡션하는 데 사용할 수 있는 방법을 제공했습니다. 상대적으로 적은 양의 데이터로 훈련되었으므로 이미지가 훈련 데이터와 다를 수 있습니다(결과가 이상할 수 있습니다!).
image_url = 'https://tensorflow.org/images/bedroom_hrnet_tutorial.jpg'
image_path = tf.keras.utils.get_file(origin=image_url)
image = load_image(image_path)
run_and_show_attention(model, image)
Downloading data from https://tensorflow.org/images/bedroom_hrnet_tutorial.jpg 67460/67460 [==============================] - 0s 0us/step